안녕하세요. 이번 X-Review에서는 2025년 ICLR에 게재된 애플에서 연구한 논문 “Depth Pro: Sharp Monocular Metric Depth in Less Than a Second”를 소개드리고자 합니다.
저번 주에 소개드렸던 Scale Depth라는 논문의 introductuon 부분에서 저자가 서로 다른 도메인간 스케일 차이 문제를 해결하는 기존의 방법론들 중 하나로써 카메라 파라미터를 활용하는 방법이 있다라고 언급을 하였습니다. 사실 Scale Depth 논문을 먼저 읽기 전에 depth pro라는 논문을 먼저 읽었는데, 해당 방법론이 바로 카메라 intrinsic 파라미터를 예측하고 예측한 파라미터를 metric depth를 예측하는데 활용을 합니다. 물론 이 논문에서는 이 부분에 초점을 둔 논문은 아닙니다. 그리고 심지어 어떤 데이터로 학습하였는지도 공개하지 않았습니다. 다만 Scale Depth를 읽기 전 Depth Pro라는 논문은 저에게 depth estimation이라는 태스크 자체가 처음 접하는 분야였고, 특히 monocular depth estimation 중에서도 거의 최신 논문이다 보니 이해하기 어려운 개념들이 많았던 터이라 해당 논문을 읽을 당시에는 단순히 넘어갔던 부분이 많았습니다. 그런데 Scale Depth논문을 읽고 다시 depth pro 논문을 보니깐 처음엔 그냥 넘어갔던 부분들이 조금 다르게 보였고, 처음읽었을 때와는 약간 다른 관점에서 바라볼 수 있게 된 것 같아서 이를 리뷰로 들고오게 되었습니다.
그럼 이만 리뷰를 시작하도록 하겠습니다.
introduction
먼저 논문 제목에서도 알 수 있듯이, 해당 연구는 단안 카메라(monocular image)만을 사용해서도 정밀하고 선명한 고해상도의 depth map을 1초 이내에 추정할 수 있는 모델인 Depth Pro를 제안합니다. 또 이 모델은 카메라 내부 파라미터(camera intrinsics)와 같은 메타데이터들 필요 없이 단일 이미지 자체만으로도 절대적인 스케일을 갖는 metric depth map을 추정할 수 있습니다.
먼저 depth pro의 성능을 보이는 실험 결과를 보여드리도록 하겠습니다.
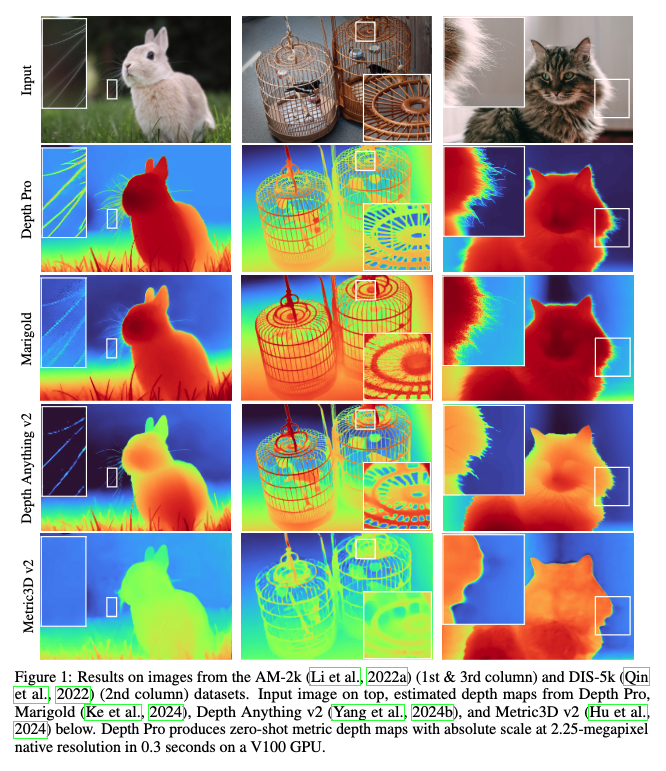
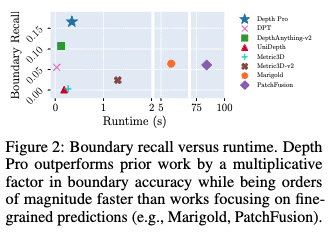
그림 1은 앞서 언급한 것과 같이 대표적인 결과를 보여줍니다. Depth Pro는 객체 경계의 선명한 윤곽(sharp delineation) 추정에 있어서 기존 모든 연구를 능가하고, 머리카락, 털등과 같은 fine한 구조나 섬세한 경계를 잘 처리하는 것을 확인할 수 있습니다. 또 그림 2을 보시면, Depth Pro는 경계 정확도에서 기존 연구들보다 수 배 뛰어난 성능을 보입니다. 정밀한 예측에 중점을 둔 연구들(Marigold, PatchFusion)보다 실행 속도도 수십 배 빠르다는 것을 확인할 수 있습니다.
