안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 Video Question Answering (VideoQA) 연구입니다. VideoQA 모델이 생성하는 답변이 시각적 정보에 얼마나 근거하고 있는 지를 Video Grounding을 통해 평가하고 기존 VideoQA 연구들을 개선하기 위한 방법을 제안한 연구입니다.
Video Question Answering (VideoQA)
VideoQA는 비디오 V=\{v_1, v_2,..., v_3\}와 질문 Q에 기반하여 자연어 답변을 생성하거나 주어진 답변 선택지 중에 정확한 답변을 선택하는 Video Language Understanding task입니다. Video에 대한 이해와 자연어에 대한 이해를 토대로 비디오 내에 있는 유의미한 정보에 집중하고 시각 정보를 토대로 질문에 대한 답변을 구하는 것을 목표로 합니다. 일반적으로 (V, Q) -> A로 정의되며, 오늘 다룰 VideoQA의 답변 A = [a_1, a_2,... a_5]은 5개의 답변 후보지 중에 하나를 고르는 객관식입니다. 일반적으로 예측은 입력을 바탕으로 조건부 확률 P(A|V, Q)를 최대화하는 방향으로 학습됩니다. A^* = arg max P(A|V, Q)
Introduction
Video Question Answering (VideoQA)은 비전-언어 모델(Vision-Language Models, VLMs)의 종합적인 이해 능력을 평가할 수 있는 핵심 task로 오랫동안 주목 받으면 연구되었습니다. VideoQA는 꽤 오랜기간 연구되어오며 많이 발전했습니다만, 모델들의 답변이 실제로 비디오를 근거로 하고 있는가에 대해서는 많이 고려되지 않았습니다. 저자는 VideoQA 모델의 답변이 정확도로만 판단되기 때문에 현재 평가방식은 모델의 실제 이해력 혹은 해석 가능성(intepretability)을 보장하는 것이 아니라고 지적합니다. 정확도 기반 평가방식은 모델이 정답을 맞혔는지에 초점을 맞추고 있으며, 그 답변이 영상 내 실제 근거에 기반한 것인지를 판단할 수 있는 수단은 부족합니다. 따라서, 저자는 모델이 정답을 예측할 때 비디오 내 어떤 프레임과 어떤 객체를 참조했는 지를 파악하는 것이 중요하며, 이를 통해 모델의 답변에 대한 근거를 알 수 있다고 말합니다. 이에 따라 저자는 3가지 질문을 제기하고 있습니다.
- Q1: 현재 VideoQA 모델이 실제로 시각적 단서에 기반하여 정답을 예측하고 있는가
- Q2: 높은 정답률을 기록하는 VideoQA 모델이 높은 Grounding 성능을 기록하는가
- Q3: 저자의 방법(weakly 접근)이 실제로 QA 및 Grounding에 도움이 되는가
저자는 위 질문들에 대한 대답하기 위해 새로운 데이터셋을 제안합니다. 저자가 제안하는 NExT-GQA 데이터셋은 기존에 많이 평가되던 데이터셋인 NExT-QA 데이터셋을 확장한 데이터셋으로 답변에 근거가 되는 구간을 사람이 직접 라벨링한 데이터셋입니다. 아래 Table1은 제안하는 NExT-GQA의 통계를 보여주고 있으며 주목할만한 점은 Train셋에 Grounding 라벨이 없다는 점입니다. 이는 저자의 접근이 Weakly이기 때문입니다. 즉, Question에 대한 답변만을 학습에 활용할 뿐 답변에 대한 근거가 되는 구간의 정보는 학습에 활용하지 않습니다.
