안녕하세요, 72번째 x-review 입니다. 이번 논문은 AAAI 2025년도에 Oral paper로 게재된 DepthAM이라는 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
Monocular Depth Estimation(MDE)은 크게 discriminative 방식과 generative 방식으로 나눌 수 있습니다. 전자는 전체적인 성능은 좋지만 high frequency의 depth 표현이 부족하고, 반대로 generative 방식은 diffusion 방식을 사용하여 자연스러운 depth를 생성하며 높은 성능을 보이지만 매우 느리다는 단점이 있습니다. 그래서 저자는 Flow Matching(FM)과 연관지어 보는데요, FM은 diffusion과 다르게 진행 경로가 더 일직선이기 때문에 계산 cost가 더 적고, 시작되는 분포와 경로 설계가 더 유연한 방식 입니다. 또한 diffusion과 다르게 가장 큰 장점은 처리 속도가 빠르다는 것이죠. 이를 기반으로 DepthFM의 핵심 아이디어는 기존 diffusion 모델처럼 noise에서 depth map을 예측하는게 아니라 이미지에서 바로 depth map을 예측하도록 합니다. 즉 노이즈가 시작 데이터가 아니라 이미지 자체를 시작점으로 해서 depth로 바로 이동하는 데이터 기반의 coupling을 제안합니다. 이는 시작점과 끝점을 실제 pair한 데이터로 설정하여 그 사이의 경로를 모델링하는 방식을 의미합니다.
하지만 FM을 사용한다 해도 해결해야 하는 문제가 2가지 존재합니다. 먼저 생성 기반의 depth 모델은 학습하는 거 자체의 cost가 크고 두번째는 그렇게 학습을 할 데이터가 부족하다는 것 입니다. depth 데이터는 GT를 만들기가 어려워서 높은 퀄리티의 데이터셋을 만드는 데 한계가 있죠.
이러한 문제를 해결하기 위해 이중 prior(이미지/depth)를 사용하고자 합니다. 먼저 이미지 prior는 Stable diffusion에서, depth prior는 discriminatvie 모델을 활용합니다. 이렇게 이중 prior를 사용하면 초기에 시각적인 지식을 갖춘 채로 FM 모델 학습을 시작할 수 있기 때문에 학습 속도를 향상시킬 수 있습니다. 또한 합성 데이터만을 사용해서 real 데이터에 대한 일반화가 가능하며 사전학습된 discriminative 모델을 통해 추가적인 성능 개선이 가능해집니다.
자세한 방법론은 아래에서 설명하도록 하고, 여기서 main contribution을 정리하면 다음과 같습니다.
- 최초로 Flow Matching을 이용하여 MDE를 직접적인 분포 전이 문제로 공식화하였으며, 유연한 경로 설계와 분포 설정으로 샘플링 속도 향상
- 학습과 데이터 효율성을 위해 generative 및 discriminative 모델의 외부 지식 활용
- 합성 데이터로만 학습했음에도 불구하고 real 이미지에 대해 MDE 및 depth completion에서 SOTA 달성
2. Method
Background: Flow Matching
FM은 데이터 간의 분포 전이를 ODE(상미분 방정식)를 기반으로 한 벡터 필드를 따라 직접 수행하게 됩니다. 이는 일반 diffusion의 denoising보다 경로가 직선적이라서 계산이 훨씬 빠릅니다.
데이터 공간 \mathbb{R}^d에서 데이터 x는 시간에 따라 변화하는 벡터 필드 u_t(x)를 따라 이동을 하는데, 이를 ODE로 나타내면 dx = u_t(x)dt가 됩니다. 여기서 벡터 필드는 데이터가 이동하는 방향과 속도를 결정합니다.
ODE의 해는 \phi_t(x)는 x가 시간 t에 얼마나 이동했는지를 나타내는 함수로, 시작 조건은 이미지가 시작점이기 때문에 \phi_0(x)=x가 되겠죠.
그 다음 p_t(x)는 확률 밀도 경로로, 시간 t에서의 x의 분포를 나타냅니다. 초기 분포 p_0가 있을 때, \phi_t를 따라 p_t로 옮겨지고, 그렇게 이동을 시키는 걸 pushforward라고 부른다고 합니다.
FM의 loss 함수는 식(1)과 같습니다.
