안녕하세요 text recognition 연구를 다룬 논문을 하나 가져와 리뷰하겠습니다. 지금까지 제가 본 트랜스포머를 활용한 text spotting, text detection, recognition 연구는 인코더-디코더 구조를 사용하였지만 해당 연구는 text recognition 태스크를 위해 디코더만 사용한 첫 연구로 제목만 보고도 너무 궁금해서 바로 읽게 됐습니다. 읽어보니 구조 자체는 간단하더라고요! 여러분들도 간단하게 읽으실 수 있지 않을까 싶습니다. 그럼 바로 리뷰하겠습니다!
1. Introduction & Related Studies
기존의 text recognition 방법들은 강건한 인식을 위해 트랜스포머의 encoder-decoder 구조를 따랐다. 이런 방법들에서는 대부분 인코더로부터 이미지의 intermediate features를 추출하고 디코더에서는 이를 활용해 text sequence를 예측하는 과정을 따랐었다. feature 추출을 위해서는 CNN이나 Vision Transformer (ViT)가 인코더로 사용됐었고 디코더로는 RNN이나 트랜스포머 구조의 디코더를 사용했다. 그리고 일부 모델들은 인식 정확도를 높이기 위해 입력 데이터를 모델에 입력하기 전에 굽은 텍스트를 펴주는 curve correction이나 해상도를 키우는 high-resolution enhacement를 추가적으로 수행했다고 한다. occlusion이나 텍스트 표면의 손상 때문에 일부 글자가 보이지 않은 것 같이 사진 자체의 정보만으로 인식하기 어려운 경우가 있기 때문에 이전 연구들을 또한 language model을 활용해서 linguistic information을 가지고 인식 성능을 향상시키고자 했다. LM을 활용하는 게 성능 향상에는 도움이 되지만 추가적으로 컴퓨팅 자원적 비용이 든다는 게 아쉬운 점이다.
1.1. Language Model
NLP 분야의 여러 태스크를 사전학습된 LMs을 활용해서 높은 성능 향상을 보였었다. 이런 모델들은 decoder-only Transformer의 구조를 채택하였으며 데이터를 바로 디코더로 전달하고 transformer 대로 결과로는 적절한 word token이 출력되는 flow를 따랐다. 이 모델은 대량의 corpus로 사전학습된다. 모델은 사전학습하는 동안 문장 속 단어의 의미나 맥락을 깊이 이해하게 되며 여러 NLP tasks에서 파인튜닝하는 과정에서 이렇게 습득된 지식으로 정확하게 텍스트를 생성한다. 이런 가능성을 가지고 보여진 한 편 이를 text recognition에 적용한 연구는 없었다고 한다.
앞서 설명한 동기를 가지고 이 연구가 수행됐다. decoder-only transformer 구조의 text recognition framework을 새롭게 제안한 것이다. 모델의 이름은 Decoder-only Transformer for Optical Character Recognition (DTrOCR)이다. 이 방법은 인코더를 필요로 하지 않는다. 이를 NLP 분야에 활용한 Generative model들은 텍스트 시퀀스를 입력으로 받고 출력으로 텍스트를 autoregressively하게 출력하는 것 처럼 저자가 제안하는 DTrOCR은 패치화된 이미지를 입력으로 받고 마찬가지로 recognition 결과를 autoregressive 하게 출력한다. DTrOCR의 대략적인 구조는 아래의 (d)와 같다. 생성형 언어 모델을 디코더 내부에서 직접적으로 사용하고 사전학습된 모델로 부터 파인튜닝하기 때문에 컴퓨팅 자원도 훨씬 적게 소요된다는 장점이 있다.
간단한 구조임에도 불구하고 여러 벤치마크 데이터셋에 대해서 우월하는 성능을 냈는데 결과는 차차 살펴보겠다.
