Abstract
개방형 작업 지시가 주어지는 비정형 환경에서 로봇이 물체를 조작하기 위해서는 세분화된 affordance를 이해하는 것이 필요하지만, 기존의 방식은 수동 annotatgion 정보나, 작업에 대하여 사전에 미리 정의된 케이스에 의존하는 한계가 있습니다. 저자들은 수동 annotation 라벨 없이, foundation 모델의 지식을 task-conditioned affordance model로 전이하기 위해 (해당 논문에서 task-conditioned affordance 모델이란, 작업을 조건으로 이용하여 그에 따른 affordance를 예측하도록 하는 것이라고 이해하시면 됩니다.) UAD(Unsupervised Affordance Distillation)라는 방법론을 제안합니다. UAD는 대규모 데이터에 <instruction, visual affordance> 쌍으로 자동 annotation을 생성하며, 시뮬레이션에서 렌더링된 객체만으로 학습했음에도 실제 로봇 환경과 다양한 인간 활동에 대한 일반화 능력을 입증하였습니다. 또한, UAD가 제공하는 affordance를 observation space로 활용하여, 10개의 데모만으로 학습한 모방 학습 정책(policy)이 unseen 객체 인스턴스와 객체 카테고리, 작업 지시의 변형까지도 효과적으로 일반화 가능함을 보였습니다.
Introduction

물체의 Affordance를 이해하는 것은 비정형 환경에서 로봇의 환경과 상호작용을 하기 위해 중요한 능력입니다. 이를 위해 로봇은 자연어로 주어진 개방형 작업 지시에 대하여 물체나 일부 영역을 넘어, 픽셀 수준의 행동 가능성을 인식해야합니다. 위의 그림으로 예를 들자면, “insert pen”을 위한 컵의 내부 영역, “lift saucepot”을 수행하기 위해 냄비의 손잡이 부분, “sweep trash”를 위한 빗자루 부분, “hang clothes”를 위한 옷걸이의 부분 등 작업을 위한 물체의 정확한 영역을 인식할 수 있어야 합니다. 이를 위해 기존 연구들은 closed-set에서 segmentation을 affordance와 그에 대한 pixel-level annotation 정보로 학습하는 방식 등으로 연구가 이루어졌으며, 최근 개방형 작업 지식에 대한 open-world 시나리오를 한 연구가 활발히 이루어지고 있습니다.
VLMs의 이미지-텍스트에 대한 이해 능력은 많은 연구를 통해 입증되었으며, 최근 해당 분야에서는 VLMs을 이용하여 affordance 정보를 인코딩하는 것을 제안하고있습니다. 그러나 VLMs의 지식을 공간적 도메인으로 효과적으로 연결하는 것인 아직 해결되지 않은 문제로 남아있습니다.(grounding에 대한 능력을 의미합니다.) 반면, self-supervised 기반의 vision 모델들은 픽셀 수준의 물체 구조를 이해하는 능력은 있으나, open-world 작업으로의 확장은 어렵기 때문에, 로봇 조작에서 task-level의 일반화 성능이 떨어지는 문제가 있습니다.
해당 논문에서는 Unsupervised Affordance Distillation(UAD) 방식을 제안하여, 수동 라벨 없이 foundation 모델의 affordance 지식을 task-conditioned affordance 모델로 전이하는 것을 목표로 합니다. UAD는 VLMs과 Large Vision Models(LVMs)의 상호보완적인 강점을 이용하여 대규모 데이터에 자동으로 <instruction, visual affordance> 쌍 annotation을 달고, 이를 이용하여 DINOv2의 가중치를 사용하여, task-conditioned decoder만을 학습하여 task-conditioned affordance 모델을 학습합니다. 이렇게 학습된 모델을 기존 벤치마크인 AGD20K에서 zero-shot으로 평가를 수행하였으며, 새로운 환경에서 unseen 물체를 포함하는 실제 로봇 데이터셋에서 일반화 성능을 입증합니다. 또한, 이러한 일반화 능력을 갖춘 UAD로 추론한 affordance 정보를 observation으로 사용하여 모방학습 policy를 학습하였으며, 제안한 프레임워크가 최소 10개의 데모만으로도 학습가능하며, unseen 환경과 객체 인스턴스, 객체 카테고리, 새로운 작업에 대한 지시로도 일반화 가능함을 입증합니다.