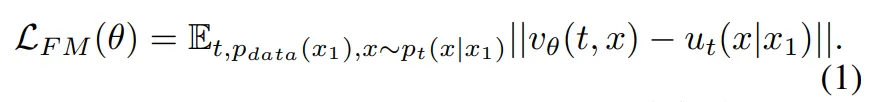
- x_1 : GT depth
- x : 중간 지점에서 샘플링한 데이터
식(1)은 모델이 예측한 벡터 v_{\theta}가 실제 벡터 필드 u_t와 얼마나 유사한 지를 학습도록 합니다.
이동하는 경로는 처음에 노이즈로 시작하여 실제 정답 데이터로 가는데, 그 사이 중간 지점은 x_t = tx_1 + (1-t)\epsilon으로 정의됩니다. 즉, 노이즈에서 출발하여 x_1로 선형적으로 이동하는 경로가 되죠.
그 다음 벡터 필드는 데이터가 이동하는 방향과 속도를 결정한다고 했는데요, 벡터 필드는 u_t(x|x_1) = \frac{x_1 - x}{1-t}로 정의합니다. 벡터는 지금 위치에서 x_1로 얼마나 빠르게 이동해야 하는 지를 나타냅니다.
Data Coupling in FM for Depth Estimation
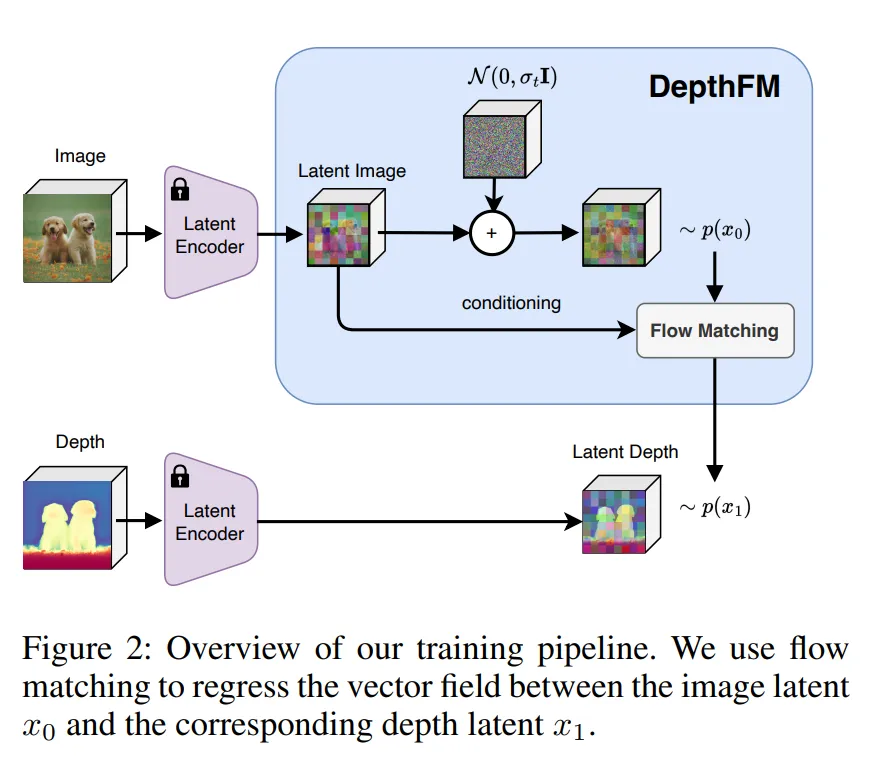
Flow in Latent Space
기본적으로 본 논문의 모델은 latent space를 쓰는데요, 이유는 고해상도 이미지와 depth 데이터를 직접 처리하면 연산량이 매우 크기 때문 입니다. VAE를 이용해서 이미지와 depth를 latent 공간으로 압축하면 시각적으로 의미있는 feature만 남은 표현으로 변환할 수 있습니다.
추가적으로 일반적인 depth 정규화 방식과 다르게 로그 스케일의 depth 정규화 방식을 적용하였습니다. 기존의 Marigold는 선형 정규화를 적용하였는데, 여기서는 depth 값을 log(depth) 형태로 변환하여 앞에 거리일 수록 더 디테일하고, 먼 거리일수록 완만하게 표현할 수 있다고 합니다.
이러한 정규화 방식을 적용한 이유는 가까운 물체가 많은 실내 공간과 멀리 있는 실외 공간까지 모두 포함할 수 있도록 하여 다양한 scene에 대해 일반화를 이룰 수 있도록 하기 위함 입니다. 모든 scene을 커버하려면 depth 값의 분포가 매우 넓은데 로그 스케일은 이 차이를 완화시켜서 학습의 안정성을 향상 시킬 수 있다고 하네요.
