안녕하세요. 저번 리뷰는 Long-text Uncertainty Quantification(LUQ) 이라는 불확실성 추정 기반으로 LLM의 Long-text response에서의 hallucination현상을 정량적으로 추론해보자는 개념의 방법론을 들고왔었는데요. 갑자기 또 매니퓰레이션과 policy 관점에서의 무언가를 들고 오게 되었습니다. 리뷰 작성이 띄엄띄엄이었어서 제 리뷰 흐름을 한번 더 정리할 필요도 있고, 리뷰 논문 선정 기준이 와리가리 하기도 했어서, 읽으시는 분들이 조금 당황스러울수도 있으실 것 같아 들고 온 이유를 좀만 정리하고 들어가겠습니다.
우선 앞선 제 리뷰들에서도 간간이 언급해왔지만, 제가 관심있는 연구 흐름은 다음과 같습니다. 복잡한 매니퓰레이션 task, 혹은 Long-horizon task에서의 매니퓰레이션 시 로봇이 사람처럼 작업을 단계별로 합리적으로 딱딱딱 잘 쪼개서 sub-task를 구성하고, 그에 맞춰 각각의 low-level policy를 수행하는 흐름을 원하고 있습니다. 말이 좀 길었는데, 연구 키워드로 정의해보면 “high-level planning” 과 “sub-task decomposition”이라고 생각하고 있습니다.
우선 ‘사람처럼 알아서 딱딱’ 이라는 관점에서, 저번 리뷰에선 ‘LLM의 common sense을 활용해서 high-level task planning 해야겠네?’ vs. ‘근데 LLM hallucination 은 간과하면 안되지?’ 로 생각의 흐름이 흘러가서 LLM hallucination의 불확실성 추정 → high-level planning 시 LLM 답변의 신뢰성 확보 쪽으로 접근해보았었습니다.
반면 이번 리뷰는 ‘로봇이 행동할 수 있는 어떤 skill policy 단위로 sub-task를 정의해보면 좋지 않을까?’의 관점에서 독특한 접근을 가지고 있어 활용성이 좋을 것 같아 들고 온 논문입니다. 사실 비디오로부터 시각적인 로봇 조작 작업 단위를 의미적으로 분해해보겠다는 내용인지라, 비디오팀 분들에게도 연관이 있을 수 있는 내용일 것 같습니다. 서론이 길었습니다. 시작합니다.
1. Introduction
실제 환경에서 요리나 청소 같은 집안일은 로봇에게는 복잡하고 긴호흡의 동작을 필요로 하는 Long-horizon task 라고 볼 수 있습니다. 그래서 로봇이 이런 실제 환경에서 진짜 동작하기 위해서는 시각적 관찰을 통해 장기적인 조작 작업을 학습하고 수행할 수 있는 능력을 갖추어야 하기에 기존엔 RL(강화학습)이나 IL(모방학습) 기반의 학습방법이 있어왔죠. 하지만 시각정보 기반의 복잡한 기술을 긴 호흡으로 학습시키겠다는 것 자체가 몇 가지 문제점이 있습니다. 긴 호흡의 시각정보 기반 학습이기에 error를 누적시킬 수 있으며, action과 state space 자체가 너무 방대해지고, 그리고 작업의 각 단계에 대해 의미 있는 어떤 학습 시그널을 주는데 어려움이 있습니다.
이 때문에 학습과정을 좀 잘 만들어 주기 위해선, Long-horizon task를 여러 개의 sub-task로 분해하는 것에 대한 필요성이 대두되는데요. sub-task로의 분해는 사실 학습 효율성을 향상시키는 것을 넘어서, 재사용 가능한 기술 학습을 용이하게 하고, 서로 다른 action trajectory 간의 어떤 정보 공유 또한 촉진하며, 더 나아가 학습된 sub-task 기반의 unseen 시퀀스 조합에 대해서도 일반화가 가능하게 합니다.
이렇게만 들으면 sub-task decomposition 참 좋고 중요한 것 같은데, 사실 태스크 분해 자체가 실제 환경에서 수행되기엔 여러 제약조건이 있어서 참 어렵습니다. 대부분의 기존 방법들은 태스크, 데이터셋 또는 로봇 플랫폼에 대한 어떤 사전정의된 가정들을 필요로 하기 때문이죠. 이런 가정은 보통 로봇의 에이전트가 목표로 하는 행동을 오직 비디오 demonstration 데이터에서만 접근할 수 있고, 비디오 외에는 별다른 정보가 없는 환경이라고도 볼 수 있겠습니다. 따라서, 저자들은 여기서 그럼 별도 제약조건 없이, 어떤 시각적 데모가 주어져도, 바로 분해할 수 있는 off-the-shelf(범용성 있는) 방법론의 필요성을 제기하게 됩니다.