2. Methods
2.1 Overall methods
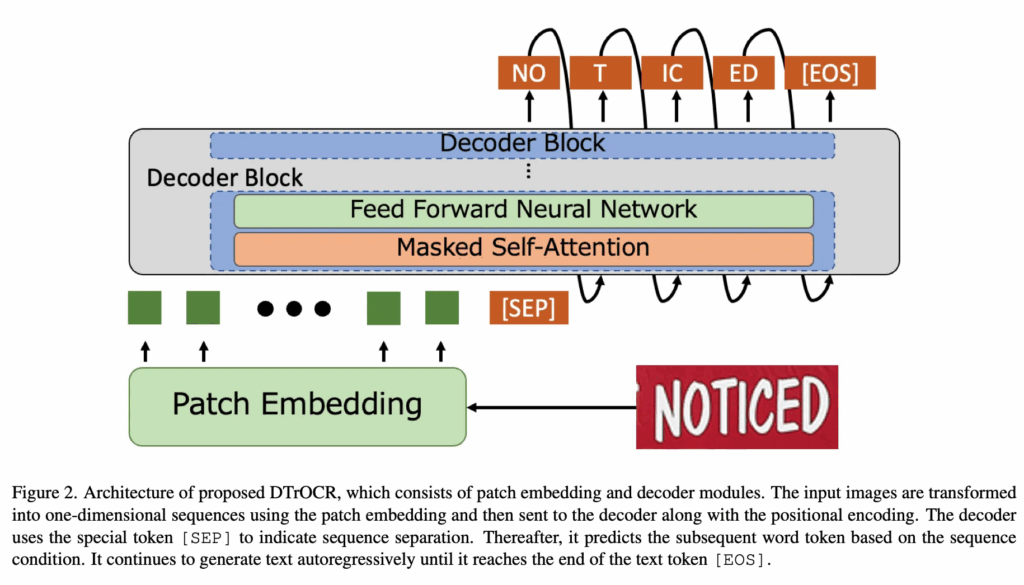
제안하는 모델의 구조는 위와 같다. 디코더로만 구성돼 있다보니 비교적 구조 또한 아주 심플하다. 크게 나눠보면 패치 임베딩되는 단계와 디코더 블록으로 나눠볼 수 있다. 모델에 입력된 텍스트 이미지는 사전에 지정된 크기의 패치로 나뉘어 패치 형태의 이미지 시퀀스 형태로 변환된다. 다음, positional embedding이 더해져 디코더의 입력으로 전달된다. 디코더의 입력으로 이미지 시퀀스와 텍스트 시퀀스를 구분하는 [SEP] 토큰이 붙여진 채로 디코더에 전달이 되는데 디코더는 출력으로 [SEP] 토큰에 이어질 텍스트를 autoregressive하게 하나씩 출력하며 [EOS] 토큰을 출력하기 전까지 텍스트 이미지 속에 있는 텍스트를 토큰 단위로 출력한다. 아래에 각 단계에 대해 더 자세하게 살펴 보겠다.
Patch Embedding Module
트랜스포머는 입력으로 시퀀스 토큰을 입력으로 받기 때문에 모델의 입력으로 들어오는 텍스트 이미지 또한 트랜스포머의 입력될 수 있기 위해 path embedding module를 통과시켜 이미지를 토큰화 시킨다. 이미지 패치화하는 과정은 ViT의 방법 그대로 사용한다. 그 다음 마찬가지로 ViT에서와 동일하게 위치 정보를 보존하기 위한 positional embedding이 각 패치 임베딩에 더해져 디코더의 입력으로 전달된다.
Decoder Module
DTrOCR은 간단하게 얘기하면 image sequence를 받아서 text recognition을 수행하다고 보면된다. 입력된 image sequence를 토대로 [SEP] 토큰을 텍스트의 시작 토큰으로 여기며 이후에 이어질 적절한 토큰을 출력한다. 매 예측은 이미지 시퀀스와 앞선 과정에서 예측된 텍스트 시퀀스 기반으로 수행된다고 보면된다. 디코더 블록의 최종 출력은 linear layer를 통과해 V만큼의 vocabulary 크기의 차원으로 projection된다. 이후 softmax function으로 확률이 결정된다. 최종적으로 beam search이 수행돼 확률값들을 가지고 최종 예측 텍스트 시퀀스를 출력으로 낸다. 학습 과정에서 cross entropy loss가 사용된다.
디코더는 generative LM으로 GPT모델을 쓴다. 사전학습된 GPT를 사용하기 때문에 이에 준하는 language knowledge를 얻기 위한 고비용 구조를 모델에 적용하지 않아도 돼 훨씬 컴퓨팅 자원을 절약할 수 있는 방법이다.
decoder-only transformer 모델의 경우 인코더를 필요로 하지 않기 때문에 기존의 encoder-decoder 구조의 트랜스포머 모델이 decodere단에서 인코딩된 feature와 디코더의 입력 시퀀스 간의 attention을 수행하던 cross attention layer를 필요로 하지 않는다. 따라서 하나의 디코더 블록은 오직 self-attention과 FFN로만 구성된다.