Direct Transport between Image and Depth
DepthFM의 핵심 목적은 기존 diffusion 모델과 다르게 p(x_1|x_0) 이미지 표현 x_0에서 바로 depth 표현 x_1로 가는 직접적인 분포 전이를 모델링하는 것 입니다.
FM을 사용하니, 먼저 벡터 필드를 정의해보겠습니다.
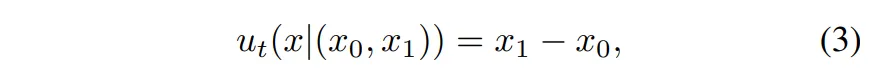
이는 간단하지만 항상 x_0 → x_1 방향으로 고정된 벡터 필드가 됩니다. 무슨 말이냐면, 시간에 따라서 변하는게 아니라서 학습이 안정적이고 계산이 간단하여 간단하지만 효과적인 정의라고 볼 수 있습니다.
시작점에서 시작해서 끝점으로 향하는데, 그 중간의 샘플링 분포 x_t는 식(2)와 같이 정의됩니다.
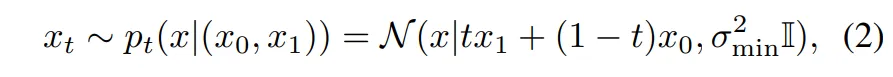
- \sigma^2_{min} : 수치적 불안정함을 방지하기 위한 스무딩
시간 t \in [0,1]에 따라 정의된 확률 분포 p_t(x|(x_0, x_1))를 통해 중간 지점 x_t를 샘플링하게 됩니다. x_0과 x_1 사이의 선형 보간 경로 위에 정규 분포(오른쪽 항)로 정의되어 있습니다.
이런 설계가 효과적일 수 있는 이유는 이미지와 depth pair로 이루어진 시작-끝점이라서 데이터 공간에서 의미적으로 매우 가깝기 때문 입니다. 그래서 FM이 diffusion보다 경로가 훨씬 짧아서 빠르고 안정적으로 학습이 가능하죠.
이러한 DepthFM의 loss 함수는 식(4)와 같습니다.
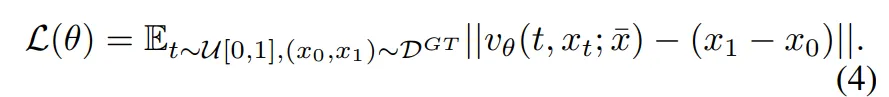
- v_{\theta}(t, x_t;\bar{x}) : 모델이 예측하는 벡터 필드
- x_t : 중간 지점
- \bar{x} : 클린한 이미지 표현 x_0
목적은 예측 벡터가 x_1 - x_0와 유사하도록 학습하는데, 여기서 \bar{x}가 사용이 되죠. \bar{x}의 역할은 단순하게 x_t만 주는게 아니라 추가적으로 x_0의 복사본을 조건으로 줘서 이미지를 명확하게 기억하고 방향 예측의 정확도를 높일 수 있도록 합니다. \bar{x}를 통해 모델은 현재 중간 지점 x_t의 위치 뿐만 아니라 출발점인 이미지 정보를 계속 잊지 않고 기억하면서 이동 방향을 예측할 수 있는 것이죠.
Noise Augmentation
으레 학습 과정에서 그러하 듯 DepthFM 역시 학습에서 모델이 다양한 상황에 대해 일반화가 이루어지도록 노이즈 augmentation을 사용합니다. 원래 diffusion 모델에서 사용하던 방식인데, 좀 더 확장하여 시작점인 t=0에 해당하는 이미지 표현 x_0에 노이즈를 추가하는 것 입니다. 단순하게 이미지의 latent 표현만 사용하는 게 아니라 \bar{x}에 가우시안 노이즈 \epsilon ~ \mathcal{N}(0,I)를 합쳐서 x_0 := \sqrt{{\bar{\alpha}_t}_s} \cdot \bar{x} + \sqrt{1-{\bar{\alpha}_t}_s} \cdot \epsilon로 정의를 하게 됩니다. 이렇게 합치면 데이터의 분산을 유지하면서 원래의 이미지 표현과 노이즈를 균형 있게 합칠 수 있었다고 합니다.