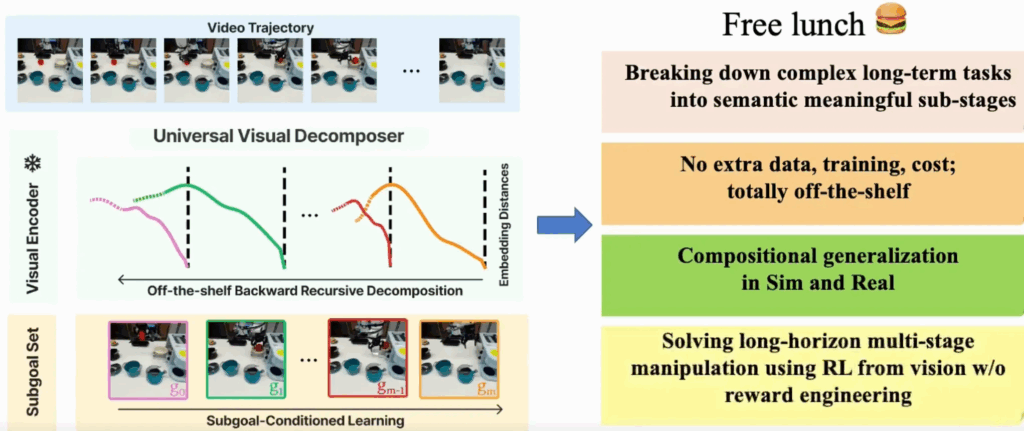
결국은 unsegmented 작업 비디오 demonstration 안에 내재된 sub-task들을 식별할 수 있는 시각적 작업 진행 자체에 대한 일반적인 지식이 필요합니다. 본 논문에서는 이를 Universal Visual Decomposer(UVD)라고 제안합니다. 즉 논문의 표현을 빌리면, 비디오 input이 들어왔을 때 사전학습된 sota급의 어떤 visual encoder로부터 임베딩된 시각적 표현을 재활용해서, 자동화된 task segmentation을 수행하는 off-the-shelf unsupervised subgoal decomposition 방법론이라고 할 수 있습니다. 저자들의 project page에선 이를 free lunch라고도 표현하고 있네요.
저자들은 여기서 핵심 통찰 하나를 써먹는데, 앞서 말한 사전학습된 visual representation 자체는 목표지향적인 인간의 행동이 담긴 짧은 비디오들에서 temporal task progress를 포착하도록 학습되었다는 사실을 관찰해내면서, 이런 representation들이 short-horizon의 atomic skill을 표사하는 로봇 영상 프레임들 간에서 단조롭게 진행되는 임베딩 거리를 학습하게 됨을 파악했는데요. 즉, 기존 visual representation을 뽑는 비디오 인코더로부터 subgoal뽑는 건 short<→long 간의 그 temporal한 양이 잘 맞지 않아 long-horizon 속의 subtask간 소속정보를 잘 담지 못하게 된다는 단점이 있게되는 것입니다. 그 결과 작업이 길어질수록 임베딩 거리는 monotonicity(단조로움)를 잃고, 전체 작업에서의 phase shift가 일어나는 프레임 부근에서 plateau(정체구간)을 보이게 됩니다. 이 현상으로부터 unsupervised 방식으로 임베딩 거리로부터 sub-task가 언제 발생했는지를 감지하는 신호를 뽑을 수 있게 되는 것입니다. 이로 인해 UVD가 도메인 특화된 지식을 전혀 필요하지 않게 되고, 별도의 조정없이 다양한 로봇 도메인에 바로 적용가능하다는 off-the-shelf의 모습을 가질 수 있게 되는 것입니다.
그렇담 이 UVD가 작업에 대한 sub-goal을 잘 추출해낼 수 있다면 어떻게 로봇 학습에 적용되는 것인가가 이제 중요해지는 데 결론만 말하면, UVD는 시뮬레이션과 실환경 모두에서 장기 시각 조작 작업을 위한 의미 있는 subgoal을 unsupervised하게 추출할 수 있었고, 이를 통해 실험적으로 강화학습과 모방학습에서 정책 성능을 크게 향상시키는 모습을 보여주었다고 합니다. 특히, in-domain과 out-of-domain 작업 모두에 대해 일반화 능력을 보여주며, 수동 데이터 수집의 부담을 줄이고 장기 작업 학습을 가능하게 하는데, 자세한 내용은 method와 experiments파트에서 더 다루도록 하겠습니다.
저자들의 contribution을 정리하면 다음과 같습니다.
- 사전학습된 visual representation을 활용한 long-horizon task를 위한 off-the-shelf visual decomposition 방법인 Universal Visual Decomposer(UVD)제안.
- UVD로부터 발견된 subgoal을 사용한 long-horizon visual 강화학습을 위한 reward shaping 방법론 제안.
- 여러 시뮬레이션 및 실제 로봇 작업에서 InD(In Domain), OoD(Out of Domain) 평가에서 정책의 성능을 개선하는 데 있어 UVD 효과 입증.
2. Related Work
로봇 매니퓰레이션에서 long-horizon skill 학습은 오랜 도전 과제이며, 기존의 계층적 강화학습(HRL) 기법은 subskill을 스스로 학습하고 이를 기반으로 계획을 수립하지만, 계산 비용이 크고 실제 로봇에 적용하기 어려웠습니다. demonstration, 즉 모방학습이나 강화학습용 로봇 데이터에서의 비디오가 주어질 경우, 기존 연구들은 subgoal decomposition을 통해 중간단계의 학습 시그널을 뽑고 누적 오차를 줄이려 하지만, 대부분 task-specific knowledge, proprioception(그리퍼나 관절 상태 등의 로봇고유정보), LLM을 활용하는 연구의 경우에는 명시적 하위 태스크 구조에 의존한다는 문제가 있습니다. 또 다른 접근으로 latent generative model 기반 subgoal 분해는 대규모 데이터나 높은 연산 cost를 요구합니다.

UVD는 최초로 어떤 task-specific한 지식이나 추가 학습 없이 동작하는 범용 시각 기반 태스크 분해 방식을 제안했다는 점에서 큰 의미가 있는 건 알겠고, 기존 사전학습된 visual representation을 그대로 sub-goal decomposition에 재활용한 첫 사례인데, 어찌보면 그냥 그대로 갖다써먹은 거 아니냐 싶겠지만 일부 기존 연구가 visual representation을 보상으로 활용한 반면, 본 연구는 이를 계층적 분해와 보상 설계 모두에 활용하면서 long-horizon visual 강화학습 문제를 해결할 수 있음을 보여준 게 의미가 크다고 저자들은 주장하네요.
