최근 미학습 물체 파지 과제를 위해 속성 정보를 이용하여 미학습 물체를 찾는 연구를 하고있었는데, 개인연구로 진행하던 affordance grounding에도 이러한 속성 정보를 활용한 연구가 나와 리뷰하게 되었습니다.
Abstract
행동을 수행하기 위한 affordance 영역을 인식하는 것은 로봇 조작 등 지능형 시스템에서 중요한 역할을 하며, 기존 연구들은 사람이 물체를 조작하는 HOI(human-object interaction) 영상을 활용하여 얻은 지식을 물체 중심의 영상으로 전달하고자 하였습니다. 그러나 이러한 방식은 노이즈가 많이 포함되어있어 학습에 사용하기에는 제한적이라는 한계가 있습니다. 따라서 저자들은 대규모 데이터로 학습된 foundation 모델의 지식을 추가 자료로 활용하여 HOI 이미지로부터 속성과 물체의 부분 정보를 추출하여 활용하는 프레임워크를 제안합니다. HOI 영상과 foundation 모델의 지식을 결합하기 위해 저자들은 (1) spatial consistency loss와 (2) heatmap aggregation을 제안하였으며 실험적으로 성능 개선을 확인하였다고 합니다.
Introduction
기존의 컴퓨터비전 분야는 물체 인식에 집중하였으며, 행동이 이루어지는 영역에 대한 이해 능력인 affordance 이해 능력은 크게 집중을 받지 못하였습니다. affordance 이해 능력은 사람의 특징으로, 경험을 통해 물건을 움직이거나 이용하는 방법에 대하여 학습합니다. 이러한 능력은 embodied ai가 환경과의 상호작용을 위해 필수적인 능력으로, 컴퓨터비전에서 이를 인식하는 분야를 affordance grounding이라 합니다.
affordance grounding은 행동에 대한 라벨이 입력으로 들어왔을 때, 물체에 행동이 이루어질 영역을 인식하는 것으로, 사람이 경험으로부터 affordance를 학습하는 방식을 따라 기존 연구들은 사람이 물체를 이용하는 이미지인 HOI(Human Object Interaction)를 활용하여 weakly-supervised 방식으로 접근하였습니다. 그러나 이러한 weakly-supervised 방식의 경우 물체를 사용하는 이미지다보니, 해당 영역에 대한 occlusion이 발생하기도 하며, 노이즈가 많이 포함되어있어 affordance에 특화된 영역 정보를 학습하는데는 어려움이 있었으며, unseen object로의 확장에도 어려움이 있었습니다.
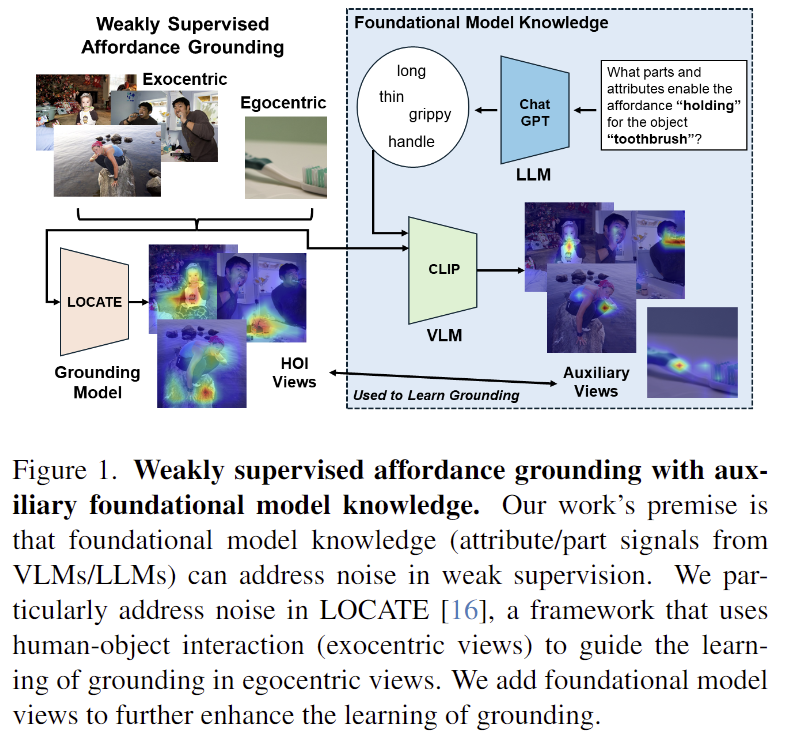
