안녕하세요 이번에도 Text-Video Retrieval 논문을 리뷰하고자 합니다. 개인 연구를 진행하면서 어떻게 하면 encoder 내부에서 비디오의 spatial-temporal 정보를 모델링 할지 고민을 하고 있는데 마침 제가 생각했던 아이디어와 비슷한 방법으로 방법론을 제안한 논문이 있어서 이번에 리뷰하게 되었습니다. 저자가 제안하는 TS2-Net는 , Video Encoder backbone에서 spatial-temporal 정보를 보다 fine-grained 모델링하는 방법을 제안한 논문입니다. 구체적으로는 두 가지 핵심 모듈로 구성되는데, 첫 번째는 Token Shift 모듈로 이는 프레임 간 시간 축을 따라 토큰 전체를 앞뒤로 이동시키는 방식으로, 토큰에 담긴 정보를 보존하면서도 프레임 사이의 subtle motion을 학습하도록 도와주는 모듈입니다. 두 번째, Token Selection 모듈은 프레임 내의 수많은 토큰 중 의미 있는 로컬 공간 정보를 담고 있는 토큰들만 선택하여, 중요도 높은 토큰만을 선택하도록 구성된 모듈입니다.
그럼 본격적으로 리뷰 시작하겠습니다.
1. Introduction
비디오에서는 spatial-temporal 정보를 효과적으로 담아낼 수 있는 비디오 인코더를 설계하는 것이 Text-Video Retrieval 연구에서 중요한 과제입니다. 특히 비디오 프레임 간의 움직임(motion)뿐만 아니라 각 프레임 내 객체들의 공간적 위치와 변화까지 잘 포착하는 것이 핵심이라고 할 수 있습니다. 그래서 이전에도 이러한 공간 및 시간적 특성을 모두 고려하는 연구들이 꾸준히 진행되어 왔습니다. 이후에는 Transformer가 등장하면서 대부분의 Video Encoder가 Transformer 구조를 사용하게 되었습니다.
그러나 기존 Transformer 기반 모델들은 공간적 혹은 시간적 차원에서 fine-grained한 표현 능력이 아직 부족한 한계가 있습니다. 예를 들어, 일부 모델들의 비디오 인코더는 일반적으로 단일 프레임의 특징을 추출하는 모듈과 그 뒤에 전역적인 특징을 합치는 모듈로 구성되어 있습니다. 이러한 구조는 인접한 프레임 간의 상호작용(fine-grained interaction)이 부족하며, 프레임 수준의 의미 정보만을 단순히 합치는 방식이기 때문에 세밀한 시간적 변화나 공간적 디테일을 포착하는 데 한계가 있습니다.

전반적으로 기존 모델들은 크고 눈에 잘 띄는 동작이나 뚜렷한 공간 정보를 표현하는 데에는 강하지만, 작고 세밀한 움직임이나 작은 물체를 표현하는 데에는 아직 부족한 점이 있습니다. 그래서 위의 그림 1처럼, ‘hat’과 같은 작은 물체나 ‘taking’과 같이 섬세한 행동을 제대로 파악해야 하는 경우에는, 정확한 비디오를 찾아내는 데 실패할 수 있습니다.
따라서 저자는 기존의 비디오 트랜스포머 구조는 유지하되, 보다 세밀한(fine-grained) 정보를 효과적으로 학습하기 위해 spatial-temporal patch context를 통합할 수 있는 방법에 주목하였고, 이를 위해 Token Shift and Selection Transformer Network(TS2-Net)이라는 방법론을 제안합니다.
TS2-Net은 두 가지 주요 모듈로 구성되어 있습니다. 첫 번째는 Token Shift Module로, 각 토큰의 특징을 하나의 단위로 간주하고, 동일한 위치에 있는 토큰들을 인접 프레임 간에 반복적으로 교환하는 방식으로 동작합니다. 이를 통해 토큰이 가진 원래의 특성을 잃지 않으면서, 시간적인 움직임 정보도 담아낼 수 있습니다.
