오늘 소개드릴 논문은 RAG에 관련된 논문입니다. 앞서서 비디오 요약(Video Summerization)에 관련된 연구를 몇가지 소개드렸는데요, 이러한 비디오에서 비디오로의 요약은 어떻게 사용될 수 있을까요?
본 논문을 통해 비디오 요약과 같은 테스크가 어떠한 프레임워크에 활용될 수 있는지 이해할 수 있을것입니다.
그럼 리뷰를 시작해보겠습니다.
🐈연구 소개
해당 논문은 카이스트와 DeepAuto라는 한국계 스타트업이 출판한 연구결과입니다. VideoRAG라는 직관적인 제목이 의미하듯이 해당 논문은 RAG 연구를 Video 데이터 도메인으로 확장한 것이 주된 내용입니다. 이러한 확장이 중요했던 이유는 기존의 RAG 프레임워크의 한계 때문입니다. 이를 이해하려면 RAG가 무엇인지 먼저 알아야겠죠?
RAG란 무엇인가? (click the title to check the information of RAG!)
RAG(Retrieval-Augmented Generation)는 대규모 언어 모델을 통해 응답을 생성하기 전에 외부의 데이터를 통해 신뢰할 수 있는 지식 베이스를 참조하여 출력의 정확도를 개선하는 기술입니다. GPT에게 “위키피디아를 기반으로 명탐정 코난의 인물을 설명해줘” 라고 레퍼런스를 명확하게 작성하면 출력의 정확도가 높아진다는 정보가 유행했었는데요, 웹상의 데이터 중에서 비교적 정리가 되고 신뢰도가 있는 위키피디아를 답변 생성에 활용하기 때문입니다. 이러한 활용 예시가 RAG의 시초라고 할 수 있겠네요.
RAG는 검색과 생성이라는 두가지 구성요소로 이루어집니다. 먼저 검색 단계에서는 주어진 질의 q에 대하여 외부지식 집합 C에서 관련 지식 집합 K를 찾아냅니다. K = Retriever(q, C) 라고 작성할 수 있겠네요. 다음으로 생성 단계에서는 검색된 지식인 K와 쿼리 q를 기반으로 답변 y 를 생성합니다. 이를 수식화하면 y = Model(q, K) 입니다. 여기서 모델은 일반적으로 대규모 언어모델과 같은 파운데이션 모델입니다. 검색된 비디오 K가 파운데이션 모델의 입력으로 하기에는 정보량이 너무 많아서 기존에는 검색대상으로서 비디오가 RAG에 직접 활용되지 않았던 것이지요.
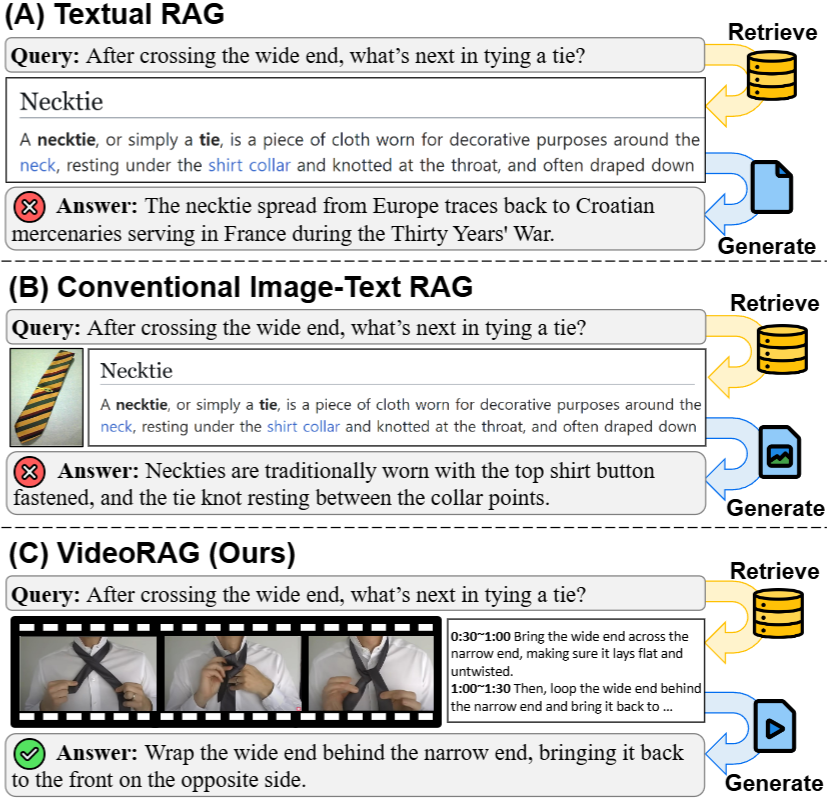
RAG에 대한 정보를 모르시는 분은 위의 토글의 안내를 확인하셨을 것이라 믿으며 간단하게 정리하면 RAG는 출력 생성을 위한 레퍼런스를 찾아 근거 데이터를 증강하는 방법입니다. 허나, 기존 RAG 프레임워크는 Figure1의 (A), (B)와 같이 텍스트나 정적인 이미지만이 레퍼런스로 사용됐었습니다.
