안녕하세요 오늘도 Scene text recognition 주제의 논문을 들고 왔습니다. 특히 단어가 가지는 의미 정보를 활용한 recognition 연구에 관심이 있어 해당 주제 위주로 공부하고 있습니다. 제가 오늘 리뷰할 SEED란 연구도 그런 연구 중 하나로 단순한 구조의 프레임워크지만 Language mode로 부터 semantic한 정보를 활용해 보다 정확한 recognition을 수행합니다. 그럼 바로 리뷰로 넘어가보겠습니다.
1. Introduction and Related Studies
문서에서 텍스트를 읽는 연구의 경우 연구가 충분하게 되어 그렇게 challenging한 태스크는 아니였습니다. 다만 여전히 natural scene에서의 텍스트 인식 성능은 좋지 않았습니다. 특히 흔들리게 촬영돼 흐릿하거나 텍스트 주변 배경과의 interference가 있는 경우, occlusion등으로 character 전체가 선명하게 보이지 않는 경우의 그 정확도는 더욱 낮았습니다. Scente text recognition 분야에서는 해당 상황에서의 문제를 tackle하는 것이 주요한 연구 goal이었습니다.
자연어 처리 분야에서 성공적으로 활용된 어텐션 기반의 인코더-디코더 구조의 모델을 text recognition 연구에 사용하는 연구들도 많았습니다. 대부분의 이런 모델들은 RNN과 함께 CNN 기반의 인코더로 부터 텍스트 이미지에서 visual features를 extract하고 RNN기반의 디코더로 character 하나씩을 예측하는 구조를 따랐는데요.
이런 기존의 방법들은 text recognition task를 시퀀스로 나열된 character를 분류하는 문제로 풀곤해 character 하나 즉 local한 정보 위주를 활용했었습니다. 텍스트 전체의 global information 은 사용하지 않았기 때문에 앞서 일부 나열했던 low-quality image가 주어져 인식을 해야할 경우 정확도가 떨어졌습니다. 논문의 저자는 이 문제는 text 전체의 global한 information을 활용하면 해결될 문제라고 생각했답니다.
그리고 제안한 것이 Semantics Enhanced Encoder-Decoder framework (SEED)입니다. 텍스트를 인코딩할 때 visual feature만을 extract하고 마는 것이 아닌 이를 활용해 semantic information을 함께 예측하는 것입니다. 그리고 이를 global information으로 활용해 decoding을 수행하는 것이다. 이때, 모델은 사전 학습된 language model로 부터 supervise를 받아 semantic information을 예측해 실제 단어가 갖는 semantic information을 충분히 represent할 수 있게 합니다.
간단하게 요약하자면 글자 하나하나를 따로 분리해 생김새만으로 인식하는 것은 어려운 경우가 있을 수 있으니 텍스트 전체 텍스트 자체가 갖는 의미를 유추하며 최대한 정답에 가까운 예측을 하자는 것입니다. 사람이 글자를 읽기 전 간혹 그 뭉뜽그린 형태를 먼저 보고 짐작을 하는 가운데 글자 하나씩을 읽어내려가는 것과 같은 원리라고 보시면 됩니다.
논문에서는 제안하는 프레임워크를 기존의 SoTA인 ASTER에 통합해 성능을 보입니다.
2. Methods
그럼 이번 절에서는 SEED의 방법론을 설명하겠습니다.