3. Problem Setting
[ Unsupervised Subgoal Discovery (USD) ]
자 다시 정리하면 결국 USD의 목표는 전체 작업 시연인 $\tau = (o_0, …, o_T)$ trajectory가 input으로 주어졌을 때, 다음과 같이 분해된 subgoal을 내뱉는 것이 목표입니다. $\text{USD}((o_0, …, o_T)) \rightarrow \tau_{\text{goal}} := (g_0, …, g_m)$, (1)
여기서 $(g_0, …, g_m)$은 subgoal로 선택된 $\tau$의 하위 집합이며, $m$은 궤적에 따라 다를 수 있습니다.
[ Policy Learning ]
policy 학습을 위해서는 시연 $D := \{\tau\}^n_{i=1}$이 주어지는데, 강화 학습 환경에서는 달성해야 할 전체 작업을 지정하기 위해 작업이 하나이고 $n = 1$이라고하는 가정이 들어갑니다.(intro에서는 가정이 많이 필요없는 off-the-shelf일거라 했는데,,, 의문입니다.) 평가는 $D$에 캡처된 작업의 gt 시퀀스인 내부 도메인 (in-domain, IND)과 $D$의 subgoal의 unseen 조합으로 구성된 외부 도메인 (out-of-domain, OOD) 로 이뤄집니다.
RGB 이미지를 K차원 임베딩 공간에 매핑하는 사전 학습된 시각적 표현 $\phi: \mathbb{R}^{H \times W \times 3} \rightarrow \mathbb{R}^K$로 표현가능하도록 하면, $\phi$와 $D$가 주어졌을 때, 임베딩된 observation 및 goal에 따라 action을 출력하는 goal-conditioned policy인 $\pi: \mathbb{R}^K \times \mathbb{R}^K \rightarrow \Delta(A)$, $a \sim \pi(\phi(o), \phi(g))$를 학습하는 것이 policy learning의 목표가 됩니다. 이 때 이 강화 학습 환경에서 에이전트에는 보상 정보가 제공되지 않으므로 $\phi$와 $D$를 사용하여 보상을 구성해야 합니다.
[Policy Evaluation]
OOD 평가의 경우 수행할 하위 작업 시퀀스를 지정하는 시연 $\tau$ 를 하나 제공하는 것으로 세팅한다고 합니다.
4. Method
사실 방법론은 생각보다 직관적이면서도 효과적으로 보였습니다. 앞서 말했듯이, 사전학습된 visual representation의 임베딩 공간에서 phase shift를 어떻게 detecting 하느냐가 메인 컨셉입니다.
[A. Universal Visual Decomposer]
자 그럼 unsupervised 방법론이니까,, 레이블이 지정되지 않은 비디오 데모 $\tau = (o_0, …, o_T)$가 주어졌을 때 유용한 subgoal을 어떻게 발견할 수 있을까요? UVD의 핵심 컨셉은 goal 프레임 $o_t$를 조건으로 할 때, 그 앞에 오는 $n$개의 프레임 $(o_{t-n}, …, o_{t-1})$이 goal 프레임에 시각적으로 근접해야 한다는 것입니다. 즉 이 goal-reaching 시퀀스에서 첫 번째 프레임 $(o_{t-n})$을 발견하면 그 앞의 프레임 $(o_{t-n-1})$은 또 다른 subgoal이 됩니다. $o_{t-n-1}$부터 시작하여 $o_0$에 도달할 때까지 동일한 절차를 recursive하게 수행하는 것입니다. 여기서 해결해야 할 두 가지 핵심 질문이 있는데, (1) 그럼 첫 번째 subgoal(타임스탬프 기준으로 마지막)을 어떻게 찾을 것인가?, (2) 현재 subgoal의 중단점을 결정하고 새 프레임을 새로운 subgoal로 어떻게 정의할 것인가? 입니다.
먼저 질문(1)은 데모에서 마지막 프레임 $o_T$가 자연스럽게 goal이 된다는 점을 관찰함으로써 간단히 해결할 수 있죠. 이제, subgoal $o_t$를 조건으로 하여, $o_t$로의 시각적 task progress 변화를 묘사하는 프레임의 하위 시퀀스에서 첫 번째 프레임 $o_{t-n}$을 추출하려고 시도합니다. 이 첫 번째 프레임을 발견하기 위해, 저자들은 로봇 제어를 위한 여러 sota pretrained visual representation(LIV[ICML 23’, Meta], Vip[ICLR 23’ SpotLight, Meta], R3m[CoRL 23’, Meta])이 단일 해결된 작업을 묘사하는 짧은 비디오 내에서 temporal progress를 포착할 수 있도록 사전학습되었단 사실을 활용합니다. 이러한 representation은 짧은 goal-reaching 비디오 시퀀스 $\tau = (o_{t-n}, …, o_t)$에 걸쳐 monotonicity(단조로운 추세)를 보이는 임베딩 거리를 효과적으로 생성할 수 있습니다. $\qquad d_\phi(o_s; o_t) \geq d_\phi(o_{s+1}; o_t), \forall s \in \{t – n, …, t – 1\}, \qquad (2)$ 여기서 $d_\phi$는 $\phi$-representation 공간에서의 거리인데. 본 연구에선 L2 distance 즉 $d_\phi(o; o’) := \Vert \phi(o) – \phi(o’) \Vert_2$로 설정합니다. 이는 여러 사전학습된 표현이 학습을 위한 임베딩 메트릭으로 L2 distance를 사용하기 때문이라고 합니다. 이를 감안하여, 이 monotonicity(단조성)라는 조건이 실패하는 $o_t$에 대해 시간상 가장 가까운 관찰을 이전의 subgoal로 설정하게 됩니다. $\qquad o_{t-n-1} := \text{arg max}{o_h} d\phi(o_h; o_t) < d_\phi(o_{h+1}; o_t), h < t. \qquad (3)$
논문에 의거해 부연 설명하면, (시각적으로 보기에 $o_t$를 향해 진행하는 것과 같이) 동일한 sub-task에 속하는 이전 프레임은 임베딩 거리가 temporal한 progression을 실제로 포착한다면, 후속 프레임보다 더 높은 임베딩 거리를 가져야 합니다. 결과적으로, monotonicity에서 벗어나는 것은 이전 프레임이 현재 subgoal과 명확한 관계를 나타내지 않을 수 있으며, 대신 그 자체가 subgoal일 수 있음을 나타냅니다. 이제 $o_{t-n-1}$이 새로운 subgoal이 되며, 전체 시퀀스 $\tau$가 소진될 때까지 (3)을 recursive하게 적용합니다. 예를 들어, 그림 1에서 마지막 프레임을 조건으로 할 때, $g_3$는 임베딩 거리에서 변곡점을 생성하여 subgoal로 선택된 첫 번째 이전 프레임입니다. 그런 다음 $g_3$를 조건으로 할 때 $g_2$가 선택되는 식입니다.