해당 논문의 contribution을 정리하면,
- 비지도학습 파이프라인을 제안하여 자동으로 VLMs과 LVMs를 활용하여 세분화된 affordance annotation을 생성함
- Zero-shot 방식으로도 기존 벤치마크인 AGD20K에서 기존 방법론보다 뛰어난 성능을 보임
- affordance를 observation space로 사용하여 적은 수의 데모만으로도 모방학습을 통해 policy를 구하고, 이를 기반으로 unseen 환경과 객체 인스턴스, 객체 카테고리, 새로운 작업 지시로 일반화가 가능함을 보임
Method
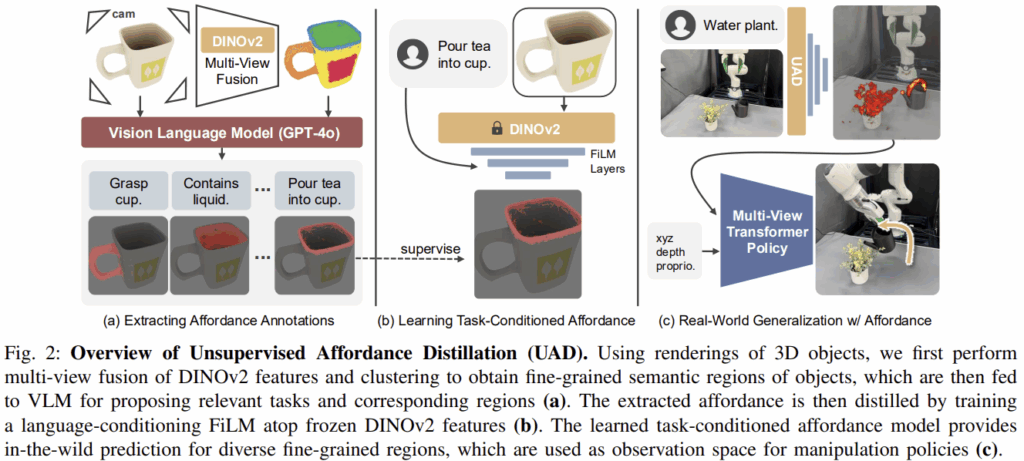
(a) 해당파트에서는 foundation model을 이용하여 어떻게 affordance anntation을 자동으로 추출할 지, (b) 자동으로 구한 annotation을 이용하여 task-conditioned affordance model을 어떻게 학습할 지, (c) 로봇 조작의 일반화를 위해 추론된 affordance정보를 observation으로 활용하여 모방학습 policies에서 어떻게 활용할 지에 대하여 다룹니다.
(a) Extracting Affordance Annotations
해당 파트는 RGB 이미지 I, 자유형식의 지시문 \mathcal{T}, 그에 대응되는 affordance map A \in [0,1]^{H⨉W}을 생성하는 것을 목표로 합니다. 또한, 2D 이미지에서의 affordance data를 모으는 것이 목표이긴 하지만, 경험적 지식과 manipulation과 open-vocabulary 3D segmentation 분야의 논문을 근거로 3D 공간상의 일관성을 유지하고자 3D 객체를 2D 이미지로 렌더링하여 affordance annotation을 생성하는 방식으로 접근하였다고 합니다.
먼저 렌더링을 위해 사용한 3D asset은 BEHAVIOR-1K데이터의 subset 물체들로, 해당 물체들이 manipulation 작업에 맞게 설정되었기 때문에 해당 데이터를 사용하였다고 합니다. (BEHAVIOR-1K 데이터는 스탠포드 대에서 수집된 로봇 조작을 위한 데이터 셋으로, 설문조사를 통해 로봇이 해주길 바라는 행동 1000개를 선정하고, 이에 대하여 엔비디아 옴니버스를 기반으로 시뮬레이션 환경에서 수집한 데이터 셋 입니다.) 전체 76개의 카테고리의 물체들에 대하여 206개의 object로 구성되며, 작업에 대한 지시는 667개 입니다. 또한, 저자들은 해당 논문이 통과한 이후에 Objaverse-XL데이터로 확장하여 10,000개 이상의 object-instruction 쌍을 연구에 추가하였다고 합니다.
