안녕하세요 이번주는 Scene Completion이라는 task를 수행하는 논문을 가져왔습니다. Scene Completion 태스크는 Scene에 대한 불완전한 정보들을 채워넣어서 최대한 현실에 가까운 복원을 하는 task라고 생각하시면 될 것 같습니다. 결국 모든 unseen 환경에서 강인하게 작동하는 정책이 나오기 전까지는 Real to Sim은 필수라고 생각해서 계속 관심을 가지고 있습니다. 최근 계속 Real to Sim을 어떻게하면 편하게, 자동으로 할 수 있을까를 고민했었는데요, 그동안 3D reconstruction 키워드로만 검색을 해서 그런지, 당연히 필요한 내용들이지만 3D reconstruction을 robotics분야에서 어떻게 학습에 효율적으로 활용하는지에 대한 방법론들만 보고 막상 정말로 원하는 task에 대한 연구를 찾지 못 했는데요, 키워드를 바꾸고 맞는 논문들이 좀 보였습니다. 해당 연구는 파이프라인 전반적으로 모든 핵심 모듈들이 foundation 모델들의 조합으로 이루어져있습니다. 읽으면서 어찌보면 당연한 말이지만 foundation 모델들이 여럿 생겨나면서 여러 연구들이 뚫리는(?)것 같습니다. 리뷰 시작해보겠습니다
Introduction
저자들도 로봇 매니퓰레이션 기술은 이제 공장이나 실험실 같은 통제된 환경을 넘어, 가정이나 병원처럼 훨씬 복잡하고 다양한 오픈월드 환경으로 확장되고 있기 때문에 로봇이 안정적이고 세심한 조작을 수행하기 위해서는 주변 환경을 구성하는 물체들의 존재를 구분하고 각 물체의 형상을 정확히 파악하는 능력이 필수적이라고 주장합니다. 그래야만 로봇은 개별 물체에 대해 안정적인 grasp와 placement를 선택할 수 있고, 주변 물체와의 불필요한 충돌 없이 조작을 수행할 수 있기 때문입니다. 하지만 실제 환경에서는 다양한 제약 때문에 이와 같은 장면 표현은 제한적인 입력으로부터 구성되어야 하기 때문에 단 한 장의 RGB-D 이미지로 접근을 시도했다고 합니다.
저자는 이 문제는 본질적으로 정해가 없는 ill-posed 문제에 속하지만, 최근 VFM들이 발전하면서 이를 해결할 수 있는 가능성이 열리고 있고, 결과적으로 단일 RGB-D 이미지 기반으로, scene의 카테고리 제한 없이 실제 환경에서 관측되는 복잡하고 가려진 장면을 완전하게 복원하는 최초의 시스템이라고 주장합니다. 기존의 연구들은 사전 정의된 물체 카테고리, 노이즈 없는 입력, 또는 간단한 장면 구성을 전제로 했거나, 해상도가 낮고 거친 복원 결과를 생성했지만 SceneComplete는 아무런 제한 없이 완벽한 복원을 했다고 합니다.
