안녕하세요, 오늘 리뷰할 논문은 CVPR2025에 게재된 논문으로, Video 기반 SGG를 다룬 논문입니다. SGG 분야 자체가 연구가 활발한 편이 아니긴 한데, 이번 CVPR을 둘러보니 단순 image 기반으로 해결하기보다는 video나 4D정보로 확장하려는 경향이 뚜렷했습니다. 지금은 image 기반의 OV-SGG쪽으로 문제 정의를 하려고 하는데 video를 기반으로 문제 정의 하는것도 함게 고려해보라는 조언을 들어서 관련 논문을 읽어보았습니다. 리뷰 시작하겠습니다.


컴퓨터비전의 시각 인지 측면에서 우리가 기대하는 목표는 주어진 이미지 / 비디오 데이터에 기반하여, 해당 데이터가 포함하고 있는 고차원적인 의미를 파악하는 것입니다. 이제 기술이 발달하여 Object Detection의 경우 잘 동작하지만, 아직 AI 모델들이 주어진 이미지 내 정보들에 대한 고차원적인 추론을 하지는 못하죠. 이제는 물체들을 검출한 다음, 각 물체들이 서로 어떤 관계에 있는지를 모델링 하기를 기대하고 있습니다. Scene Graph Generation(SGG)은 이런 image understanding을 위한 task로, 각 물체 뿐만 아니라 이들 간의 관계도 예측하여 보다 고차원적인 작업을 수행하고자 합니다. SGG에서는 각 object들과 이들 간 관계를 <subject-predicate-object> triplet으로 잘 기술하는 것을 목표로 하고 있고, image 뿐만 아니라 3D point cloud, video 등 다양한 입력 형식에 대해서로 확장되고 있습니다.
imge SGG도 long-tail distribution 문제가 있어 자주 등장하거나 당연하고 쉬운 class에 예측이 편향되는 경향이 있는데, Video SGG쪽에서도 unbiasing이 꽤 핫한 키워드인듯 합니다. 최근에 이른 class imbalance / bias 문제를 완화하기 위해 attention 기반 방법들이 제안하거나 spurious correlation을 줄이고 label correlation을 보다 잘 반영하는 등의 방법론이 등장했지만 여전히 성능 측면에서 한계를 보인다고 합니다. 저저들은 그 근본적인 이유가 기존 방법들이 scene graph의 본질적인 visual-semantic 정보를 간화하고 debiasing 기술에만 지나치게 의존하기 때문이라 주장합니다.
저자들은 Scene Graph가 본질적으로 시각적 정보(visual information)과 의미적 정보(semantic information)를 동시에 통합하는 구조이므로, bias 또한 visual bias와 semantic bias로 구분할 수 있다고 합니다. 여기서 말하는 visual bias는 동영상의 품질 저하(동영상에서 나타나는 blur나 occlusion으로 인해 object의 feature representation이 손상)로 인해 발생하는데, Fig1(a)에서 객체들이 시간에 따라 부분적으로 가려지는 등 모델이 강건한 visual feature를 학습하는데 방해가 되는 원인이라고 합니다. Video SGG(VidSGG)에는 semantic bias도 발생하는데, 기존 방법론들은 relation을 예측하는 relation generator를 단순히 visual feature에만 의존해 학습하였고, 이런 단일 모달 정보에 의존하는 것은 자주 등장하는 클래스(frequent predicate class)에 편향되는 결과를 낼 수 있다고 합니다. 맥락적 정보가 부족할 때 사람이 단순한 예측을 하게 되는 것과 유사하다고 생각하시면 됩니다.
저자들은 VidSGG의 편향 문제를 해결하기 위해 먼저 VidSGG에서 발생하는 편향을 1.visual bias와 2.semantic bias로 구분하고, 이에 대응 할 수 있는 VISA(VIsual and Semantic Awareness) 프레임워크를 제안합니다(Fig 1의 (b), (d)). VISA는 우선 Memory-Enhanced Temporal Integrator를 통해 visual bias를 완화합니다. 이 모듈은 이전 프레임의 entity representation을 현재 프레임의 representation에 통합해서 객체의 표현을 더 풍부하게 만들어주었습니다(과거 정보를 통합해 연속적인 entity의 representation을 보완했다고 생각하시면 됩니다). 이후, relation generation를 사용해서 일차적으로 scene graph를 생성한 뒤, hierarchical semantic extractor를 통해 점진적으로 semantic information을 정제하게 됩니다. hierarchical fusion strategy로 visual / semantic 정보라는 모달리티들의 context를 통합해서 semantic bias를 완화하는데, visual debiasing은 visual feature의 분산을 줄이고, semantic debiasing은 KL divergence를 증가시켜 희귀한 relation을 더 잘 인식하도록 유도하게 됩니다.
저자들은 이렇게 visual / semantic bias를 완화해서 다양한 성능 평가에서 기존보다 개선된 결과를 보였습니다.
저자들이 주장하는 contribution은 다음과 같습니다:
- 우리는 VidSGG에서 발생하는 시각적 편향(visual bias)과 의미적 편향(semantic bias)을 명확히 정의하고, 이들이 모델 성능에 미치는 영향을 분석하였다.
- 우리는 이러한 편향을 동시에 해결할 수 있는 VISA 프레임워크를 제안하였다. VISA는 memory-enhanced temporal integration(메모리 기반 시각 정보 통합)과 hierarchical semantic extraction(계층적 의미 추출)을 통해 시각적 및 의미적 편향을 모두 완화하였다
- 이론적 분석과 광범위한 실험을 통해 VISA의 유효성을 검증하였으며, VidSGG에서 SOTA를 달성하였다.