모델 구조는 다음과 같습니다
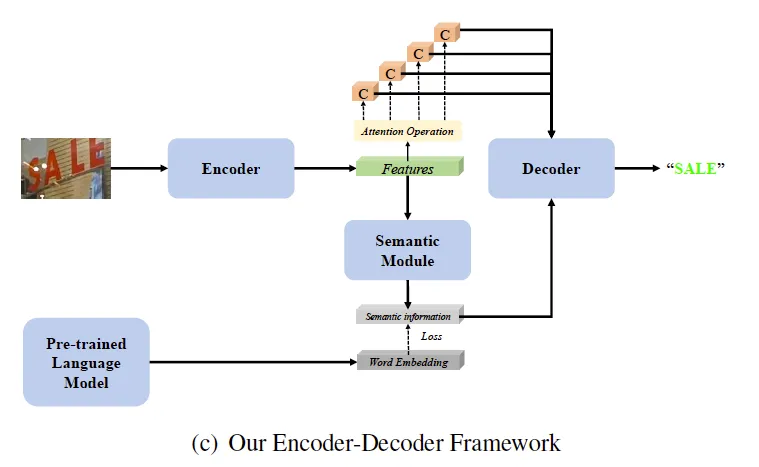
크게 4개의 요소로 나눠볼 수 있는데 1) CNN 백본과 RNN이 있는 인코더는 text image의 visual feature를 extract하기 위함입니다. 2) semantic module은 visual feature로 부터 semantic information을 예측합니다 3) pretrained language model이 있는데 semantic module로 부터 학습된 semantic information 학습을 지도하는 역할을 수행합니다 4) 마지막으로 디코더는 RNN으로 설계돼 있으며 최종적인 recognition 결과를 순차적으로 예측합니다.
2.1 FastText Model
pretrained language model로는 FastText를 사용합니다. 저는 FastText는 처음 알게되었는데 이는 Facebook AI Research에서 만든 단어 임베딩 모델로 중심 단어를 입력하면 주변 단어를 예측하도록 학습이 되며 같은 문맥 즉 같은 문장 안에 등장하는 단어 사이에 공유하는 의미가 비슷할 거다라는 생각을 가지고 단어 임베딩을 학습합니다. 그리고 문장 속 각 단어의 임베딩은 단어를 구성하고 있는 subword의 임베딩들의 합으로 결정되어 out of vocabulary에 대해서도 강건함을 보이는 것이 특징입니다. novel한 단어나 일부 글자가 잘려 확인이 어려운 단어가 natural scene에서는 많은데 이런 점에서 해당 language model을 사용하는 것이 SEED를 설계하는데도 큰 강건성을 주었다고 설명합니다.
2.2 General Framework
많은 scene text recognition 방법론은 인코더 디코더 구조를 가져갑니다. 인코더에서 visual feature를 추출하면 디코더에서는 각 글자에 대응되는 영역의 visual feature를 사용해 각 recognition 결과를 순차적으로 뽑습니다. 이런 방법은 text recognition에 적용하기에 좋은 방법이었으나 하나의 글자의 visual feature가 정확하지 않은 경우에는 어렵습니다. 그래서 global semantic information을 함께 활용해 이 문제를 다루고자 했습니다.
기존의 어텐션 기반의 인코더 디코더에서 더 나아가 semantic module을 덧붙여 semantic information을 추가로 예측하게 설계하였고 사전 학습된 language model에서의 word embedding으로 부터 supervision을 받도록 하였습니다.
2.3 Architecture of Semantics Enhanced ASTER
이 논문에서는 해당 프레임워크를 ASTER에 적용해 프레임워크의 유효성을 확인하였습니다. 저자는 이렇게 통합된 모델을 Semantics Enhanced ASTER (SE-ASTER)이라고 칭했습니다. 해당 모델의 구조도는 아래와 같습니다
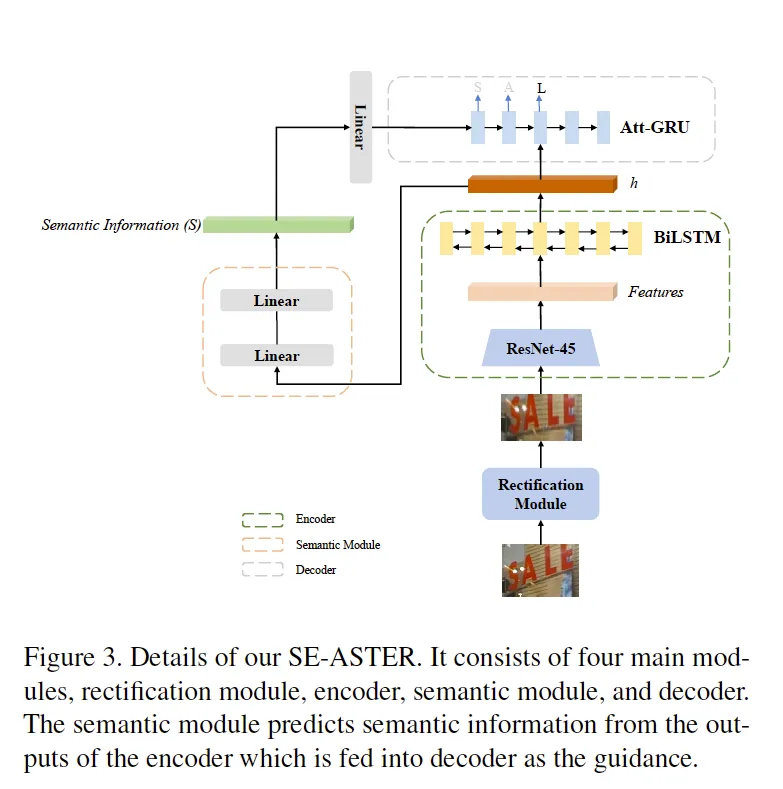
4개의 모듈로 구성돼 있습니다. irregular 텍스트를 rectify하기 위한 rectification module, text image 로 부터 visual features를 추출하기 위한 인코더, semantic module, 디코더로 구성됩니다. 앞서 설명한 SEED와 다른 점은 인코더 앞단에 rectification module이 붙는다는 것입니다.
