이번에 소개드릴 논문은 self-supervised monocular depth estimation 쪽 논문입니다. 해당 task로 논문을 쓰고 있어서 당분간 주기적으로 해당 분야의 최신 논문 리뷰를 작성할 것 같네요.
self-supervised monocular depth estimation에 대한 논문들의 framework은 거의 대부분 2019년 ICCV에 게재된 monodepth2 논문을 베이스로 하고 있으니 이쪽 분야에 대해서 익숙하지 않으면 monodepthv2 논문 예전 연구원분들의 리뷰를 참고하면 좋을 듯 합니다. 리뷰 쓰는 현재 열이 38도 정도 나고 있어서 리뷰 퀄리티가 조금 떨어지는 점 양해부탁드립니다ㅜ
Intro
self-supervised monocular depth estimation의 taks를 간략하게만 소개하면 GT로 사용할 lidar, depth camera, radar 같은 sensor 없이 단순히 RGB 이미지만으로 depth를 학습하고 예측하는 방법론을 의미합니다. 초기에는 stereo camera를 기반으로 연구를 많이 했었는데 2019년 monodepth2를 기점으로 단일 카메라의 비디오 프레임을 활용해서 self-supervised learning을 하는 연구가 꾸준히 등장하고 있습니다.
이렇게 self-sup depth estimation 연구가 등장하게 된 배경으로는 Lidar, radar 같은 depth sensor가 함께 촬영된 데이터셋을 취득하는 것이 비용적으로 만만치 않으며, 마찬가지로 stereo camera를 기반으로 촬영된 데이터셋도 단일 카메라로 촬영된 데이터보다는 그 수가 상대적으로 적기 때문에 데이터 접근 효율성 관점에서 비디오 프레임 기반 self-sup 연구가 많은 관심을 받았던 것 같습니다. 지금은 그 인기가 좀 시들해진 것 같긴 하지만서요ㅎ..
아무튼 제가 다룰 논문의 주제도 비디오 프레임을 입력으로 하는 self-sup monocular depth estimation 방법론으로, 이러한 기존 비디오 프레임 기반의 방법론들은 보통 loss function, geometric constraints, feature representation learning, occlusion 및 dynamic object를 다루기 위한 semantic information, CNN + Transformer 등의 아키텍처 변환 등등 여러가지 측면에서 성능 개선을 하기 위한 다양한 시도들을 진행했습니다.
여기서 논문의 제목을 보시면 아시겠지만 제가 리뷰할 논문 제목 안에 diffusion이라는 내용이 들어있거든요? 그래서 저자는 이전 연구들의 framework이 너무 discriminative-based paradigm에만 고려하고 있다고 지적합니다. 어떻게든 generative 특성을 지닌 diffusion model을 이쪽 연구에 가져오게끔 빌드업을 하려는 모습입니다.
아무튼 저자들은 요즘 Diffusion model이 다양한 downstream discriminative task에서 많이들 활용되고 있다는 점을 언급하며 여기엔 segmentation과 depth estimation과 같은 task에서도 마찬가지라고 합니다. 근데 기존 diffusion 기반 depth 추정 방법론들은 GT가 없으면 학습하기 어려워서 supervised learning에서만 도입되었다고 하는데요. 저자들은 diffusion model의 뛰어난 생성 능력을 기반으로 target GT가 없는 (self-sup learning) 상황에서 depth를 학습하는 방법론을 새롭게 제안했다고 합니다.
저자들은 이 diffusion model을 활용해야하는 이점이 무엇이냐에 대해 다음과 같은 3가지를 이야기하는데 intro에 담긴 내용이라 그런지 모호한 말들 위주로 작성이 되어있긴 합니다 (특히 2번..)
- 강력한 생성능력이 depth 예측에 더 높은 퀄리티를 보장한다는 점.
- self-sup monocular depth estimation을 조건적인 디노이즈 과정으로써 재구성함으로써 task의 한계를 극복할 수 있다?
- 예측값에 대한 불확실성을 통해 안전이 중요한 어플리케이션에서 사용 가능하더라
아무튼 그래서 저자들이 논문을 통해 제안하는 방법론은 크게 2가지로, 첫째는 coarse-to-find pseudo GT diffusion process를 만들었다는 점, 둘째는 contrastive depth reconstruction 방식을 제안했다는 점입니다.
