안녕하세요 이번주 리뷰는 human demonstration 영상과 생성형 모델을 활용한 효율적인 모방학습 데이터셋을 취득하는 방법에 관한 논문입니다. 모방학습이 로봇을 조작하는 방법의 확실한 트렌드로 자리잡고 있지만 모방학습용 데이터 취득에 대해서는 여전히 다양한 논문들이 다양한 방법들을 들고 나오고 있습니다. 저는 시뮬레이션을 활용한 합성 데이터 취득에 관심이 있고, 또 다양한 시행착오 후 현재는 생성형 모델을 활용한 asset을 통해 시뮬레이션 환경을 구성해 데이터를 취득하는 것에 관심이 있습니다. 다만 생성형 모델로 만든 mesh를 어떻게 현실적으로 정렬할 것인지가 문제였는데, 해당 논문도 하나의 human demonstration 영상을 통해 flow matching policy를 위한 데이터셋을 무한으로 생성할 수 있다는 점을 어필하는 논문이라 해결책이 있을것 같아 읽어보게 되었습니다.
Introduction
전통적인 모방학습에서는 로봇 조작기술을 학습하기 위해 teleoperation이나 kinesthetic teaching(저도 처음 접한 단어인데 로봇의 joint를 직접 움직여 가며 데이터를 취득하는 과정이라고 합니다 ㄷㄷ)을 통해 로봇 자체를 시연하면서 데이터를 수집합니다. 로봇을 직접 조작하며 데이터를 수집하기 때문에 observation과 action이 잘 정렬된 시연 데이터를 수집할 수 있게 됩니다. 그러나 이러한 로봇 시연 데이터 수집 과정은 전문적인 기술자와 장비가 필요하며, 시간과 비용이 많이 소요됩니다. 특히 kinesthetic teaching의 경우, 사람이 직접 로봇을 잡고 조작해야 하기 때문에 카메라를 가리거나 시야를 차단하는 문제도 발생할 수 있다고 합니다. 사실 논문에 적혀있긴 했지만 대부분 teleoperation을 한다고 생각하지만, 그럼에도 여전히 엄청난 시간과 비용이 필요한건 사실입니다.
저자는 이를 해결할 수 있는 방법으로 human demonstraion을 주장합니다. 다른 human demonstraion 활용 논문들이 주장하듯 훨씬 더 간편하며, 인터넷에 이미 풍부한 데이터가 존재하기 때문에 이를 활용해야 한다고 주장합니다. 하지만 여기엔 당연하지만 큰 문제가 있습니다. embodiment gap이 존재해 로봇과 사람의 관절 구조, 관찰 방식, 조작 능력의 차이를 메꿔주어야 합니다. 예를들어 사람은 전자레인지 문 여는것이 너무 자연스럽고 이를 수행하기 쉬운 관절 구조를 가지고 있지만, 6자유도를 가진 UR5e로 teleoperation을 진행했을 때 전자레인지 문을 여는것은 굉장히 어려운 일이었습니다. (거의 성공한 적이 없습니다.)
최근에는 객체 중심의 대응 관계를 탐색하여 인간 시연을 로봇 시뮬레이션에 전이하는 방식도 등장했습니다. Object centric한 접근을 통해 embodiment gap을 해결하는 노력들을 기반으로 저자들도 인간 시연의 수집 용이성과 로봇 시연의 구조적 일치성을 모두 살리기 위해, Real2Gen이라는 프레임워크를 제안했습니다. 기존 Real2Sim 접근법과 달리, 환경을 스캔하거나 3D 모델을 구축할 필요 없이, 인간 시연에 등장한 객체의 외형만으로 3D generative 모델을 활용해 시뮬레이션 가능한 메시를 생성한다고 합니다. 이후 아래 그림과 같이 메시들을 다양한 포즈로 배치하고, scripted expert agent가 자동으로 grasping 및 manipulation task를 시뮬레이션하여 데이터를 생성해 flow matching policy를 학습한다고 합니다.