자세한 알고리즘 및 수도코드는 아래와 같습니다.


실제로 식 (2)는 임베딩 및 픽셀 공간의 노이즈로 인해 모든 단계에서 유지되지 않을 수 있으며, 분해된 각 subgoal 사이에 미리 설정된 최소 시간 간격을 두어 너무 가깝지 않도록 하고, 임베딩 거리를 먼저 평활화하는 로우 패스 필터 절차를 통해 subgoal 기준 식 (3)이 효과적이게 됩니다.

Fig. 2에서는 UVD의 반복적인 분해 과정을 시각화하여 임베딩 거리 곡선(왼쪽)과 그 결과로 분해된 subgoal(오른쪽)을 보여줍니다. 시뮬레이션 작업은 FrankaKitchen에서, 실제 로봇 작업은 Fold-cloth 세팅에서 이뤄집니다. 동작의 경우에는 서랍 열기, 충전기 집기, 플러그 꽂기, 전원 스트립 켜기 및 서랍 닫기를 보이는데요. 왼쪽 임베딩 거리 시각화에서 검은색 점선은 UVD가 단조 감소가 깨지는 시점을 식별하는 시점을 나타내며, 앞서 언급한 최소 간격을 고려합니다.
[B. UVD-Guided Policy Learning]
UVD가 발견한 subgoal들이 policy learning을 보완하는 데 사용되는 건 모방학습, 강화학습 2가지로 나눠서 살펴볼 수 있겠습니다.
<Goal Relabeling.(모방학습 적용의 경우)>
UVD는 demo에서 각 궤적 단위로 수행되므로, 궤적 내의 모든 관찰을 이후 시점에 등장하는 가장 가까운 subgoal로 relabeling할 수 있습니다.
특히, 행동이 라벨링된 궤적 $\tau = (o_0, a_0, …, o_T, a_T)$와 UVD가 발견한 하위 목표 $\tau_{\text{goal}} = (g_0, …, g_m)$가 주어졌을 때, 각 시점 t에서의 관찰 $o_t$는 시간 t 이후에 처음 나타나는 subgoal $g_k$로 라벨링됩니다.
즉, ${\text{Label}(o_t) = g_k, \quad \text{where } g_k \text{ is the first subgoal after } t}$ 가 되고.
이 과정을 통해 다음과 같은 augmented goal-relabeled trajectory $\tau_{\text{aug}} = \{(o_0, a_0, g_0), …, (o_T, a_T, g_m)\}$을 만들 수 있습니다.
이제 모든 transition이 goal-conditioned 조건을 가지므로, 어떤 goal-conditioned imitation learning 알고리즘이든 적용할 수 있으며, 본 연구에서는 단순화를 위해 목표 조건 행동 모방(GCBC) (GCIL [NIPS 19’], GCSL [ICLR 21’ Oral])을 사용했습니다.
<Reward Shaping.(강화학습 적용의 경우)>
위의 goal relabeling은 IL 환경에 적용됩니다. 하지만 IL에 필요한 데모 수집은 cost는 높습니다. 반면, RL은 훨씬 적은 수의 데모로도 가능하며, 예외 처리와 같은 부가적인 학습 효과도 기대할 수 있습니다. 이러한 배경에서, 저자들은 UVD subgoal을 RL에서 어떻게 활용할 수 있는지, 특히 장기 RL에서 exploration 문제를 어떻게 완화할 수 있는지가 핵심 접근으로 이뤄졌습니다.
UVD는 subgoal을 선택할 때, 각 연속된 subgoal 쌍 사이의 임베딩 거리가 monotonicity를 보이도록 구성하니까, 여기서 다음과 같은 UVD 기반 보상 함수를 정의하게 됩니다.
${R(o_t, o_{t+1}; \phi, g_i) := d_\phi(o_t; g_i) – d_\phi(o_{t+1}; g_i)}$
여기서 $g_i \in \tau_{\text{goal}}$이며, 만약 시점 t+1에서의 관찰 $o_{t+1}$이 $g_i$에 충분히 가까워지면, 학습 중 자동으로 다음 목표 $g_{i+1}$로 전환됩니다.
이러한 방식의 보상은 목표를 향해 일관되게 전진하는 행동을 유도한다고 합니다.
[C. UVD Goal Inference]
이제 UVD로 subgoal도 뽑아내고, policy learning도 했는데, inference는 어떻게 하는 지 살펴보겠습니다.
추론 시에 학습된 subgoal-conditioned 정책을 적용할 때, 각 관찰 단계에서 정책이 따라야 할 subgoal을 결정해야 합니다. 저자들은 두 가지 전략으로 나눠 접근합니다.