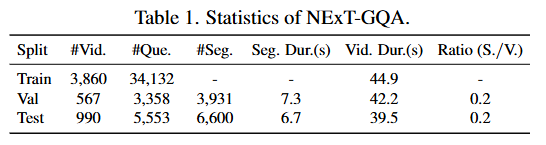
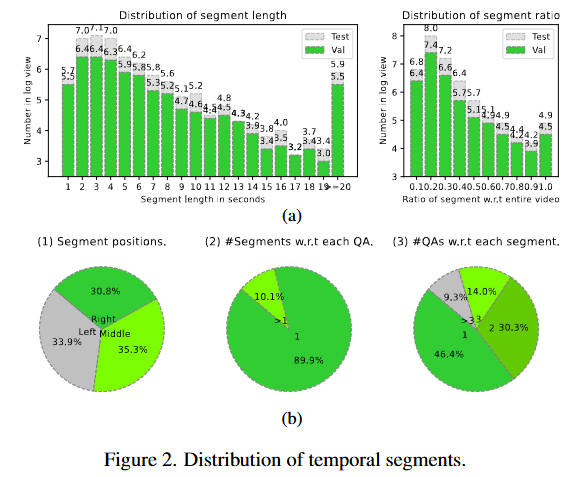
Figure2는 NExT-GQA 데이터셋의 validation셋과 test셋의 grounding GT에 대한 정보를 보여줍니다. 구간의 위치가 특정 위치에 편향되어있지 않아 제안하는 데이터셋이 벤치마크로서 기능하기에 충분하다는 것을 보여줍니다.
저자는 기존에 존재하던 VideoQA 모델들을 이 데이터셋에 평가하여 정확도 69%를 기록하는 현 SOTA 모델도 Grounding 성능은 16%를 기록했음을 강조하며 정답률과 Grounding 능력을 통한 답변의 시각적 정당성을 함께 평가해야함을 주장합니다. 또한, Grounding과 QA를 같이 평가할 수 있는 새로운 평가지표를 제안합니다. VideoQA 답변의 정답률과 Grounding의 성능을 비교 분석하며 Weakly세팅에서의 VideoQA 및 Grounding의 성능을 향상시킬 수 있는 방법을 제안합니다.
즉, 정답만 맞추던 기존의 VideoQA 모델이 갖는 근본적인 한계점을 지적하고 답변의 시각적 정당성을 부여할 수 있는 학습 방법과 답변의 시각적 정당성을 평가할 수 있는 데이터셋과 평가지표를 제안합니다.
Evaluation Metric
저자의 방법론에 대해 설명하기 전에 먼저 어떻게 VideoQA과 Grounding 능력을 평가하는 지를 설명하겠습니다. 저자가 제안하는 Weakly GQA(visually-Grounded Question Answering)은 기존 VideoQA의 답변과 답변의 근거가 되는 구간을 출력하는 task입니다. 기존 VideoQA 모델은 실제 비디오 내에서 시각적 근거에 기반하여 답변을 하고 있는 지를 반영할 수 없습니다. 모델의 답변이 비디오의 어떤 부분에 근거하여 답변을 생성하고 있고, 그 근거의 구간이 얼마나 일치하는 지를 측정하는 Grounding Metric의 필요성을 강조합니다.
먼저 저자는 IoP(Intersection over Prediction)을 제안합니다. IoU와 비슷하지만, 분모를 모델의 예측으로 하는 평가지표인데, 이는 모델이 근거로 하는 구간이 실제 GT에 포함된다면 모델이 예측의 근거를 정확히 보고 있다는 것을 의미하기에 사용합니다. IoU보다는 조금 더 유한 성능 평가지표입니다. 저자는 QA의 정확도, GQA의 정확도, IoP, IoU 총 4가지 지표를 통해 모델을 평가하며, GQA 정확도는 IoU가 0.5 이상인 예측을 정확하다고 예측하는 것으로 답변과 Grounding이 모두 정확해야 정답으로 간주하는 정확도를 의미합니다. 자세한 모델의 성능은 방법론 이후 실험 결과에서 확인해보겠습니다.