이처럼 빠르고 정확한 성능을 동시에 달성할 수 있었던 이유에 대해서 방법론 적인 측면에서 메서드 파트에 들어가기 전 간단하게 설명을 드리고 넘어가도록 하겠습니다.
먼저, Depth Pro는 효율적인 multi-scale ViT 기반 아키텍처를 도입합니다. 이 구조는 이미지의 전역적인 context를 포착하는 동시에, 고해상도 상에서의 미세한 구조들 예를 들어 머리카락이나 풀잎처럼 얇고 복잡한 경계선까지도 섬세하게 추정할 수 있도록 설계되어 있습니다. 해당 아키텍처에 대한 자세한 설명은 이후 method 파트에서 다루도록 하겠습니다.
또한, 단순한 깊이 예측 손실만을 사용하는 것이 아니라, 경계의 선명도 정보들을 보존하기 위해 다양한 손실 함수(gradient, Laplace 등)를 조합하여 학습이 이루어집니다. 여기에 더해서 학습 데이터는 단순히 현실 데이터만을 사용하는 것이 아니라, 픽셀 단위의 정확한 ground truth를 제공할 수 있는 합성 데이터까지 함께 사용함으로써, 더 세밀한 예측이 가능하도록 합니다.
이러한 전략들을 사용함으로써 Depth Pro는 복잡한 장면에서도 세밀한 영역까지 뚜렷하게 추정할 수 있고, 동시에 초 단위 이하의 빠른 추론 속도를 갖추고 있어, 기존 모델들과는 차별화되는 정확도와 실용성 모두를 만족시키는 성능을 보여주는 논문이라고 보시면 될 것 같습니다.
이제 메서드 부분을 설명드리겠습니다.
Method
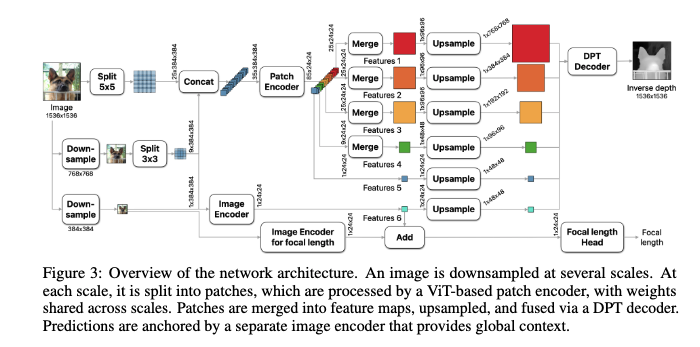
먼저 하나의 이미지에 대해서 다중 스케일로 패치들을 추출합니다. 위 그림에서 볼 수 있듯이 첫번째 플로우에서는 하나의 이미지를 5×5로 총 25개의 패치로 추출하고 그 바로 아래 플로우에 대해서는 다운 샘플링을 거친 이미지에 대해 3×3으로 총 9개의 패치를 추출하고 3번째 플로우에 대해서는 다운샘플링한 이미지 하나 자체를 패치로써 사용하게 됩니다.
