안녕하세요, 허재연입니다. 오늘 살펴볼 논문은 CVPR 2025 논문으로, 학회에 참석했을 때 포스터 세션에서 직접 저자에게 컨셉을 설명 들었던 논문입니다. 저자들이 SGG를 주제로 CVPR2025에 논문을 두 편이나 내셨더군요.. 본 논문은 SGG에서도 모달리티 별 통합된 프레임워크를 제안하였다는 점에서 흥미로웠습니다. 리뷰 시작하겠습니다.
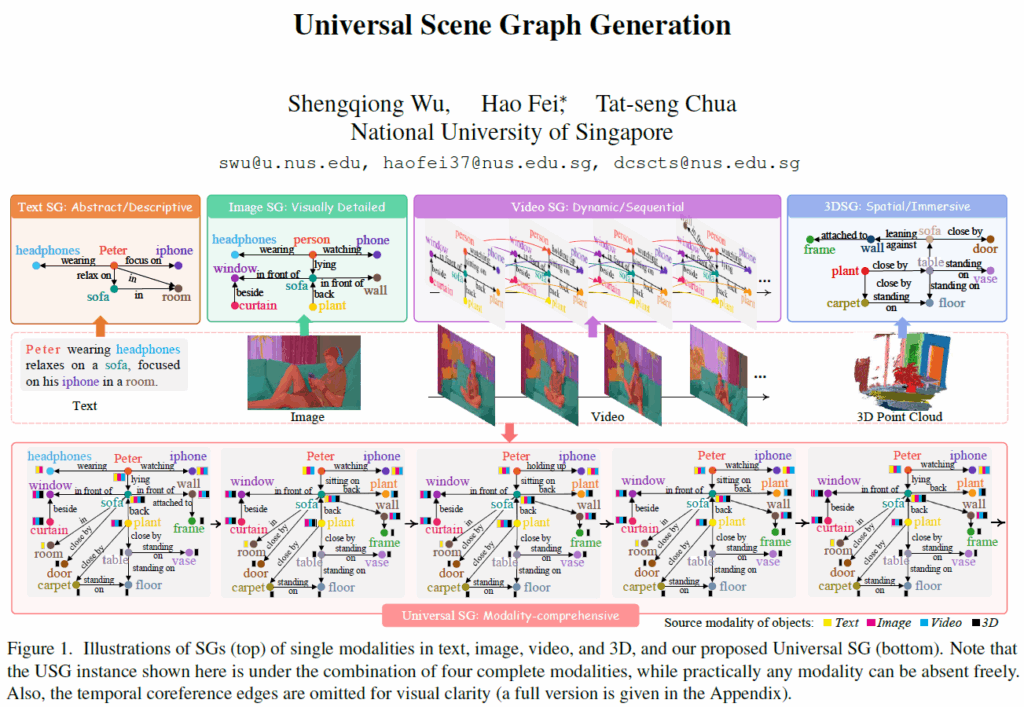

Scene Graph Generation은 장면 이해를 위한 task로, 주어진 이미지 내의 물체들을 찾고 이들 간의 관계(relation, predicate)를 정확하게 예측하는것을 목표로 합니다. 최근에는 단순히 image 형태의 입력뿐만 아니라 video나 3D point cloud 입력에 대해서도 Scene Graph를 활용해 보다 고차원적인 데이터 이해를 시도하고 있습니다.
지금까지는 각 모달리티별로 독립적인 Scene Graph Generation이 연구되고 있었는데, 본 논문의 저자는 다음과 같은 부분에 집중합니다.
“사람은 다양한 감각 모달리티를 활용해 세계를 인식하는데, 서로 다른 상호보완적인 경로를 통해 정보를 받아들이기에 주변 환경에 대해 잘 인식할 수 있다.”
이에 따라 이미지뿐만 아니라 텍스트, 비디오, 3D 형식 등 다양한 모달리티를 함께 활용했을 때는 서로 다른 표현 능력을 가진 각 모달리티 고유한 특성을 활용할 수 있으니, 이들의 보완적인 정보를 활용하여 SGG을 더 잘 수행되게 해보자는 motivation으로 통합 프레임워크를 제안합니다. 각 모달리티마다 특성 및 가지고 있는 정보의 성격이 크게 다르기에, 이를 함께 이용해보자는 것이죠.