학습 과정을 설명하겠습니다. 모델의 입력으로 텍스트 이미지가 들어갑니다. rectification module로 부터 텍스트에 대한 왜곡이 보정됩니다. 보정된 텍스트 이미지가 인코더의 입력으로 들어가고 visual feature가 추출됩니다. 인코더는 45계층의 CNN 레이어와 2 계층의 Bidirectional LSTM (BiLSTM) 네트워크로 구성돼 있습니다. 인코더의 출력은 feature sequence의 형태로 나옵니다.
출력된 feature sequence는 다음 semantic module과 디코더의 입력으로 사용됩니다. semantic module에 입력으로 넣기 전 feature vector를 1차원의 벡터로 변환합니다. semantic module은 상당히 간단한데요. 두개의 linear layer로 구성된 모듈로 결과로 semantic information S가 출력됩니다.
디코더는 Bahdanau-Attention 매커니즘을 따르는데 이는 하나의 attentional GRU 계층으로 구성되며 단방향으로 설계되어 각 단어를 예측할 때 마다 이미지의 각 글자가 위치한 영역에 집중해서 예측을 수행합니다.
semantic module의 출력인 semantic information은 하나의 선형 레이어를 통과해 차원수가 맞춰지고 디코더에서 GRU의 상태를 초기화하는데 사용됩니다.
2.4 Loss function
학습 시 최적화는 semantic module과 디코더에서 이뤄집니다. SE-ASTER는 end-to-end하게 학습되구요. 즉, 입력부터 출력까지의 하나의 통합된 네트워크로 하나의 loss function으로 학습이 이뤄집니다. 아래는 모델 최적화를위한 loss fucntion입니다.
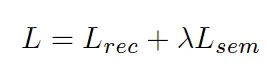
모델의 최종 출력인 텍스트 시퀀스에 대해 각 character에 대한 예측 확률을 가지고 GT와의 cross entropy가 계산된 것이 L_rec입니다. 그리고 L_sem은 예측된 semantic information과 실제 text transcription자체에 대해 FastText로 부터 나오는 워드 임베딩간의 cosine embedding loss를 구한 것입니다. 람다는 두 loss의 균형을 두기 위해 더한 하이퍼파라미터로 저자는 1로 설정하였다고 합니다. contrastive loss대신 cosine embedding loss를 사용한 것은 학습 속도를 빠르게 하기 위함이라고 합니다. 해당 loss는 아래의 식으로 구해질 수 있습니다.
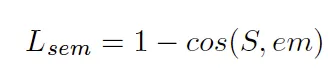
3. Experiments
추가적인 사전학습이나 데이터 증강 없이 합성된 대량의 데이터셋에 대해서 학습됐다고 한다.