첫번째에서 coarse-to-find를 저자들이 유독 강조를 하는데 이는 고정된 고해상도에서 작업하는 기존의 diffusion 방식과 달리 저자들이 제안하는 coarse-to-fine diffusion 방식이 더 빠른 추론 속도와 더불어 더 정확한 성능을 도달할 수 있었기 때문이라고 합니다 (그림 1 참조)
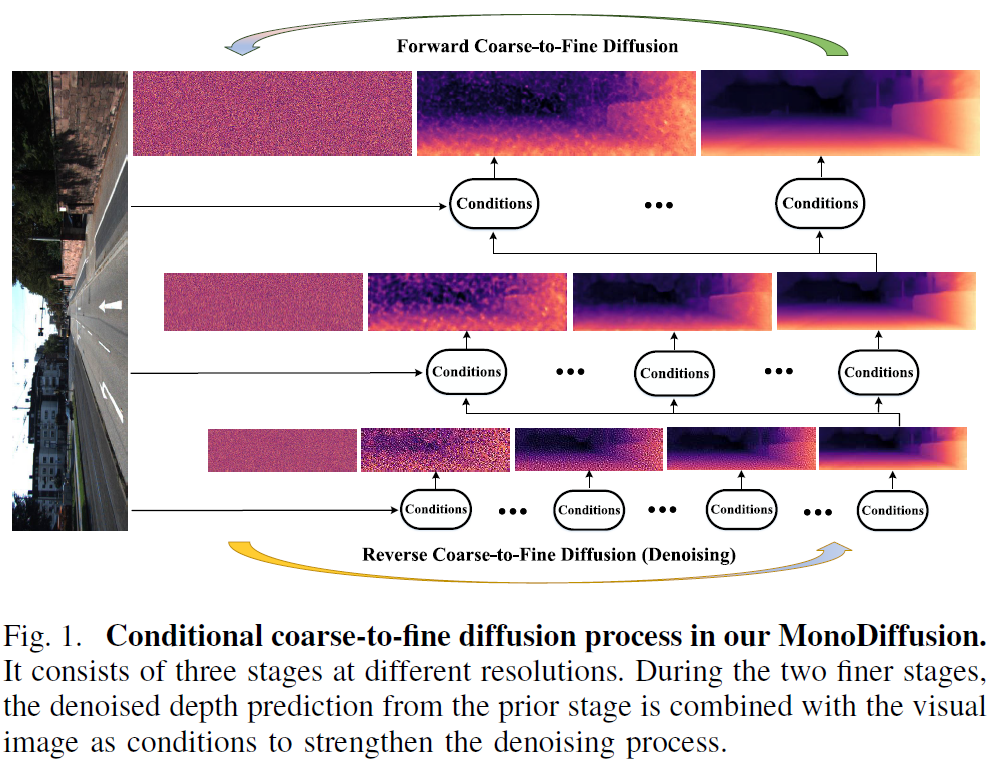
두번째 contribution은 자신들의 framework으로 학습시킨 depth model의 depth 값이 종종 번지는 현상이 발생하는데 이 문제를 완화시켜주는 기법이라고 하네요 (아래 그림2 붉은 박스와 같은 번짐 현상을 해결하려고 하는 것).

Method
그럼 본격적인 방법론에 대해서 소개드리겠습니다. 우선 diffusion model을 self-sup monocular depth estimation에 적용하기 위해서는 아래와 같은 상황들을 해결해야한다고 합니다.
첫째로, diffusion model 학습을 위해서는 target GT에 순차적으로 nosie를 생성하는 forward process가 필요한데 self-sup learning 기반의 monocular depth estimation이 해당 논문의 task이기 때문에 학습에 사용할 target GT가 없다는 점을 해결해야합니다.
둘째로, diffusion model의 경우 이 noise를 단계별로 제거함으로써 최종적인 depth를 예측하는 것인데, 기존의 diffusion framework처럼 고해상도 레벨에서 반복적으로 노이즈를 제거하게 된다면 너무 많은 연산량과 추론 시간이 필요하다는 점이죠.
이러한 두 가지 문제점에 대해서 저자들은 매우 심플하게 해결합니다. 우선 첫번째 문제는 그냥 기존의 self-sup SOTA 모델을 활용해서 teacher model을 학습 후 diffusion model을 학습시키기 위한 pseudo GT 만드는 것입니다.