비지도학습 방식으로 affordance annotation을 수집하는 과정은 위의 Fig.2의 (a)에서 대략적인 개요를 확인하실 수 있습니다. 즉, LVMs를 이용하여 각 물체에 대한 세분화된 semantic 영역을 찾고, VLM을 통해 각 객체와 관련된 작업 지시문 후보를 제안합니다. 이후 VLM을 통해 물체 영역과 작업 지시문을 연결하는 방식으로 이루어집니다.
- Fine-Grained Region Proposal
- 먼저 각 물체를 빈 장면에 위치시킨 뒤, 14개의 view로 렌더링된 RGB 이미지 I^K_{i=1}를 생성하고, 해당 view의 point cloud들을 world 좌표계를 기준으로 모아 point cloud P \in \mathbb{R}^{N⨉3}를 생성합니다.
- 이후 각 이미지에 대하여 DINOv2를 적용하여 픽셀 수준의 feature를 생성하고, 이를 3D point cloud로 투영시켜 융합된 global feature F_{global} \in \mathbb{R}^{N⨉d}를 생성합니다. (융합하는 과정을 코드로 확인해보니, 각 view에서 추출한 feature에 대응되는 depth값을 이용하여 가중합 한 것으로 보입니다.)
- 이후, texture 정보에 덜 민감하고 의미론적 영역 정보만을 얻기 위해 PCA를 적용하여 F_{reduced} \in \mathbb{R}^{N⨉3}를 구하고, 여기에 유클리디안 거리를 통해 N개의 point cloud에 대하여 M개의 영역으로 클러스터합니다. 여기서 M은 자동으로 결정되며, 각 포인트에 대한 region 라벨은 r_n \in \{1, ..., M\}이 되도록 합니다.
- Task Instruction Proposal
- 앞서 제안된 영역을 기반으로, 적절한 작업 지시를 결정하기 위해 VLMs(저자들은 GPT-4o를 이용하였다고합니다)를 활용합니다. 이를 위해, 먼저 가장 자연스러운 view(즉, 대표이미지)를 찾기 위해 각 객체의 view별 이미지를 CLIP으로 임베딩하고, 클래스 이름을 CLIP으로 임베딩하여 cosine similarity가 가장 높은 view를 선택합니다.
- 이후 앞서 구한 M개의 영역 정보를 원본 이미지에 입힌 뒤,원본 이미지와 영역에 대한 정보가 중첩된 이미지, 객체 카테고리 이름을 함께 VLM으로 입력하여 객체와 연관된 작업 지시문 \{\mathcal{T}_1, ... , \mathcal{T}_J \}을 생성합니다. 예를들어 커피 머그컵에 대해 “rim of the coffee mug – region for drinking and pouring”과 같은 지시문을 생성하게 됩니다. (아래에서 프롬프트를 확인하실 수 있습니다.)
- Region and Instruction Mapping
- 마지막으로 생성한 지시문과, 물체 영역을 연관지어주는 과정이 필요하니다. 저자들은 affordance가 이진 마스크가 아니라, 연관성이 높은 영역은 1에 가까운 값을 가지는 등 연속적인 값이어야 한다고 보앗으며, 이를 위해 VLM이 지정한 각 영역 r에 대하여 해당 포인트들의 특징을 평균내 f_{ref} \in \mathbb{R}^{d}를 구한 뒤, 이를 F_{global}와 cosine similarity를 계산하여 0~1 사이의 유사도 점수를 부여합니다.
- 이렇게 구한 0~1 사이의 점수를 각 view의 이미지로 다시 렌더링하여 각 view 별 연속적인 픽셀단위 affordance map A \in [0,1]^{H⨉W}를 구합니다.

이러한 과정을 통해, (I, \mathcal{T}, A) 형식의 데이터를 생성하게 됩니다.