Method
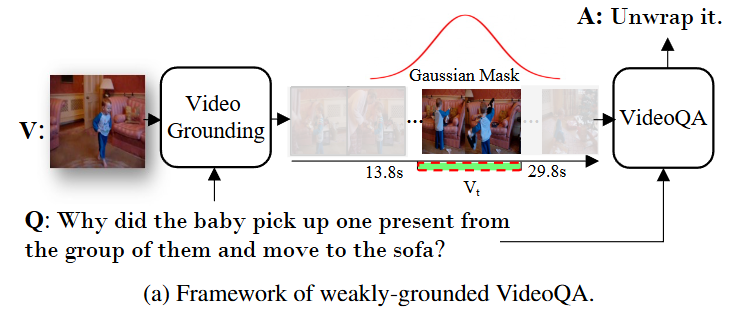
우선 저자의 접근은 Weakly입니다. Fully-supervised Visually-Grounded Video Question Answering은 라벨링 비용이 너무 큰데다가 학습 데이터셋에 편향되기에 확장성이 부족합니다. 따라서 temporal annotation이 없이 학습할 수 있는 방법론의 필요성을 강조합니다. 저자의 방법은 기존 VideoQA 모델 위에 lightweight grounding 모듈을 붙이는 방식으로 grounding supervision 없이도 attention을 조절해 모델이 질문에 관련된 구간이 집중할 수 있도록 유도합니다.
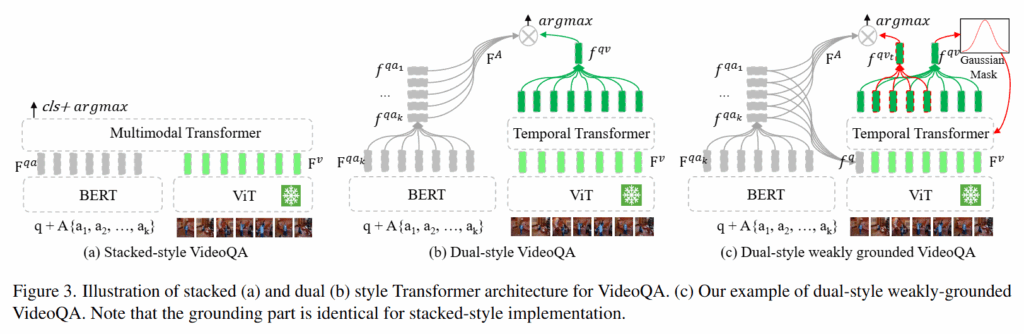
Figure3의 (a)와 (b)는 기존 VideoQA 모델들의 구조입니다. (c)는 저자가 lightweight 모듈을 더한 구조로 Grounding 능력을 강화하는 방법입니다. (a) Stacked-style은 심플하게 각각 질문과 비디오를 인코더를 거친 후에 Multimodal Transformer를 통해 질문에 대한 답변을 생성하는 것으로 가장 간단하면서도 효과적인 방법입니다. 다만, 연산량이 크고 큰 Multimodal Transformer를 사용해야 어느정도 성능이 나온다는 단점이 있습니다. (b) Dual-style은 각각의 모달리티를 서로 특징을 추출한 후에 비디오 특징을 Temporal Transformer를 통해 시간 정보를 주입합니다. 그 후 전체 영상의 특징을 추출해 질문, 답변과의 유사도를 기반으로 정답을 예측하는 방법입니다.
저자는 3가지의 방법을 통해 grounding 능력을 향상시켰습니다. Post-hoc(PH)와 Naive Gaussian(NG)와 Naive Gaussian+(NG+)입니다. 여기서 +는 contrastive learning입니다.
post-hoc 방식은 grounding 학습을 따로하지 않고 temporal attention의 출력을 기반으로 시각적 근거를 추출하는 방식입니다. temporal transformer의 attention map에서 최대 attention 값을 갖는 시간을 주변으로 임계값으로 잘라 temporal 구간을 정의하는 방법으로 dual-style에서는 QA prediction token에 대한 attention, stacked-style에서는 multi-head attention을 평균하여 사용합니다. 기존 모델의 grounding 능력을 평가하기 위한 방법으로 grounding을 따로 학습하지는 않아 기존 모델이 답변을 할때 어느 프레임을 근거로하고 있는 지를 확인하기 위한 방법입니다.
naive gaussian은 가우시간 기반 soft grounding기법으로 모델이 grounding 시점을 예측하도록 합니다.
