이번에 소개드릴 논문은 CVPR2025에 게재된 논문으로 Visual Navigation task 관련 논문입니다.
메타, 뉴욕대, 버클리 AI research에서 작성한 논문이고 교신저자가 르쿤이 형이여서 그런지 포스터 섹션에서도 많은 사람들이 몰린 논문이었고 oral 발표도 했었더군요.
Intro
보통 사람은 어떤 목적지로 길을 찾고 가려고 할 때, 제약 조건과 반사실성을 고려하면서 그들의 향후 경로를 상상할 수 있다고 합니다. 쉽게 얘기해서 한번 가봤던 장소에서 길찾기 할 때 기존에 화장실까지 간 다음 우회전해서 쭉 가면 목적지에 도착했었지만 만약 그 장소가 막혀있거나 할 경우 다시 우회하여 다른 길로 가는 방법에 대해 상상을 할 수 있다는 말이죠.
근데 현존하는 로봇 네비게이션 방법론들은 agent에 대한 정책이 일명 하드코딩되어 있기 때문에, 새로운 제약 조건이 주어지는 경우에는 그 조건을 지키면서 길 찾기를 수행하기 어렵다고 합니다. 예를 들어 로봇한테 좌회전을 하지 말고 목적지에 도착해 라고 명령을 하면 모델이 그것을 지키면서 올바른 길찾기를 하기 어렵다는 뜻이죠.
또한 기존의 supervised visual navigation 방법론들은 더 어려운 길찾기를 수행해야하는 상황에서 많은 연산량을 수행하기 위한 추가적인 메모리 할당을 능동적으로 못한다고 합니다. 사실 이 부분은 제가 기존 work을 자세히 알지 못하고 저자들도 특별히 설명하고 넘어가지 않아서 부가적인 설명을 드리기가 어렵네요^^..
아무튼 기존의 방법론들은 무언가 모델 설계 자체에 한계가 존재하기에 다양한 제약 조건을 모델한테 준다거나 이러한 더 복잡한 상황을 고려해야하는 상황에서 메모리 한계가 있는 등 단점들이 존재하는 것 같습니다. 그래서 저자들은 기존의 연구들과는 완전히 다른 새로운 framework을 제안합니다. 바로 과거 프레임들의 표현과 액션을 기반으로 비디오 형식의 미래 특징들을 예측하는 모델을 만들어내는 것이죠. (아래 그림 참조)
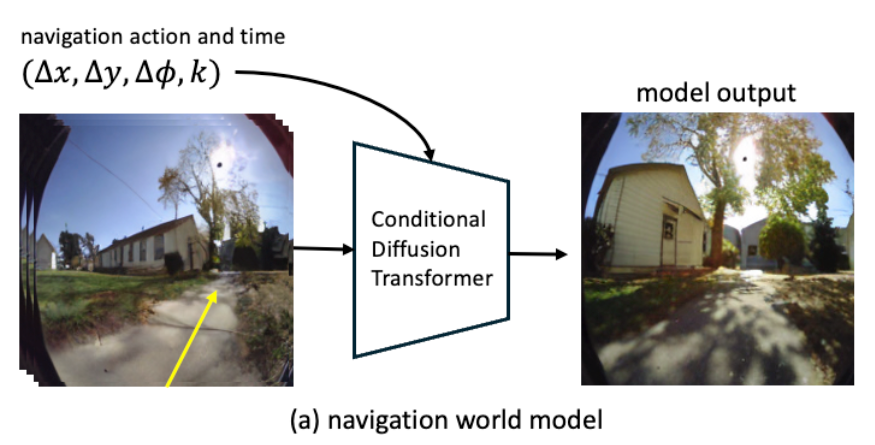
저자들은 이를 Navigation World Model(NWM)이라고 명칭하였습니다. NWM은 우선 다양한 로봇 에이전트로부터 수집된 방대한 양의 비디오 데이터로 학습을 합니다. 학습이 마친다면 NWM은 이제 잠재적인 네비게이션 계획을 스스로 시뮬레이션하고 이 방식대로 갈 경우에 올바르게 목적지에 도달할 수 있는지 검증함으로써 새로운 경로를 계획합니다. (아래 그림 참조)

저자들은 경로 예측 단계에서, Model Predictive Control (MPC) framework에서 NWM을 사용하여 NWM이 성공적으로 목적지에 도달할 수 있도록하는 action sequence를 최적화하였습니다.
또 다른 방식으로는 기존의 navigation을 수행하는 방법론을 가져와 자신들의 NWM이 시뮬레이션한 영상을 토대로 경로를 예측하도록 하고 이 경로들 중 가장 우수한 경로를 선택하는 방식 등을 통해 자신들의 NWM이 네비게이션을 수행하는데 얼만큼 도움이 되는지를 평가하였다고 합니다.
저자들의 모델은 방대한 양의 데이터와 그 데이터에 속해있는 다양한 환경, 움직이는 객체 종류 등을 학습하였으며 덕분에 하나의 모델만으로 별도의 3D 정보 없이 다양한 환경과 시간축에 따른 동적 움직임 등을 파악하고 길찾기를 수행한다고 하네요.
Method
그럼 저자들이 제안하는 NWM은 어떤식으로 구성되었는지 방법론에 대해서 알아보겠습니다.
