안녕하세요 5번째 X-review 입니다. 오늘은 지난주에 이어서 Zero-shot 6D pose estimation에 대해 작성해보려합니다.
ECCV2024에 기재된 논문으로 geometric 정보와 vison정보를 모두 foundation model을 통해서 학습없이 6D를 추정하는 논문입니다.
그럼 바로 리뷰 시작하도록 하겠습니다.
Abstract
6D pose estimation 분야에서 늘상 어려운 문제는 훈련 중에 보지 못한 새로운 객체의 6D 포즈를 추정하는 것입니다. 기존의 Zero-shot이라고 불려왔더 모델들은 대규모 rendering dataset으로 추가적으로 지도학습을 하면서 이 문제들을 해결하게 됩니다. 하지만 이런 방법들은 렌더링된 데이터의 품질과 다양성에 성능이 좌우됩니다. 또한 unseen 객체에 대한 일반화 성능이 매우 제한됩니다. 이를 해결하기위해 최근 foundation model들의 일반화 능력을 활용하면서 6D를 예측하는 연구가 이어져 왔습니다.
하지만 지금까지 6D분야에서는 주로 foundation 모델을 사용할 때, vision foundtation model의 능력만을 사용하여 6D를 예측하는 연구가 이어져왔습니다 . 하지만 이 논문은 vision foundation model의 표현력과 더불어서 geometric foundation model의 일반화 능력도 함께 사용하면서 최초로 시각 정보와 3D 정보를 동시에 반영한 모델입니다. 그럼 바로 introduction에서 설명드리겠습니다.
introduciton
보통 앞에있는 컵이나 그것을 짚고 물을 따라 먹을때 저희 사람의 경우 잠재의식 덕분에 가능합니다. 이것을 vision 분야에서는 object 6D pose estimaion 문제로 형식화 합니다 이는 scene내에서 객체의 rotation 과 translation을 통해서 정확히 어디에 있는지를 파악하는 것입니다. 이러한 6D pose는 로봇이나 많은 응용분야에 필수적입니다. 6D pose에서 요즘은 크게 두가지로 나눌 수 있습니다. CAD 모델을 사용하는 model-based 또는 여러 사진들의 집합(멀티뷰) 또는 비디오를 input으로 넣어 예측 하는 model-free기반이 있습니다. 또한 그중에서도 instance-level, category-level, Zero-shto method로 나뉘게 됩니다. instance-level은 학습된 특정물체에 대해서만 예측이 가능하며 정밀도는 좋지만 특정 물체에 대해서만 학습하게되므로 일반화 능력이 저하됩니다. 그래서 category-level로 발전을 하게되었고 category level에서의 unseen object에 대한 능력이 저하되면서 foundation model을 통한 Zero-shot method가 현재 많은 연구가 진행되어지고 있습니다. 본 논문 또한 model-based 의 Zero-shot method라고 보시면 될 것 같습니다.
논문의 저자는 논문 속에서 이런 말을 합니다 “Do we really need task-specific training at the time of foundation models?” 파운데이션 모델의 시대에 task에 특화된 학습이 전혀 필요없다고 강하게 얘기를 하면서 foundation의 일반화 능력과 학습을 따로하지 않는다는 점을 강하게 어필하면서 저자의 방법론을 제안합니다

저자가 사용한 foundation 모델은 총 2가지입니다. DINOv2 와 GeDi 입니다. DINOv2같은 경우 2023년 Meta에서 발표한 논문으로 약 142M데이터로 self-surpervised learing 기법으로 현재는 많은 Downstream Task에 활용중입니다. 하지만 이러한 Vision Transformer 기반의 2D foundation model이 2D 의 feature를 3D 포인트 클라우드로 끌어올려서 6D pose 추정하는 것은 이 논문이 최초입니다. 기존에 CLIP 이 point cloud understanding Task에서는 사용된적은 있지만 6D pose까지 활용한 방법은 없다고 합니다.
또한 저자는 GeDi를 함께 활용합니다. GeDi는 3D point cloud registration을 위한 geometric foundation model로 patch-level의 point descriptor를 생성하기 위해 학습된 모델입니다. 위 모델은 국소적인 부분을 LRF(local refeence Frame)기준으로 정준화를 하고 pointnet++ 기반 네트워크를 통해서 회전과 이동에 대한 불변성을 갖추고 3D descriptor를 추출하게됩니다. 말이 조금 어렵게 설명을 했는데 이해가 어려우신 분들은 기존 고전적인 SIFT 방식에서 keypoint 방향을 맞춰줄때 도미니언트 방향으로 정렬해주는데 그것을 3D에서 맞춰준다고 보시면 될것 같습니다. 이렇게 정렬을 하고나서 pointNET++통해서 descriptor를 생성하게 됩니다 보통은 이런 모델들은 유사한 유형의 포인트 클라우드간의 정합에 설계되었지만 저자는 이러한 종류의 descriptor를 6D에 성공적으로 적용하였습니다.
