이번 리뷰 논문은 최신 VLA 논문입니다. 현재 VLA 방법론들의 평가 방법이 난잡한 상황에서 많은 기법들이 CALVIN과 LIBERO 벤치마크를 이용해서 평가를 하는 흐름으로 보입니다. 해당 기법은 두 벤치마크에서 현재 SOTA를 달성한 방법론으로 물리적인 정보를 VLA에 직접 주입하기 위해서 Dynamic, Semantic, Depth 정보를 VLA 기법 중 하나인 image-based forecasting 방법을 이용한 첫 방법론입니다.
Intro
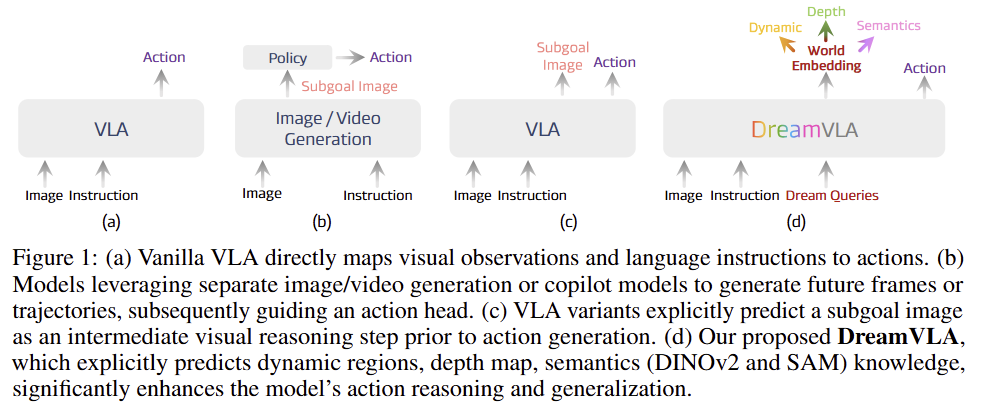
최근 VLA이 로봇 분야에서 놀라운 결과물을 보여주고 있습니다. 이러한 영향 이면에는 Multi-modal LLM과 Generation model들이 뒷받침이 되어주고 있죠. fig 1을 보면 저자가 VLA 분야를 크게 구분한 예시로 (a)와 같이 직접 raw action을 예측하는 형태, (b)와 같이 앞선 미래를 예측한 영상을 토대로 policy를 생성하는 (b), VLA 모델이 예측 뿐만이 아니라 raw action도 같이 예측하는 형태 (c)도 등장하기 시작했습니다. 특히 (b)나 (c)와 같이 영상으로 시각적 예측 (dense visual forecasting) 방식을 활용하는 경우, 실제 세계의 물리적인 이해를 영상 형태 뿐만이 아니라 로봇이 state로 예측이 가능해지기 때문에 Seer와 같이 높은 성능을 보여주었습니다.
허나, 실제 물리 세계는 더 복잡한 정보로 구성되어 있기 때문에 의미 dense visual forecasting만으로는 근본적인 한계가 존재합니다. (1) Redundant pixel information: 연속적인 장면을 예측하는 로봇 태스크에서는 두 subgoal 사이에서 변화되는 정보가 적을 가능성이 높습니다. (2) Lack of spatial information: 2D 영상에서만의 예측을 수행하기 때문에 3차원 정보에 대한 이해가 부족합니다. (3) Lack of high-level knowledge forecasting: 의미론적인 정보에 대한 예측을 수행하는데에 큰 한계를 가집니다. 저자는 이러한 한계로 인해 기존의 Fig 1-(a~c) 방법론들이 world-level future knowledge 측면에서 prediction-action loop가 부족하다고 주장합니다.
이러한 한계를 극복하기 위해 저자는 DreamVLA를 제안합니다. 해당 기법은 아주 간단합니다. future frame을 예측하는 대신에 figure 1-(d)와 같이 로봇 조작과 밀집하게 관련된 world embedding~dynamic area, depth, high-level semantic feature~를 예측합니다. 해당 접근은 사람이 행동 하기 전에 world로부터 간략한 정보를 취득하는 방법과 유사하다고 보면 됩니다.