우선 NWM은 현재 world에 대한 상태를 파악할 수 있게 해주는 데이터 (관측 영상)과 어디로 움직이고 바라보는 중인지를 나타내는 action 값을 입력으로 받게 됩니다. 이러한 입력을 토대로 모델은 agent가 바라보는 시점을 기준으로 한 미래 상태 값을 예측합니다.
그래서 모델 학습에 사용되는 데이터셋은 ego-centric video dataset 형식으로 구성이 되어 있는데, 수식으로 나타내면 아래와 같습니다.
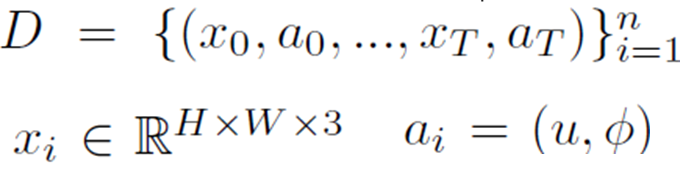
우선 D는 ego-centric video이고 여기서 x는 RGB 이미지를, a는 translation u와 rotation 파이선 D는 ego-centric video이고 여기서 x는 RGB 이미지를, a는 translation u와 rotation 파이 값으로 구성됩니다. translation은 앞,뒤, 좌,우 움직임을 나타내고 action은 yaw pitch roll 3가지 중 yaw angle만을 고려한다고 합니다.
저자들의 목적은 이전의 관측 정보들과 액션 정보들을 토대로 그 다음 미래의 latent state로의 확률적 맵핑을 수행하는 world model F을 만들어내는 것입니다.
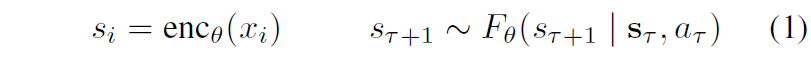
여기서 s_{\mathcal{T}} = (s_{\mathcal{T}}, ..., s_{\mathcal{T}-m}으로 사전학습된 Variational AutoEncoder를 통해 인코딩된 과거 m개의 시각적 관측 값들을 의미합니다. VAE를 사용하는 이유는 latent를 압축시킬 수 있다는 이점이 있으며, 시각화가 필요한 경우 디코딩 과정을 통해 쉽게 픽셀 공간으로 다시 되돌릴 수 있기 때문이라고 합니다.
또한 저자들은 환경과 에이전트의 형태에 구애받지 않는 단일 월드 모델을 학습시키는 것이 목적이라서, task 또는 액션과 관련된 임베딩을 전혀 사용하지 않았다고 합니다. World Model을 만들 때 최대한 단순한 구조를 채택함으로써 어떠한 환경과 에이전트에 적용하더라도 무난하게 잘 동작하도록 의도한 것으로 보이네요.
아무튼 위에 수식1은 액션을 모델링한 것이긴 한데 사실 저 수식1은 시간에 따른 dynamic을 제어하는 부분에 대해 전혀 고려하지 않은 내용이라고 합니다. 그래서 저자들은 time shift k라는 변수를 새로 추가하여 액션 a_{\mathcal{T}} 을 translation, rotation과 더불어 time shift k도 함께 추가하였습니다. 조금 더 설명하자면, a_{\mathcal{T}} 은 시간 변화 k에 따라서 특정화되며, k를 통해 모델이 미래 또는 과거로 몇 단계만큼 이동해야하는지를 결정할 수 있게 됩니다.
따라서, 현재 상태 s_{\mathcal{T}} 가 주어졌을 때, 저자들은 랜덤하게 timeshift k 값을 지정하고 이를 토대로 비디오 프레임을 이동시킴으로써 그에 대응되는 미래 상태 s_{\mathcal{T}+1}을 정의할 수 있는 것이죠. 그러면 네비게이션 액션은 \mathcal{T} 로부터 k만큼 움직인 m = \mathcal{T}+ \mathcal{k} -1 까지의 합으로 근사화할 수 있다고 합니다.
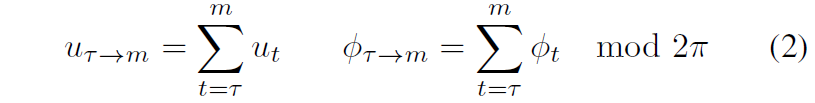
위의 수식과 같은 구성을 통해 모델은 네비게이션 액션에 대해 학습하는 것 뿐만 아니라 추가로 환경에 대한 temporal dynamic까지 학습할 수 있다고 합니다. 참고로 저자는 이 K 값을 +- 16으로 설정했다고 하네요.
Diffusion Transformer as World Model
아까전에 저자들은 world model F가 확률적 맵핑을 수행하도록 만드는 것이라고 했었죠. 그래야만 확률적 환경에 대해서 시뮬레이션을 할 수 있을 것이니깐요. 저자들은 이를 위해서 world model F를 Conditional Diffusion Transformer (CDiT)를 기반으로 만들었다고 합니다.
우선 CDiT의 구조에 대해서 살펴볼 필요가 있겠네요. CDiT의 구조는 아래와 같습니다.
