오늘부터는 CVPR 2025의 Oral 및 Highlight 논문들을 중심으로 다양한 연구를 리뷰해보려 합니다.
이번에 살펴볼 논문은 박성준 연구원의 CVPR 참관기 세미나에서 소개되었던 페이퍼로, 제가 집중하지 않는 다른 분야에서는 어떻게 모달리티별 이해를 확장하고 있는지를 보여주고 있다는 생각이 들어 리뷰하게되었습니다.

- Conference: CVPR 2025
- Authors: Kaiwen Zha, Lijun Yu, Alireza Fathi, David A. Ross, Cordelia Schmid, Dina Katabi, Xiuye Gu
- Affiliation: Google DeepMind, MIT CSAIL
- Title: Language-Guided Image Tokenization for Generation
1. Introduction
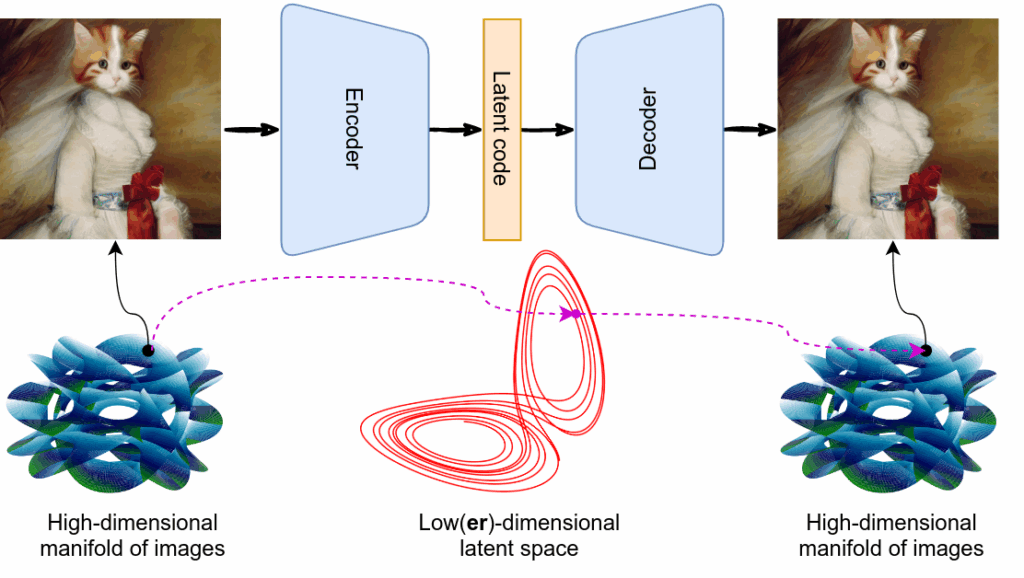
이미지 생성 연구는 이제 다양한 응용 분야에서 고품질 이미지까지 합성할 수 있을 정도로 발전했습니다. 이러한 발전의 핵심에는 Image Tokenization이 있다고 합니다. 이는 고차원 픽셀 데이터를 압축된 latent space로 변환하여, 생성 모델이 더 효율적이고 정밀하게 작동할 수 있도록 도와주었기 때문이죠. Diffusion 모델이나 Auto-Regressive 모델들은 이 과정을 통해 원본 이미지 대신 토큰 공간에서 학습 및 생성을 수행하며, 계산 효율성과 품질 모두를 높일 수 있었다고 합니다.
하지만 기존의 Image Tokenization 방식에는 한계가 있는데, 바로 생성 영상의 품질과 압축률 사이의 Trade-off 문제 입니다. 특히 고해상도 이미지에서는 이 문제가 더욱 심각하게 작용된다고 합니다. 압축률을 높이면 계산 비용은 줄어들지만 그만큼 세부 묘사가 손상되고, 품질을 유지하려고 하면 토큰 수가 많아져 계산량이 증가합니다.
이러한 문제를 해결하기 위해, 저자들은 Image Tokenization 과정에 언어 정보, 즉 텍스트 캡션을 활용하는 방식인 TexTok을 제안하였습니다. 아이디어는 “언어로부터 이미지 의미를 추출한다”는 관점에서 착안했다고 하는데요. 인간이 이미지를 설명할 때 먼저 전체적인 의미를 말한 후 세부사항으로 들어가듯, Image Tokenization도 텍스트 조건을 통해 이와 유사한 방식을 따르게 한 것입니다.
여기서 재밌는 점은 텍스트 캡션이 별도의 라벨링 없이도 웹에서 쉽게 수집 가능하거나, VLM을 통해 자동 생성 가능하다는 점입니다. 따라서 TexTok은 별도의 주석 비용 없이 실제 데이터에 쉽게 적용할 수 있는 장점이 있다고 합니다. 본격적인 리뷰 시작하겠습니다.
2. Method
2.1 Preliminary
원래는 쉽게 뛰어넘는 섹션인데, 제가 자주 리뷰하던 분야가 아닌만큼 해당 챕터에서부터 차근차근 Image Tokenization 태스크에 대해 알아보겠습니다.
이미지 생성 모델에서 Image Tokenization은 필수적인 전처리 과정이라고 합니다. 입력 이미지를 고정된 크기의 latent space로 압축해 생성 모델이 더 간단하고 효율적으로 학습할 수 있게 도와주죠. 이 과정은 크게 두 가지 방식으로 나뉩니다.

Vector-Quantized (VQ) Tokenizer (Discrete Latent Tokenizer) :
- 대표적으로 VQ-VAE, VQGAN 같은 모델들이 있습니다
- 이미지를 일정한 격자 형태로 나눈 뒤, 각 영역을 정해진 상단 이미지처럼 코드북의 이산 토큰으로 표현합니다.
- 이미지의 표현력을 코드북의 품질에 의존하게 되며, 표현의 유연성은 떨어지는 편이라고 합니다.
Continuous Latent Tokenizer:
- VAE 기반 모델들이 여기에 속하며, 이미지의 각 패치를 연속적인 벡터로 인코딩합니다.
- 저자가 제안하는 TexTok은 이 continuous 방식에 기반하고 있으며, 1D 구조를 채택하고 있습니다. 1D 구조가 무엇인지는 아래 수식과 함께 설명하겠습니다.
제가 예전에 작성한 VQ-VAE 리뷰 [NIPS 2017] Neural Discrete Representation Learning Background에, 이 두 가지 Image Tokenization 차이를 그림과 함께 작성해두었으니 함께 읽어보면 도움이 될 것 같습니다.