저자는 해당 방법을 통해서 VLA 분야에서 벤치마크로 많이 애용되고 있는 CALVIN에서 sota를 달성한 결과를 보여줍니다.
Method
Problem Definition and Notation
저자는 로봇의 조작을 풍부한 세계 지식~foundation model을 배워 활용하는 것을 목적으로 합니다. 이러한 맥락에서 저자는 vision–language–action reasoning을 inverse dynamics problem로 해석하여 정립합니다.
로봇 실행을 개선하기 위해 풍부한 세계 지식을 지침 원칙으로 활용하는 것을 목표로 합니다. 이러한 맥락에서, 우리는 vision-language-action 추론을 역동역학 문제(inverse dynamics problem)로 공식화합니다. 이는 future world knowledge prediction을 로봇 제어를 위한 내적 추론 정보로 가정하여 명시적인 예측과 실행이 가능하도록 합니다.
각 time step t에는 로봇은 3가지 heterogeneous signal: a natural language instruction l , a raw visual frame o_t , proprioceptive state s_t 을 전달 받습니다. 또한 transformer 구조의 모델이 미래 정보를 예측하기 위해서 특수한 spatial token인 <dream> query ~ DreamLLM을 활용하며, 모든 입력은 결합되어 입력으로 활용됩니다. 아래의 수식과 같이 결합된 model M 는 간소화된 잠재 표현인 world embedding w를 예측합니다.
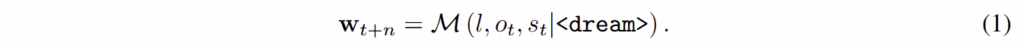
그 다음, world embedding으로 motion cue, spatial details, high-level semantics를 예측합니다. 이는 아래와 같이 predictor P 를 통해 n steps에 따라 추론됩니다.
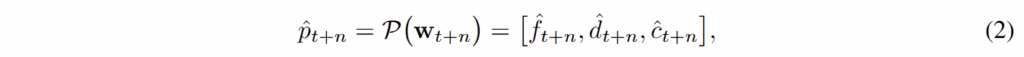
여기서 f는 dynamic regions, d는 monocular depth, c는 high-level semantic feature (e.g. DINOv2, SAM)을 encode한 정보라고 보시면 됩니다.