Real2Gen은 기존 SOTA인 DITTO 대비 평균 26.6% 향상된 성공률을 기록하고 일반화 능력도 향상시켰다고 합니다. 찾아보니 DITTO도 동일 저자가 24년에 개제한 논문인데 trajectory transform을 통한 imitation learning 데이터 수집하는 방법론입니다. 여기에 시뮬레이션을 통한 다양성을 부여한게 아닌가 싶습니다. 뿐만 아니라 3D mesh 생성의 효율성에 대한 체계적인 평가를 진행한 점도 contribution이라고 합니다.
Methods
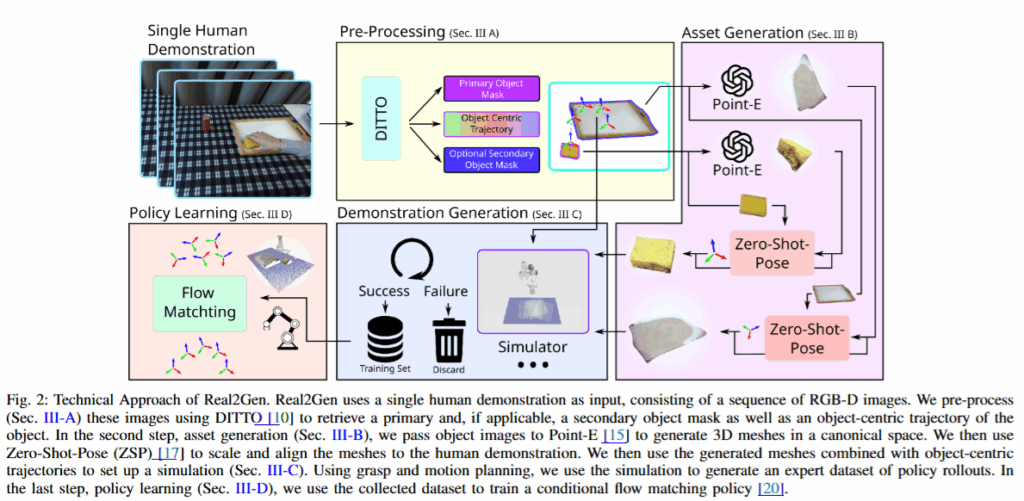
전체적인 파이프라인은 RGB-D 영상 시퀀스에서의 물체 궤적 추출, 영상속 asset들의 asset generation, zero-shot 포즈 추정, 이를 SAPIEN 시뮬레이터를 활용한 시뮬레이션에 적용 후 데이터 생성 순입니다. 더 자세히 살펴보도록 하겠습니다.
A. Pre-Processing Human Demonstration
먼저 human demonstration이 담긴 T개의 RGB-D 이미지의 시퀀스를 받아 DITTO 기반의 추출기를 활용해 객체의 trajectory를 얻습니다. DITTO를 자세히 읽어보진 않았지만 물체를 segment 한 후에 지속적으로 re-detection, relative pose estimation을 통해 추적하는 것으로 이해했습니다. 이 때 조작 대상 객체를 p(primary)로 지정하고 목표객체를 s(secondary)로 지정해 첫 번째 프레임을 통해 각각의 segment mask m_p, m_s를 구하고 이어서 p의 궤적 J_p를 구합니다. 이때의 segment 마스크는 asset generation을 위해서도 사용됩니다.
B. Asset Generation
이후 Pre-Processing 단계에서 얻은 primary 객체와 secondary 객체에 대한 segment mask를 활용해 분할된 물체를 통해 3D generative foundation model을 통해 asset generation을 수행합니다. 저자의 경우 Point-E와 marching cube를 결합한 모델을 사용했다고 합니다. Point-E를 통해 pointcloud들을 생성한 후 marching cube 알고리즘으로 mesh를 만들어내서 사용합니다. 저자는 이 방법이 구현이 쉽고 실용적이어서 채택했다고 합니다. 저자가 다른 image to 3d나 text to 3d 모델도 있긴 하지만 metric을 맞추기 까다로워서 그냥 이런식으로 진행했다고 합니다. 기존에는 VLM을 사용해 mesh의 타당성을 확인하면서 스케일을 추정하는 방식도 제안됐었지만, 더 직접적인 접근이 유리하다고 합니다.