기존의 노이즈 augmentation 연구들은 주로 노이즈-이미지 쌍을 사용하는데, 이 논문을 그걸 확장해서 처음으로 노이즈-이미지-depth 쌍을 형성할 수 있었고 그게 효과적이라는 것을 실험적으로도 보여준 것이죠.
Dual Knowledge Transfer for better Training and Data Dfficiency
이 부분은 기존 사전학습 모델로부터 외부 지식을 가져오는 방식에 대해 설명하며 이를 Dual Knowledge Transfer라고 부르고 있습니다.
depth estimation 모델이 학습하는데 크게 두 가지 challenge 함이 있다고 이야기 했잖아요.
첫번째는 연산량이 크고 두번째는 높은 품질의 GT depth를 얻는게 어렵다는 것 입니다.
이러한 한계를 해결하기 위해 이미 잘 학습된 generative diffusion 모델과 discriminative depth 모델을 활용하는 것이죠.
Image Prior for Training Efficiency
먼저 이미지 prior는 하나의 가정으로 시작합니다.
이미지를 잘 생성하는 모델은 기본적으로 scene에 대한 구조적인 지식을 가지고 있어야 한다는 것 입니다. 가령, diffusion 모델은 대규모의 이미지로 학습했기 때문에 물체가 멀리 있는지 가까운지에 대한 구조적인 정보를 어느 정도는 학습할 수 있을 것이라는 겁니다. 이러한 시각적인 구조 정보를 DepthFM에 전달함으로써 표현력을 향상시킬 수 있습니다.
diffusion 모델은 여러 파라미터화를 통해 학습이 될 수 있는데요, 예를 들어 직접적인 데이터 값이나 노이즈, 혹은 두 분포 사이의 벡터 v 등을 예측할 수가 있습니다. 그 중에 v를 파라미터화하면 시작 분포와 마지막 분포 사이의 velocity를 예측하는 방식입니다. (여기서 v는 \alpha_tx_0 - \sigma_tx_1 입니다.)
이와 다르게, FM에서는 벡터 필드를 단순하게 v = x_1 - x_0로 정의했잖아요. 보다시피 더 간단하긴 하지만 diffusion 모델이 사용하는 파라미터화와 매우 유사하다는 것을 알 수 있습니다. 이건 diffusion 모델이 학습한 v 파라미터와 기반의 사전 지식을 FM 방식에서도 거의 그대로 재사용할 수 있다는 의미 입니다.
따라서 diffusion 모델을 가져와서 그 모델의 파라미터를 FM에 맞게 finetuning 함으로써 처음부터 새롭게 모델을 학습하는 것보다 빠르게 수렴하도록 할 수 있습니다.
Depth Prior for Data Efficiency
일반적으로 생성형 모델은 시각적으로 자연스러운 결과를 만들 수 있지만 정량적 지표로는 discriminative 모델보다 뒤처지는 경우가 많다고 합니다. 이유는 discriminative 모델들은 수많은 GT depth 데이터를 기반으로 학습하기 때문에 수치적으로 정확도가 높고 테스트에서도 좋은 결과를 보이는 경향이 있다고 합니다.
이러한 두 모델의 특징을 보완하기 위해 사전학습된 discriminative depth 모델을 teacher 모델로 사용해서 생성형 모델을 간접적으로 가르치는 방식을 제안합니다.
GT 데이터가 없는 real 이미지로 구성된 unlabeled 이미지 데이터셋 \hat{D}_u에 대해 discriminative 모델 T을 사용하여 이미지들의 depth 결과를 우선 생성합니다. 이렇게 얻어진 새로운 데이터 쌍 D_u = \{(u_i, T(u_i))\}이 pseudo labeled 데이터가 됩니다. 즉 이미지 u_i에 대해 teacher 모델 T가 예측한 depth ㅆ(u_i)를 GT처럼 간주하고 사용하는 것이죠.
전체 학습 데이터셋 D는 실제 GT 데이터셋이 있는 D_{GT}와 앞서 생성한 pseudo label 데이터셋 D_u 중 일부를 섞어서 구성합니다. 이 때 D_u에서 몇 개를 가져 올지에 대해서는 하이퍼파라미터 k로 조절하며 k \cdot |D_{GT}|만큼 무작위로 선택하게 됩니다.
이렇게 구성한 데이터셋에 대해 앞서 말씀드린 FM의 loss를 적용하는 것 입니다.
해당 방식은 실제 GT 데이터가 없어도 마치 GT가 있는 것처럼 학습할 수 있도록 하기 때문에 한계점이었던 부족한 데이터의 문제를 해결할 수 있습니다. 또한 동시에 생성형 모델의 시각적 표현력은 그대로 유지할 수 있습니다.