Methods
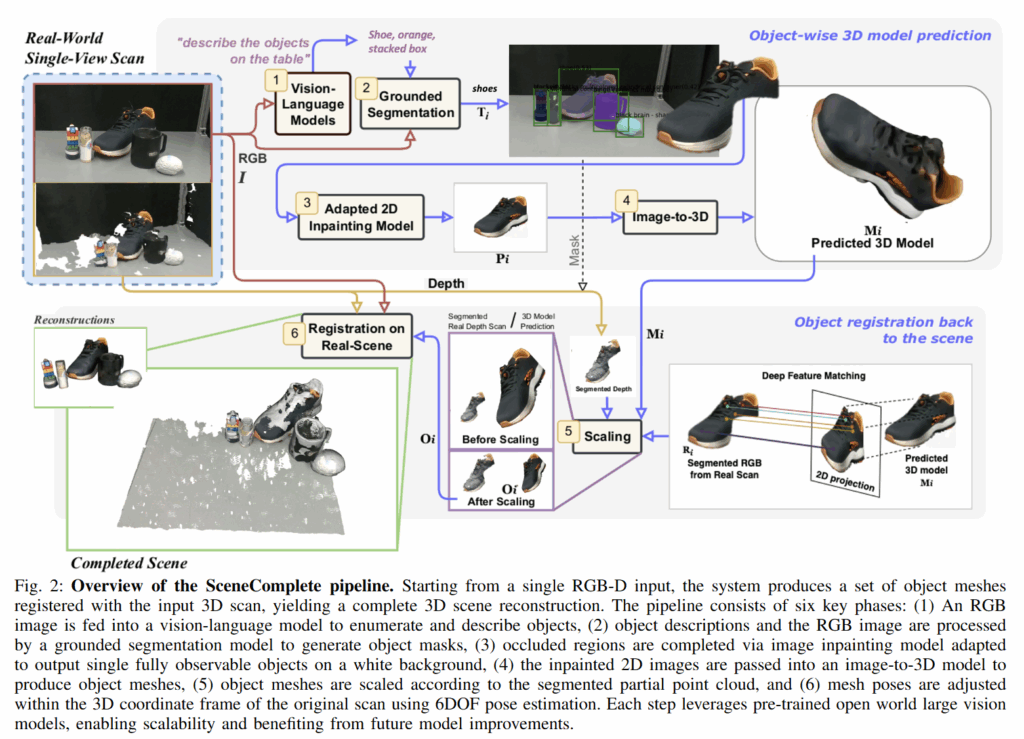
우선 SceneComplete라는 태스크이긴 하지만 결론부터 말하자면 object centric한 (배경없는) scene 복원이 이루어집니다. 단일 RGB-D로부터 VFM을 활용해 scene 내의 물체들의 이름과 색상을 얻어 이 텍스트들을 쿼리로 segmentation mask를 얻습니다. 이후 2D inpainting 모델을 통해 각 객체의 가려진 영역을 보완하여 완전한 2D 이미지를 생성하고, 이 이미지를 image to 3d 모델에 전달하여 정밀한 메쉬를 생성합니다. 마지막으로, 스케일 정합과 6D Pose Estimation을 수행해 생성된 메쉬들을 실제 3D 장면 내에 정확히 정렬해줍니다.
이미지 처리 (Segmentation, Inpainting)

우선 GPT-4o를 통해 “RGB 이미지에 존재하는 물체를 일반적인 이름과 색상으로 나열하라”는 프롬프트를 통해 “bag”, “red cup”과 같은 객체 리스트를 얻고, 각 텍스트에 대해 Grounded-SAM2를 활용해 segmentation mask를 얻습니다. 코드에서는 이 때 만약 겹치는 마스크가 있다면 NMS를 통해 처리해줍니다.
현실의 복잡한 manipulation scene에는 다양한 occlusion이 발생할 수 있으므로, segmentation mask를 inpainting model에 넣어 완전한 2D 이미지를 얻는 과정을 거칩니다. 이때는 BrushNet이라는 모델을 사용한다고 합니다. 하지만 BrushNet은 원래 예술적인 이미지 데이터셋을 기반으로 학습된 모델이기 때문에, 현실적으로 보이지 않는 output이 많았다고 합니다. 이를 해결하기 위해 저자들은 BrushNet을 실제 테이블 위 객체 중심의 도메인에 맞도록 LoRA를 활용해 finetuning 했다고 합니다.
