안녕하세요 6번째 X-review 입니다. 이번에도 6D 쪽 논문을 가져왔습니다. 이번 논문 2025년 CVPR에 accept된 UA-Pose 입니다.
그럼 리뷰 바로 시작하도록 하겠습니다.
최근 6D pose estiamtion 연구에서는 학습때 보지못했던 새로운 물체에대해서 6D를 추정할 수 있는 단계까지 연구가되고있는데요 기존 category level의 성능을 많이따라잡고 있습니다. 이번에 제가 소개해드릴 논문은 이러한 흐름속에서 partial reference만을 입력으로 사용해도 6D pose를 추정할수 있는 연구입니다.
이전까지의 연구들을 간단히 짚고 넘어가겠습니다.
pose-estiamtion은 크게 model-based와 model-free방식으로 나뉘게됩니다. model-based는 CAD모델이 주어졌을 때 이 모델을 기반으로 2D-3D 매칭을 통해 pose를 예측하는 방식인데요 하지만 이 방식은 test-time에 정확한 CAD모델이 존재해야 한다는 한계점들이 있습니다.
반면에 model-free방식은 다양한 reference 이미지들만 있으면 CAD모델 없이도 pose를 주정할 수 있는데요, FoundationPose 같은 방법이 대표적입니다. 이 방식은 unseen object에 대해서도 일반화가 가능하다는 장점이 있습니다 하지만 그만큼 다양한 포즈의 RGBD이미지가 필요합니다. 즉 reference 이미지 수가 부족하거나, occulsion이 심한 경우엔 성능이 좋지 못하다는 한계점이 존재하게 됩니다. 최근에는 이런 한계를 극복하기 위해, RGB이미지로부터 3D를 생성하는 image-to-3D 기반 방법들도 제안되고 있습니다. 최근 한 연구중에서는 3D 모델을 바로 pose estimation에 활용했지만 실제와의 차이가 커서 정확도가 떨어지는 문제점들이 있었습니다.
이 논문은 기존에 방식들의 문제점들을 해결하고 uncertainy-aware한 방법을 통해서 pose estimation과 object completion을 동시에 수행하는 논문입니다. 자세히 말씀드리면 reference이미지들이 불완전하다는 가정하에 3D 모델의 unseen영역에 대한 불확실성을 모델에게 알려주고 이를 기반으로 pose 신뢰도를 판단해서 object모델을 점진적으로 보완해 나가는 구조입니다.
그럼 본격적으로 논문 리뷰 시작하도록 하겠습니다
introduction
6D object pose estimation은 위에서 설명과 같이 model-based에서 model-free 접근 방식으로 발전해 왔습니다. 기존 방법들은 일반적으로 두 가지 전제 조건에 의존합니다. 첫번째로는 정확하게 구축된 CAD 모델이 주어질 것. 두번째는 여러 방향에서 촬영된 reference 이미지들이 확보될 것. 하지만 실제 환경에서는 이러한 조건들을 충족시키기 어렵다는 한계가 있습니다. 물체의 3D 모델이 존재하지 않거나 수많은 이미지를 사전에 촬영하는 것이 비현실적이기 때문입니다.
이러한 한계를 해결하기 위해 Meta에서 발표한 FoundationPose는 model-free paradigm을 제시했습니다. 이 방법은 사전 학습된 pose refinement와 selection 네트워크를 활용하여, 16장의 reference RGBD 이미지로부터 SDF 기반의 object 모델을 생성하고 이를 기반으로 pose를 추정합니다. FoundationPose는 model-free pose estimation의 성능을 크게 향상시켰지만, 여전히 reference 데이터가 충분히 확보되어야 한다는 제약이 존재합니다. 최근에는 RGB 이미지 한 장만으로 object mesh를 생성하는 image-to-3D 기법들이 활발히 연구되고 있습니다. 그러나 기존 연구들은 이렇게 생성된 mesh를 단순히 pose estimation의 초기값으로 사용하고 끝나는 경우가 많았고 이 mesh가 실제 물체와 정확히 일치하지 않을 경우 정확한 pose 추정이 어렵다는 문제가 있었습니다.
