어느 덧 25년도의 절반이 지나고도 20일이나 더 지났습니다. 체감 상 매우 짧게 느껴지지만 실제로는 긴 시간인 반년의 기간 동안을 되돌아보는 글을 작성하고자 합니다.
사실 이번 상반기 동안에 연구와 관련해서 회고할만한 내용이 그리 깊지도 넓지도 않은 상황입니다. 친형이 작년부터 많이 아팠기 때문에 저는 5월중순까지 연구실을 쉬었었기 때문이죠. 그래서 그런지 요즘 떠오르는 연구 트랜드나 동향에 대해서 적응하는 것이 많이 힘들었습니다. 특히 연구 트렌드에 대해서 동료들한테도 묻고 교수님께서 6월에 열린 CVPR을 보내주신 덕에 학회도 참석해보며 조금씩 접하였을 때 제가 느낀 감정은 그저 매우 빠른 기술 발전 속도에 그저 압도 당했다 라는 말밖에 안나오더군요.
CVPR 학회 참석 후기에서도 작성했던 내용이지만, 제가 알던 perception 관련 연구들의 비중이 많이 줄어든 것을 쉽게 체감할 수 있었습니다. 예전에는 segmentation, detection, depth estimation와 같이 어찌보면 기본이 되는 perception 방법론들이 많이들 연구되고 있었는데 지금은 물론 그 수가 적지는 않지만 예전만큼 주류를 이루는 연구들이 아니었습니다.
아무래도 Foundation model들이 등장하면서 이들의 성능을 넘길 수 있는 연구를 개인과 학교들이 할 수 없기 때문에 이들을 활용해서 더 확장되고 고도화된 연구를 하는 쪽으로 많이들 넘어간 것으로 보이며 그 중 하나가 비디오를 입력으로 기반한 연구들이 예전에 비해 많이 보였던 것 같습니다.
이러한 것들을 종합적으로 고려해봤을 때, 너무 제 자신의 사고와 연구 폭이 너무 옛 기준에 갇혀있다는 느낌을 받았던 것 같습니다. 제가 그동안 연구했던 분야들은 입력으로 사용되는 정보들도 image level에서 국한되며, task 자체도 depth나 segmentation과 같은 어찌보면 low-level percetion에 맞추어졌다는 점에서 무언가 과거의 연구 트랜드에만 갇혀있는 느낌이 들었던 것 같아요.
그러나 Foundation model과 LLM의 등장 이후로 급속도로 빨라지는 기술 연구 속도에 제 자신을 억지로 맞춘다고해서 현실적으로 그걸 따라잡을 수 있을 것 같지 않아 걱정이네요. 그래서 억지로 새로 나온 기술들을 급급하게 공부하기보다는 방향성을 잡아야겠다는 생각이 드는 요즘입니다. 일단 궁극적으로 저의 목표가 무엇인지를 정하고 그 목표에 도달하기 위해 필요한 기술들이 무엇인지, 그 기술의 현재 수준과 앞으로 보완해야할 점은 무엇인지 등을 아는 것이 우선적으로 필요하다고 볼 수 있겠네요. 이렇게 방향성을 잘 정하게 되면 그 연구 방향으로 꾸준히 나아가기만 하더라도 (설령 최신 트렌드 기술을 따라잡지 못하였다는 것에서 비롯된 조급함 없이) 만족스러운 연구를 할 수 있을 것 같다는 결론을 현재는 내리고 있습니다.
일단 제가 관심 있어하는 분야는 자율주행 쪽입니다. 물론 그렇다고 해서 꼭 자동차를 위한 기술로 한정 짓는 것은 아니고 실내/외 무인이동체에 대해서도 모두 고려하고 있습니다. 엄밀히 따지면 이 두 이동체의 주행 환경과 목적성은 다르기 때문에 이들의 자율주행 문제를 푸는 접근 방식이 서로 다를 수는 있겠으나 주행에 필요한 핵심 기술들은 비슷하다고 생각합니다.
이러한 자율주행 분야에 대해 저의 방향성을 잡기 위해서 크게 차량과 무인로봇으로 나누어 산업 동향을 간단하게 살펴보았습니다. 우선 자율주행 차량에 관해서 해당 업계를 이끌어나가는 top2는 웨이모랑 테슬라라고 생각하기 때문에 이 둘을 중점적으로 찾아봤습니다.