그리하여 입력으로 3D 모델을 넣어 DINOv2를 통해 3D 모델에 대한 2D 시각적인 특징을, geometric 의 특징을 GeDI로 입력을 넣어줍니다. 그 후에는 특징들을 합쳐서 RANSAC을 이용하여 3D 매칭을 뽑아내고 R,t를 추정하게됩니다.
본 논문의 maincontribution은 아래와 같습니다
- unseen 객체에 대한 6D pose estimation 에서 geometric foundation model 과 vision foundation 모델 간의 시너지를 효과적으로 활용한 최초의 연구
- 어떠한 학습도 필요 없이 6D 자세 추정을 수행하여 향후 등장할 수 있는 새로운 foundation model들과도 쉽게 통합 가능한 솔루션 제안
- BOP benchmark에서의 SOTA 달성
Method
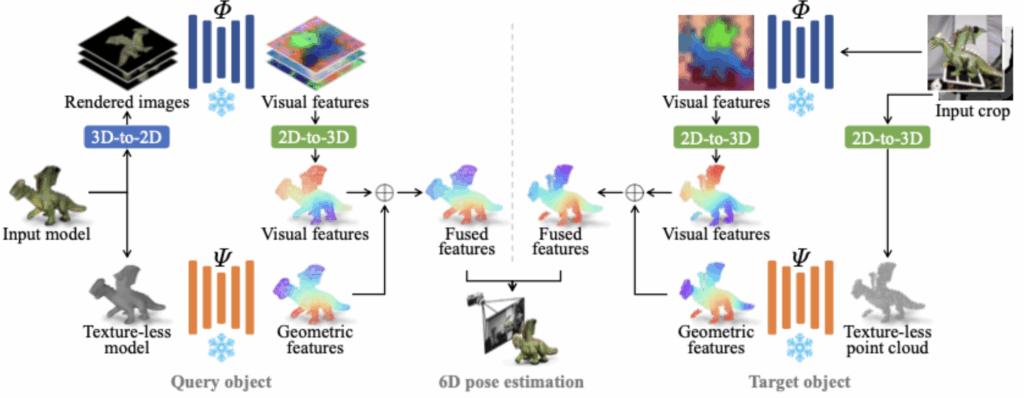
위는 FreeZe 논문의 전체적인 파이프라인 입니다. foundation을 활용해서 별도의 학습없이 이루어지다 보니 pipeline은 매우 간단합니다.
Q(query object)와 이미지안에서 등장하는 Q의 실제 인스턴스를 나타내는 T (target object)로 나뉘게 됩니다.
Query object processing
Input으로는 3D CAD model이 들어갑니다. 여기서도 두가지 foundation 입력에 맞게 처리를 해주게 됩니다. 먼저 3D 모델 표면에서 N개의 점을 샘플링하여 포인트 클라우드 를 생성하게됩니다. 이를 geometric foundation model에 입력으로 사용하게됩니다.
또한 vision foundatation model인 DINOv2의 입력으로 사용하기위해서 3D 모델로부터 다양한 시점에서 렌더링된 이미지(2D)들을 생성하고 그것을 입력으로 사용하게 됩니다. 이때 렌더링된 이미지들은 각 이미지에 대해새 object segmentation mask도 함께 렌더링 되어서 사실상 mask 영역만을 crop한 이미지를 DINOv2의 입력으로 사용하게 됩니다. 이 과정에서 다양한 시점에서의 시각 특징을 추출합니다 이러한 특징은 depth와 intrinsics parameter를 이용해서 다시 3D 공간으로 투영하여 geometric의 output과 concat하게 됩니다. 이를 통해 2D 시각 특징을 기존 3D 로 역투영하여 point cloud와의 3D-3D 매칭을 수행할 수 있는 기반을 마련하게 됩니다
Target object processing
6D에서 또 중요한것은 pose 만이 아닙니다 Target object에 대해 위치를 추정해야합니다. 그래서 저자는 CNOS 또는 SAM모델을 활용해서 region proposals를 생성하고 이를 query 객체의 템플릿과 유사도를 비교하게 됩니다 각 proposal에 대해서 시각 특징의 유사도를 기반으로 점수를 부여하고 그에 따라 confidence score를 가집니다. 하지만 실험적으로 CNOS에서 정확도와 confidence score사이에서 불일치 한 점이 있다고합니다. 정확한 마스크일수록 오히려 낮은 confidence를 가지는 경우가 발생하여 하나의 마스크를 고르기 보다는 confidence가 높은 여러 마스크들을 타깃 객체 후보로 유지한다고 합니다. 또한 입력 이미지 내의 최소 바운딩 박스도 함께 추찰하여 박스로 crop한 이미지를 vision 모델의 인코더를 넣어줍니다. 이때는 query 객체에서와는 다르게 픽셀의 시각적 특징을 point cloud에 직접적으로 할당하게 됩니다 . 그 이유는 RGB crop 이미지의 픽셀과 depth 간의 일대일 대응관계이기(입력이미지 RGB-D 이기때문) 입니다.