이에 저자는 이러한 제약을 극복하기 위해서 사전 학습된 pose estimation 모듈은 그대로 두되, object model은 테스트 시점에서 계속 학습되는 구조를 제안합니다. neural SDF를 test-time에 self-supervised 방식으로 학습하게됩니다
또한 저자는 불완전환 관측만으로 object model을 구성하게 되면 해당 모델의 일부 영역은 실제로 관측된 영역이고 일부는 전혀 보지 못한 영역이 됩니다. 이러한 상황에서 어떤 영역이 신뢰가능한 정보인지 구분하지않으면 pose추정시에 잘못된 영역을 관측할 수있기에 object의 texture와 geometry뿐 아니라 uncertainty map을 포함한 hybrid representation을 도입 하여 pose filtering에서 신뢰도를 평가합니다 이러한 평가는 test time 때 단계적으로 어떻게 보완해 나갈지 기준이 됩니다.
그래서 저자의 contribution을 정리하면 아래와 같습니다
- object를 단순한 geometry나 textuer만으로 표현하는 것이 아니라 어디가 보였고 어디가 안보였는지를 명시적으로 표시하는 hybrid-object representation을 도입합니다.
- 추정된 pose가 신뢰할 수 있는지를 판단하기 위해 seen IOU라는 새로운 confidence metric을 활용하여 불확실한 pose는 아예 제거하는 filteruing 구조를 포함합니다.
- test-time 중에 들어오는 RGBD frame들을 활용하여 object model 자체를 점진적으로 개선해 나가는 online object completion 구조를 제안합니다
method
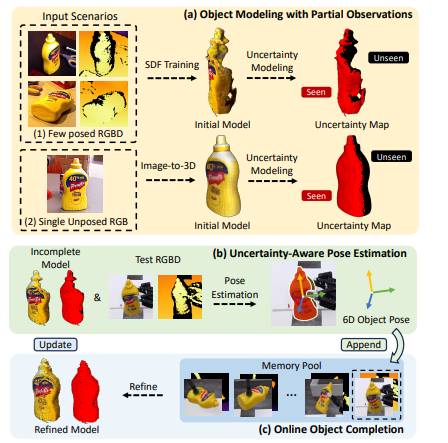
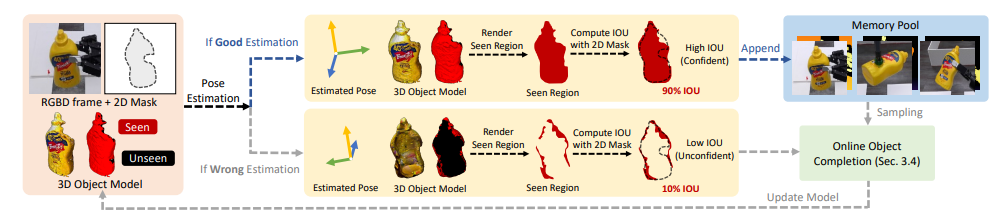
위에 보시는 fig1 의 파이프라인을 따르게 됩니다. 우선 불완전한 관측 정보만으로 초기 object M을 구성합니다. 저자는 입력 시나리오로 두가지를 나누게 됩니다
1. 2장의 reference RGBD 이미지와 해당 카메라 pose가 주어지는 경우 -> neural SDF를 학습하여 3D 객체 모델을 생성합니다
2. 단 한나의 unposed RGB 이미지가 주어지는 경우 -> image-to-3D 방식을 통해서 coarse mesh를 생성합니다
그렇다면 생성되기 까지의 과정에 대해서 설명드리도록 하겠습니다.
Hybrid Object Representation
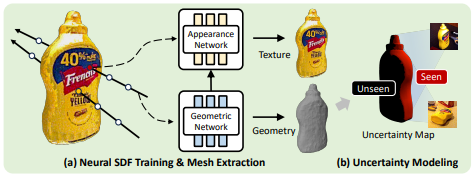
저자는 불완전환 관측만으로도 pose를 추정하기위하여 geometry와 texture 뿐만 아니라 object에 대한 uncertainty까지 통합해서 hybrid object representation을 도입했는데요 위의 fig 2-a)에서 보듯이 입력으로 주어진 RGBD 이미지들과 해당 pose 기반으로 두 네트워크를 학습합니다.