(b) Learning Task-conditioned Affordance Model
그 다음은, task-conditioned affordance 모델을 학습하는 방법에 대한 설명으로, 위의 Fig 2의 (b)에 해당합니다. 저자들은 사전학습된 DINOv2의 가중치는 freeze하고, 그 위에 경량화된 language-conditioned 모듈을 추가하여 해당 모듈만을 학습하였습니다. 구체적으로, OpenAI의 API를 이용하여 지시문에 대하여 임베딩 e_{\mathcal{T}}를 구하고, DINOv2의 visual feature를 e_{\mathcal{T}}에 조건으로 제공하기 위해 FiLM 레이어를 적용합니다. FiLM 레이어는 e_{\mathcal{T}}와 픽셀 공간의 feature X \in \mathbb{R}^{H⨉W⨉C_{in}}를 입력으로 받아 출력 feature X' \in \mathbb{R}^{H⨉W⨉C_{out}}을 생성합니다. 해당 논문은 3개의 FiLm을 통해 최종적으로 출력 feature의 채널이 1이 되도록 합니다. 학습에는 binary cross-entropy loss를 이용하여 예측된 affordance map이 자동으로 생성한 annotation과 유사해지도록 합니다. 이러한 모델을 저자들은 UAD라 하였습니다.
(c) Policy Learning with Affordance as Observation Space
UAD는 로봇 조작을 위한 vision 기반의 policy 네트워크에 통합될 수 있으며, 작업 정보를 조건으로 이용하는 시각 정보 제공이 가능해집니다. 기존의 policy architecture가 task-agnostic한 visual representation을 학습한 것과 다르게, UAD는 작업에 대한 지식을 활용하여 집중해야 할 영역 정보를 제공합니다. 저자들은 활용 가능성을 검증하기 위해 RVT(v1,v2; RVT는 주어진 작업 지시에 대하여 3D manipulation을 수행하기 위한 모방학습 기반의 로봇 시스템으로, RGB-D 이미지를 기반으로 point cloud를 만들고, 주변의 여러 가상 시점에서 렌더링한 이미지를 만들어 트랜스포머가 그리퍼의 6D Pose를 예측하도록 한다고 합니다. 특히, v2에서는 10번의 데모만으로 높은 성능을 달성하였다고합니다.)의 multi-view transformer policy에 UAD를 적용하였습니다. “grasp watering can”과 같은 언어 지시가 주어졌을 때, 먼저 UAD를 통해 각 view의 affordance map을 예측합니다. 이후, RVT의 방식을 따라서 각 view에 대해 depth 정보와 포인트들의 world 좌표계상의 xyz 좌표, global proprioception vector를 추가합니다. policy network는 7차원의 action 정보를 출력하며 이는 6-DoF의 end-effector pose와 그리퍼 행동에 대한 이진 값으로 이루어집니다. 모방학습을 이용하여 policy를 학습하였으며, affordance 모델 자체는 policy 학습 과정에는 freeze 되어있으며, 소수의 데모로도 효과적으로 학습이 가능하고 다양한 환경에 일반화가 가능함을 실험을 통해 입증하였습니다.
Experiments
저자들은 실험을 통해 다음 3가지에 대한 검증하고자 하였습니다.
- 3D 물체를 렌더링한 이미지만으로 학습한 UAD가 실제 로봇 데이터에서 affordance 예측에 얼마나 잘 일반화되었는지? 기존 벤치마크와 비교한 결과는 어떤지?
- UAD를 observation 공간으로 이용하였을 때, visual representation으로써 어떤 일반화 성질을 가지는지?
- UAD기반의 policy가 실제 환경에서 잘 작동하는지?
1) Task-Conditioned Affordance Prediction
해당 실험결과는 UAD의 affordance 예측 성능을 확인하고자 하였으며, UAD는 시뮬레이터로 렌더링된 3D object만을 이용하였다는 점을 어필합니다.