이렇게 생성된 mesh는 DINO 기반의 feature matcher인 Zero Shot Pose를 통해 정렬을 진행한다고 합니다. 생성된 mesh는 영상 속의 객체와 동일한 인스턴스가 아니기 때문에 foundation pose 같은 방식의 6D pose estimation 모델들을 활용하는 것은 불가능했다고 합니다. 그래서 DINO를 기반으로 카테고리 수준에서 pose estimation이 가능한 Zero Shot Pose를 사용한 것 같습니다. 생성된 mesh에 대해 피보나치 샘플링을 통해 80개의 RGB-D 뷰를 생성해 각 이미지들로부터 descriptor를 추출하고 Point-E의 input으로 사용된 이미지와 유사도를 기반으로 top 30개의 descriptor 쌍을 correspondence로 선택합니다. 이후 이를 바탕으로 7-DoF affine 변환을 추정해 메시를 demonstration 영상과 정렬한다고 합니다. 이렇게 정렬된 mesh를 만드는데는 인간의 개입이 전혀 없고 그대로 시뮬레이션에 투입되어 사용이 가능하다고 합니다.
C. Demonstration Generation
Asset generation이 완료된 후 SAPIEN 시뮬레이터에서 사전에 만들어둔 테이블과 그 위에 구성된 Franka Panda로봇, 손목에 부착된 RGB-D 카메라를 통해 demonstration을 생성합니다. 조작 대상 객체들을 테이블 위에 배치한 후 다양하게 회전시켜 다양성을 확보한다고 합니다. 이후 motion planning을 사용해 grasping을 실시한 후 추출된 trajectory대로 이동시키며 데이터를 확보합니다. Motion planner로는 MPlib를 사용한다고 합니다. ROS와 디커플링된 파이썬 기반의 모션 플래닝 라이브러리인데, lightweight + 쉬운 사용법이 강점이라고 합니다. 시뮬레이션 상의 demonstration이 종료된 후에는 GraspNet의 pose error metric을 통해 조작 대상 객체의 실제 위치와 기대 위치간의 오차를 활용해 성공, 실패 여부를 확인 후 성공한 demonstration 데이터만 정책 학습에 사용한다고 합니다. 다른 시뮬레이션을 활용한 데이터생성 연구 코드를 봤을때는 Isaac Lab을 활용하면 자체 기능을 활용할 수 있을 것 같습니다.
D. Policy Learning
Demonstration 데이터를 수집한 후에는 PointFlowMatch를 기반으로 한 imitation learning을 학습시킨다고 합니다. 현재의 로봇 observation을 condition으로 예측된 action gaussian distribution이 실제 demonstration의 동작 분포를 target distribution으로 flow matching 하는 구조라고 합니다. (사실 이 말을 좀 더 자세히 이해하기 위해서는 Flow matching에 대한 이해가 좀 더 필요할 것 같습니다 하하,,)
Experiments
실험은 DITTO 방법론을 베이스라인으로 작업성공률을 지표로 정량적인 평가를 진행하고, 추가로 mesh generation에 대한 평가도 진행했습니다.
정량적인 평가의 경우 DITTO에서 정의한 sponge on tray, coke on tray, paperroll upright 세개의 task를 기준으로 평가했습니다. 각각 스펀지와 콜라캔을 쟁반에 올리는 pick and place task와 넘어져있는 키친타올을 세우는 task입니다. Task 별로 하나의 human demontration을 통해 메시와 800개의 demonstration을 생성해 학습에 활요했다고 합니다. 이 때 DITTO는 같은 객체를 추적하는 전제로 작성됐기 때문에 LoFTR방식으로 설계돼서 이를 ZSP로 Real2Gen과 동일하게 변경해 실험을 진해했다고 합니다.
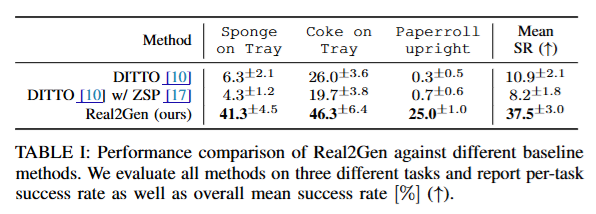
전반적으로는 Real2Gen이 훨씬 높은 작업 성공률을 보였고, 저자들이 놀라웠던 점은 DITTO에 ZSP를 적용했을 때 오히려 성공률이 떨어지는 점이었다고 합니다. 작업 성공률과 별개로 시뮬레이션 상에서 grasping과 motion planning의 성공 비율이 생각보다 적었다고 합니다. 따로 결과를 보여주지는 않아서 어느정도로 실패하는지는 코드를 돌려봐야 알 것 같습니다.
