안녕하세요 이번에 소개할 논문은 Text-Video Retrieval(TVR) 모델에 Parameter-Efficient Transfer Learning(PEFT) 기법을 적용시킨 논문입니다. TVR 태스크는 기본적으로 Text와 Vision의 매칭을 기반으로 수행되기 때문에 CLIP가 같은 모델을 백본으로 많이 사용합니다. 하지만 사전학습된 모델을 Full-finetuning 하는 것은 Cost가 너무 많이 들기 때문에 백본은 고정시켜놓고, 학습가능한 모듈을 도입하여 학습하는 PEFT가 많이 연구되고 있습니다. 여기서 학습가능한 모듈이란 Adapter,LoRA (Low-Rank Adaptation), Prompt Tuning 등의 기법들을 의미합니다. 최근 TVR 태스크는 PEFT 기법을 적용시키는 연구가 많이 진행되고 있어 방법론과 문제 정의를 참고할겸 리뷰하게 되었습니다.
1.Introduction
앞서 말씀드린대로 CLIP 모델을 Full-finetuning 하는 것은 Cost가 너무 많이 들고 또한 과적합의 위험성이 있기 떄문에 PEFT를 접목시킨 연구들이 진행되고 있습니다.
하지만 기존의 연구들은 비디오 데이터의 고유한 특성을 고려하지 않고 단순히 PEFT 기법들을 도입했다고 합니다. 그래서 저자는 이를 문제 삼아 PEFT 방법을 적용시킬때는 비디오의 두 가지 특징을 고려해야 한다고 주장하고 있습니다.

첫 번째 특징은 Temporal Sparsity 입니다. 비디오 데이터를 살펴보면, 비슷한 장면이 반복되는 경우가 많습니다. 예를 들어, 그림 1에서처럼 화면은 고정되어 있고 사람이 설명을 하는 장면이 있을때, 프레임이 중복되는 경우가 있을 수 있습니다. 그런데 이러한 모든 프레임을 동일하게 처리하게 되면, 오히려 중요한 정보가 희석되고, 불필요한 장면까지 모델이 학습하게 되어 비효율적일 수 있습니다. 특히 CLIP과 같이 영상을 프레임 단위로 나누어 표현하는 모델에서는, 이처럼 비슷한 프레임들이 많아질수록 결과적으로 특징이 지나치게 부드럽게(Over-smooth) 표현되는 문제가 발생합니다. 이는 영상 내의 미세한 변화나 중요한 디테일이 묻혀버리는 현상으로 이어질 수 있습니다. 따라서 비디오의 특징을 반영하기 위해 시간적으로 중요한 장면만 선택하여 학습에 활용하는 방식(Temporal Sparsity)이 필요합니다.
두 번째 특징은 Temporal Correlation입니다. 비디오는 이미지와 다르게, 장면들이 시간에 따라 이어지면서 어떤 행동이나 사건이 일어나는 과정을 보여줍니다. 그래서 비디오를 제대로 이해하려면, 이전 장면과 다음 장면이 어떻게 연결되어 있는지도 같이 고려해야 합니다.
예를 들어, 그림 1에 나온 예시처럼, 쿼리 문장에 ‘dog’와 ‘bird’ 라는 두 개의 객체가 포함되어 있다 할때, 쿼리 패치가 프레임 #3에 있다고 가정하고, 해당 패치와 다른 패치들 간의 유사도를 시각화해보면, 일반적인 self-attention 방식은 강아지 객체에만 집중하고, 새 객체는 간과하는 경향이 나타납니다. 이는 self-attention이 한 프레임 안에서만 연산되기 때문입니다. 그렇기 때문에 여러 프레임에 걸쳐 등장하는 다양한 객체나 행동을 이해하기 위해서는 프레임 간의 관계도 고려를 해야합니다.
