안녕하세요, 예순 일곱번째 X-Review입니다. 이번 논문은 2025년도 CVPR에 올라온 Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models입니다. 바로 시작하도록 하겠습니다.
1. Introduction
본 논문은 Zero-shot Anomaly Detection task와 함께 reasoning까지 수행하는 모델을 제안하는 논문입니다. 기존 전통적인 unsupervised AD에 대해서 먼저 소개를 드리자면, 이는 학습 때는 normal한 sample들을 통해 normal feature들의 분포를 학습하게 되고, inference시에 normal sample과 anomaly sample을 함께 보면서 anomaly를 찾아내는 식으로 연구가 되어 왔습니다. 이런 방식은 비교적 얻기 힘든 데이터인 anomaly sample을 학습 중에는 사용하지 않기는 하지만, 여전히 많은 양의 normal data가 필요하다는 전제가 있긴 합니다. 하지만, 의료 영상 같은 경우에는 data 보안 privacy 문제가 있을 수도 있고, 혹은 정상이나 이상 여부를 사람이 직접 분류해야 한다는 부담이 있기도 해서 실제 현실에서는 이런 normal data가 많다는 전제가 성립이 안될수도 있죠. 따라서 본 논문에서는 normal data없이도 zero shot으로 이상 여부를 판단하는 쪽으로 접근하고자 하였습니다.
또한, 맨 처음에 이 zero shot AD와 함께 reasoning까지 수행하는 모델이라고 언급을 했었는데, 저자는 지금까지 Anomality와 관련된 reasoning 연구는 잘 이뤄지지 않았다고 합니다. 그 이유로는 일단, 대규모 데이터셋이 없기 때문인데요. 따라서 지금까지의 방법론들은 단순하게 입력 image에 대해서 이상일 확률인 anomaly score만 예측하고 있지 왜 anomaly인지에 대한 설명은 output으로 뱉지 못한다고 볼 수 있습니다. 하지만, 실제 산업 현장이나, 의료 현장에서는 단순 이게 anomaly인 영상이다 에서 그치는게 아니라 왜 이상인지 설명하고, 그에 대한 시각적인 근거까지 제공받기를 원합니다.
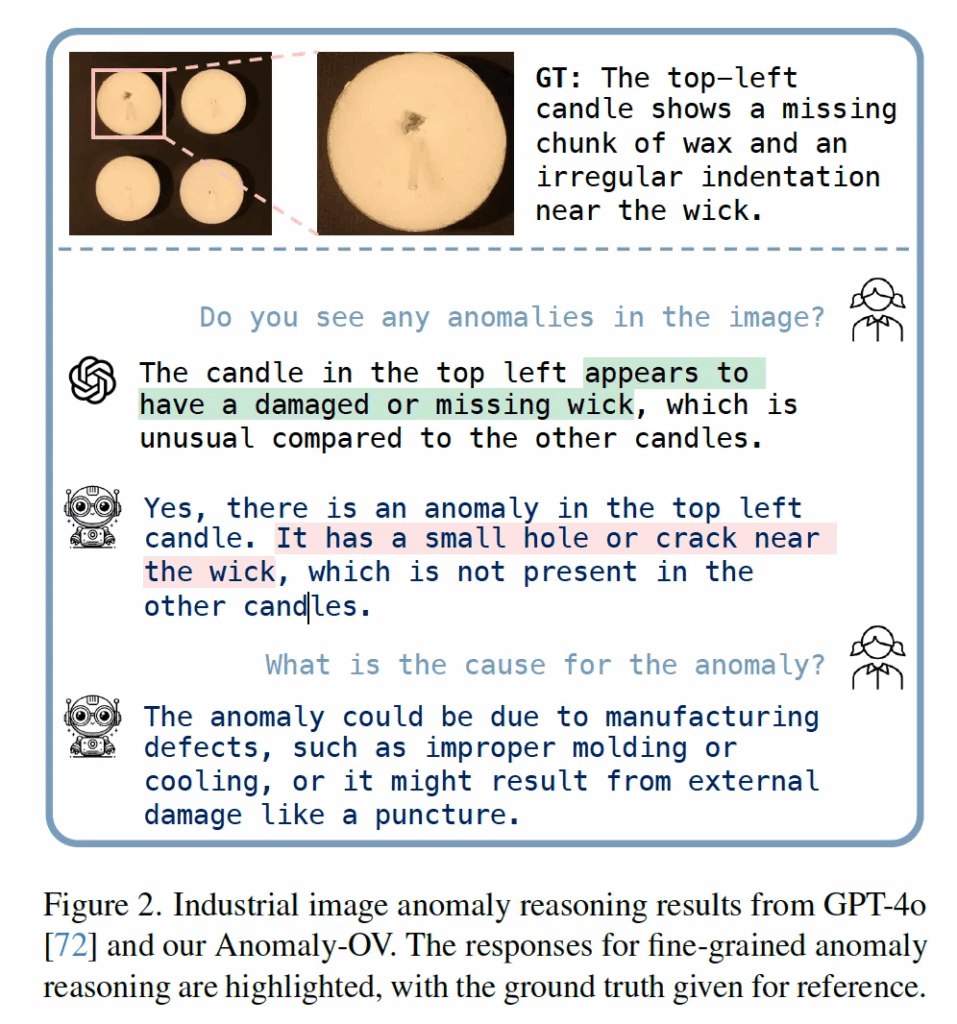
위 Fig2를 보시면, 최신 MLLM 모델인 GPT-4o도 AD task에서는 reasoning을 잘 못한다는 점을 확인할 수 있습니다. 구체적으로, 입력 이미지와 GT를 보시면 좌상단 초에 촛농이 일부 빠져 있고, 심지 근처에 움푹 들어간 부분이 있는 것을 확인할 수 있습니다. 이에 대해 “Do you see any anomalies in the image?” 라고 질문했을 때 GPT-4o는 심지가 없거나 손상됐다고 판단을 하고 있는 것을 확인할 수 있죠. 즉, 좌상단 candle이 anomaly인 점에서는 잘 판단했다고 볼 수 있겠지만, 왜 anomaly인 점에 대해서는 잘못된 reasoning을 하고 있습니다.