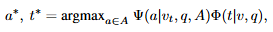
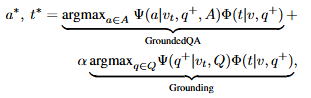
여기서 \Psi는 시점 v_t에서 질문 q에 대한 답변 a를 예측하는 모듈이고, \Phi는 grounding 모듈로 질문 q와 v에 대해서 중요한 시간 t를 예측합니다. grounding을 먼저 수행하고 grounding을 기반으로 localized QA를 수행합니다. 여기서 평균과 표준편차(분산)은 학습 가능한 파라미터로 전체 영상 길이를 d라고 할때 t=(\mu - \gamma\sigma, \mu + \gamma\sigma) \cdot d를 구간으로 학습합니다. dual transformer 위에 gaussian mask prediction head를 추가하는 것으로 teamporal feature에 대한 gaussian weighted token aggregation을 수행합니다. 이 방법은 시각적 근거 학습할 수는 있지만, naive한 방법으로 grounding 성능 향상에 한계가 존재합니다. 아래 그림은 NG 방법을 나타내는 그림입니다.
naive gaussian+ 는 cross-modal self-supervision을 도입하는 것으로 positive 질문 q^+에 대한 grounding 구간을 가깝게, negative 질문 q^-에 대한 groudning 구간은 멀리하는 것으로 contrastive learning을 수행합니다.
Q는 positive 질문들의 집합인 Q^+와 negative 질문들의 집합인 Q^-의 합집합으로 간단하게는 질문들 집합을 의미합니다. 이때, 전체 질문 중에 10%는 GPT4로 rephrasing하여 생성하는 것으로 Q^+를 확장하여 사용합니다. positive sample의 수가 적을 것을 우려하여 추가해준 방법입니다. 아래 그림은 NG+의 contrastive learning을 보여주는 그림입니다.

저자는 위와 같은 Gaussian Masking과 contrastive learning을 통해 기존 VideoQA모델도 Grounding 능력을 갖출 수 있게 되었으며, 단순히 답변을 생성하는 것이 아니라 비디오의 어느 구간에서 답변의 근거를 갖추게 되었는지를 설명할 수 있게 되었다고 설명합니다.
Experiments
- Q1: 현재 VideoQA 모델이 실제로 시각적 단서에 기반하여 정답을 예측하고 있는가
- Q2: 높은 정답률을 기록하는 VideoQA 모델이 높은 Grounding 성능을 기록하는가
- Q3: 저자의 방법(weakly 접근)이 실제로 QA 및 Grounding에 도움이 되는가
저자는 위 3가지 질문에 대한 답을 위해 실험을 진행했고, 실험결과를 통해 위 3개의 질문에 대한 해답을 구합니다.
Q1: 현재 VideoQA 모델이 실제로 시각적 단서에 기반하여 정답을 예측하고 있는가
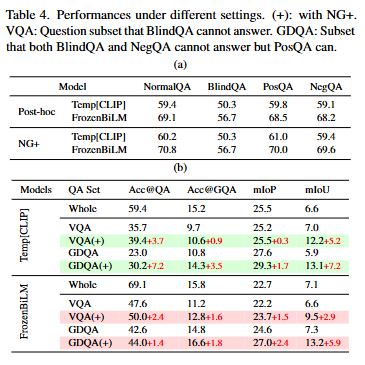
위 실험에서의 NormalQA는 기존의 VideoQA 방식입니다. BlindQA는 비디오를 제공하지 않은 상황에서 질문만을 통해 답변을 생성하는 평가방식입니다. PosQA는 positive 질문을 NegQA는 negative 질문을 통해 답변을 생성하는 평가방식입니다. 저자는 만약 기존 모델들이 시각적 정보를 기반한 답변을 생성하고 있었다면, NormalQA에서의 성능과 BlindQA의 성능 차이가 심해야하고, PosQA와 NegQA의 성능 차이가 심해야한다고 설명합니다.