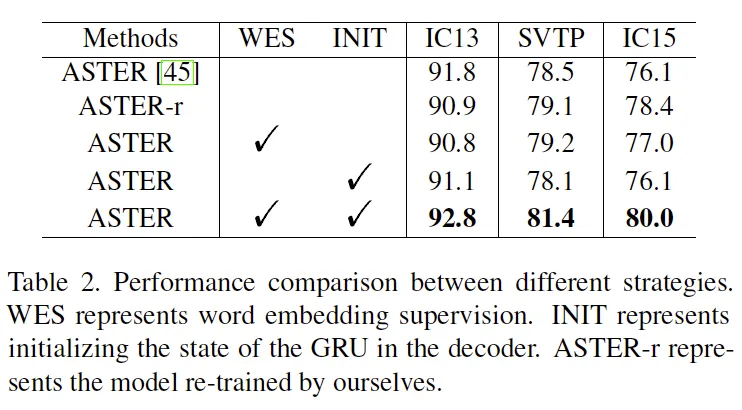
semantic information과 정답 word embedding 간의 semantic loss는 구하지만 디코더는 평소대로 0으로 초기화 하는 것과 semantic loss는 빼고 예측한 semantic information으로 디코더를 초기화는 방법을 비교한 실험입니다. semantic loss를 구하지만 디코더를 0으로 초기화하는 것은 그리 성능 향상을 가져오진 않았습니다. semantic 모듈이 디코더에 어떠한 영향도 주지 않기 때문이라고 설명합니다. semantic information으로 초기화하는 것은 SCTP, IC15 데이터셋 같은 low-quality 데이터셋에 대해서 더 낮은 성능을 보였습니다. 예측된 semantic information이 오히려 방해가 되었고 pretrained language model로 부터의 supervision이 필요하단 것을 알 수 있는 결과였습니다. 마지막으로 이 둘을 합친 경우 즉 논문에서 제안하는 방법이 제일 성능이 좋습니다. 여기서 Table 2.의 ASTER-r는 논문의 저자가 본인 환경에서 학습한 결과로 특히 앞선 두 방법에 비해 low-quality 텍스트가 많은 SVTP, IC15에서 성능 향상이 이뤄진 것으로 보아 실제 incomplete 단어를 recognize하는데 도움이 되었다고 생각해볼 수 있습니다.
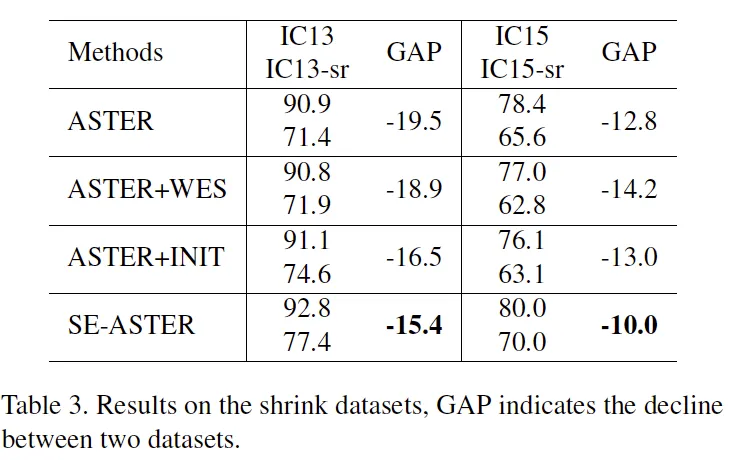
실제 task recognition은 text detection과 함께 수행되어야 하는 경우가 많습니다. 부정확한 detection으로 인해 incomplete text같은 상황이 발생하고 이런 경우 정확한 recognition이 이뤄지지 않게 됩니다. 이를 error accumulation이라고 하는데 논문의 저자는 incomplete text같이 low-quality의 텍스트에 대해 강인함을 가진 SEED 모델이 해당 문제에 대한 대안이 되겠다고 하며 진행한 실험입니다. 평가 이미지에 대해 랜덤하게 일부를 제거한 shrinked 데이터셋을 구축해 평가를 진행해 성능이 하락하는 정도를 비교하였습니다. SE-ASTER는 학습 시 데이터에 대해 증강을 일절 하지 않았습니다. 결과를 정리하자면 논문에서 제안한 방법으로 성능 향상 폭을 다른 방법과 비교해서 크게 줄일 수 있었습니다.