우선 웨이모와 테슬라는 똑같은 완전 자율주행 차량이라는 목표에서 서로 다른 철학과 접근방식을 가지고 있습니다. 웨이모는 고전적인 시스템 공학의 원칙 기반으로 자율주행 차량에 대한 전략을 구성합니다. 즉 이들은 안전을 매우 중요시 여기기 때문에 엄격한 경계 내에서 명확히 문제 정의를 하고 만약 이를 해결하여 다음 단계로 넘어가기까지 안전성을 철저히 검증한다고 합니다.
그래서 이들은 피닉스, 샌프란시스코와 같은 제한된 지역 내에서 입증 가능한 자율주행 안전 사례를 계속 축적함으로써 대중과 규제 기관의 신뢰를 우선적으로 확보하는데 초점을 두고 있다고 합니다. 특히 이 안전성은 산업의 성장과도 매우 관련이 높기 때문에 더더욱 이를 중요하게 여기고 있는 듯 합니다. 이들은 이러한 안전성을 위해 정해진 환경 안에서만 서비스를 제공할 뿐만 아니라 자율주행 차량의 하드웨어 구성 많은 신경을 쓰게 됩니다.
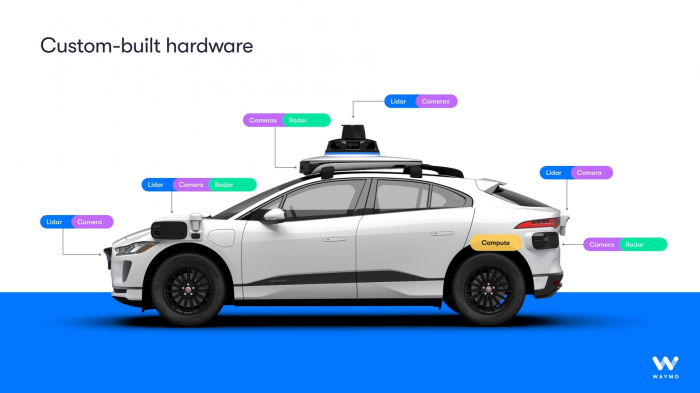
웨이모의 자율주행 차량은 우선 LiDAR(3D 매핑 및 객체 탐지), 레이더(속도 측정 및 악천후 성능), 그리고 고해상도 카메라(Jaguar I-PACE 모델 기준 29대)를 포함한 포괄적인 센서 제품군을 사용합니다. 이러한 다양한 센서들을 융합해서 활용하는 센서퓨전 방식은 각 센서의 단점들을 다른 센서의 장점이 보완하는 상호보완적 방식을 통해 자율주행 인식 과정에서 발생하는 사고를 예방할 수 있습니다. 예를들어, 특정 유형의 센서가 햇빛의 눈부심(카메라)이나 짙은 안개(LiDAR)로 인해 기능이 저하될 경우, 다른 센서가 이를 보완하여 보다 견고한 인식 시스템을 구축할 수 있겠죠. 하드웨어 기술들도 꾸준히 발전하고 있기 때문에 해당 센서 제품군의 비용은 하락하고 있지만, 2024년 기준 약 12,700달러로 여전히 어마어마한 비용을 가지고 있기 때문에 개인 차량보다는 상업용 로택시 등으로 밖에 현재로써는 활용할 수 없다는 단점도 있긴 합니다.
반면 테슬라는 웨이모랑 접근 방향성이 조금 다릅니다. 테슬라는 인간도 두 눈으로 충분히 운전을 하는데 고도화된 AI도 그럼 인간의 시각 시스템과 유사한 카메라만으로 자율주행을 충분히 할 수 있지 않겠냐는 논리를 기본적으로 가지고 있습니다. 테슬라는 자신들이 판매한 소비자들의 테슬라 차량에서 수집한 방대한 양의 주행 데이터를 기반으로 비용이 많이 들고 확장이 어려운 사전 제작된 HD 맵 없이 어디에서나 운전할 수 있는 일반화된 AI를 만드는 것을 목표로 하고 있습니다. 그래서 waymo와 같이 정해진 지역에서만 자율주행 하는 것이 아니라 언제 어디서든 자율주행을 하는 것을 목표로 하고 있습니다.