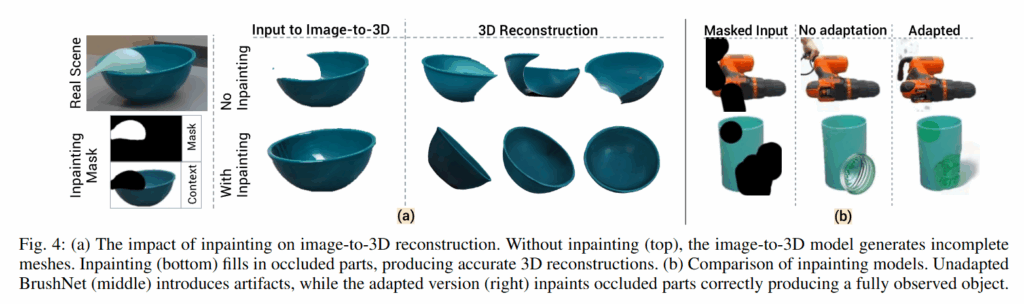
다만 YCB Object를 가지고 finetuning을 했다고 하는데, 예시 scene도 그렇고 코드의 example도 전부 YCB Object로만 구성돼있어 이게 진짜 의미가 있나,, 싶습니다. 전에 리뷰했던 다른 Amodal Completion모델중 다량의 현실 데이터를 구축해 학습한 모델도 존재하는데, 왜 굳이 BrushNet을 finetuning해서 쓴건지 (contribution을 위해서,,,?) 의문이긴 합니다. 결과물은 배경이 흰색인 이미지로 출력되기 때문에 한 번 더 SAM을 통해 객체별 깔끔한 segmentation mask를 얻어줍니다.
3D Mesh 생성 및 정렬
생성된 깔끔한 mask들을 통해서 단일 image를 3d로 만들어주는 모델을 통해 watertight mesh를 뽑습니다. 저자들은 InstantMesh라는 모델을 활용했습니다. 우선 Diffusion을 이용해 NVS를 수행한 후, multiview 이미지를 통한 LRM을 통해 mesh를 생성합니다. 저자들은 다양한 변수가 존재하는 depth나 카메라 정보를 활용하는 방법보다 rgb만을 활용하는 image to 3d 접근이 훨씬 일반화에 유리하다고 주장합니다. 이 과정을 거쳐 [-1, 1] 범위의 정규화된 좌표계에 존재하는 3d mesh 모델을 가지고 scale 정합, 6D Pose Estimation을 수행합니다.
정규화된 좌표계에서 생성된 3D mesh는 스케일 정보가 현실과 맞지 않는데요, 이를 위해 모델로부터 얻은 mesh를 uniform하게 추출한 pointcloud와 metric한 poincloud간의 scale 정합을 진행해줍니다. 먼저 생성된 mesh를 2D로 projection해서 DINO를 활용한 Dense Correspondence Matching을 진행합니다. 이후 descriptor map간의 pixel level로 대응점을 찾아 3D point로 복원합니다. 이후 두 pointcloud의 중심을 맞추고 대응점이 같아지도록 scale 파라미터를 구해줍니다.
Scale이 맞은 Mesh를 얻었다면, Foundationpose 모델을 model-free방법으로 (CAD 생성 과정 없이) 진행해줍니다. 이렇게 물체들 간의 Relative Pose를 얻게 되면 scale정보와 relative pose를 모두 반영해 최종적으로 obj 파일로 output을 얻을 수 있습니다.
실제 적용
해당 프레임워크는 제가 IJCAS에 제출할 논문의 Baseline으로 삼을 논문이어서 저자들이 준비한 예시 자료로 코드를 돌려봤는데요, YCB Object는 3D mesh생성까지는 문제없이 진행이 됐지만 이외의 물체들이 정말 inpainting이 잘 되는지를 확인해봐야 할 것 같습니다. 또 scale과 6D Pose가 정합된 상태로 obj파일을 만들어내서 모든 물체를 원점에 그대로 소환해도 mesh들이 align 되는 구조인데, 물체들간의 relative pose는 맞지만 시뮬레이터에 올렸을 때 scene 자체의 좌표계와 맞지 않는 문제가 있어서 이 부분은 구현을 해야할 것 같습니다.
