이번에 가져온 논문은 제가 OWL_ViT에 파인튜닝 기법으로 사용해볼 FLYP 논문입니다. 기존에 존재하는 다른 파인튜닝 방법론보다 성능이 더 좋다는 것이 논문에 구체적으로 설명되어 있기도 하고 연구하고 있는 파이프라인에 적용되어 있어서 논문을 읽어볼 겸 X-Review에 들고왔습니다. 생각보다 단순한 내용이라 간단하게 읽어보시면 좋을 것 같습니다.
Abstract
CLIP이 여러 벤치마크에서 SOTA를 달성한 시점에서 CLIP을 이용한 여러 downstream task에 대해서 사전학습과 동일한 방식으로 fine tuning 하는 것이 좋은 성능을 내는 것을 저자가 실험적으로 증명하게 됩니다.
이러한 방식으로 7 distribution shift 부분과 6 transfer learning , 3 few-shot learning 벤치마크에서 기존 파인튜닝 방법론보다 더 좋은 성능을 내게 됩니다.
여기서 말하는 distribution shift란 모델이 학습할 때 사용한 데이터분포와 실제 테스트 환경에서 의 데이터 분포가 달라지는 현상입니다.
기존 방식보다 저자의 방법론을 사용하는 것이 OOD 데이터셋에서는 4.2퍼센트 더 좋은성능을 보이고 SOTA였던 LP-FT 방식보다 ID OOD 데이터에서 모두 1퍼센트 더 높았다고 합니다.
Introduction
CLIP과 ALIGN 등의 비전-언어 대규모 대조학습 모델들은 zero shot 분류기로서의 추가학습 없이도 괜찮은 성능을 가지며 OOD에 대한 강건성이 뛰어나다는 장점이 있습니다.
그런데 이후 파인튜닝으로 ID에 대한성능을 더 올리고 싶을 수가 있는데 소수의 라벨을 이용해서 fine tuning을 하게되면 ID 에 대한 성능은 오르고 ( 학습시킨 레이블) 기존에 가지고 있던 OOD에 대한 강건성은 떨어진다는 단점이 존재합니다.
이 논문은 이러한 현상을 어떻게 완화할지에 대한 연구이며 파인튜닝 과정의 미묘한 변화로 OOD에 대한 강건성이 줄어드는 것을 완화시킬 수 있는 것을 논문의 제목을 통해 보여줍니다. ( finetune like you pretrain )
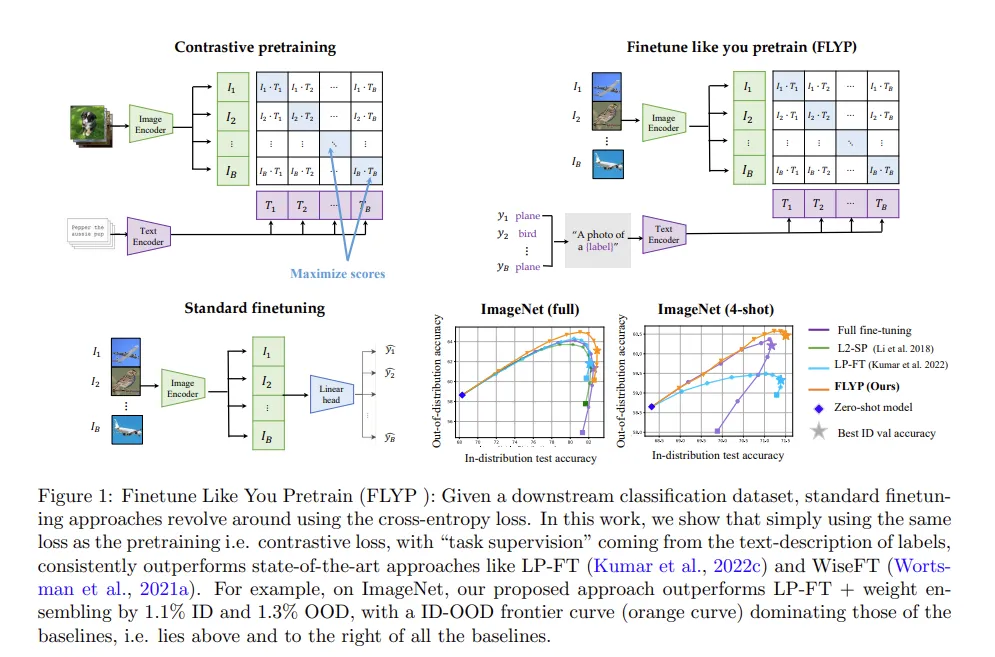
보통 Cross-entropy loss로 fine tuning 하는 것을 저자는 사전학습때와 같은 대조학습 기법으로 fine tuning하게 됩니다. 기존 SOTA인 LP-FT & WiseFT 보다 나은 성능임을 보입니다.