다음과 같이 world embedding w_{t+n} 이 주어졌을 때, 통합 모델 M에 의해 <action> query는 latent action embedding에 할당되어 연관된 액션 정보를 통합합니다. Denoising-diffusion Transformer D는 latent feature에 기반하여 n-step action을 수행합니다. 이는 아래와 같이 표현됩니다.
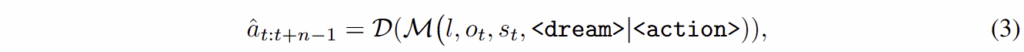
Model Architecture
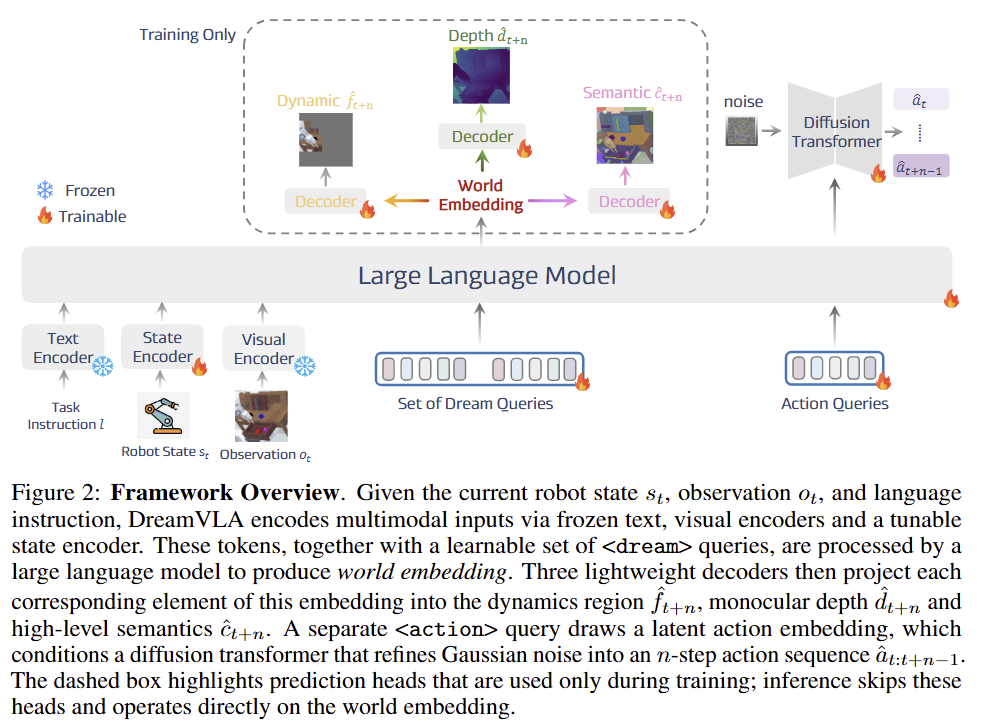
전반적인 DreamVLA의 모델 구조는 figure 2에서 확인 가능합니다. Transforemr 구조를 가진 해당 모델은 크게 3가지 모듈로 구성되어집니다. 먼저, heterogeneous inputs은 각자 개별적인 서로에 맞는 모달에 따른 encoder를 통해 임베딩됩니다. 언어는 CLIP으로, 시각 정보는 MAE로 patch화 되어 입력되고, proprioceptive states는 FC layer를 통해 임베딩 됩니다. 인코딩 이후에 학습 가능한 쿼리셋 <dream>과 <action>이 인코딩된 정보에 결합되어 입력됩니다.
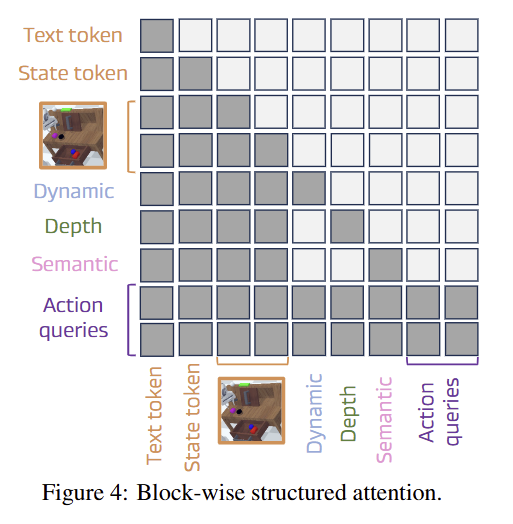
그 다음, GPT-2를 기반으로하 fig 4로 structured causal and non-causal attention mechanism를 수행합니다. 해당 과정을 통해 low-level perceptual signal을 의미론적인 응집된 world state로 추론되어집니다.
마지막으로, 간단한 convolutional layer로 구성된 light-weight output heads를 통해 world embedding을 명시적인 예측으로 decoding 합니다. 명시적 예측 정보로 dynamic region, monocular depth, semantic feature를 재구성합니다. 추론 단계에서는 해당 명시적인 예측을 수행하는 디코더를 생략하여 연산량을 절약합니다. 이는, world embedding 자체가 동적 변화, 깊이, 의미론적 특징을 캡슐화한 상태에서 추론되기 때문에 잠재적으로 정보를 가진 상태에서 추론이 됩니다. 해당 정보와 병행하여 latent action embedding을 Denoising Diffusion Transformer를 사용하여 raw action을 추론합니다.