테슬라는 LiDAR와 레이더를 생산 차량에서 제거하고 오직 8개의 카메라 제품군에만 의존하고 있습니다. 이는 위에서도 설명드렸다시피 인간이 눈만으로도 주변 환경을 인식하면서 운전을 하니, 카메라만으로도 충분히 일반화된 자율주행 솔루션을 구현할 수 있다는 철학이 담겨있는 것이죠. 그리고 이러한 세팅 덕분에 waymo와 달리 하드웨어 비용(차량당 약 400달러)과 복잡성이 극적으로 줄어들었습니다. 그러나 Lidar, radar와 같은 센서 퓨전의 이점을 취하지 못하기 때문에 RGB 카메라가 인식하기 어려운 환경에서 AI가 올바른 판단을 내리지 못하게 되면 큰 사고로 이어져 결국 차량 안밖으로 사상자를 만들 수 있다는 문제가 발생할 수 있습니다.

제가 듣기로 테슬라가 한달 전쯤?부터 로보택시를 시범 운영했다고 들었습니다. 그동안에는 기술력 부족으로 로보택시를 운용하지 못했었고 지금도 완전 초창기 시범운영이라 10대?정도 테스트했다고 들었어서 아직 waymo에 비해 갈길은 멀지만 잠재력만큼은 정말 뛰어난 것 같습니다. 이는 waymo와 같이 상업용 로보택시 전용 차량을 살 필요 없이 테슬라 모델 Y에 software 업데이트만으로도 충분히 자율주행이 가능하기 때문이죠. 실제로 머스크는 로보택시가 상용화되면 언제든지 소비자들이 보유한 테슬라 차량을 로보택시처럼 굴려서 우버택시처럼 활용할 수 있다고 희망찬 미래를 이야기했었죠.
지금까지 하드웨어 세팅과 입력 모달리티 활용에 대해서 웨이모와 테슬라를 비교했다면 이번엔 자율주행을 수행하기 위한 model architecture에 대해서 비교해보겠습니다.
우선 웨이모의 소프트웨어 스택은 모듈식으로 구성되어 있다고 합니다. 이는 인식(perception), 예측(prediction), 계획(planning), 제어(control)를 위한 별개의 트랜스포머 기반 모델들로 이루어지는데 이러한 구조는 각 구성 요소를 독립적으로 테스트, 검증 및 업데이트할 수 있게 해줍니다. 즉 시스템을 더 해석 가능하게 만들고 규제 기관에 안전 사례를 제시하기 용이하게 만들 수 있는 것이죠.
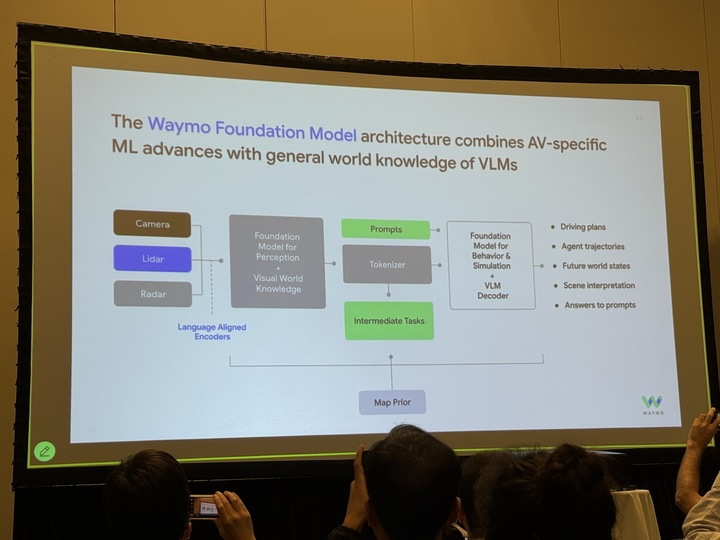
근데 요즘은 LLM이 한창 좋은 모습을 보여주다보니 기존의 waymo가 활용한 Camera, Lidar, Radar 말고도 language까지 고려한 자율주행 용 VLM을 설계하는 것에도 관심이 많은 듯 합니다. 위 사진은 CVPR 워크숍에서 waymo 발표를 들었을 때 촬영한 슬라이드인데, 자신들이 개발하는 Waymo Foundation model이고 이들은 HD Map 정보, Camera/Lidar/Radar 그리고 Language 정보 등을 토대로 경로 계획/ 미래 상태/ 장면 이해/ 프롬프트에 대한 답변 등 다양한 task를 하나의 모델로 다 수행가능한 것처럼 보입니다.