보시면 self-attention, cross-attention, FFN 등 메인 stream이 좌측에 존재하고 있고, 우측에는 condition 정보를 주는 브랜치가 있는 모습입니다. 여기서 컨디션으로 사용되는 정보는 action, timeshift, diffusion step 등의 값들이 있는 모습이네요.
메인 스트림에 대해서 우선 더 자세히 살펴보면, Future state (target frame)에 대해서만 self-attention을 먼저 수행하고 있는 모습이며 이 덕분에 저자들은 CDiT가 시간 효율적인 autoregressive modeling을 수행할 수 있다고 강조합니다.
그리고 과거 프레임에 대한 토큰 정보들을 조건으로 전달해주기 위해서, cross-attention을 수행하게 됩니다. 여기서 query token은 target frame에 해당하고 Key와 Value 값이 과거 프레임에 대한 토큰 정보들로 구성되는 모습입니다.
그리고 우측에 conditioning brench에 대해서도 소개하면, 아까 컨디션 값들은 translation과 rotation으로 구성된 action 값, timeshift k 그리고 diffusion step을 의미하는 time t 총 3개의 값으로 구성이 되어있다고 했었죠. 저자들은 여기에 sine-cosine feature를 추출함으로써 d/3 형태의 차원으로 맵핑을 수행해주었다고 합니다. 그 이후에 2개의 MLP layer를 태워준다음 그 feature들을 모두 concat하여 d차원 길이의 벡터 ψa를 만들어주었다고 하네요.
이렇게 action을 어떠한 임베딩 벡터로 변환한 것과 마찬가지로 timeshift와 diffusion step 값 역시 동일하게 임베딩 벡터로 만들어주었다고 합니다. 그리고 이 3개의 임베딩 벡터를 아래와 같이 다 더함으로써 최종적인 conditioning vector를 만들 수 있다고 하네요.
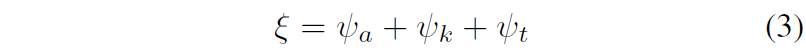
이 컨디션 벡터는 AdaLN 블록을 통과해 scale과 shift 상수를 만드는데 활용이 되고, 이 값들이 아까 전 main brench에서 attention을 수행하기 직전 layer normalization할 때의 scale과 shift 파라미터로 활용이 되게 됩니다.
일단 저자들이 이 Diffusion Transformer(DiT)에 condition 조건을 넣도록 하는 CDiT 구조를 새롭게 만든 것 같아요. 그래서 DiT와의 차별성을 강조하는 부분이 논문에 담겨있는데 그 부분에 대해서 조금 설명드리면, 우선 전체 입력에 대해 DiT를 바로 적용하게 될 경우 연산량이 너무 많이 늘어나게 된다고 합니다.
프레임 당 입력 토큰의 개수를 n이라 하고, frame 길이를 m, 각 토큰의 차원을 d라고 해봅시다. 이때 기존의 DiT를 활용하게 되면 scaled Multi-head attention을 수행하는데 있어 예상되는 연산량은 O(n^{2}, m^{2}, d) 라고 합니다. 즉 프레임 길이에 대해서도 제곱이고 프레임 별 토큰의 개수에도 제곱의 연산량을 가지게 된다는 것이죠.
반면에 저자들이 제안한 CDiT 구조는 cross-attention 과정을 통해 프레임들 간에 정보 교환을 시킬 수 있게하고 이 연산량 자체가 프레임 내 토큰 개수의 제곱만큼 연산량이 소모되므로 ( O(m, n^{2}, d) , 더 많은 프레임을 활용해서 context를 더 풍부하게 가져갈 수 있다고 합니다.
Diffusion Training
결국 Diffusion 모델이기 때문에 학습 방식도 noise를 제거하는 방식으로 학습이 진행됩니다. 우선 forward 단계에서 target state s_{\mathcal{T}+1} 에 노이즈를 추가해주게 되는데, 이 노이즈는 임의의 timestep t에 따라 무작위로 선택되어진다고 합니다. 조금 더 구체적으로 noisy state s^{(t)}_{\mathcal{T}+1}은 아래 수식과 같이 표현할 수 있습니다.
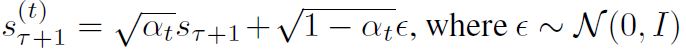
여기서 앱실론은 가우시안 노이즈를 의미하고, \alpha_{t}는 노이즈 스케쥴을 제어하는 분산 값이라고 합니다. 여기서 diffusion step t 값이 커지면 커질수록 s^{(t)}_{\mathcal{T}+1}은 순수한 노이즈 값이 되는 것이라고 이해하시면 될 것 같습니다.
reverse 과정에서는 주어진 조건들 (context s_{\mathcal{T}} , current action, diffusion timestep t)을 토대로 s^{(t)}_{\mathcal{T}+1}로부터 original state s_{\mathcal{T}+1}을 되찾는 과정을 수행하게 됩니다. 저자는 denoising하는 모델 파라미터를 아래와 같은 수식으로 표현합니다.
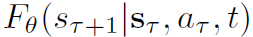
모델의 목적 함수는 clean target과 predicted target 사이에 mean-squared error를 계산하는 것으로 노이즈를 제거하는 것을 목표로 학습한다고 이해하시면 되겠습니다.