<Nearest Neighbor>
먼저, 학습할 subgoal의 고정된 순서가 하나만 있는 경우 (즉, IND 실험 세팅인 경우), 간단한 NN 목표 선택 전략을 사용합니다. 즉, 새로운 관찰에 대해 가장 가까운 임베딩 ( $d_\phi$ 로 판단)을 갖는 학습셋의 관찰을 계산하고 해당 subgoal을 사용합니다. 이는 낮은 수준 정책에 대한 관찰 조건부 goal을 출력할 수 있는 non-parametric한 고수준 정책 $\pi(\phi(o), \phi(g))$ 으로 해석할 수 있습니다.
<Goal Relaying>
OOD 또는 다중 작업 IND 평가를 수행할 때, 에이전트는 사용자가 지시한 작업을 완료해야 합니다. 이러한 설정에서는 훈련에서 보이는 subgoal이 잠재적인 unseen 작업에 유효하지 않을 수 있으므로 위의 NN 방식이 더 이상 적용되지 않을 수 있습니다. 대신, 임베딩 거리를 기반으로 현재 지시된 목표를 릴레이할 것을 제안합니다. 특히, 지시된 subgoal의 시퀀스 $g = (g_0, …, g_m)$ 가 주어지면, 정책은 현재 관찰과 하위 목표 사이의 임베딩 거리가 특정 임계값 미만이 될 때까지 첫 번째 남은 하위 목표에 조건을 적용하고, 그 시점에서 정책은 시퀀스의 다음 하위 목표에 조건을 적용합니다.
5. Experiments
method의 how to 자체보단 실험에 비중이 더 많았는데요.
실험은 다음 3가지 question에 중점을 둡니다.
- UVD는 multi-stage 나 multi-task IL(모방학습)에서 compositional generalization 즉 조합적 일반화 능력이 있는가?
- UVD의 subgoal은 long-horizon RL에서 reward shaping을 가능하게 하는가?
- UVD는 real-robot task에서 적용될 수 있는가?
[A. Simulation Experiments]
시뮬레이션 실험을 위해 FrankaKitchen 환경을 사용합니다. 빨주노초~ 로 표시된 총 7가지 객체들과 상호작용할 수 있고, 저자들은 해당 환경이 데이터셋을 정제해서 successful trajectories만 포함시키면서 총 513개의 에피소드를 만들었고, 해당 모든 에피소드들은 VR헤드셋 기반 teleoperation으로 수집되었다고 합니다. 각 에피소드에서 7개 객체 중 임의 선택된 4개의 객체가 임의 순서로 섞이면서 아래와 같은 training, InD eval, OoD eval을 구성하게 됩니다.

<Visual and Policy Backbones.>
UVD에서 사용되는 visual representation을 뽑는 사전학습된 모델은 기본적으로 비디오 데이터에 대해 temporal objective로 학습된 resnet50 기반 R3M, VIP, LIV 입니다.
policy 아키텍쳐는 MLP기반으로 단순하게 구성해서, 사전학습된 representation의 UVD에서의 활용성 측면을 강조했다고 합니다.
<Baselines.>
UVD의 가치를 입증하기 위해 goal-conditioned behavior cloning (GCBC) baseline과 비교합니다. visual representation 방식은 고정한 상태에서, GCBC와 GCBD+UVD 간의 유일한 차이점은 학습 때 목표를 labeling하는 방식입니다. 각 observation에 대해 GCBC는 동일한 trajectory에서 마지막 frame을 목표로 labeling합니다.
<IL Evaluation Protocol.>
아까 Fig3을 참고하면, n개의 객체 시퀀스 조합으로 IND 평가를 통해 학습하고, 나머지 24 – n개의 작업 시퀀스는 보이지 않는 OOD 시나리오 평가를 위해 남겨둔다고 합니다. 기본적으로 n = 16을 사용하며, 공정한 비교를 위해, 모든 실행 세트에 대해 3개의 고유한 사전 정의된 시드에 의해 생성된 동일한 3개의 무작위 seen-unseen 분류를 사용한다고 합니다. 정책 성능 평가는 전체 작업의 성공률(success rate)과 완료된 하위 작업 수(completion)이고, 평균, 표준표차로 표현됩니다.
각 하위 작업에 대한 성공 기준은 시뮬레이션 gt 상태에 의해 결정됩니다.