그리고 waymo의 경우 매년 챌린지를 열고 있는데 25년 챌린지로 선정된 task들은 아래와 같습니다.
- Interaction Prediction: Given agents’ tracks for the past 1 second on a corresponding map, predict the joint future positions of 2 interacting agents for 8 seconds into the future
- Sim Agents: Given agents’ tracks for the past 1 second on a corresponding map, simulate 32 realistic joint futures for all the agents in the scene.
- Scenario Generation: The Scenario Generation Challenge expands on the Sim Agents Challenge. In the Sim Agents challenge, the task is as follows: Given one-second pose histories of all agents on a provided map, simulate 32 realistic joint futures for all the agents.
- Vision-based End-to-End Driving: Various approaches to developing autonomous driving systems exist, including a modular approach, which may involve distinct components for perception, prediction, and planning for example, and an end-to-end approach, which may involve directly learning to map raw sensor data to driving actions. This latter approach is especially attractive to explore given the advancements in Large Language Models which bring world knowledge and reasoning capabilities.
가장 최근의 challenge task로 지정된 것으로 보아 이 4가지 task들이 현재 waymo에서 가장 관심있는 기술 키워드와 task가 아닐까 라는 생각이 듭니다. 흥미로운 점은 단순히 perception해서 planning/action하는 것뿐만 아니라 다양한 시나리오를 생성해서 최대한 real 환경을 만드는 것 역시 중요하게 생각한다는 점입니다. 이렇게 다양한 환경들과 OOD를 포함하는 edge case들은 실제 데이터로 취득하기 어렵기 때문에(그리고 데이터를 얻는 순간 사고도 날 수 있구요.) 이러한 환경들을 묘사하고 시뮬레이션하는 기술을 중요하게 생각하는 것 같습니다.
테슬라는 FSD v12를 통해 단일화된 ‘엔드-투-엔드’ 아키텍처로 전환하였으며 이러한 거대 단일 신경망은 카메라로부터 비디오 입력을 받아 조향, 가속, 제동과 같은 제어 명령을 바로 예측합니다. 이러한 end to end 학습 방식은 기존 스택 방식에서 모듈 간에 존재할 수 있는 정보 병목 현상을 제거하여 개발 및 추론 속도를 가속화 할 수 있습니다. 그러나 이러한 ‘블랙박스’ 특성은 디버깅, 검증, 그리고 결정에 대한 설명을 매우 어렵게 만들어 안전 인증에 상당한 도전 과제를 제기한다는 문제도 있어서 안전성을 중요하게 여기는 자율주행 특성상 이 end-to-end 방식이 민간과 규제기관을 설득하기 어려울 수도 있다고 합니다.
물론 그래도 추구해야하는 방향성 자체는 제 생각에 end-to-end로 가는 것이 더 맞다고 생각을 하고 있으며, 웨이모 역시도 이를 인정하고 있기 때문에 challenge task에 end-to-end driving을 포함하고 있다고 생각합니다. 실제로 language 모델까지 alignment한 foundation model을 개발하고도 있고요.
무인로봇 쪽 동향도 간단하게 한번 살펴봤습니다. 이쪽은 어느 회사가 잘나가는지 제가 잘 몰라서 Gemini보고 정리 좀 해달라고 부탁을 했는데 아래와 같은 회사 리스트를 뽑아주더군요.