이러한 문제를 해결하기 위해 저자들은 VLMs과 LLMs를 결합하여 affordance gournding을 위한 부가적인 지식을 얻고자 하였습니다. 위의 Figure 1에서 확인할 수 있듯 GPT를 이용하여 affordance와 관련된 영역 정보와 속성 정보를 추출하고, 이 정보를 zero-shot 능력이 있는 CLIP에 입력하여 auxilary heatmap mask를 생성합니다. 이후 기존의 weakly-supervised 방식의 연구인 LOCATE(이전 X-review 참고해주세요)에 적용하여 저자들이 제안한 auxilary heatmap이 성능 개선에 효과가 있는지를 실험적으로 검증하였습니다. 또한, 학습 과정에 (1) CLIP의 지식을 물체 중심 이미지로 전달하기 위해 spatial consistency loss를 도입하고, (2) HOI 이미지와 foundation 모델의 지식을 결합하기 위한 heatmap aggregation을 제안하였습니다.
저자들의 contribution을 정리하면
- 다양한 프롬프트를 사용하여 CLIP의 zero-shot affordance grounding 능력을 평가하고, LLM의 지식을 활용하여 성능 개선을 보임
- auxiliary affordance mask 형태로 VLMs와 LLMs의 지식을 활용하는 새로운 방식 제안
- LOCATE의 물체중심적 영상과 CLIP의 grounding 결과 사이에 patial consistency loss를 통해 KLD(Kullback-Leibler Divergence; 두 분포 사이의 차이를 측정하는 지표)가 개선됨을 확인함
- HOI 영상에 VLMs 정보를 통합한 auxiluary affordance mask와 학습하는 것이 효과적임을 보임
Method
저자들은 기존의 weakly-sueprvised 방식에 사용되는 데이터(HOI 이미지)가 노이지하다는 점을 가장 큰 문제로 보았고, 이를 해결하기 위해 LLM을 이용하여 affordance 관련 속성 및 부분 정보를 알아낸 다음, 이 지식과 CLIP을 통합한 auxiliary heatmap을 생성하여 학습에 사용하는 것을 제안하였습니다. 저자들은 2023 CVPR에 공개된 weakly-supervised 방식인 LOCATE에 자신들이 제안하는 auxiliary heatmap을 적용하고 성능을 평가하였습니다.
0. LOCATE
저자들은 기존의 weakly-supervised 방식들이 사용하는 HOI 이미지가 노이지함을 문제로 보았으며, 이에 대한 개선을 위해 LLM 기반으로 생성한 auxiliary heatmap을 통해 성능을 개선시키고자 하였습니다. 따라서 기존의 LOCATE 를 베이스 프레임워크로 사용하였습니다. 다음은 LOCATE 프레임워크에 대한 설명입니다.