그리고 두번째 문제에 대해서는 해상도가 상대적으로 작은 coarse 레벨에서 denoise iteration 수를 늘리고, fine-detail을 다루는 high resolution에서는 denoise iteration 수를 줄여서 연산량을 낮추는 것이죠. 따라서 저자들의 diffusion model은 그림1에서 보셨다시피 원본 해상도 , 1/2해상도, 1/4 해상도에서 denoise 과정을 처리하는 3단계 Coarse-to-Fine diffusion 모델 구조를 가지고 있습니다.
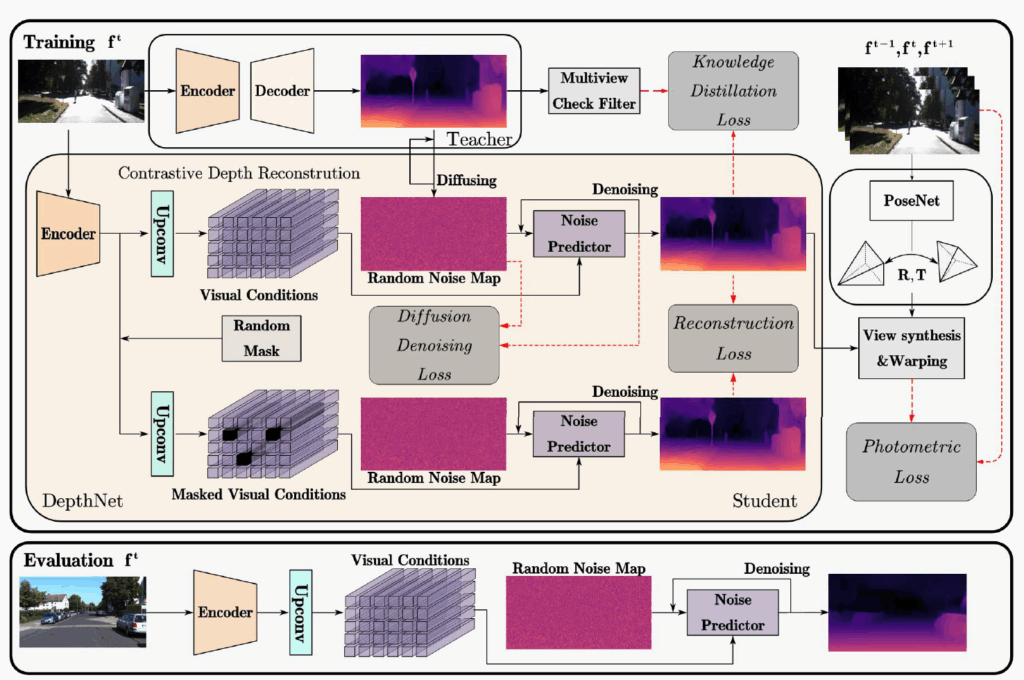
방법론의 전체 framework은 위에 그림과 같이 이루어져있습니다. 제일 위에 teacher model의 output에 random noise map을 적용해서 중앙에 student model 학습을 위한 GT를 생성합니다.
수식적으로 차근차근 설명드리면, 우선 Teacher model에서 예측한 pseudo GT에 noise를 단계별로 적용하여 noisy sample를 취득하는 수식은 아래와 같습니다.
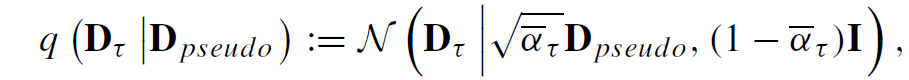
여기서 D_{pseudo} 는 teacher model의 output인 pseudo GT를 의미하며, \bar{\alpha}_{\tow} 는 t step에 따른 noise의 세기라고 간단하게 이해하시면 좋을 것 같습니다.
이 noise map과 student encoder에서 RGB 영상을 입력으로 해서 추출한 Visual Condition을 noise predictor의 입력으로 하여 얼만큼의 noise가 포함되어있는지를 예측하게 됩니다.