각 데이터 모달리티의 특징을 살펴보면, 이미지의 경우 구체적인 시각 정보를 제공해 object의 위치, 크기, 시각적인 속성(attribute)등을 정밀하게 기술하는 scene graph를 생성할 수 있지만 시간적인 정보나 동적인 변화를 표현하기 어렵습니다. 텍스트의 경우 이미지에서 명확히 드러나지 않은 객체의 속성, 행동, 사건 등 객체 간 관계를 비교적 유연하게 표현할 수 있지만 일반적으로 이미지보다 시각적인 세부 요소나 공간적 정보가 부족합니다. 비디오 데이터의 경우 temporal 정보를 추가적으로 가지기에 정적인 이미지 데이터와 비교해 동적인 사건, 행동, 시간적 변화등을 더 잘 표현할 수 있고, 3D 데이터의 경우 물체들의 공간적 관계나 크기, 방향 등 공간적인 특성을 더 잘 모델링 할 수 있습니다.
각 모달리티마다 각각 특화된 정보를 갖고 있기에 직관적으로도 다양한 모달리티를 활용해 Scene Graph를 생성하면 더욱 풍부한 정보를 표현할 수 있을 것입니다. 이는 반대로 말하면 단일 모달리티에만 의존해 SG를 생성하면 포괄적인 장면 그래프를 생성하는데 한계가 있음을 의미합니다. 저자들이 말하는 실제 application에서의 이상적인 프로세스는 단일/여러 모달리티를 조합한 입력을 시스템에 제공하고, 시스템이 각 모달리티 고유 정보와 이들이 공유하는 정보를 적절하게 추출해 통합된 scene graph representation을 생성하여 이를 활용해 장면을 전체적으로 이해하는 것입니다.
하지만 기존에는 여러 모달리티 입력을 고려하지 않고 각각의 데이터에 대해서만 독립적으로 연구가 진행되고 있었기에 모든 모달리티를 포괄하는 프레임워크가 아직 제안되지 않았습니다. 이에 저자들은 본 논문에서 다양한 조합의 모달리티를 입력으로 scene graph를 생성하는 Universal Scene Graph(USG) Generation을 제안합니다. 위 그림 1처럼 USG는 다양한 개별 모달리티를 입력받을 수 있고 이들을 조합해 포괄적인 scene representation을 제공할 수 있다고 합니다.
나이브한 방법론으로는 각 모달리티에 대해 개별적으로 Scene Graph를 파싱한 뒤 이를 합쳐서 하나의 USG로 통합하면 될 것 같은데, 이렇게 할 경우 여러 모달리티에서 동일한 객체를 병합하는 과정에서 모달리티 고유의 장면 정보를 유지하기 어렵고, 각 모달리티의 SG parser들이 서로 독립적으로 동작해서 모달리티 간 상호보완적인 의미 정보가 무시되거나 feature space의 차이로 인해 동일 객체를 정확히 matching하기 어렵다는 문제가 있다고 합니다.
또한, 데이터 측면에서도 3D 데이터의 경우 대부분 정적인 실내 장면에 초점이 맞춰졌다던지, video 데이터으 ㅣ경우 action에 초점이 맞춰졌다던지의 편향이 존재하는 문제가 있었다고 합니다. 이런 도메인 격차로 USG의 일반화 성능이 제한될 수 있다고 합니다.
저자들은 USG Parser(USG-Par)라는 프레임워크를 제안해 어떤 모달리티 입력이든 end-to-end로 장면을 parsing해서 universal한 scene graph representation을 얻을 수 있도록 하였습니다. 모델 학습 과정에서 도메인 간 데이터 불균형 문제를 완화하기 위해 텍스트 데이터를 중심으로 한 contrastive learning을 함께 수행했습니다(ImageBind의 경우 image를 중심으로 contrative learning을 진행했었는데, 본 논문의 저자들은 text가 보다 유연한 표현력을 갖고 있다고 판단한 것 같습니다)
결과적으로, USG Parser로 생성한 USG는 단일 모달리티 기반의 Scene Graph보다 더 포괄적인 장면 정보를 제공해 줄 수 있다고 합니다.
Method
USG-Parser는 각 모달리티별 입력을 입력받아 object representation을 추출하고, 다른 모달리티 간 추출된 객체들이 동일 객체인지 여부를 확인한 후 모달리티 align을 수행하게 됩니다. 이후 relation proposal constructor를 거쳐 객체 간 관계를 모델링하여 relation의 후보를 선별하고 최종적으로 relation decoder를 거쳐서 선택된 relation pair를 기반으로 객체들 간 최종 relation을 예측합니다. 하나씩 살펴보겠습니다.