기존에 비디오를 직접적인 레퍼런스로 활용하지 못했던 까닭은 비디오 데이터가 중복되는 내용이 많고 길기 때문에 답변 생성을 위한 입력토큰으로 가공하기 어렵고, 본질적으로 멀티모달 데이터이기 때문에 텍스트와 비전의 특징값(feature)가 적절하게 융합되어 활용되어야 하나, 비디오 데이터셋이 가공한 텍스트 정보까지 함께 제공하는것이 드물었기 때문입니다.
본 논문은 frame selection과 automatic speech recognition 기술을 통해 이를 해결했는데요, frame selection으로 비디오의 크기를 줄여 입력 토큰으로 활용될 수 있게하며, automatic speech recognition 를 통해 자동 자막을 생성하여, 가공하지 않은 비디오에서도 텍스트 정보를 활용할 수 있게 설계했습니다. 지금까지 해당 연구의 컨셉과 제시한 문제, 이에대한 접근법을 알아보았습니다. 뒤이어서는 자세한 VideoRAG 설계 방법을 말씀드리겠습니다.
🐈설계 방안
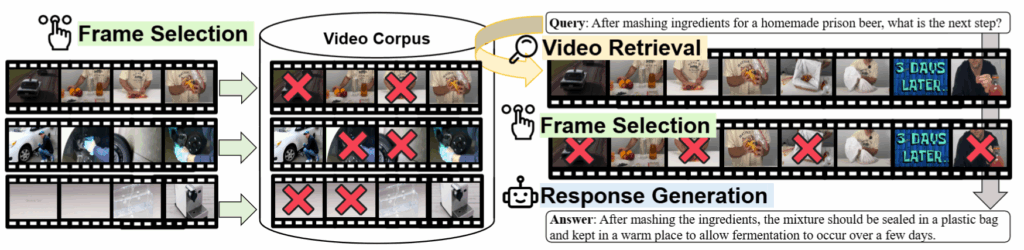
지금부터 논문에서 제시한 비디오를 위한 RAG 구조를 소개하겠습니다. RAG는 크게 검색과 생성 단계로 나뉘기에 이에 맞추어 소개해보겠습니다.
• 검색 단계
검색은 전체 데이터베이스(C)에서 텍스트 쿼리(q)와 관련된 비디오 집합(V)을 찾아내는 과정에 해당합니다. 해당 과정은 텍스트와 이미지 입력을 공통된 임베딩 공간에 임베딩하는 LVLM을 활용합니다. 해당 모델을 통해 데이터들을 공통 공간으로 임베딩 하고 쿼리에 대해 가까운 비디오 임베딩을 topk 방식으로 선출하여 집합 V를 구축하게 됩니다.
즉 해당 단계에서는 q와 유사한 비디오를 기반으로 최적의 subset을 찾는것을 목적으로 합니다. 최적의 subset은 생성에 활용되는데 문제는 비디오 데이터의 속성에 의해 데이터의 압축이 필요하다는 점입니다. 본 논문은 frame selection으로 데이터의 효율성을 높였습니다. 최적의 subset 선출을 위한 수식은 아래와 같습니다. Comb(-)의 경우 랜덤 샘플링을 의미하며, f(-)의 경우 scoreing fuction으로 유사도 함수로 학습가능한 MLP로 구현하게 됩니다. 유연한 scoreing fuction으로 adaptive sampling을 구현한 것이지요.