정성적 결과는 아래에 있습니다
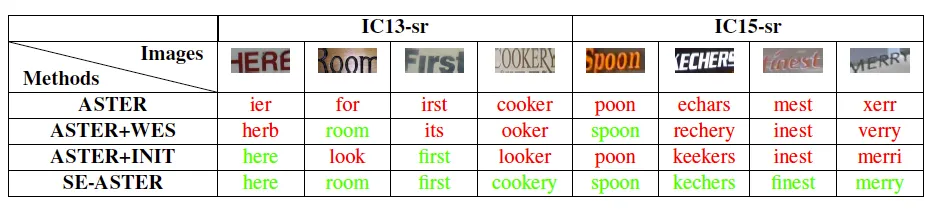
다음으로 각 이미지 마다 단어 목록 (lexicon)을 주고 예측되는 semantic information와 각 단어의 word embedding간의 cosine 유사도를 시각화학 결과입니다
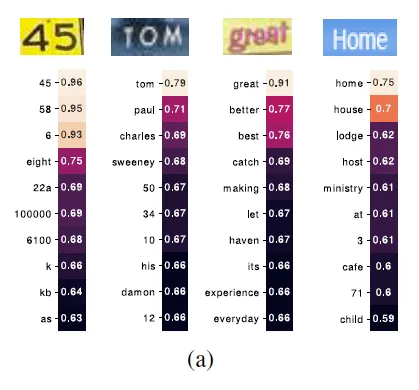
의미가 비슷한 단어와의 유사도가 높게 나오는 것을 확인할 수 있습니다. 예를 들면 Home은 home과 그리고 house, lodge같이 모두 사람이 거주하는 공간을 나타내는 단어와 제일 유사도가 높았습니다.
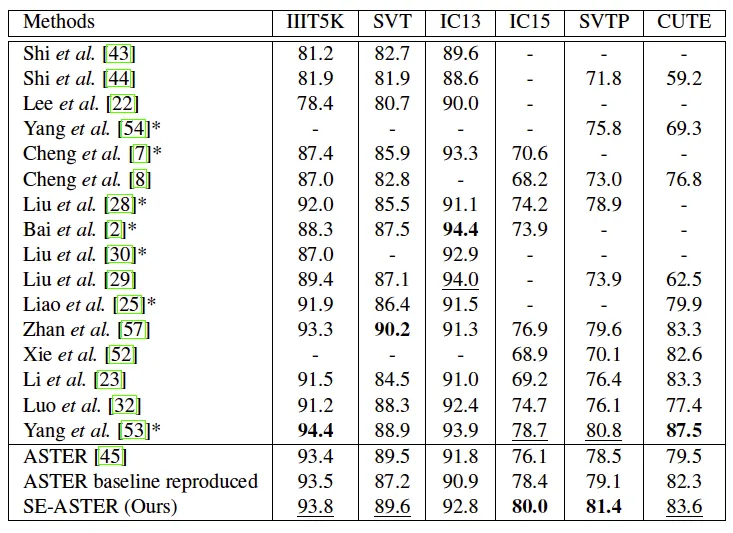
위는 다른 SoTA간의 성능 비교 결과입니다. 앞서 한번 얘기했지만 low quality text 데이터셋인 IC15와 SVTP에서의 성능은 제일 높았습니다. 다른 데이터셋에서는 두번째 정도의 순위를 갖습니다. 저자는 베이스라인과의 성능 향상 정도를 더욱 강조하며 제안하는 프레임워크는 다른 모델에도 쉽게 적용할 수 있기 때문에 다른 모델에 적용하면 보다 높은 성능을 보였을 것이라고 설명합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 사용한 language model이 FastText고 얘는 각 단어의 embedding을 subword embedding의 합으로 결정해 out of vocabulary에 강건함을 보이는게 특징이라고 하셨는데, subword가 구체적으로 뭐고 어떻게 구성이 되는건가요 ? character 의미를 담고 있는건지, 혹은 최소한의 의미를 담는 부분을 말하는건지, 와닿지 않아 질문드립니다.