TempCLIP은 dual-style의 VideoQA이고, FrozenBiLM은 stacked-style의 VideoQA 모델입니다. 두 모델 모두 저자의 예상대로 성능차이가 심하지 않고 둘 모두 비슷한 성능을 기록하고 있는 것을 통해 기존의 모델들은 시각적 정보를 통해 답변을 생성하는 것이 아니라 시각적 정보를 참고하지 않더라도 자연어 이해능력을 통해 답변을 생성하고 있다고 설명하고 있습니다. 즉, Language Understanding 능력에 편향되어 시각적 정보는 크게 참조하지 않더라도 답변을 생성하고 있는 것을 의미합니다. 저자는 이것은 잘못되었음을 지적하고 Grounding의 중요성을 강조합니다.
즉, Q1에 대한 저자의 결론은 기존 모델들이 시각적 근거에 기반한 답변을 생성하지 않고 있다는 점을 지적합니다.
Q2: 높은 정답률을 기록하는 VideoQA 모델이 높은 Grounding 성능을 기록하는가
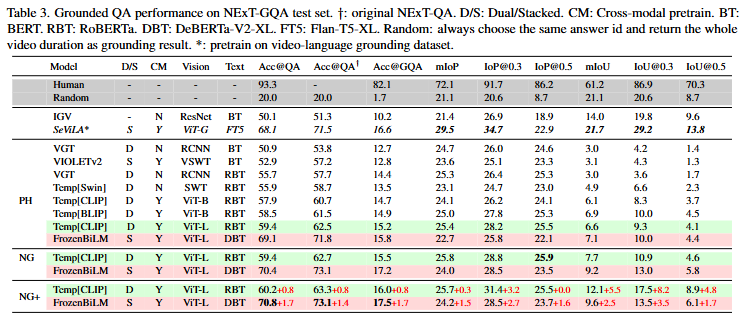
Table3는 저자의 NExT-GQA에서의 기존 모델들의 성능과 저자의 방법을 도입한 모델의 성능을 비교하고 있습니다. Acc@QA는 기존 VideoQA의 평가, Acc@GQA는 grounding 능력을 포함한 성능입니다. 앞서 설명한 TempCLIP과 FrozenBiLM을 베이스라인으로 삼았으며, 두 모델은 각각 dual-style, stacked-style에서의 SOTA 모델입니다. FrozenBiLM의 Acc@QA 성능이 TempCLIP보다 뛰어나지만, Acc@GQA, IoP, IoU에서는 더 낮은 성능을 보이는 것을 확인할 수 있습니다. 저자는 이를 통해 Q2에 대한 결론을 내리고 있으며, QA 성능이 높다고해서 Grounding까지 잘하는 것은 아니라고 말합니다.