<Notation>
- I: 입력 이미지
- \hat{I} = D(Z): 복원된 이미지, 여기서 Z = E(I)는 이미지에서 추출한 latent token
- E: 토크나이저 역할을 하는 인코더
- D: 디토크나이저 역할을 하는 디코더
이제 수식을 통해 일반적인 Image Tokenizer 과정을 살펴보겠습니다.
(1) 입력 이미지 압축
입력 이미지 \mathbb{R}^{H \times W \times 3}가 주어졌을 때, 토크나이저 역할을 하는 인코더 E는 이를 latent 공간으로 압축합니다. 보통 2D latent map Z = E(I) \in \mathbb{R}^{h \times w \times d}로 표현되고, 여기서 h = \frac{H}{f}, w = \frac{W}{f}으로, f는 다운샘플링 비율입니다. 각 위치의 latent vector z \in \mathbb{R}^d는 하나의 continuous token 역할을 하며, 총 h \times w 개의 토큰으로 이미지가 표현되는 셈이죠
(2) 이미지 복원
이 latent token들을 디코더 D에 다시 넣으면, 복원된 이미지 \hat{I} = D(Z)를 얻을 수 있습니다. 이때, 원본 이미지 I와 복원 이미지 \hat{I} 사이의 차이를 최소화하는 방향으로 토크나이저가 학습됩니다.
그러나, 최근에는 이러한 2D 구조에서 더 나아가 1D 토크나이저가 제안되었다고 합니다. 그럼 2D 구조와 1D 구조의 차이는 뭘까요?
2D Tokenizer
- 이미지 전체를 h \times w 형태의 격자로 나눈 후, 각 위치마다 하나의 latent vector z \in \mathbb{R}^d를 생성합니다.
- 예를 들어, 256×256 이미지를 16×16 패치로 나누면 16×16 = 256개의 토큰이 나오게 되죠
- 여기서 토큰 수는 항상 이미지 해상도와 패치 크기에 의해 고정됩니다.
→ 그래서 “토큰 수를 자유롭게 조정”하는 것이 어려운거죠
1D Tokenizer
- 반면, 1D 구조에서는 이미지를 격자로 나누지 않고, 바로 N개의 연속 토큰으로 압축한다고 합니다.
- 예를 들어, 원래 256개의 토큰이 필요했던 이미지를 64개의 토큰만 사용해서도 표현할 수 있게 되는 구조입니다.
- 이 방식은 토큰 수를 자유롭게 설정할 수 있어서, 압축률을 유연하게 조정할 수 있다는 장점이 있습니다.
TexTok은 바로 이 1D 구조를 기반으로 하여, 다양한 token budget 설정에서도 효율성과 품질을 모두 확보할 수 있다고 합니다. 이 구조 위에서 텍스트를 어떻게 활용하는지는 다음 섹션에서 본격적으로 설명됩니다.
2.2 TexTok: Text-Conditioned Image Tokenization
TexTok은 토크나이즈할 때, 이미지에 대한 캡션(설명)을 활용합니다. 예를 들어 “초록 들판 위를 달리는 갈색 말”이라는 문장이 있다면, 모델은 이 문장을 통해 이미지가 어떤 내용인지 미리 파악할 수 있게 됩니다. 그러면 이미지 토크나이저는 굳이 ‘말이 달린다’, ‘초록 들판이다’ 같은 큰 의미까지 다 알아내려 애쓰지 않고, ‘갈기의 질감’, ‘다리의 그림자’처럼 더 세밀한 시각적 특징에 집중할 수 있게 되는거죠!
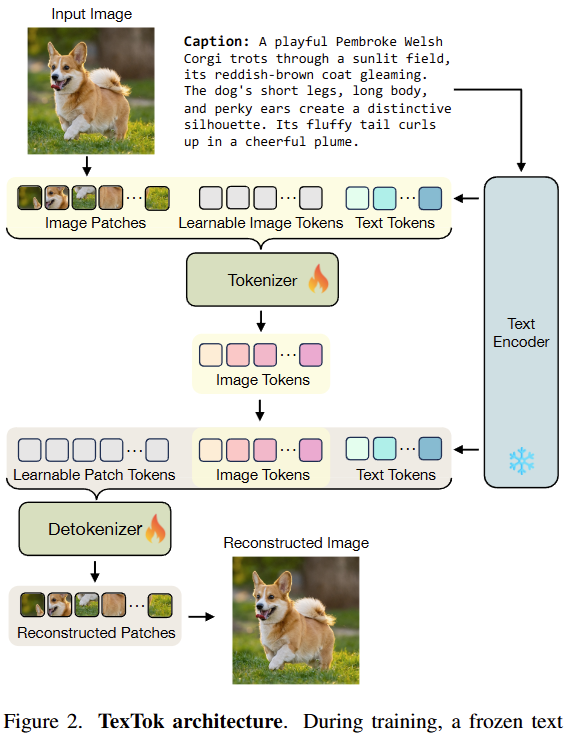
TexTok의 전체 구조는 크게 두 단계로 나뉘는데, 먼저 첫 번째 단계인 Tokenization Stage에서 어떤 식으로 토큰을 생성하는 지를 살펴보겠습니다.
2.2.1 Tokenization Stage

먼저 상단 이미지처럼 입력 이미지와 캡션이 페어로 모델에게 주어집니다.