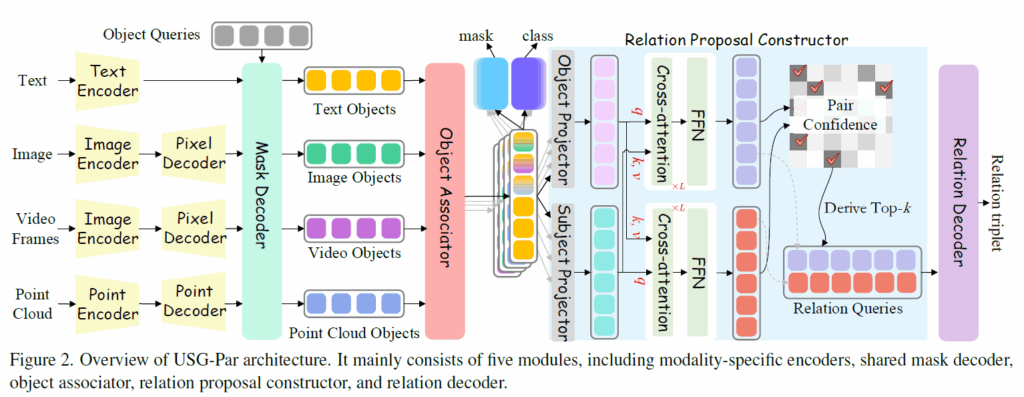
Modality-specific Encoder
우선 각 모달리티 데이터 입력을 처리하기 위해 각 입력을 독립적으로 인코더에 태웁니다. text encoder로는 OpenCLIP을 사용했고, Image 및 video 데이터에는 CLIP-ConvNeXt를 사용했다고 합니다. CLIP인데 통상의 ResNet / ViT이 아니고 ConvNeXt 를 image encoder로 학습한 모델입니다. 픽셀 디코더로는 Mask2Former를 변경한 구조로, multi-stage deformable attention layer로 구성된다고 합니다(multiscale feature 출력). 3d 데이터인 point cloud의 경우 Point-BERT라는 모델을 사용하여 super-point feature를 생성하고, point decoder를 거쳐 multi-scale point feature를 생성했다고 합니다. 모든 모달리티별 feature는 linear layer를 거쳐 동일 차원 d 공간으로 projection됩니다.
Shared Mask Decoder
각 모달리티에서 얻은 객체 정보들이 상호보완적인 정보를 제공할 수 있기에 이를 통합하기 위해 Shared Mask Decoder 프레임워크를 적용시킵니다. Mask2Former라는 구조와 같이 multi-scale featuer와 cascaded docoder를 활용해 modality-speific feature {H}^{*} 와 이에 대응되는 object query feature {X}^{*}_{l} 사이 masked cross-attention을 수행합니다.
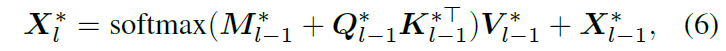
여기서 {N}^{*}_{q}는 쿼리 수를 의미하고 l은 layer index입니다. {M}^{*}_{l-1}는 이전 단계에서 예측된 마스크를 resize하고 binarize한 출력값이라고 합니다. Q, K, V는 각각 linear layer F에 대해 {Q}^{*}_{l-1} = {F}_{q}({X}^{*}_{l-1}), {K}^{*}_{l-1} = {F}_{k}({H}^{*}), {V}^{*}_{l-1} = {F}_{v}({X}^{*})입니다. cross-attention 과정을 생각하시면 됩니다. 이 때 이미지, 비디오, 3D 데이터의 경우 H*를 multi-scale feature output에서 샘플링해서 가져온다고 합니다. 추가적으로 비디오 데이터의 경우 프레임 간 시간 정보를 효과적으로 포착하기 위해 transformer 기반 temporal encoder를 사용해 객체 간 temporal 관계를 모델링한다고 합니다. 제가 비디오와 3D쪽은 잘 모르는데 각 모달리티 정보를 잘 살려주기 위해 추가적인 기법들이 등장하네요. 이후 {L}^{mask}개의 디코더 층을 거치고 나면 최종적으로 정제된 object queries {Q}^{*}를 얻게 된다고 합니다.