본 논문에서는 이런 AD task에서의 reasoning 연구를 위해 본 논문에서 anomaly detection 특화된 instruction tuning용 대규모 image-text pair 데이터셋인 Anomaly-Instruct-125k라고 하는 데이터셋과 함께, 이 reasoning 성능을 평가할 수 있는 VisA-D&R이라고 하는 데이터셋을 제안합니다. 또한 앞서 봤던 figure2처럼 기존 MLLM이 fine-grained한 anomaly를 정확하게 탐지하거나 설명하지 못하는 점을 해결하는 Anomaly-OV라고 하는 ZSAD(zero shot anomaly detection0 모델을 제안합니다.
본 논문의 contribution은
- 처음으로 anomaly detection과 reasoning을 위한 instruction tuning dataset과 벤치마크를 구축했다는 것
- Anomaly-OV라고 하는 anomaly detection, reasoning 특화 sota 모델을 제안했다는 것
으로 정리해볼 수 있겠습니다. 이 데이터셋 구축 과정과, Anomaly-OV 모델에 대해서는 아래 Method 파트에서 설명드리도록 하겠습니다.
2. Method
2.1. Preliminary
본 논문에서 제안한 모델에 대해 살펴보기 전에, 베이스로 삼은 MLLM에 대해 먼저 설명드리도록 하겠습니다. 제안된 Anomaly-OV는 LLaVA-OneVision 모델을 base로 삼았는데요. LLaVA-OneVision은 크게 Visual Encoder와 Projector, LLM으로 구성됩니다. 이 중에 Visual Encoder 관련해서는 CLIP 기반으로 구성이 되어 있는데 기존 CLIP이 원래 224×224 크기의 고정된 해상도만 처리하도록 학습되었기 때문에, LLaVA-OneVision에서는 AnyRes라는 방식을 사용하였습니다. 이 AnyRes는 단순하게 고해상도 영상을 사전에 정해둔 수만큼의 여러 crop으로 나눈 다음에 각각을 encoding해서 pooling으로 합치는 방식입니다.
2.2. Architecture Overview
이제 본 Anomaly-OV의 구조에 대해 살펴보자면, 먼저 LLaVA-OneVision과 동일하게 AnyRes라고 하는 image-splitting 기법을 사용합니다. 그럼 고해상도의 입력 영상이 7개의 crop으로 나눠질 수 있겠고 다음 식1처럼 표현해볼 수 있겠죠.
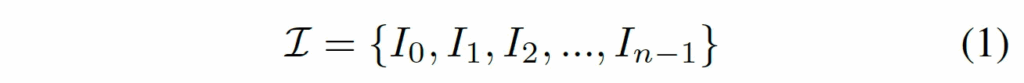
여기서 I_0은 resized된 원본 영상이고 I_{j≠0}는 다 crop들 입니다.
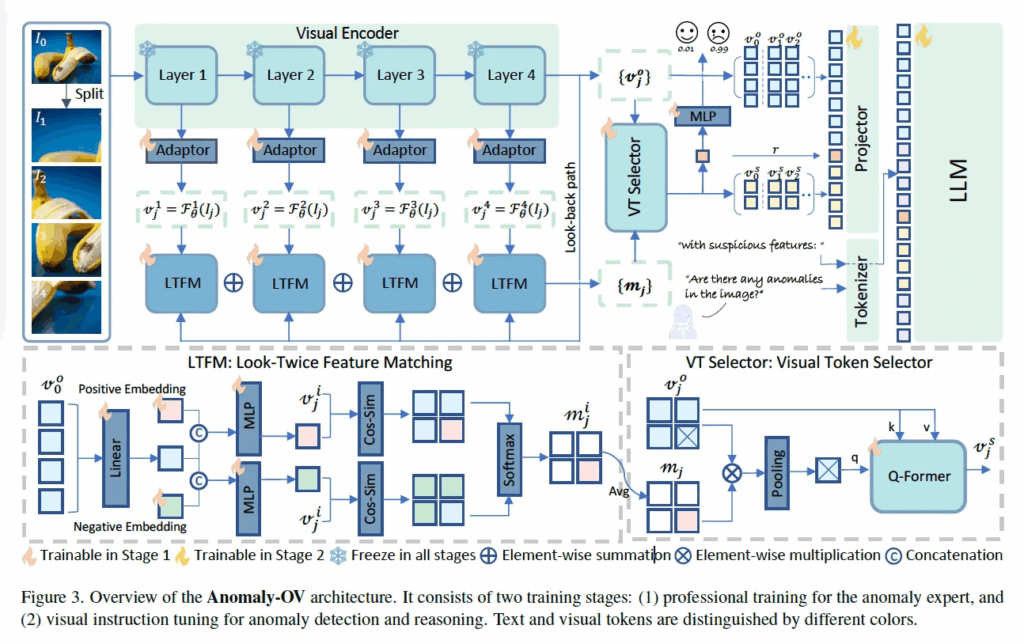
위 Fig3이 전제 프레임워크 그림인데, 맨 좌상단에 보심 원본 영상과 이를 split한 영상들이 한번에 들어가는 것을 확인할 수 있습니다. 이 image I는 visual encoder F_θ 입력으로 들어가 visual feature {v^o_j}가 나오게 됩니다. 그림에서 보이는 것처럼 visual encoder는 layer4개짜리 ViT와 각 layer별 Adapter로 구성되어 있구요.