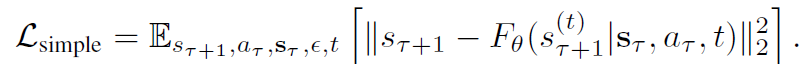
위에 loss를 줄임으로써 모델은 현재 상태의 context, action등을 조건으로 사실적인 future frame을 생성할 수 있게 학습이 됩니다. 그리고 저자들은 DiT 논문들과 동일하게 노이즈의 공분산 행렬을 예측하고 이를 variational lower bound loss를 통해 지도학습을 했다는데 이 부분은 DiT 논문을 아직 읽지 못해서 리뷰에 설명을 담지 못하겠네요:(
Navigation Planning with World Models
지금까지는 World Model의 구조와 학습 방식에 대해서 알아보았습니다. 근데 이제 결국 이 World Model이라 함은 future frame을 생성하는 약간 novel view synthesis에 더 가까운? 느낌이 듭니다. 하지만 논문의 제목과 main task는 결국 navigation이란 말이죠? 지금부터는 world model이 navigation을 수행하는데 있어 어떻게 활용될 수 있는지에 대해 소개하려고 합니다.
우선 직관적으로, 우리가 이미 한번 가본 경험이 있는 환경에서 길을 찾는다고 한다면, World model은 목적지까지 도달할 수 있는 여러 경로들을 simulation 한 뒤 그중에서 가장 괜찮은 경로 하나를 골라서 나아가면 됩니다. 만약에 한번도 보지 못하는 환경이 주어졌을 때는, 아무래도 world model의 상상에 의존해서 길을 찾아나갈 수 밖에 없겠네요.
수식적으로 표현하면, latent encoding s_{0} 와 navigation goal s^{*} 가 주어졌을 때, goal에 도달할 likelihood가 최대화되는 action의 sequence (a_{0},...,a_{\mathcal{T}-1}) 을 찾아야만 합니다.
더 구체적으로, 초기 condition s_{0} 와 action a = (a_{0}, ... , a_{\mathcal{T}-1}) 이 먼저 주어지면 이들을 NWM의 입력으로 사용해서 1~T time 까지의 state들을 계산할 수 있습니다 (즉, s = (s_{1}, ..., s_{\mathcal{T}}), s ~ F_{\theta}(\cdot | s_{0}, a) ).
이렇게 T step에서의 state s_{\mathcal{T}} 에서 최종 목적지인 s^{*} 까지 도달가능한지에 대한 비정규화된 점수를 \mathcal{S}(s_{\mathcal{T}}, s^{*}) 라고 나타낸다고 합니다. 이 비정규화된 점수는 무엇이냐면, 두 state에 대한 비정규화된 perceptual similarity라고 하더라구요? 쉽게 말해서 지금 state가 VAE를 통해 encoding되어있으니 다시 decoder를 통해 pixel-space로 decoding할 수 있고 이렇게 디코딩된 이미지들에 대해서 얼만큼 시각적으로 유사한지에 대한 유사도를 계산했다고 합니다.
그리고 저자들은 추가로 초기 state와 T step에서의 state 그리고 그 T 단계까지 도달하기 위한 일련의 action 결과값들을 입력으로 하는 energy function을 새로 정의합니다. 우선 이 energy function이 어떤 항들로 구성되어있는지부터 보여드릴게요.
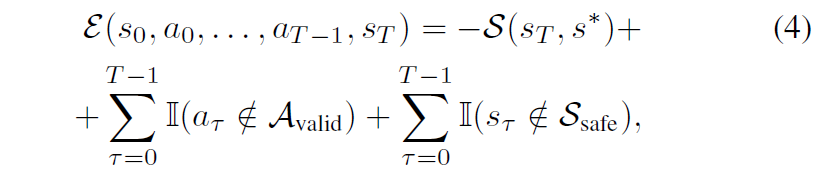
우선 제일 첫번째 텀은 아까 위에서 T번째 state와 최종 목적지에 해당하는 state에 대한 비정규화된 perceptual similarity score를 의미합니다. 근데 이제 저자들은 이 유사도 스코어가 높아야하고 반대로 에너지 함수는 최소화가 되어야하기 때문에 저 유사도 스코어 텀 앞에 -를 붙인 모습입니다.
두번째 텀과 세번째 텀은 각각 action과 state에 대한 constraints를 의미합니다. action에 대한 제약 조건 예시로는 “never go left and right”와 같을 수 있는데 이러한 제약 조건에 만족되는 action이 \mathcal{A}_{valid} 에 속하게 되는 것이고, 마찬가지로 state에 대한 제약 조건의 경우에는 “never explore the edge of the
cliff”와 같은 조건이 부여되었을 때 이 상태에 도달하지 않고 안전한 state에만 머물게끔 강요하는 term이라고 이해하시면 되겠습니다.
정리를 하자면, NWM 자체가 navigaiton을 수행하기 위해서는 action 값을 예측해야하는 것이고 이 올바른 action이란 무엇이냐라고 했을 때 수식4로 정의된 에너지 함수를 수식5와 같이 최소화하는 것이 가장 좋은 action이다 라는 것입니다.