먼저, Geometric Network는 3D 공간상의 임의의 위치에 대해 Signed Distance Function(SDF) 값을 예측합니다. SDF는 어떤 3D 점이 object의 표면으로부터 얼마나 떨어져 있는지를 나타내는 함수인데 0보다 작으면 object 내부 0이면 표면 0 보다 크면 object 외부를 의미합니다. 이를 통해서 object의 3D mesh를 추출하게 됩니다. 그 다음 Appearance Network는 Geometric Network에서 얻은 중간 feature와 카메라뷰의 방향을 입력으로 받아 해당 위치에서 관측되는 RGB 색상을 예측합니다. 이 둘은 volumetric rendering방식을 통해서 self-supervised하게 학습됩니다. 여기서 말한 volumetric rendering 방식은 카메라 에서 나가는 pixel ray를 따라 일전 간격으로 3D위치를 샘플링하여 object표면에 가까운 정도에따라 가중치를 부여하고 예측한 색상 값을 누적하는 방식입니다. NERF방식이라고 보시면 될 것 같습니다.(저도 김수환교수님 강의때 들었던게 끝이라 이해하는데 시간이 걸렸습니다… 설명을 원하시면 댓글 부탁드립니다..)
Uncertainty Modeling
위에서 얻은 3D mesh 와 appearance 정보를 바탕으로 uncertainty를 판단해야합니다. 저자는 mesh의 각 점에 대해서 reference 이미지에서 관측된 적이 있는지 없는지를 가지고 구분하게 되는데 mesh상의 각 점들을 reference 이미지에 투영하여 비교하게됩니다
저자는 두 가지 지표를 도입하게되는데요 Uncertainty 와 seen IOU입니다. 먼저 uncertainty rate는 투영했을때 비율을 의미합니다
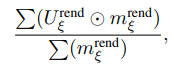
m -> object mask이고 U는 해당 pose로 렌더링한 uncertainty map입니다.
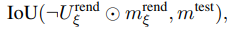
다음으로는 seen IOU는 현재 pose로 렌더링한 object mask중 확실한 영역과 (seen) 과 test image의 실제 object mask간의 겹치는 정도를 측정하였습니다. 실제 관측된 영역만을 기준으로 IOU를 계산하게됩니다
Uncertainty-aware Pose Estimation
이렇게 생성된 hybrid object representation과 uncertainty 정보를 활용하여, 이제 실제 6D pose를 추정하는 단계로 들어갑니다. 우선 여기서의 입력들은 비디오 시퀀스라는 가정하에 pose initialization-> refinment -> selection의 과정을 반복적으로 수행하게됩니다.
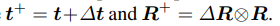
처음 중심점을 기준으로 median depth를 사용하여 translation초기값을 설정하고 각 pose 후보에대해 현재 pose object를 렌더링한 RGBD와 test이미지의 실제 RGBD를 비교해 pose 보정값을 예측하게됩니다.
이렇게 refinment된 pose들 중 uncertainty rate와 seen IOU 기준으로 신뢰성 있는 pose만 선택됩니다 반대로 조건을 만족하지 못한 pose는 버려지게 됩니다. 선택된 pose들은 Memory pool에 저장되어 지고 이것을가지고 점진적으로 3D object를 보완하는데 사용된다고 합니다.
Uncertainty-aware Object Completion
앞서 설명드린 것처럼 매 프레임마다 6D pose를 예측하고 이 중에서 Uncertainty Rate와 Seen IoU가 모두 높은, 즉 신뢰할 수 있는 pose만 Memory Pool에 저장하게 됩니다. 이렇게 누적된 정보는 현재 프레임의 pose예측 결과가 신뢰하기 어려운 경우에 memory pool바탕으로 다시 object를 완성시키는 과정을 수행하게 됩니다.
하지만 저자는 프레임수가 늘어나게되면 메모리 한계가있어 효율성을 높이기위해서 처음에는 memory pool에 저장된 프레임 수가 충분히 적으면 모두 사용하고 일정 개수 K개를 초과하는 순간부터pool의 첫 번째와 마지막 프레임은 고정적으로 포함시켜서 시작과 끝 시점을 고정합니다. 이후에는 가장 많은 unseen영역을 추가로 보여주는 프레임을 하나씩 선택해서 보여줍니다. 이 과정을 반복해서 총 K개의 프레임을 뽑고 이를 기반으로 다시 SDF를 수행하게됩니다. 이렇게 선택된 프레임들을 기반으로 새로운 SDF를 학습하게되면 기존 object 모델 보다 정교한 3D 모델이 생성된다고 합니다.
Experiments
저자가 사용한 데이터셋은 YCB -video, YCBInEOAT, HO3D입니다.