LP-FT 방법론은 Linear probe + Full tune 방식으로 처음에는 모델 대부분을 freeze하고 분류기만 학습한 다음 전체를 미세조정하는 방법론입니다.
즉 고정된 embedding 공간에서 선형 분류기만 학습시켜 빠르게 적응시키고 전체 embedding 공간을 downstream task에 맞춰서 조정하는 방법이라 생각하면 됩니다.
논문에서 다루지는 않지만, 해당 방법론은 약간 변형하면 FLYP에서도 적용할 수 있어서 성능이 개선될지 알아보고싶은 부분입니다. (CLIP 인코더의 마지막 한두개의 layer만 먼저 학습하고 다시 full fine tune 하는 방식이 작동될지 궁금합니다.)
WiseFT (사전학습된 파라미터와 파인튜닝된 파라미터를 가중평균(앙상블)
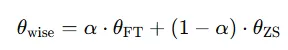
저자는 위의 2stage 인 linear probe & full tune 과 가중치 앙상블 같은 방식처럼 여러 파인튜닝 세부방법론이 존재하지만, 정해진 정답같은 것은 없다고 합니다.
이전에 방식들의 공통점은 결국 모두 표준적인 supervised 의 학습방식, 즉 Cross-entropy loss를 사용하는 이미지 분류기 학습의 약간의 변형이며 이는 사전학습의 과정을 고려하지 않고 supervised 방식만 적용하면 suboptimal 즉 최적이 아닌 결과를 낳는다고 주장합니다.
저자의 방식은 기존의 방식들보다 더 단순한 대안인데도 더 나은 성능임을 어필하는데 pretrain때 사용하던 contrastive loss를 그대로 분류기를 파인튜닝에 사용하면 더 나은 성능을 낼 수 있다는 것입니다.
즉 class label을 프롬프트의 형태로 변환하고 이 프롬프트와 이미지 임베딩간의 contrastive loss를 최소화하는 방식으로 학습을 진행합니다.
FLYP의 이런 방식은 이전의 LP-FT나 WiseFT 없이도 일관되게 더 나은 성능을 보이며 기존 방법들과 앙상블 할때조차 더 FLYP가 좋은 시너지를 낸다고 합니다.
그리고 저자의 FLYP는 minibatch 안에 동일한 클래스에 속한 여러 이미지가 들어있더라도 이들 관의 관계를 모두 negative로 간주하고 대각선의 pair만 positive로 간주하는게 성능이 더 좋았다고 합니다. 논문에서 alblation 실험으로 class overlap을 고려한 false negative를 제거해봤지만 성능이 오히려 떨어졌고 이건 저자들이 예상치 못한 결과였다고 합니다. 저자도 왜 그런지 명확하게 설명되지는 않지만 결국 pretraining 방식(CLIP)과 동일한 방식을 유지하는 것이기 때문이라고 추측합니다.
그리고 개인적인 생각으로는 해당 논문에서 평가한 벤치마크들의 class 숫자가 1000개 ~ 200, 100, 62 개 정도였던 것으로 보아 사실상 overlap이 생길 확률이 낮다고 생각하고, 재학습할 데이터의 class숫자가 적다면 class간의 overlap이 많이 생길테니 그런 overlap들을 다시 positive로 바꿔주는 방식이 더 성능이 나을수도 있다고 생각합니다. 또한 같은 클래스에 여러 prompt를 넣을 수 있지만 단순히 a photo of a {class} 만 사용하더라도 충분히 좋은 성능을 냈고 prompt를 다양화 하더라도 성능이 크게 달라지지 않았다고 합니다.