그럼 총 25+9+1=35개의 패치를 가장 일반적인 하나의 ViT인코더에(patch Encoder)에 태우게 됩니다. 이렇게 모든 스케일에 대해서 하나의 patch encoder를 태움으로써 가중치를 공유하면서 학습이 이루어지게 됩니다. 이것의 의미를 좀 더 자세하게 설명을 드리면, 여러 해상도의 입력을 받은 네트워크(patch encoder)는 결과적으로 어떤 스케일의 이미지든 일관된 방식으로 즉, 객체가 크게 보이든 작게 보이든 같은 구조로 해석이 가능하게 되는 것입니다.
정리하자면 다중 스케일에서 공통적으로 나타나는 구조적 특성을 일관되게 인식하게 끔 함으로써 다양한 크기의 지역 정보를 통합해서 더 정확하고 정밀한 깊이 추정을 하기 위해서 이러한 방식을 적용했다고 생각하시면 될 것 같습니다.
크기가 고정된 이미지를 인풋으로 받고 5개의 패치에 대해서 하나의 ViT 기반 patch encoder가 weight를 공유하면서 병렬적으로 처리 가능하기 때문에 Depth Pro가 속도 측면에서 좋은 성능을 낼 수 있었던 것 같습니다. 이 구조 덕분에 Marigold나 PatchFusion처럼 fine-grained하게 작동하는 다른 복잡한모델들에 비해서는 구조가 단순하기 때문에 훨씬 빠른 연산이 가능하고, 실제로도 수십 배 빠른 속도를 보입니다. (absolute speed로만 보면 Depth Anything이 훨씬 빠름.)
각 패치는 흔히 우리가 알고 있는 plain한 ViT 구조에 입력으로 들어가게 되는데,. 여기서 중요한 건, 이 ViT는 고정된 이미지를 384×384 크기로 잘라서 입력받고, 내부적으로도 16×16 단위로 다시 쪼갠 다음, 그 위에서 글로벌 self-attention 연산을 수행한다는 것입니다. . 다만 이 연산은 해당 패치 내에서만 이뤄지기 때문에, 결국 5×5 패치 스케일에서는 국소 영역, 3×3에서는 중간 영역, 1×1에서는 전체 영역에 대한 정보를 각각 학습하게 되고, 이게 멀티스케일 feature map을 뽑아내는 효과랑 비슷하게 작동하게됩니다.
그리고 가장 해상도가 높은 5×5 스케일에 대해서는 디테일을 더 잘 포착하기 위해서 intermediate feature를 한 번 더 뽑아내. 이로 인해 해당 스케일에서는 25 + 25개의 feature가 생기고, 전체적으로는
(25 + 25) + 25 + 9 + 1 = 총 85개의 패치가 사용됩니다.
이렇게 여러 스케일에서 얻은 feature들을 merge하고 upsample한 다음, DPT decoder와 유사한 구조의 decoder에 넣어서 inverse depth 을 예측하게 되는 구조라고 보시면 될 것 같습니다.
결국 이 구조의 핵심은, 일반적인 ViT를 그대로 가져다 쓰면서도 패치 단위 병렬 연산을 가능하게 하고, 각 스케일이 서로 다른 공간 정보를 포착하게 만들어서 정확도와 속도 둘 다 잘 챙겼다라는 것을 보입니다.
그리고 앞서 구한 inverse depth map을 아래 focal length Head의 예측결과를 가지고 스케일링을 진행해줌으로써 최종적인 metric depth map을 구할 수 있게 됩니다.
이전에 리뷰했던 Scale depth에서 별도의 Scale Query를 가지고 어떠한 신의 시멘틱정보를 알아냄으로써 이를 가지고 스케일을 추정하여 metric depth map을 추정한 것과 비슷하게 해당 논문 또한 focal length를 예측하는 별도의 모듈을 추가하여 이를 가지고 metric depth를 예측하게 됩니다.
최종 DPT decoder를 타고 출력된 값은 inverse depth map을 가지고 (1m 단위의 실제 거리 값이 아니라 정규화된 z가 분모로 간 값이라고 보시면 됩니다.) 최종적으로 metric depth map D_m을 얻기 위해, 모델이 예측한 픽셀 단위의 focal length f_{px}와 이미지 너비 w를 이용해 아래와 같은 방식으로 최종 metric depth를 구하게 됩니다.