이러한 noise 예측과 이를 통한 denoise 과정이 diffusion에서 모델이 학습하고 prediction하는 과정이며 이 과정은 Coarse resolution부터 Fine resolution까지 모두 동일하게 진행됩니다. 다만 Fine resolution에서는 저자들이 Coarse resolution과 조금 다른 과정을 한가지 더 수행하게 되는데 Coarse level에서는 Visual Condition이 오직 RGB image의 feature로만 추출한다면, 그 이후 finer 과정에서는 이전 resolution에서 예측한 depth map 결과도 convolution 연산을 통해 geometric cue를 뽑아서 RGB feature와 함께 Visual Condition으로 활용한다고 합니다. 그리고 해당 visual condition과 noise predictor를 통해 예측한 noise를 실제 GT noise와 계산하는 diffusion denoising loss를 통해 학습이 진행됩니다(아래수식 참고).
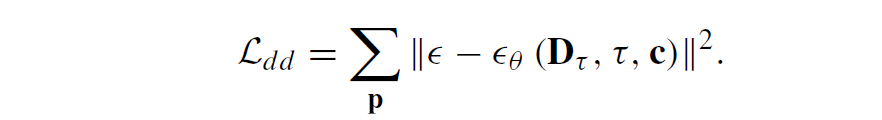
이렇게 student model이 denoise 과정과 이를 통한 diffusion denoising loss로 학습하는 것과 별개로 teacher model의 output과 direct로 학습하는 Knowledge distillation loss도 함께 적용이 됩니다. 이때 저자들은 teacher model의 output에 noise가 있을 것을 염두해두고 multi-view check filter라는 이전 연구의 기법을 활용하여 pseudo GT의 부정확한 부분을 한번 걸렀다고 합니다.
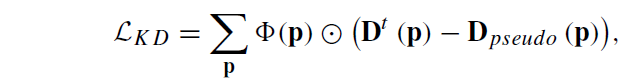
여기서 파이(p)는 multi-view check filter를 의미하며, circle dot은 element-wise multiplication을 의미합니다.
이 multi-view check filter라는 것은 저자들이 제안한 것은 아니고 기존 방법론의 기법을 활용한 것이라서 저자가 설명을 디테일하게 다루지는 않지만, 해당 filter의 컨셉만 간단하게 소개드리면 (시간축으로 연속된 두 프레임에 대해) target frame과 source frame 각각 depth map을 추론한 후, 이 두 프레임을 채널축으로 concat하여 camera pose network의 입력으로 사용하여 두 카메라의 관계를 예측, 이를 토대로 target에서 source로 warping시킨 depth map과 source에서 target으로 warping시킨 depth 정보들을
pose network가 두 카메라 사이의 상대적인 pose 값을 예측할 수 있기 때문에 depth와 pose 정보를 통해서 target image plane의 좌표를 source image plane의 좌표로 projection할 수 있으며 이를 통해 target frame에서 예측한 depth와 source frame depth를 target으로 와핑시켰을 때의 depth 값의 오차를 계산합니다. 동일하게 x,y coordinate도 source to target으로 warping된 좌표값과 실제 target 좌표값 사이의 오차를 아래와 같이 계산할 수 있습니다.
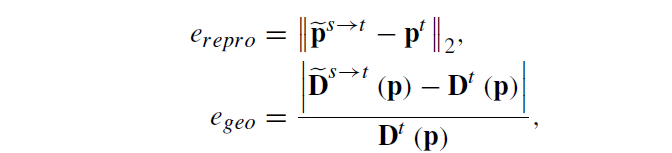
기 오차값들에 대해 아래 수식과 같이 일정 수준 이상의 오차 내에 존재하는 픽셀들에 대해서만 유효한 depth pixel로 판단하여 knowledge distillation loss의 사용할 pseudo GT로 사용하게 됩니다.
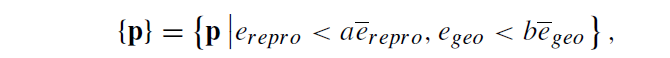
Contrastive Depth Reconstruction
지금 소개드릴 내용은 아까 그림 2에서 모델의 depth 값이 번지는 현상이 종종 발생한다고 했었는데 그 문제를 완화시키고자 저자들이 제안하는 기법입니다.
그림3의 overall framework에서도 볼 수 있듯이 Random Mask를 적용하여 Masked Visual Condition이라는 것을 추출하고, 이를 기반으로 모델이 denoise 과정을 거쳐 prediction을 예측한다음 Mask가 처리되지 않은 depth map과의 L1 loss 계산을 통해서 학습하게 됩니다.