그리고 저자는 이들의 contribution이 새로운 loss 를 제안한 것이 아닌 사전에 pretrain 때 사용했던 loss를 그대로 쓰는 단순한 방식임을 강조하고 극도로 단순한 방식이 기존의 복잡하고 정교하게 pretrain 하려고 했던 방법론들보다 훨씬 잘 작동한다는 사실을 정량적으로 증명한 것이라고 설명합니다. 그러면서 zero shot classifer 를 supervised 방식으로 fine-tune 할때 standard로 FLYP 를 채택하는 것을 추천한다고 합니다.
FLYP: Finetune like you pretain
FLYP는 pretraining objective ( contrastive learning) 을 downstream 분류 task에 그대로 이어서 적용하는 가장 자연스러운 확장입니다. 기존 clip 학습처럼 이미지를 인코딩하고, label을 텍스트로 바꿔 텍스트 인코딩한 뒤, 두 벡터를 contrastive learning으로 학습합니다. 파인튜닝 이후 예측 방식은 zero-shot과 동일하며 여전히 similarity를 비교해서 예측한다고 합니다. 그래서 모델 구조나 방식은 바꾸지 않고 표현만 fine-tune 하는것이 핵심입니다.
FLYP vs. standard finetuning
기존 fine-tuning 방법(LP, FT)은 일반적으로 이미지 인코더만 업데이트하며, 텍스트 인코더는 사용하지 않거나 고정된 채로 유지됩니다. FLYP는 텍스트 인코더도 업데이트를 진행하는데, 이는 단순히 기존 방법론이 텍스트 인코더를 업데이트 했다고 해서 성능이 나오는 것이 아님을 보입니다. ( 실험적으로 cross-entropy loss를 쓰면서 분류기의 linear head의 가중치를 기존 clip의 text embedding 가중치로 초기화하고 학습했지만, FLYP 방식보다 낮은 성능을 냈다고 합니다.)
즉 FLYP방법론에서의 텍스트 인코더를 학습 시키는 것이, 구조상 선형 분류기의 역할을 하는 부분도 학습시키는 것이기 때문에 텍스트-이미지 align이 된다고 주장하는 것입니다.
Experiments
저자는 3가지 실험 설정에서의 성능을 기존의 finetuning 방법론과 비교합니다.
- Distribution shift → CLIP의 원래 강점이자 FLYP가 성능 우위를 보인 실험 영역입니다.
- Few-shot learning → 클래스당 소수 샘플로 few shot 학습할때의 성능입니다.
- Transfer Learning → ID와 OOD 구분 없이 기존처럼 pretrain → downstream dataset에서 학습을 진행합니다.
사용한 데이터셋들은 ImageNet + OOD variants ( 기본 Imagenet과 5개의 OOD 버전인 V2,R,A,Sketch,ObjectNet 등이 있습니다.)
WILDS-iWildCam ( 야생동물 데이터셋으로 ID OOD는 카메라 위치와 배경 차이로 구분합니다.)
WILDS-FMoW ( 위성 이미지로 ID OOD는 시간대와 대륙의 위치 차이로 구분합니다.)
Caltech101 ( 101개의 일상 물체 클래스 입니다.) Stanford Cars (196개의 자동차 클래스 입니다.)
Flowers102 (102종의 꽃 종류 클래스입니다.)
PatchCamelyon ( 병리 이미지로 양성/음성 의 binary 클래스입니다.)
Rendered SST2 ( OCR된 감정 문장 임지로 긍정/부정 이진분류입니다.)