Method
제안하는 VISA 프레임워크는 (1) Memory Guided Sequence Modeling (MGSM)와 (2) Iterative Relation Generator (IRG)로 구성됩니다. 우선 기존의 object detector로 영상 프레임 내 객체들을 식별하고, RoI Align으로 객체의 feature representation을 얻습니다. MGSM 모듈에서는 이 특징을 정제하여 subject와 object의 representation을 생성하고, 보다 개선된 특징 표현을 만들어냅니다. 이후에 2개의 개별 FFN을 통해 서로 다른 주어, 목적어의 임베딩을 생성합니다. 이렇게 만들어진 visual representation을 바탕으로 IRG 모듈에서는 계층적 의미 추출기(hierarchical semantic extractor, HSE)를 사용해서 시각적 정보와 의미적 정보를 통합합니다.
이 과정을 반복해서 unbiased semantic relation을 추론하고, 최종 relation을 예측합니다. 각 요소들을 더 자세히 살펴보겠습니다.
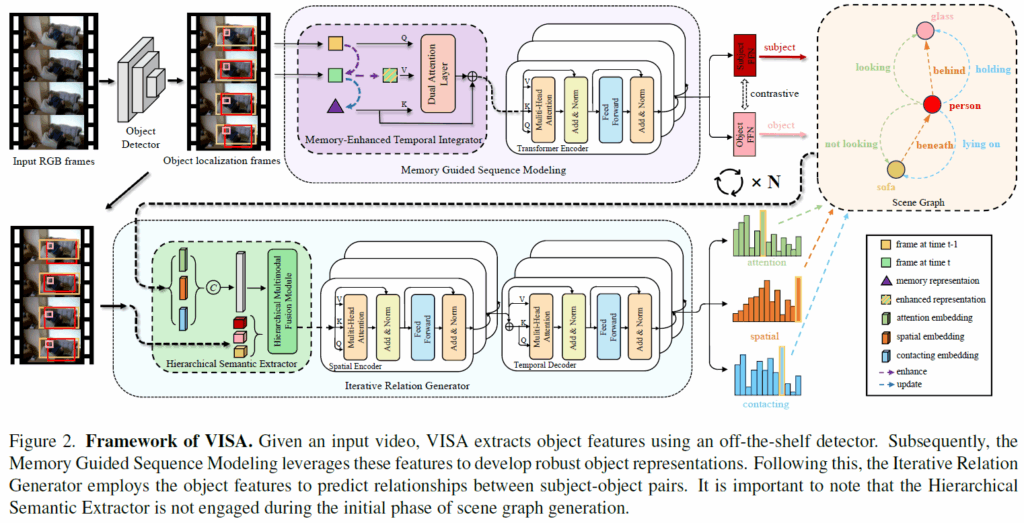
Memory Guided Sequence Modeling
저자들은 비디오의 길이가 길어질수록 transformer가 blurring이나 occlusion에 취약한 작은 객체들에 대해 좋은 visual representation을 생성하지 못하는 경향을 발견하였다고 합니다. 이런 저품질 표현은 시각 정보의 불안정성으로 feature representation의 분산이 크게 만들어 자주 등장하는 객체에 편향되고 드물게 등장하는 객체를 간과하게 된다고 합니다. 이를 이론적으로 분석하면, 이런 불안정성은 객체의 표현에 noise를 추가해 다음과 같이 모델링할 수 있다고 합니다.
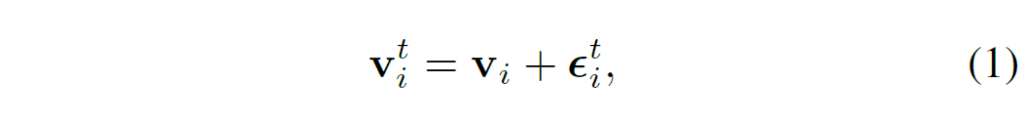
여기서 {ϵ}^{t}_{i}는 시간이나 객체에 독립적인 평균이 0인 가우시간 노이즈를 의미합니다. t번째 프레임에서 관측된 특징은 객체의 표현으로 직접 사용되며, 다음과 같습니다.
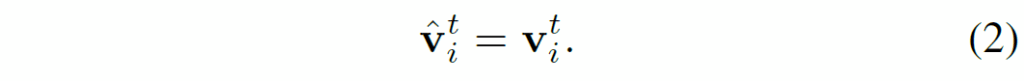
이에 따라, 이 시각 표현의 기댓값(expectation)과 분산(variance)은 다음과 같이 계산된다고 합니다.
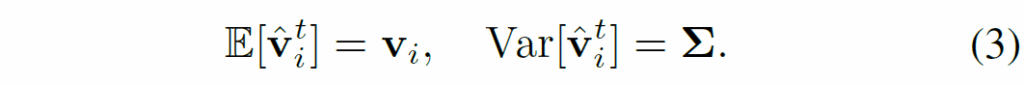
저자들은 이처럼 단일 프레임에서의 추정이 편향되지 않았더라도 시각적 불안정성에 의해 유입된 노이즈는 결과적으로 높은 분산(high variance)을 유발하며, 이 높은 분산이 특징 표현의 안정성을 떨어뜨리고, 나아가 관계 예측relation prediction의 정확도를 저해하게 된다고 합니다. 뭐 말이 길고 수식적으로 입증하려고 주저리주저리 써져 있지만 결국 비디오에서 물체가 블러나 가림으로 제대로 visual feature의 품질이 떨어지면 피쳐가 분산이 커져서 불안정해지고 안정성이 떨어져 relation을 예측하는데 좋지 못한 영향을 끼친다.. 정도로 요약할 수 있겠네요.