Pretraining with Synthetic Datasets
모델은 GPT로 language knowledge를 얻지만 전달받는 이미지와 그 지식을 연결짓는 건 학습이 되지 않은 상태다. 따라서 여러 텍스트 형태, 여러 장면, 자필로 작성된 텍스트, 타이핑된 텍스트 등으로 합성된 데이터셋을 가지고 사전학습이 진행돼 이미지 정보와 언어 정보가 연결된다.
Fine-Tuning with Real-World Datasets
합성 데이터만으로 학습하는 것은 real world data로 학습하는 것 간의 도메인 갭이 있기 때문에 저자는 합성 데이터로 사전학습 한 이후 real world data로 파인튜닝을 수행했다고 한다. 학습과정은 합성 데이터셋에서의 학습과 파인튜닝 과정 모두 앞선 방법을 동일하게 사용한다.
3. Experiments
oTA와의 벤치마크 성능 비교와 ablation study에 대한 실험 결과이다. 예측된 text sequence가 모든 character에 대해서 맞히면 맞았다고 본다.
text recognition에서의 SOTA인 모델과의 정성적인 비교 결과이다. occlusion이나 정형화되지 않은 레이아웃의 텍스트에 대해서도 보다 정확하게 예측하였다. 그리고 이전 모델로는 실패했던 two-line 텍스트에 대해서도 recognition을 정확히 예측했다.

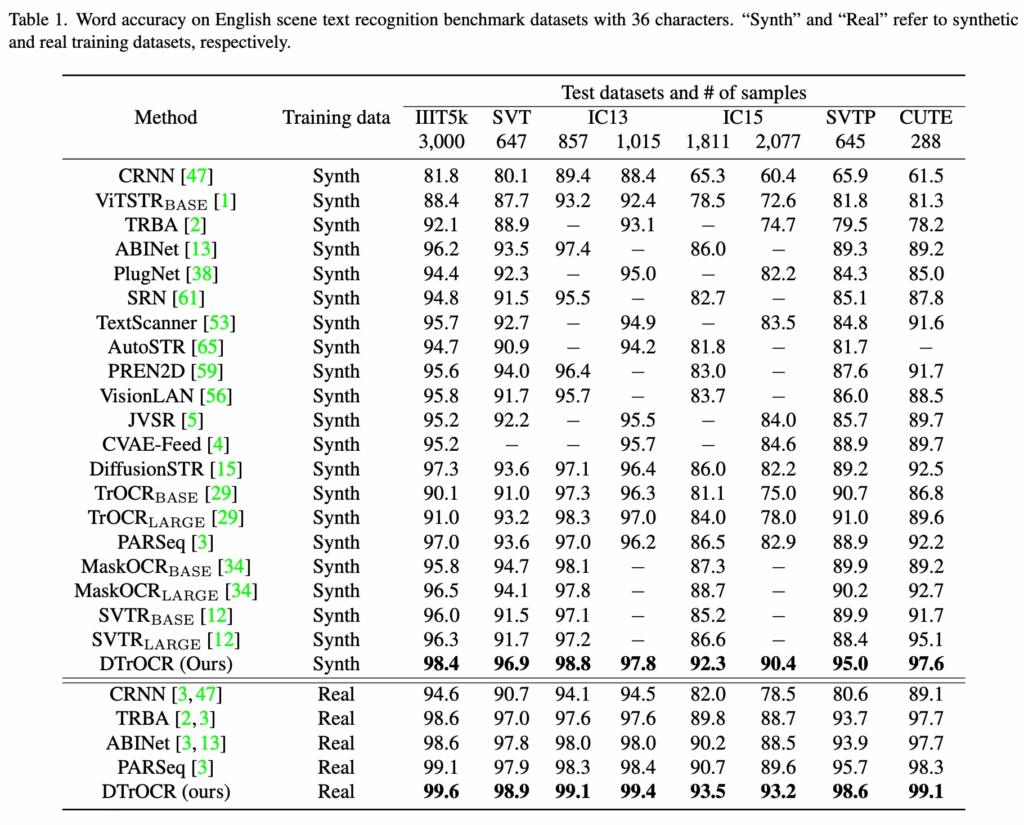
다음은 scene에서의 text가 아닌 영수증 같은 문서에서의 text recognition 모델과 성능을 비교한 실험의 결과다. CNN 기반의 feature 추출기나 ViT를 인코더로 사용한 기존 모델과 비교했을 때 논문에서 제안하는 모델은 이미지 추출 단계를 생략하고도 추월하는 성능을 냈다.