Object Associator
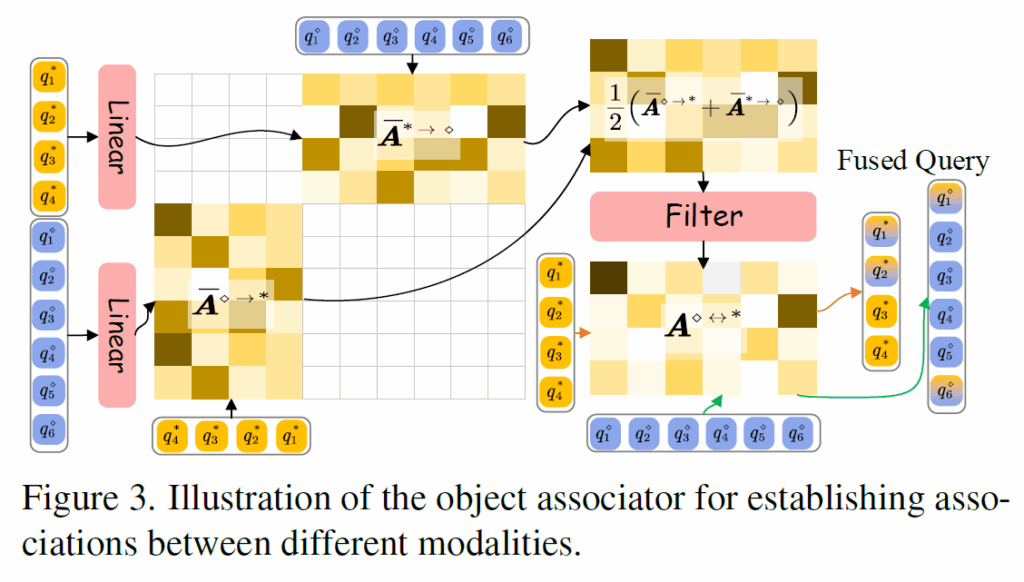
위에서 언급했듯, 모달리티 별 통합 universal scene graph를 생성하는데 가장 어려운 부분은 다양한 모달리티에서 동일한 객체를 정확하게 병합하는 것이라고 합니다. 이를 위해 저자들은 연관 relationship을 결정하기 전에 transformation layer를 도입해 object들을 서로의 feature space로 projection하였습니다.
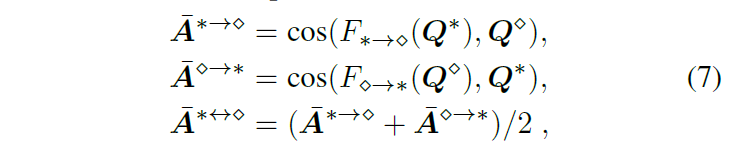
위 수식 7번에서의 F()는 Q를 linear transformation하는 함수이고, Q는 각 모달리티의 object query입니다. 최종적으로 모달리티 간 유사도를 나타내는 코사인 유사도 행렬을 얻은 뒤 CNN기반 필터링 모듈을 거쳐 한번 더 정제하여 association matrix {A}^{∗↔⋄}를 얻습니다. (위 그림 3 참고)
Modality-specific Object Detection Head
이후 object detection은 각 object query segmentation mask와 category label을 예측하는 과정을 통해 수행됩니다. 각 모달리티의 고유 정보를 유지하며 각 모달리테에서 객체를 검출하기 위해 모달리티 별 head를 적용합니다. head구조는 모든 modality별로 동일하다고 합니다.
Relation Proposal Constructor
이 부분은 위 Figure 2를 보시면 이해가 편하실텐데, <subject-predicate-object> triplet에서 주어 및 목적어에 해당하는 각 임베딩을 생성하게 됩니다. 이들 간 cross-attention을 통해 정보를 교환하고, 이후 이들 임베딩 간 코사인 유사도 matrix를 만들어 최종적으로 pair confidence matrix를 만들어냅니다. 모든 relation을 전부 계산해보기에는 연산복잡도가 너무 크게 때문에 여기서 의미 있는 관계들이 커지도록 학습되길 기대하며 top-k개를 선별한 뒤, top-k개에 해당하는 relation queries(subject, object embedding 조합입니다)를 Relation Decoder에 태워 최종 relation 예측에 사용합니다.
Relation Detector
Relation Proposal Constructor를 통해 subject 및 object 후보 쿼리를 추출했으니, 이들을 concat하여 relation query를 구성해 transformer 기반 relation decoder에 태워 최종적으로 관계를 예측합니다.
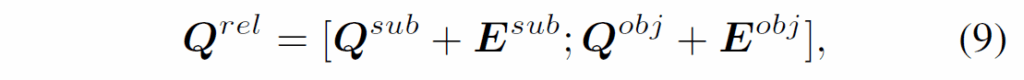
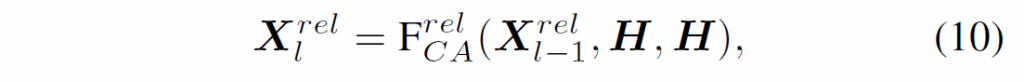
(9)번 수식에서 ;는 concatenation을 의미하고, (10)번 수식에서 {X}^{rel}_{0} = {Q}^{rel}는 relation decoder에 입력되는 relation query feature입니다. F는 context embedding H를 key와 value로 활용하는 크로스 어텐션 연산입니다.