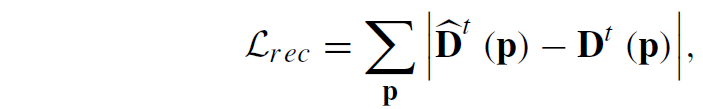
음 근데 이 방식이 얼만큼 효과적인지는 잘 모르겠는 것이 저자들이 분명 student model의 depth 번짐 현상을 해결하기 위해 위와 같이 automasking 방식으로 학습하는 과정을 추가했다고 하였는데 이 문제정의 할 때 사용한 그림2에서 번짐이 있다는 예시만 보여주고 자신들이 제안하는 해당 loss로 학습시켰을 때 그 번지는 부분이 해결되더라 라는 것은 안보여줬거든요. 그리고 논문에서도 다루는 분량과 내용이 1페이지 반컬럼도 못미치다보니 그냥 weak contribution으로 어떻게 끼어넣은 아이디어가 아닌가 싶습니다.
Implementation Detail
원래 diffusion하면 image를 latent space로 projection 시키는 encoder와 이를 복원시키는 decoder를 pretrained model을 활용하는 경우가 많은데, 해당 논문은 기존 연구들과의 pair한 비교 때문인지 self-sup monocular depth estimation 방법론의 모델 인코더 디코더를 활용하는 모습입니다.
Encoder로는 CNN과 Transformer로 구성된 LiteMono라는 방법론의 encoder를 활용하였으며, 역시나 teacher model로도 LiteMono를 그대로 활용했다고 합니다. 마찬가지로 decoder도 LiteMono의 방법론을 그대로 활용하였습니다. 또한 coarse-to-fine 과정에서는 하나의 공통된 noise predictior를 사용하는 것이 아닌 개별적인 3개의 noise prediction를 활용하였습니다.
한가지 의문이 드는 것은 Teacher model로 사용한 LiteMono라는 방법론은 이름에서도 유추하실 수 있듯이 상당히 가볍고 빠른 추론을 위해 제안된 self-sup depth estimation model 입니다. 물론 diffusion을 수행해야한다는 점에서 가볍고 빠른 추론을 신경안쓸 수 없기 때문에 student model의 구조를 LiteMono로 사용하는 것은 이견이 없지만, teacher model도 LiteMono를 활용했다는 점은 사실 좀 납득이 가지는 않네요. 얘가 성능이 가벼운 것 치고는 좋은 것이지 큰 모델들과 비교하면 당연히 성능이 낮을 수 밖에 없거든요. 이 부분에 대해서 저자들이 딱히 밝히지는 않고 있어서 궁금하네요.
Experiments
학습에 사용한 데이터셋은 KITTI, Make3D, 그리고 DIML 데이터셋을 사용하는데 보통 KITTI를 가장 많이 사용하고 Make3D는 모델의 generalization performance를 보여주기 위해 평가용 데이터로만 활용되는 비교적 단순한 데이터셋에 해당합니다. DIML은 이쪽 분야에서는 잘 활용하지 않는 평가 셋이라서 저도 낯설게 느껴지는데 저자들이 diffusion model의 zero-shot 성능을 더 잘 보여주기 위해 추가로 도입한 데이터셋으로 판단됩니다.
평가 메트릭으로는 아래의 것들을 사용합니다.
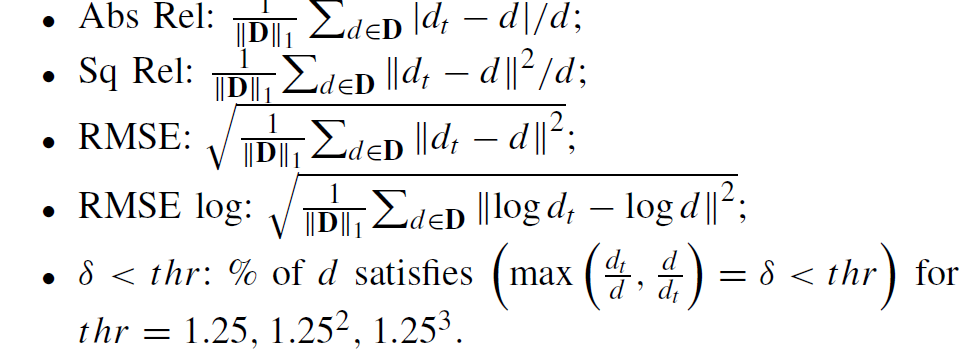
여기서 Abs_rel, Sq Rel, RMSE, RMSE log는 값이 작을수록, delta는 값이 클수록 좋은 성능을 나타내고 있다고 이해하시면 되겠습니다.