Q3: 저자의 방법(weakly 접근)이 실제로 QA 및 Grounding에 도움이 되는가
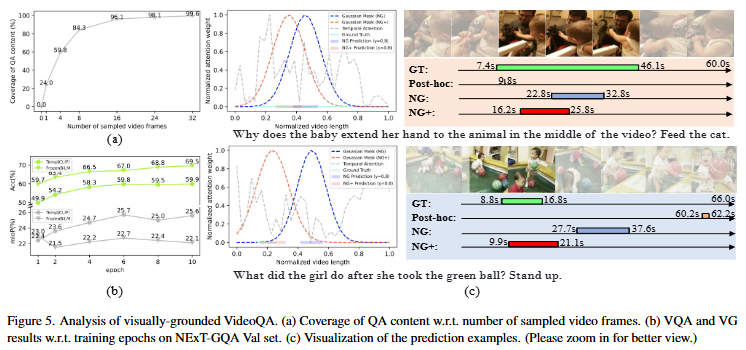
저자는 Figure 5의 결과를 통해 Q3의 결론을 내리고 있습니다. Method에서도 설명한 것과 같이 저자가 제안하는 gaussian masking과 contrastive learning은 실제로 grounding에 도움이 되는 것을 확인할 수 있습니다. Table3에서의 성능 또한 PH보다는 NG, NG보다는 NG+의 성능이 높은 것을 보여주며, 저자가 제안하는 방법론이 효과가 있음을 보여주고 있습니다.
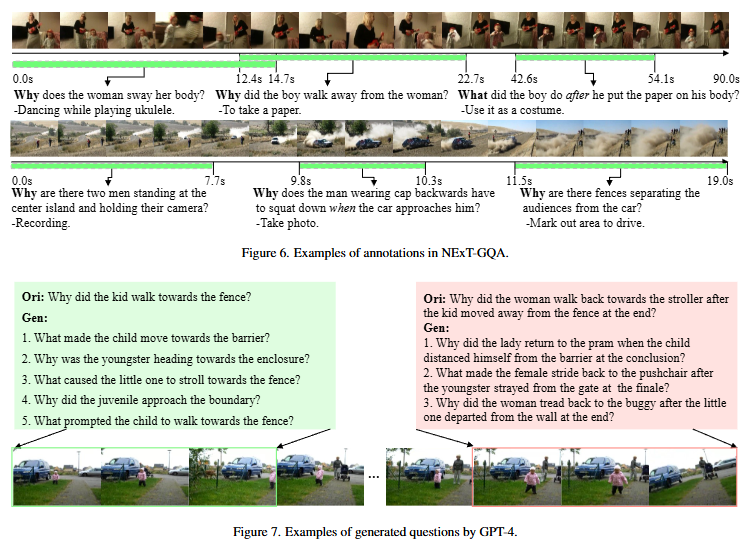
위는 저자가 라벨링한 NExT-GQA 데이터셋의 실제 예시와 GPT4를 통한 positive 질문들을 rephrasing을 통해 생성한 예시입니다.
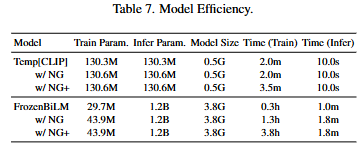
Table7은 베이스라인 모델들의 비교로 stacked-style과 dual-style의 모델 efficiency 비교 입니다. 마지막으로 정성적 결과와 함께 리뷰 마치겠습니다.
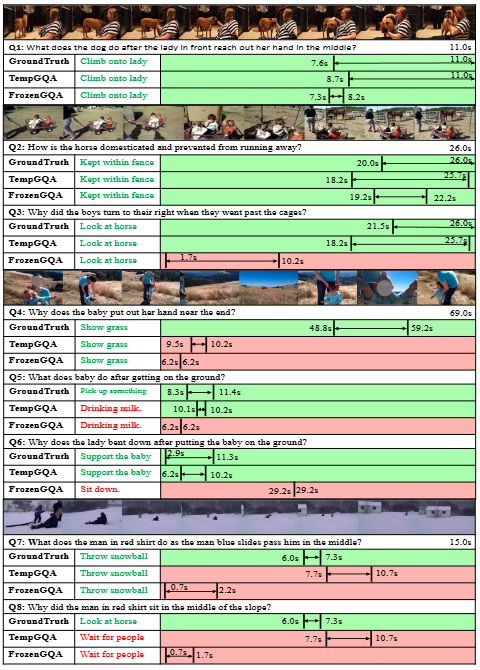
감사합니다.