두 번째는 Token Selection Module로, 모든 시공간 패치 특징과 [CLS] 토큰 간의 상관관계를 기반으로, 지역적인 공간 의미(spatial semantics)에 가장 크게 기여하는 토큰들을 선택하여 의미 있는 토큰들을 강조합니다. 이 과정을 통해 토큰의 중요도를 추정하고, 핵심적인 의미 정보를 더욱 효과적으로 모델링할 수 있도록 합니다.
결론적으로, 저자가 제안한 모델은 MSRVTT, VATEX, LSMDC, ActivityNet, DiDeMo 등 다양한 벤치마크에서 SOTA를 성능을 달성했으며, ablation study를 통해 토큰 시프트(token shift) 모듈과 토큰 선택(token selection) 모듈이 Text-Video Retrieval의 정확도를 향상시키는 데 기여함을 확인했습니다.
저자의 Contribution을 정리하면 다음과 같습니다
1. Text-Video Retrieval 성능 향상을 위해 local patch를 강화하는 video-language learning 기법 제안
2. 비디오의 temporal, spatial 정보를 더 잘 모델링 할 수 있는 토큰 시프트 트랜스포머(token shift transformer)와 토큰 선택 트랜스포머(token selection transformer) 두 가지 모듈 도입
3. 여러 벤치마크에서 SOTA를 달성하고, 추가 실험으로 효과를 입증
2. Method
그럼 이제 모델의 방법론을 살펴보겠습니다. 저자가 제안하는 TS2-Net은 text encoder, video encoder, 그리고 text-video matching의 세 가지 구성요소로 이루어져 있습니다. text encoder는 GPT 모델을 사용하고 쿼리 단어 시퀀스 끝에 [EOS] 토큰을 추가하여 [EOS] 토큰의 인코딩을 쿼리 representation q로 활용합니다. video encoder는 비디오 프레임들의 시퀀스를 프레임별 비디오 representation으로 인코딩합니다. 최종적으로 쿼리와 비디오 representation q ,v를 바탕으로 쿼리와 비디오 후보 간의 cross-modal similarity를 계산합니다.
- Token Shift Transformer
저자가 제안하는 video encoder는 Token Shift Transformer와 Token Selection Transformer가 추가된다고 했습니다. Token Shift Transformer는 Vision Transformer(ViT) 를 기반으로 하며, 트랜스포머 블록 내에 Token Shift 모듈을 삽입합니다.

Token Shift 모듈은 비디오에서 미세한 움직임을 효과적으로 모델링하는 것을 목표로 하고 있습니다. 이전에도 Token Shift 기법이 있기는 하였습니다. 그림 3(a,b,c)는 2021년에 제안된 Shift-Transformer 모델이 제안하는 방식을 보여주고 있습니다.
그림 3(a)에 있는 기본적인 channel temporal shift 방식은 프레임의 일부 채널을 시간 축을 따라 이동시키는 방식입니다. 구체적인 숫자로 예를 들어 설명을 드리면, 비디오에서 12개의 프레임을 샘플링 하고, 1개의 프레임에는 196개의 토큰이 있고, 각 토큰은 768개의 채널(768차원)을 가지고 있다고 가정하겠습니다. 그러면 이 방식은 전체 768개의 채널 중 일부(예: 앞뒤 각 256개)를 시간축을 따라 앞 또는 뒤 프레임의 토큰으로 이동시켜, 프레임 간 정보교환을 유도합니다.
그리고 그림 3(b), (c)의 [VIS] channel shift 와 [CLS] channel shift 는 특정 토큰의 일부 채널만([CLS]를 제외한 나머지 토큰 또는 [CLS]만 이동) 시간 축을 따라 이동시키는 방식입니다. 하지만 ViT 구조에서는 각 토큰이 독립적으로 존재하며, 특정 위치에 대한 고유한 공간 정보를 담고 있기 때문에, 토큰 내부의 일부 채널만 따로 이동시키면 정보가 분리되어 의미가 흐트러질 수 있습니다.
반면, 토큰 전체를 통째로 이동시키면 토큰에 담긴 정보를 온전히 보존할 수 있고, 동시에 프레임 간 상호작용도 자연스럽게 이끌어낼 수 있기 때문에 저자는 token 단위로 전체 채널을 이동하는 방식을 제안합니다. 이 방식은 그림 3(d)를 통해 확인할 수 있는데 기존 a,b,c 방식의 채널 단위의 이동에서 토큰 단위의 이동으로 바뀐 것이기 때문에 특별한 설명은 없이 넘어가도록 하겠습니다.