D_m = \frac{f_{px}}{w \cdot C}
실제로 우리가 다루는 이미지들 중에는 EXIF 메타데이터가 부정확하거나 아예 없는 경우도 많기 때문에, 이를 해결하기 위해 Depth Pro에서는 focal length head 를 따로 붙입니다. 이 헤드는 간단한 합성곱 기반 모듈인데, 앞서 설명한 Image Encoder에서 뽑은 전역적인 feature와 깊이 추정 네트워크에서 고정된 feature를 함께 입력으로 받아서 해당 focal length을 예측하는 구조라고 보시면 될 것 같습니다. 손실 함수는 간단하게 L2 Loss를 사용합니다.
그리고 이 초점 거리 헤드는 depth를 예측하는 네트워크랑 함께 joint 학습되는 게 아니라 깊이 네트워크가 먼저 학습된 이후에 별도로 따로 학습됩니다.
이렇게 따로 학습하는 방식에는 몇 가지 장점이 있다고 합니다.
첫째로, 깊이 추정과 초점 거리 추정이라는 두 가지 서로 다른 태스크의 학습 목표를 굳이 동시에 조정하지 않아도 되기 때문에, 손실 함수 간의 균형 문제를 피할 수 있다는 점이 있고요.
둘째로는, 초점 거리 예측만을 위한 학습을 완전히 독립된 데이터셋에서 진행할 수 있다는 점입니다.
예를 들어, 깊이 supervision이 없는 이미지 데이터셋이더라도 EXIF 정보를 포함하고 있다면 초점 거리 학습에 쓸 수 있기 때문에, 보다 넓은 도메인에서 일반화된 추정이 가능해집니다. (반면 단안 깊이 추정은 보통 좁은 도메인에 묶이는 경우가 많기 때문에 도메인 한계가 있는 편입니다.)
제가 쓰다가 뺴먹은 내용이 있는데, 밑에 image encoder 또한 1×1 patch를 가중치 공유 없이 단독으로 입력을 받는부분이 있습니다. 해당 부분은 Image Encoder는 이미지 전체를 한 번에 처리하여 전역적인 문맥 정보를 추출하는 역할을 한다고 생각하시면 될 것 같습니다.이를 위해 마찬가지로 입력 이미지를 384×384 해상도로 다운샘플링한 뒤, ViT 구조를 통해 feature를 추출합니다. 물론 patch encoder 또한 1×1 패치(전역적인 정보를 가지고 있는)을 입력을 받지만 다른 패치들과 가중치를 공유한다는 점에서 오로지 전역적인 정보만을 해당 인코더가 학습한다고 보기는 힘들기 때문에 이렇게 encoder를 목적에 따라 각각 나눈 것 같습니다. 결과적으로 image Encoder는 Patch Encoder가 추출한 국소 피처들이 이미지 전체에서 어떤 위치에 있는지를 이해할 수 있도록 global context를 제공한다 라고 보시면 될 것 같습니다.
이후 Image Encoder에서 나온 출력은 이후의 decoder 과정에서 Patch Encoder의 출력과 함께 결합되어, 보다 정밀하고 문맥적으로 일관된 depth map 예측을 가능하게 됩니다.
Loss
Depth Pro는 이 정규화된 inverse depth를 기반으로 다양한 손실 함수들을 적용하는 방식으로 학습을 진행하게 됩니다.
L_{MAE}(\hat{C}, C) = \frac{1}{N} \sum_{i=1}^{N} |\hat{C}_i - C_i|
먼저 모든 메트릭 데이터셋에 대해, depth pro는 픽셀 i마다 평균 절대 오차 L_{MAE}를 계산하고 실제 데이터셋(합성 데이터셋이 아닌)에서는 각 이미지의 상위 20% 오차 픽셀을 제외합니다. 실세계 센서로 얻은 depth 맵은 종종 노이즈, 결측치, 잘못된 거리를 포함한 경우가 많아서 이 때문에 loss에 이런 잡음이 큰 영향을 줄 수 있습니다. 오차가 좀 많이 큰 값들(outliers)을 제거함으로써, 모델이 노이즈가 적고 의미 있는 신호에만 집중하도록 유도하기 위함인 것 같습니다. 그래서 실제로는 이를 노이즈가 적은 합성 데이터 셋에는 적용 하지 않습니다
위와 다르게 카메라 내부 파라미터가 없거나 스케일이 일관되지 않은 비메트릭 데이터셋에 대해서는, 손실을 적용하기 전에 예측값과 정답값을 중앙값으로부터의 평균 절대 편차를 사용하여 정규화를 진행하여 손실을 계산하게 됩니다.