앞선 문제를 해결하기 위해 저자는 Retrieval framework with sparse-and-correlated AdaPter (RAP)를 제안합니다. 구체적으로는 Temporal Sparsity를 고려하기 위해 Low-Rank Modulation (LoRM) 모듈을 제안하고, Temporal Correlation을 고려하기 위해 Asynchronous Self-Attention (ASA)을 제안합니다. 자세한 방식은 다음 섹션에서 설명드리고 저자의 Contribution을 정리하고 넘어가겠습니다.
- RAP 제안: CLIP 기반 TVR에 PEFT 기법을 적용해 파라미터 수를 줄이고 temporally sparse, correlated video feature를 생성함.
- Low-rank modulation: 비디오의 Temporal Redundancy 문제를 완화하기 위해 low-rank modulation module 사용
- Asynchronous Self-Attention: 계산 효율을 유지하면서도 Long-range Dependency를 반영할 수 있는 구조 제안
- 성능 : 기존 PEFT 및 Full-finetuning보다 동등하거나 더 우수한 성능 달성
2. Method
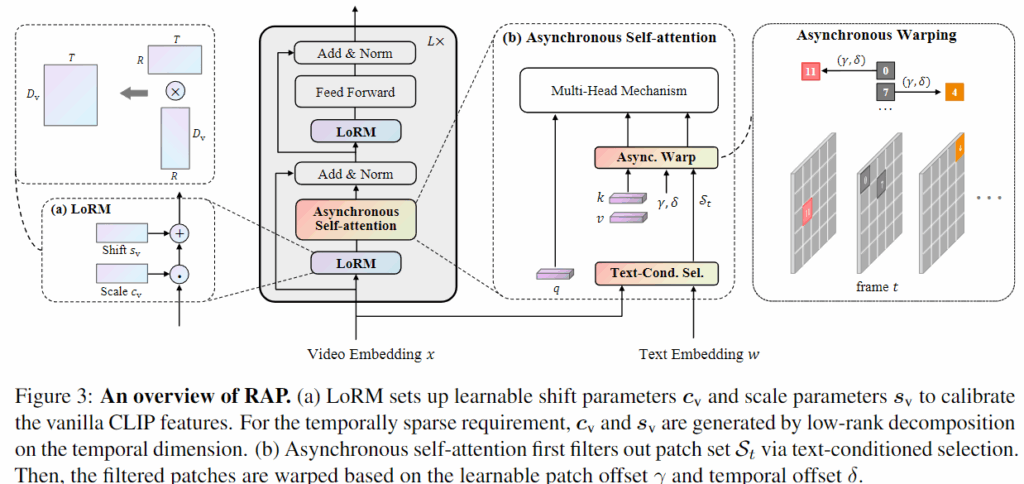
저자가 제안하는 모델 구조는 다음과 같고, CLIP을 백본으로 하기에 모델 구조도 CLIP의 한 Layer에 추가적인 모듈이 설계된 것을 확인할 수 있습니다. 먼저 모듈 설명에 앞서 비디오와 텍스트가 어떻게 임베딩되는지 살펴보겠습니다.
2.1 Feature Embedding
Video Embedding

비디오 임베딩은 먼저 각 프레임을 P×P 크기의 patch로 분할하여, 한 프레임당 N=H×W/P2개의 patch를 생성하고, 여기에 CLS 토큰을 포함한 (N+1)개의 token에 대해 임베딩을 수행하며, 이를 통해 t번째 프레임은 xt0∈R(N+1)×Dv 형태의 초기 frame-level feature로 표현됩니다. 이 때 전체 T개의 프레임이 주어지면, l번째 Transformer layer의 비디오 표현은 xl∈RT×(N+1)×Dv로 구성되며, 이를 CLS 토큰 표현 fl∈RT×Dv와 patch 표현 pl∈RT×N×Dv로 분리해 사용할 수 있습니다.
Text Embedding
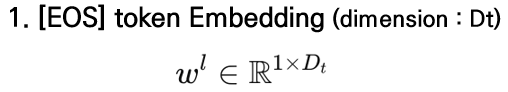
텍스트 임베딩은 입력 문장 끝에 [EOS] 토큰을 추가하여 문장 전체의 의미를 요약하는 global 표현을 얻고, l번째 레이어에서 [EOS] 위치에서의 출력 벡터를 문장 임베딩으로 사용하며 이는 wl∈R1×Dt로 정의됩니다.