- Token Selection Transformer
다음은 Token Selection Transformer에 대해 알아보도록 하겠습니다. Retrieval를 잘 수행하기 위해서는 결과적으로 각 프레임에서 중요한 정보를 하나로 잘 모아 하나의 비디오 프레임 벡터로 표현할 수 있어야합니다.
가장 간단한 방법은 각 프레임들을 평균 내거나 temporal Transformer 레이어를 여러개 쌓는 방법이 있습니다. 하지만 모든 토큰을 다 사용하면, 배경 같은 중요하지 않은 정보까지 포함돼서 비디오 표현이 복잡해지고 성능이 떨어질 수 있고, [CLS] 토큰만으로 정보를 요약하면 중요한 중요한 물체나 객체 정보가 빠질 수 있습니다. 따라서 저자는 각 프레임에서 객체의 중요한 의미를 포함하는 유용한 토큰들을 선택하는 Token Selection Transformer를 제안합니다.
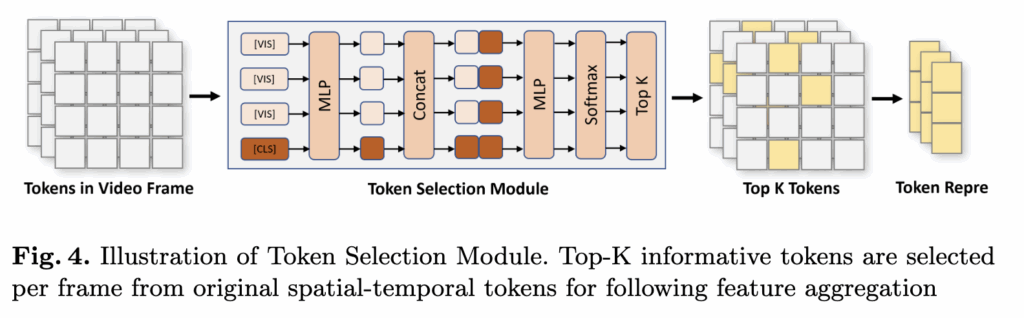
구체적으로, 하나의 프레임은 [p_cls, p₀, p₁, …, pₙ₋₁] 형태로 구성되며, 총 (N+1)개의 토큰이 있고, 각 토큰은 768채널의 벡터로 표현됩니다.
이제 각 토큰의 채널 수를 줄이기 위해 MLP를 적용해 768채널을 384채널로 축소합니다. 다음으로 각 일반 토큰이 프레임 전체에서 얼마나 중요한지를 판단하기 위해, 모든 일반 토큰에 대해 [CLS] 토큰과 짝을 지어 [p′_cls, p′₀], [p′_cls, p′₁], 과 같이 새로운 토큰 쌍을 만듭니다.
이렇게 만들어진 토큰 쌍들을 다시 MLP에 통과시키고, Softmax를 적용해 각 토큰의 중요도 점수를 계산합니다. 그다음, 이 점수를 기준으로 상위 K개의 중요한 토큰만 선택하는 Top-K 토큰 선택을 수행합니다.
이렇게 선택된 토큰들만 모아 새로운 프레임 대표값으로 활용하고, 모든 프레임에서 선택된 토큰들을 모아 Transformer에 입력합니다. 이를 통해 비디오 전체에 대한 전역적인 표현을 학습할 수 있게 됩니다.
- Differentiable TopK
Token Selection 모듈에서는 각 프레임에서 중요한 토큰 Top-K개를 선택했습니다. 하지만 여기엔 한 가지 문제가 있는데, Top-K selection 이나 one-hot 벡터 방식은 수학적으로 보면 이산적인 연산(discrete operation)이기 때문에, 딥러닝 모델에서 필요한 미분 계산이 불가능하다는 점입니다. 그래서 이 논문에서는 ‘Perturbed Maximum Method’라는 방법을 사용해서 미분 가능한(differentiable) 방식으로 미분 가능한 Top-K selection을 구현합니다.