Experiments
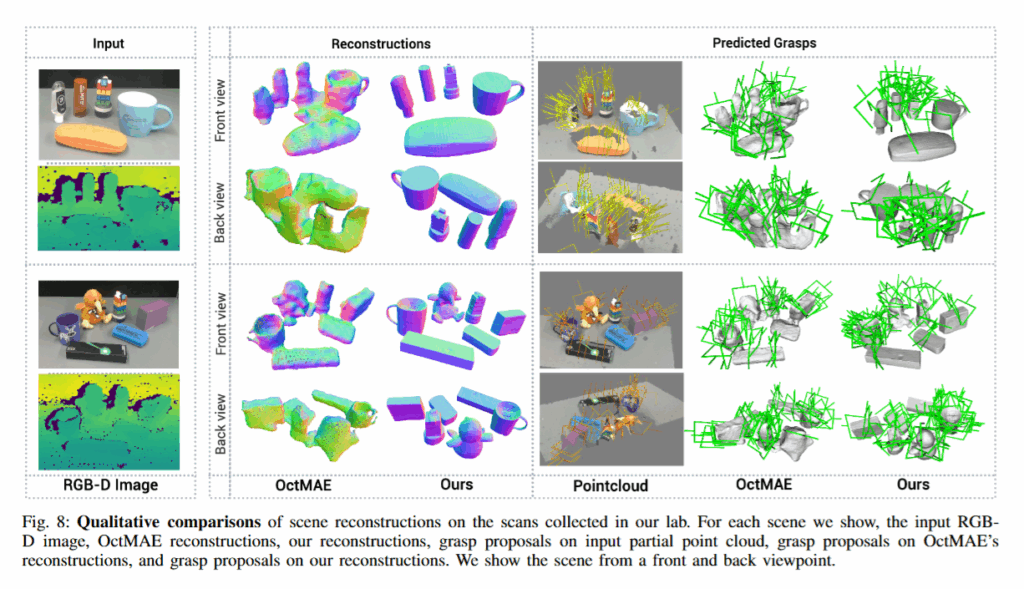
정성적인 결과를 봤을때는 하나의 mesh가 끊이지거나(검은색) 두 개의 mesh가 붙어있는(빨간색) 경우 없이 복원에 성공했다고 합니다. 다만 grasping 관점에서 봤을 때 gt와 모양이 좀 다른 mesh가 많지 않나 생각합니다.
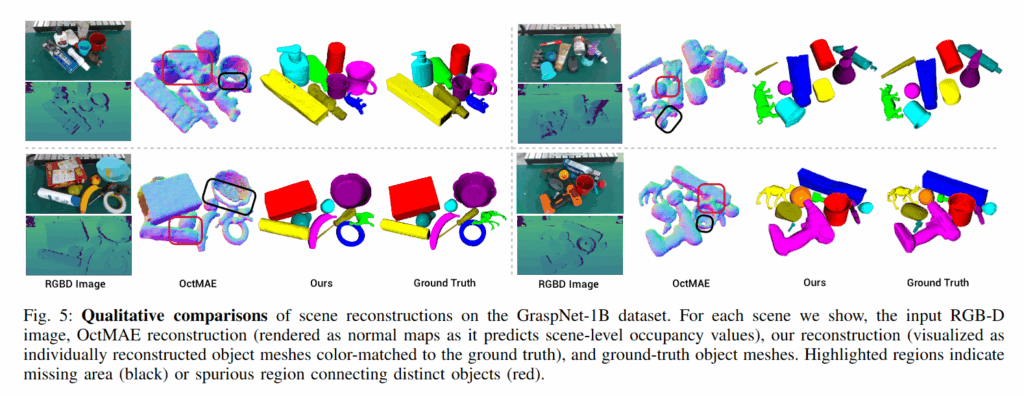
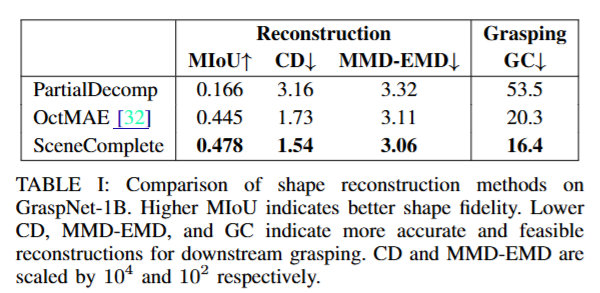
저자들은 성능을 세개의 실험을 통해서 평가했습니다. 먼저 가장 처음으로는 Scene Reconstruction and Grasping 실험을 진행했습니다. GraspNet-1B 데이터셋을 활용해 SceneComplete를 기존의 단일 뷰 기반의 Scene Reconstruction 기법과 비교했습니다. 비교대상은 OctMAE라는 방법론인데, 3D mesh를 복원하는 파이프라인은 저자들이 처음으로 제시했기 때문에 OctMAE의 occupancy map을 기반으로 uniform하게 pointcloud를 생성 후에 메시화해서 진행했다고 합니다. 평가지표로는 MIoU, Chamfer Distance와 MMD-EMD를 사용했습니다. CD의 경우 한 pcd의 모든 점에서 비교대상 pcd와의 최소 거리의 평균입니다. Earth Mover’s Distance – Maximum Mean Discrepancy (MMD-EMD)는 두 pointcloud 간의 분포 차이를 정량화해서, 하나의 분포를 다른 분포로 변환하는 데 필요한 최소 이동 비용을 평균적으로 계산한 값이라고 합니다. GraspingGC같은 경우는 복원한 대상으로 다수의 grasping 후보를 만든 뒤 해당 후보들이 gt에서도 유효한 grasping point가 되는 확률이라고 합니다. 결과는 아래 table1으로 확인 가능합니다. 다른 방법론들과 비교했을 때 전반적으로 우수한 성능을 보입니다.