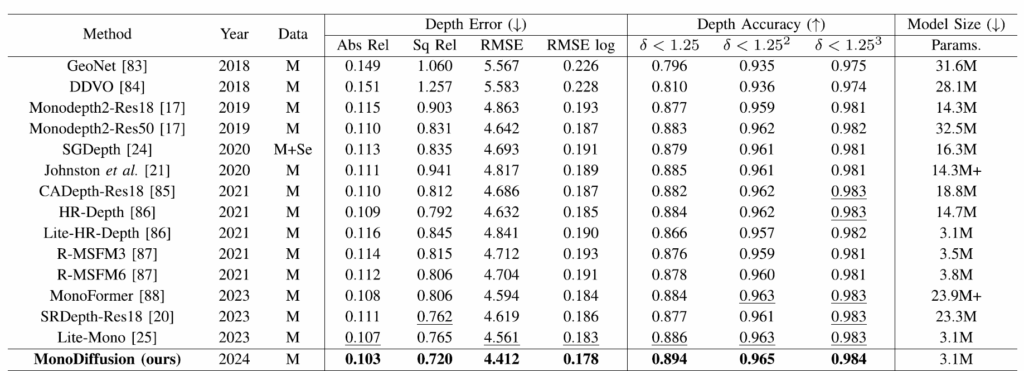
위에 표는 KITTI dataset에 대한 정량적 비교 평가입니다. 우선 teacher model로 사용한 Lite-Mono보다 더 좋은 성능을 달성했다는 점에서 인상적인 결과를 남겼습니다. 다만 아쉬운 점이 있다면 비교 방법론이 조금 옛날 방법론들이라는 점도 아쉽게 느껴지는 부분입니다. 또한 더 아쉬운 것은 예전 방법론들 중에서도 자신들보다 성능이 좋은 모델들은 비교결과표에서 다 빼버렸다는 점인데, 리뷰어들 입장에서는 해당 분야에 깊은 관심이 없으면 모를 수 밖에 없는 상황인지라 저자의 이런 행동이 아쉽게 느껴지네요ㅜ
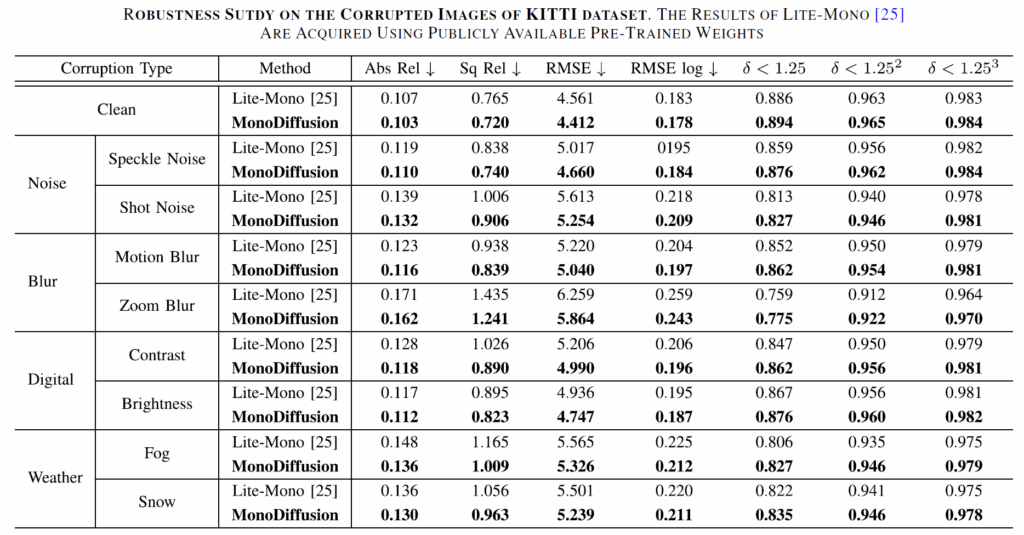
위에 표는 Teacher model로 활용한 Lite-Mono와 자신들의 Monodiffusion 모델이 입력에 다양한 noise가 반영되었을 때 얼만큼의 성능 드랍이 있는지, 즉 얼마나 입력 노이즈에 강인한 깊이 추정이 가능한지를 평가한 것으로, KITTI dataset에 Noise, Blur, Digital, weather 등 다양한 인위적 noise를 적용해서 평가한 것으로 판단됩니다. diffusion model이 noise를 제거하는 방향으로 학습을 하다보니 여러 noise 상황에 대해서 더 좋은 깊이 추정 성능을 보여주는 것이 아닐까 싶습니다.