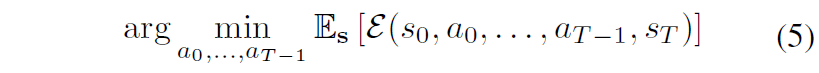
이러한 목적 함수는 Model Predictive Control(MPC) 문제로 다시 재구성할 수 있어서, 저자들은 Cross-Entropy Method를 통해서 이를 최적화했다고 합니다. 근데 Cross-Entropy Method가 무엇인지에 대해서는 main paper에 분량상 이유로 설명이 없어서 혹시나 궁금하신 분들은 따로 찾아서 공부하시면 좋을 듯 합니다. 우선은 NWM 모델 자체로 action을 어떻게 예측하는지에 대한 큰 흐름 및 방향성은 수식4의 에너지 함수 정의와 이를 최적화하는 방향으로 간다고 이해하고 넘어가겠습니다.
Ranking Navigation Trajectories
근데 NWM을 이용해서 action을 예측하는 방법은 위에 방식 말고도 한가지 더 있다고 합니다. 그건 바로 기존의 navigation policy를 바로 활용하는 것인데, 저자들은 NOMAD라고 하는 이전 SOTA visual navigation model을 이용해서 여러가지의 sample 경로들을 예측하고 이 경로들 중에서 수식5번처럼 그 샘플링된 경로들의 에너지를 계산해서 이들을 정렬한 뒤, 가장 작은 에너지 값을 가지는 샘플을 활용했다고 합니다.
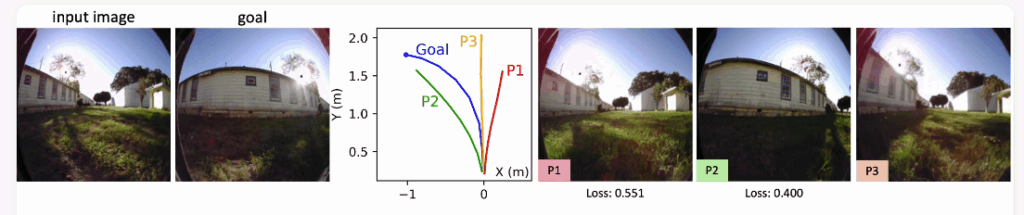
쉽게 얘기해서 input image와 goal image를 주면 NOMAD와 같은 기존 SOTA Visual Navigation 모델을 통해 Goal까지 도달할 수 있는 경로를 여러 가지로 예측할 수 있습니다(아래 그림 속 빨강, 초록, 노랑 line). 그리고 이 action 값과 input image를 토대로 NWM은 실제 future state 영상들을 생성해보는겁니다. 그렇게 생성된 제일 마지막 image가 실제 goal image와 얼만큼 유사한지에 대해서 image 유사도를 측정하는 loss 함수등을 이용해 score를 계산하게 되고, 여기서 score가 가장 큰(또는 loss가 가장 낮은) action 경로를 최종 경로로 판단하고 활용하는 것이 Ranking Navigation Trajectories 방식입니다. 아래 그림에서는 NWM을 통해 P1, P2, P3 모두 시뮬레이션 해보고 그 뒤 P2가 가장 작은 loss값을 가지고 있기 때문에 P2를 최종 경로로 활용하게 되는 것이죠.
Experiments
우선 논문 속 모델 사이즈가 1B 정도로 크기 때문에 방대한 양의 데이터로 학습을 하게 되는데, 학습에 SCAND, Tartan Drive, RECON, HuRoN데이터셋을 사용한 듯 합니다. SCAND는 다양한 환경에서 사회적 규정?을 준수하는 비디오 네비게이션 셋이고, TartanDrive는 오프로드 주행에 중점 데이터셋, RECON은 오픈 월드 내비게이션, HuRoN은 소셜 상호작용을 담고 있는 데이터라고 합니다.
아무튼 이러한 데이터셋들은 서로 다른 환경과 분포, agent들로 구성이 되어 있기 때문에 이 데이터셋들 마다 가지고 있는 물리적 특성들이 다 달라서 하나의 모델에 데이터를 몰아넣고 학습하는 것은 부적합할 수 있습니다. 그래서 우선 저자들은 현재 위치와 비교하여 상대적인 action을 추론하도록 하는데, 이때 agent 별로 서로 다른 step size(아마도 보폭, 한 step마다 움직이는 이동거리?를 의미하는 듯 합니다)를 표준화 해주기 위해, 프레임들 사이마다 agent가 실제 움직인 거리 값에 미터 단위의 평균 step size값으로 나누어주었다고 합니다. 이렇게 함으로써 서로 다른 agent들끼리의 action space가 유사해지도록 만들었다고 하네요.
평가지표로는 네비게이션을 얼만큼 잘했는지를 평가하는 메트릭으로 정확도를 판단하는 Absolute Trajectory Error (ATE)와 포즈의 일관성을 잘 유지하는지를 평가하는 Relative Pose Error (RPE)를 사용했으며, 이 world model이라 함이 결국 view를 생성하는 것이다보니 얼만큼 사실적으로 만들었는지를 평가하기 위해 영상 퀄리티 지표 LPIPS, DreamSim, PSNR을 사용했습니다.