각각의 query 와 target에서 feature들은 L2정규화 되면서 concat 됩니다
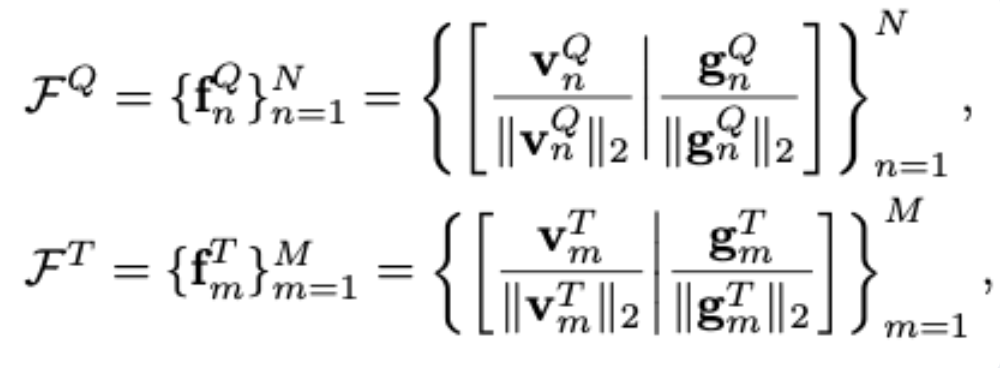
FQ : query 객체의 모든 포인트에 대한 fused feature 집합
fQ : query 객체의 n번째 3D 포인트에 대한 feature
VQ : DINOv2 기반 시각 특징
gQ : GeDi기반 기하 특징
따라서, query 객체의 포인트 클라우드 P^Q와 해당하는 fused feature F^Q, 그리고 target 객체의 포인트 클라우드 P^T와 fused feature F^T를 각각 구성한 뒤, 이들 간의 3D-3D feature matching을 통해 대응 관계를 찾습니다. 이 때 RANSAC을 통해서 추정하며 여러 후보 중 inlier 수가 가장 많은 pose가 최종 결과로 선택됩니다.
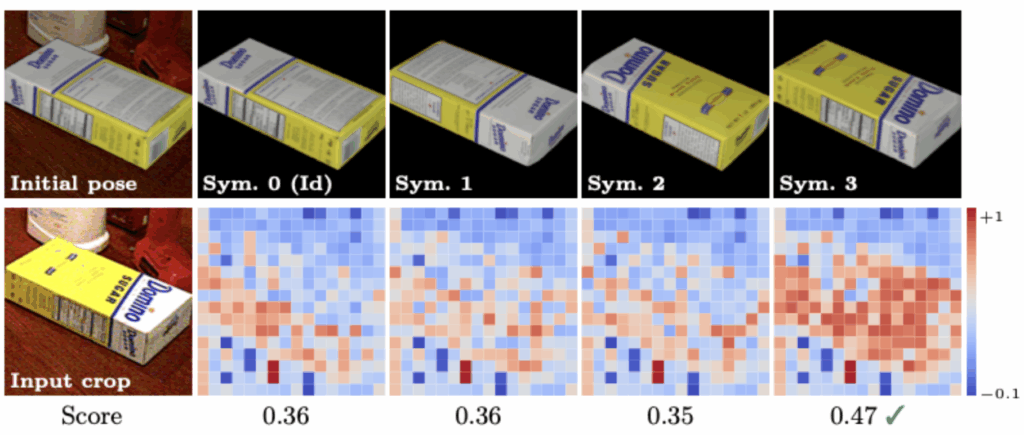
하지만 6D pose estimation에서 흔히 발생하는 문제 중 하나는 대칭 물체입니다. 즉, 두 포인트 클라우드가 기하학적으로 유사하더라도 실제 물체의 텍스처나 시각 정보가 다를 수 있기 때문에 잘못된 포즈로 정합될 수 있습니다. 이를 해결하기 위해 저자는 symmetry-aware refinement 단계를 도입합니다. 먼저 추정된 포즈를 입력 받아 iteratvie closest point(ICP) 알고리즘을 적용합하여 포인트 단위에서 우선적으로 정밀하게 맞춰줍니다.여기서 icp는 흔히 3D포인트 클라우드 정합에서 널리쓰이는 알고리즘인데요 두 포인트클라우드가 주어졌을때 최적의 R,t가나오게 반복적으로 추정하는 것을 말합니다. 그 다음 단계에서는 포즈에 대해 여러 rotation을 생성하고 렌더링된 템플릿과 target 이미지 간의 시각적 유사도를 계산하여 가장 높은 유사도를 보이는 후보를 선택함으로써, 실제 물체의 시각 정보와 일치하는 포즈로 정밀하게 보정할 수 있습니다. 위의 사진처럼 초기 pose는 다르지만 렌더링된 모델들과 유사성을 통해서 최종적으로 선택되게 됩니다.