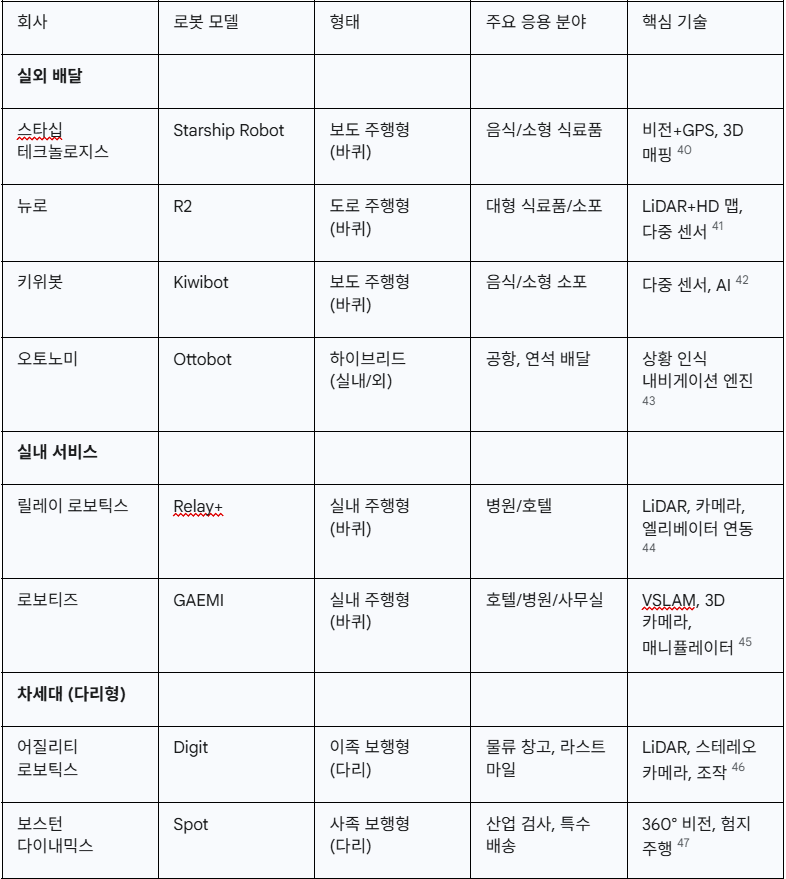
일단 크게 실내용 로봇과 실외용 로봇으로 구분을 할 수 있으며 대부분은 바퀴를 통해 이동을 하는 로봇들이었습니다. 대표적으로 스타십 테크놀로지와 키위봇은 음식 및 소용 식료품 등을 배달하는 소형 배달 로봇을 서비스하는데 스타십의 경우 대학교와 같은 교통량이 적고 한정된 공간 안에서 배송 서비스를 주로 진행합니다.

스타십 로봇은 마치 waymo의 sensor fusion 셋업처럼 위의 작은 소형 로봇에 12개의 카메라, 초음파 센서, 레이더를 신경망과 결합하여 99%에 가까운 배송 성공률을 보여준다고 합니다. 스타쉽은 먼저 위성 이미지로 보행로, 횡단보도, 도로 등 길의 종류를 구분한 뒤 해당 데이터를 기반으로 로봇은 목적지까지 도달할 수 있는 기본 경로를 계획합니다.
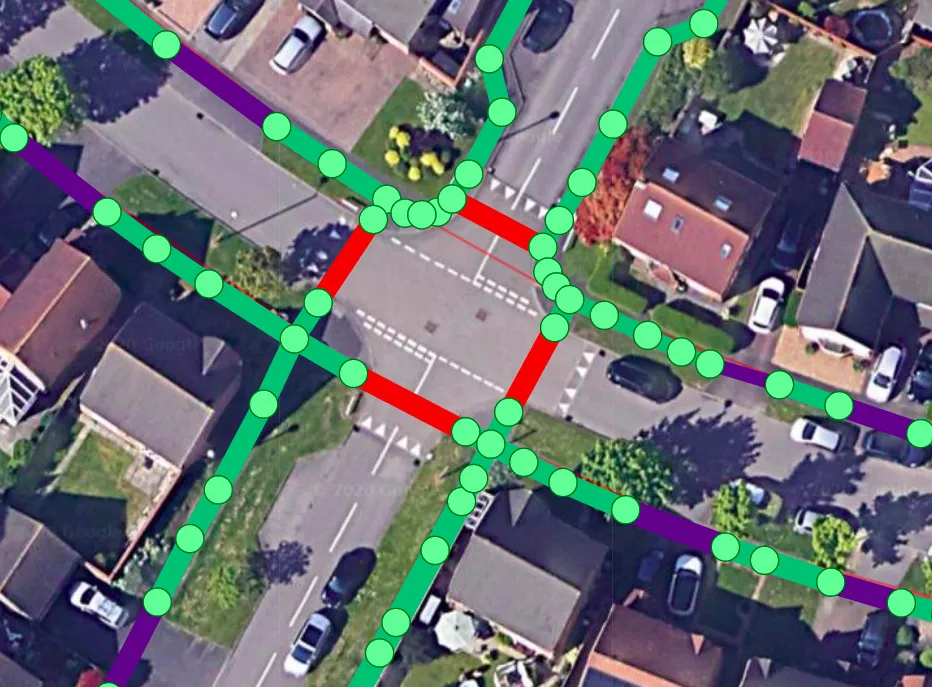
이렇게 계획된 경로를 토대로 로봇은 이동을 시작하는데 이 과정에서 취득된 센서 데이터를 통해 건물, 가로등, 기둥 등에서 아래와 같은 edge feature를 추출한다고 합니다.