모델 구조를 봤으니, 이제 학습을 어떻게 하는지 살펴보겠습니다.
object detection loss
훈련 과정에서느 예측된 entity mask와 GT entity mask 간 헝가리안 매칭을 적용해 텍스트, 비디오, 이미지, 3D 모달리티의 object query들을 실제 entity에 할당합니다. 이렇게 정해진 매칭 결과를 활용해 mask prediction과 분류 학습을 진행합니다. object classification에는 sigmoid cross entropy를 사용하는데, 이는 object query와 category name의 text embedding간 내적을 통해 얻어진 logit과 실제 객체 클래스 라벨 라이에서 계산합니다. 또한 segmentation을 위해 binary CE loss와 Dice loss라는 것을 활용한다고 합니다.
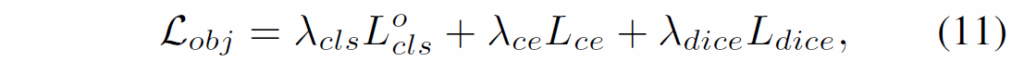
Object Association Loss
object assiciation 모듈을 학습하는데는 GT association matrix를 사용합니다. 이는 binary matrix이고, 모달리티 간 동일한 객체인지 여부를 나타낸다고 합니다. 이 행렬이 sparse하기 때문에 안정적인 훈련을 위해 postivie entries에 도 높은 가중치를 준 weighted binary CE loss를 사용한다고 합니다.
Relation Classification Loss
predicate 분류에는 sigmoid CE를 사용합니다. 이 때 relation proposal constructor가 가장 신뢰도 높은 object pair를 올바르게 선택하도록 하기 위해서 pair confidence matrix C에 대해 weighted binary CE loss L_pair를 적용시킨다고 합니다.
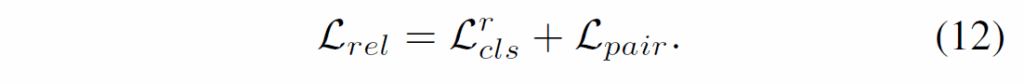
Text-centric Scene Contrastive Learning.
USG-Par를 학습할 때 모달리티 간 도메인 불균형을 해결해야 하는데, 다양한 모달리티 조합에 대한 USG 데이터가 부족해 성능이 떨어질 수 있습니다. 저자들은 이를 해결하기 위해 text 데이터를 중심으로 scene contrastive learning 기법을 제안하였습니다.
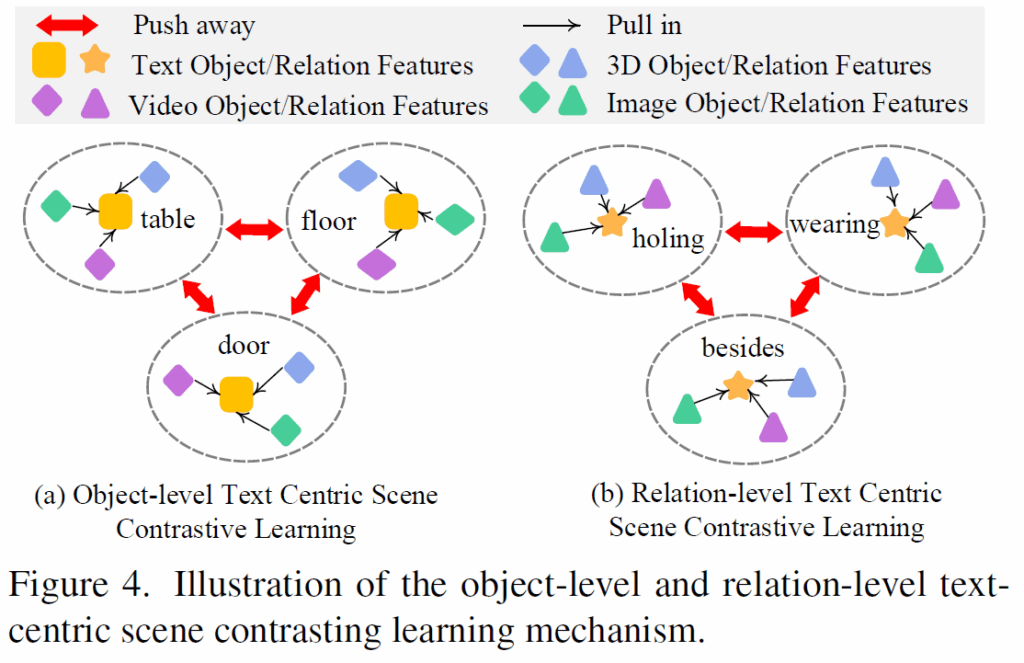
Figure 4와 같이 다른 modality를 text를 중십으로 정렬시키는 방식인데, texual scene graph가 가장 다양성이 높고 일반적인 도메인을 가지며, 다른 모달리티 정보를 text에 결합하여 특정 모달리티 조합에 대한 USG 데이터 부족 문제를 완화할 수 있다고 합니다. 해당 text 객체가 다른 modality에 존재하면 positive pair로 구성하고, 그렇지 않으면 negative pair로 구성해 contrastive learning을 수행했다고 합니다. contrastive loss는 다음과 같습니다.