Experiments
FreeZe 모델은 BOP Benchmark에 포함된 총 7개의 핵심 데이터셋 LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB, YCB-V 을 대상으로 실험을 수행하였고 모든 데이터셋에서 기존 방법들을 뛰어넘는 높은 성능을 보였습니다. 먼저, T-LESS와 ITODD는 전자기기 부품 등 산업용 물체로 구성되어 있으며 대부분 texture가 없고 기하적으로 대칭적인 특성을 지닌 CAD 기반 모델들로 구성되어 있습니다. 이러한 texture-less 객체는 시각 정보로는 분별력이 떨어질 수 있기 때문에 일반적인 vision-only 방식으로는 포즈 추정에 어려움을 겪습니다. 반면 LM-O, TUD-L, HB, YCB-V는 일상 사물로 구성된 RGB-D 기반 모델들로 다양한 texture와 형태를 포함하고 있습니다. FreeZe는 이러한 다양한 조건에서 별도의 학습 없이 높은 성능을 보였습니다. 해당 논문에서 평가지표는 AR입니다.
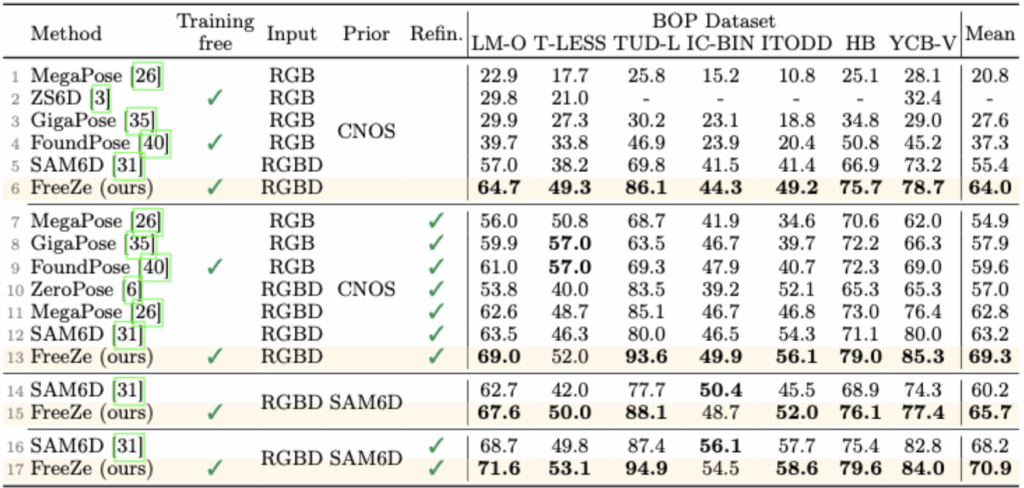
저자는 총 segmentation을 CNOS 대신 SAM6D에서 사용하는 segmentation prior를 사용하여 측정하였습니다. 첫번째로는 CNOS에서 측정된 지표를 보면 T-LESS를 제외하고 모두 최고의 성능을 보이고있습니다. 확실히 T-LESS난 ITODD 등 texture가 많이 없는 물체등에서는 낮은 성능을 보이지만 다른 모델들에 비해 상대적으로 가장높거나 비슷한 성능을 보이고있습니다. 추가적으로 SAM6D에서의 segmentation 방법론을 사용하며CNOS보다 좋은 성능을 보이는 것으로 보입니다.