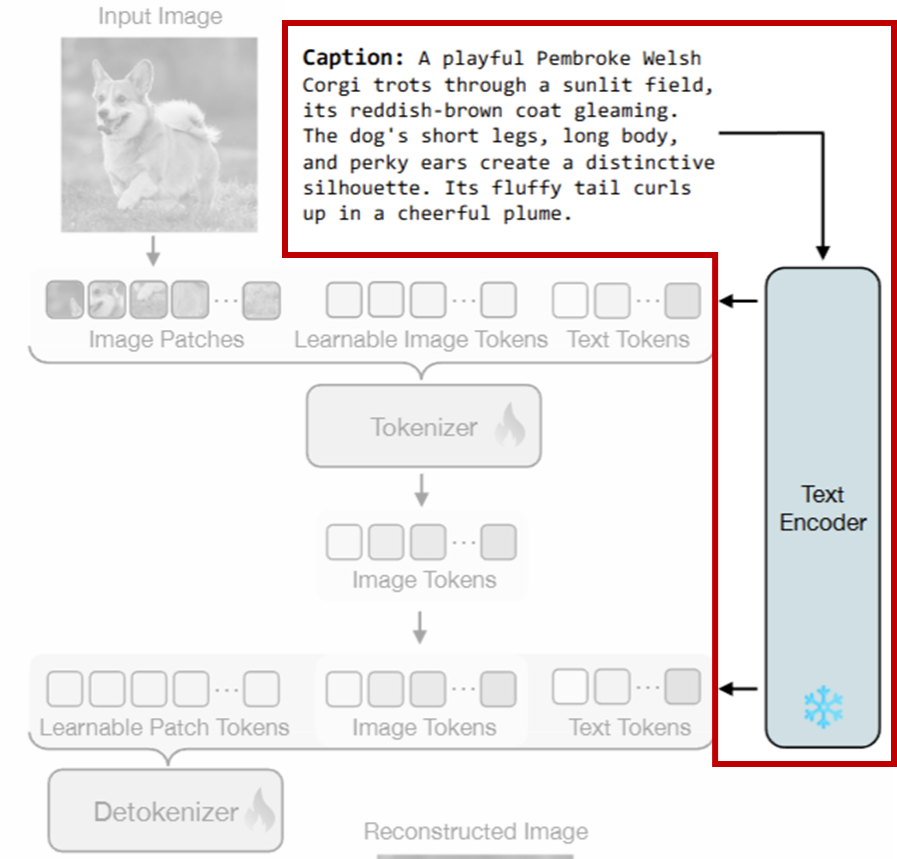
이 텍스트는 *T5 모델을 통해 텍스트 임베딩으로 변환되며, 이 임베딩은 Tokenizier 뿐만 아니라 이후 De-Tokenizier 에도 함께 전달됩니다. 즉, 텍스트는 토큰 압축과 다시 복구하는 전 과정에서 일관된 의미 정보를 제공하는 역할을 하죠.
*T5 model은 google의 Text-to-Text Transfer Transformer 모델 입니다. 텍스트 인코더겠죠?
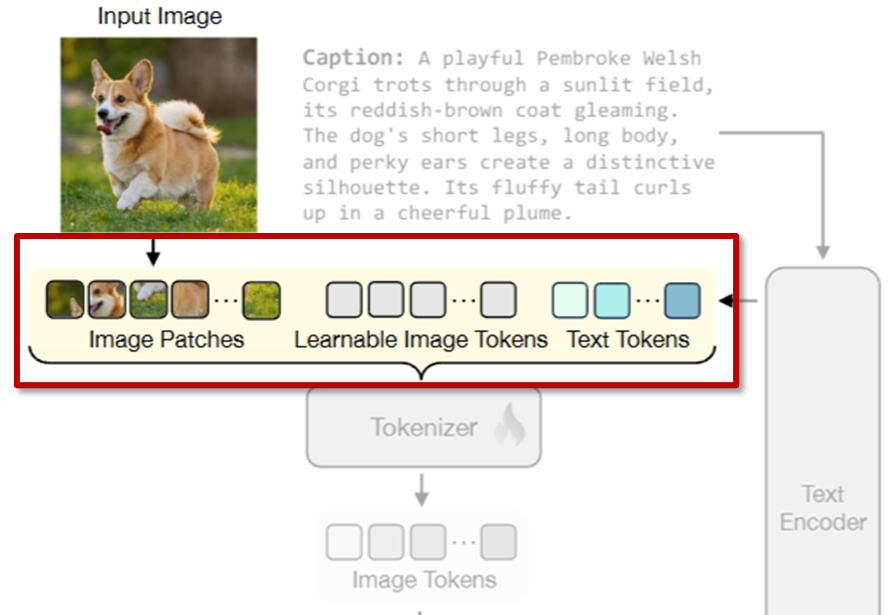
TexTok의 토크나이저는 ViT 기반 모델로, 상단 이미지처럼 입력으로 총 세 가지 종류의 토큰을 입력받습니다:
(1) 이미지 패치 토큰
이미지 I를 일정한 패치 크기 s로 나눈 뒤, 각 패치를 flatten하고 projection layer를 거친 토큰 P \in \mathbb{R}^{hw \times D}입니다.
h, w: 패치 개수
(2) 학습 가능한 이미지 토큰
실제로 모델이 학습을 통해 만들어내는 출력 토큰입니다. 총 N개의 토큰이 있으며, L \in \mathbb{R}^{N \times D}로 표현됩니다.
N: 직접 설정할 수 있는 토큰 수
(3) 텍스트 임베딩 토큰
앞서 T5 인코더를 통해 얻은 텍스트 임베딩을 선형 변환하여 T \in \mathbb{R}^{N_t \times D} 형태로 삽입합니다.
N_t: 텍스트 토큰의 개수
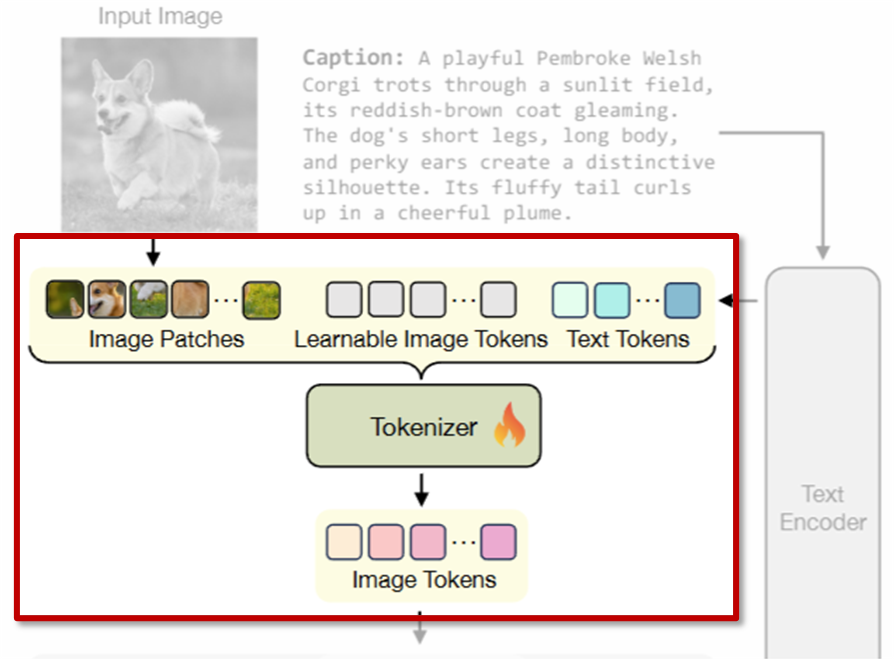
이 세 종류의 토큰은 하나로 concat해서 ViT Tokenizaer에 입력되고, 출력에서는 학습된 이미지 토큰 L만 남게됩니다. 이 토큰들이 최종적으로 이미지의 latent 표현이 되며, 이후 디코더에서는 다시 텍스트 토큰과 함께 사용되어 이미지를 복원하게 됩니다.