2.2 Low-rank Modulation
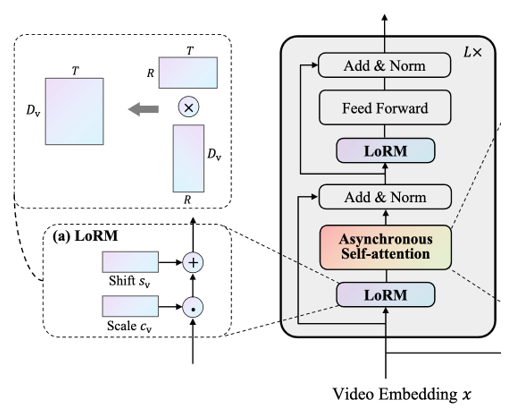
그럼 저자가 첫 번쨰로 제안하는 Low-rank Modulation에 대해 살펴보겠습니다.
먼저 비디오의 경우, 프레임별로 CLIP에서 추출된 feature는 비디오의 시간적 특성을 잘 반영하지 못하고, 인접한 프레임 간 중복 정보가 많아 over-smooth한 표현이 생성되는 문제가 있습니다. 이를 해결하기 위해 저자는 Scale과 Shift 파라미터를 사용하여 중요한 프레임을 강조하고 덜 중요한 프레임은 억제하도록 합니다. 하지만 모든 레이어에 해당 파라미터를 추가하면 모델이 무거워지므로, 파라미터 수를 줄이기 위해 두 개의 작은 행렬 곱으로 구성된 low-rank 구조를 사용합니다.
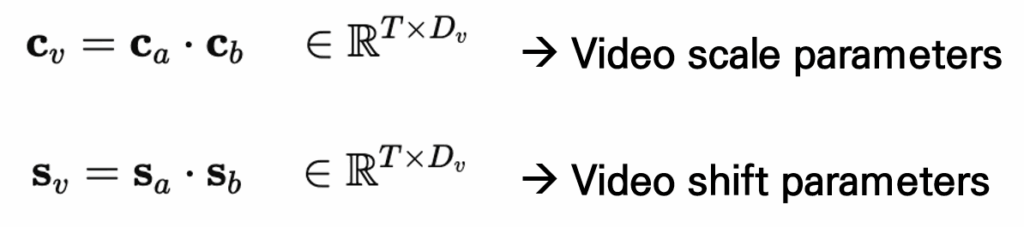
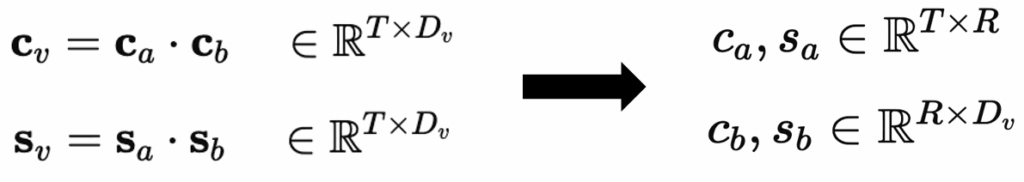
학습 가능한 파라미터 Scale, Shift를 사용해 CLIP feature x에 대해 u=cv⊙x+sv 의 방식으로 적용됩니다.

low-rank 구조를 사용하면 전체 프레임을 일부 차원(rank-R) 으로 근사할 수 있기 때문에 , 결과적으로 시간적 중복성을 줄이고 정보가 응집된 feature가 생성됩니다.