또한 parallel gripper와 dextrous hand를 통해 조작 가능성은 어느정도인지 평가를 진해했습니다. 시뮬레이터에서 YCB-Video 데이터셋과 GraspNet-1B를 gt삼아 복원한 객체들을 각각 CGNet(parallel), Antipodal Grasping (dextrous hand)를 활용해 평균적인 Grasping 성공률을 기준으로 평가했습니다. 결과는 PartialDecomp 대비 2배 이상 성공률이 상승했습니다.


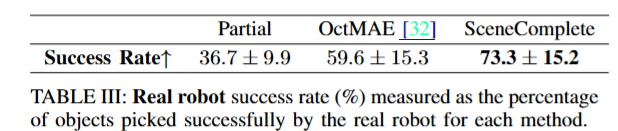
마지막으로는 Real World에서 평가를 진행했습니다. 현실에서 Franka Panda와 Realsense D435 카메라를 이용해 pick and place 실험을 진행했고, 15개의 실제 table top scene에서 scene reconstruction을 진행한 뒤 pick and place 실험을 진행했다고 합니다. 이 때도 기존의 방법론들을 크게 앞서는 성능을 볼 수 있습니다. 평가 지표는 success rate입니다. OctMAE의 경우 YCB와 같은 일상적인 물체에 대해 복원력이 크게 떨어졌다고 합니다.
Conclusion
Open world에서 scale과 6D Pose를 모두 생각해 로봇이 실제로 조작이 가능한 scene을 reconstruction하는 파이프라인을 처음으로 제시한 것은 의미가 있지만, 각종 foundation 모델들을 더불어 많은 모델들을 거치는 구조라 잡다한 오류가 많을 것 같은 아쉬움은 있습니다. 그렇다고 다른 방법을 제시할 수는 없지만 각각 모듈들이 발전함에 따라 더 완성도 있는 파이프라인이 나올 수 있지 않을까 생각합니다. 저자들도 Grounded-SAM 단계에서 생각보다 객체의 part를 segment하는 경우나 인접한 물체도 하나로 segment하는 경우가 종종있고, Image to 3D 모델도 가끔 엉뚱한 형상을 만들어내는 것이 한계라고 합니다. 또 Scale 추정방식이 단순히 평균을 사용해 하나의 파라미터를 기준으로 정합하기 때문에 객체의 모야엥 따라 부정확한 scene register가 생긴다고 합니다.
안녕하세요 영규님 리뷰가 꽤나 간편하게 읽힌 것 같습니다.