위 Loss fuction을 base로 다양한 손실함수들을 학습과정에 적용을 하게 됩니다.
앞서 구한 정규화된 inverse depth map들에 대해 다중 스케일에서 1차, 2차 도함수에 대한 오차도 계산을 하는데요. (이것이 가지는 의미가 무엇인지에 대해서는 바로 뒤에 설명드릴 예정) 이것을 바탕으로 아래와 같은 다양한 loss function을 정의합니다.
Mean Absolute Gradient Error: L_{MAGE} = L_{S,1,6}
평균 절대 그래디언트 오차
Mean Absolute Laplace Error: L_{MALE} = L_{L,1,6}
평균 절대 라플라스 오차
Mean Squared Gradient Error: L_{MSGE} = L_{S,2,6}
평균 제곱 그래디언트 오차
L_{<em>,p,M}(C, \hat{C}) = \frac{1}{M} \sum_{j=1}^{M} \frac{1}{N_j} \sum_{i=1}^{N_j} |\nabla^</em> C^j_i - \nabla^* \hat{C}^j_i|^p
여기서 스케일 j는 역거리 맵을 블러링하고 2배씩 다운샘플링하여 계산합니다.
이제 저 손실함수를 무작정 다 쓰는 것이 아니라 그 상황에 맞는 적절한 손실함수를 골라서 적용하는 방식입니다.
언제 어떤 손실함수를 쓸지는 저자는 관찰과 실험을 통해서 학습 커리 큘럼을 설계를 하게됩니다.
그럼 어떤 관찰로 인해 이런 학습 커리 큘럼을 제안하게 되었을까요?
첫째, 실제 및 합성 데이터셋을 혼합하여 학습하는 것이 제로샷 정확도 기준에서 일반화 성능을 향상시킨다.
둘째, 합성 데이터셋은 픽셀 단위로 정확한 정답을 제공하지만, 실제 데이터셋은 누락 영역, 불일치 거리값, 객체 경계에서의 오차 측정값 등을 포함하는 경우가 많다.
셋째, 학습이 진행됨에 따라 예측 결과가 점점 더 선명해진다.
위와 같은 관찰을 통해 두 단계로 구성된 학습 커리 큘럼을 설계하게 됩니다.
첫 번째 단계에서는 네트워크가 도메인 전반에 대해 일반화할 수 있도록 학습하는 데 목적을 둡니다. 이를 위해 모든 라벨링된 학습 데이터셋을 혼합하여 학습하게 되는데요, 구체적으로는 메트릭 데이터셋에는 L_{MAE}, 비메트릭 데이터셋에는 메트릭과 분리시켜 정규화된 버전을 사용해서 L_{MAE}를 최소화 하는 방향으로 학습하게 됩니다.
그리고 학습의 두 번째 단계는 예측된 거리 맵의 경계를 선명하게 만들고, 세밀한 디테일을 드러내기 위해 설계되었습니다. 네트워크가 선명한 경계를 예측하도록 하기 위해, 앞서 잠깐 언급한 예측값의 그래디언트(1차 도함수,2차 도함수)에 대한 supervision도 함께 사용하게 되는데요.
위처럼 1차 도함수를 활용하는 이유는 단순히 픽셀의 깊이가 얼마인가? 만 보는 것이 아니라 이 픽셀이 이웃 픽셀 사이의 깊이 변화율이 얼마나 정확한가 도 학습시키기 위해서 사용한다고 이해하시면 될 것 같습니다. (깊이맵의 경계를 뚜렷하게 하기 위해서 !) 2차 도함수는 곡률(curvature)이나 깊이 변화의 급격한 변화를 부드럽고 정밀하게 포착하기 위해 사용한다고 이해하시면 될 것 같습니다. 결과적으로 깊이 구조의 곡률을 표면이 완만하게 휘어지거나, 단순한 경계가 아니라 더 복잡한 형상에 대해서 더 경계를 부드럽게 재현할 수 있게 됩니다.