2.3 Asynchronous Self-Attention
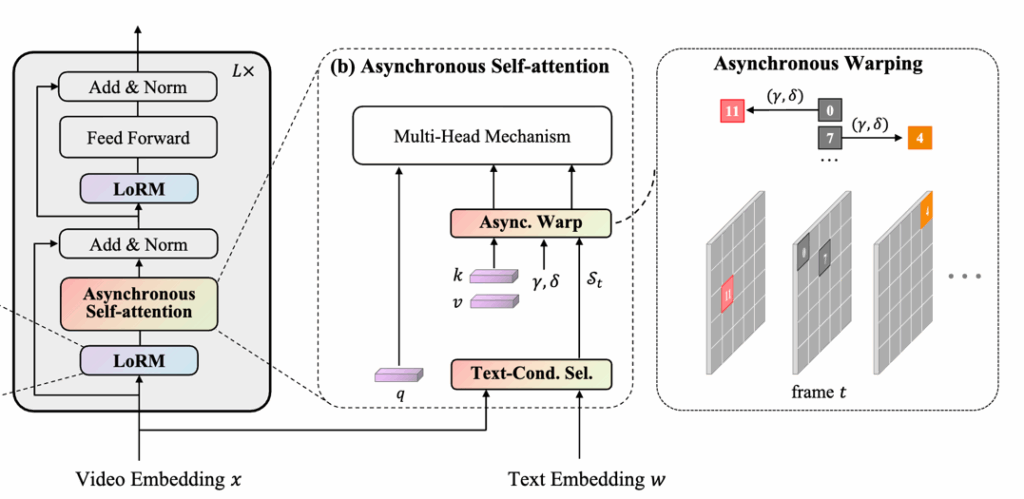
기존의 Self-Attention은 한 프레임 내에서만 패치들 간의 관계를 학습하는데, 이는 영상이 갖는 시간적 흐름을 반영하지 못해 이미지와 영상 사이에 표현 차이(modality gap)가 발생합니다. 이를 해결하기 위해 이 논문에서는 Asynchronous Self-Attention을 제안합니다. 하지만 한 프레임의 패치와 다른 프레임들의 패치들간의 attention 연산을 수행하면 계산 비용이 증가하기 때문에 영상 내에서 텍스트와 의미적으로 관련된 부분에만 Asynchronous Self-Attention을 하기 위해 Text-conditioned Selection을 먼저 수행합니다.
Text-conditioned Selection

먼저, 프레임별로 추출된 영상 특징들을 평균 풀링하여 하나의 video feature를 만듭니다. 그런 다음 주어진 텍스트 후보들 중에서 이 영상과 가장 유사도가 높은 문장(w*)를 선택합니다. 이후 선택된 문장(w*)과 영상의 각 패치 간 유사도를 계산하고, 그중 Top-K 개의 패치만 골라 집합 St로 정의합니다.
Asynchronous Self-Attention

이후 선택된 패치들(St)에 대해서만 Asynchronous Self-Attention을 적용함으로써, 영상 내 시간적 관계를 학습할 수 있도록 합니다. 이를 위해 각 패치의 쿼리는 원래대로 사용하고, 키(key)와 밸류(value)는 오프셋(offset)을 적용해 다른 위치의 정보와 연산을 하도록 구성합니다. 이때 γ는 패치 위치 방향의 오프셋, δ는 시간 축 방향의 오프셋으로, 둘 다 학습 가능한 파라미터이며 모든 레이어에 공유됩니다. 예를 들어, 특정 프레임의 n번째 패치가 선택되었으면, 해당 패치의 키와 밸류는 (n + γn)번째 위치, (t + δt)번째 프레임을 사용해 구성됩니다. 선택되지 않은 패치에 대해서는 원래의 키와 밸류를 그대로 사용합니다.
3.Experiments
먼저 MSR-VTT 벤치마크에서 결과를 살펴보겠습니다.