3. Experiments
학습은 합성 데이터 Hypersim, VirtualKITTI를 사용합니다.
평가는 real 데이터(NYUv2, KITTI, ETH3D, ScanNet, DIODE)에 대해 zero shot으로 평가하였으며 teacher 모델로는 Metric3D v2를 사용하였다고 합니다.
Zero-shot Depth Estimation
Main Quantitative Result
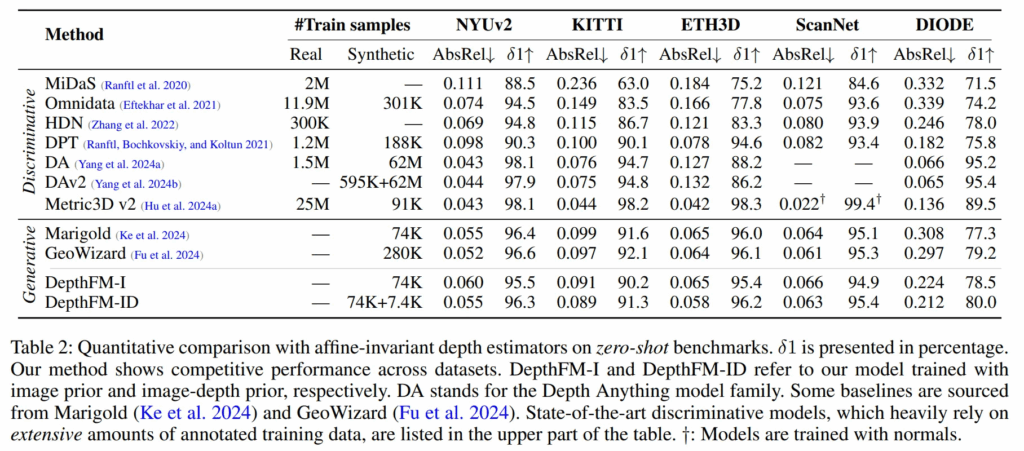
먼저 Tab.2는 DepthFM과 다른 depth estimation 모델과 비교합니다.
기존 방법론들과 다르게 본 모델은 대규모의 학습 데이터 없이 높은 성능을 낼 수 있도록 설계하였는데요, 이는 두 개의 prior를 활용하여 discriminative와 생성형 모델의 장점을 모두 활용하도록 하였습니다.
사실 여전히 discriminative와 성능 차이가 조금 있긴 합니다만 .. 저자가 말하기로는 학습에 필요한 계산량을 줄이면서도 모델의 학습 효율성을 높이면서 기존의 생성형 방식들보단 좋은 성능을 보일 수 있었다고 합니다. 또한 scene의 종류에 상관없이 다양한 데이터셋에서 GT 없이도 좋은 zero shot 성능을 보이고 있습니다.
Comparison against Generative Models
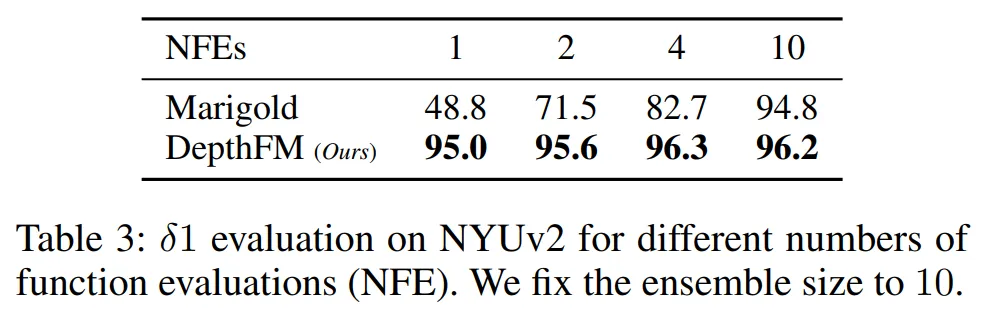

다음은 기존 diffusion의 샘플링 방식과 비교하여 샘플링 방식의 효과를 보이고 있습니다.
대표적인 diffusion 기반의 MDE 모델인 Marigold와 비교하였는데요, 평가 횟수(NFE)가 동일한 조건일 때 Marigold보다 훨씬 좋은 성능을 보이는 것을 알 수 있습니다. 특히 1,2와 같이 적은 평가 횟수일 때 그 차이가 두드러지는 것을 볼 수 있습니다. Marigold가 4번은 평가해야 나오는 성능이 1번 평가하는 것만으로 가능해지게 됩니다.