<UAD의 일반화 성능 검증>
먼저, 저자들은 UAD의 일반화 성능 검증을 위해 (1) 학습 데이터, (2) 새로운 객체 인스턴스, (3) 새로운 객체 카테고리, (4) 새로운 지시문으로 구성을 바꾸어 평가 데이터를 준비하였으며, 평가 데이터는 Amazon MTurk를 이용하여 수동으로 라벨을 생성한 것으로 보입니다. 평가지표는 Area Under ROC Curve (AUC)를 이용하여 예측된 affordance map과 GT affordance map 사이의 오차를 평가하였습니다. 실험은100개의 <instruction, visual affordance>쌍으로 평가하였으며, 4가지 세팅에서 모두 AUC 점수 0.92 이상을 기록하여 강력한 일반화 성능을 보였다고 합니다. (정확하게 각 수치가 어떤 AUC를 얻었는 지 보여야할 것 같은데,,, 단순히 모두 0.92 이상 달성했다는 말로 끝내버렸습니다… appendix에도 논문에도 프로젝트 페이지에도 없네요..)
<UAD의 실제 로봇 장면으로 일반화 가능성 검증>
저자들은 UAD가 실제 로봇 장면에도 일반화가 가능한지를 검증하고자 하였습니다.

저자들은 실제 로봇 조작 데이터인 DROID에서 affordance를 예측할 수 있는 지 평가하였으며, 이에 대한 결과를 위의 Fig 4를 통해 확인하실 수 있습니다. 세분화된 작업 지시가 입력으로 들어갔으며, 각 에피소드에서 카메라로부터 첫번째 프레임을 사용하고, 대상 객체가 명확하지 않은 이미지는 제외하였다고 합니다.
실험결과 UAD는 DINOv2 백본을 통해 실제 환경, 다중 객체, 복잡한 장면에서도 일반화가 가능함을 보였습니다. 특히, CLIP보다 더 세밀하고 강인하게 특징을 포착하며, 이진 마스크 형태인 OpenSeeD와 다르게 연속적인 확률을 예측할 수 있다는 것을 통해, 행동에 대한 연관도를 표현할 수 있음을 어필합니다.
<기존 방법론과의 AGD20K에서의 비교>
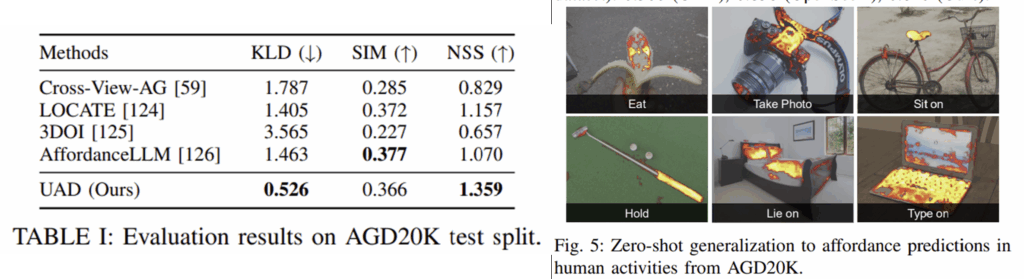
저자들은 Affordance에서 많이 활용되는 기존의 벤치마크인 AGD20K에서성능을 비교하였습니다. 위의 Table 1과 Fig. 5가 이에 대한 결과로, 자유 지시어를 대상으로하는 UAD도 평가를 위해 "region to <action> the <object>"의 형식으로 지시문을 설정하였다고 합니다. 실험 결과, 대부분의 지표에서 상당히 좋은 성능을 달성하였습니다.
참고로, 저자들이 리포팅한 기존 연구들은 unseen에 대한 성능으로, 저자들과 마찬가지로 새로운 affordance-object 셋에 대한 평가를 수행한 결과입니다. 성능은 상당히 좋은 성능을 보였으며, seen 케이스보다도 좋은 성능을 보이기도 하였습니다. 그러나, 저자들이 UAD를 학습할 때 자동으로 생성한 지시문에 해당 affordance 정보들이 정말 포함되지 않았는지는 검증이 되지 않아서, 공정한 비교가 아닌 것 같습니다.
전반적으로 해당 파트에 대한 실험 결과가 신뢰성을.. 얻기 조금 어려운 상태인 것 같지만, 이후에 policy를 학습해서 시뮬레이션 환경과 실제 환경에서 로봇을 조작한 게 인정을 받은 것 같습니다..