1. Detail about Comb(-) (click the title to check the information!)
단순 랜덤샘플링을 적용하면 발생가능한 경우의수가 너무 많습니다. 이를 줄이기 위해 먼저 클러스터링을 통한 Frame space reducing을 진행합니다. 사전 정의된 k개를 통해 K-means++ 방식으로 비디오의 프레임을 clustering한 후 클러스터의 센터를 먼저 산출합니다. 이렇게 프레임 갯수를 줄인 이후 랜덤 샘플링을 진행하여 안정성을 높였습니다.
2. Details about f(-) (click the title to check the information!)
f는 데이터셋마다 다르지만 약 3개의 layer로 구성된 MLP입니다. 그렇다면 이는 어떻게 학습할까요? 직접적으로 데이터에 대한 유사도 GT를 구성하기는 어려우니 자동적으로 수집된 레이블을 통해 학습하게 됩니다. 학습 방법은 쿼리와 관련된 비디오를 활용하며, 관련된 비디오에서 랜덤으로 subset들을 추출합니다. 이후 subset 임베딩과 쿼리의 임베딩의 거리를 기반으로 가장 가까운 n가지는 True, 가장 먼 n가지는 False로 라벨링하여 이진 분류로 학습하게 됩니다.
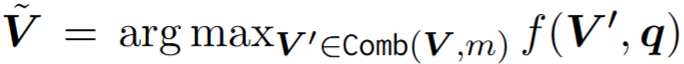
즉, 우선적으로 랜덤 샘플링을 통해 비디오의 중복된 정보를 확률적으로 제거합니다. 이렇게 랜덤 샘플링된 데이터베이스의 비디오들 중에서 LVLM 기반 임베딩하여 쿼리(q)와 가장 유사한 비디오를 통해 최적의 subset을 구성하게 되는 것입니다. 이때 비디오의 임베딩 방법은 아래와 같습니다. LVLM으로 모델링한 비디오와 텍스트 특징량을 선형결합합니다.

• 생성 단계
생성은 간단합니다. 검색 단계에서 선출된 비디오 집합(V)과 쿼리(q)를 잘 배치하여 하나의 토큰을 만든후, 이를 답변 생성을 위한 LVLM의 토큰으로 입력하는 것입니다. 본 논문에서는 아래와 같이 따른 교차방식으로 토큰을 구성하였습니다. 이때 Vi는 하나의 비디오이며, ti는 이에 해당하는 텍스트 특징량입니다.
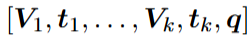
이상으로 VideoRAG의 프레임워크를 알아보았습니다. 제안한 샘플링 기법으로 비디오 도메인 데이터의 큰 용량이라는 한계를 없애고, LVLM을 통한 멀티모달(이미지, 텍스트) 데이터의 임베딩을 하여 기존의 RAG가 비디오 데이터를 답변 생성에 참조하기 위한 데이터로 확장했습니다.
🐈 실험
본 논문은 직관적인 컨셉을 새롭게 도입한 만큼, 실험 파트도 중요합니다. 논문에서는 기존의 RAG 연구에서 활용하는 실험 세팅을 따랐다고 하는데요, 실험 세팅을 이어서 설명하면 다음과 같습니다. 실험은 QA(질의응답) 테스크에 대해 진행되었으며 WikiHowQA라는 WikiHow 페이지를 기반으로 구축된 질의응답 데이터셋과 HowTo100M이라는 유튜브 비디오 기반으로 구축된 비디오-텍스트 검색을 위한 데이터셋을 검색의 데이터베이스로 추가 활용했습니다. QA 데이터와 검색의 리소스가 서로 다른 해당 실험 결과 뿐만 아니라, 더욱 직접적인 성능을 테스트하기 위해 HowTo100M 데이터셋을 기반으로 저자들이 QA 데이터셋을 (자동적으로) 생성하여 video 기반 QA를 수행한 성능또한 리포팅하였습니다.