해당 여러 로봇들이 주행하면서 취득한 해당 edge feature들은 서버로 보내지고 서버에서는 해당 정보를 토대로 3D world map을 생성할 수 있다고 하는데 그 과정에 대해서는 디테일하게 나오지 않아서 아쉽네요ㅜ. 아무튼 이렇게 개별 로봇들이 각자의 배송을 수행하면서 취득한 데이터들은 각각의 3D map을 생성할 수 있게 되는 것이고 이 개별 3D map을 통합하는 과정을 수행한다고 합니다. 예시로는 두 로봇에서 검출된 동일한 옥상에 대하여 자신들의 소프트웨어가 기존의 지도와 어떻게 연결시켜 합칠지를 연산해서 추가한다고 하는데.. 디테일한 설명은 회사 소개 글에 찾을 수가 없어서 아쉽네요잉.
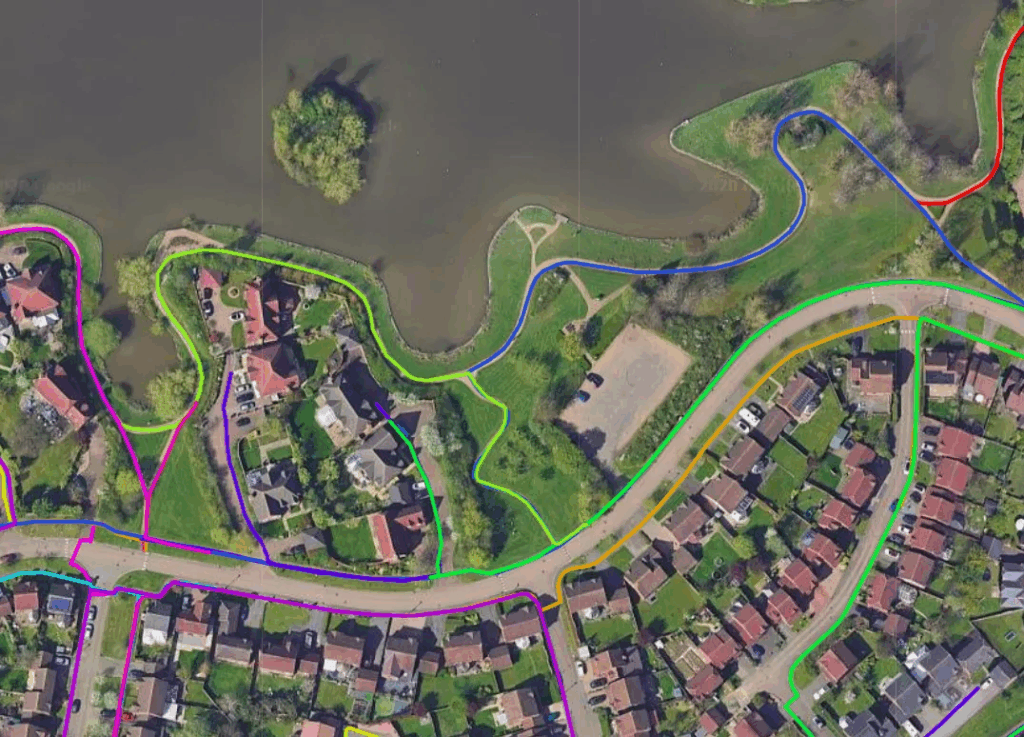
아무튼 위와 같이 새로운 지역에 대해 개별 로봇들이 취득한 데이터를 합치는 과정을 통해 통합된 맵을 생성할 수 있게 되며 그림 속 서로 다른 색깔의 라인들이 각각 다른 로봇에서 취득한 데이터라고 생각하시면 되겠습니다.