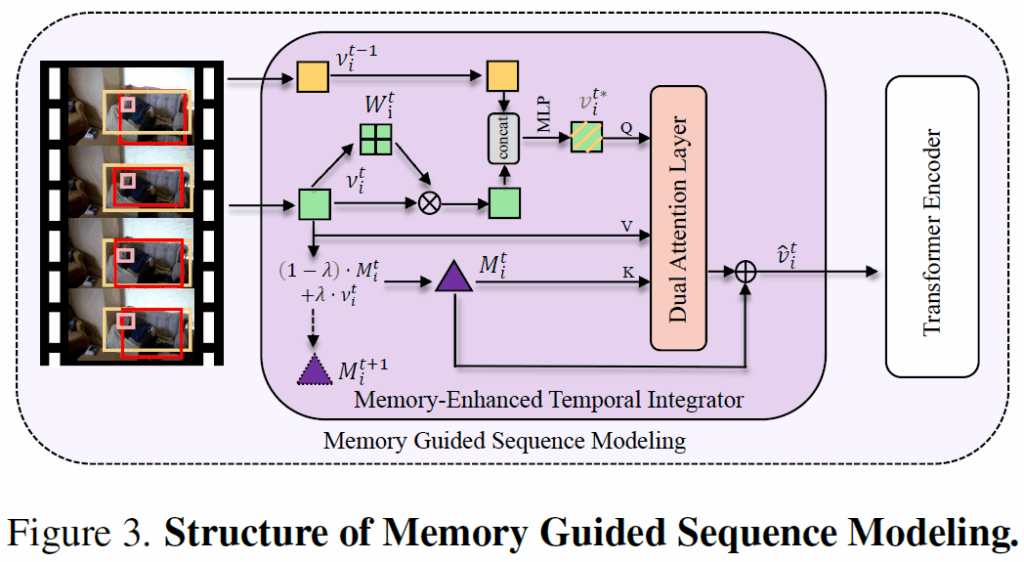
시각 정보가 불안정해져서 분산이 높아지면 안좋다는 얘기를 하고, 이를 해결하기 위한 Memory Guided Sequence Modeling (MGSM) 모듈을 설명합니다. MGSM은 이전 프레임들로부터의 시각적 정보를 활용하여 현재 프레임의 객체 특징 표현을 강화해주어, 시각 표현이 부족해서 생기는 분산을 감소시킬 수 있다고 합니다. 일단 현재 프레임의 features들을 기반으로 adaptive weights를 계산합니다.
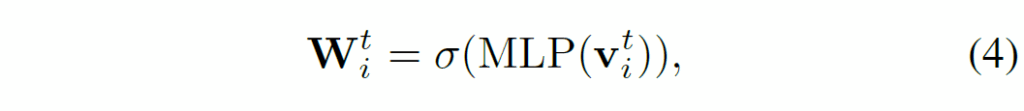
수식(4)에서σ는 시그모이드 함수입니다. 이 가중치를 활용해서 다음과 같이 weighted feature representation를 얻습니다.
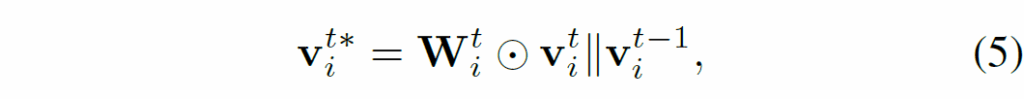
수식 (5)에서 ⊙는 element-wise multiplication을 의미하고, ||는 feature concatenation을 의미합니다. 이 이후에는 시각적 정보를 누적해주고 현재 representation을 정재하기 위해 다음과 같이 업데이트를 한다고 합니다.
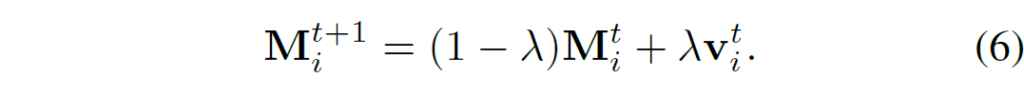
수식 6의 업데이트 결과로 memory representation의 기댓값과 분산은 시간이 지나면 다음처럼 안정화된다고 합니다.
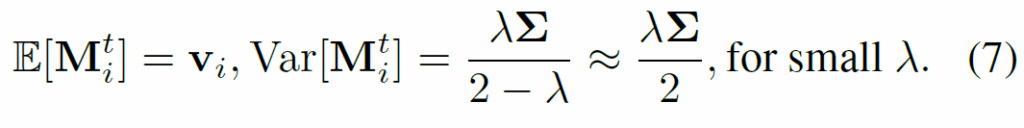
이 수학적 분석을 통해 λ 값이 작을수록 분산이 감소하며, 이에 따라 특징 추정의 안정성(robustness)이 개선된다고 합니다. 하지만 λ가 지나치게 작을 경우, 새로운 정보를 반영하지 못하게 되어가 느려지고, 오히려 편향(bias)이 유입될 수 있어서 적절한 값을 선택해야 한다고 하네요. supplementary 부분에 길게 수학적 증명이 늘어져 있긴 한데, 결국 적절하게 하이퍼파라미터를 설정하여 시간이 지날수록 적절하게 시각 정보를 업데이트 해야 한다는 것 같습니다. 최종적으로 정제된 feature representation은 다음과 같이 dual attention layer를 거쳐 얻어집니다.