정성적인 결과를 보더라도 다양한환경 가려져있거난 texture가 없는 모델에서 물체들을 학습없이도 안정적인 결과를 보여주게됩니다.

하지만 저자는 실패사례도 함께 보여주는데요 입력 이미지에서(d) 해당 손잡이 부분이 완전히 가려져 있어, 추가적인 사전 정보 없이는 올바른 포즈를 예측하는 것이 어려웠다고 합니다. 다만 보이는 부분은 정확하게 정렬되었습니다.
Ablation study
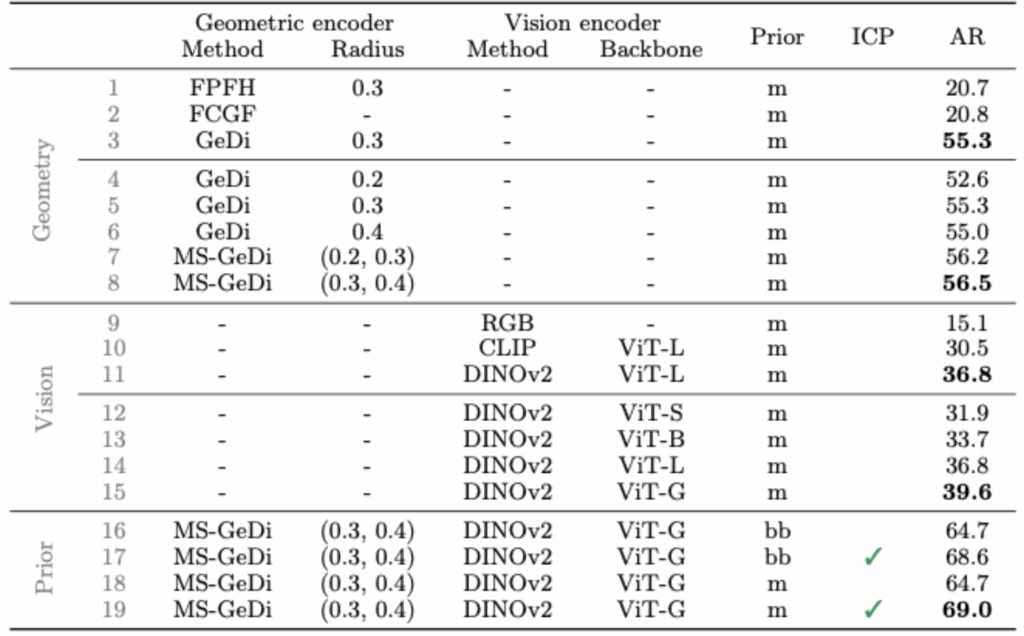
FreeZe에서 GeDi는 기존 handcrafted 보다 30점 이상 향상된 AR을 보였으며 특히 다중 스케일 MS-GeDi가 가장 우수한 성능을 나타냈습니다. 또한 Vision encoder로는 DINOv2 + ViT-Giant 조합이 다른 vision foundation model을 압도하였고, ICP 기반 refinement는 AR을 4점 이상 끌어올려 높은 성능을 보이고있고 최종적으로는 multiscale GeDi 와 DINOv2에서 vit-G 모델을 사용하여 linemod – o dataset에서 높은 성능을 보였습니다.

다음으로는 symmentic에 효과적인 SAR 과 기존 알고리즘 ICP를 도입한 ablation study입니다. 대칭객체가 많지않은 데이터셋에서는 비슷한 성능을 보이는 반면 대칭객체가 많은 데이터셋 IC-BIN, HB, YCB-V 에서 SAR이 효과적인 모습을 보였습니다.
감사합니다.
끝으로 BoP 벤치마크에서 높은 성능을 보이고있음에도 불구하고 코드도 공개되어있지 않습니다. 또한 score 계산 부분이나 렌더링, 포인트 클라우드 처리 이런 부분에 대해서는 논문에서도 자세히 설명되어있지 않아 아쉬움이 남는 논문이였습니다
안녕하세요 우진님, 좋은 리뷰 감사합니다.