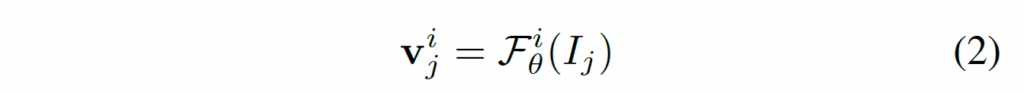
각 layer별 vector는 위처럼 표현해볼 수 있겠습니다.
또, 원래 CLIP같은 경우에는 text encoder 타고 나온 embedding과 visual embedding간의 align을 맞추도록 학습을 하기에 이미 encoding된 image feature가 Zero shot AD를 수행하기 위한 class 정보를 갖고 있다고 판단하여, 무거운 text encoder를 빼고 오직 visual model 자체에서 나오는 정보를 사용하고자 하였습니다. 이를 위해 설계된게 저기 그림에 LTFM이라고 하는 모듈 부분입니다. LTFM은 Look-Twice Feature Matching 약자인데, 이름 그대로 두 번 보도록 하는 것입니다. 구체적으로는 원본 영상으로 뽑은 visual feature v^o_0이 global 정보를 담고 있기에 얘를 레퍼런스 삼아서 crop 이미지들을 하나씩 다시 보면서 의심되는 token을 찾는 역할을 합니다.
그담 그림에서 LTFM까지 통과한 다음을 보면 VT Selector라고 하는 모듈을 통과하는 것이 보입니다. 이 VT Selector는 앞 단계 LTFM에서 수상하다고 판단된 visual token들 중에 정말 중요한 것들만 골라서 LLM에 넘겨주는 역할을 합니다. LLM이 모든 token들 중에 뭘 봐야 하는지 모르기에 이 의심스러운 토큰들에 집중하도록 하는 것이죠. 근데, 모든 경우에 anomaly 관련 질문을 하지 않을수도 있으니까(예를 들어 “Can you describe the content of the image? 같은 질문) original visual feature도 입력으로 넣어줍니다.
2.3. Look-Twice Feature Matching
전체적인 동작과정을 살펴봤으니, 다음으로 LTFM 모듈에 대해서 자세히 살펴보도록 하겠습니다. 이 LTFM 과정은 global 정보를 담고 있는 v^o_0를 기반으로, 특정 영역이 정상인지 이상인지 구분할 수 있는 embedding을 만드는 역할을 합니다. 우선, global vector v^o_0에서 유용한 정보만을 추출하기 위해 layer linear T^o_i를 태운 다음, 두 learnable한 embedding e+와 e-와 concat해 각각의 MLP G+, G-를 태워 anomaly를 표하는 vector d+와 normal vector인 d-를 뽑아냅니다.
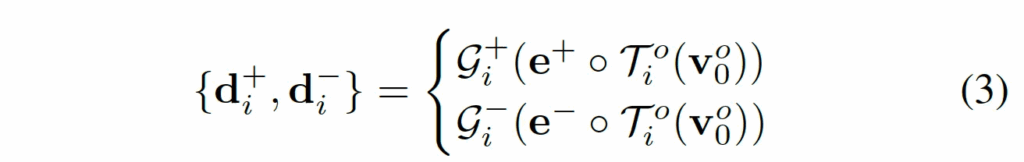
수식으로 나타내면 다음과 같습니다. 이렇게 뽑아낸 d+와 d-는 이후에 이미지의 각 부분이 normal인지 anomaly인지 판단하는데 사용되는데, 이 과정은 CLIP의 zero shot classification과 유사하게 각 feature vector와 기준이 되는 feature vector간의 cosine similarity를 기반으로 합니다.
구체적으로 앞에서 생성된 anomaly vector d+와 normal vector d-를 사용해, ViT의 i번째 layer에서 추출된 j번째 crop patch feature v^i_j와의 유사도를 계산하고 이를 softmax로 정규화해 해당 token이 anomaly일 확률을 뽑아내는 것이죠.