이 방법에 대해 자세히는 알지 못해서 간단하게만 설명 드리면, Top-K 토큰을 선택하기 위해 먼저 각 토큰의 중요도 점수 S를 계산합니다. 여기에 Perturbed Maximum Method를 적용하게 된다면 S에 작은 노이즈(perturbation)를 더해 선택을 확률화 해줄 수 있다고 합니다. 이를 통해서 Top-K 연산을 미분 가능하게 만들 수 있고, 결론적으로 역전파 계산이 가능하게 만들어 준다고 하네요.
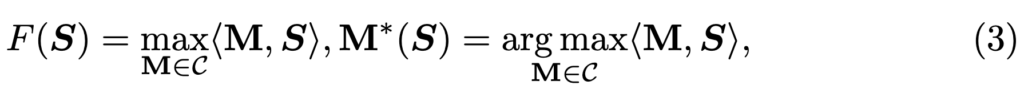
- ⟨M,S⟩ : 선택된 K개의 토큰 중요도를 더한 값
- M : 선택된 토큰들을 나타내는 one-hot 행렬입니다.
- C : 가능한 모든 Top-K 조합의 집합
- Text-Video Matching
그럼 이제 비디오와 텍스트의 최정 벡터를 뽑았으니 둘의 유사도를 기반으로 매칭을 수행해야 합니다. 최종 텍스트-비디오 유사도 s는 각 프레임별 유사도 si에 가중치를 곱해 모두 더한 값으로 표현이 됩니다. 이 가중치 𝛼i 는 소프트맥스 함수로 계산되며, 각 프레임의 중요도를 반영합니다. 수식으로 살펴보면 다음과 같습니다.

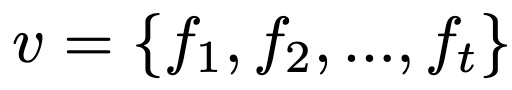

3. Experiment
이제 실험 부분 살펴보도록 하겠습니다.
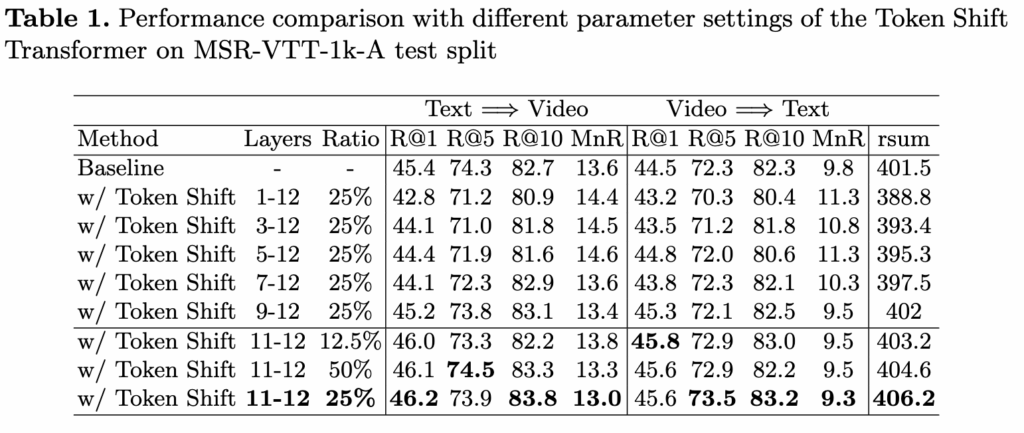
먼저 Token Shift Transformer의 핵심 요소인 shift layer 와 shift ratio 대한 실험을 진행했습니다. 12 layer로 구성된 ViT 구조에서 토큰 시프트 모듈을 어느 layer에 적용할지가 중요한데, 실험 결과 가장 깊은 11layer과 12layer에만 적용했을 때 검색 성능이 가장 좋아졌습니다. 반면 얕은 layer나 여러 layer에 걸쳐 시프트를 적용하면 공간 정보를 모델링하는 능력이 손상되어 성능이 떨어졌습니다. shift ratio는전체 토큰 중 약 25%를 앞뒤로 움직였을 때 최적의 성능을 보였으며, 다양한 비율에서 모두 기준 모델보다 성능이 향상됐고 특히 R@1 지표에서 큰 개선이 있었습니다. 또한 기존 Shift-ViT의 다른 시프트 방식들과 비교했을 때, 제안한 토큰 시프트 모듈이 토큰의 정보 완전성을 잘 유지해 공간 모델링 능력을 해치지 않아 가장 좋은 결과를 냈습니다.