Fig.3으로 정성적 결과를 봐도 적은 샘플링 단계만으로도 실제 scene에 대한 표현을 잘 하는 반면에 Marigold는 일정 수준 이상의 depth map을 생성하기 위해서는 더 많은 단계가 필요하다는 것을 볼 수 있습니다.
Depth Completion

추가적으로 depth completion에 대해 평가했는데요,
기존 연구에 따라 전체 픽셀 중에 2% 정도의 depth만 주어진 상황에서 DepthFM을 fine-tuning하여 Tab.5와 같이 평가하였다고 합니다.
최소한의 finetuning만 진행했음에도 불구하고 DepthFM이 SOTA를 달성하였다고 합니다.
다만 최근에 나온 diffusion 기반의 depth completion 방법론들과는 비교가 돼있지 않아서 supplementary에 추가로 리포팅된 것이 있을 지 확인해봐도 좋을 거 같습니다.
Ablation Studies
Image-depth Coupling
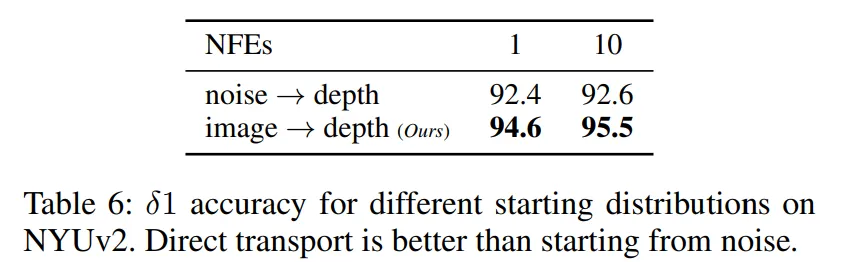
이제 ablation study로, 먼저 이미지와 depth coupling에 대한 실험 결과 입니다.
일반적인 FM 방식은 벡터 필드를 학습할 때 optimal transport 기반의 loss 함수를 사용하지만, 시작점을 정규분포에서 샘플링한 노이즈로 설정을 합니다.
반면에 DepthFM은 입력 이미지의 latent 코드에서 직접 출발하기 때문에, 생성의 시작점이 실제 이미지의 표현이냐 아니면 무작위 노이즈냐가 기존 방식과의 주요한 차이점 입니다.
Tab.6을 보면 DepthFM처럼 이미지의 latent 표현에서 시작할 경우에 특히나 적은 수의 평가만으로도 훨씬 더 높은 정확도를 달성하는 것을 확인할 수 있습니다. 이는 실제 입력 정보를 더 잘 반영하는 방식으로, 이미지를 출발점으로 시작하는 것이 학습과 평가에서 모두 더 효율적이라는 것을 보여주고 있습니다.
Knowledge Transfer from Image Prior
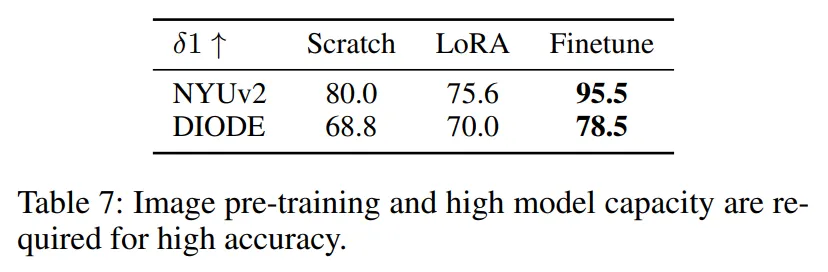
다음 Tab.7은 이미지 생성 모델의 사전 지식을 전달받는 게 얼마나 효과적인지를 보여주는 실험 입니다.
Scratch는 아무런 사전 지식 없이 처음부터 학습한 모델이고, LoRA는 Low-Rank adaptation을 사용해서 부분적으로 finetuning한 버전 입니다. 마지막으로 finetuning이 현재 모델인 이미지 prior를 사용하여 전체 모델을 finetuning한 세팅 입니다.
Tab.7을 보면, LoRA를 사용한 경우에는 파라미터의 수가 제한되어 있어서 모델링이 충분하지 않아 이미지 prior가 depth estimation으로 전달이 잘 되지 못한 것으로 보입니다.