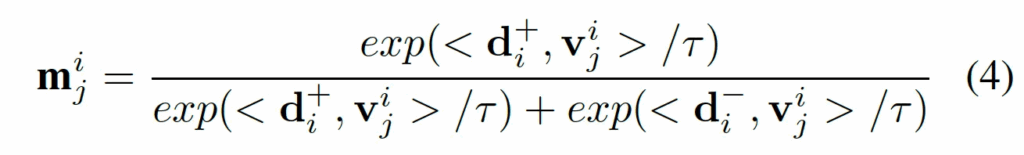
식4처럼 이렇게 나온 각 layer별m^i_j를 평균내어 최종 token significance map을 뽑아냅니다.
이 과정은 사람이 어떤 물체를 검사할 때 사용하는 방식에서 모티브를 얻었다고 하는데요.
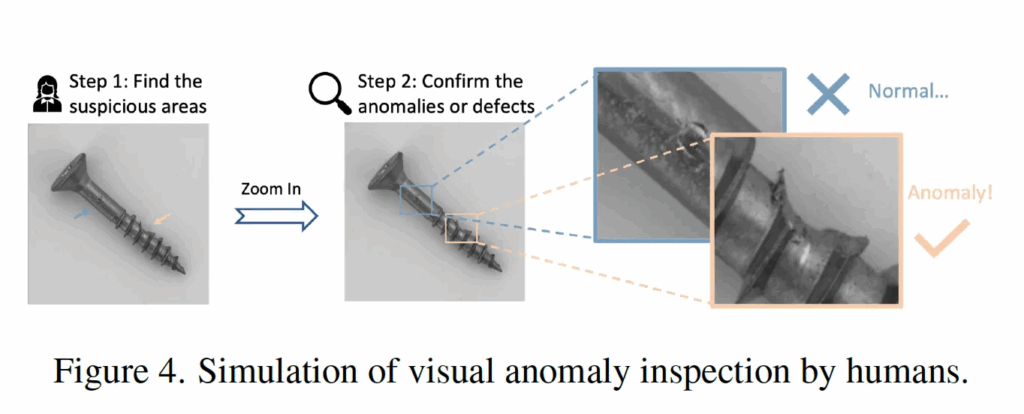
그림4처럼 사람이 어떤 물체에 대해 검사를 할 때 전체 이미지에 대해서 첫 번째로 의심스러운 영역을 찾은 다음에, 그 영역에 대해서 다시 살펴보는 이런 방식을 따른 것입니다. 이 LTFM에서는 전체 global feature를 기준으로 normal/anomaly vector를 뽑는 부분이 첫 번째 1st look이라고 할 수 있겠고, 이후에 각 crop image patch feature를 normal/anomaly vector와 비교해 하나하나 확인하는 부분이 2nd look이라고 보면 되겠습니다.
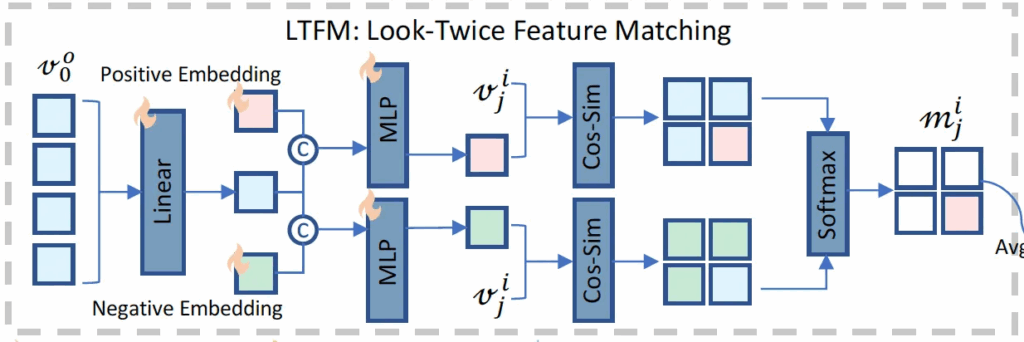
방금 설명드린 부분은 위 그림을 참고하면 될 것 같습니다.
2.4. Visual Token Selector
다음으로는 VT Selector 모듈에 대해 설명드리도록 하겠습니다. 이 모듈은 고해상도 image를 crop해 처리하는 최근 MLLM 구조 특성상, 한 이미지에 대한 visual token구사 수천 개(LLaVA-OneVision의 경우에는 7290개 token)에 이르는 문제를 해결하기 위해 도입되었습니다. 이렇게 많은 토큰 들 중에서 특정 task에 중요한 token만을 선택해야 하는데, 일반적인 LLM은 해당 도메인에 대한 지식이 없으면 어떤 token이 중요한지 스스로 잘 판단해내지 못하죠. 이를 보완하기 위해 Anomaly-OV는 어떤 token이 중요한지 판단하는 expert를 제안합니다.