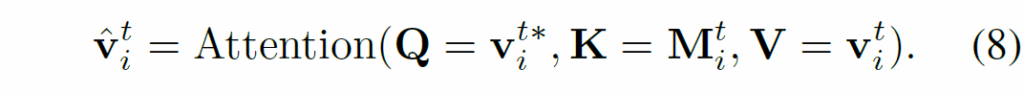
이후, enhance된 마지막 feature representation은 트랜스포머 인코더에 넣어서 subject와 object에 대한 representation을 생성합니다. MSGM은 이렇게 특징을 점차 정제하고, 이전 지식을 활용해 낮은 분산을 유지하여 visual bias를 완화했다고 합니다.
Iterative Relation Generator
기존의 unbiased SGG 기법들은 대부분 visua. representation만을 바탕으로 물체 간 predicate를 직접 예측하는 방식을 채택했는데, 저자들은 이런 기존 방식이 마치 사람이 충분한 문맥 정보 없이 시각적 단서만을 기반으로 관계를 추론하는것과 비슷하기에 semantic bias가 쉽게 발생할 수 있다고 합니다. 특히 context(문맥 정보)가 부족하면 모델이 학습 데이터에 포함된 분균형한 사전 분포(prior distribution)에 과도하게 의존하게 되어 relation prediction이 편향되기 쉬워집니다.
이 부분도 정보 이론적 수식적 전개를 이어나가는데, 충분한 문맥 정보가 부족할 때 의미적 편향이 발생하며, 이는 predicate을 예측할 때 uncertainty가 증가하는 결과를 유발하고 모델이 학습 데이터의 편향된 prior distribution에 의존하도록 한다는 논지입니다. 다음 수식 (9)를 보면 entropy H로 표현하는데, {v}_{i}, {v}_{j}는 각각 주어와 목적어의 feature representation을, S는 추가 문맥 정보를 의미합니다. 문맥 S가 추가적으로 제공되면 관계 예측의 uncertainty가 감소하게 됩니다. 조건부 엔트로피 감소 -> 모델의 uncertainty 감소 -> 편향된 prior distribution에 대한 의존 감소(+사전 분포의 영향력 감) 의 논리 흐름입니다.
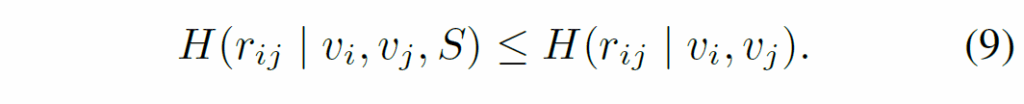
여기에 베이즈 정리와 likelihood를 도입하여 쭉쭉 수식을 정리해나가는데, 정리하면 다음과 같습니다.
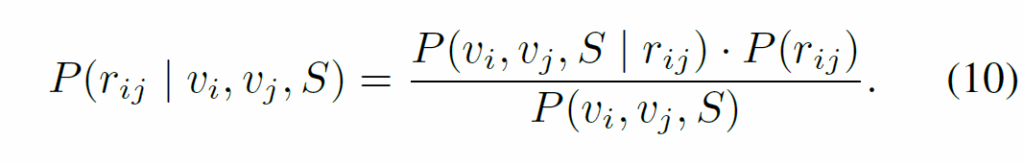
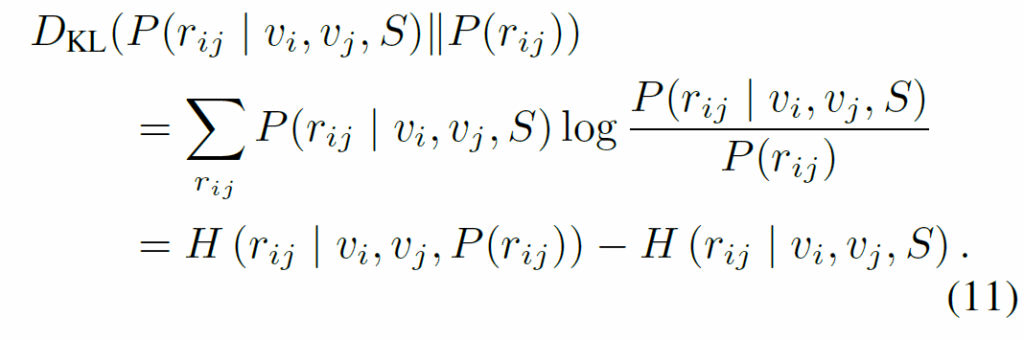
수식 (10)에서 P({r}_{ij})는 사전 분포(prior)이고, P({r}_{ij} | {v}_{i}, {r}_{j}, S)는 사후 분포(posteriors)입니다. (11)에서 {D}_{KL}는 prior와 posterior 간 KL divergence입니다. 요약하면, KL divergence가 클수록 모델이 사전 분포에 덜 의존하고, 문맥 정보를 더 효과적으로 활용한다. context 정보를 추가하면 편향된 사전 분포에 덜 의존하게 된다. 문맥 정보를 넣어서 편향을 완화하자. 정도가 되겠네요. 이렇게 수식으로 이론적 배경을 깐 다음 모델 내부에 문맥 정보를 통합해야 한다고 주장하며 이에 기반한 모델을 제안합니다. 이렇게 제안된 Iterative Relation Generator(IRG) 모듈은 반복적으로 semantic debiasing을 수행하게 됩니다.