매핑 프로세스의 마지막 단계는 로봇이 완전 자율 주행을 하기 전에 보도의 위치와 폭을 정확히 계산하는 것입니다. 이는 로봇이 해당 지역을 탐색하면서 촬영한 카메라 이미지를 참조로 처리하고 위성 이미지를 기반으로 이전에 생성한 2D 지도를 통합하여 만들어집니다.
매핑 프로세스의 마지막 단계는 로봇이 완전 자율 주행을 하기 전에 보도의 위치와 폭을 정확히 계산하는 것입니다. 이는 로봇이 해당 지역을 탐색하면서 촬영한 카메라 이미지를 참조로 처리하고 위성 이미지를 기반으로 이전에 생성한 2D 지도를 통합하여 만들어집니다. 아래 그림에서 저 노란색 원이 이제 경로를 수정하는 위치를 의미하고 이 위치에 따라서 기존 2D 위성 지도의 경로(녹색라인)가 조정이 되는데 아래 예시가 원래는 GIF이지만 리뷰 사이트에는 GIF가 안올라가서 아쉽네요.

그리고 재밌는 점은 회사측이 밝히길, 계절이 변화되거나 새로 건물을 짓고 공사하는 등의 변화가 배송 로봇의 길찾기에 생각보다 큰 영향을 주지 않는다고 합니다. 이미 자신들이 위와같은 과정을 통해 만든 3D map이 이러한 변화에 상관없이 강건한 네비게이션을 수행할 수 있다고 하며, 설령 완전히 새로운 도로가 생기는 등 큰 변화가 발생하더라도 매일 배달 로봇들이 배달하면서 취득한 데이터로 맵을 업데이트하기 때문에 하나의 로봇이 새로운 도로에 대해 업데이트를 마치면 다른 로봇들은 언제 그랬냐는듯이 그 새 코스를 한번 와본것처럼 익숙하게 돌아다닌다고 하네요?
결과적으로 스타십 테크놀로지는 위성 영상과 로봇이 직접 취득한 데이터를 통해 맵을 어떻게 계속 보정하고 보완해나가는지를 중요하게 여기는 듯 합니다. 그리고 이러한 맵은 로봇이 현재 자신이 어디에 위치하고 있는지, 그리고 목적지까지 어떠한 경로로 갈 것인지에 대한 모든 과정에서 매우 중요한 정보로 활용되기 때문에 좋은 맵을 만드는 것에 더더욱 집중하는 것이 아닌가 합니다.
그리고 이런 무인 배달 로봇들에 대한 동향을 찾아보다가 “라스트 마일”이라는 개념을 처음 접하게 되었는데요. 라스트 마일이란 통신 업계에서 주로 최종 통신 구간의 의미로써 많이 사용되는 용어인데 배달 분야 관련해서는 물건이 고객한테 배송되기까지 거치는 많은 과정 중에서 마지막 지점을 지칭할 때 사용하는 용어라고 합니다.
즉 거리의 개념이라기보다는 말그대로 고객에게 전달되기 바로 직전 단계를 의미하는 것이고, 이게 무인 배달 로봇에서는 고객이 위치하는 장소에 도달하기 위한 일종의 장애물들?을 어떻게 수월하게 통과할것이냐를 의미하는 것으로 보입니다. 가령 위에서 소개한 스타쉽 테크놀로지 로봇이 고객이 위치한 건물까지 잘 도착을 했다면 이제 건물 안으로 들어가서 고객이 있는 현관문까지 가면 좋을텐데, 그런 기술이 아직 많이 부족하다는 것 같아요.
로봇이 직접 그 건물의 출입구를 찾아서, 실내를 다시 탐사하고 계단이 있으면 계단을 지나가거나 엘리베이터가 있으면 엘리베이터를 눌러서 직접 고객이 있는 층까지 도달하는 것은 아까 위에서 소개드린 실외 길찾기랑 또 완전히 다른 문제라고 볼 수 있기 때문입니다.
특히 스타쉽 로봇은 바퀴 달린 로봇인데 저 로봇 하드웨어 설계상 계단은 못올라가고 턱이 높은 장소도 지나가기 어려울 수 있습니다. 그래서 다리형 로봇의 필요성이 점차 증가하는 추세이긴한데, 다리형 로봇을 제어하는 것은 바퀴형보다 더 어려운 상황이기도 하고 쉽게 넘어질 수도 있어서 아직 바퀴형에 비해 상용화하기 어려운 듯 보이네요.