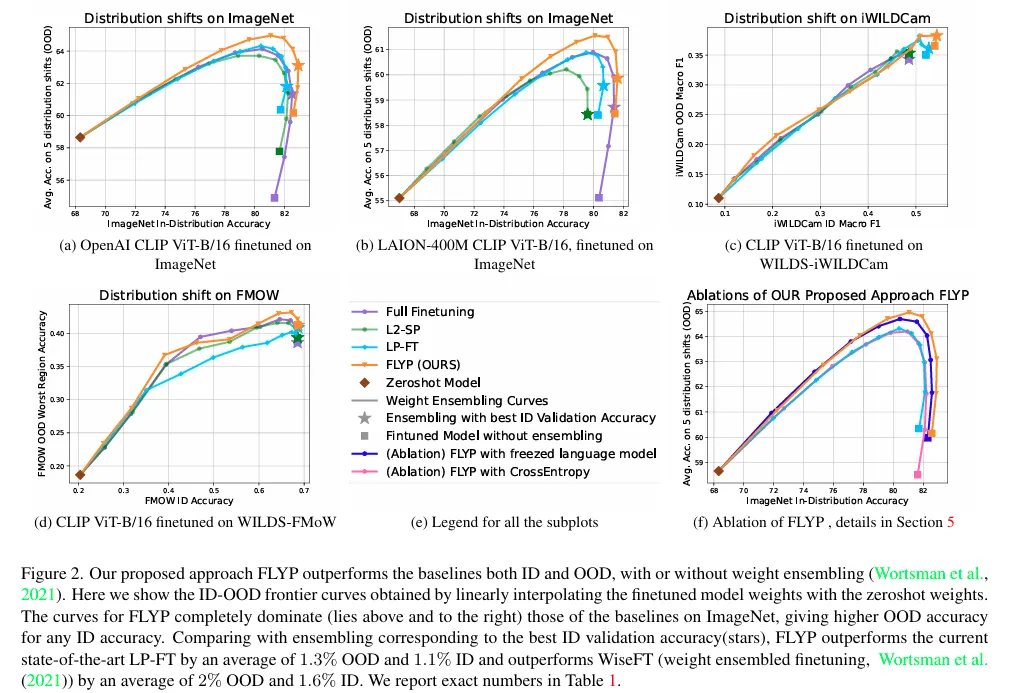
X축 : ID 정확도
Y축 : OOD 정확도
곡선 : 10개의 가중치 앙상블 수치를 이용하여 ID/OOD에 대한 성능을 interpolation하여 나타냅니다. 모든 조건에서 FLYP 의 곡선이 더 오른쪽 위에 존재하여 성능을 입증합니다.
그래프를 보면 곡선형태인 것도 존재하고 우상향 직선형태인 것도 존재하는데 이를 통해 학습할 데이터 분포에 따라 가중치 앙상블을 0.7~9정도 적용하는게 더 좋을 때도 있고 아예 적용하지 않는 것이 더 좋을때도 있는 것을 알 수 있습니다.
(f) 부분에서의 파란색과 분홍색 곡선의 ablation을 통해 단순히 대조학습을 이용하는 것 ( cross entropy → contrastive learning ) 때문에 성능이 오르는 것이 아닌 부분과 텍스트 인코더까지 학습하는 것 이 성능향상의 주된 원인이 아닌 점을 보입니다.
그리고 OOD에 대한 성능이 왜 오르는지에 대한 의문이 들 수 있는데 OOD 로 쓰인 Dataset이 사실 ID랑 완전히 domain이 다르지 않을 수도 있고, 추가적으로 학습을 시키는 행위 자체가 명시적인 label supervision을 주는 것이기 때문에 downstream task의 supervised learning이 추가적인 정보를 줬다고 생각할 수 있습니다.
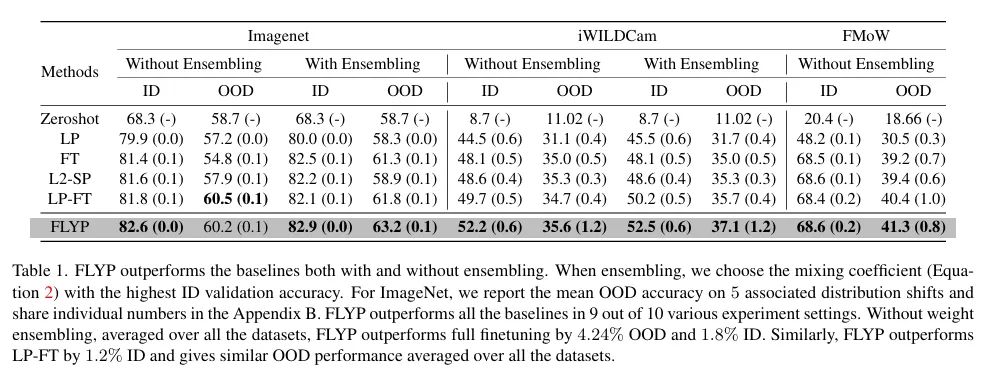
FLYP는 10가지의 실험 조건중 9가지에서 기존 기법들보다 뛰어난 성능을 보이며 그 1가지 마저도 앙상블을 적용했을때 기존의 방법론보다 더 나은 성능을 보입니다.