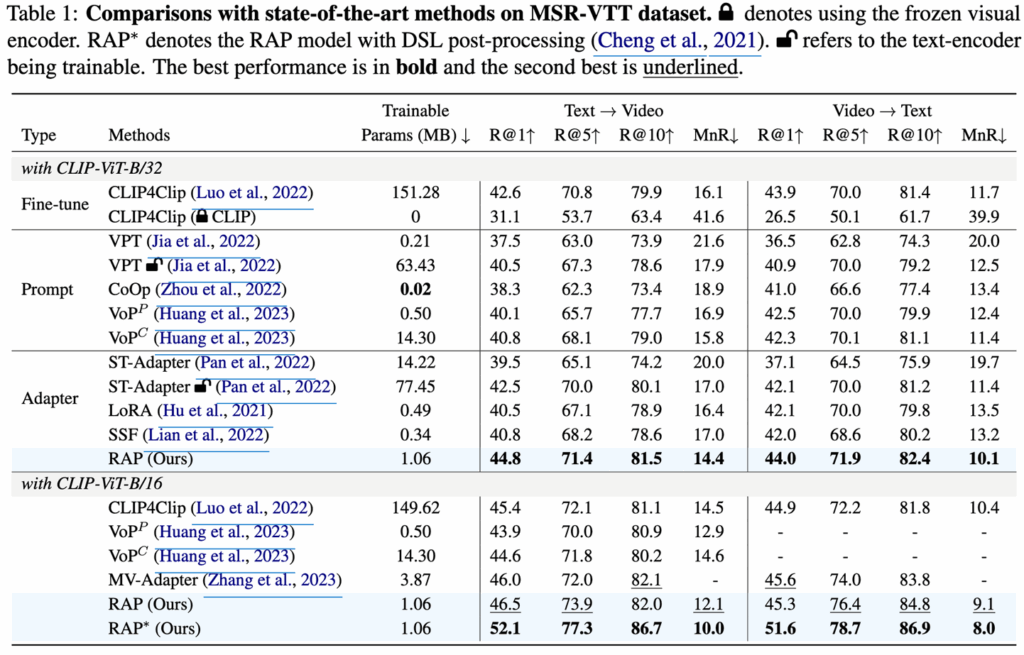
비교 모델로는 CLIP을 Full-finetuning한 CLIP4Clip과 Prompt-tuning 및 Adapter 기반의 모델들과 비교합니다.
MSR-VTT 데이터셋에서 RAP는 CLIP4clip과 비교했을 때 R@1 기준으로 2.2% 높은 성능을 보였으며, 훈련에 필요한 파라미터를 비교했을 때 0.7%(1.06M vs. 151.28M)의 파라미터만 사용하고도 성능을 높일 수 있다는 것을 보여주었습니다. 또한 다른 프롬프트 튜닝 및 어댑터 기반 방식들보다도 더 나은 성능을 기록했습니다.
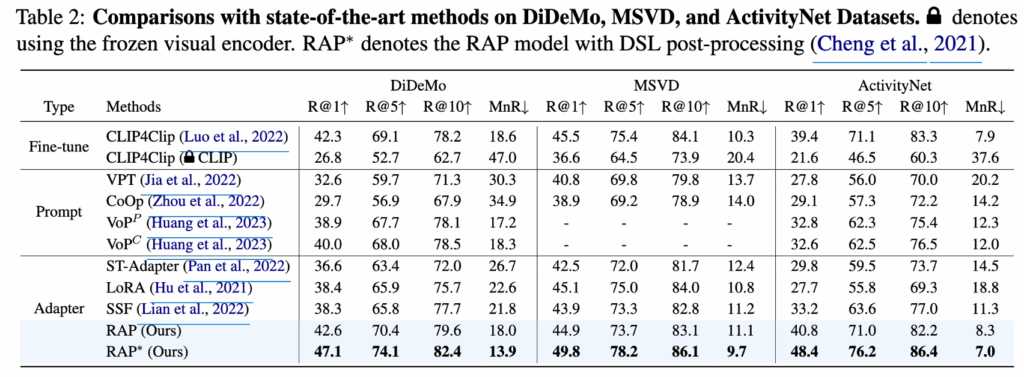
MSR-VTT 데이터셋 뿐만 아니라 DiDeMo, MSVD, ActivityNet 데이터셋에서의 결과도 살펴보면 CLIP4Clip이나 다른 프롬프트 튜닝, 어댑터 기반 방식보다 성능이 높은 것을 확인할 수 있습니다.