실험의 비교로 사용된 모델은 RAG 기술을 적용하지 않고 대형 모델을 기반으로 쿼리(q)에 대한 답변을 생성한 1) NAÏVE 방법과 텍스트 데이터셋만으로 데이터베이스를 구축해 생성에 활용하는 2) TextRAG, 텍스트와 정적인 이미지로 데이터베이스를 구축한 3) TextImageRAG 방법을 제안한 4) VideoRAG와 비교했습니다. 이때 생성 단계의 입력으로 vision 도메인 데이터만 활용한 VideoRAG-V와 오디오 정보를 통해 자동 생성한 텍스트 데이터를 융합해 생성의 토큰으로 제공한 VideoRAG-VT를 각각 리포팅하여 비디오의 멀티모달 데이터를 충분히 활용하는 것의 이점을 명확히 보였습니다.
# Main Results:
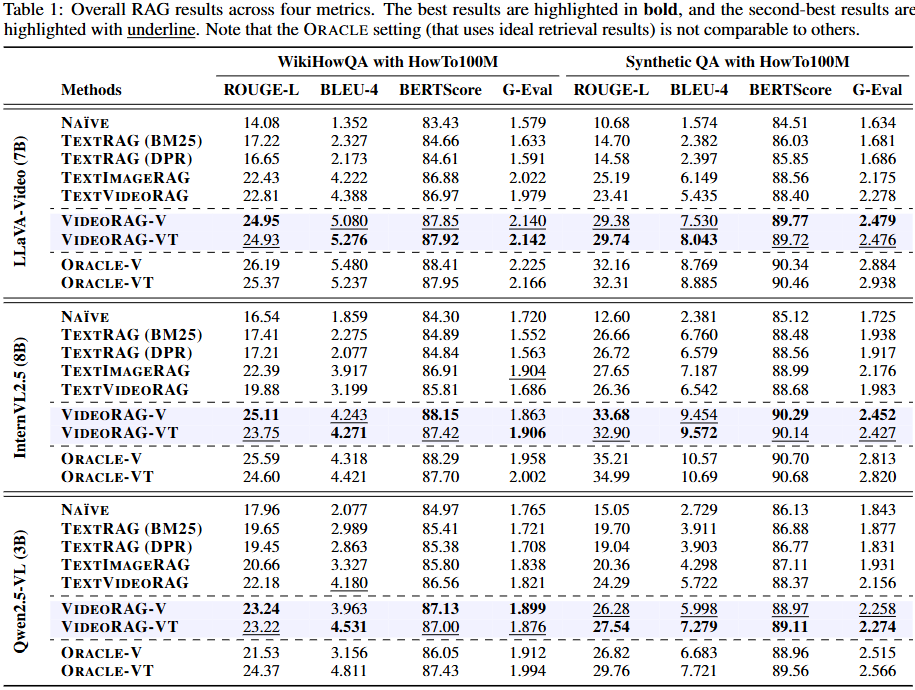 Table1. bold가 가장 높은 성능, underline이 두번째로 높은 성능 (Oracle 결과 제외)
Table1. bold가 가장 높은 성능, underline이 두번째로 높은 성능 (Oracle 결과 제외)
논문에서는 Table1을 통해 나이브 하더라도 비디오를 검색 기반 데이터의 증강으로 활용하는것이 얼마나 중요한지 보였습니다. 실험에서는 Text기반 혹은 Image/Text 기반 방법에 비해 Video를 활용하는 방법이 높은 QA 성능을 달성함을 확인할 수 있습니다. 랜덤 샘플링을 하더라도 텍스트보다는 이미지(+spatial)가, 이미지보다는 비디오(+spatial, +temporal)가 더욱 많은 정보를 갖고있었음을 보이는 증거에 해당합니다. 한편 VideoRAG-V와 VideoRAG-VT의 미미한성능 차이를 통해 답변 생성에 활용되는 대부분의 정보는 시각적 특징내에 포함되어 있었음을 예측할 수 있습니다. 혹은 기존의 QA 데이터셋이 멀티모달 AI를 위한 성능 검증에 적합하지 않게 설계되었을 가능성도 놓치지 않아야 합니다.