다시 말해 핵심은, 이미지의 의미 구조를 텍스트가 먼저 설명해주기 때문에, 이미지 토큰은 그만큼 더 디테일한 묘사에 집중할 수 있다는 점이라고 합니다. 저자가 말하길… 정보의 역할을 분리하고 효율적으로 할당함으로써 더 적은 수의 토큰으로도 정교한 표현이 가능해졌다고 하네요. (사실 저는 여기서 저자의 포장 실력에 감탄했는데요… 사실 텍스트를 함께 넣은게 전부고 토큰 압축하는건 Transformer한테 맡긴 걸 이렇게 그럴싸하게 표현한거 아닌가? 라는 생각이 드는 부분인 것 같습니다..)
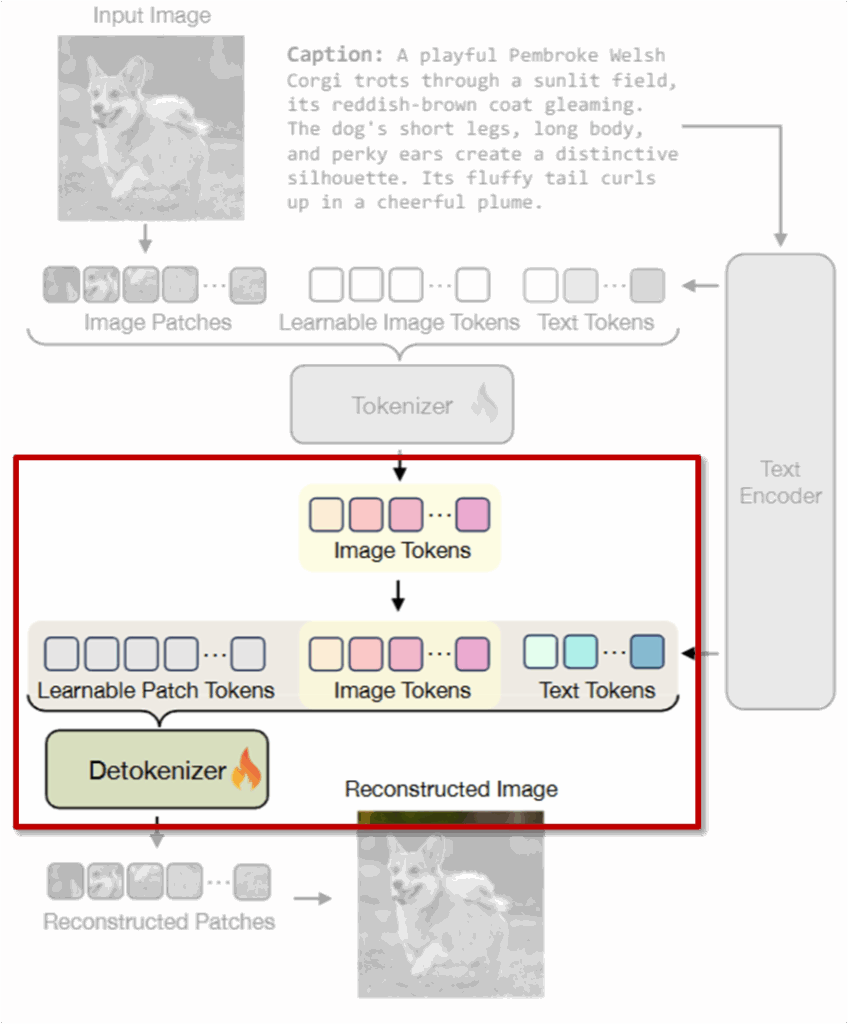
이제 Detokenization 단계는 앞서 생성된 이미지 토큰을 다시 원래 이미지 형태로 복원하는 과정입니다. 이때도 Tokenization과 마찬가지로 텍스트 정보가 함께 활용된다는 점이 핵심입니다. Detokenizer도 마찬가지로 ViT 구조를 따르며, 세 가지 종류의 입력을 받습니다:
(1) 학습 가능한 패치 토큰
이미지를 복원할 때 사용되는 토큰입니다. 이미지의 해상도에 맞춰 h \times w 개의 learnable tokens를 사용합니다.
(2) 이미지 토큰
앞서 Tokenization 단계에서 만들어졌던 N개의 이미지 토큰입니다. 이 토큰은 원래 이미지의 시각적 세부 정보를 압축해 담고 있는 상태라고 합니다.
(3) 텍스트 토큰
Tokenization 단계에서 사용했던 동일한 텍스트 임베딩이 다시 들어갑니다. 이렇게 함으로써, 이미지 복원 시에도 전체적인 의미 정보가 함께 고려됩니다.
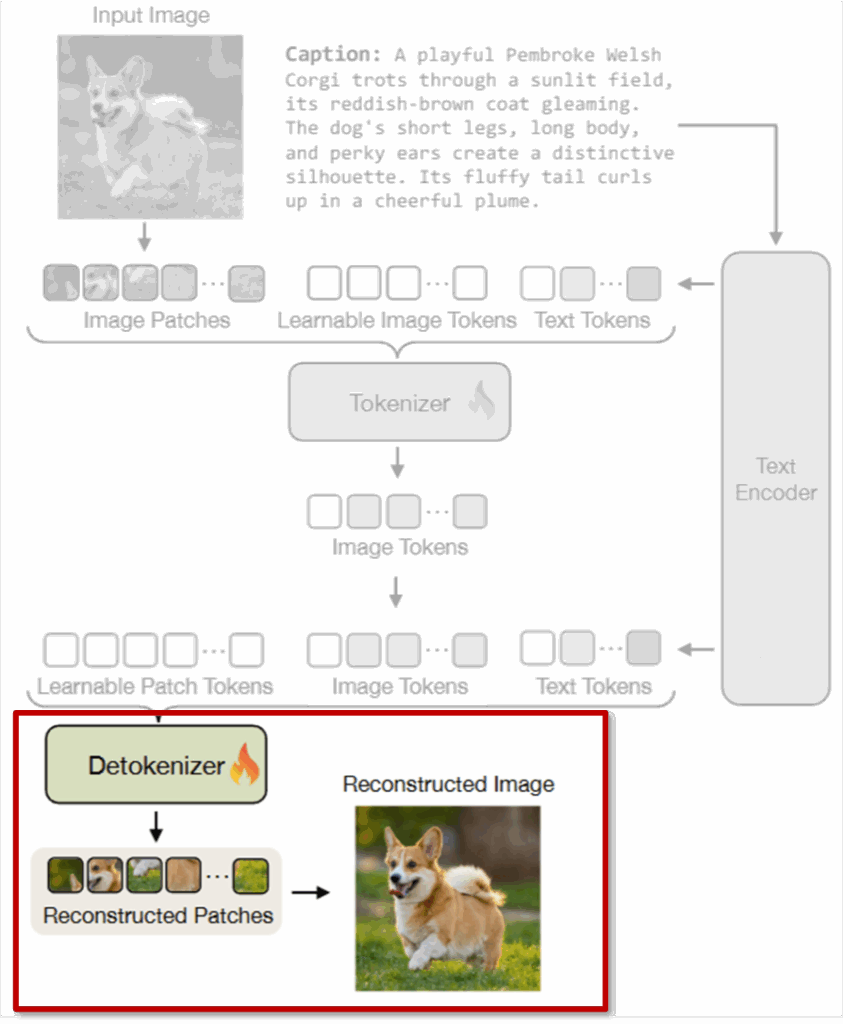
이 세 토큰들을 다시 합쳐서 ViT 구조인 Detokenizer에 넣으면, 최종적으로 이미지 패치를 재구성할 수 있게 됩니다.