첫번째 iteration에서는 각 주어-목적어 pair에서 의미 정보를 추론해 semantic embedding을 생성합니다. t 프레임에서 각 s-o pair (j,i)에 대해 다음과 같이 복합 객체 특징(composite object features)을 구성하게 됩니다
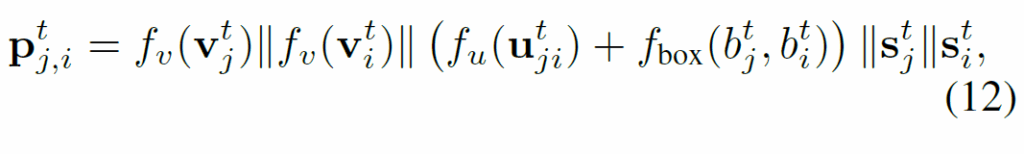
여기서, {v}^{t}_{j}, {v}^{t}_{i}는 주어/목적어의 visual feature represenation을, {v}^{t}_{ji}는 RoIAlign을 통해 추출한 두 객체 간 union box feature map, {s}^{t}_{j}, {s}^{t}_{i}는 GloVe에서 얻은 semantic embedding, f는 feature transform 함수입니다.
그 다음에 relationship 을 예측해서 attention, spatial, contacting 등과 같은 카테고리를 얻습니다. 이 예측 결과 중 가장 확률이 높은 semantic embedding을 선택하여 통합된 triplet embedding을 얻습니다.
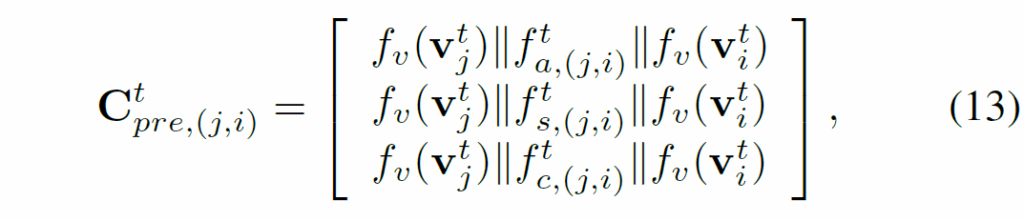
여기서 {f}^{t}_(a,(ji)}, {f}^{t}_(s,(ji)}, {f}^{t}_(c,(ji)}는 각각 attention, spatial, contacting 관계에 대응하는 semantic embedding입니다.
이후에 계측적 문맥 정보를 잘 활용하기 위해 Hierarchical Semantics Extractor(HSE) 모듈을 사용합니다.
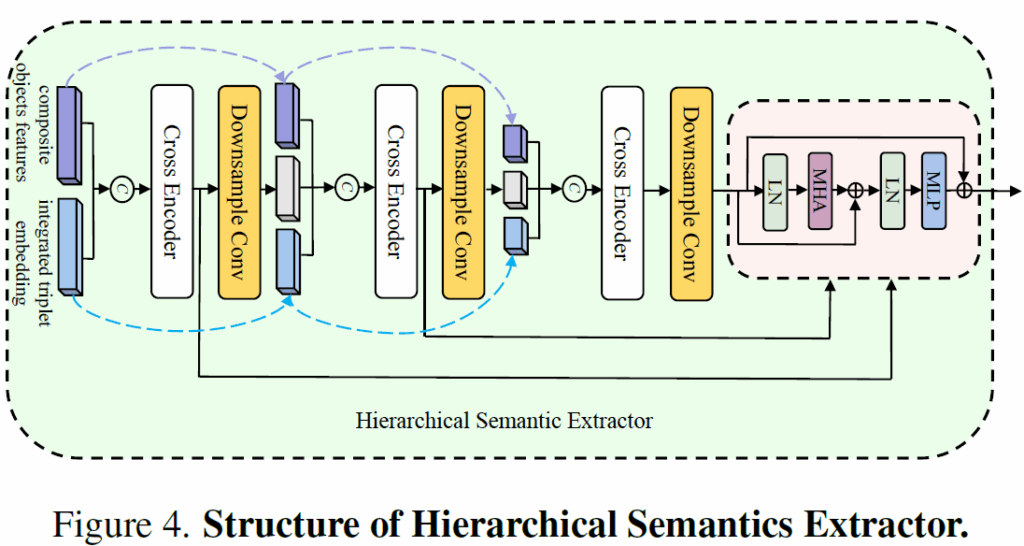
저자들이 새롭게 제안한 것은 아니고, 기존 video-text retrieval연구의 multi-hierarchical feature fusion기법을 활용한 것이라고 합니다. 복합 객체의 특징(composite object features)와 integrated triplets을 결합해 보다 세분화된(fine-grained) 시각적/의미적 representation을 생성할 수 있다고 합니다.