반면에 사전학습된 이미지 prior를 전체 모델에 충분히 반영하면서 finetuning한 경우에 가장 좋은 성능을 보이고 있습니다.
이런 결과를 통해 저자는 이미지 prior와 표현력이 depth estimation의 성능을 높이는데 필요하다는 것을 입증하고 있습니다.
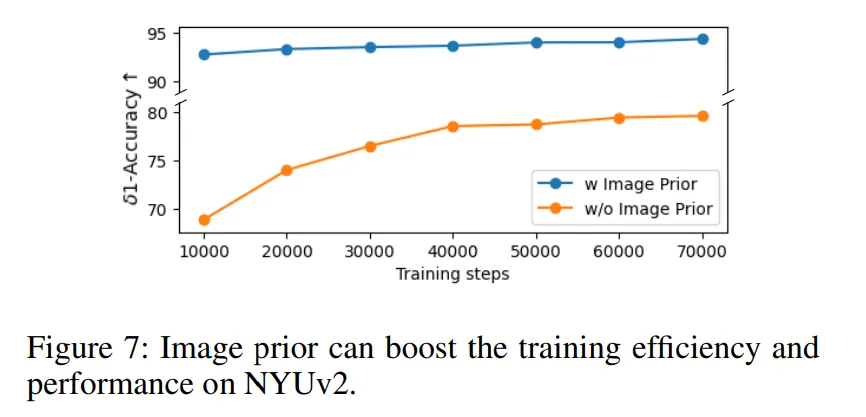
추가적으로 Fig.7을 보면 NYUv2 데이터셋에서 정확도를 학습 단계별로 시각화한 것인데, 이미지 prior를 사용한 경우에 훨씬 속도도 빠르고 정확도도 높은 것을 보여주고 있습니다. 이는 단순하게 성능이 좋은 것 뿐만 아니라 학습의 효율성도 개선되었음을 보여주는 결과 입니다.
Knowledge Transfer from Depth Prior

마지막으로 depth prior로부터의 knowledge transfer에 대한 ablation study 입니다.
앞선 이미지 prior에 추가적으로 discriminative depth 모델의 prior를 합쳐서 얻을 수 있는 효과에 대한 실험 입니다.
이미지 prior를 사용할 때 보다 depth prior까지 함께 사용할 경우 모델의 성능이 크게 향상한다는 것을 강조하고 있습니다. 해당 실험에는 없지만 supplementary에 하이퍼파라마터를 어떻게 설정하는 지에 대해서도 추가적으로 리포팅 해놓았고 여기서도 언급을 하고 있습니다.
discriminative 모델의 데이터를 전체 데이터의 10% 정도 포함시킬 때 가장 안정적인 성능을 보이고 있고, Tab.8의 결과도 동일한 세팅이라고 합니다.
반대로 discriminative 데이터 비율이 너무 높아지면 depth map이 더 흐릿하고 오히려 원래 자연스러운 depth map의 표현력이 안 좋아지기 때문에 정확도와 정성적인 선명함 사이에 trade-off가 있어서 DepthFM은 그 사이의 균형을 조절하여 최적의 성능을 낼 수 있음을 보여주고 있습니다.
안녕하세요! 좋은 리뷰 감사합니다.
짧은 질문하나 하겠습니다.
ablation study도 그렇고 대부분의 실험이 NYUv2 에서 많이 하는 것 같습니다.
이 방법론이 로그 스케일을 적용해서 가까운건 디테일하게 먼 것은 완만하게한다 라고 말씀주셨는데 비교적 가까운 물체들이 많은 indoor scene에서만 잘 작동을 하는가? 라고 생각을 했는데 막상 Table2에 대해서는 Marigold 보다 좋은 성능을 보여주진 못하고있습니다. 그래서 궁금한것이 저자가 indoor outdoor에 대해 구분지으면서 얘기 한 부분이 혹시 있는지 궁금하고 추가적으로 기존 정규화 방식과의 차이에 대한 저자의 언급은 없었는지 궁금합니다!
감사합니다 👍
안녕하세요, 리뷰 읽어주셔서 감사합니다.
논문 실험 부분에서 indoor와 outdoor 도메인을 명확하게 구분해서 성능 차이가 발생하는 것에 대해 이야기하진 않습니다. 실험이 NYUv2와 같은 indoor scene을 중심으로 평가하고 있긴 하지만, outdoor와 뭔가 구분 지으면서 얘기하고 있진 않습니다.