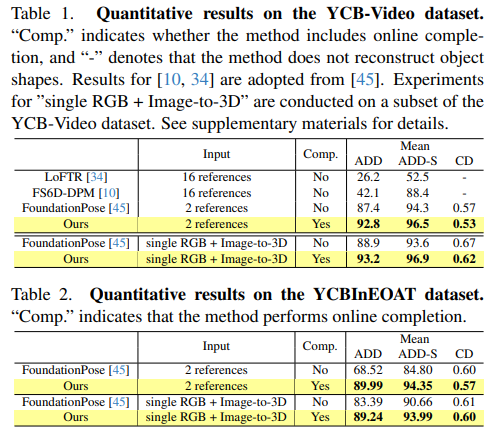
실험 결과 2 reference 또는 단일 RGB , image-to-3D 에서 ADD 및 ADD(-s)성능이 기존 FoundationPose를 넘겼습니다 특히 online completion을 추가함을써 geometry 복원성능인 chamfer distance 까지도 개선되었음을 보였습니다. 저자는 chamfer Distance를 통해서 불완전한 관측만으로 구성된 초기 3D object 모델이 online completion을 거치면서 얼마나 정확히 보완되는지를 정량적으로 보여주었습니다.

또한 HO3D에서도 FoundationPose 보다 2 references 만을 가지고도 높은 성능을 보입니다 다만 아쉬운점은 기존에 foundationPose의 16장의 reference 성능과의 비교 성능은 없었습니다. 이는 저자가 주장한 reference를 줄이는데 비교하기 위해서 그랬지 않을까 하는 생각이 듭니다.
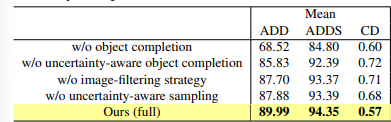
추가적으로 abblation study입니다. 저자가 제안한 uncertainty 기반 filtering과 sampling 전략이 중요하다는 걸 강조하고 있습니다. 특히 object completion 자체를 제거하면 성능이 확연히 떨어지는 걸 보면 UA-Pose는 단순 추정 모델이 아니라 feedback 기반으로 3D 객체를 점진적으로 refinement하는 시스템이라는 걸 확인할 수 있습니다.

정성적 자료입니다 OOC가 없는 경우에는 occlusion 영역이나 뒷면이 복원되지 않아서 뚫린 geometry가 그대로 유지되는 반면 OOC를 적용한 경우는 새로운 시점에서 관측된 정보들이 점차 통합되면서 더 완성도 높은 object model이 구성되는 걸 확인할 수 있습니다. 특히 t=1 이후에는 두 방법의 결과가 명확히 갈리는 모습이 눈에 띕니다
실은 논문을 반쯤 읽었을때 부터 너무어려워서 이해하는데 어려움이 컸습니다 질문 주시면 답변드리겠습니다!
안녕하세요 우진님 리뷰 감사합니다.
저도 최근에 관심이 좀 생겼는데 혹시 처음에 말씀하신 “3D 모델을 바로 pose estimation에 활용했지만 실제와의 차이가 커서 정확도가 떨어지는 문제점”이 존재하는 연구가 어떤 연구인지 알 수 있을까요?
또 test-time 중에 online object completion 같은 경우는 seen IoU를 기준으로 필요하다고 판단되는 경우에만 진행을 하는건가요? Input으로 받은 객체의 불완전한 형상을 가지고 여러 Pose를 뽑아서 그걸 가지고 추론 과정에서 SDF를 재학습 하는 것으로 이해해도 될까요? 그렇다면 추론 시간이 좀 오래걸리거나 구조가 조금 복잡한 물체의 경우 완성된 결과 자체가 불완전할 수도 있을 것 같다는 생각이 드는데, 저자의 얘기도 있을까요?
답변감사합니다 영규님!
Q1 .-> A : GigaPose 같은 기존 연구에서는 image-to-3D 방법으로 생성된 모델을 바로 pose estimation에 사용했다고 저자는 언급했습니당
Q2 -> 또 test-time 중에 online object completion 같은 경우는 seen IoU를 기준으로 필요하다고 판단되는 경우에만 진행을 하는건가요?