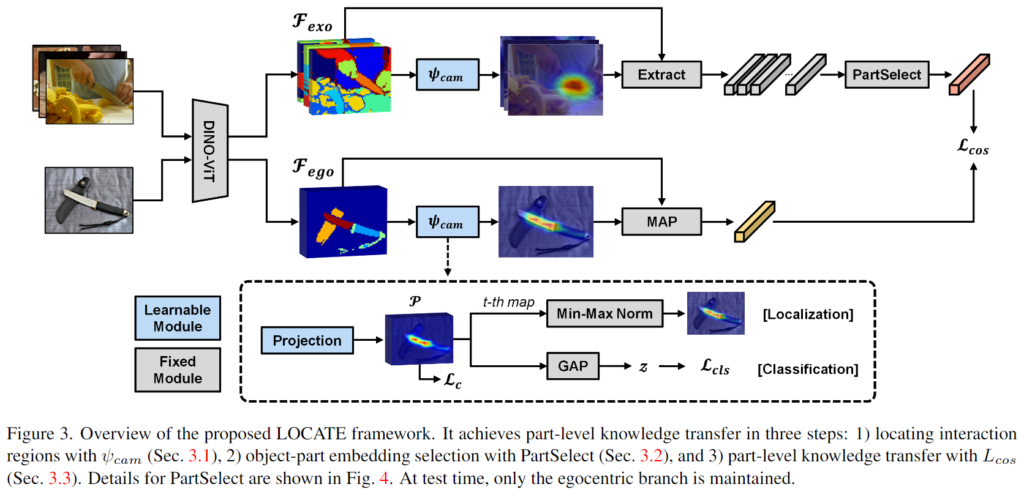
LOCATE는 물체 중심 이미지(egocentric image)x^{ego}에 대한 물체 라벨 o와 affordance 라벨 y가 주어졌을 때, k개의 상호작용 이미지(exocentric) \{x_1^{exo}, ..., x_k^{exo}\}를 샘플링하여 이용합니다. 사전학습된 DINO-ViT를 적용하여 exocentric 이미지의 feature 들을 모아 f_{exo}를 구하고 egocentric 이미지에 대한 feature f_{ego}를 구합니다. 이후 2개의 convolution 레이어로 이루어진 class-activation map 레이어를 통해 두 affordance에 대한 heatmap을 생성하도록 학습을 수행합니다.
이때 HOI 이미지에는 객체 위치나 영역이 부정확하고 노이즈가 포함될 수 있다는 문제가 있어 LOCATE는 PartSelection 모듈을 통해 객체 부분과 배경 및 사람이 가리고 있는 부분을 구분합니다. 학습에는 아래와 같이 가중합된 loss를 이용하며, 여기서 \mathcal{L}_{cls}는 클래스에 대한 cross-entropy loss, \mathcal{L}_c는 egocentric localization map이 중심에 집중하도록 하는 loss이며, \mathcal{L}_{cos}는 egocentric feature와 PartSelection으로 선택된 영역의 feature 사이의 유사도를 높이기 위한 loss 입니다.
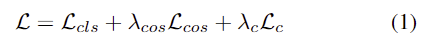
1. Foundational Model Knowledge Probing
저자들은 LLM으로부터 affordance 정보를 추출한 뒤 이를 CLIP과 결합하여 네트워크를 학습하고자 하였습니다.
(1) Gathering LLM attribute and part knowledge

직관적으로 생각해보면, 어떠한 행동이 이루어지기 위해서는 일정한 특성이 필요합니다. 예를들어, “cutting with”이라는 물체를 자르는 행동이 있을 경우, 이러한 행동을 위해서는 칼날과 같이 날카로운 부분이 있어야 합니다. 이러한 속성 정보를 저자들은 affordance grounding에 사용하고자 하였고, GPT-3.5-turbo에 아래와 같은 프롬프트를 입력하여 물체와 affordance에 대응되는 물체 영역과 3~5개의 속성 정보를 추출하였습니다.