태스크에 특화된 학습없이 기존의 파운데이션 모델을 그대로 가져다 쓰면서 단순하게 모델을 설계한 부분이 흥미로웠던 것 같습니다. 한가지 단순한 궁금증이 있습니다. Geometric feature와 visual feature가 L2 정규화 이후 단순히 concat을 하는데, 서로 다른 도메인에 대해서 concat 말고도 다른 fusion 전략이 있는데(attention-based fusion과 같은) 단순히 concat으로 한 이유에 대한 저자의 언급이나 혹은 다른 ablation study가 있었는지 궁금합니다. 감사합니다.
리뷰 읽어주셔서 감사합니다 우현님!
질문 주신 feature fusion 방식에 대해 답변드리자면,논문에서는 geometric feature와 visual feature를 각각 L2 정규화한 뒤 단순히 concat하는 전략을 사용하고 있으며, 그 이유에 대한 명확한 설명이나 attention 기반 fusion 등과의 비교 실험은 포함되어 있지 않습니다. concat만으로도 충분히 효과적이었다고 판단하였고, 다른 fusion 기법은 향후 연구 과제로 남겼습니다. 따라서 현재로서는 concat 기반이 유일한 fusion 전략이며, attention-based fusion 등에 대한 ablation은 아직 진행되지 않았습니다.
감사합니당
안녕하세요, 좋은 리뷰 감사합니다.
실험 부분에서 평가를 AR에 대해서만 하고 있는 거 같은데, 제가 알기로는 6D에서 조금 더 메인이 되는 평가 지표는 ADD나 ADD-S로 알고 있습니다. 혹시 이런 평가 메트릭으로 리포팅한 실험은 없었을까요 ?
그리고 Query object와 target object 사이의 시각적 특징을 바로 할당을 하냐 안 하냐의 차이가 있는 거 같은데, Fiugure 상으로는 둘 다 2D-to-3D 과정을 거쳐서 동일한 위치에 있는 시각적 특징을 서로 매칭하는 것 아닌가요 ? 어떤 차이가 있는 지 조금 더 설명 부탁드립니다.
감사합니다.
질문 감사합니다! 건화 연구원님!
Q1. AR 말고 ADD나 ADD-S 기반 평가 실험도 있나요?
없습니다… 논문 및 Supplementary material 모두 BOP Benchmark의 기본 평가 지표인 AR 만 사용하고 있으며 ADD / ADD-S 기반의 리포팅된 결과는 제공되지 않습니다.
Q2. Query object와 target object 모두 visual feature를 2D-to-3D로 매핑하는 것 같아 보이는데, Figure 상의 차이는 뭔가요?
네, 두 경우 모두 2D 이미지를 DINOv2로 추출 → 3D point에 back-project하여 2D-to-3D lifting을 수행하는 건 동일합니다. Query object는 CAD 모델 기반으로 여러 뷰를 렌더링하고, 각 뷰에서 얻은 2D feature를 다수의 시점 평균으로 통합합니다.즉, multi-view rendered images → 평균 visual feature assignment Target object는 RGBD 이미지 상에서 하나의 crop된 view만 사용하고,그 crop의 foreground 픽셀만 시각 feature로 사용합니다. 결과적으로, 둘 다 2D-to-3D projection은 같지만 Query는 multi-view 평균 기반 Target은 단일-view에서 foreground만 사용하는 점이 핵심 차이입니다.
안녕하세요 우진님 리뷰 감사합니다
서로 다른 모달리티에서 학습된 vision foundation model과 geometric foundation model을 융합해 zero-shot 6D pose estimation을 가능하게 한 최초의 접근이라고 이해했습니다. 이때 visual feature(DINOv2)와 geometric feature(GeDi)를 어떻게 단순 concat하면 정합이 되는지 궁금합니다. 리뷰에 적힌 내용이 같은 feature space에 잘 정렬한 것이다 라고 이해하면 되는걸까요??
리뷰 읽어주셔서 감사합니다.
말씀하신 대로 DINOv2와 GeDi는 서로 다른 modality에서 학습된 foundation model입니다. 저자들은 이 두 feature를 같은 feature space로 정렬한다기보다는, 각각 L2 정규화하여 스케일을 맞춘 뒤 단순 concat하여 사용합니다. 이를 통해 geometric과 visual 특성을 균형 있게 반영한 fused descriptor를 만들고, 이후 RANSAC 기반 3D registration에 활용하는 구조입니다. 따라서 정합성은 동일한 feature space에서 alignment된다는 의미보다는, 두 modality의 정보를 정규화 후 결합하여 서로 보완되도록 구성한 것으로 이해하시면 될 것 같습니다.
감사합니다