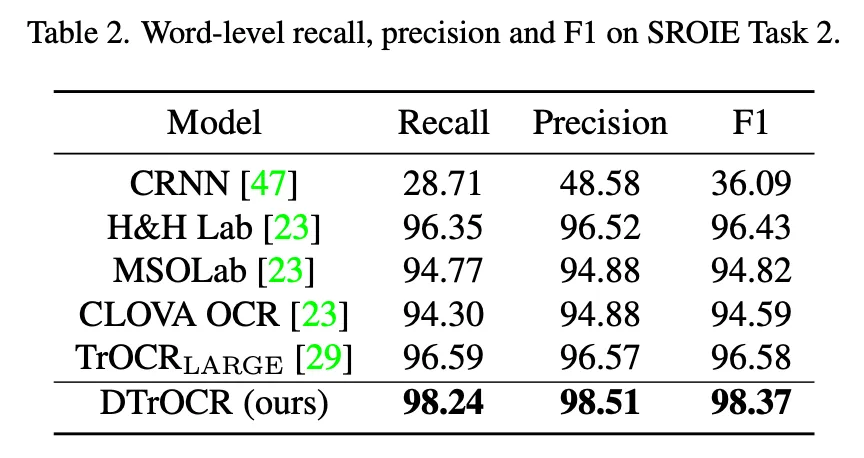
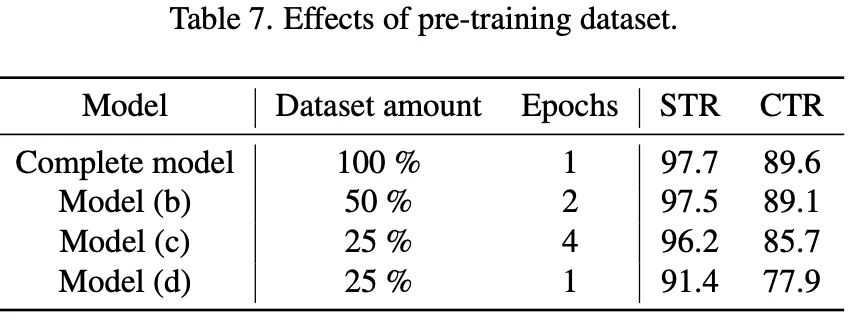
다음은 중국어로 구성된 텍스트 데이터셋(CTR)에 대한 벤치마킹 실험 결과이다. 논문에서 제안하는 모델이 영어 뿐만 아니라 문자의 개수도 훨씬 많고 저 복잡한 형태의 언어인 중국어에 대해서도 recognition 성능이 기존의 방법보다 정확한 걸 보인 실험으로 여러 언어에 대한 일반성을 보였다고 할 수 있겠다. 물론 파라미터의 개수와 FPS는 비교적 많고 낮다. 하지만 저자는 기존에 제일 좋은 성능을 보인 large scale model인 MaskOCR과 비교했을 때 훨씬 좋은 성능을 내면서도 파라미터수는 그 보다 작다고 설명하고 FPS의 경우 낮지만 language model에 대한 가속기에 대한 연구가 지속되고 있기 때문에 해당 문제는 이후에 해결될 수 있다고 설명한다.