정량, 정성적 비교를 위해 baseline으로 삼은 방법론은 크게 3가지로, DIAMOND, GNM, NoMaD가 있습니다. DIAMOND는 지금 논문과 유사한 diffusion world model인데 굳이 차이점을 꼽자면 현 논문은 conditional transformer라면 DIAMOND는 UNet 구조의 diffusion model이라고 합니다.
그리고 GNM과 NoMaD는 모두 일반적인 goal-based Visula Navigation 방법론들로 딥러닝 네트워크를 통해 target 지점까지 경로를 찾는 방법론들입니다. 다만 NoMaD의 경우 탐사하고 경로를 찾는 과정에서 diffusion policy를 사용한다는 차이가 있습니다 (GNM은 CNN 태우고 fc layer로 예측함).
Ablation study
우선 ablation study 결과부터 살펴보겠습니다. 첫번째 실험은 자신들이 제안하는 CDiT 구조가 기존의 DiT보다 얼만큼 효율적인지에 대한 실험입니다.
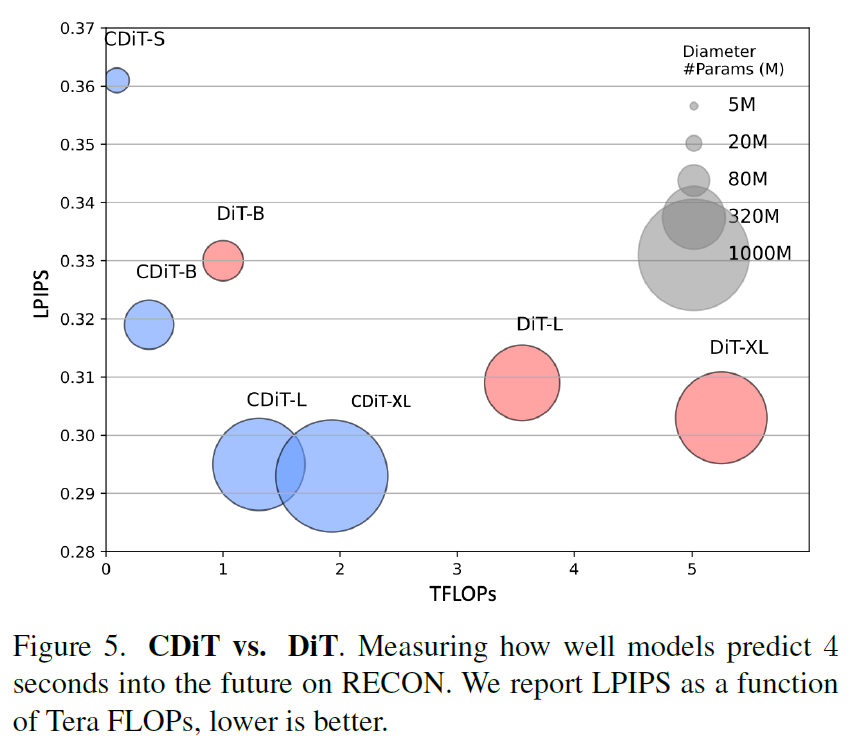
보시다시피 CDiT의 경우 DiT보다 더 좋은 LPIPS 성능(값이 낮을수록 좋음)을 보여주고 있으며, 더 낮은 TFLOps를 가지고 있다는 점입니다. 특히나 DiT-L모델보다 3배나 더 많은 파라미터를 지닌 CDiT-XL모델이 더 좋은 TFLOPs를 가지고 있다는 점인데, target state에 대해서만 token 길이의 제곱배만큼 attention 연산을 하고 m개의 frame에 대한 일련의 context state들에 대해서는 linear한 연산량을 지니다보니 메모리 이점이 크게 나타나는 듯 합니다.
다음은 Goal, Context, action & time과 관련된 ablation study 결과입니다.
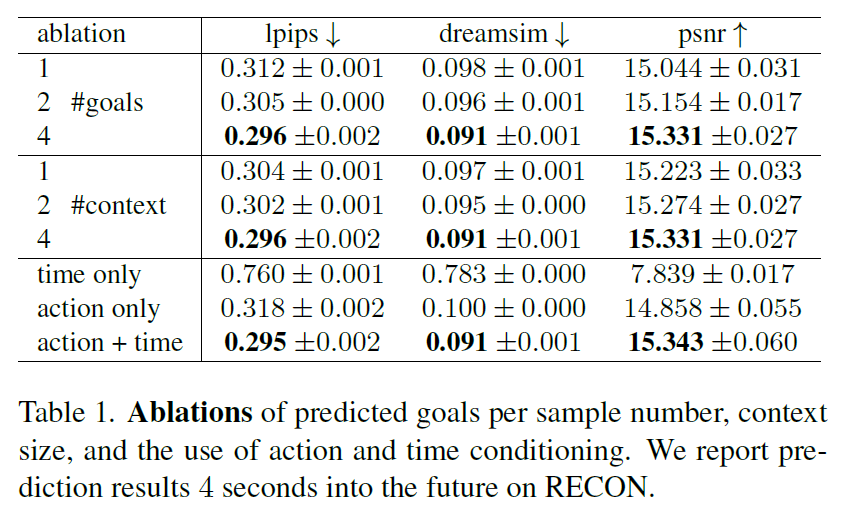
우선 모델을 학습시킬 때 목적함수가 noise가 없는 원본 goal state s_{\mathcal{T}+1} 와 diffusion model을 통해 denoise된 F_{\theta}(s^{(t)}_{\mathcal{T}+1} | s_{\mathcal{T}}, a_{\mathcal{T}}, t) 사이의 오차를 줄이는 방식으로 학습이 된다고 위에서 말씀을 드렸습니다. 여기서 이 goal state에 해당하는 s_{\mathcal{T}+1} 는 timeshift k 값을 통해 현재 state에 해당하는 frame 기준으로 k길이만큼의 앞 또는 뒤 frame을 의미하게 됩니다.