기존 정규화와의 차이는 로그 스케일을 썼기 때문에 비교적 더 완만하게 차이를 표현할 수 있다는 정도로만 언급되고 있습니다.
감사합니다.
안녕하세요 건화님 좋은 리뷰 감사합니다.
Image Prior에 대해서 diffusion 모델이 학습한 v 파라미터로부터 knowledge distill 방식으로 FM 방식에서도 거의 그대로 재사용할 수 있도록 수식을 맞추어낸 트릭이 신기하네요.
어찌됐든 Diffusion 방식과 FM 방식 속에 discriminative한 모델의 pseudo label까지 자연스레 잘 녹여내어 결합했고 이것이 실제로 유의미한 성능을 보였다는 점에서 의미가 있는 논문인 거 같습니다.
근데 제가 flow matching을 잘 몰라서,,, 사실 처음 읽을 때부터 FM에 대해 검색해가며 읽게되었는데요. 이해한 게 맞는지 잘 모르겠어서 질문드립니다.
1. diffusion 과 다르게 진행 경로가 더 직선적이라 계산이 빠르다의 의미가 정확히 어떤 의미인가요..? 이것도 diffusion처럼 노이즈<->이미지 간의 변환 과정을 거치는데, 그걸 어떤 수학적 수식으로 모델링된 벡터장 기반으로 더 빠르게 예측한다는 것인가요??
2. Direct Transport between Image and Depth 에서, 이미지 자체를 시작점으로 해서 depth의 끝점으로 향해간다는 것이 이미지 latent feature에 noise 먹인 거의 어떤 한 픽셀로부터, latent depth에 대한 동일한 어떤 한 픽셀로 변환되어간다는 의미인가요..?
3. Diffusion parameter —> FM parameter 로 옮겨온 FM finetuning 방식이 image->depth 예측의 도메인 말고, 다른 modality domain 이나 다른 downstream task에도 적용이 될 수 있을까요? 예를 들면 image -> normal map 혹은 image -> text 혹은 image -> segmentation 등?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사하니다.
1. 경로가 직선적이라 빠르다는 의미는 원래 diffusion처럼 많은 denoising 과정을 반복하는게 아니라, 이미지에서 depth로 직접 연결되는 벡터 필드를 학습하기 때문에 더 적은 스텝 안에 원하는 결과로 이동할 수 있음을 의미합니다.
2. 말씀하신 것처럼 depth latent feature 공간을 목표로 하고 각 픽셀이 이미지 표현에서 대응하는 depth 표현으로 이동하도록 벡터 필드를 따라가는 개념이 맞습니다. 다만 실제 픽셀 단위의 직접적인 이동보다는 전체 latent 표현 상에서 각 위치의 특정 벡터가 depth에 대응되는 곳으로 변환되도록 학습합니다.
3. 개념적으로만 생각해보면 다른 모달리티로의 변환이나 다운스트림 task로 확장이 가능할텐데요 .. 이게 마냥 된다고 얘기하기보다는 depth가 아닌 다른 모달리티 데이터와 분포나 표현이 얼마나 잘 align이 맞춰지는지에 따라 달라질 것 같습니다.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
FM에 대해서 궁금한게 있는데, 원래 FM도 노이즈로 시작을 하는 것은 동일한데 본 논문에서는 그걸 노이즈가 아닌 이미지로 대체한 것으로 이해하면 될까요 ? 근데 노이즈가 존재하는 \bar{a}를 concat한다면 결국에는 RGB 이미지에 노이즈가 존재하는 latent가 만들어질 거 같은데 차이점이 어떻게 되는지가 궁금합니다.
감삼다. 👍👊
안녀하세요, 리뷰 읽어주셔서 감사합니다.
우선 첫번째 질문에 대해는 말씀하신 것처럼 기본적으로 노이즈로 시작해서 데이터를 향해 가는 경로를 학습하는 점은 diffusion과 동일한데요, 다만 순수 노이즈 대신에 시작점을 RGB 이미지의 latent 표현으로 두고 목표하는 지점을 depth latent로 둔다는 점이 다르다고 볼 수 있을 것 같습니다.
두번째 질문에 \bar{a}는 중간 시점의 noise latent를 의미하는데, 이걸 concat해서 쓰면 RGB latent에도 노이즈가 섞여있는 상태가 됩니다. 하지만 노이즈가 초기 입력을 완전히 덮어버리는게 아니라 필요한 정보는 latent에 남아있다는 점이 차이점이라고 할 수 있습니다.
감사합니다.