또, table3에서 이미지에 대해 랜덤하게 일부를 제거했다는게, 평가 영상 일부를 없애는게 아닌 image 내부 픽셀을 랜덤 마스킹한걸로 이해하면 될까요? 그 비율이 어느정도였는지 궁금합니다.
감사합니다.
안녕하세요 윤서님 질문 감사합니다.
1. 단어를 구성하는 인접한 character 묶음을 하나의 subword입니다. 예를 들어 subword의 길이를 다음과 같이 정해두고 (l_min = 2, l_max = 4) ‘where’이란 단어의 subword 집합은 다음과 같이 나타낼 수 있습니다. ({wh, he, er, re, whe, her, ere, wher, here}) 단어 전체에 대한 임베딩과 가능한 모든 subword가 갖는 임베딩이 더해져 ‘where’이란 하나의 단어의 임베딩이 결정됩니다.
2. 이미지를 크롭했다는 의미입니다. 제가 읽어도 명확하지가 않았네요. 이미지의 위, 아래, 좌, 우 방향에 대해서 동시에 최대 15% 까지 crop을 수행합니다.
감사합니다.
안녕하세요 지연님 좋은리뷰 감사합니다.
되게 예전 논문인데도 텍스트 임베딩으로 유사도계산을 이용하는 방식이 사용됐었네요.. 뭔가 semantic moduel이 이름은 중요해보이는데 그냥 임베딩 벡터로 만드는 linear layer 두개인 것 같고 fasttext 가 주요할 것 같습니다. 궁금한점은 semantic information 을 하나의 선형 레이어를 통과시키고 나서 디코더의 GRU 의 상태초기화에 사용된다 하셨는데 그렇게 사용해도 되는 이유나 개념에 대해 조금 더 자세히 설명해주시면 감사하겠습니다.
GRU는 순환신경망(RNN) 중 하나인데요 입력 시퀀스에 대해서 순차적으로 학습할 때 게이트란 걸 사용해 이전 정보를 얼마나 취하고 버릴지를 선택할 수 있게 해 장기의존성 문제를 해결한 LSTM과 비슷하지만 비교적 더 간단한 구조를 갖는 신경망입니다. 이 논문에서 semantic information으로 GRU의 초기 (hidden) state를 설정하는데요 입력된 텍스트 이미지에서 텍스트가 갖는 의미 정보를 초기의 hidden state으로 설정해 GRU의 입력과 함께 학습됩니다. 입력 시퀀스 내에서만 문맥을 고려해도 되는 일반적인 경우에는 초기 상태가 0으로 초기화 되고 이후의 학습 과정에서 이전 입력 시퀀스로 부터 학습한 정보를 hidden state으로 넘겨주는 것과 달리 해당 모델은 외부적으로 semantic한 정보를 주입하는 과정이 추가적으로 필요하기 때문에 이렇게 설계했다고 보시면 되겠습니다.
안녕하세요 지연님 좋은 리뷰 감사합니다.
Experiments 초반 부분에서 “semantic loss는 구하지만 디코더를 0으로 초기화하는 것”과 “semantic loss 없이 디코더를 semantic information으로 초기화하는 것”을 비교했다고 하셨는데, 두 실험 설정이 각각 모델의 어떤 부분에 영향을 주는지를 제가 이해하지 못했는데 좀더 부연 설명해주실 수 있을까요? 언뜻 보면 둘 다 semantic module을 사용하는 것 같은데 역할이 헷갈립니다.
얘기해주신대로 두 경우 semantic module을 통해 시각 특징으로 semantic information을 생성하고 이는 LM의 워드 임베딩과 유사하도록 학습된다는 건 동일합니다.
GRU라는 순환신경망을 이용해 인코딩된 시각 피처를 시퀀스로 받아 각 피처가 어떤 문자에 대응될지를 예측하도록 학습 하는데요 이때 입력 이미지에서의 텍스트가 가지는 의미인 semantic 임베딩을 신경망의 첫 입력에 대한 hidden state으로 사용할지 여부에 대한 것이라고 보시면 됩니다. semantic loss를 계산하지만 GRU를 0으로 초기화한다는 것은 semantic module로 부터 예측한 텍스트에 대한 의미 정보를 고려하지 않겠다는 것라고 보면 되겠지요!