한편 데이터베이스에서 가장 이상적인 참조 데이터를 기반으로 응답을 생성한 Oracle 결과가 통상적으로 가장 좋았는데요, 연구에서는 최적의 참조 데이터를 선별하기 위해서는 Text 데이터가 중요함을 아래와 같이 분석해냈습니다.
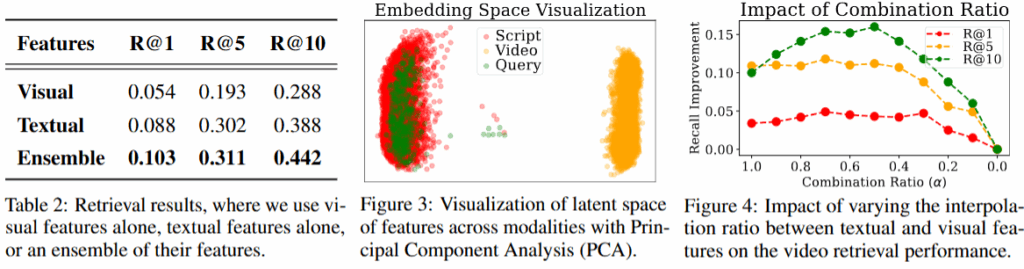
최적의 참조 데이터를 찾기위해서는 쿼리에 대한 비디오 검색의 성능이 좋아야합니다. Table2에서 visual만 사용했을때보다 textual만 사용했을때 성능이 더 높았는데요, 이는 성공적인 비디오 검색을 위해서는 텍스트 정보가 필수적임을 의미합니다. 또한 이러한 현상에 대한 정성적 분석 결과로 Figure3 을 제시했습니다. Figure3에서 보면 임베딩 공간내에서 쿼리(Query)와 텍스트(Script)가 유사한 공간에 임베딩 되어 검색에 용이했음을 알 수 있습니다. 마지막으로, 앞서서 수식2에서 비디오 특징량 설계를 위한 vision 도메인(1-α) 데이터와 text 도메인(α) 데이터의 선형 결합 방법을 밝혔는데, 이 결합 가중치에 따른 검색 성능 결과도 Figure4에 제시했습니다. text의 비율이 클수록 (x축 1.0) 안정적으로 높은 성능임을 보이며 text 정보의 중요성을 확인할 수 있었습니다.
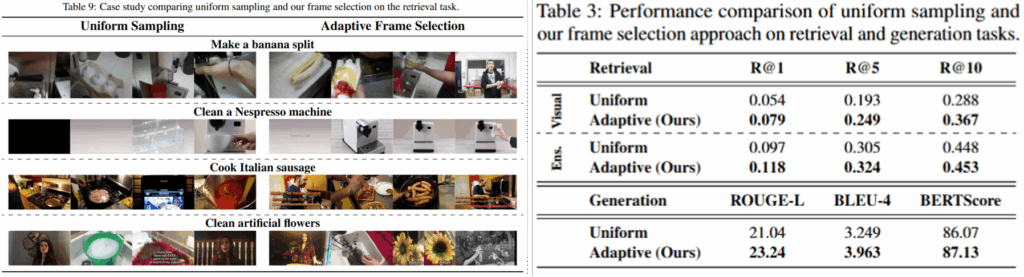
마지막으로 소개드릴 실험은 샘플링 기법에 대한 실험입니다. Table3의 실험 결과 단순히 uniform하게 샘플링하는것에 비해 제안한 방법으로 일부 frame을 선별하는것이 RAG의 메인 테스크인 검색과 생성 모두에서 유의미했음을 확인할 수 있습니다. 해당 결과를 통해 비디오 요약 기술을 적용한다면 RAG를 통핸 QA 성능이 더욱 개선될 수 있음을 기대할 수 있습니다. Table9는 제안한 선별 방법의 정성적 결과로 uniform하게 선별한 결과에 비해 유의미해 보이는 프레임을 선별했음을 확인할 수 있습니다.
앞서서 논문을 소개하기전에 비디오 요약 기술이 앞으로 어디에 활용되는지 해당 논문을 통해 짐작할 수 있다고 언급드렸습니다. 리뷰를 읽으시면서 그 정답을 찾으셨나요?
이상으로 리뷰를 마치겠습니다. 감사합니다.