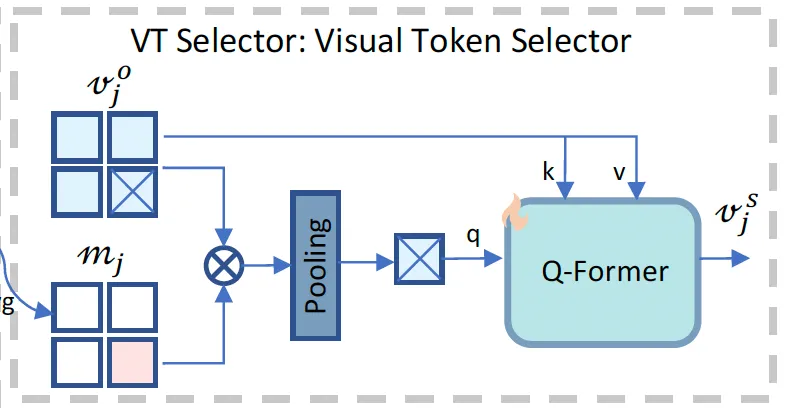
구체적으로는 위 그림처럼 동작하는데, 먼저 각 crop image의 visual token {v^o_j}에 앞서 LTFM 단에서 뽑은 significance map m_j를 곱해 수상하지 않은 token은 0으로 만들어 무시하도록 하고, 이 수상한 token만 강조하도록 필터링합니다. 이후, 이렇ㄱㅔ 필터링된 token들을 spaitl average pooling P를 통해 q_j로 pooling합니다.
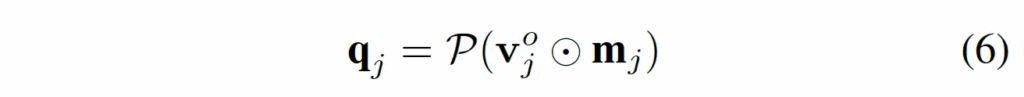
방금 말한 부분이 식6과 같구요. 마지막으로 Q-Former를 태우는데, 앞서 풀링까지 해 뽑은 q_j를 query로 원본 visual token v^o_j를 key value로 하여, v^s_j를 뽑아냅니다.
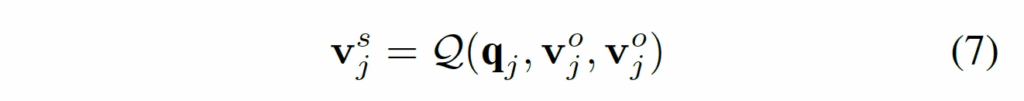
이렇게 뽑은 feature는 수상한 의미를 담고 있는 visual feature고, 이는 이후 text generation하는 LLM에 입력으로 들어가 reasoning하는데 활용됩니다. 결국 요약하자면, VT Selector는 anomaly expert가 고른 수상한 의미를 LLM이 보다 잘 이해하도록 정제해 전달해주는 역할을 한다고 보심됩니다.
2.5. Inference and Loss
Anomaly Prediction
다음으로 loss부분에 대해 설명을 드리자면, 원래 기존 AD 모델들은 입력으로 들어오는 image에 대해 이 image가 anomaly일 확률을 prediction하는 식으로 동작했습니다. 본 논문에서 제안된 Anomaly-OV도 이를 따르고자 했습니다.
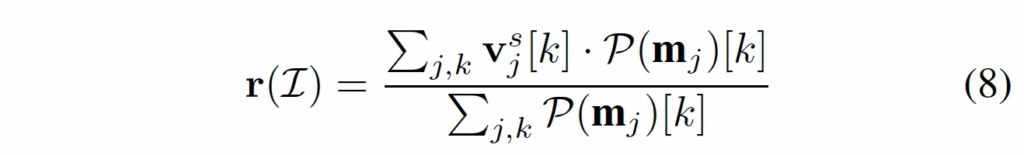
Anomaly-OV는 image는 원본 image와 함께 crop image가 합쳐져 입력으로 들어가기에, 각 crop 별 anomaly 정도를 합쳐 anomaly score를 내고자 하였습니다. 식8을 보면 각 crop feature들이 VT-Selector 모듈에서 Q-Former 까지 타고 나온 정제된 feature인 v^s_j와 그 crop에서 어느 patch가 anomaly인지 그 정도를 담고 있는 가중치 map인 m_j와의 가중평균을 하게 됩니다.
이렇게 나온 r(I)가 image 전체에 대해 anomaly 정도를 담고 있는 vector입니다.
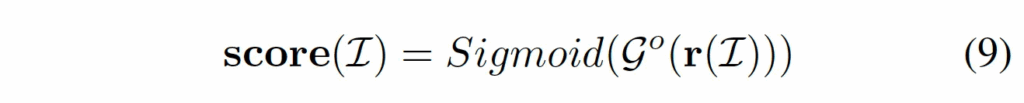
이후 r(I)를 MLP 태운 후 sigmoid를 통해 최종 anomaly score를 뽑게 됩니다. 학습 시에는 BCE loss를 사용하게 되고, 이 loss를 통해 Anomaly-OV 내부에 있는 LTFM과 VT-Selector를 학습시키게 되는 것이죠. LLM을 통해 생성한 prediction에 대해서는 cross entropy loss를 통해 학습됩니다.