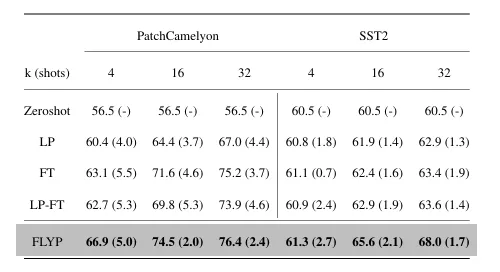
이진 분류 작업에서는 few shot 성능이 다른 기존 방법론 대비 성능 향상폭이 큰 것을 알 수 있습니다.
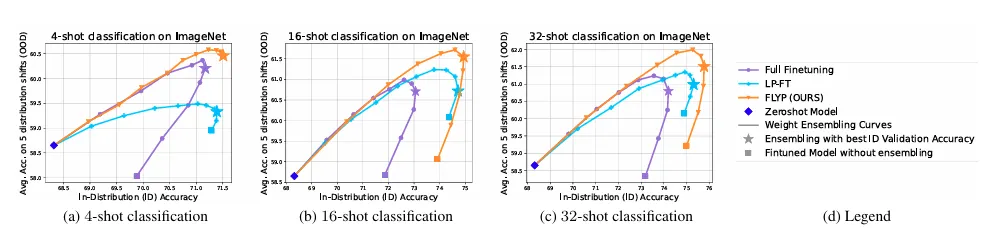
데이터량이 적었던 이진분류 이외의 ImageNet 에서도 few shot 성능이 기존 방법론보다 훨씬 뛰어남을 보입니다.
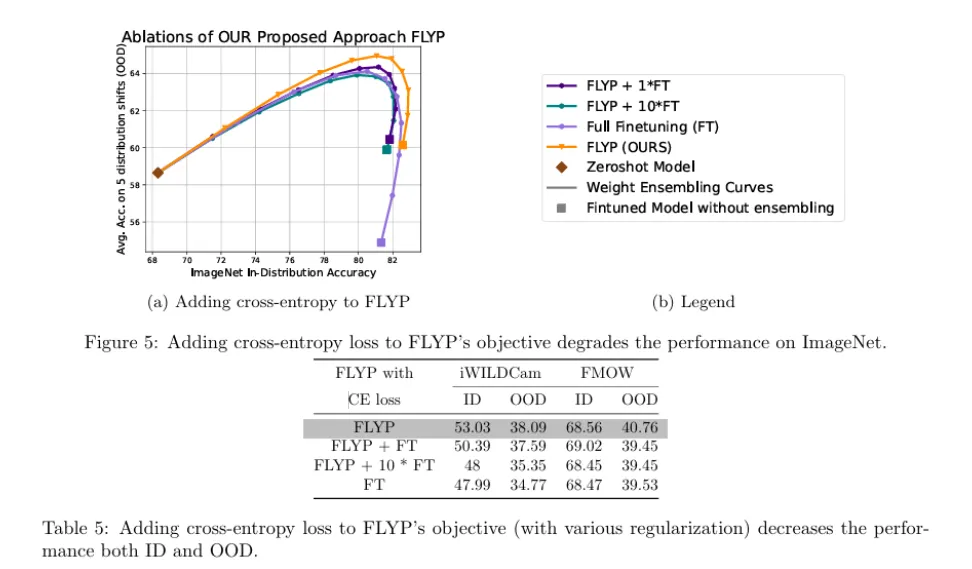
논문의 appendix에 존재하는 표로 FLYP 방법론에 기존의 fine tuning 방식의 cross-entropy를 추가하여 1대1 비율과 1대 10 비율로 학습했을때의 성능이 낮아짐을 보입니다. 즉 사전학습때의 방식을 유지하는 것이 성능향상의 비결임을 알 수 있습니다.