이제 학습 방식도 간단히 정리해보면 다음과 같습니다. TexTok은 여러 가지 손실 함수를 함께 사용해 학습되는데, 각 손실은 복원 품질을 높이기 위해 조금씩 다른 역할을 한다고 합니다.
(1) ℓ2 Reconstruction Loss: \mathcal{L}_{\text{rec}} = \| \hat{I} - I \|_2^2
복원된 이미지와 원본 이미지 간의 픽셀 단위 차이를 최소화하는 Loss.
(2) Perceptual Loss: \mathcal{L}_{\text{perc}} = \sum_{l} \| \phi_l(\hat{I}) - \phi_l(I) \|_2^2
\phi_l은 l번째 layer에서 추출한 feature입니다. 중간 피처맵 사이의 차이를 줄이는 Loss로, 주로 이미지의 구조나 질감 같은 부분을 잘 복원하도록 도와준다고 합니다.
(3) GAN Loss
TexTok에서는 StyleGAN Discriminator를사용하며, Generator와 Discriminator는 각각 다음과 같은 Loss를 사용합니다. Generator는 진짜처럼 보이게 하고, Discriminator는 진짜인지 가짜인지 구분하는 Loss 인거 아시죠?
- Discriminator Loss: \mathcal{L}_{\text{D}} = \mathbb{E}_{I}[(D(I) - 1)^2] + \mathbb{E}_{\hat{I}}[D(\hat{I})^2]
- Generator Loss: \mathcal{L}_{\text{GAN}} = \mathbb{E}_{\hat{I}}[(D(\hat{I}) - 1)^2]
(4) LeCAM Regularization: \mathcal{L}_{\text{LeCAM}} = \lambda \cdot \text{KL}(D(I) \| D(\hat{I}))
GAN 학습을 안정화하기 위해 쓰인 정규화 함수라고 합니다. 논문에서는 이 수식이 명시적으로 쓰이지는 않았지만, LeCAM은 Generator와 Discriminator의 출력을 KL divergence 등의 방식으로 정규화하는 목적으로 사용한 것 같습니다. (논문에서는 LeCAM을 StyleGAN 기반 GAN 학습에 결합하여 더 안정적인 학습이 가능하도록 하네요)
이러한 Loss를 모두 함께 사용하는 방식 덕분에, TexTok은 이미지의 구조, 세부 질감, 전체 분위기까지 균형 있게 복원할 수 있었다고 합니다.
2.2.2 Generation Stage
TexTok 구조의 마지막 단계는 바로 이미지 생성(Generation)입니다. 이 논문에서는 Generator로 Diffusion Transformer (DiT)를 사용하였고, TexTok에서 학습된 latent image token 위에 이 DiT를 학습시켰다고 합니다.
여기서 중요한 포인트는, Generator는 이미지 latent token만 생성하면 되고, 텍스트 임베딩은 detokenizer에서 직접 받는다고 합니다. 다시 말해, Generator 입장에서는 의미 정보는 이미 텍스트로 주어졌기 때문에 이미지의 시각적 디테일만 생성하면 되는 구조이죠.
DiT는 두 가지 조건 조건 하에서 이미지 latent token의 분포를 학습하고, 각 조건에 따라 inference에서의 처리 방식이 달라진다고 합니다.
Text-to-Image Generation
- 사용자가 입력한 캡션을 기반으로 DiT는 이미지 latent token을 생성
- 텍스트 임베딩은 tokenizer 뿐만 아니라 detokenizer에도 함께 전달
- 최종적으로는 생성된 latent image token + 텍스트 임베딩을 함께 detokenizer에 넣어 이미지를 복원
즉, 텍스트 하나만 입력하면 그에 알맞은 이미지를 생성할 수 있는 것이죠
Class-Conditional Generation
- 텍스트 대신 클래스 정보(예: ‘강아지’, ‘자동차’)만 조건으로 사용
- DiT는 해당 클래스에 맞는 latent image token을 생성하고,
- 사전 정의된 캡션 목록 중 해당 클래스에 맞는 문장 하나를 샘플링하여 detokenizer에 함께 입력
- 이 방식은 기존 class-conditional generation과 호환되는 구조라고 하네요
2.3 TexTok 흐름
Train Stage
이미지 I → Tokenizer E→ latent image token Z 생성. Z와 텍스트 임베딩을 같이 사용하여 Detokenizer D가 이미지 복원 \hat{I}. 이 과정을 바탕으로 DiT는 latent token Z의 분포를 학습.
Generation Stage
텍스트 or 클래스 조건에 따라 Generator인 DiT가 latent image token \hat{Z}를 생성. 이미 준비된 텍스트 임베딩과 함께 \hat{Z}를 Detokenizer D에 넣어 이미지 \hat{I} 생성.
3. Experiments
3.1 Implementation Details
Text Caption Acquisition
텍스트-이미지 생성(Task)에서는 캡션이 이미 존재하므로 바로 토크나이징에 사용되었고, 캡션이 없는 경우 (ex. ImageNet) VLM인 Gemini v1.5 Flash를 사용해 오프라인에서 이미지 캡션 생성하여 학습에 사용ㅎ였다고 합니다.