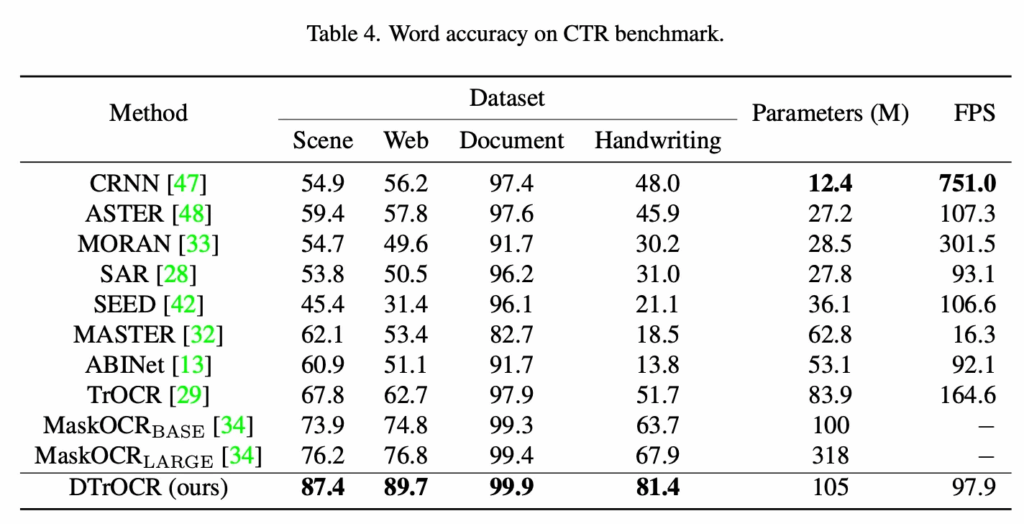
아래는 모델 구조에 대한 ablation study 결과이다. Model (a)는 이미지 시퀀스를 만들 때 패치화 대신 인코더로 부터 추출된 feature의 시퀀스로 이미지 시퀀스로 구성한 경우이다. 복잡한 형태를 갖는 중국어 특성상 image feature를 사용한 경우가 조금 더 좋았지만 그에 못지 않게 논문에서 제안하는 decoder-only 모델도 높은 정확도를 보인다. 또한 STR의 경우 더 좋은 결과를 보였다. 그리고 RoBERTa란 LM을 사용한 것과의 성능도 비교했지만 GPT-2를 사용하는 게 성능이 좋았다.
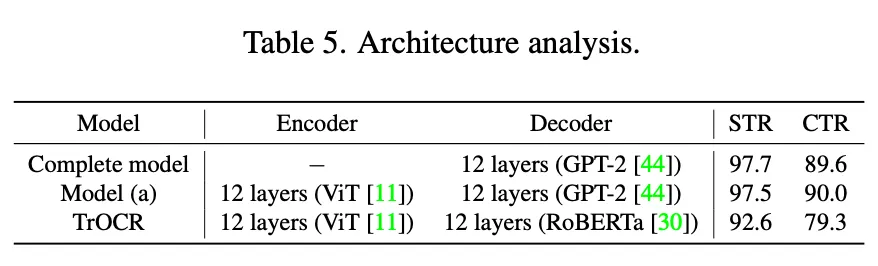
아래는 학습 과정에서 사용된 각 단계에 대한 효과를 확인한 실험이라고 보면된다.
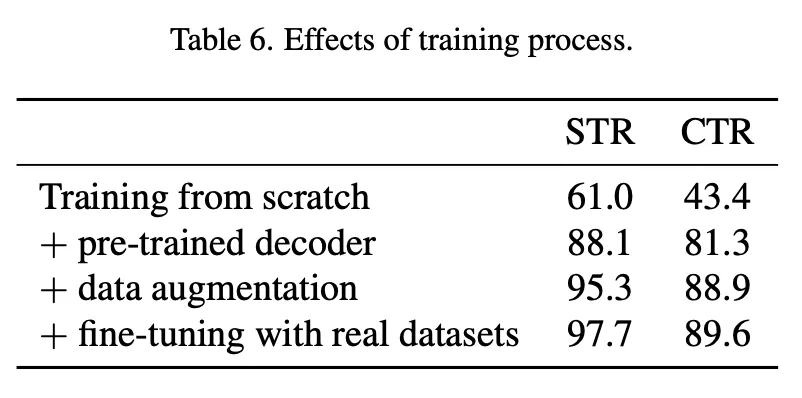
아래는 사전학습 때 사용하는 합성 데이터셋의 양과 epoch수를 가지고 비교한 실험이다. Model (b), (c)는 데이터셋을 차례대로 50%, 75% 줄인 방법이고 이때 iteration 수는 그대로 가져갔다. 데이터양을 줄였을 때 성능이 떨어지는 것으로 비추어 보아 데이터량을 증가시키는 게 성능 향상에 영향을 준다는 것을 확인했고 학습 횟수를 늘리는 것보다 더 효과적임을 확인할 수 있었다. Model (d)는 에포크수의 증가 없이 감소된 데이터셋으로 사전학습한 경우의 결과인데 성능 하락 폭이 더 크다.
4. Conclusion
리뷰한 내용을 정리해보겠다. 기존의 text recognition 모델 중 트랜스포머를 사용한 모델은 많았지만 거의 모든 모델은 인코더-디코더 구조를 사용해 text sequence를 예측하기에 앞서 텍스트 이미지로 부터 특징을 추출하는 과정을 거쳤었다. 한편, NLP 분야에서는 여러 테스크에 대해서 디코더만으로 구성된 트랜스포머 구조로 효과적인 성능 개선을 확인한 연구가 많았는데 이 text recognition 분야에서는 이를 적용하지 않은 상태였었다. 이 논문은 text recognition 분야에 decoder-only transforemer 구조를 처음 적용한 연구라고 불 수 있겠고 연구를 통해 그 가능성이 검증되었으며 앞으로도 이를 확장한 연구를 기대해볼 수 있겠다.