2) Policy Learning in Simulation
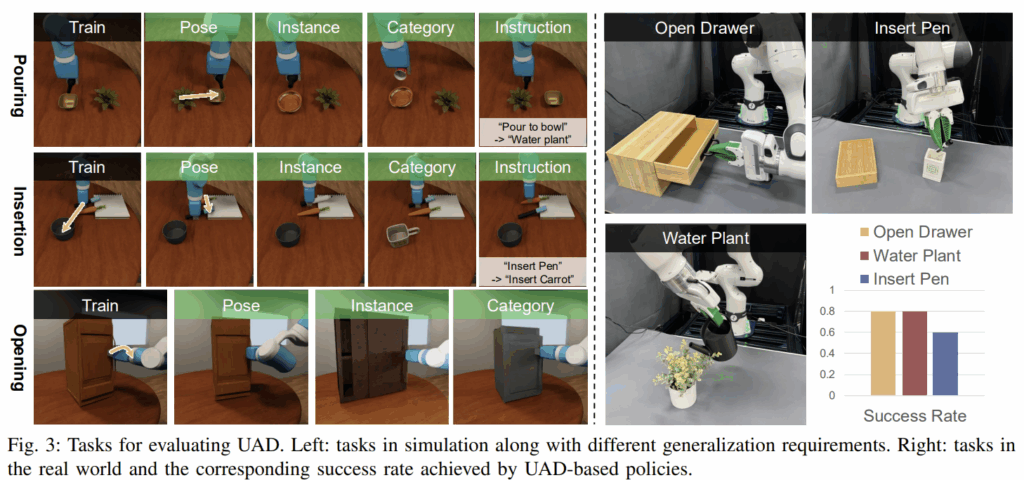
다음은 UAD 결과를 observation space로 사용하여 모방학습을 통해 policy를 학습하고 일반화 성능을 검증한 결과입니다. 실험은 사실적인 렌더링과 다양한 물체를 포함하는 OmniGibson 환경에서 수행하였으며, Pouring/Insertion/Opening 작업에 대하여 일반화 능력을 평가하였습니다. 각 작업은 10개의 데모를 이용하였으며, 마찬가지로 (1) 새로운 객체의 pose (2) 새로운 객체 인스턴스 (3) 새로운 객체 카테고리 (4) 새로운 작업 지시문 4가지 세팅에 대한 변화를 주어 일반화가 가능함을 보였습니다. 위의 Fig. 3의 초록색으로 pose/instance/category/instruction이라 쓰여있는 것이 이러한 변형이 일어난 경우를 의미하며, 자세한 결과는 프로젝트 페이지의 Generalization Properties for Policy Learning 데모영상을 참고하시면 좋을 것 같습니다.
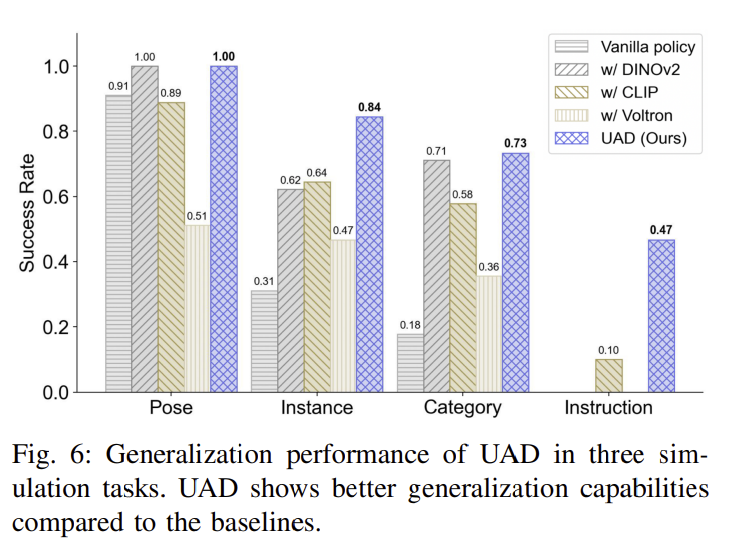
또한, 저자들은 RGB 이미지를 이용하는 vanilla policy와 DINOv2, CLIP, Voltron과 같은 사전학습된 visual representation을 이용하는 방식들과 추가로 비료를 수행하였습니다. Table 4는 그 결과를 시각화 한 것으로, 3가지 작업에 대한 평균 success rate을 나타냅니다. 실험 결과를 통해 저자들은 UAD가 객체 외형이 변하여도 강인하게 작동함을 확인하였으며( insertion을 검은 마커로 학습하였으나, 흰색 마커도 성공적으로 조작함), 정밀한 시각 인지가 필요한 작업에서도 잘 작동함을 확인하였습니다(서랍의 얇은 손잡이에 대한 grasp point 예측이 opening 작업을 위한 다른 방법론들보다 우수한 성능을 보였다고합니다). 마지막으로, 자연어 지시문이 달라질 경우 성능이 크게 저하되는 기존 방법론과 다르게, UAD는 상호작용 대상이 달라지더라도 상대적으로 잘 작동하는 결과를 확인하였으며, 이를 통해 자연어를 통한 유연한 조작 명령 처리가 가능함을 보였습니다.