그래서 이 k 값을 어떻게 잡느냐에 따라 현재 state 기준으로 여러개의 goal state를 만들 수 있다는 의미이고, 그렇다면 학습할 때 goal state를 몇개까지 만드는게 성능에 더 좋은가? 에 대한 실험은 한 것이 표 1 제일 위에 #goals 에 대한 실험입니다. 저자들은 1개, 2개 4개에 대한 실험을 진행했고 결과적으로 개수가 가장 많은 4개일 때 더욱 사실적인 영상 생성 결과를 얻을 수 있었다고 하네요.
두번째 실험은 context size에 대한 ablation 입니다. 이 부분은 저희가 condition을 줄 때 연속된 frame에 대한 state를 context 정보를 위해 넣어주게 되는데 이 길이를 얼만큼 가져가는지에 대한 내용입니다. 당연하게도 context 길이가 길면 길수록 모델이 target state에 대한 이해력이 더 높아지기 때문에 context의 길이는 1,2,4 중 4인 경우 가장 좋은 성능을 달성했습니다.
그리고 condition을 줄 때 context 뿐만 아니라 action과 time도 함께 제공하게 되는데, 이 time과 action이 각각 영상 생성에 얼만큼 영향을 주는지에 대한 ablation study도 함께 진행됩니다. 결론만 말씀드리면 time만 넣는 것은 성능에 오히려 안좋은 영향을 보여주었으며, action이 영상 생성 관점에서 매우 중요한 요소라는 점을 확인할 수 있었네요. 물론 action과 time을 다같이 넣어주는 경우 제일 좋은 성능을 달성했다는 점에서 두 정보가 모두 중요하다라는 점은 변함이 없습니다.
Video Prediction and Synthesis
다음은 다른 방법론과의 영상 생성 측면에서 성능 비교를 나타낸 결과입니다.
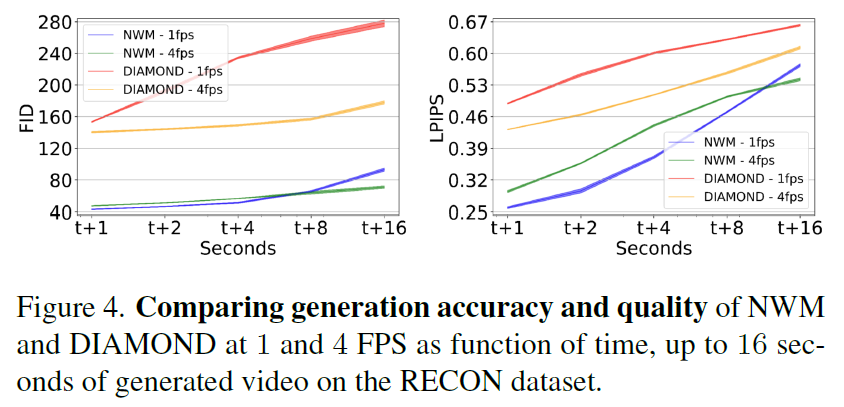
아까 DIAMOND는 Unet 구조의 DIffusion model이라고 말씀드렸습니다. FID도 생성 영상 퀄리티를 평가하는 지표로 값이 낮을수록 좋습니다. 우선은 GT action값과 현재 state에 대한 입력 영상을 제공해주면, 모델은 그 현재 frame 기준 +1, +2, +4, +8, +16초 이후의 state(image)를 예측하게 됩니다. 그렇게 예측한 state를 decoder를 통해 image로 변환한 뒤 실제 +1, …, +16초 이후의 GT 이미지와 얼만큼 유사한지를 영상 품질 측정 메트릭으로 평가하게 됩니다.
우선 +1에 가까울수록 input state와 인접한 frame일테니 생성된 퀄리티도 더 좋을 것이고 반대로 +16의 경우 16초 뒤의 상황을 생성하는 것이므로 실제 16초 뒤에 GT 이미지랑 차이가 많이 생길 수 있겠죠. 그래서 t+16으로 갈수록 영상 품질 성능이 떨어진다는 것이 두 모델의 공통적 특징입니다.
그럼에도 불구하고 저자들이 제안하는 NWM이 DIAMOND와 비교해서 항상 좋은 성능을 보여주고 있다는 점 특히 FID 기준으로는 매우 큰 성능 차이가 난다는 점에서 transformer와 UNet의 구조적 차이, 그리고 conditioning의 중요성등이 나타나는 것 같습니다.
생성된 결과에 대한 정성적 비교는 저자들이 홈페이지에 동영상을 올려놨기 때문에 해당 링크 타고 확인하시면 좋을 듯 합니다.