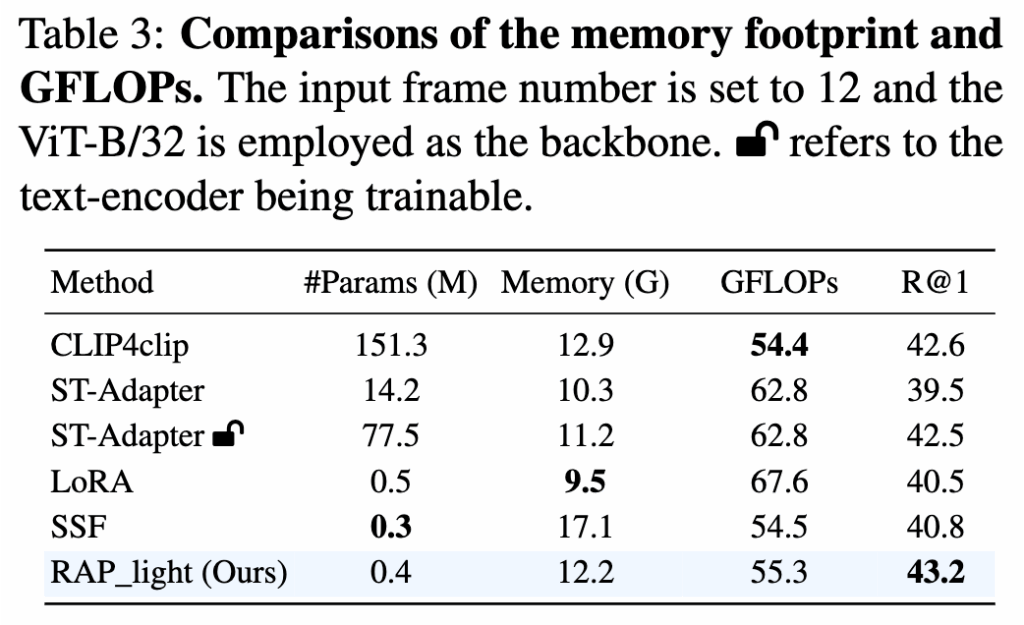
추가로, 제안한 모델의 메모리 사용량과 연산 복잡도를 알아보기 위해, 학습 중 GPU 메모리 사용량과 모델의 GFLOPs를 표 3에 제시했습니다. 여기서 저자는 마지막 4개 레이어에만 LoRM과 ASA를 적용한 RAP_light로 실험을 진행했습니다. 그 결과, 전체 파인튜닝된 CLIP4clip과 비교하여 RAP_light는 학습 가능한 파라미터 수를 크게 줄이면서 메모리 사용량을 약간 낮추고, 동시에 성능은 향상시켰습니다.
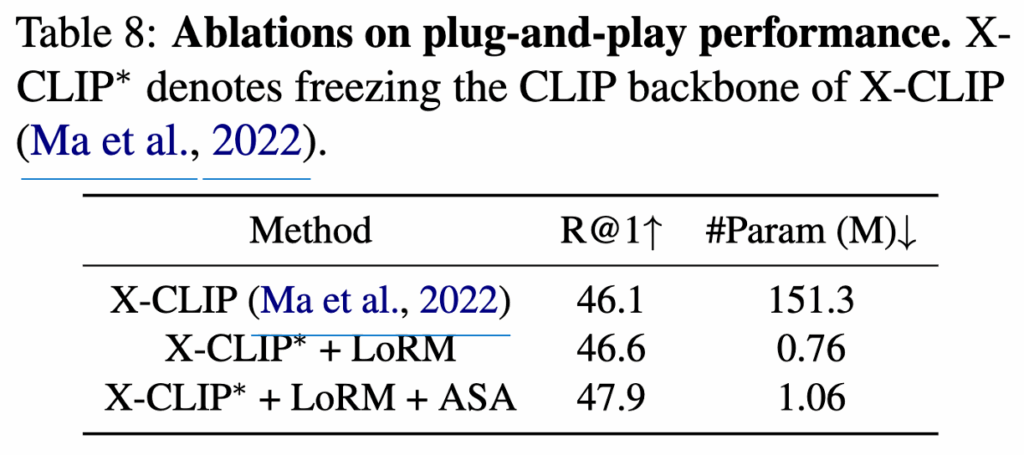
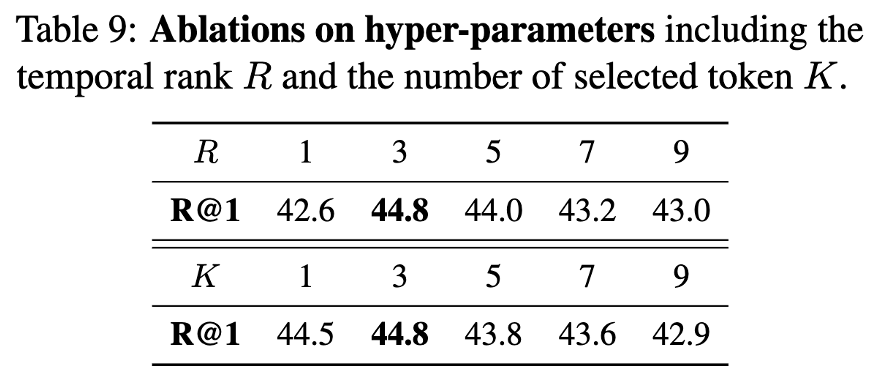
LoRM과 ASA는 plug-and-play 방식의 모듈이기 때문에 기존 CLIP 기반 모델에 추가하여 사용할 수 있습니다. 이를 입증하기 위해 CLIP 기반 방법인 X-CLIP을 기반으로 실험을 진행했으며, 이때 CLIP 백본은 고정하고 각 Transformer 레이어에 LoRM을 삽입한 뒤 기존의 self-attention을 ASA로 대체했습니다. 그 결과는 표 8에 나와 있으며, LoRM과 ASA를 통해 성능이 좋아지는 걸 확인할 수 있었습니다. 또한 하이퍼파라미터 관련 실험도 진행했는데 LoRM에 적용되는 rank R과 ASA가 적용되는 토큰(K 값)을 조절해본 결과 R=3, K=3일 때 가장 좋은 성능이 나왔습니다.