위 처럼 저자는 2가지에 대한 Loss를 설계함으로서 모델이 더욱 일반화된 성능과 세밀한 디테일에 대해 강인한 표현이 가능하게 학습이 이루어지도록 합니다.
다음은 실험파트 입니다.
Experiments
이제부터는 Depth Pro가 실제로 어느 정도 성능을 보여주는지 살펴보겠습니다. 특히 이 논문에서는 제로샷 상황에서도 얼마나 일반화된 메트릭 depth 추정이 가능한지, 그리고 얼마나 얇고 날카로운 경계까지 잘 살리는지를 기준으로 평가합니다.
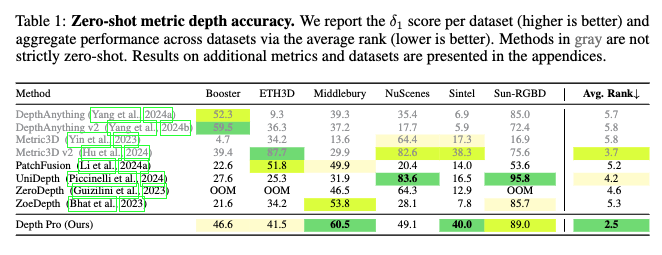
우선 가장 핵심적인 성능지표인 δ1 기준 메트릭 depth 성능을 보면, Depth Pro는 Booster, Middlebury, Sun-RGBD 같은 다양한 도메인에서 전체적으로 고르게 상위권 성능을 보입니다. 실제로 평균 랭크로 봤을 때 가장 낮은 2.5로, 타 모델들 대비 도메인에 특화되게 튜닝하는 것 없이도 가장 일관된 제로샷 성능을 보여준다고 볼 수 있습니다.
반면, DepthAnything이나 Metric3D 계열은 indoor/outdoor 별로 모델을 다르게 쓰거나 테스트 크롭 사이즈를 별도 조정하는 등 사실상 완전한 제로샷이라 보기 어려운 설정이 많았습니다. 그래서 논문에서도 이 모델들은 회색 처리해 구분하고 있다는 것을 보실 수 있습니다.
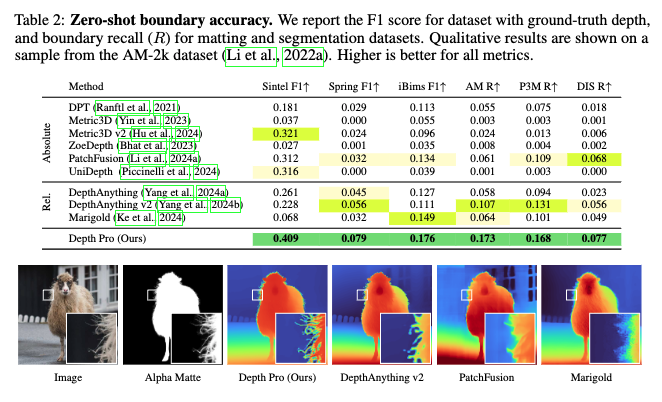
위가 Depth Pro가 다른 모델들과 가장 차별화되는 지점을 보여주는 실험 테이블이라고 볼 수 있는데요, 바로 경계 예측입니다. 특히 머리카락, 털, 윤곽선 등 얇은 구조를 얼마나 정확하게 살려내는지 평가하는 boundary metric 기준에서 거의 모든 데이터셋에서 압도적인 1등을 기록합니다.
특히 Marigold나 PatchFusion처럼 경계 특화 모델보다도 훨씬 높은 precision과 recall을 기록하면서도 속도는 수 배 빠릅니다. 예를 들어 AM-2k(여기에는 머리카락, 깃털, 얇은 털과 같이 얇고 복잡한 구조를 가진 객체들이 포함됨)에서 Depth Pro의 경계 recall은 0.173 인데, Marigold는 0.064, Metric3D v2는 0.024 수준입니다.