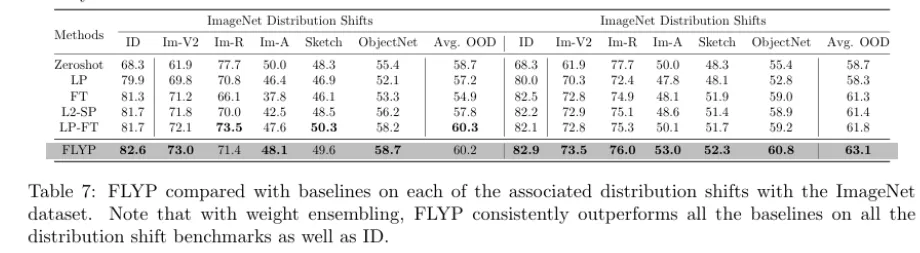
ImageNet 에서의 ID와 OOD 의 성능을 기존 방법론과 비교하는데, wegiht ensembling을 적용했을때 다른 방법론들보다 더 나은 성능을 보이고 적용하지 않을때에는 LP-FT와 거의 유사한 성능을 보입니다. 즉 대조학습을 이용한 파인튜닝이 weight ensembling 을 더 효과적으로 이용한다고 생각할 수 있습니다.
Conclusion
본 연구에서는 FLYP 방식을 제안하고 zero shot 비전 분류기의 파인튜닝에 적용했습니다. 라벨이 존재하는 데이터로 프롬프트 기반의 분류기를 파인튜닝할 때 기존의 방식인 Cross entropy 손실 대신 사전학습에 쓰인 contrastive loss를 동일하게 사용하는 간단한 방법으로 이전 방법론들의 성능을 능가한다는 것을 정량적으로 증명합니다. 저자의 방법론이 이미지-텍스트 기반 모델의 파인튜닝 과정에서 새로운 표준이 되어야 한다고 주장하는데 저자가 그냥 사전학습의 손실을 그대로 따라하는 것이 기존의 복잡한 방법론들보다 왜 더 좋은 결론을 내는지에 대한 현상을 완벽하게 이해되지 않은, 흥미로운 현상이라고 하며 아직 해결해야 할 과제라고 합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다. 리뷰 재밌게 읽었습니다.
서두에 Distribution shift에 대한 개념을 간단히 설명해주시고 이후에 평가에서는 ID, OOD 데이터셋에 대한 실험에 대한 결과만을 다루고 계셔서 궁금한점이 생겨서 댓글 드립니다.
Distribution shift랑 out of Domain과 같은 개념인지가 헷갈리네요. 만약에 다르다면 Distribution shift만을 평가하는 요소가 있었는지가 궁금합니다.
그리고 두번째 질문인데요 논문 제목에는 zero shot이라는 단어가 들어가 있어서 읽다가 좀 헷갈렸는데, 라벨이 있는 데이터셋을 사용하여 제로샷 모델인 CLIP을 텍스트 인코더까지 fine-tuning한 것 같은데, 논문에서는 해당 부분에 대해서는 제로샷 모델이라고 보는지가 궁금힙니다. 표에는 제로샷에 대한 실험이 있는데 리뷰에는 제로샷 성능에 대한 언급이 없어서 질문드립니다! finetunning을 했어도 CLIP의 일반화 성질이 조금은 남아있지 않을까 싶어서 궁금하네요. 감사합니다.
안녕하세요 우현님 답글 감사합니다.
질문에 대해 설명해드리자면 제가 ID OOD 에 대한 이름을 언급 안해서 out of domain이라 생각하신 것 같은데 각각 in distribution 과 out of distribution으로 학습떄와 비슷한 분포의 데이터이거나 다른 데이터 분포의 경우를 얘기하고 결국 OOD 데이터들이 distribution shift 된 데이터셋이라고 보면 됩니다.
그리고 파인튜닝을 한 순간부터 contrastive learning을 사용한것과 별개로 이미지 텍스트가 라벨을 가지고 형성된 정보로 파인튜닝 되었기에 zero shot이라고 보기 어렵습니다. downstream task에서의 지도학습을 loss함수만 바꾼거라고 생각하면 될 것 같습니다. 표에 있는 제로샷 실험은 파인튜닝전 clip의 zero shot 성능이고 clip의 의도 자체가 대규모 언어-텍스트 대조학습 모델로 downstream에 파인튜닝하기 좋게 만든 형태라 생각하시면 됩니다.
리뷰 잘 읽었습니다. 아이디어가 되게 심플한 방법이라 재밌게 읽었습니다.
제가 이해한 바로는 FLYP는 CLIP의 contrastive loss를 그대로 fine-tuning에 적용하면서, 각 이미지에 대해 하나의 텍스트 프롬프트만을 positive로 간주하고 나머지는 모두 negative로 처리하는 방식 같습니다.