Planning Using a Navigation World Model
그러면 이제 NWM을 이용한 navigation 성능도 살펴보겠습니다.
우선 다른 visual navigation model을 사용해서 NWM으로 최적의 action을 평가하는 방식과, NWM 모델 자체만으로도 네비게이션을 수행하는 방식 총 2가지가 있다고 위에서 설명드렸었죠. 저자들은 NWM 단독으로 action을 예측할 때는 Cross-Entropy Method 방식을 통해 에너지 함수를 최소화하는 action 값을 예측하였다고 했는데, 여기서 goal image와 모델이 제일 마지막으로 예측한 image 사이의 LPIPS를 최소화하는 방향으로의 action 값을 계산하였다고 합니다.
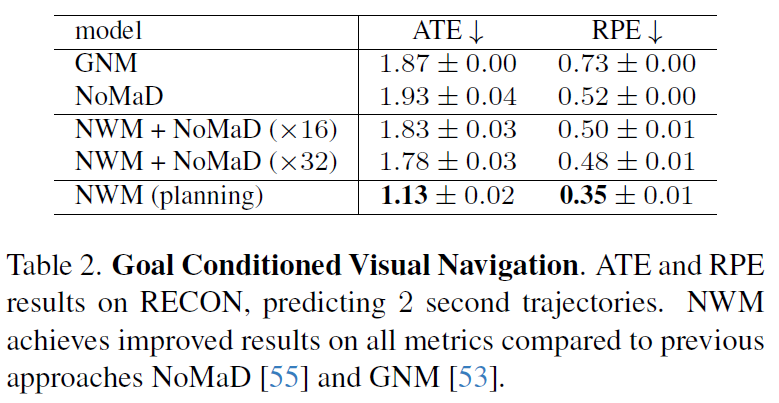
위에 표 살펴보시면 NWM + NoMaD 방식이 NoMaD의 경로 후보군들을 NWM으로 다 평가해서 최적의 action을 선정하는 방식이고, 제일 하단에 NWM이 Cross-Entropy Method로 action 값을 예측했을 때의 성능입니다. 결론부터 말씀드리면 NWM 단독으로 action을 추론할 때 가장 좋은 성능을 달성하였다고 합니다.
그리고 재밌는 점은 NoMaD 단독 성능보다 NWM을 통해 NoMaD의 예상 경로를 test해보고 ranking을 계산해서 가장 점수가 높은 경로를 선택하는 NWM + NoMaD 방식이 더 좋았다는 것이죠.
Generalization to Unknown Environments
다음은 일반화 성능에 대한 결과입니다. 지금까지는 모델이 알고 있는 환경에서 action과 현재 state에 따른 view를 생성했다면 지금 실험은 한번도 보지 못한 환경에서 action값과 현재 input이 주어졌을 때 얼만큼 사실적인 view를 생성하는지를 평가한 것으로 이해하시면 되겠습니다.

저자들은 기존의 in-domain data로 학습한 것 외에도 Ego4D dataset을 추가로 학습시켰을 때 generalization 성능이 얼만큼 개선되는지를 비교 평가하였습니다. 이 Ego4D dataset은 이미지와 time-shift에 대한 정보만을 가지고 있기 때문에 translation과 rotation등과 같은 action 값이 없어서 모델 학습 시킬 때 해당 값들을 사용할 수 없었으며 따라서 저자들은 unlabeled set이라고 명칭합니다.
아무튼 이렇게 unlabeled set을 추가로 학습할 경우 NWM이 unknown 환경에서 주어진 action에 따라 영상을 생성할 때 조금 더 좋은 퀄리티의 영상을 생성할 수 있었다 합니다. 다만 unlabeled set으로 학습할 경우 known environment에 대해서는 성능이 크게 감소하는 점이 아쉽게 느껴지네요.
Limitation
저자들은 자신들의 모델의 한계점들을 차근차근 밝혀줍니다. 우선 첫째로 Out of Distribution data에 대하여 모델이 추론할 때 time step이 점차 지나가면서 생성되는 영상의 모습이 학습 때 보았던 데이터와 유사한 느낌으로 생성한다는 문제점이 발생한다고 합니다. 예를들어서 아래 그림에서 input은 그냥 image인데 time step이 점점 커질수록 생성된 영상에서는 좌우 상단에 검정색 조리개 같은게 보이기 시작합니다. 이게 학습 때 보았던 데이터가 제일 하단과 같이 렌즈 커버들이 보이는 영상들이 섞여있어서 모델이 자연스럽게 학습 때 봤던 형태의 렌즈 방식으로 영상을 생성하였다고 합니다.


두번째로는 모델이 보행자의 움직임과 같은 시간적 역학을 시뮬레이션하는 데 어려움을 겪습니다. 아래 사진과 같이 바다를 향하는 action을 주고 경로에 대한 이미지를 생성하라고 해보면 모델은 그냥 저기서도 사람이 걸을 수 있는 줄 알고 마치 바다를 바닥?같이 생각하고 움직였을 때의 view를 생성한다고 합니다.

아무튼 이러한 문제점들은 더 긴 context와 더 많은 학습 데이터를 통해 모델을 학습시키면 해결될 수 있을 것이라고 저자들은 믿고 있네요.