복합 특징 {p}^{t}_{j,i}를 다음과 같이 주어/목적어 기준으로 분해하고,
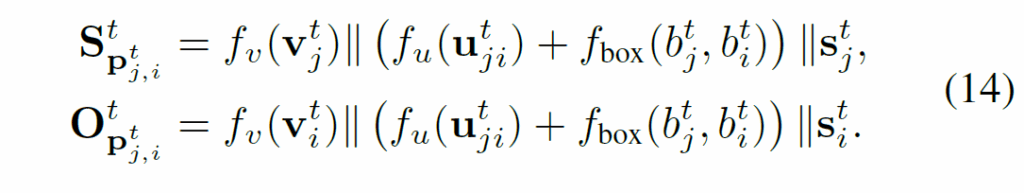
integrated triplet embedding {C}^{t}_{pre(j,i)}도 다음과 같이 분해합니다.
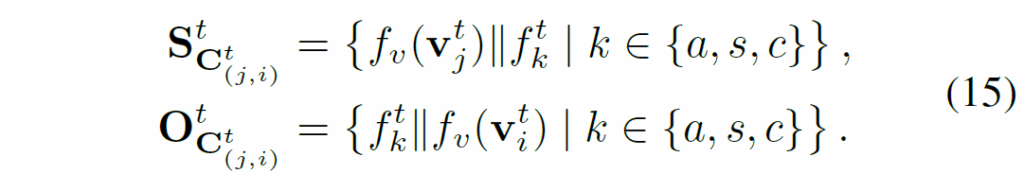
이렇게 만들어진 finegrained한 representation은 이전 CA layer의 다운샘플링된 임베딩과 함께 conv layer를 거쳐 다음 CA layer의 입력으로 넣게 됩니다. 이렇게 구조를 계층적으로 구성하면 모델이 multi-level contextural information을 포착할 수 있게 하여 결과적으로 불확실성과 편향된 prior distribution에 대한 의존을 줄일 수 있다고 합니다. 말은 복잡하게 써져 있지만 결국 문맥 정보를 주입하기 위한 모듈을 추가했다 정도로 정리할 수 있을 것 같아요.
IRG를 N번 반복한 후, 최종 객체 간 predicate는 spatial encoder, temporal encoder를 거쳐 예측하게 됩니다. 기존의 VidSGG에서 사용한 구조를 그대로 사용한 것 같아요.
Training and Testing
학습 단계에서는 우선 MGSM으로부터 생성된 객체 특징(object features)을 활용해 초기의 scene graph를 생성합니다. 이후 N번 반복을 하게 되면, HSE(Hierarchical Semantic Extractor)를 통해 hierarchical visual-semantics fusion embedding을 생성합니다. 앞에서 설명했듯 memory representation {M}^{t}_{i}는 0인 텐서로 초기화되고, triplet도 무작위로 초기화됩니다. total loss는 다음과 같습니다.
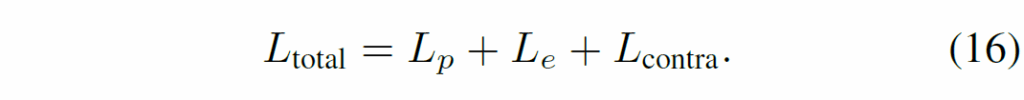
위 total loss 식에서 {L}_{p}, {L}_{e}는 각각 predicate와 entity에 대한 classification loss입니다. 둘 다 cross-entropy로 학습됩니다. 마지막 contrastive loss term은 이전 unbiased scene graph generation in videos라는 CVPR2023 논문에서 사용한 것을 그대로 사용했다고 하네요.
학습 이후엔, MGSM 모듈의 visual debiasing을 통해 각 객체를 예측하게 되고, IRG 모듈은 semantic debiasing을 수행한다고 합니다.
Experiments
데이터셋으로는 VidSGG 평가에 널리 사용되는 Action Genome이 사용되었고, 지표는 SGG에 주로 사용되는 mean Recall@K(mR@K)가 사용되었습니다. detector로는 AG dataset으로 학습된 ResNet101기반 Faster RCNN이 사용되었다고 합니다.
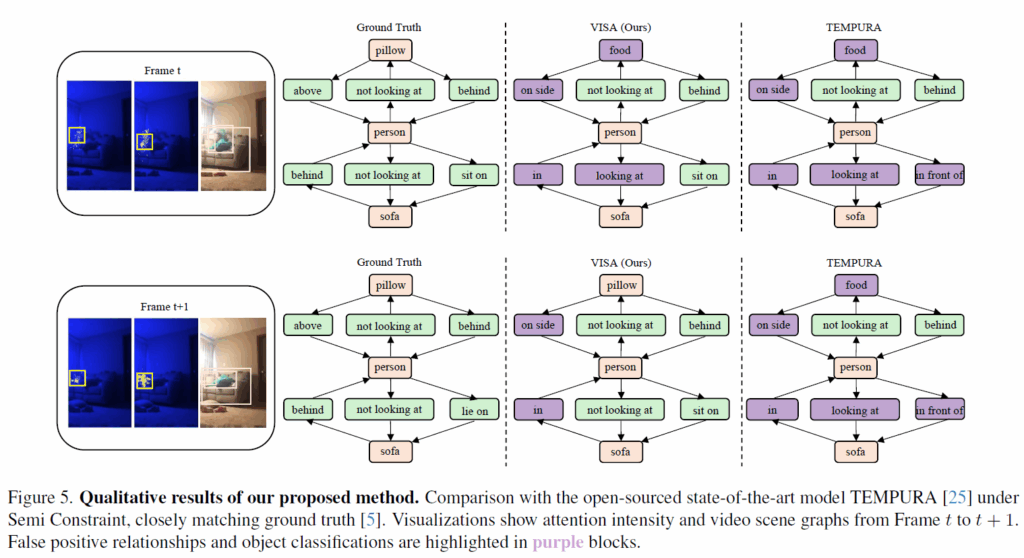
먼저 Fig5의 정성적 분석입니다. semi constraint라는, 하나의 장면에서 여러 predicate을 기술하는 조건에서 수행되었다고 합니다. FP relationship이나 객체를 잘못 예측한 것이 보라색 박스로 표시된 것인데, 기존의 TEMPURA라는 방법론과 비교했을 때 제안 프레임워크가 t -> t+1로 진행됨에 따라 visual debiasing을 통해 object representation을 효과적으로 강화했다고 합니다. 추가적으로 문맥 정보를 활용해 단일 프레임 안에서 저 정확한 predicate(ex : sit on)을 추론해 낼 수 있었다고 합니다. 이를 통해 SG의 문제를 visual bias와 semantic bias로 나누는 것이 타당하며, 제안 프레임워크가 각각 bias를 효과적으로 완화한다고 주장합니다.