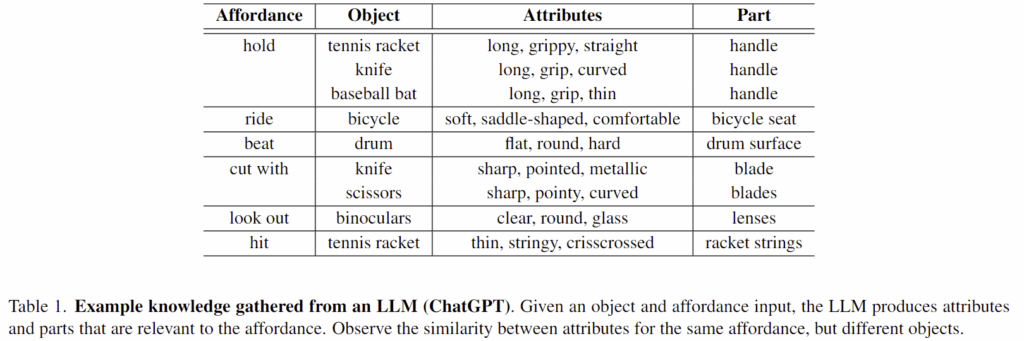
위의 Table 1은 AGD20K 데이터에 대한 일부 답변을 리포팅한 것으로, 행동에 대응되는 물체 영역과 그에 대산 속성 예시를 확인하실 수 있습니다. “hold”에 대응되는 부분들은 “handle”이며, 그에 대한 속성 예시들이 비슷한 결과를 나타내는 것을 확인하실 수 있습니다. 실제로 제가 실험을 해봤을 때도, 언어적으로 어떤 행동이 이루어질 영역에 대한 정보는 잘 추론하는 것을 확인할 수 있었습니다.
(2) Combining affordance knowledge with CLIP
다음은 앞서 추출한 정보를 CLIP과 결합하여 affordance grounding 학습에 사용하기 위한 과정입니다. CLIP의 지식을 가장 효과적으로 추출할 수 있는 방법에 대하여 알아본 뒤, LLM의 지식을 CLIP과 결합하여 grounding map을 생성합니다.
저자들은 LLM으로 얻은 객체 속성 정보와 부분 정보를 바탕으로 CLIP에 다양한 프롬프트를 입력하여 grounding map을 생성합니다. 이에 대해 아래와 같이 여러 템플릿을 적용한 실험을 통해 CLIP의 지식을 가장 효과적으로 추출하는 방식을 찾습니다. (실험파트의 Table 2에서 이에 대한 결과를 확인하실 수 있습니다.)

저자들은 CLIP ViT-B/32 버전을 사용하였으며, 멀티모달 트랜스포머 모델의 내부 동작에 대하여 설명가능하도록 만들기 위한 프레임워크를 제안한 논문[1]을 적용하여 grounding map을 생성하였습니다.
[1] Chefer, Hila, Shir Gur, and Lior Wolf. “Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers.” ICCV 2021.
2. Integrating Auxiliary Views with LOCATE
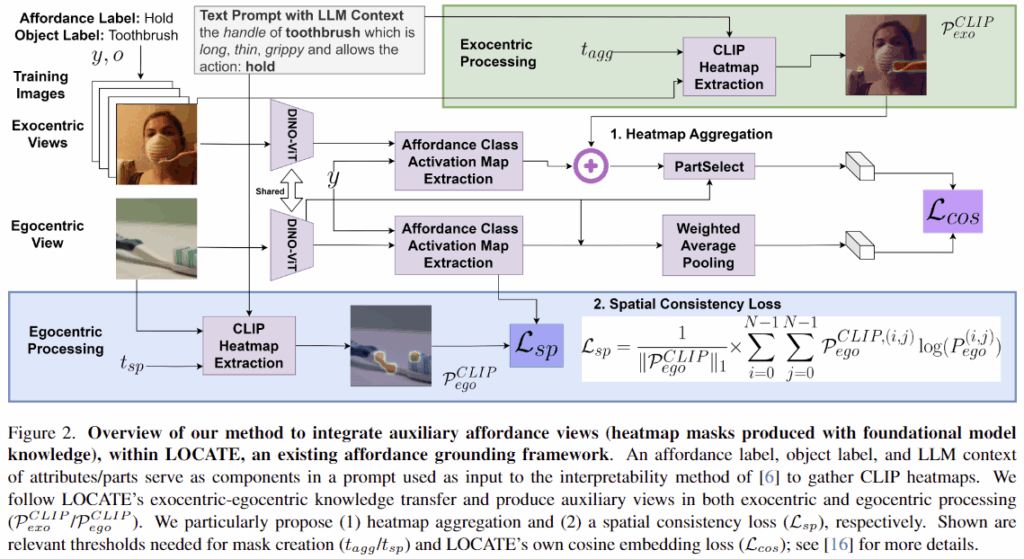
저자들은 LLM과 CLIP으로 구한 grounding map을 auxiliary affordance view로 활용하여 LOCATE 프레임워크에 보조적인 supervision 정보로 학습을 수행하였습니다. 또한, 이를 위해 spatial consistency loss와 heatmap aggregation 과정을 제안하였습니다.