안녕하세요 중요한 논문을 소개해주셔서 감사합니다.
세미나때 자세하게 설명해주셔서 기억에 남는데요, 리뷰를 보니 또 질문이 생겨서 댓글을 남깁니다.
먼저 제가 놓친것인지 궁금한데 질문 집합의 생성 방법이 무엇인가요?
만약 작업자의 수동 생성이라면 video grounding labeling처럼 데이터 가공비용이 발생하는데 영역에 대한 직접 라벨링보다 비용이 작기때문에 해당 질문 집합 생성으로 대체한 것인지 궁금합니다.
둘째로는 결국 NG 생성에 있어 모델의 성능에 의존하게 되는데, 이에 대한 초기 학습 불안정성, sparse 데이터셋 학습의 어려움과 같은 예상되는 문제에 대한 언급이 있었는지 궁금하네요.
감사합니다.
안녕하세요 황유진 연구원님 좋은 댓글 감사합니다.
질문 집합의 생성은 거대 언어 모델인 GPT4를 사용하여 생성합니다. 이는 grounding 학습을 수행할 때, contrastive learning을 효과적으로 하기 위함입니다. positive sample의 가지수를 늘려 모델로 하여금 더 일반적인 성능을 기대할 수 있습니다. 라벨링은 평가를 위한 validation set과 test set에서만 존재하여 학습할 때에는 사용되지 않습니다. 라벨링 비용도 물론 고려사항이었겠지만, 주 목적은 GPT4를 사용한 data augmentation으로 인해 contrastive learning을 효과적으로 학습이라고 생각해주시면 될 것 같습니다.
NG 방법론의 경우, 초기 학습 불안정성, sparse 데이터셋 학습의 어려움 같은 문제가 저도 존재했을 것이라 생각됩니다. 논문에서는 따로 이 문제에 대해서 언급하고 있지 않지만, 저의 생각으로 답변드리자면, 기본적으로 QA모델을 베이스라인으로 학습하였기에, 완전 랜덤으로 시작하는 것은 아니라서 어느정도는 학습이 안정적으로 되었을 것 같다는 생각이 들고, sparse 데이터셋 학습은 앞에서 언급했던, GPT4를 통한 contrastive learning으로 어느정도 보완할 수 있었을 것이라 생각됩니다.
감사합니다.
안녕하세요. 제가 Video Question Answering task에 대해서 잘 몰라서 간단한 질문을 좀 드리려고 합니다.
task 설명 내용을 보니 모델이 답변을 할 때 객관식으로 5가지 answer 중 하나를 고르는 것으로 이해를 했는데, 그럼 이러한 객관식 기반의 방법에서는 입력으로 Question에 해당하는 text 뿐만 아니라 Answer에 해당하는 text도 함께 모델의 입력으로 사용되는건가요?
마지막 질문으로 기존의 VideoQA Sota 방법론이 정확도는 69%이지만 Grounding 성능은 16%밖에 안된다면서 단순히 정답률만으로는 시각적 정당성을 평가할 수 없다고 저자가 주장한다고 했었는데 저는 여기서 궁금한게 그럼 grounding을 제대로 하지 못했는데 어떻게 기존 SOTA는 70% 가까이의 성능을 달성했는지가 궁금하네요. 이에 대해서 저자가 덧붙이는 말이 없나요? 없다면 성준님이 생각하시기에는 왜 기존 연구들이 낮은 grounding 성능에 비해 높은 Answering 성능에 도달할 수 있었던 것일까요?
감사합니다.
안녕하세요. 신정민 연구원님 좋은 댓글 감사합니다.
일반적으로 VideoQA에서는 언급해주신 것처럼 5개의 답변 후보군 중에 하나를 선택하는 방식으로 수행됩니다. 따라서, Answer에 해당하는 text도 함께 모델에 입력됩니다.