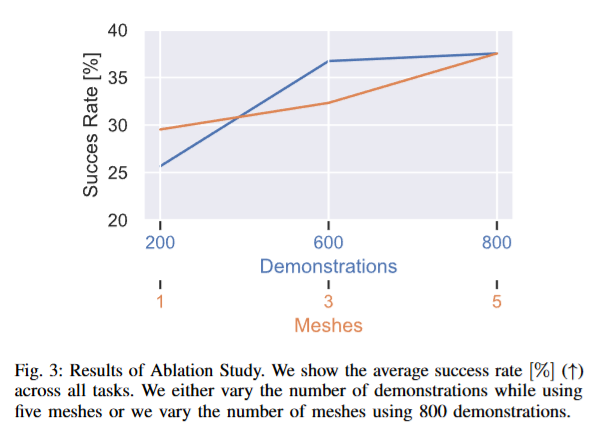
Ablation의 경우 800개의 고정된 demonstration을 각각 1,3,5개의 서로 다른 인스턴스로 구성했을 때와 5개의 서로 다른 인스턴스를 사용해 200, 600, 800개의 demonstration으로 학습을 진행한 경우의 성공률 입니다. 당연한 결과가 보여진 것 같습니다.
Mesh Generation의 경우 자동 생성, 정렬 파이프라인의 효율성과 품질을 평가하기 위해 기존 Objaverse 데이터셋과 비교했다고 합니다. Task에 사용된 sponge, can, tray, paperroll에 대해 100개의 mesh를 objaverse에서 선택해 Point-E 방식으로 생성한 Real2Gen의 asset과 비교했다고 합니다. 모든 메시들에 대해 ZSP기반의 정렬을 수행해서 사용했다고 합니다.
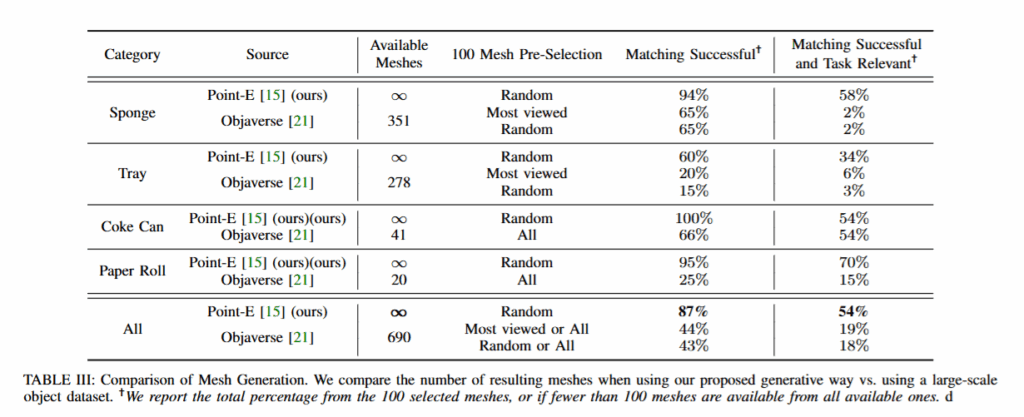
Available Mesh 수를 무한대라고 비교하는건,, 흠,,, 이게 맞나 싶습니다. Task Relevant의 경우에는 객체가 해당 task를 수행하는데 적합한지, grasping이 가능한 형태인지를 만족하면 relevant 하다고 평가하고, matching successful의 경우 ZSP 가능 여부입니다. 이 두가지를 통해 generated 된 mesh를 평가했습니다. 이는 사람이 수작업으로 판단했다고 합니다. 저자는 generative model을 사용하는 만큼 task relevant인지를 평가하는 것은 매우 중요하다고 합니다.