(1) Spatial Consistency loss
먼저, 저자들은 물체의 부분 정보와 속성 정보를 활용하여 egocentric 이미지의 afforance grounding을 개선시키고자 하였습니다. 저자들은 egocentric 이미지에 이러한 지식을 적용하기 위해 CLIP에 프롬프트"{part} of {object} which is {attributes} and allows the action: {affordance}"로 relevance map \mathcal{F}^{CLIP}_{ego}를 생성한 뒤, 일정 임계치를 기준으로 이진화하여 relevance map \mathcal{P}^{CLIP}_{ego}를 구하였습니다.
저자들은 이렇게 구한 \mathcal{P}^{CLIP}_{ego}와, LOCATE의 egocentric feature중 affordance에 대응되는 영역을 나타내는 \mathcal{P}_{ego}가 일관성을 가지도록 하기 위해 binary cross-entropy loss를 사용하여 학습을 진행하였습니다. 이때, CLIP으로 구한 relevance map이 잘못 예측된 경우를 고려하기 위해 positive term만 사용하였다고 합니다.
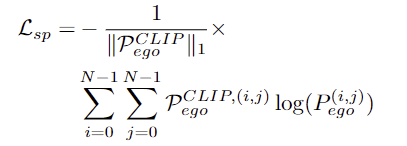
즉, Spatial Consistency loss는 네트워크가 객체 부분과 속성과 관련된 영역에 집중하도록 하는 보조적인 역할을 하도록 한 것입니다.
(2) Heatmap aggregation
exocentric에서 egocentric으로 affordance 정보를 전이하는 weakly-supervised 방식은, egocentric 이미지보다 많은 exocentric 이미지를 활용할 수 있다는 장점이 있습니다. 그러나 이러한 방식은 주로 CAMs(Class Activation Maps)의 출력을 학습에 사용하기 때문에, 노이즈가 포함될 수 있는 단점도 존재합니다. (배경 영역이 함께 포함되거나, affordance 영역이 손에 의해 가려지는 경우가 발생할 수 있음)

저자들은 부분 정보와 속성 정보가 heatmap에 가이드를 줄 수 있다고 보았으며, 이를 위해 affordance a로부터 생성한 localization map \mathcal{P}_{exo}와 앞서 구한 relevance map \mathcal{P}_{CLIP}의 결합방식(합집합/교집합/CLIP relevance map만 사용)에 따른 네트워크의 성능을 확인하였습니다. 위의 Figure 3에서 1행을 사용하면 기존의 LOCATE 방식이고, 2행은 저자들이 제안하는 auxiliary heatmap만 사용하는 방식, 3행과 4행은 각각 두 결과의 합집합과 교집합 결과를 사용하는 예시입니다. 이에 대한 실험을 통해 trade-off 관계에 대해 알아보고, 어떠한 전략이 가장 효과적인지에 대한 실험을 진행합니다.
Experiments
실험은 affordance grounding 분야에서 일반적으로 사용되는 벤치마크인 AGD20K를 이용하였으며, 20,061장의 exocentric 이미지와 3,755장의 egocentric 이미지를 이용합니다. 해당 데이터는 seen과 unseen 2가지 set이 존재하며, seen set은 36개의 affordance-object 조합으로 학습 및 평가를 수행하며, unseen set은 25개의 affordance-object 조합이 있으며, 여기서 학습에 사용되는 object와 평가에 사용되는 object는 겹치지 않도록 하여 객체에 대한 일반화 성능 평가가 가능하도록 합니다. 평가지표는 KLD와 SIM, NSS를 사용합니다.