3. Dataset and Benchmark
3.1. Anomaly-Instruct-125k
방법론 설명은 이쯤 하고, 다음으로 본 논문에서 제안한 데이터셋에 대해 짧게 설명드리도록 하겠습니다. 이전까지는 image 기반의 AD와 그에 대한 reasoning을 함께 학습할 수 있는 multi-modal instruction data가 거의 없없고, 한계도 존재했습니다. 예를 들어 AnomalyGPT라고 하는 모델은 prompt tuning 기반의 dataset을 제안하기는 했는데, 규모도 작고, instruction 다양성도 떨어지면서 단순 localization 중심 instruction으로 구성이 되어 있었죠. 이런 문제를 해결하기 위해 본 논문 저자들은 Anomaly-Instrut -125k를 제안합니다.
여기서는 class이름과 anomaly 종류를 조합해 간단한 text prompt를 만든 다음, 여기에 bbox가 표시 되어 있는 image를 함께 GPT-4o 입력으로 넣어서 이미지를 설명하는 text를 생성하도록 하였습니다. 이후, LLaVA방식과 유사하게 예시를 던져주는 in-conetect learning 방식으로 instruction을 만들었죠.
여기서는 기존 데이터셋인 MVTec AD, BMAD, Anomaly-ShapeNet, Real3D-AD, MVTex-3D AD를 사용했으며, 이 데이터셋을 가져와 사용했음에도 다양성이나 규모가 부족하다고 판단하여 GPT-4o+Google image 검색을 사용해 추가적으로 anomaly image와 text를 수집하고 정제하는 파이프라인을 도입하였습니다. 이 과정을 통해 수집한 72,000장의 WebAD가 추가되어 125k 구모의 Anomaly-Instruct 데이터셋을 구축하였습니다.

데이터셋 예시는 위 fig5를 보심 되는데, 보시면 대부분 multi-turn 대화 형식으로 구성이 되어 있고, 보시면 anomaly 감지나 설명같은 low-level reasoning 부터, 이 anomaly의 원인을 추론하거나 개선하려면 어떻게 해야하는지에 대한 보다 복잡한 understanding을 요하는 reasoning까지 포함하는 질의응답을 포함하고 있습니다.
3.2. VisA-D&R
다음으로는 본 논문에서 제안한 평가 벤치마크인 VisA-D&R입니다. 이 VisA라고 하는 데이터셋은 원래 Industry AD task에서 사용되는 데이터셋인데, 이를 베이스로 reasoning을 평가할 수 있는 벤치마크를 구성했다고 보심 됩니다. 이 VisA-D&R은 앞선 Anomaly-Instruct-125k와 유사한 방식으로 question-answer 형식으로 구성을 하였습니다.

예시는 위 Fig6에서 확인할 수 있으며, 보시다시피 평가 방식이 크게 두 가지로 나뉘는데 먼저, detection에 대해서는 “Are there any defects for the object in the image? please reply with ‘yes’ or ‘no’.”라고 하는 질문에 대해 yes/no로 대답하도록 하고, 이 결과를 Acc, Precision, Recall, F1score등으로 정량적으로 평가하였습니다.
다음 Reasoning 부분에 대해서는 또 두 가지 level로 나눌 수 있는데, 그림에서 보이는 Q1, Q2 부분이 low level reasoning으로 단순 어느 부분이 anomaly인지, 무엇이 anomaly인지를 설명하는 부분이 하나 있으며, 하이라이팅된 Q3, Q4 부분처럼 왜 이런 이상이 생겼는지? 혹은 어떻게 개선할 수 있는지에 대해 답하는 complex reasoning 부분입니다. 이에 대한 추론 결과에 대해서는 ROUGE-L, SBERT, GPT-Score를 사용해 정량적으로 평가하였습니다.
4. Experiments
4.1. Training&Evaluation
실험 부분 살펴보기 전에, 간략히 학습 평가 방식에 대해 설명드리자면, 본 모델은 2-stage로 나뉘어 학습됩니다. 먼저 stage1에는 anomaly expert 모듈(LTFM, VT-Selection)을 학습시키며 이는 Zero-Shot AD task를 수행하기 위함입니다. 이때는 Anomaly-Instruct 데이터셋을 사용하며, 평가는 VisA 데이터셋을 사용하여 zero shot AD를 평가하였습니다. 다음 Stage2에서는 앞 stage에서 학습한 anomaly expert와 visual encoder를 freeze하고 projector와 LLM만 학습합니다. 이 stage는 instruction-following 능력을 향상시키는 목적이 있죠. 이때는 단순 Anomaly-Instruct 데이터셋 외의 원래 기존 LLaVA-OneVision에 사용했던 instruction 데이터셋도 같이 사용해 모델의 일반화 성능을 유지할 수 있도록 하였습니다.