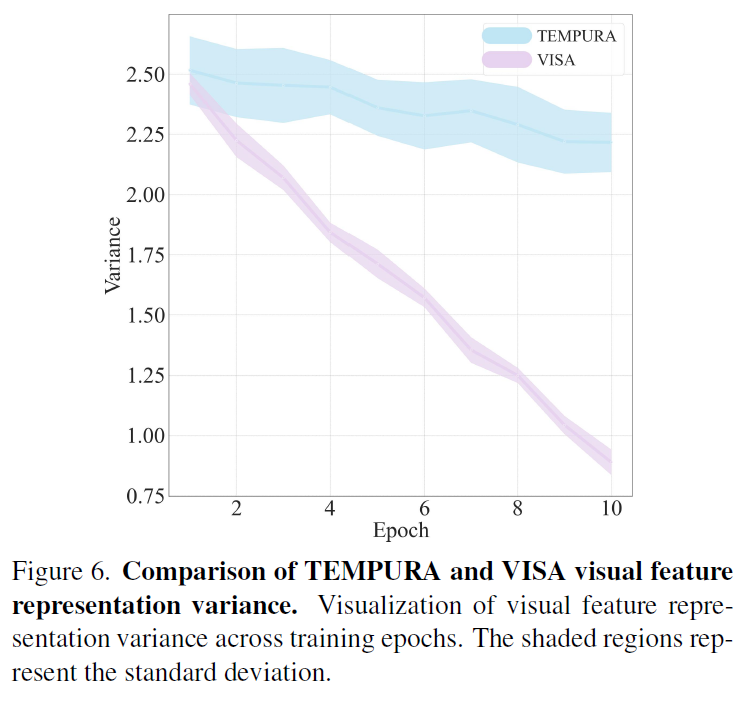
Fig6은 학습 epoch 동안의 feature representation의 분산/표준편차를 나타낸 것입니다. TEMPURA는 분산과 표준편차가 커서 feature representation의 안정정이 떨어지지만 VISA는 확실히 분산과 편차가 적습니다.
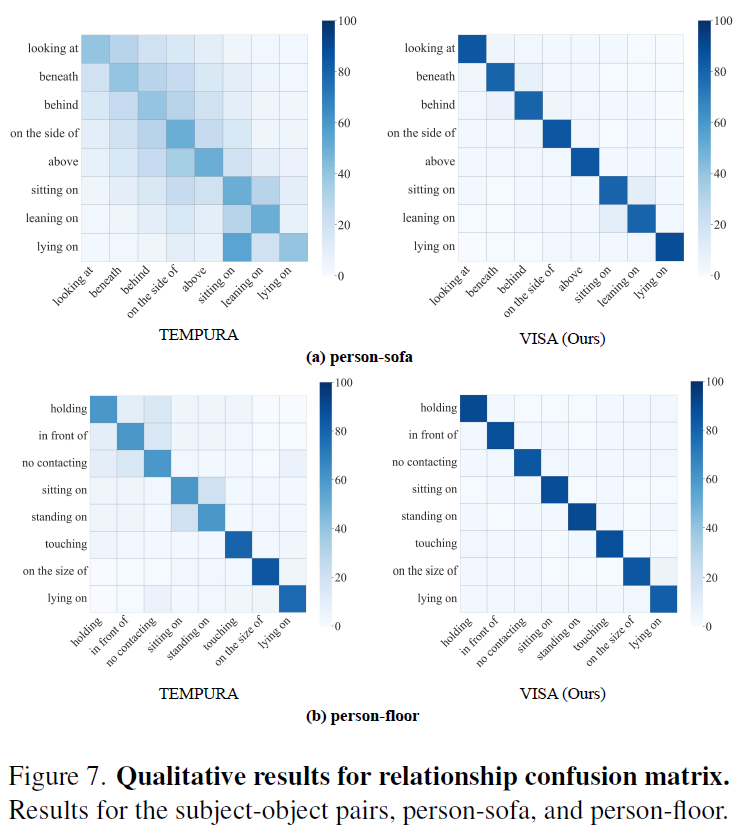
Fig 7에는 TEMPURA와 VISA의 relationship 예측 결과를 confusion matrix로 나타낸 것인데, VISA가 prior distribution에 대한 영향이 줄어 debiasing 측면에서 강점을 보입니다.