감사합니다.
지난번 세미나에서 발표해주신 논문이라 쉽게 읽었습니다.
1. 아무래도 프레임마다 중요한 정도가 다를 수 있을 것 같다는 생각이 드는데요, ASA의 text-conditioned selection에서 top-K를 선택할 때 모든 프레임에서 동일 개수의 패치를 고르는 것 말고 adaptive하게 선택하는 방법에 대한 실험 결과가 있는지 궁금합니다. 없다면 adaptive하게 선택하는 것이 추가되었을 때 어떤 효과가 있을까요? 의견 궁금하네요
2. RAP에서 LoRM과 ASA를 마지막 4개 레이어에만 적용한 것이 최적인 이유에 대한 분석이 있는지 궁금합니다. 다른 레이어에 넣었을 경우에 대한 실험은 없는지, 마지막 4개에만 추가한 이유가 있는지 없다면 그렇게 추가해야한 이유가 무엇일지 의견 궁금합니다
안녕하세요 정의철 연구원님 좋은 리뷰 감사합니다.
Low-rank Modulation에서 scale과 shift가 시각적 정보를 통해 중복되는 프레임을 억제하고 중요한 정보를 남기는 압축하는 것과 같은 기능을 하는 것으로 이해했습니다. Text-Video Retrieval은 아무래도 text에 연관된 video의 정보가 중요할 것으로 생각되는데 텍스트의 정보를 반영하지 않은 채로 비디오의 정보를 압축하게되면 실제로는 텍스트와 연관된 한 부분이 억제될 수도 있을 것 같은데 이 부분에 대한 의철님의 생각이 궁금합니다.
감사합니다.