Comprehensive World Knowledge Prediction
해당 섹션에서는 world knowledge를 명시적으로 예측하기 위한 자세한 방법을 설명 합니다. 여기에는 (i) motion–centric dynamic region, (ii) 3D depth geometry, (iii) high-level semantics가 포함됩니다. 이러한 보완적인 신호는 raw pixel에 대한 compact하고 구조화된 대안을 제공하고, inverse dynamics planning을 위한 look-ahead context를 정책에 제공할 수 있도록 합니다.
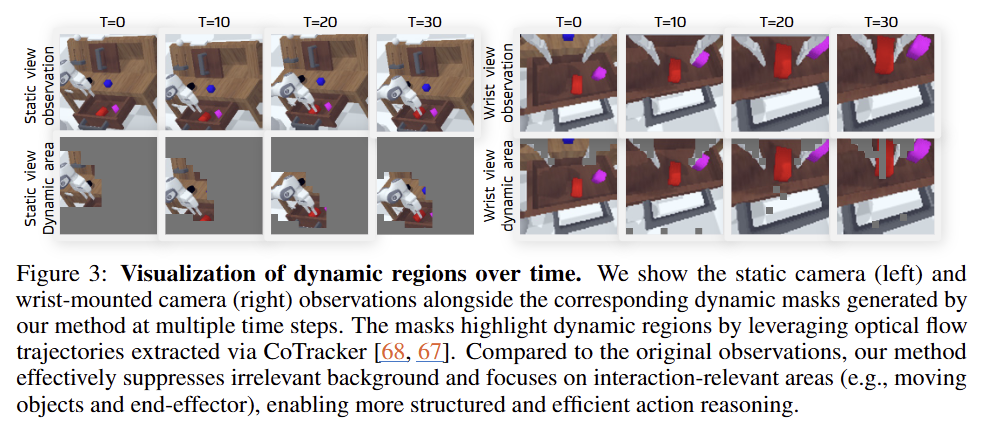
Motion-centric dynamic-region reconstruction. 로봇이 세계를 이해하기 위해서 dynamic regions을 예측하는 것은 관측 장면의 어떤 부분이 움직이는 것이 자연스러운지를 이해시켜주는 좋은 도구라고 볼 수 있습니다. 이 때, 언어 명령과 관측 장면과 로봇의 현 상태는 실질적인 행동과 관측에 해당되는 영역을 이해하는데에 큰 도움을 줄 수 있습니다. fig 3에서 볼 수 있는 바와 같이 DreamVLA는 밀집된 optical flow를 예측하거나 전체 future frame을 생성하지 않습니다. 대신, CoTracker를 적용하여 동적 영역, 즉 로봇의 end-effector 또는 다른 움직일 수 있는 물체와 함께 움직이는 픽셀을 추출하여 해당 정보를 DreamVLA가 훈력하여 해당 영역만 재구성 가능하도록 학습합니다. 해당 정보를 loss로 표현하면 아래와 같습니다.
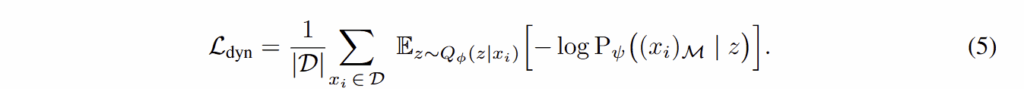
여기서 x는 원본 영상, z는 masked image, Q()는 CoTrackerf에 해당 합니다.
Depth prediction. 깊이 정보는 로봇이 목표로 도달하기 위해, 장애물을 회피하기 위해 어디로 나아가야 하는지에 대한 world 지식을 부여합니다. 만약에 depth sensor를 사용할 수 있다면, 이를 ground-truth로 DreamVLA를 지도 학습을 수행합니다. 만약에 없다면 Depth-Anything으로부터 추론된 정보를 self-supervised teacher로 활용합니다. loss는 scale-normalized mean-squared error를 활용하며, 이는 아래와 같습니다.