이러다보니 궁금한 점이 하나 생기는데… 만일 하나의 이미지에 여러 객체(A, B, C)가 포함된 multi-label 상황에서는 어떤 텍스트를 positive로 선택하는지 궁금합니다. 예를 들어 A, B, C 세 가지 클래스가 동시에 존재하는 경우, 이 중 어떤 레이블을 대표 레이블로 삼아 contrastive pair를 구성하나요?
그리고 이런 구조가 multi-label classification이나 object-centric task에도 확장 가능한지 궁금합니다. 제 생각이지만 지금은 이미지 하나에 객체가 아주 많이 있는 데이터셋은 아닌 것 같은데.. 만일 하나의 이미지에 30개 이상의 객체가 있을 때는 이런 Finetuning 기법이 잘 워킹할지도 궁금합니다
안녕하세요 주영님 답글 감사합니다.
이해하신 방법이 맞고, 해당 방법론에서 쓴 벤치마크들에는 멀티라벨인 경우가 없습니다. 다만 만약 멀티라벨이 들어오는 경우라면 모두 positive로 고려해서 contrastive learning 과정중에서 positive인 부분을 늘려야할 것 같습니다.
그리고 드는 생각이 CLIP 자체가 대규모 이미지-텍스트 pair 로 학습될때 인터넷의 캡션을 긁어와서 학습했으니 흠 사실 여러 객체가 들어있는 상황이더라도 인터넷 캡션이 보통 중앙에 있는 피사체나 전체 scene을 설명한다거나 하나의 객체에 대해서만 캡션을 달아뒀을 확률이 높을 것 같아서 ( 뇌피셜이지만..) 결국 singe label 처럼 학습되지 않았을까 싶습니다.
이러한 이유로 multi label에서는 이미지를 각 라벨에 따라 poistive로 넣어줘야할 것 같고 사실 이 FLYP 에서 주장하는 것이 꼭 contrastive learning 뿐만 아니라 여러 foundation 모델에서 사전학습에 사용했던 loss를 그대로 파인튜닝에 사용하는 것이 사전학습된 모델의 표현공간을 유지한다는 것을 보인 것 같습니다. object-centric tast을 잘 모르지만 해당 task 에서 주로 사용하는 모델의 가중치를 가져와서 fine tuning 시 사전학습때와 동일한 loss를 쓰기를 권장하는.. 그렇게 생각합니다.
저희가 하고있는 OWL_ViT에 FLYP 를 적용하는 방법도 CLIP encoder를 가져와서 contrastive loss를 쓰는건데, 동시에 object detection head는 freeze 시켜놓고 원래 OWL_ViT의 localization 능력은 그대로 사용할 수 있는 것처럼 다른 task 에 특화된 모델에서 충분히 사용할 수 있지 않을까 생각합니다. 감사합니다.
리뷰 잘 읽었습니다. 아이디어가 간단하면서도 좋네요. 생각해보면 코사인 유사도로 분류를 수행하도록 사전학습을 했는데 cross-entropy로 Finetuning을 하면 freeze하지 않은 부분의 사전학습된 feature extractor가 망가질 수 있을 것 같다는 생각이 듭니다. 간단한 질문 남기자면, CE가 아니라 cosine similarity로 비교하는것에 성능이 좋다는 장점이 있지만 분명 단점도 함께 있을 거라 생각하는데, 연산량 이외에 다른 feature 관점에서의 단점은 없나요? 논문에서 저자가 단점 관련해서 언급한 부분이 있나 궁금합니다.
안녕하세요 재연님 답글 감사합니다.
논문에 feature 관점에서의 cosine similarity loss를 쓰는 것의 단점은 딱히 언급되지 않습니다.. 다만 드는 생각으로는 CE 의 loss 구조상 명확한 한개의 class를 찾으려 하므로 클래스간의 경계가 명확해지는 장점이 존재하지만 cosine similarity loss는 구조상 그러한 경계가 명확하지 않을 수 있을거라 생각합니다. 사실 논문 ablation 성능을 보면 대조학습 기반의 성능이 CE Loss 썼을때랑 큰 차이는 없고 가중치 앙상블까지 적용 가능하다는 점이 또다른 장점이지 않나 싶습니다.