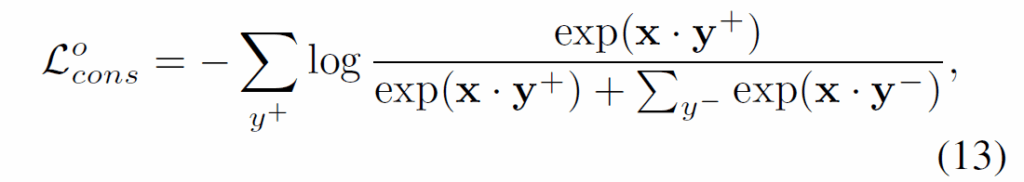
x,y는 pair 간 쿼리 임베딩을 의미합니다.
지금까지 살펴본 loss항들을 weighted sum하여 다음 total target loss로 학습을 진행하게 됩니다.
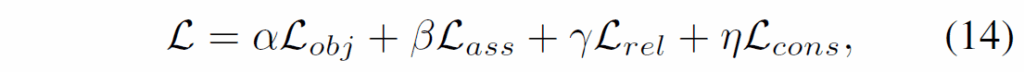
Experiment
실험 결과 보고 리뷰 마무리하겠습니다.
단일 모달리티 및 다중 모달리티 모두에서 실험을 수행했다고 합니다. 단일 모달리티의 경우 각 모달리티에서 일반적으로 사용되는 SGG 데이터셋을 사용했다고 합니다. 이미지 기반 SGG는 VG 및 PSG, 비디오 기반 SGG에는 AG와 PVSG, 3D 장면에는 3DDSG, 텍스트 기반 SG에는 FACTUAL이라는 데이터셋을 사용했다고 하네요. 이미지의 Visual Genome 이외 다른 모달리티 데이터는 처음 봅니다. 이 중 일부 데이터셋은 bounding box 라벨만 있기에SAM-2를 활용해서 pseudo segmentation mask를 생성했다고 합니다.
다중 모달리티의 경우 텍스트-이미지 / 텍스트-비디오 / 텍스트-3D 데이터 쌍을 활용하여 다중모달 SG를 구성했다고 합니다. 각 caption으로부터 GPT-4o를 사용해 초기 텍스트 기반 SG를 파싱하고, 이후 텍스트와 visual object를 label matching 방식으로 연결했다고 합니다. 추가적으로 풍부한 text description을 확보하기 위해 caption을 재작성/확장하여 시각적 컨텐츠와 완전히 일치하지 않더라도 연관될 수 있는 구조로 만들었다고 합니다. 이미지-3D cross-modal SG는 2D 이미지 뷰를 해당하는 3D 장면과 연결했으며, 이미지-비디오 cross-modal SG의 경우, 무작위로 프레임을 선택하여 사용했다고 합니다.