<Results.>
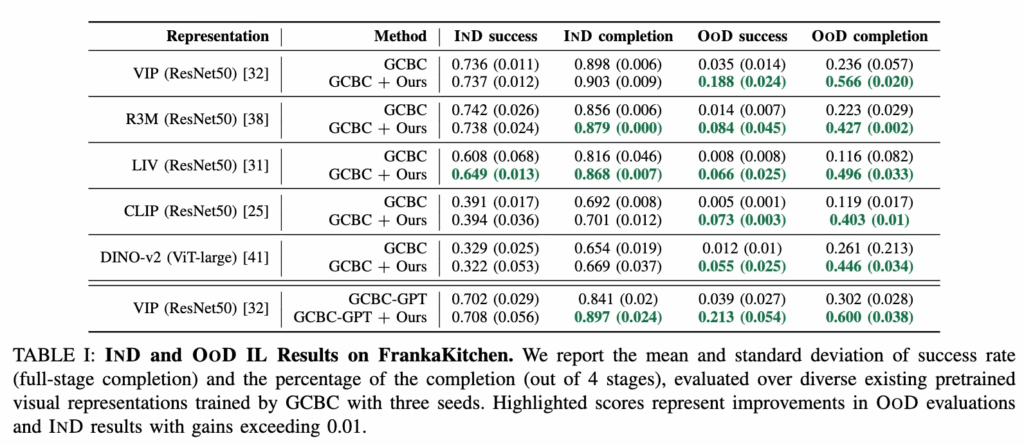
UVD를 사용함으로써, 모든 사전 학습된 visual representation은 다양한 IND 성능에도 불구하고 OOD에 대한 일반화 평가에서 꽤나 많은 개선치를 보여줬습니다. 그럼에도 OoD에선 절대적인 성공률 자체가 낮긴하지만.. 단조성 임베딩 거리를 학습하도록 명시적으로 훈련된 두 representation인 VIP와 LIV는 다른 representation에 비해 더 높은 성능을 보여줍니다. CLIP, DINO-v2와 같이 정적 이미지 학습에 집중된 모델들도 UVD 적용 시 OOD에서 향상되나, 시간적 특징 기반 모델에 비하면 상대적으로 작은 결과를 보였습니다. 특이한 점은 GPT 스타일의 causal transformer 기반 policy를 활용한 VIP 표현에서도 UVD가 OOD 환경에서 success와 completion을 크게 높이며, 이는 과거 정보에 민감한(policy that is history-aware) 구조 즉 더욱 복잡한 정책 아키텍처임에도 불구하고 UVD가 일반화 성능을 향상시킨다는 점을 시사했습니다. 즉 이 부분에서 저는 코드적으로 구현만 잘 가능하다면, sub-task에 대한 low-level policy가 VA/VLA 방식으로 학습된 policy(즉 대규모 IL)여도 이 때 UVD를 적용하여 sub-skill에 대한 pseudo label로써 학습 시그널을 더 좋게 만들어주니 앞으로 VA/VLA policy 학습이 필요할 시 저의 연구에 활용해먹는 데 의미 있을 수 있겠단 생각이 들었습니다.
<Ablations.>
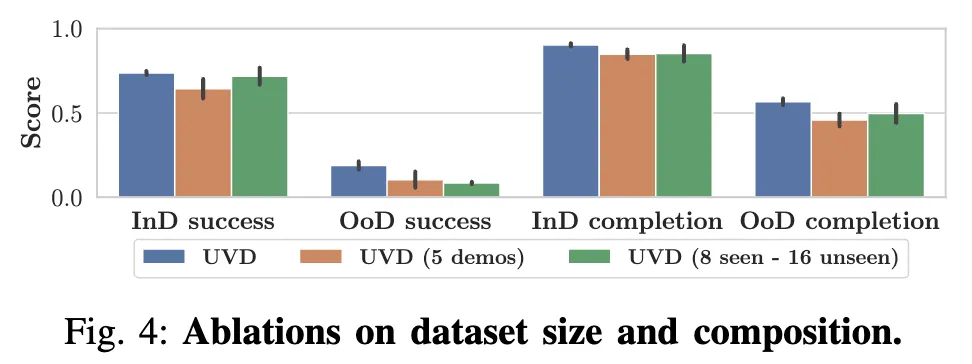
해당 ablation study는 모두 VIP를 백본으로 설정하고 진행했다고 합니다. 학습 작업 당 데모 수를 5개로 줄이거나, 학습 작업 수를 8개로 줄이되 각 작업당 전체 데모 수는 8+16으로 유지하는 경우로 실험했는데, 그 결과 IND 및 OOD 성능이 모두 유사한 경향이거나 살짝만 낮아지는 경향을 보이면서, UVD가 다양한 데이터 크기와 다양성에도 강건한 OOD 일반화가 가능함을 보여줬습니다.
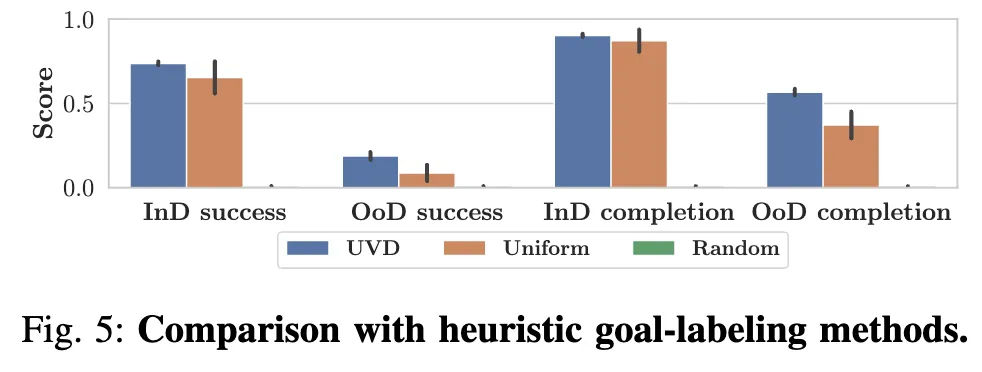
마지막으로, UVD가 강력한 OOD 일반화를 달성하는 데 대안이 될만한 subgoal 생성 방법 비교로, Uniform과 Random 방식에 대한 비교 ablation study입니다. Uniform 방식은 관찰 후 고정된 크기의 window 내에서 프레임을 무작위로 선택합니다. Random은 demonstration 내에서 3~5개의 프레임을 subgoal 프레임으로 무작위로 선택합니다. 그림 5에서 볼 수 있듯이, 이러한 대안들은 모든 설정 및 지표에서 성능을 저하시켰는데, 이러한 대안들은 중복되고 의미적으로 덜 중요한 subgoal들을 도입하기 때문이라고 합니다. 결과적으로, 이들은 IND에서는 비슷하게 수행될 수 있지만, OOD 일반화는 저하되는 모습을 보였습니다.