Table 1에서 sintel 데이터셋 부분 metric 3D와 unidepth를 보시면 metric 3D가 17.3, unidepth가 16.5로 metric depth accuracy에서는 metric 3D가 성능이 약간 더 좋은 것을 확인할 수 있습니다. 반면 table 2의 boundary accuracy 평가에서는 unidpeth가 0.316 metric 3D가 0.037로 unidepth가 훨씬 성능이 좋다는 것을 확인할 수 있습니다. 이를 보았을 때 결국 “metric accuracy가 좋다고 해서 경계 품질이 좋은 건 아니다”라는 점을 명확히 보여줄 수 있고, Depth Pro는 경계 품질과 속도 모두를 만족하는 모델이라는 점을 보이는 표라고 보시면 될 것 같습니다.
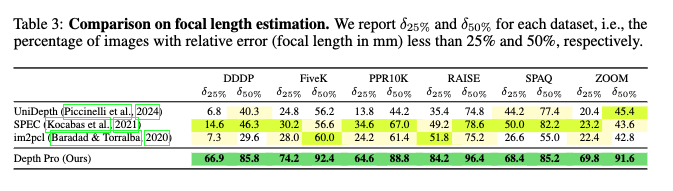
Depth Pro를 맨 처음 읽었을 때에는 focal length 추정 성능부분을 넘겨서 인상깊게 해당 테이블을 보지 못했던 것 같은데, 성능이 기존 focal length predictor들(SPEC, im2pcl, UniDepth 등)과 비교했을 때, 거의 모든 데이터셋에서 상대 오차 25% 이내 예측률이 2배가량 높은 것을 보고 좀 놀랐습니다.
PPR10K 같은 인물 중심 데이터셋에서는 Depth Pro가 64.6%의 이미지에서 25% 이내의 오차를 보였지만, 두 번째로 좋은 SPEC 모델은 34.6%에 그친 것을 확인할 수 있습니다.
뭔가 이러한 차이는 단지 성능 수치 그 자체보다도, 실제 metric depth 추정에서 focal length를 예측하는 모듈을 활용한 기반 scaling이 얼마나 효과적인지 보여주는 실험이라고 생각됩니다.
실내는 근거리 객체 위주, 실외는 원거리 구조가 많아 같은 크기 객체라도 모델 입장에서는 이미지 상에서 depth 표현을 다르게 하게 될 수 있는 부분이 있습니다. depth pro는 실내/외 별 사용하는 센서에 따른 카메라 intrinsic 파라미터를 가지고 이를 예측하여 실제 metric depth를 예측한다는 점에서, ScaleDepth의 영상의 시멘틱 정보로 scale 예측에 대한 부분과 위와 같이 카메라 intrinsic 파라미터를 예측하는 것을 둘다 활용한 하면 성능이 어떻게 나올지도 개인적으로 궁금하여 기회가 된다면 실험해보고 싶단 생각을 하였습니다.
결과적으로 Depth Pro는 단순히 평균 성능이 뛰어난 모델이라기보다는, 다양한 도메인에서도 강건하게 작동하고, 얇은 경계와 구조까지도 정확하게 살리면서, 동시에 속도와 효율성까지 챙긴 모델일고 보시면 될 것 같습니다.
안녕하세요 우현님 좋은 리뷰감사합니다!
간단한 질문 하나 남기겠습니다
focal length를 통해서 실제 metric depth를 구하는 걸로 이해했습니다.
두 모듈이 따로 학습을 통해서 이루어지는 것 같은데
focal length를 예측하는 부분에서의 도식화를 보면 image encoder에서 나온 값과 더해지게 되는데 이 부분의 이해가 명확하게 되지않아서 질문드립니다!
감사합니돠!
안녕하세요 우진님 읽어주셔서 감사합니다.
이미학습 완료된 depth estimation 네트워에서 feature 6을 frozen된 상태로 사용하고, 이 위에 작은 CNN head를 붙여 focal length를 예측하는 형태라고 보시면 됩니다. feature 6 자체는 depth branch 기준으로 고정되어 있기 때문에, focal length head는 이를 입력으로만 활용하고 feature 자체를 변경하거나 영향을 주지않는다고 생각하시면 될 것 같습니다!
감사합니돠.