저자가 논문에서 언급한 내용으로는 기존 연구들이 grounding 능력이 부족하다는 언급이 전부입니다만, 어떻게보면 당연한게 기존에는 grounding을 학습하지 않았기에 성능이 낮을 수 밖에 없다고 생각합니다. grounding 능력이 부족함에도 기존 SOTA가 높은 성능을 달성한 것은 물론 저저가 언급한 시각 정보, 언어 정보 혹은 데이터셋에 편향되었기 때문도 있을 것 같습니다. 또 한가지 이유로는 답변의 근거가 되는 구간이 단순히 유사도가 높은 한 프레임을 중심으로 선정하는 방법으로는 정확하지 않을 수 있다는 점인 것 같습니다. 제 생각으로는 답변의 근거가 아니더라도 유사한 프레임이 있을 수 있지만, 근거가 되는 구간은 그 구간 내에서 고르게 유사도가 높은 구간이어야하기 때문입니다.
감사합니다.
세미나 때 발표해주신 덕에 쉽게 읽게 이해할 수 있었습니다.
리뷰 읽다가 궁금한 점이 생겼는데.. 지금은 시각적 근거가 단일피크만 존재한다고 가정하고 문제를 푸는 것 같습니다. 그런데, 시각적 근거가 2개 이상인 경우에는 어떻게 해결하지? 라는 의문이 생겨서 그런데… Naive Gaussian에서 단일 피크를 가정하여 정규분포 근사 방식이, multi-modal grounding 에는 한계가 있지 않을지 궁금합니다.
안녕하세요, 홍주영 연구원님 좋은 댓글 감사합니다.
저도 주영님의 같은 의문을 가지고 있습니다. 실제로 본 논문은 유사도가 가장 높은 단일 피크 지점을 중심으로 가우시간 연산을 수행하지만, 단일 피크 지점이 무조건 정답의 근거가 된다는 것은 저자의 전제일뿐 증명되지 않았다고 생각합니다. 주영님의 지적처럼 시각적 근거가 한군데 이상일 수도 있고, 유사도가 높은 단일 프레임이 정답의 근거가 되기보다는 질문과 고르게 유사도가 높은 구간이 질문의 근거가 될 가능성이 더 높다는 것이 제 생각이기 때문입니다. 저자는 본 연구가 weakly-supervised 연구이기 때문에 어느정도의 한계를 인정하고 차선책을 사용한 것 같지만, 더 나은 방법이 있을 것이라 생각합니다. 이 부분은 직접 실험을 통해 확인해봐야할 것 같습니다. 좋은 인사이트를 나눠주셔서 감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
grounding 모듈은 어떻게 연산 되는지 궁금한데, 단순히 프레임과 질문과의 유사도를 계산해 가장 유사도가 높은 구간을 선택하는 것인가요?
그리고 왜 Gaussian Mask를 도입했는지도 궁금합니다. 구간을 선택할때 굳이 Gaussian Mask를 도입한 이유가 있을까요?
감사합니다.
안녕하세요, 정의철 연구원님 좋은 댓글 감사합니다.
의철님이 말씀해주신 것처럼 질문과의 유사도를 계산하여 가장 유사도가 높은 구간을 선택하는 방법을 사용하고 있습니다. Gaussian Mask를 도입한 이유는 유사도가 가장 높은 한 프레임은 한 순간일 뿐 근거의 구간이 될 수 없기 때문입니다. 저자는 유사도가 가장 높은 지점이 정답의 근거가 된다는 것을 전제로 유사도가 가장 높은 지점을 중심으로 Gaussian Mask를 통해 구간의 timestamp를 예측할 수 있도록 학습했습니다. 이 방법은 weakly-supervised grounding에서 사용되는 방법으로 GT 구간이 없는 경우에 사용되는 방법 중에 하나입니다. 저자는 weakly-supervised grounding 연구에서 영감을 받아 VQG에 해당 방법을 활용했습니다.
감사합니다.