Probing Affordance Groundings from CLIP
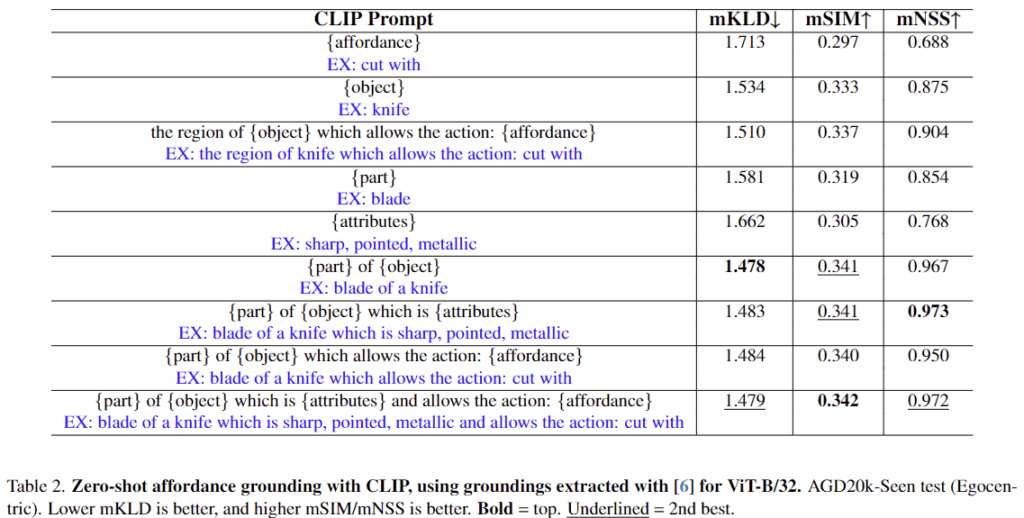
Table2는 CLIP으로부터 affordance grounding map을 효과적으로 추출하기 위한 실험 결과로,affordance grounding map을 추출하는 가장 효과적인 프롬프트를 찾습니다. Table 2를 보시면, 1행의 affordance만 사용할 경우 가장 낮은 성능을 보이며, 6행의 물체의 부분 정보는 객체 이름과 함께 사용될 때 가장 좋은 mKLD 성능(1.478)을 보이는 것을 확인하실 수 있습니다. 또한, 6행과 7행의 결과를 통해 물체 부분 정보와 객체 정보에 속성을 추가로 고려할 경우 mNSS가 가장 좋은 결과(0.973)를 달성하는 것을 확인할 수 있습니다. 마지막으로, 모든 정보를 활용할 때 mSIM에서 가장 좋은 성능(0.342)을 달성하고 나머지 두 평가지표에서도 2번째로 좋은 성능을 달성하였다는 것을 보였습니다.
Effect of spatial consistency loss
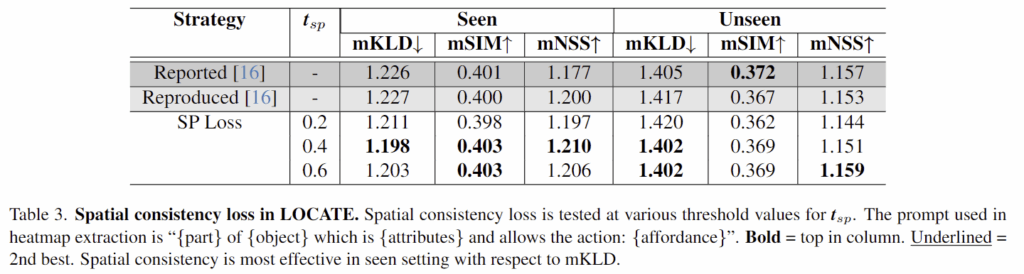
Table 3은 저자들이 도입한 spatial consistency loss를 사용하였을 때 결과를 리포팅한 것입니다. 앞의 t_{sp}는 이진화 할 때 사용한 임계치를 의미하며, 기존 방법론과 비교했을 때 대체로 성능 개선이 있었음을 확인하였습니다. 특히 Seen 케이스에서 성능 개선이 뚜렷하게 이루어졌으며, 이에 대해 저자들은 학습에 사용된 속성과 부분 정보가 대상 객체에 특화되어있기 때문이라 분석하였습니다.