정성적으로 확인해봤을떄는 토큰 시프트 트랜스포머가 적용된 모델이 ‘shake hands’ 같은 미세한 움직임도 잘 포착하는 것을 확인할 수 있었습니다.
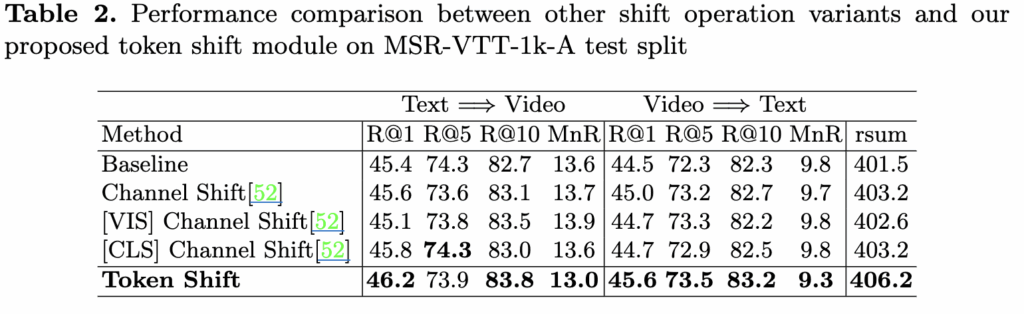
Token Selection Transformer의 Ablation 실험 결과를 보면, 한 프레임에서 너무 많은 토큰을 선택하기보다는 적은 수의 토큰만 선택하는 것이 검색 성능에 더 도움이 된다는 것을 알 수 있습니다. 예를 들어, 프레임당 2개의 토큰을 선택했을 때 성능이 가장 좋았고, 50개를 선택했을 때는 오히려 성능이 떨어졌습니다. 이는 적은 수의 핵심 토큰만으로도 중요한 공간 정보를 잘 유지할 수 있지만, 너무 많은 토큰을 선택하면 중복 정보가 많아져 성능이 나빠지기 때문이라고 저자는 분석하고 있습니다. 무작위로 토큰을 선택하는 경우에도 약간의 성능 향상은 있었지만, 학습을 통해 중요한 토큰을 선택하는 모듈이 훨씬 더 좋은 결과를 보여주었습니다.

이를 정성적으로 살펴보면 Token Selection Transformer를 적용한 모델은 작은 ‘bag’ 같은 세밀한 객체도 잘 찾아내는 것을 확인할 수 있었습니다.