조금 더 찾아보니 결국 end-to-end 배송을 위해서는 하이브리드 방식으로 접근을 해야할 것 같다는 내용이 있었는데, 예를 들어 실외 배송을 할 때는 바퀴형 플랫폼을 이용해 목적지 부근까지 도착을 해서 최종 목적지(아마 건물 실내를 의미하겠죠?)까지 가는 플랫폼은 다리형 로봇이 운송한다는 것이죠.
아무튼 지금까지 자율주행 차량과 로봇에 대해서 특정 회사들을 중심으로 그들이 어떤 문제에 관심이 많고 어떻게 서비스하는지를 간단하게 알아보았는데 사실 회사들이 자신의 기술에 대한 구체적인 방식을 노출하지는 않아서 보면 볼수록 그래서 어떻게 한다는거지? 하는 궁금증이 많이 들긴 했지만 대략적으로 어떤 문제에 관심이 많구나 정도를 알아볼 수 있었던 것 같습니다.
특히 스타십 테크놀로지가 웨이모랑 비슷하게 문제를 풀고 있다는 생각이 많이 들었는데, 우선 서비스를 제공할 물리적 환경을 정해놓고, 다양한 센서들의 퓨전과 위성 영상 등의 활용을 통해 99%에 가까운 배송 성공률을 보여주고 있다는 점에서 많이 유사했던 것 같아요. 근데 결국 테슬라가 추구하는 자율주행의 방향성이 매우 어렵지만 된다면 훨씬 더 많은 파급력이 있다고 생각하는 편이라 무인 로봇들도 카메라만으로 정해진 목적지까지 길을 찾아가는 방향성으로 발전해야할 것 같다는 생각이 들었습니다.
글을 쓰다보니 지난 상반기에 대한 회고가 아니라 회사 소개하는 느낌이 되어버렸네요. 그렇지만 상반기가 한달 반정도 밖에 안남은 상황에서 연구실을 복귀했기 때문에 회고할만한 내용이 크게 없었기도 했고 이번 기회에 잘나가는 회사들은 무슨 문제에 관심이 있는가를 대략적으로 알게 되어서 좋았던 것 같습니다. 앞으로의 연구 방향성에 대해서도 그저 막연하게 visual navigation을 해야지라는 생각만 하고 있었는데 이번에 찾아본 자료와 여기서 더 보충해가지고 연구 방향성을 더 보완하면 좋지 않을까 합니다.
회사에서의 산업동향 야무지게 정리되있네요 잘 읽었습니다
리뷰에 작성하신 것처럼 최신 트랜드만 좇기보단 큰 목표에 맞는 방향성 설정이 정말 중요하다는거 정말 공감되네요ㅋㅋ 그래서 그런데 자율주행이라는 키워드 안에서 본인의 연구 질문 혹은 핵심 문제 하나 뽑는다면 뭐가 가장 궁금하신 가요?
그리고 그 연구 주제로 CVPR 기대해보겠습니다 파이팅 ^^
안녕하세요 글 재밌게 읽었습니다.
관심있던 분야는 아니지만 읽어보니 되게 흥미롭고 재밌어보이네요.. 풀어야할 문제도 많아보이고 실생활과 바로 연관되어 보이는 분야라 그런지 재밌게 느껴진 것 같습니다.
마지막에 배달로봇 설명해주신 부분에서 최단거리로 주행해야 전력이나 부품의 소모성대비 효율을 낼 수 있을 것 같으니 그러한 방법론도 연구해볼 수 있고, 위성사진으로 1차적으로 길들을 만들고 이후에 센서정보들 융합해서 3D map 만든다는거 보면 이게 밤, 낮 의 RGB 를 모두 학습해서 새벽이든 밤이든 계절변화든 강건한건지 사람이 자주 안돌아다니는 시간에 센서정보들을 취득해서 3D map이 이쁘게 만들어진건지 그런것들도 궁금하긴 하네요. 기업만의 전략이 있었겠다만 생각보다 쪼개서 해결해야할 부분이 많아보여서 괜찮아보이는 것 같습니다. 아 그리고 좀 다른 분야이지만 드론으로도 배달을 하는 것 같던데, UAV로 last mile problem 푸는 것들도 봤던 것 같아서 그런쪽은 아예 관심 없는건지 궁금합니다.