4.2. Zero-shot Anomaly Detection
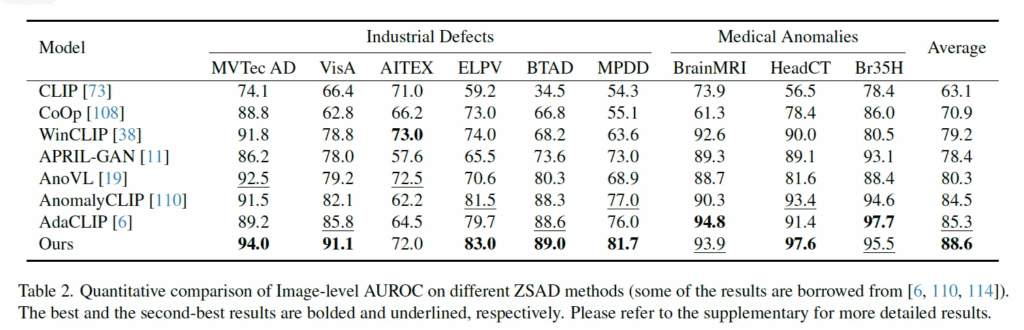
먼저 본 논문에서 제안된 Anomaly-OV와 기존 ZSAD(zero shot AD) 방법론과의 성능 비교를 한 표를 살펴보도록 하겠습니다. 위 Table2를 보면, 위에 쭉 적혀있는 것들은 여러 dataset이름이며, image-level AUROC score가 평가지표인데 다른 zero shot 방법론과 비교하여 여러 데이터셋에서 SOTA를 달성하였습니다. 여기서 볼만한 점은, 기존 AdaCLIP이나 AnomalyCLIP 등 이런 방법론들은 text encoder를 사용하는 방법론인데, 이와 비교하여 성능이 뒤지지 않음을 보이면서 text encoder 없이도 충분히 AD가 수행 가능하다는 점을 보여준다는 점입니다. 이런 점에 대해서 저자는 WebAD라고 하는 대규모 인터넷 데이터를 추가로 학습했기 때문이라고 언급하고 있습니다.
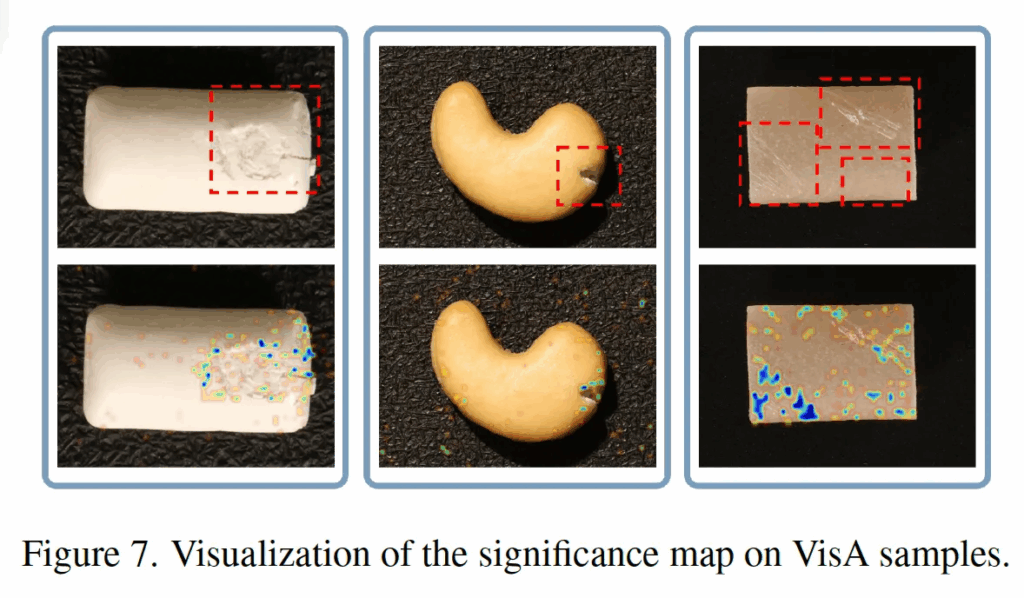
정성적으로 살펴보면, 위 Fig7은 singificance map을 시각화한건데(아래 행), 이를 보아 모델이 gt mask를 통해 학습하지 않더라도 자동으로 알아서 anomaly 영역 주변에 높은 중요도를 부여하는 token selection 구조를 갖고 있는 것을 확인할 수 있습니다. 즉, 본 논문에서 제안된 anomaly expert(Look Twice Feature Matching과 VT Selector)가 효과적이라는 점을 보여주는 것이죠.
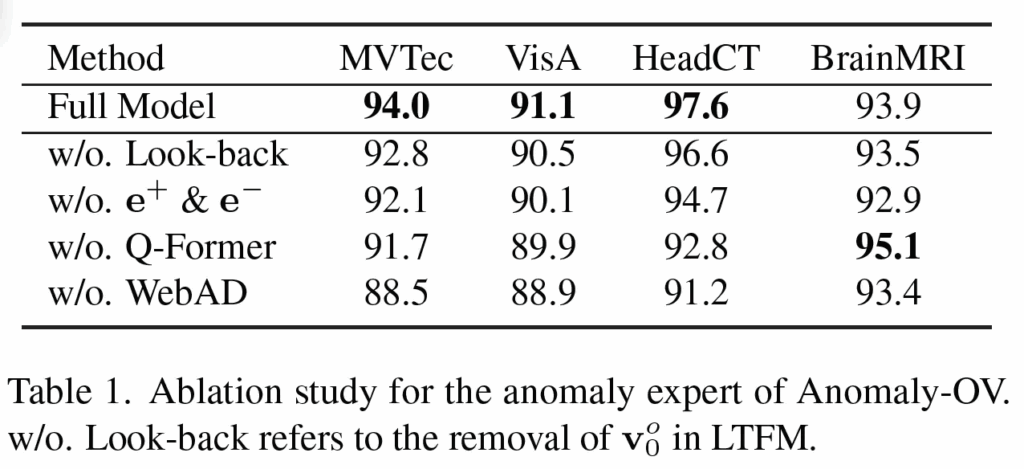
또 위 Table 1의 Ablation study 결과가 나와있는데, look-back과 normal/anomaly를 구분하는 learnable한 embedding(e+, e-)를 제거했을 때 성능이 떨어지는 것을 보아 이 역시 모델이 class-aware한 anomaly를 잘 학습한다고 볼 수 있겠습니다. 또, Q-Former를 적용했을 때, BrainMRI 데이터셋에서는 좋은 성능을 보이지는 않았지만, 나머지 벤치마크에서는 token aggregation의 효과를 보여주고 있습니다.