넴 무조건적으로만 하는건 아닙니다 online object completion은 seen IOU threshold가 0.7이하로 떨어지는 경우에만 수행된다고 합니다. 계산비용이랑 불필요한 재학습을 줄이기위한 것 이라고 생각하셔도 될거같습니다
Q3 -> 음 실시간 추론까지는 아니지만 30초 내외로 작동한다고 합니다. 또한 복잡한 물체에 대한 언급은 없지만 완벽한 모델을 복구하는데는 아직 한계가 있을듯합니다. 다만 점진적으로 좋아지는 거는 기대할 수 있지않을까 생각이드네요 아무래도 test때 학습을 하는거라
안녕하세요, 좋은 리뷰 감사합니다.
SDF에서 어떤 3D 포인트가 물체의 표면으로부터 얼마나 떨어져 있는지를 나타내는 함수라고 말씀해주셨는데요, 그걸 계산했을 때 0이면 표면이 되는건데 그럼 처음에 함수를 계산할 때의 물체의 표면이라는건 어떻게 정의되는건가요 ? 표면인 곳을 찾으려고 이 함수를 계산하는 거 같은데 그걸 계산하는 기준이 3D 포인트와 물체의 표면이다보니 이 때의 표면은 3D 공간에서 어떻게 정하는건지 궁금합니다.
감사합니다.
좋은 질문 감사합니다.!
처음부터 “표면”이 명확히 주어지는 건 아닙니다. neural SDF 기반 방식에서는 RGBD 이미지와 object mask 그리고 카메라 포즈를 통해 관측된 포인트들을 3D 공간에 복원하고 이 포인트들이 물체의 표면 근처에 있다고 가정합니다.
이후에 관측된 점들 주변에서의 거리들로 부터 학습하는겁니다 self-supervision입니다 감사합니당
손우진 연구원님 좋은 리뷰 감사합니다.
uncertainty map U^{rend}는 어떻게 구해지는 궁금합니다.
또한, pose initialization에서 초기 rotation은 어떻게 선정하게되나요?
마지막으로 YCBInEOAT 데이터는 YCB-V와 어떤 차이가 있나요?
ablation study 결과를 보면, object completion이 성능 개선에 가장 큰 영향을 준 것으로 보입니다. object completion이 이루어지지 않았을 때 Uncertainty-aware Pose Estimation가 성능을 보완할 수 있는 것 같은데, 이에 대한 실험 결과는 어떤 것을 보면 될 지 궁금합니다. 4가지 요소에 대하여 하나씩 빼는 것 말고 조합에 대한 결과가 궁금한데 이는 따로 리포팅 된 결과가 없을까요?
답변감사드립니다!!!
Q1.
먼저 이 맵은 3D object mesh의 각 vertex가 reference 이미지들에서 보였는지 여부를 기준으로 생성됩니다.학습된 mesh의 vertex들을 각 reference 이미지 시점에서 투영해보고 하나라도 보였다면 해당 vertex는 “certain (0)”, 하나도 보이지 않았다면 “uncertain (1)“로 표시한다고합니다
Q2
논문에서는 translation을 object mask 중심의 median depth를 기준으로 초기화한 뒤, rotation은 icosphere 기반으로 sampling했다고합니다 object 중심을 기준으로 카메라 뷰포인트 생성하고 그 뷰포인트마다 in plane rotation을 적용해서 가설을 만들었습니다
Q3
우선 제가 이해한 바로는 YCB-video는 사람 손으로 조작되는 영상 중심이고 후자는 실제 로봇 작업환경에 가까운 RGBD 영상으로 구성되어 있다는 차이로 알고있습니다
Q4
저 또한 아쉽지만 ablation study 는 하나씩 제거하는 거 외에는 supplementary에도 없더라구요 ..
안녕하세요 우진님, 리뷰 잘 읽었습니다.
애초에 어려운 내용이기도 한 것 같고, 정보가 생략된 부분이 많아 이해하기 어려웠는데요. 덕분에 질문이 좀 됩니다.
1. ‘기존 연구들은 이렇게 생성된 mesh를 단순히 pose estimation의 초기값으로 사용하고 끝나는 경우’ 에서 pose estimation의 초기값으로 어떻게 사용한다는 것인가요? 단순히 입력으로 들어가고 그 이후의 something이 있다는 것인가요?
2. 본 논문에서 뜻하는 학습되는 neural SDF는 bundleSDF를 뜻하는 것인가요? NeuS를 뜻하는 것인가요?
3. image-to-3d 방법론은 무얼 사용한 건가요..