<UVD-Guided Reinforcement Learning.>
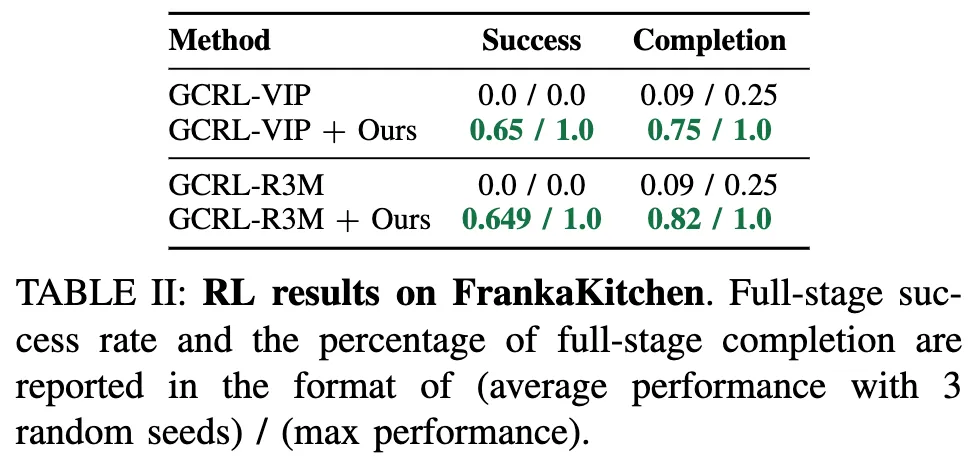
UVD 기반 강화학습 결과입니다. UVD가 뽑은 subtask에 대해 goal-based 보상을 reshaping해서 RL에 넣는 방식이었는데, 학습 과정 자체는 앞선 method에서 말했듯이 action label이 없이 단일 비디오 demo만이 에이전트에게 주어지는 세팅이었습니다. 즉 unsupservised이죠.
전자레인지 열기 → 주전자 옮기기 → 조명 스위치 토글 → 캐비닛 슬라이드 의 작업시퀀스를 평가대상으로 삼았는데,
GCRL은 baseline이고, 이는 보상을 구성할 때 시연 영상의 마지막 프레임을 모든 시점의 goal로 고정해서 사용하는 것입니다. 기본적으로 강화학습 알고리즘은 PPO로 구성했고, 위 테이블 2에서 평균 success, 최대 success, 작업완료율 로 평가했습니다.
실험결과 UVD 기반의 reward reshaping된 visual RL이 월등히 더 높은 성능을 보였는데, 물론 baseline이 19,21년도 방법론이긴 하지만 그럼에도 불구하고, unsupservised라는 점에서 정말 놀라운 성과이긴 합니다.
정리하면 UVD+RL이 학습 그 자체에 유효함을 보인 것이라고 할 수 있겠으나, 미리 정의된 작업시퀀스를 평가대상으로 삼았기에, 작업의 일반화 관점에서는 역시 아직 RL-based 방법론 자체가 대응이 불가능한 요소이기때문이지 않을까라고 생각이 듭니다.
[B. Real-World Experiments]
<OOD Evaluation.>
실제 Franka 로봇에서 수행되는 3가지 multi-stage task로 평가를 구성하는데요. pick, pour, fold, articulated manipulation 등의 sub-task를 포함한 조합이라고 합니다. 각 작업에 대해 100개 정도의 teleoperation 데이터를 수집했다고 하며, 이 때 관련 객체들의 위치는 고정된 분포 내에서 무작위 배치했다고 합니다. 정책 학습은 시뮬레이션과 동일하게 MLP기반의 GCBC 방식으로 수행했습니다.
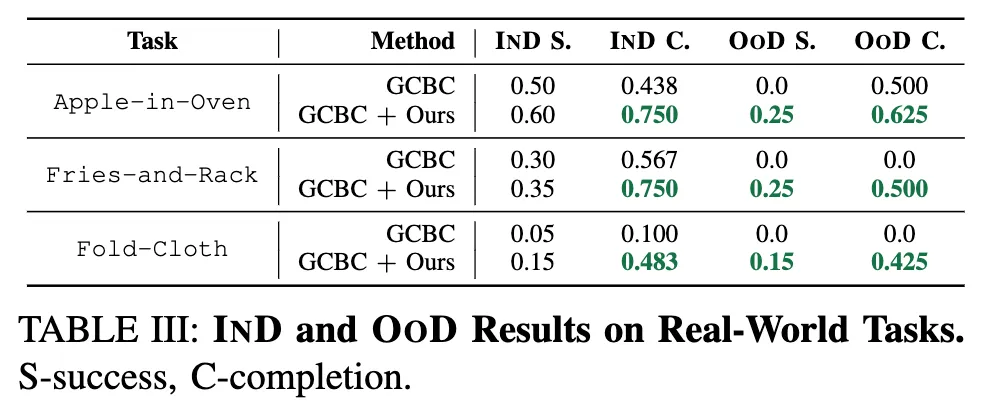
시뮬레이션에서 sub-task들이 조합가능했던 것과 달리, 실제 작업에 대한 평가에서는 시퀀셜한 의존성을 가지기에 임의 순서로 수행할 수가 없습니다. 그래서 compositional generalization을 평가하기 위해 정책이 중간 작업을 건너뛸 수 있는지, 즉 환경에서 그 작업의 결과 상태(post-condition)이 이미 충족되어 있는 경우를 실험했다고 합니다. 예를 들어 fries-and-rack 작업은 초기 상태에서 감자튀김이 이미 접시에 놓여있는 경우로 테스트하는 것입니다.이 경우엔, 의미 있는 subgoal로 학습된 정책이면, 바로 그릇을 들어서 rack에 올리는 작업을 이해하고 수행해야겠죠. 마찬가지로 사과태스크의 경우는 사과가 처음부터 접시에 놓여있는 상황으로, 옷접기 태스크의 경우는 이미 대각선 방향으로 한번 접힌 상태를 초기조건으로 설정하여 이런 식으로 평가를 진행했다고 합니다.