Best heatmap aggregation strategy
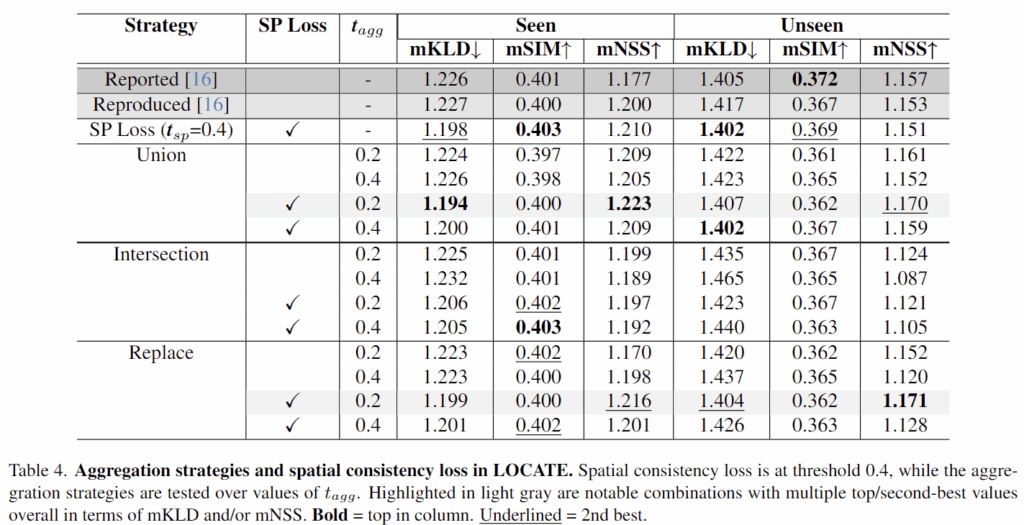
Table 4는 CLIP relevance map의 결합 방식과 그에 따른 spatial consistency loss 사용 여부의 성능을 리포팅한 결과입니다. 저자들은 1-2행과 6-7행의 결과를 통해 합집합 방식을 적용하고 SP loss를 사용한 결과가 기존 베이스라인 방식에 비해 대체로 성능이 개선되었음을 실험적으로 보였습니다.(unseen에서는 mSIM이 더 좋긴 합니다..) 또한, CLIP relevance map만을 사용한 결과(Replace)를 통해 CLIP으로 영상에서 부분 정보 및 속성 정보도 효과가 있음을 보였습니다. 그러나 Intersection에서는 유의미한 성능 개선이 이루어지지는 않았음을 보였습니다. 이는 Figure 3의 예시에서도 확인하실 수 있듯 너무 많은 영역이 제거되었기 때문으로 보입니다. 추가로 저자들은 실험을 통해 auxiliary map을 결합하는 방식뿐만 아니라 loss도 적용해야 효과적으로 성능 개선이 이루어짐을 보였습니다.
Conclusion
해당 연구는 LLM과 VLM의 기반 지식을 활용하여 affordance grounding 성능을 향상시키는 방법을 제시하였으며, 기존 학습 파이프라인에 foundation 모델의 지식을 통합함으로써 강인하고 일반화 가능한 예측이 가능함을 보였습니다. 저자들은 추후 속성과 부위에 대해 여러 객체가 공유할 수 있는 특성을 효과적으로 찾기 위한 방안을 연구하고자 하며, 속성 및 부위 정보를 조건으로 활용하여 unseen에서 더 좋은 일반화 성능을 달성할 수 있도록 연구를 진행하고자 한다고 합니다.
지금 하고자 하는 실험과 유사성이 높은 논문이네요.
LLM으로부터 속성 정보를 추출하고 해당 속성 정보를 CLIP으로 affordance + Locate를 수행하는 결과에 대한 분석 내용이 흥미로운 것 같습니다.