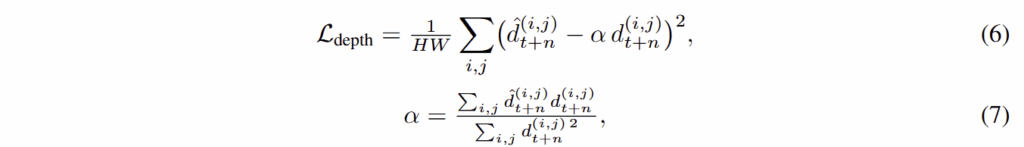
여기서 alpha는 scale 모호성을 해소하기 위한 항에 해당합니다. 수식 (7)은 깊이 정보들의 순서들을 유지하는 역할이 크며, 정확한 depth를 유지하는 것이 아니라 로봇 액션이 월드 지식을 이해하기 위함을 상기해야합니다.
Contrastive semantic forecasting. 미래 시점의 semantic feature를 예측하는 것은 로봇 작업에 있어 중요한 객체 또는 영역을 이해 시키고 목표 선택 및 파지 영역을 제시하는 중요한 정보(e.g. object identity and
affordances)를 제공할 수 있습니다. 저자는 해당 정보를 미래 시점의 영상으로부터 DINOv2 혹은 SAM을 수행하여 이를 InfoNCE loss를 사용하여 학습을 수행합니다. 이는 다음과 같습니다.
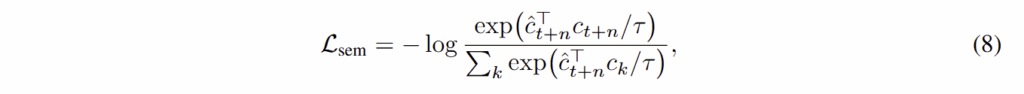
여기서 k는 예측해야 하는 tokens의 수, τ는 temperature에 해당합니다.
Inverse Dynamics via Denoising Diffusion Transformer. 마지막으로 DiT를 활용하여 raw action을 추론합니다. 아래는 DiT를 활용한 loss에 대한 수식입니다.
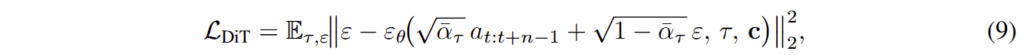