이만 리뷰 읽어주셔서 감사합니다!!
안녕하세요 지연님 좋은 리뷰 감사합니다.
방법론을 읽으면서 개인적으로는 디코더만 사용하는 것보다 인코더를 함께 사용하는 구조가 더 나은 성능을 낼 것이라고 기대했는데,
Ablation Study를 보니 오히려 디코더만 사용하는 경우의 성능이 더 좋은 결과를 보여서 의외였습니다. 혹시 논문 내에서 이러한 결과에 대해 어떤 분석이나 설명이 포함되어 있었는지 궁금합니다. 만약 별도의 설명이 없다면, 지연님의 의견은 어떤지 궁금합니다.
감사합니다.
안녕하세요 질문 남겨주셔서 감사합니다
논문에서는 CTR 데이터에 대한 결과와 비교하면서 STR의 경우 이미지 내 텍스트가 갖는 특징 자체가 보다 덜 복잡하기 때문에 인코더 없이 논문에서 제안하는 구조만으로도 더 정확한 성능을 낸 것이라고 설명합니다. 또한, 여기에 제 생각을 붙이자면 텍스트를 다루는 태스크 특성 상 객체 검출과 비교했을 때 비교적 저차원의 특징으로도 충분하기 떄문애 인코딩 과정 없이도 좋은 성능을 낼 수 있었다고 생각합니다. 따라서, 만약에 태스크가 달라진다면 해당 방법론이 적절한 방법은 아닐 수도 있겠다는 생각입니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 모델은 decoder만 사용하여 text recognition을 수행하는 모델로 이해했습니다. 이 디코더는 pretrained 된 GPT를 사용하는 것으로 보이는데, 그럼 학습 중에는 freeze해서 사용하는 것인가요 ? 만약 그렇다면 어디를 학습하는 것인지 궁금합니다.
또, language knowledge와 이미지를 연결짓는게 학습이 되지 않은 상태여서 사전학습을 통해 이미지와 언어 정보를 연결한다고 하셨는데, fine-tuning과 같은 방식으로 pre-training을 한다고 했는데 이 사전학습 과정이 어떻게 knowledge와 image정보가 연결되는 과정인가요 ?
감사합니다.
안녕하세요.
질문 감사합니다.
1. 본 모델에서 학습 과정은 합성 데이터셋으로 사전학습하는 과정과 real 데이터셋으로 파인튜닝 단계로 나뉘는데 논문에서는 두 학습과정에서 어디를 freeze하고 어디를 학습가능하게 놔두었다는 언급은 없었습니다. 이는 코드를 확인하고 알려드리겠습니다!
2. 가져오는 GPT 모델은 언어를 이해하고 생성하는데 탁월하지만 실제 이미지 입력을 함께 받아와 recognition을 수행하는 능력은 학습되지 않았기에 real data로 파인튜닝하기 전에 합성된 데이터로 해당 태스크에 대한 훈련을 하는 거라고 보시면 될 것 같습니다.
감사합니다.
안녕하세요 지연님 좋은 리뷰 감사합니다. 읽다가 한가지 궁금한 부분이 생겨 답글 드립니다.
Decoder Module 부분에서 decoder-only transformer 모델의 경우 인코더를 필요로 하지 않기 때문에 결과적으로 cross attention layer를 사용하지 않게 된다고 이해했는데 이 경우에 이미지와 텍스트 modality 간의 어떤 연관성 같은 부분은 어떻게 학습이 되는지가 궁금합니다. 혹시나 제가 놓친 부분이 있다면 알려주시면 감사하겠습니다.
안녕하세요 우현님 질문 주셔서 감사합니다.
이 논문은 디코더 말고 추가적으로 모달리티를 정렬하거나 하는 모듈이 없다는 게 큰 특징인데요.
디코더 입력으로 이미지를 패치화해 임베딩 하고 이 이미지 임베딩에 추가적으로 text에 대한 토큰 임베딩이 함께 입력돼 self attention 으로 학습되면서 두 모달리티에 대한 연관성이 학습된다고 보시면 되겠습니다. 감사합니다.