결론으로는 위의 표 3에서 확인할 수 있듯이, 모든 작업에서 UVD 기반 방법은 OOD 작업을 성공적으로 해결한 반면, 기존 베이스라인은 IND에서는 유사한 성능을 보이더라도 OOD에서는 완전히 실패했습니다.

마지막으로, Figure 6은 OOD 작업에서의 UVD 정책 실행 결과에 대한 시각화입니다. 샘플링된 프레임들과 해당 프레임의 조건 하위 목표(inset frame)를 함께 보여줍니다. 모든 경우에서, UVD는 훈련 데이터에서 의미 있는 하위 목표를 회수하고, 정책은 이 하위 목표가 표현하는 semantic subtask를 성공적으로 수행했습니다.
6. Conclusion
UVD는 어떠한 task-specific한 지식이나 추가 학습 없이도, off-the-shelf하게 적용가능하단 장점이 있었지만, 사실 이건 다 fully observable한 매니퓰레이션 태스크에 국한된 경우입니다. 즉 시뮬레이션 환경처럼 이상적으로 모든 visual scene이 관측되어야한다는 전제가 있긴 합니다. partially observable한 상황(예를 들면 navigation task나 scene이 급변하는 embodied task)에서는 직관적이고 의미있는 subgoal을 뽑아내지 못할 수 있다는 단점이 있습니다.
그럼에도 future work로는 egocentric 시나리오나, key-frame detection 기반의 video understanding, dense video caption task 등에서 활용될 수 있는 점이나, UVD방식으로 뽑은 task-graph가 reset-free RL(환경 세팅을 매번 초기화하지 않아도 되는 RL)에 활용될 가능성이 있다고 합니다. 이 부분은 사실 잘 모르는 태스크긴 한데 메모차 남겨놨습니다.
안녕하세요 재찬님 리뷰 감사합니다.
해당 논문에서 subgoal을 이미지 가지고 판단하는거로 이해했는데요, 혹시 gripper의 state가 변하는 부분이나 로봇의 전체적인 state의 변화가 매우 적은 (의미있는 행동을 하러 이동한 직후, 혹은 gripper가 움직이는 경우)를 같이 사용해서 판단하는 것은 어떻게 생각하시나요? 제가 subgoal 개념을 완전히 이해한게 맞는 질문인지는 모르겠습니다,,!!
안녕하세요 영규님, 리뷰 읽어주셔서 감사합니다.
본 논문에서 정의하는 UVD 알고리즘 기반의 subgoal 찾기는 video 관점에서 visual적인 임베딩 distance의 ‘단조성’이 깨지는 지점을 subgoal 지점으로 잡는다는 것이 핵심입니다.
실제로 이전에 제가 리뷰했던 Q-attention 같은 논문에선 gripper state가 열리고 닫히는 부분을 관측하는 상황이나, 로봇 end-effector의 속도가 0에 근접하는 지점을 관측하며 해당 지점들을 로봇이 행동하는 데 있어 중요한 scene으로 판단하여 key point scene으로 정의하고 탐지하여 이것을 강화학습이나 모방학습 시 supervision으로써 사용하는 경우도 있었기에, 본 논문의 UVD + key point selection 을 같이 섞는 방법도 충분히 유의미할 수 있다고 생각합니다.
안녕하세요 재찬님 좋은리뷰 감사합니다.
생각보다 설정해줘야하는 부분이 좀 있는 것 같은데 이중 하나라도 빠지거나 좀 독특한 image embedding 경향성을 보이는 task 에서는 성능이 좀 떨어질 수 있겠네요.. 이건 좀 이상한? 질문이기는 한데 goal 에서 멀어지는 쪽이 오히려 정답일 경우도 있을까요? 즉 단조성이 보이는게 무조건 subgoal 로 분류되지는 않겠지만, 실제 그런 경우가 노이즈를 제외하고 어떤 경우가 있을지 궁금합니다. 아무래도 이미지만으로 그걸 분석하는 것인데 특정 이미지 환경에서는 그런 경우도 있지 않나 해서 질문드립니다.
안녕하세요 인택님, 리뷰 읽어주셔서 감사합니다.
사실 본 논문이 video input으로부터 시각적인 로봇 조작 작업 단위를 의미적으로 분해해보겠다는 것인지라, video 팀 분들이 댓글로 질문 많이 해주시거나 의견주시거나 그래주시길 원했는데, 제가 생각해보지 못한 부분을 인택님이 딱 짚어주셨네요.
음.. 결론적으로 말하면 언급하신 상황이 있을 수 있을 것 같습니다. 무조건 최종 goal 에 가까워지는 temporal 한 visual embedding 변화가 있을거다라라는 전제에 허점이 있을 수 있는게, 최종 goal에서 멀어지는 embedding 표현을 가지면서 단조성을 갖고있다가도, 조명변화나 배경 내의 동적인 물체가 갑자기 침투한다던지 등의 scene 내의 예상치 못한 동적변화에는 subgoal이 아님에도 단조성이 깨지는 상황으로 볼 수 있을 것 같습니다. 아니면,,, 음 최종 goal로 가는 와중에 장애물을 꼭 피해서 머얼리 돌아가는 행동이 subgoal이어야만 할때도 비슷한 문제로 생각될 수 있을 것 같네요. 정말 visual embedding의 ’단조성이 깨지는 부분’이 subgoal이라고 하는 것이 맞냐? 에 질문에 대한 허점을 잘 여쭤보신 것 같아요! 이 부분의 알고리즘을 개선하는 것도 아마 future work가 될 수 있지 않을까 생각합니다!