3.2 Evaluation Protocol
Reconstruction 성능 (tokenizer 기준)
토크나이저가 이미지 정보를 얼마나 잘 보존하고 있는지
- rFID: 복원된 이미지 분포가 실제 이미지 분포와 얼마나 가까운지 (낮을수록 좋음)
- rIS: 복원된 이미지가 명확하게 인식될 수 있는지 (높을수록 좋음)
- PSNR: 원본대비 복원 이미지 noise 비율 (높을수록 좋음)
- SSIM: 원본-복원이미지 얼마나 유사한지 (높을수록 좋음)
- LPIPS: 인간의 인지와 유사한 perceptual 유사도 (낮을수록 좋음)
Class-Conditional Generation 성능
주어진 클래스 조건을 보고 얼마나 정확한 이미지를 생성했는지
- gFID: 생성 이미지가 해당 클래스 분포에 얼마나 가까운지 (낮을수록 좋음)
- gIS: 생성 이미지가 명확하고 다양하게 생성되었는지 (높을수록 좋음)
- precision
- recall
Text-to-Image Generation 성능
텍스트 설명을 바탕으로 이미지가 얼마나 잘 생성되었는지
- FID: 텍스트와 관련된 이미지 품질 (낮을수록 좋음)
- CLIP score: 이미지-텍스트 사이의 유사도 (높을수록 좋음)
3.3 Effectiveness of Text Conditioning
Table 1(a): ImageNet에서의 성능
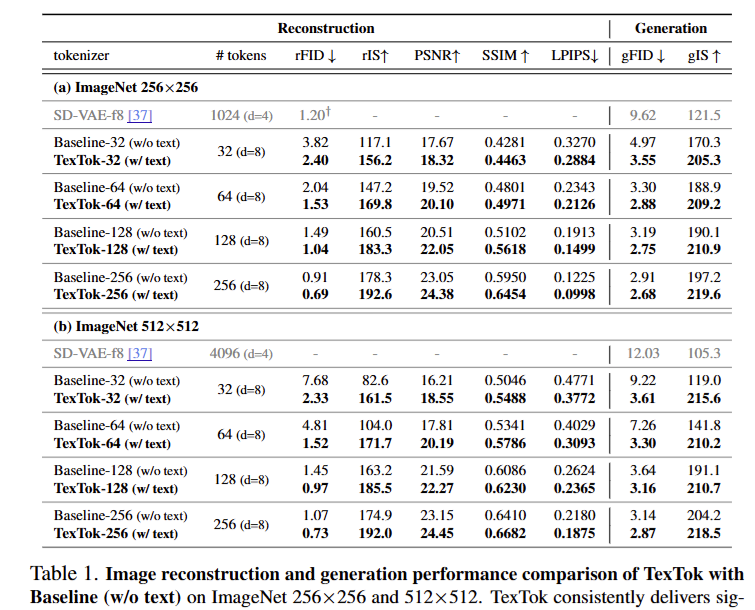
256×256 (Table 1(a))
TexTok은 기존 방식(Baseline w/o text)보다 rFID와 gFID에서 모두 우수한 성능을 보였습니다. 특히 토큰 수가 적을수록 텍스트 조건의 효과가 더 크게 나타났다고 합니다. 예를 들어, 32개의 토큰만 사용할 경우 rFID는 37.2% 향상되었고, gFID는 28.6% 개선되었습니다. 또, TexTok은 같은 rFID를 달성하면서도 Baseline의 절반 토큰만 사용하는 2× 압축률을 보여줬습니다.
512×512 (Table 1(b))
고해상도에서 텍스트 조건의 효과가 더 크게 나타났다고 합니다. 특히 rFID에서 최대 69.7%까지 향상시켰고, gFID도 최대 60.8% 개선되는 등 압도적인 성능 향상을 보였습니다. 게다가 Baseline 대비 rFID를 비슷하게 유지하면서도 1/4 토큰 수만으로 달성한 것도 의미있었다고 합니다.

Figure 1에서는 다양한 토큰 수 설정 하에서 TexTok이 생성한 이미지들을 시각적으로 비교한 것인데요. 이를 통해 텍스트 조건 입력이 실제 이미지 생성 결과에 어떤 영향을 주는지 확인할 수 있었다고 합니다.
동일한 토큰 수를 사용할 경우 TexTok은 더 선명하고 세부 묘사가 잘 살아있는 이미지를 생성하는 반면, Baseline(w/o text)은 상대적으로 흐릿하고 구조가 무너진 결과를 보여주었습니다. 특히 토큰 수가 적을수록 이 차이는 더욱 도드라졌다고 하네요.
3.4 System-level Image Generation Comparison
TexTok은 단순한 토크나이저 대체를 넘어서, 기존 이미지 생성 시스템 대비 뛰어난 성능과 연산 효율성을 보여주었다고 하며 이를 증명하기 위한 실험도 수행하였습니다. 이를 위해, vanilla DiT를 generator로 고정하고, 토크나이저만 TexTok으로 바꿔 다양한 이미지 생성 실험을 수행하였습니다.
Table 2. 이미지 생성 결과
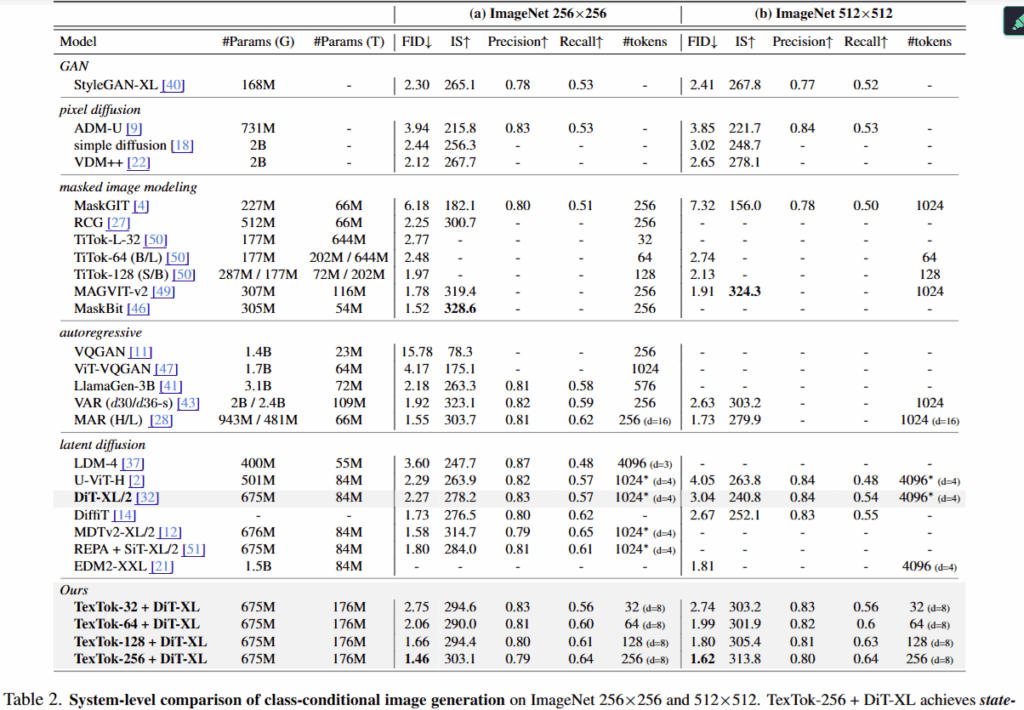
256×256 (Table 2(a))
TexTok-256 + DiT-XL은 FID 1.46이라는 기존 SoTA을 뛰어넘는 결과를 보였습니다. 토큰 수를 줄이면서도 TexTok은 성능을 유지했고, TexTok-64나 TexTok-32와 같은 압축 버전도 DiT-XL/2 대비 높은 성능을 보였다고 합니다.