3) Policy Learning in the Real World
마지막으로 저자들은 실제 환경에서 UAD 기반의 policy를 평가하였습니다. 동일하게 Pouring/Insertion/Opening 작업에 대하여 평가를 수행하였으며, Franka Emika Panda 로봇과 2대의 RGB-D 카메라로 table-top 환경을 구성하였으며, 10개의 사람 데모를 이용하여 학습을 수행하였다고 합니다. Fig. 3의 오른쪽 3개 이미지와 그래프가 실제 환경에서의 결과를 나타내는 것이며, 실제 영상은 마찬가지로 프로젝트 페이지의 데모 영상을 참고해주세요. 평균 73%의 작업 성공률을 달성하였으며, 실제 환경에서 조작이 가능함을 보였습니다.
AGD20K 성능이 너무 뛰어난 결과를 리포팅하였는데,우선 다른 도메인의 데이터지만 다양한 데이터로 학습한 것이 좋은 결과로 이어진 것 같습니다. 방법론 자체는 기존의 다른 연구들처럼 자동으로 학습용 데이터 만들어내고, 그 데이터를 이용하여 affordance를 학습하는 방식으로, 크게 다르지는 않은 것 같습니다. 그래도 도메인이 다른 경우에도(단일 물체에 대한 학습-다중 물체가 존재하는 장면에서 평가) 유의미한 결과를 보였다는 것이 가치가 있는 것 같습니다. 또한, 논문에서 실험 결과 리포팅과 관련하여 아쉬운 점이 있기는 하지만, 실제 데모를 통해 잘 작동하는 결과를 보여주었다는 점에서 신뢰도를 얻을 수 있지 않았나 합니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
예시 중에 insert pen이 몇번 등장하는데, 컵의 내부 영역을 affordance로 정의하는 것이 맞는가? 라는 생각이 듭니다. 사실 자동 annotation 생성 시부터 문제가 되는 현상 같은데, 한 물체에 대한 object-centric한 이미지를 구성하여 annotation을 만들어가다보니, 물체(cup)와 물체(pen)가 상호작용하는 과정을 이해하지 못한다는 한계가 있는 것 같습니다.
결론적으로 저는 pen 손잡이 -> 컵의 내부 영역 으로 물체의 상호작용 영역과 그것들 사이에 대한 trajectory로 affordance가 정의되는 방향으로 발전되어야 할 것 같은데, 해당 상황에 대한 저자들의 고찰이나 승현님의 의견이 궁금합니다.
질문 감사합니다.
우선 제 개인적인 생각으로는, insert pen일 경우 cup에 대한 affordance 영역은 컵의 내부가 맞는 것 같습니다. 물론, 상호작용의 대상인 pen에는 활성화가 되어있지 않은 점과 관련하여서는 저도 의문이 생기는 부분이긴 합니다. 프로젝트 페이지에 Insertion: pick pen and insert into pen holder라 되어있는 점을 참고할 때, Insert pen은 펜 잡고 넣는 과정이라 저렇게 컵 내부만 표현이 된 것 같습니다.
이러한 관점에서 재찬님이 이야기하신 것 처럼 물체 중심적인 이미지로 인해 다른 물체와의 상호작용을 이해하지 못하는 점을 나눠서 풀지 않았을까 합니다.