위 수식은 DiT를 따르는 구조이며, c는 world embedding라고 보시면 됩니다. (정확하게는 LLM에서 얻은 latent feature라고 하는데… world embedding을 설명한 것 같습니다.)
Experiment
GPU는 8 A100 80GB를 활용
CALVIN
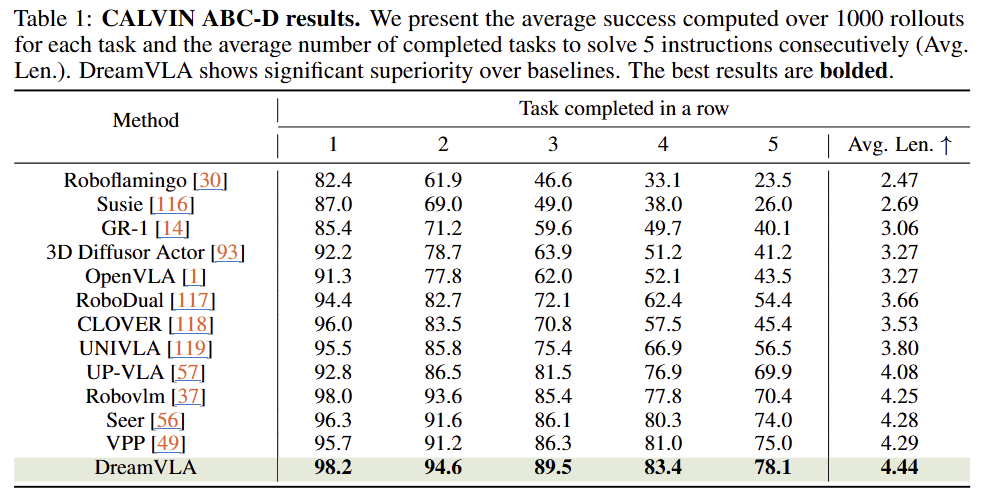
CALVON에서 SOTA를 달성함
RealWorld
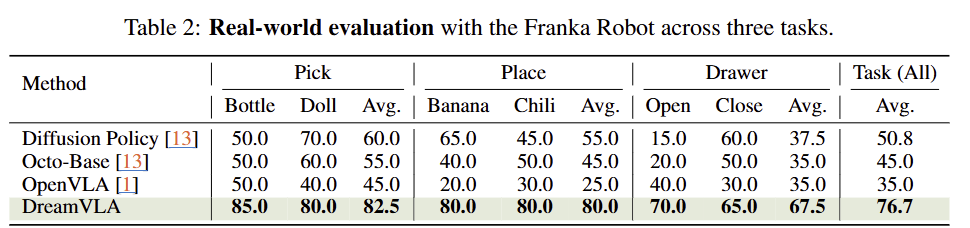
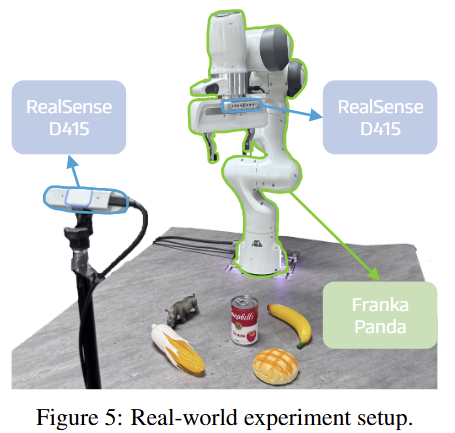
실제 세계에서도 이전 기법보다 높은 성능을 보여줌. DROID로 사전 학습하고 각 태스크 별로 100 demonstration을 만들어서 추가 학습 후에, 20번의 시도에 따른 SR에 대한 성능 Tab2를 볼 수 있음
Ablation Study
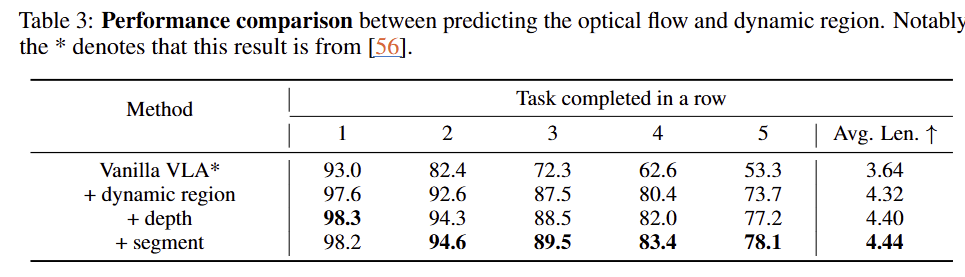
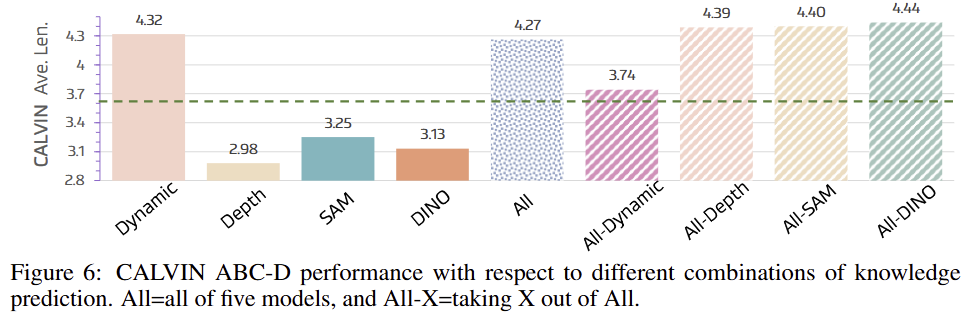
Q1: What is the contribution of each modal characteristic? fig 6을 통해서 어떤 foundation과 deocoder와 teacher 모델 조합이 좋은 성능을 보여주고 있습니다. tab 3에서는 어떤 지식을 부여했을 때 성능 보여주고 있습니다.