질문이 있는데, 이런 scenecomplete 라는 task가 결국에 미래의 강력한 Foundation model 이 나오면 한가지의 FM 모델만으로도 해결이 가능할까요? 혹은 이렇게 가져다 조합해서 사용하면서 보이는 한계점들을 보완하는 방식으로 연구가 진행될지 궁금합니다. 이쪽 분야는 잘 모르지만 뭔가 영규님이 드는 의문점(brushnet사용) 대비 real world에서의 성능이 좋아보이는 것도 신기하네요..
안녕하세요 인택님 리뷰 읽어주셔서 감사합니다
일단 Scene Completion 태스크를 전담하는 하나의 Foundation Model의 등장에 대해 개인적으로는 좀 회의적입니다. input으로부터 output까지의 과정을 생각했을 때 단일 모델로 end-to-end로 처리하기 위해서는 매우 방대한 학습 데이터와 연산 자원이 필요하지 않을까.. 싶습니다.
물론 기술의 발전 속도를 생각하면 가능성을 완전히 배제할 수는 없겠지만 (사실 진짜 나올지 안 나올지 모르겠습니다 ㅋㅋ), 현 시점에서는 완성형 Foundation Model보다는 저자도 이야기했듯 각 단계별 FM 모듈들을 더 우수한 모델로 교체하거나 알고리즘을 개선하는 방향으로 진행되지 않을까 싶습니다.
또 저도 다 자세하게 알지는 못 하지만 BrushNet이 “예술적인”느낌을 주기 위해 학습된 모델인 만큼 위에 figure4의 b를 보시면 뭔가 조금 아쉽지 않나,, 생각이 들긴 합니다. 훨씬 더 좋은 정성적인 결과를 보여준 모델들을 봤던것 같아서 이건 한 번 실험을 해보려고합니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
6D pose 쪽 연구를 살펴보면 계속 등장하는것이 image-to-3D 방향으로 mesh를 만들어서
model free로 해결을 많이하는 연구로 이루어지는데 reconstruction으로 최로로 제안한 논문이라 재밌게 잘 읽었습니다
하나 질문하고 자하는 것으 brushnet 을 사용한다는 점이 다소 낯선데,, 얘네들을 통해서 어떤 거를 뽑아내는지가 궁금합니다 그리고 foundataionpose한테 넘겨줘서 해결하는거같은데 3D mesh 모델을 넘거주는거 맞을까요?
안녕하세요 우진님 댓글 감사합니다
BrushNet같은 경우는 가려진 2D상의 객체를 완성시키는 모델입니다. Fig3을 보시면 카메라의 시점에서 컵이 가려져있는데, 가려진 컵의 segment해서 넣어주면 가려지지 않은 상태의 컵을 inpainting해서 output으로 주는 모듈입니다. 3D Mesh는 완성된 컵 한 장의 이미지를 통해 멀티뷰 이미지를 만들어 낸 후 reconstruction을 진행합니다.
그리고 foundationpose에 넘겨주는 input은 scale이 정합된 상태의 3D mesh입니다.
논문 잘읽었습니다.
간단한 질문 남기고 가겠습니다.
Q1. Deep feature matching을 수행하여 scale을 찾아 낼 때, Mesh를 어떻게 각도에서 2D로 사영시킨 값을 활용해야 효율적일까요?
Q2. Tab 1의 메트릭들이 생소하고 고민이 많은 것 같습니다. 저희가 작성할 논문도 해당 메트릭을 활용하여 평가를 진행하도 문제가 없을까요? 저희가 주장하고자 하는 가설을 입증하는 데에 적절한 메트릭일까요?
안녕하세요 태주님 댓글 감사합니다
A1. 어떤 기준으로 정해진건진 모르겠지만 공식적으로 구현된 코드상에서는 정면에서 z축으로만 30도 올라가있는 하드코딩된 camera pose에서 한 장만 가지고 찾아내는데, 여러장을 sampling해서 고르면 좀 더 강인한 파이프라인이 되지 않을까 생각합니다.
A2. 저도 메트릭에 대한 생각을 하면서 읽었었는데, Tab 1의 3D mesh 관련 지표들이 geometric한 부분을 평가하는 만큼 image to 3D모델의 기하구조 표현이 좋아지면 유의미한 변화가 있지 않을까 생각합니다.