4.3. Anomaly Detection & Reasoning
다음으로는 Anomaly-OV가 기존 MLLM과 비교해 봤을 때 anomaly detection 및 anomaly reasoning 성능이 얼마나 개선되었는지에 대한 실험 결과를 살펴보도록 하겠습니다.
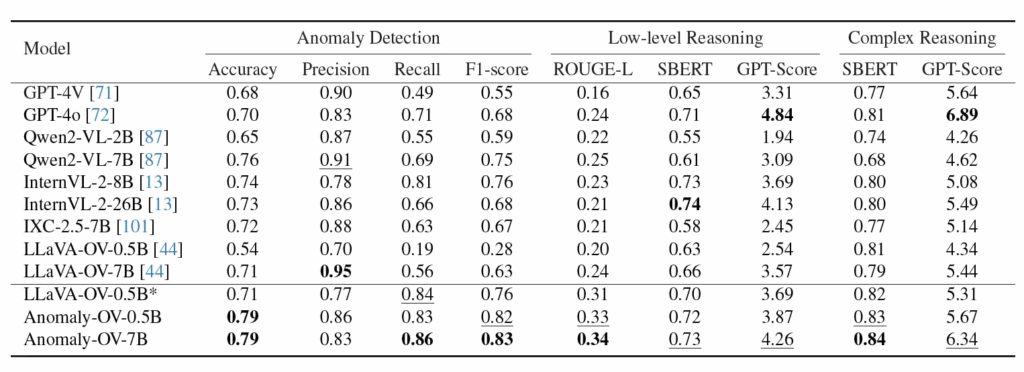
위 Table을 보시면, zero shot으로 VisA-D&R 데이터셋에 대해 평가한건데 기존 MLLM과 비교하여 더 정확한 성능을 보입니다. 여기서 볼만한 점은 모델명 옆에 모델 크기도 함께 적혀져 있는데, 일반적으로 LLM 크기가 클수록 reasoning 성능은 높아지지만, detection 성능은 비례해서 늘어나지 않는다는 점입니다. 또, 대부분의 MLLM은 precision이 굉장히 높은 반면에 recall이 낮아 실제 anomaly를 잘 놓치는 경향이 있다는 점을 볼 수있습니다.


또, 위 Table3이랑 Table5를 보면 GPT-4o는 reasoning을 잘 하기는 하지만, anomaly 자체를 설명하는데 부정확한 경우가 많은데, 구체적으로 바로 위 표의 Do you see any anomalies in the image?라고 하면서 영상을 입력으로 넣었을 때, gt는 우하단에 변색이 되어있다는 점인데 GPT-4o의 답은 마카로니가 반으로 잘려 있다는 점이 anomaly라고 하는, 잘못된 reasoning을 하고 있는 것을 확인할 수 있죠.
또 다시 그 정량적인 표로 돌아가서 보면 LLaVA-OV-0.5B*가 구분선 아래에 있는 것을 확인할 수 있는데, 얘는 그냥 LLaVA-OV-0.5B를 Anomaly-Instruct-125k 데이터셋으로 fine-tuning한 버전입니다. fine-tuning하지 않은 모델과 비교했을 때 precision도 올랐고 recall도 0.19에서 0.84로 엄청난 성능 향상을 보여주면서 제안된 데이터셋의 효과를 확인할 수 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
그림3에 모델 구조를 보면 Tokenizer 입력으로 “with supicious features”라고 적힌 문장이 들어가는 것 같은데 이건 모델 학습할 때 항상 같이 들어가는 것인가요? 혹은 매 들어오는 이미지에 따라서 manually하게 바뀌는건지 궁금합니다. 또, 본 방법론이 이전 연구들과는 다르게 text encoder를 사용하지 않았음에도 더 좋은 성능을 보인 것으로 이해했는데 text encoder 없이 준수한 성능을 낸 직접적인 원인이 무엇인가요?
감사합니다.
댓글 감사합니다.
그림3에 있는 “with suspicious features:” 라고 적힌 부분은 학습, 추론 단 둘 다에서 고정되게 항상 들어가게 됩니다.
또, text encoder 없이 더 좋은 성능을 낸 이유에는 우선 굉장히 많은 데이터(webAD 기반)로 학습한게 가장 큰 요인일 것 같구요. 또 본 논문에서 제안한 LTFM의 경우 중요한 token만 LLM으로 넣는 과정을 수행하면서 text 없이 visual feature 자체만으로 학습하도록 한 점도 이유로 들 수 있겠습니다.