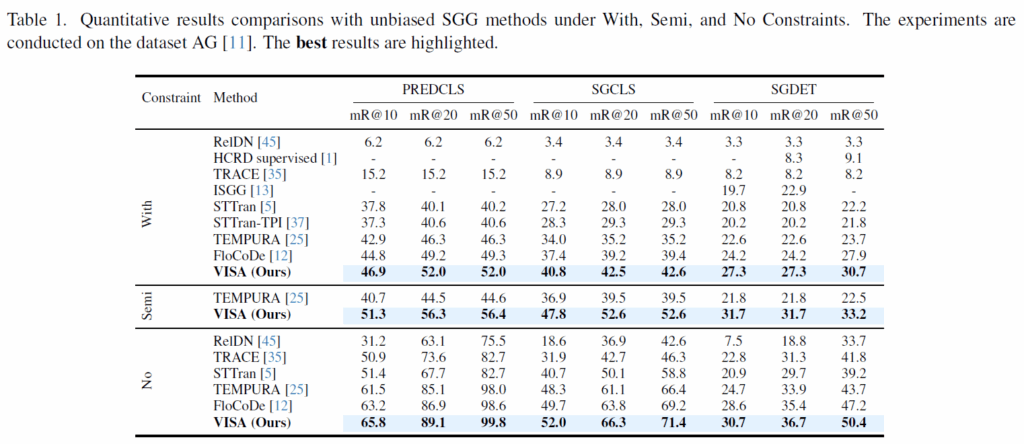
정량적으로도 그 성능을 보였는데, 모든 mR@K에서 VISA가 SOTA를 달성했습니다. 저자들이 제안한 debiasing 전략이 효과적임을 알 수 있습니다. 하나 아쉬운것은, R@K 대비 mR@K를 함께 보여주면 debiasing이 더 눈에 들어오지 않았을까 하는 생각이 드는데 원래 이쪽이 mR@K만 리포팅을 하는지, 아니면 저자들이 자신감이 없어서 R@K를 리포팅 하지 않은 것인지는 모르겠네요.
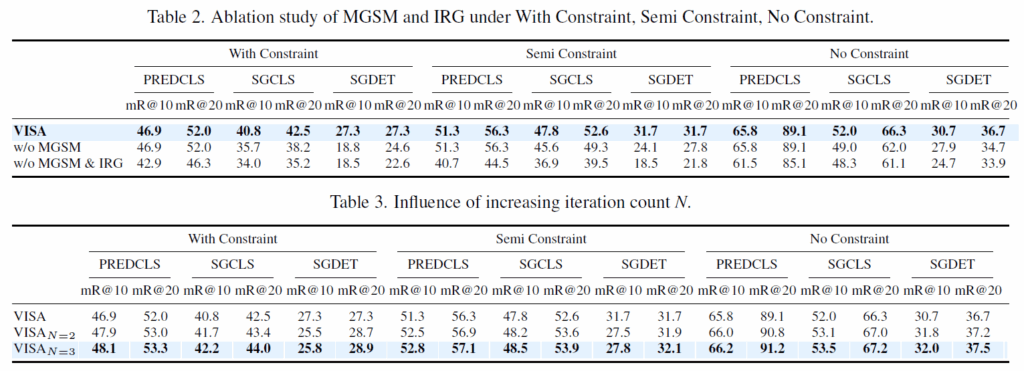
ablation 결과 확인하고 리뷰 마무리하도록 하겠습니다. Table 2는 MGSM, IRG 모듈에 대한 ablation인데, 이를 통해 VISA의 visual debiasing / semantic debiasing 모듈이 미치를 영향을 분석했습니다. 각 모듈을 제거함에 따라 성능이 감소해서, 각 모듈이 효과적으로 debiasing을 수행한다고 하네요. 한편, PREDCLS task의 경우 GT 시각 정보(박스가 주어짐)를 기반으로 하기 때문에, MGSM을 적용하지 않았아서 그 영향이 나타나지 않은 것이라고 합니다.
처음으로 비디오 데이터 기반의 논문을 리뷰해 보았는데, 낯선 요소들이 많네요. 이번 기회에 틈틈히 논문을 더 읽어보여 익숙해져야겠습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
본문에서 relationship 을 예측해서 attention, spatial, contacting 등과 같은 카테고리를 얻는다고 하셨는데, 각각이 의미하는게 무엇인지 궁금합니다.
또한 multi-hierarchical feature fusion기법을 통해서 context 정보를 추가해준다고 하셨는데, 이게 어떻게 context 정보를 추가해줄 수 있는지가 이해가 되지 않습니다.
어느 부분을 통해 context 정보가 학습되는 것인지 알려주시면 감사하겠습니다.
attention, spatial, contacting 카테고리의 예측이라 함은, 3가지 다른 특성을 가진 별도의 relation embedding을 병렬로 예측해서 활용한다고 생각하시면 됩니다. Figure 2에서 연두, 주황, 하늘색 으로 나타난 분포를 보시면 이해가 쉬울 것입니다. (Action Genome 데이터셋에서 각 relation의 annotation이 크게 attention, spatial, contacting 3가지로 나뉘어져있습니다)
multi-hierarchical feature fusion 기법은 context 정보를 추가하는게 아니라, composite object feature와 integrated triplet을 결합해 보다 fine-grained한 visual / semantic representation을 얻기 위함입니다.