Conclusion
저자는 향후 연구 방향으로 articulated object에 대한 asset generation을 제시했습니다. 현재 대부분의 연구가 그렇듯 생성형 모델을 활용하는 real to sim에서는 articulated object에 대한 연구가 필요한 것 같습니다. Metric이 없는 Image to 3D의 output mesh를 어떻게 처리하는지가 관심사였지만 직접적인 해법을 찾지 못해 좀 아쉽지만 depth를 활용했기 때문에 2D 매칭을 3D로 projection할 수 있었던 것 만큼 적극적으로 활용하는 방법으로 계속 생각해야 하나..? 싶은 생각을 해볼 수 있었습니다.
영규님 좋은 리뷰 감사합니다.
먼저, 조작 대상 객체p와 목표 객체s가 어떻게 다른지 설명해주실 수 있을까요? p로 s를 조작하는건가요?
또한, 실험 결과는 시뮬레이터 환경에서 실험하는 것 인가요?
마지막으로, 영상에 등장하는 객체에 대하여 3D generative 모델을 사용하여 mesh를 생성한다고 하셨는데, 여기서 scale 정보를 고려할 수 있도록 depth 정보와 Point-E를 사용한 것으로 이해하였습니다. 그렇다면, 영규님도 scale 정보를 해결하기위해 해당 방법론을 적용하실 계획이신 지 궁금합니다.
안녕하세요 승현님 댓글 감사합니다.
Scene에 구성된 두 개의 mesh 중 조작 대상인 Primary한 객체가 p입니다. Secondary같은 경우는 두 개의 mesh중 조작 대상이 아닌 goal지점으로 생각하시면 될 것 같습니다. 스펀지(p)를 쟁반(s)에 올려라 식입니다.
실험은 시뮬레이터 환경에서 실행되어 수집한 데이터로 Real world에서 평가했습니다.
해당 논문이 제시한 방법은 metric이 없는 기존의 3d generative model의 mesh를 사용하지 않기 위해 Depth를 활용한 pointcloud를 생성하는 모델을 사용하고 mesh는 marching cube 알고리즘을 사용했습니다. 저는 생성형 모델을 통해 mesh를 받고싶어서 해당 방법을 그대로 따라가서는 근본적인 문제를 해결할 수는 없다고 생각하지만, metric한 scale을 정할 기준으로는 사용할 수 있을 것 같습니다!!
좋은 논문 리뷰 감사합니다.
가장 관심 가지고 있는 부분에 대해서 풀어진 논문이라 흥미롭게 읽은 것 같습니다.
간단한 질문 남기고 가겠습니다.
Q1. Demonstration Generation 파트 부분이 제일 관심이 있던 파트인데요. 읽어보니깐 pick & place 정도만 적용 가능한 것 같더라구요. 제시된 도구인 GraspNet, motion planner (MPlib)로는 pick & place도 쟁반과 같이 place의 위치가 바닥면의 수직인 케이스만 가능해보이고… 맞나요?
Q2. 맞다면 Paperroll upright는 어떻게 하는지 그림이 안그려집니다. 설명 부탁드립니다.
안녕하세요 태주님 댓글 감사합니다.
A1. 맞습니다. 논문에도 GraspNet을 활용해 grasping pose들을 메시별로 사전정의 해둔 뒤 잡고나서는 object centric trajectory대로 이동만 하는 것이라, secondary object가 있는 경우 (한 Object 위에 다른 object를 place 하는 경우) place의 위치는 물체의 center에 수직 방향으로 접근한 후 place 하는 정도로 제한된다고 적혀있습니다.
A2. 그래서 Paperroll upright의 경우에도 논문에는 별다른 얘기가 없지만 정의된 Grasping대로 잡은 후에 object centric trajectory대로 움직이기만 하는 (세우려는 의지는 없는?) 식으로 움직인 결과가 우연히 성공하는 그림이 아닐까? 싶었습니다. 실제로 그래서 성공률도 더 낮은게 아닌가 생각하고 있습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
읽으면서 간단한 궁금증이 생겨서 질문 남기겠습니다!
human demonstration을 통해서 sim 환경울 구성하는 과정에서 T개의 RGB-D sequence image를 받아 trajectory를 생성한다고 이해를 했습니다. 이 과정에서 T의 갯수나, 프레임 단위에 따라서 성능이 달라질 것 같은데 그거와 관련된 평가가 없는지 궁금합니다.
감사합니다!