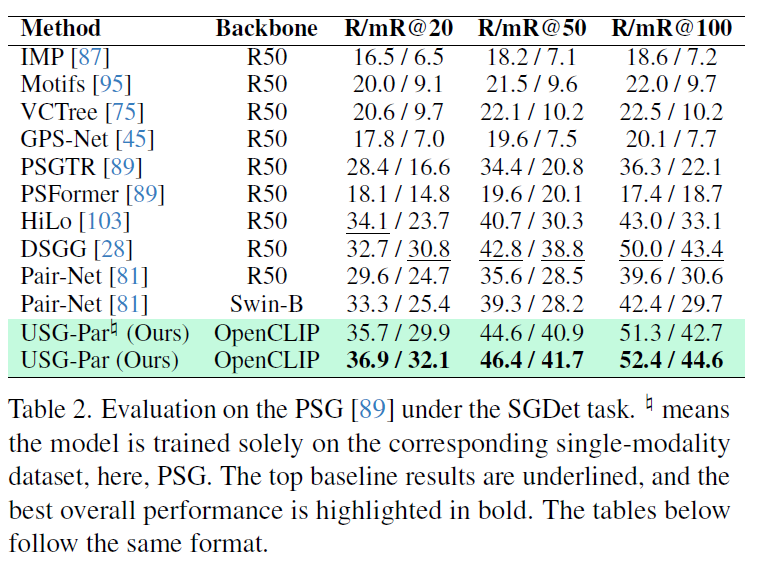
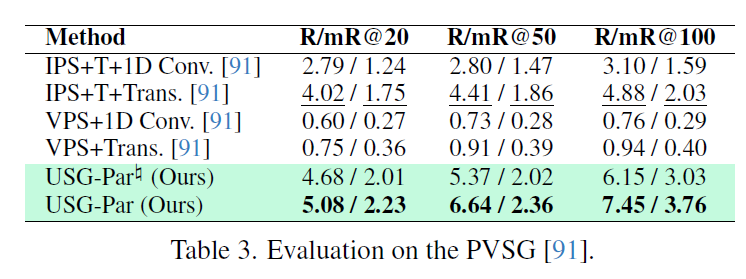
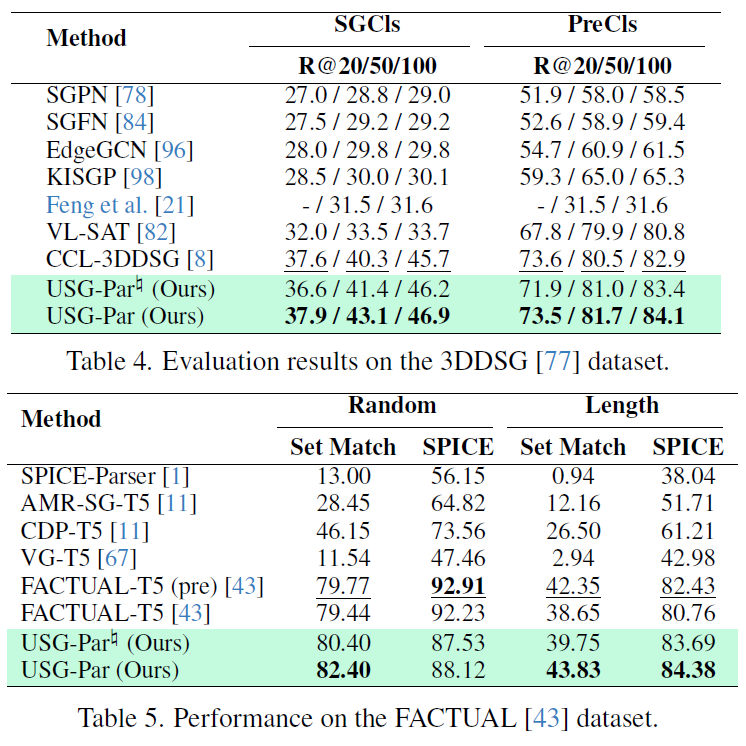
table 2,3,4,5는 각각 단일 모달리티(이미지, 비디오, 3D, 텍스트)에서의 성능입니다. 단일 데이터셋 학습 세팅에서 기존 SOTA baseline들과 비슷한 수준의 성능을 달성했고, 일부 모달리티에서는 기존 성능을 뛰어넘는데 성공했습니다. 다양한 모달리티에 걸쳐 해당 프레임워크 설계가 효과적임을 보였습니다.

다중 모달리티에 걸친 USG 파싱 능력을 평가하기 위해 다양한 pair 기반의 multimodal 데이터셋을 활용한 실험을 수행했습니다. 베이스라인으로 각 모달리티에 대해 가장 우수한 SG 파서를 개별적으로 적용한 후 결과를 결합하는 파이프라인을 사용했는데, Table6과 같이 제안하는 모델은 멀티모달 데이터로만 학습했음에도 기존의 개별 SG 파서를 결합한 방식보다 더 뛰어난 USG 생성 능력을 보여주었다고 합니다.
appendix에 보다 디테일하게 재밌는 요소가 많으니, 디테일한 정보가 궁금하신 분들은 추가적으로 직접 찾아보시면 좋을 것 같습니다.
최초로 다양한 모달리티를 통합한 SGG 프레임워크를 제안한 USG를 살펴보았습니다. 그리 연구가 활발한 분야가 아닌데, 각 모달리티 정보를 통합하기 위해 잘 고안된 모델이 나와 재밌게 읽었습니다. 다른 모달리티는 익숙하지 않아서 그런지 좀 복잡하게 느껴졌네요. 다음에는 open-vocabulary 세팅의 논문을 살펴볼 생각입니다.
감사합니다.
리뷰 잘 읽었습니다.