참고로 256, 64, 32는 생성에 사용된 이미지 토큰 수를 의미합니다. TexTok-32는 이미지를 32개의 연속적인 토큰으로 압축한 뒤 생성에 사용하는 버전이죠. TexTok은 텍스트 임베딩을 통해 작은 토큰 수로도 고품질의 이미지를 생성할 수 있었다고 합니다.
512×512 (Table 2(b)):
고해상도에서도 TexTok의 장점이 뚜렷하게 나타납니다. 256개의 토큰만으로도 SoTA보다 우수한 FID를 달성하며, 32개의 토큰만 사용하는 경우에도 기존 DiT (1024개 토큰)보다 더 나은 성능을 보입니다.
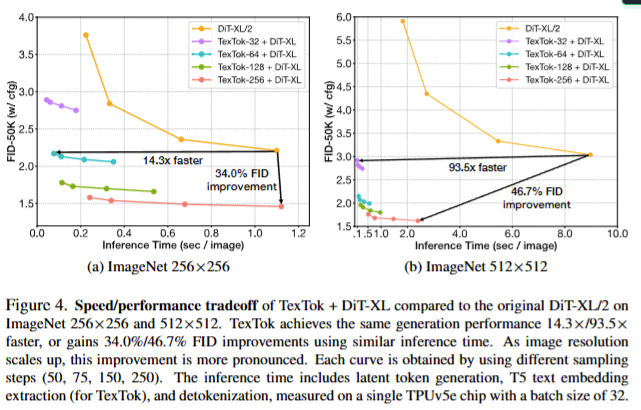
속도-성능 트레이드오프 (Figure 4a, 4b):
뿐만아니라, 단순히 토크나이저만 TexTok으로 바꾸는 것으로도 256×256에서 14.3배의 속도 향상, 또는 동일 속도 기준 34.3% FID 향상을 달성하였다고 합니다. 512×512에서는 93.5 배의 속도 향상 혹은 46.7% FID 향상 + 3.7배 더 빠른 inference 타임을 보였습니다. 다시 말해, 해상도가 커질수록 TexTok의 효과는 더욱 극대화되며 토크나이저의 효과를 볼 수 있었죠

정성적 결과 (Figure 6):
위의 이미지는 TexTok 기반으로 class-conditional 하게 생성된 것입니다. 생성 이미지는 텍스트의 클래스 조건에 맞춘 정교한 구조와 의미 표현이 잘 반영되어 있으며, 세부 디테일 또한 뛰어났다고 그림과 함께 보여주었습니다.
3.5 Text-to-Image Generation
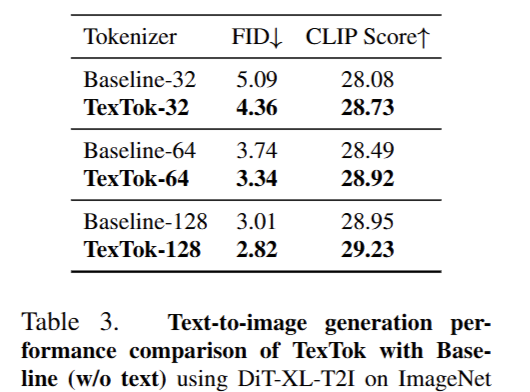
Text-to-image generation 성능 (Table 3):
ImageNet 256×256 에서, TexTok은 Baseline(w/o text) 대비 모든 토큰 수 설정에서 FID 성능을 꾸준히 향상시킬 수 있었습니다. 특히 텍스트를 사용했을 뿐인데도, TexTok은 별도의 비용 없이도 성능을 높였고, 다양한 토큰 수(예: 32, 64, 128)에서도 일관되게 높은 성능을 보ㅕㅆ죠
뿐만아니라 TexTok은 Generator에 이미 사용된 텍스트 임베딩을 그대로 tokenizer에서도 사용하므로, 텍스트 추출이나 캡션 생성에 추가 비용 없이 성능 향상을 달성할 수 있다는 장점이 있었습니다.
다시 말해, 추가 학습이나 비용 없이도 성능 향상이 그냥 따라온다는 점이 저자가 주장하는 핵심이죠
3.6 Tokenization/Generation Inference Efficiency
마지막으로 인퍼런스 타임까지 비교한 결과입니다.
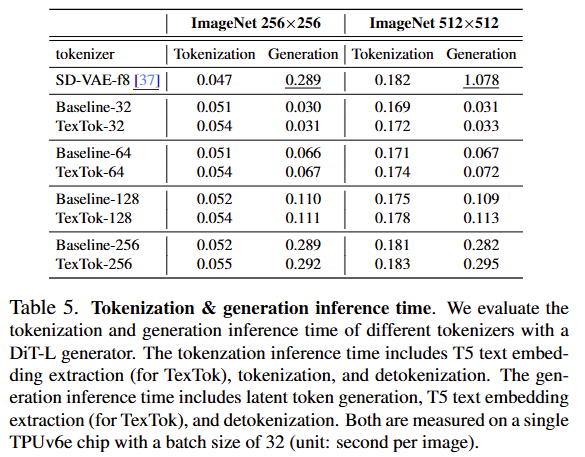
토크나이즈 + 생성 시간
ImageNet 256×256, 512×512 해상도에서 TexTok은 Baseline 대비 Tokenize 시간은 유사하거나 약간 증가했지만, 생성 속도는 전반적으로 빠르거나 비슷한 수준을 보였다고 합니다. 특히 TexTok-32는 Baseline-32보다 더 빠르게 생성되며, SD-VAE-f8 대비 압도적으로 낮은 생성 시간(예: 0.289 → 0.054)을 보여줍니다.