안녕하세요 우현님 리뷰 감사합니다
Patch Encoder가 여러 해상도에 대해 가중치를 공유하도록 구성된 이유가 최대한 scale-invariant한 추론을 위해서 라고 생각하는데요, 1×1과 5×5를 생각해보면 엄청나게 다르다고 생각하는데 하나의 encoder가 제대로 학습을 할 수 없기 때문에 Image encoder가 도움을 주는(?) 형태인건가요? 구조에 대해 조금만 더 설명 부탁드립니다!!
안녕하세요 영규님 읽어주셔서 감사합니다.
물론 Patch Encoder도 전체 이미지를 1×1로 다운샘플리해서 하나의 patch로 입력받기 때문에 전역적인 정보를 어느 정도 포착할 수 있습니다. 그런데 Patch Encoder는 여러 크기의 패치에 대해 같은 가중치를 공유하면서 학습이 이뤄지기 때문에 각 patch의 위치나 크기에 상관없이 잘 작동하는 일반적인 표현을 학습하는 데 초점이 맞춰져 있다고 저는 이해를 하였습니다. 반면에 Image Enoder는 오직 전체 이미지에 대해서만 작동하도록 설계되어 있기 때문애 말씀 주신 것처럼 각 patch의 예측이 Global context을 잘 활용할 수 있도록 도와주는 보조적인 역할을 수행한다고 보시면 될 것 같습니다.
정리하면 Patch Encoder는 다양한 크기의 local patch로부터 공통 표현을 추출하고,
Image Encoder는 global context를 조금 보완적으로 제공해서 decoder가 보다 정확한 depth를 추론할 수 있도록 지원한다고 이해하심 될 것 같습니다.
사실 제가 질문의 의도를 이해하지 못해서 조금 장황하게 설명드렸는데 답변이 되었을까요
감사합니다.
좋은 리뷰 감사합니다. 제가 depth쪽은 거의 지식이 없어서 새롭게 배우는 느낌으로 재밌게 읽었습니다. 실험 테이블에서 경계 예측하는 부분에서 궁금한점이 있는데요, depth를 잘 예측해야하는만큼 물체의 경계를 잘 예측해야 하는 것은 이해가 가는데, table2같은 경우에 지표가 그럼 어떻게 측정이 되는건가요? 무엇을 경계라고 하는지, 어떻게 측정하는지 궁금합니다.
감사합니다
안녕하세요 재연님 읽어주셔서 감사합니다.
Depth pro의 중요한 컨트리뷰션 중 하나로 depth boundaries 를 평가하기 위한 새로운 지표(metric) 세트를 제안하는데 이를 리뷰에 적지 않았네요.. ㅠ
여기서 추가적인 설명을 드리겠습니다.
일단 기존에는 픽셀 단위로 정밀하게 깊이 정답을 갖춘 다양하고 현실적인 데이터셋들을 구하기가 쉽지 않기 때문에 저렇게 샤프한 경계를 기존에는 평가하기가 힘들었다고 합니다.
그래서 위와 같은 한계를 좀 해결하기 위해 기존의 세그멘테이션 용 고품질의 데이터 셋이라던지, 매팅용 등등으로 제작된 좀 픽셀 단위로 gt가 정확히 존재하는(경계를 평가할 수 있는) 그런 데이터 셋을 재활용을 하자!라고 하였고 이것이 핵심이라고 보시면 될 것 같습니다. 어떻게 보면 깊이 경계에 대한 간접적인 GT로 활용하는 것이죠
그래서 이제 실제로 재연님께서 궁금하신 부분에 대해서 답변을 드리자면,
먼저 예측한 depth map에서 인접한 두 픽셀 간의 depth 차이가 일정 비율 이상인 경우에 두 픽셀 사이를 경계(occlusion boundary)라고 판단을 합니다. 그 다음에 이제 이 예측된 경계가 실제 GT로부터 얻어낸 경계와 얼마나 정확히 겹치는지 (Precision), 얼마나 많이 놓치지 않았는지 (Recall)를 계산해서 F1 score을 얻는 방식으라고 보시면 될 것 같습니다.
아 그리고 추가적으로 segmentation이나 matting 데이터셋은 경계가 완전히 정답이라고 보긴 어려운 경우가 있어가지고 이런 경우에는 Recall만 측정해서 얼마나 예측이 잘 맞는지만 보는 식으로 구성되어 있습니다.
답변이 되셨을까요!
감사합니다!