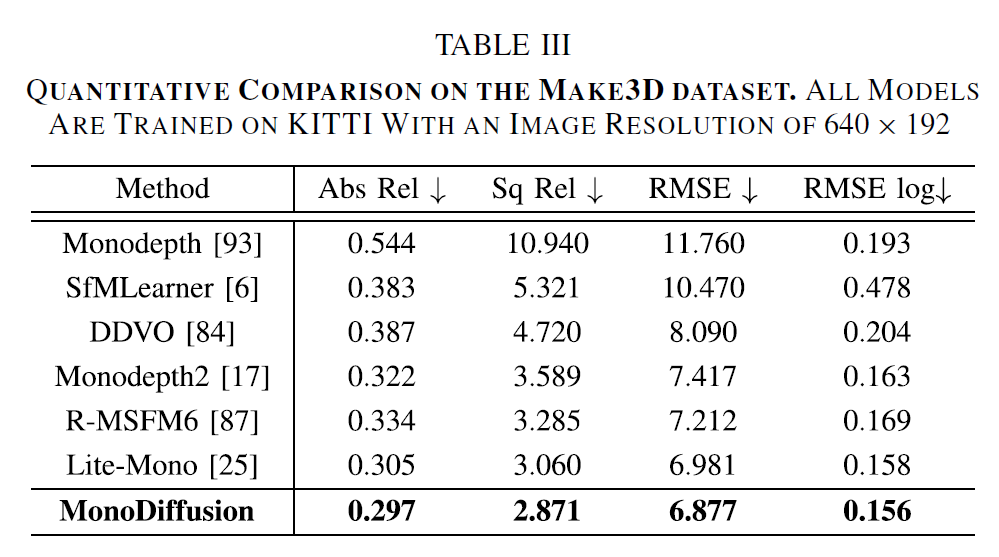
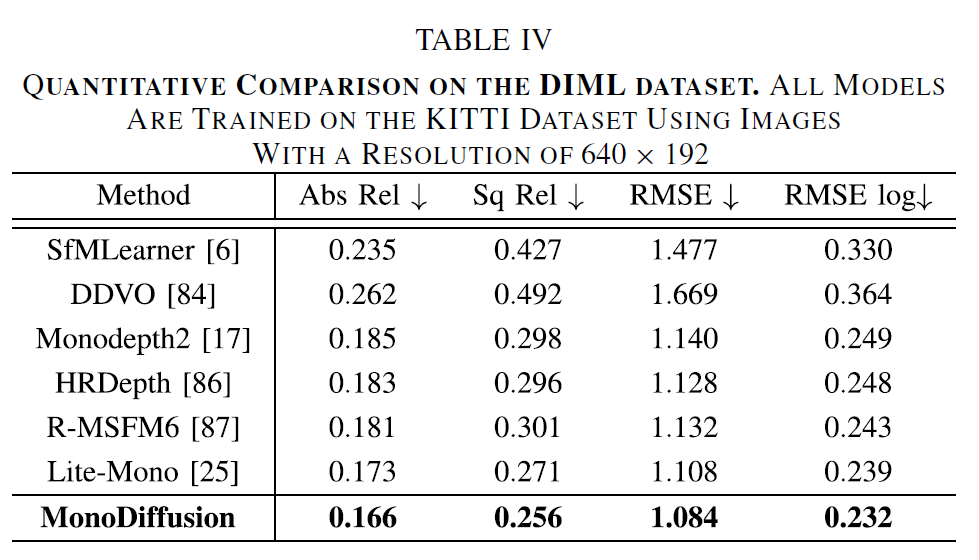
다음은 KITTI dataset으로 학습한 모델이 make3D 데이터셋과 DIML 데이터셋에서 평가하였을 때의 성능을 나타냅니다. 마찬가지로 위에서 사용되는 비교 방법론들은 당연히 teacher model로 사용한 LiteMono보다 안좋은 성능의 방법론들만 골라서 넣었기 때문에 저자들의 방법론보다 성능이 떨어진다는 점 참고하시면 좋을 것 같습니다. 하지만 그럼에도 teacher model인 Lite-Mono보다 모든 메트릭에서 좋은 성능을 달성했다는 점에서는 긍정적으로 평가할 수 있겠습니다.