오랜만에 승현님 리뷰를 Best Paper Finalist 이라는 제목에 이끌려 읽게되었네요 ㅎ
읽다가 궁금한 점들 몇 가지 질문 남겨두겠습니다.
instruction과 region 간 mapping을 cosine similarity 기반으로 수행하는거 같은데, multi-region이 동일 instruction에 해당될 경우에는 어떻게 처리하나요? 한 instruction에 대해 여러 region이 대응되는 것이 가능한가요?
그리고 생성된 instruction이 실제로 해당 region의 기능적 의미를 잘 반영하는지를 검증 과정은 따로 없는 것으로 이해했는데.. noisy하거나 모호한 instruction이 학습에 악영향을 주진 않았나요?
마지막으로 최근 로보틱스팀이 리뷰해주신 논문에서는 백본으로 DINOv2를 쓰는 경우가 많았던 것 같습니다. (이거 GroundingDINOv2 맞죠 ㅎ?) 해당 백본이 어떤 점에서 유리하길래 많이 사용하는지 궁금합니다. 분명 처음에 해당 백본을 적용한 논문이 있었을테고, 거기서 어떤 부분에서 기존방법론과 차별점이 있었길래 계속 쓰이는지 궁금하네요
질문 감사합니다.
우선, 제가 이해하기로는 Region and Instruction Mapping 과정을 통해 instruction에 대응되는 단일 region을 찾는 것이었습니다. 만일 multi-region이 할당된다고 하더라도, 할당된 영역을 다 통합하여 하나의 영역으로 접근할 것 같습니다.
좋은 지적인 것 같습니다. 저도 데이터를 생성한 뒤 이를 검증하는 과정에 대한 언급이 없어 아쉽긴 합니다. 다만 노이지하더라도 많은 데이터를 생성할 수 있다는 장점 덕분에 좋은 성능을 달성하지 않았을까 합니다.
groundingDINOv2가 아니라 메타에서 공개한 dinov2를 사용한다고 합니다. 우선 dinov2가 이미지에 대한 이해능력이 좋아 사용한 것이라 생각합니다. 제가 이전에 리뷰했던 논문인 [CVPR 2024]One-Shot Open Affordance Learning with Foundation Models의 경우, CLIP과 지도학습 기반의 모델 DeiT3와 DINOv2의 feature에 대하여 시각화하여 결과를 확인하였는데, DINOv2가 물체 영역에 대한 구분력이 뛰어나다는 실험은 있었습니다.
좋은 논문 리뷰 감사합니다.
Q1. AGD20K에서 신뢰하기 힘들다고 말씀하셨는데… 어떤 부분인지 궁금합니다.
Q2. 모방 학습에서의 강인성 실험 파트에서 새로운 지시문에도 강인하다고 하는데… 이게 어떻게 가능한지 그림이 안그려지네요. 어느 정도 제약이 있는 변형을 주었을 거라고 생각이 듭니다. 어느 수준인지 알려주시면 감사드리겠습니다.
질문 감사합니다.
A1. 먼저 AGD20K에 대한 성능의 신뢰성에 대해서는, 저자들이 세팅에 대한 명확한 설명이 없기 때문입니다. 우선 함께 리포팅된 기존 방법론의 성능은 AGD20K의 unseen set에 대한 성능으로, unseen set은 학습 및 평가에 affordance-object 쌍이 다르게 구성되어있습니다.(예를 들어, 학습에 open-book/open-bottle이 있으면 평가에는 open-refrigerator로 수행하는 것 입니다.) 해당 방법론은 아예 다른 도메인의 데이터를 활용하였다고 볼 수 있으나, 학습 데이터를 자동으로 생성하는 과정에 affordance-object 쌍이 포함 될 수 있습니다. 이에 대한 자세한 설명이 없어 의문이 생긴 것 입니다. 물론 기존의 seen과 성능을 비교해도 좋은 성능에 속하기는 합니다.
A2. 해당 논문에 변형 정도를 명시하지는 않았습니다. 그러나 논문과 데모 사이트에서 확인하기로는 “insert pen → insert carrot”뿐만 아니라 “pour beer → water plant”라는 예시가 있어서, 목적한 행동 자체는 동일하지만 이에 대한 행동 표현과 물체는 다양하게 확장 가능하도록 한 것 같습니다.