여러 모달리티(이미지, 비디오, 3D, 텍스트)를 통합하여 Scene Graph를 생성하는 USG Parser를 제안한 논문 같습니다.
몇 가지 궁금한 점이 있어 댓글 남겨두겠습니다.
1. (alignment 성능) USG Parser에서 object association을 위한 cross-modal alignment는 CNN 기반 모듈로 수행되는데, 이는 cross-attention과 비교했을 때 어떤 장단점이 있는지 궁금합니다. 특히 representation collapse 없이 feature를 정렬하기 위한 다른 방법은 없을까요?
2. (단일 모달리티 대비 USG의 이점) 단일 모달리티에서도 유사 성능을 달성한 만큼, 실제 환경에서 굳이 멀티모달로 확장할 이유가 뭘까요? 아니면 어떤 상황에서 USG가 큰 차이를 만들어낼 수 있을지도 궁금하네요
3. (parser 일반화) 다양한 모달리티에 대해 general하게 작동하는 하나의 파서가 각각 특화된 parser들을 뛰어넘는 것이 가능한가요? 오히려 높은 성능을 원할 경우 task-specific한 parser가 더 유리할 수도 있지 않나 라는 생각이 드네요
1. 저도 논문을 처음 읽을 때 object associator에서 matrix에 CNN을 사용한 부분이 눈에 띄었는데요, 본문에는 ‘redundant noise를 효과적으로 필터링 해주면서 local detail을 활용할 수 있는 구조인 CNN 기반 구조를 사용했다’ 정도로만 설명되어 있습니다. 3계층 3×3커널 CNN으로 구현되어 있네요. 아마 간단한 MLP를 태우려고 하다 2d 구조를 유지하기 위해 convolution 구조를 채택한게 아닐까 추측해봅니다. 대칭적으로 linear layer를 거치고 평균낸 다음 CNN을 거치는 복잡한 구조가 아닌, 정보 주입에 자주 사용되는 CA로 간단하게 구현하면 안되나? 라는 생각을 해봤는데, CA는 2개의 input만 고려해야 하는 단점이 있기 때문에 3개 이상의 입력을 동시 고려해야 하는 본 프레임워크에서는 제외한게 아닐까 생각됩니다.
2. 사실 저도 여러 task를 동시에 수행하거나(OD+segmentation), 여러 모달리티를 동시에 입력 받는(ex : video+depth) 통합 프레임워크의 필요성에 대해 크게 공감되지는 않습니다. 하지만 통합적인 framework를 제안한 것 자체가 큰 contribution이고, 저자들은 그 이유를 잘 풀어서 서술했다고 생각됩니다(각 모달리티마다 갖는 정보 특성이 있고, 데이터에 내제된 bias가 있으니 통합 framework가 필요하다). 궁극적으로 각 modality에서 잘 동작한다면, 여러 modality 정보를 통합적으로 고려하면 주변 상황에 대해 보다 포괄적으로 이해가 가능하지 않을까 싶습니다.
3. 일단 저자들이 제안하는 구조가 다양한 modality에 효과적으로 동작하는 것을 맞으나, 각 모달리티 형태 데이터가 아주 풍부하다면 generalist보다 specialist가 (단일 모달리티 데이터만 주어졌을 때) 더 최적화된 성능을 낼 것 같다고 생각합니다. 하지만 충분히 다양한 데이터를 활용할 수 있다면 하나의 모달리티 데이터가 주어졌을때의 specialist보단 보완적인 정보를 더 활용할 수 있는 generalist가 다양한 상황에서 안정적인 예측을 할 것으로 생각됩니다(극히 개인적인 생각입니다)
안녕하세요 재연님 리뷰 감사합니다.
여러 모달리티를 입력으로 받아서 정보가 풍부한 scene graph를 다루는 방법론으로 이해했는데요,
제가 서랍장같은 열리고 닫히는 물체를 3D로 복원하는 연구에도 관심이 있는데, 서랍장을 예로 들면 서랍장에 서랍1, 서랍2가 어떤식으로 움직여서 열리는지에 대한 정보를 텍스트로 전달하고 이미지와 함께 scene graph로 표현해볼 수 있을까요??
기존에는 image 기반 scene graph가 활발하게 연구됐는데, 최근에는 video, 3d, depth와 같은 다른 모달리티에도 확장하려는 시도가 활발합니다. 아직 성능이 제한적이기는 하지만, 충분히 3d 데이터에 대해서도 의미 있는 scene graph를 구축해서 로봇의 scene understanding에 활용할 여지가 있어 보입니다. 하지만 활용 가능할 정도로 성숙하려면 아직 갈 길이 멀어 보이네요.