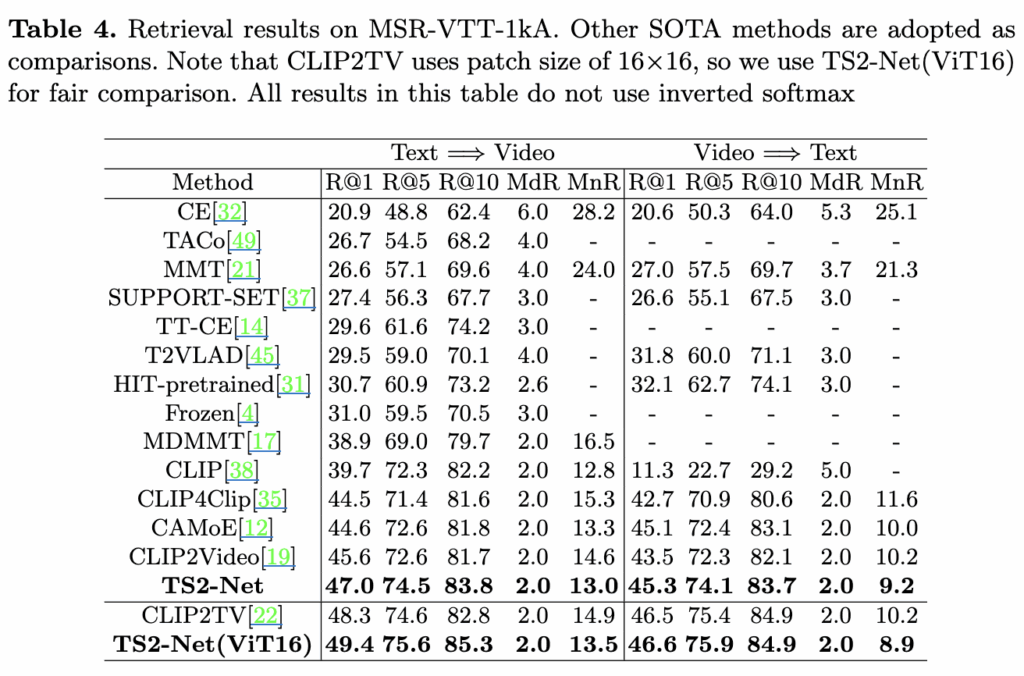
저자가 제안하는 모델을 다섯 개의 벤치마크 데이터셋에서 평가를 진행했습니다 . MSR-VTT-1kA 테스트 결과를 보면, TS2-Net은 여러 평가 지표에서 기존 방법들 보다 좋은 성능을 보였습니다. 특히 토큰 시프트 트랜스포머와 토큰 선택 트랜스포머 덕분에 미세한 움직임과 중요한 객체를 효과적으로 포착할 수 있어, 최종 비디오 표현이 더 향상되었다고 해석할 수 있습니다. 한편 텍스트-비디오 검색(text-to-video retrieval) 쪽에서 더 큰 성능 향상이 나타났는데, 이는 제안된 모듈들이 비디오 인코더 성능을 크게 개선한 반면, 텍스트 인코더는 상대적으로 단순하게 설계되었기 때문이라고 분석하고 있습니다.
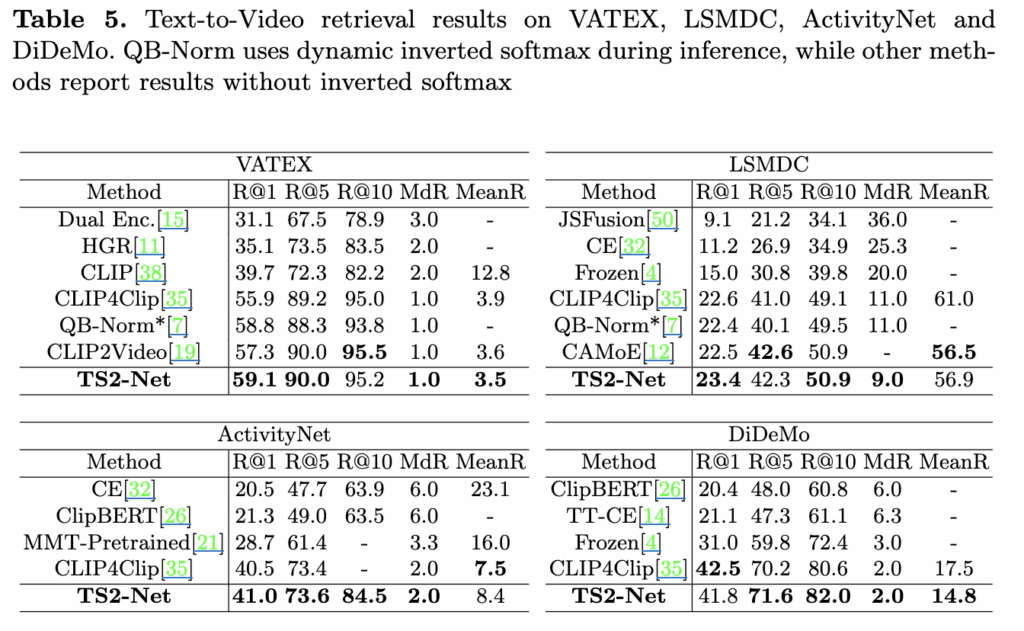
또한, VATEX, LSMDC, ActivityNet-Caption, DiDeMo 등 다른 데이터셋에서도 TS2-Net은 일관된 성능 향상을 보여, 공간적·시간적 특징을 동시에 잘 인코딩하여 다양한 데이터셋에서 잘 작동함을 입증했습니다.