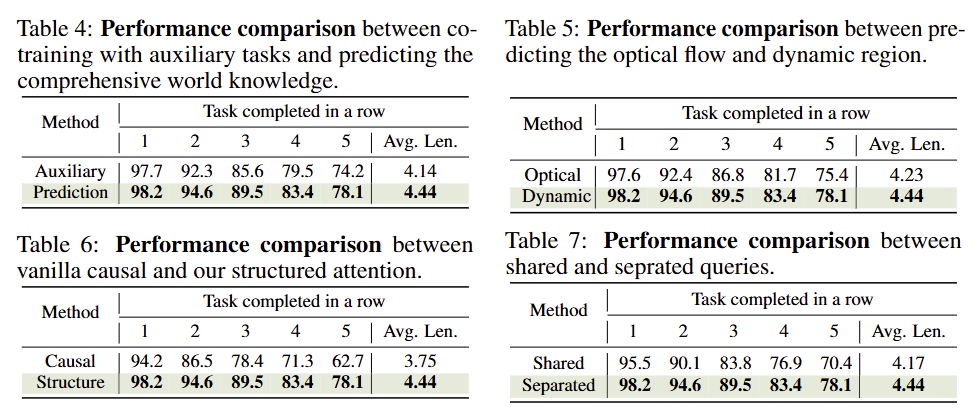
Q2: Auxiliary Tasks vs. Future Knowledge Prediction: which drives improvement? Tab 4에서 보이는 바와 같이 별도의 예측 모듈의 지식을 전달 받는 방법과 직접 예측하는 방식을 사용했을 떄의 성능 차이를 볼 수 있음. 직접 미래를 예측하는 prediction에서 좋은 결과를 보여줌
Q3: Why do we use the optical flow as the mask instead of directly forecasting it? Tab 5에서 보이는 바와 같이 optical flow를 직접 학습하는 방법보다 dynamic region ~ patch를 예측하는 것이 더 좋은 성능을 보여줌. 이는 픽셀 수준으로 예측해야하는 optical flow를 예측하는 것보다 간략한 동적 영역을 예측하는 것이 복잡도가 낮아 학습이 용이했던 것을 보임
Q4: The effectiveness of structured attention in DreamVLA. Tab 6에서 보이는 바와 같이 attention map을 fig 4와 같이 causal 방식으로 수행하는 것보다, 바로 structure attention을 수행 했을 때, 더 높은 성능을 보여줌
Q5: Can we use the shared query to predict the comprehensive world knowledge? Tab 7에서 보이는 바와 같이 <dream>과 <action>을 구분한 Separated와 공통으로 사용하는 Shared로 구분된 실험으로 두 쿼리는 구분되어 사용되는 것이 더 좋은 성능을 보여줌. 두 정보는 포괄적으로 유기적인 정보지만, 세계 지식을 토대로 행동이 구성되는 것이기 때문에 분리된 토큰이 더 좋은 성능을 보여준 것이라고 판단됨
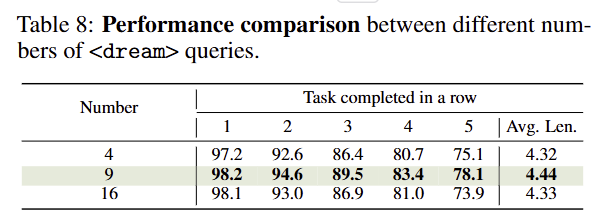
Q6: Effect of the query count per modality inside queries. Tab 8에서 보이는 바와 같이 <dream> tokens의 크기에 대한 실험 결과이며, 실험적으로 9개로 설정했을 때 좋은 성능을 보여줌
이제 로봇 정책도 multi-modal에 정착하는 것 같습니다. 어떤 방향이 맞는지 모르겠지만, 기존 인지 모듈이 하던 작업들이 로롯 조작에 있어 도움이 될 것이라고 의심하지 않기 때문에 추훈 연구에서는 기존 인지 연구에서 정의된 문제와 해결법들을 로봇 정책의 문제를 해결하는 데에 적시에 활용하도록 노력을 가하고자 합니다.