간단한 질문 남기고 가겠습니다.
Q1. 해당 논문이 CVPR workshop 논문인데 왜 워크샵으로 나온 것일 까요?
Q2. CLIP은 freezing이 되는 걸까요?
Q3. Tab 4에서 Replace – sp loss (x)는 clip만 사용한 방식 같은데, 이미 베이스를 넘겼네요? sp loss를 안쓴거지 weakly super vision은 적용된건지 궁금합니다.
Q3.
질문 감사합니다.
A1. 우선, 성능에 아쉬움이 있다고 생각합니다. 또한, 저자들이 제안하는 프레임워크 역시 강한 컨트리뷰션으로 인정받기는 어려웠다고 생각합니다. (글도 정리가 덜 된것 같습니다)
A2. 넵. CLIP은 어찌보면 Pseudo label 생성을 위해 사용하다보니 학습이 이루어지는 대상은 아닙니다.
A3. 네. 일단 exocentric 이미지로부터 생성한 heatmap을 학습한다는 것으로부터 weakly supervised 방식이라 보고, sp loss는 저자들이 제안한 clip 기반의 heatmap과 기존의 LOCATE에서 생성하는 heatmap이 유사해지도록 유도하고자 한 것으로, sp loss 없이도 학습이 가능합니다.(LOCATE의 heatmap을 clip 기반의 heatmap으로 변경)
안녕하세요 승현님, 좋은 리뷰 감사합니다. 기존 LOCATE의 affordance grounding 정보에 속성 정보 기반 CLIP relevance heatmap의 auxiliary한 weakly-supervised signal 주어서 grounding 성능을 향상할 수 있었던 것으로 이해했습니다.
1. 저도 태주님과 유사한 질문인데, CLIP 이 freeze된 것으로 우선은 이해했습니다. 해당 CLIP에 egocentric 이미지와 attirbutes&affordance 관련 prompt를 넣어서 그로부터 나온 relevance map이란 것은, [1]의 논문에서 제안한 방식인 건가요?
2. exocentric 이미지에 대한 CLIP relevance map도 논문 파이프라인 figure 상에는 나타나는 것 같은데, 일단 ego와 exo 둘 다에 대한 CLIP relevance map을 만들어서 활용하는 것이 맞나요?
3. Heatmap aggregation 전략에 대한 실험결과에서 Intersection에선 유의미한 개선이 이루어지지 않았던 이유를 너무 많은 영역이 제거됐기 때문이라고 말씀해주셨는데, 오히려 그럼 의문인 점은 Union의 경우 과하게 배경 영역이 포함되어 noisy한 정보를 가져갈 수 있을 것 같은데, noisy해짐에도 불구하고 성능이 좋았던 이유는 무엇일까여ㅛ. …
감사합니다.
질문 감사합니다.
1. 넵. [1]은 멀티모달 추론에 사용되는 transformer에서 self-attention뿐만 아니라 co-attention도 함께 처리하여 bi-modal transformer구조에서 프롬프트에 해당하는 영역을 확인할 수 있도록 하는 논문으로, 저자들은 CLIP ViT-B/32를 이용할 때 이에 대한 프롬프트 영역이 활성화된 relevance map을 구하였습니다.
2. exocentric에 대한 CLIP에 대한 relevance map과 LOCATE에서 사용한 HOI CAM의 Union 영역을 이용하는 것이므로 이해하신바가 맞습니다. 이를 통해 egoecntric 이미지에서도 특정 물체 영역이 집중하도록 학습하는 것이 목표입니다.
3. 우선 평가지표와 GT 마스크의 영향이라 생각합니다. 보시면 GT가 명확한 경계가 아니다보니, 조금 더 넓은 범위를 포함하였을 때 지표상으로 이익이 있는 것으로 보입니다. 이야기하신대로 노이지해진다는 점은 한계이며, 이에 대한 다른 데이터나 방향이 연구가 이루어지면 좋을 것 같습니다.(아직은 기존 연구를 따르는 연구가 많네요..)