고해상도 (512×512) 테이블 오른쪽
해상도가 높아져도 TexTok은 빨랐습니다. 예를 들어 TexTok-64는 0.072초, Baseline-64는 0.067초로 유사하고, SD-VAE-f8의 1.078초에 해 15배 이상 빨랐다고 하네요
4. Summary
TexTok은 이미지 생성에서 핵심적인 단계인 Image Tokenization 과정에 언어(captions)를 추가하여, 더 의미 있고 효율적인 이미지 토큰 표현을 가능하게 만든 방법론입니다.
기존 토크나이저는 이미지 정보만을 기반으로 모든 시각 정보를 압축했기 때문에, 압축률을 높이면 표현력이 손상되고, 세밀한 묘사를 원하면 토큰 수가 많아지는 trade-off 문제가 있었습니다. TexTok은 이러한 문제를 해결하기 위해, 텍스트 임베딩을 토크나이저와 디토크나이저 양쪽에 모두 조건으로 입력하여, 정보의 역할을 나누고 더 적은 수의 토큰으로도 정교한 이미지 표현을 가능하게 했습니다.
TexTok은 단순히 텍스트를 추가한 것처럼 보이지만, 그 효과는 꽤 인상적이었습니다. 텍스트와 이미지 간의 의미 분리해서, 기존 방식의 한계를 넘어선 효율성과 정밀도를 동시에 달성한 것이죠. 게다가 엄청나게 많은 실험들과 압도적인 성능이.. CVPR에 붙은것을 완전히 납득하게 만든 결과 아닌가 싶습니다.
하이요 리뷰 보고 질문있어서 남깁니다.
우선 리뷰 초반에 vector quantized 형식과 continuous한 방식에 대해 설명을 해주셨는데 quantization 방식이 continuous한 방식과 비교해서 표현력이 떨어진다면 반대로 장점 같은 부분은 없는걸까요?
가령 토큰을 추출하는데 있어서 메모리를 덜 먹고 더 빠르게 한다던지 같은?
두번째 질문으로는 학습 안정화를 위해, LeCAM Regularization을 사용한다고 했었는데 이 부분이 신기해서요. 왜 Discriminator의 output들끼리 KL Divergence를 줄이는 방향으로 학습하게 되면 학습의 안정화가 되는지 궁금합니다.
마지막으로 요즘은 Diffusion과 Gaussian splatting 때문에 GAN을 활용한 연구가 거의 없다고 들었는데 이번에 이렇게 나오니 반갑기도 하지만 반대로 저자의 방법론에 Diffusion 같은 방식이 아닌 GAN을 활용하는 이유가 무엇인가요? Diffusion framework을 적용하기 어렵기 때문일까요?
감사합니다.
Q1. Vector quantized의 장점은?
-> 말씀하신대로, 효율성 (메모리 & 연산) 측면에서 장점이 있습니다. Continuous 하게 표현하지 않다보니 discrete token 처리에 효율적이죠. 그리고 continuous latent 에 비해 optimization landscape도 간단해서 학습이 안정적이라는 장점이 있습니다.
Q2. LeCAM Regularization이 왜 학습 안정화에 도움이 되는가?
-> LeCAM은 GAN에서 자주 발생하는 mode collapse, 불안정한 discriminator–generator dynamics를 완화하기 위해 제안된 방법이라고 하네요. 쉽게 말해 Discriminator가 너무 급격하게 변화하지 않도록 자기 자신을 regularization하는 방식이라고 합니다. 이를 위해, Discriminator의 이전 출력 분포 D_prev(x)와 현재 출력 분포 D(x) 사이의 KL Divergence를 최소화하는 것이죠.
그렇다면 왜 안정적이냐? 일반적인 GAN에서는 D가 너무 빨리 강해지면 G는 gradient를 제대로 받지 못하는 문제가 있다고 합니다. 그에 반해 LeCAM은 D의 변화 폭을 제한해주기 때문에 G가 점진적으로 바뀌기 때문인 것 같습니다.
Q3. Diffusion이 대세인데 언제적 GAN을 쓰는거냐!
-> 이건 제가 저자는 아니라 정확한 이유를 알 수는 없겠으나.. 제가 추측하기에, Diffusion은 GAN에 비해 상대적으로 많이 느리기 때문 아닐까… 하는 생각이 드네요. 사실 해당 논문의 방식을 Diffusion으로 구축할 수도 있긴 합니다.
안녕하세요, 홍주영 연구원님. 좋은 리뷰 감사합니다.
압축 과정에 대해 자세히 설명해주셔서 편하게 읽을 수 있었습니다.
최근 language 쪽 기법들이 굉장히 고도화돼서 다양한 분야에 language 정보를 활용하는것 정도는 알고 있었는데 tokenization에도 활용할 수 있을 줄은 몰랐네요.. 신박한 아이디어 같습니다.
궁금한 점이 있어 간단히 질문 남기겠습니다!
1. 같이 들어가는 캡션의 품질에 의해 이미지 토큰이 영상의 semantic한걸 담아야 하는 부담감이 크게 좌우될 것 같은데요, 관련 실험이나 분석, 혹은 언급이 있을까요??
2. Detokenizer를 ViT로 사용한다고 하는데, ViT가 어떻게 디코더 역할을 수행하는지 와닿지 않습니다. 일부 구조를 변형한 ViT라고 생각하면 될까요??
Q1. 캡션 품질이 성능에 영향을 미칠거 같은데 관련 실험 있나?
-> 직접적인 분석은 없었지만, 캡션 생성에 Gemini v1.5 Flash를 사용했다고 합니다. 제법 강력한 VLM을 사용한 것으로 봤을 때… 즉, 좋은 캡션에 의존하고 있다는 점에서 텍스트 품질은 핵심 영향일 수는 있을 것 같긴 합니다. 그렇지만 양질의 캡션을 뽑는건 논문에서 집중하는 부분과는 다소 거리가 있어 보이긴 합니다!
Q2. ViT가 어떻게 디코더(Detokenizer) 역할을 하는 것인가?
-> 일단 해당 논문에선 Detokenizer로서 ViT 구조를 변형한 Diffusion Transformer (DiT) 를 사용합니다. ViT와 구조는 유사하지만, DiT는 diffusion 모델링을 위한 time step embedding, U-Net-like 구조 또는 residual block을 갖춘 형태로 설계되었다고 하네요. 다시 말해 ViT의 구조를 일부 변형해 디코더처럼 작동하도록 학습시킨것이죠!