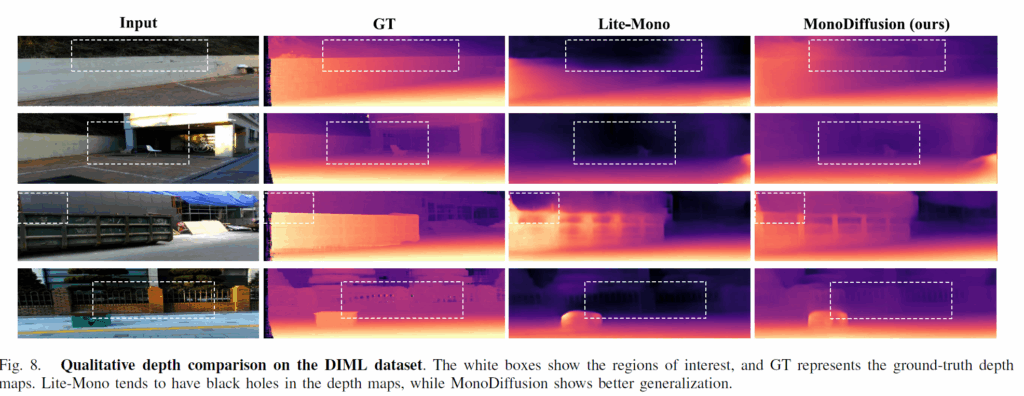
위에는 DIML 데이터에 대한 정성적 비교결과로 자신들이 제안하는 depth map이 GT와 더 유사한 예측이 가능하다는 점, 그리고 기존의 teacher model은 까맣게 hole이 생기는 반면에 자신들은 (정확한 depth인진 모르겠지만) 값을 예측한다는 점에서 생성 모델의 이점을 강조하고 있습니다.
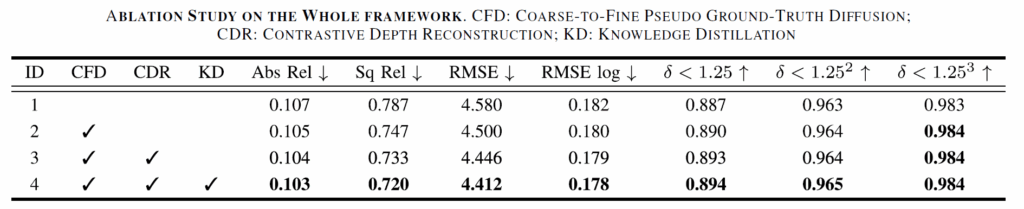
마지막으로 아래 표는 ablation study 결과입니다. 저자들이 제안하는 CFD, CDR, KD를 각각 적용하였을 때의 성능이 얼만큼 향상하는지를 나타내고 있습니다.
결론
diffusion model을 self-sup monocular depth estimation 방법론에 처음? 적용한 것인지는 잘 모르겠지만(아마 방법론 이름을 보니 처음 제안한 것이 맞는 듯 합니다) diffusion framework을 적용시키기 위해 노력한 과정은 contribution으로 인정해야할 것 같습니다. 다만 자신보다 더 좋은 성능의 방법론들과의 비교는 테이블에서 빼버린 점, limitation을 언급하지 않는 점에서 저자들의 논문을 붙이고 싶다는 그 마음이 같은 분야에서 논문을 썼었고 지금도 쓰려고 하는 저로서 한편으로는 이해되면서도 논문을 읽는 독자로써는 아쉽게 느껴질 수 밖에 없었네요.