4. fig 2-a) 에서 말하는 입력으로 주어진 RGBD 이미지들과 해당 pose 부분이 잘 이해가 되질 않습니다. object mesh를 뚫고 지나가는 저 ray 기반의 rendering된 이미지를 말하는 건가요? 아니면 저 mesh를 만들기전의 원본 raw 이미지를 말하는 건가요? 뭔가 figure랑 설명이 매치가 잘 안되는 것 같습니다. 제가 figure를 보고 이해하기론 RGBD 이미지와 pose로 SDF 학습시켜 뽑은 mesh에서 sampling한 ray 2개에서 뽑은 point들을 각각 apperance net이랑 geometric net에 들어가는 것으로 이해했는데요.. 어떤 게 맞나요?
5. neural SDF, apperance net, geometric net 모두 학습하는 network가 맞나요? 학습 시그널을 어떻게 준다는 건지 잘 모르겠습니다. loss 수식 설명이 필요한 것 같아요..
6. uncertainty modeling에서 크사이가 뜻하는 바가 뭔가요? 이게 없어서 uncertainty rate의 의미를 잘 해석하지 못했습니다..
7. Uncertainty-aware Pose Estimation 시, 처음 중심점은 무엇이고, median depth는 무엇인가요? 뭔가 t랑 R 머시기 하면서 써진 식 아래에 그런 설명이 있는데 수식이랑 notation 매핑이 안되어서 이해가 안됩니다.
8. uncertainty rate와 seen IOU 기준 신뢰성 있는 pose 선정 시에, 그 기준값은 뭔가요?
9. online completion과 chamfer distance이 각각 무엇이고 그들간의 관계가 정확히 뭔가요? online completion은 memory 기반의 feedback형식의 그냥 object completion과 다른 점이 있나요?
10. OOC가 뭔가요?
답글 감사합니다!
Q1.
초기값은 보통 pose hypothesis 생성 단계에서 r과 T을 추정하는 데 사용된다는 뜻입니다. image-to-3D나 CAD mesh를 이용해 만든 물체 모델을 이용하여 렌더링 기반의 이미지 생성 → 그것과 실제 이미지 간의 feature matching 또는 loss 비교를 통해 pose를 초기화합니다. 이후에는 refinement module 등을 통해 이 pose가 업데이트됩니다. 저자는 이를 test time에서 계속 업데이트하는 방식으로 사용했습니
Q2
UA-Pose에서 사용하는 neural SDF는 특정 이름 있는 모델을 그대로 가져다 쓴 것은 아니고, 여러 기존 접근에서의 개념을 응용한 구조입니다.
neural SDF 자체는 기존의 NeuS + BundleSDF 기반의 구조를 제안한 것입니당
Q3. image-to-3d 방법론은 무얼 사용한 건가요..
InstantMesh를 사용합니다.
Q4.
넵 거의 맞는데 조금 수정드리자면 rendering이미지가 아니라 raw RGBD 데이터에서 유도한 3D포인트들이 먼저이고 그걸 neural SDF를 학습한 뒤 mesh를 없습니다 그리고 이 mesh위에서 sampling한 ray가 실제로 pose estimation시점 또는 color rendering 시점에 appearance network와 geometry network의 입력으로 사용됩니다 저도 다시보고 알았습니다 .ㅎㅎ
Q5.
네 모두 학습되는 네트워크가 같습니다 (수식은 논문에있는데 나중에 직접 만나서 설명드리겠습니다..조금 말로 설명하기가 어려움이있어요..)
Q6
여기서 말한 크사이는 r,T를 포함한 것입니다…
Q7
이게 우선 test image에서 object mask의 중심점을 선택합니다 그 위치의 단일값이 아니라 mask안의 depth분포에서 중앙값을 취한다는 의미입니다. 계속해서 r,T랑 업데이트가 되니까 보정한 RT의 최종값이라고 생각하시면됩니다
Q8.
우선 둘다 0.5의 기준입니다 uncertainty는 작아야하고 seen IOU는 0.5보다 커야 신뢰할 수있다고 합니다
Q9.
chamfer distance는 3D point cloud의 mesh간의 유사도를 수치로 나타내는 거리 기반지표입니다 두 meshㄱ의 모든 점 쌍간의 최단거리를 평균적으로 측정해 reconstruction을 평가하는겁니다.
말 그대로 online방식입니다 기존 object completion은 정적인 조건하에서 복원하는데 test-time에서 입력이 점진적으로 들어오는 상황은 고려를 못하는겁니다.
Q10
online object completion의 약자입니다