안녕하세요, 이번 X-Review 로 DETR 논문을 가져왔습니다.
저번 ViT 는 Image classification 을 목적으로 Transformer를 응용하였는데요, 이번 DETR은 Object Detection을 목적으로 Transformer 를 사용합니다. 다만 완전히 트랜스포머만 사용하는 것은 아니고 큰 차이점으로 CNN feature map을 사용한다는 점과 이미지를 패치 단위로 나누지는 않는다는 차이점이 있겠네요. 물론 논문의 제목처럼 트랜스포머를 사용하면서 NMS 없이 end-to-end로 OD 를 해낸점을 저자는 논문에 여러번에 걸쳐서 언급합니다. 제가 기초교육을 팔로우업하면서 원복해볼 OWL_ViT에 DETR 에 쓰인 방식이 많아서 이번리뷰 작성하게 되었습니다.
Abstract.
DETR 저자는 Detection pipeline을 hand-designed 요소 없이 구성하게 됩니다.
hand-designed된 요소는 NMS 나 anchor 같은 설계들을 말합니다.
Transformer 의 encoder-decoder 구조를 거의 그대로 사용하고 학습된 object query를 통해 예측을 수행하게 됩니다.
그리고 set prediction 이라는 개념을 도입하는데, 이는 간단히 말하면 예측 결과를 순서가 없는 집합(set) 으로 보고 GT와 1대1 매칭이 되도록 하는 것입니다. 이러한 최적의 permutatoin(순열) 을 헝가리안 매칭을 통해 찾게됩니다.
COCO 데이터셋에서 기존 Faster R-CNN 과 비슷한 정확도와 효율성을 달성한다고 어필하고있습니다. 동일 구조로 panoptic segmentation에도 확장이 가능하며 경쟁 모델들보다 우수하다고도 합니다.
Introduction
OD의 목표는 물체의 Bbox와 label 을 예측하는 것입니다. 해당 논문이 나오기 이전 Detector 들은 이러한 OD 의 목표를 indirect way로 설정했다고 주장하는데, 이는 앞서 언급한 NMS나 anchor box를 이용한 인간의 사전정보가 들어간 접근법들을 사용한 것입니다.
저자는 이러한 휴리스틱한 방법론들 없이 end to end로 해결했다고 말합니다.
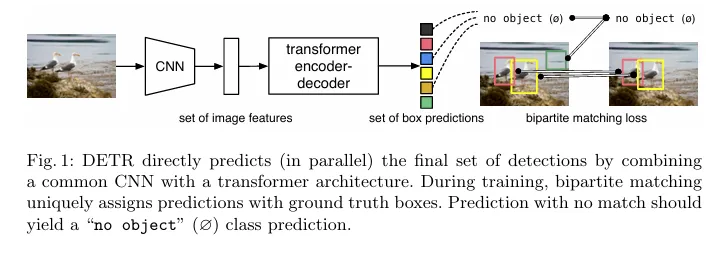
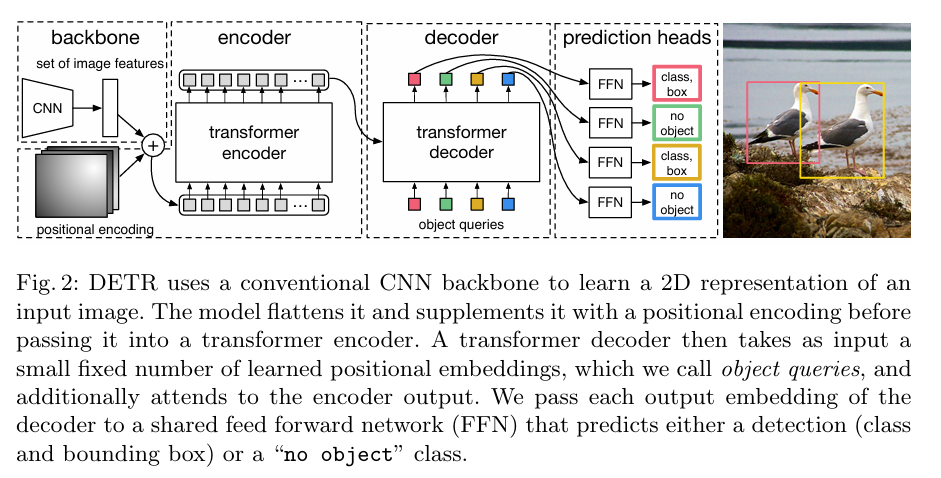
DETR의 구조로 사실 전체 방법론은 이 도식도 하나로 전부 이해할 수 있을만큼 매우 간단합니다. 일반적인 CNN 의 결과를 Transformer에 넣고 최종 detection 결과는 병렬적으로 나오게 됩니다. 훈련시에는 예측박스와 정답박스를 1대1 헝가리안 알고리즘을 이용하여 매칭하고, 예측하는 prediction 수는 100개로 고정되어있다고 합니다. 만약 5개의 object가 이미지에 존재한다면 95개의 prediction은 “no object” 로 학습하게 됩니다.
저자의 bipartite매칭 (헝가리안 알고리즘을 사용한 매칭) 은 이전 결과와 상관없이 병렬적인 예측이 가능한데, 이는 예측과 GT의 1대1 매칭을 보장함으로써 GT의 순서와 상관없이 같은 결과가 나오게 하는 것입니다. 이러한 특성을 permutation invariance 라고 합니다.
저자는 DETR이 다른 customized layers 들을 필요로하지 않기 때문에 CNN 이나 Trnasformer를 가지고 있는 프레임워크에서 쉽게 재가공할 수 있다고 합니다.
결과적으로 Faster R-CNN 에 견주는 성능을 냈는데, Big object 에 대해서는 더 좋은 성능을, small object에 대해서는 더 안좋은 성능을 보였다고 합니다. 이를 Transformer의 non-local적 특성 때문이라고 주장하며 Faster R-CNN 이 RPN 같은 구조로 small object에 대한 성능 개선을 이루어낸 점으로 저자의 모델도 비슷한 방식으로 좋은 성능 개선을 이루어낼 수 있을거라고 합니다.
저자의 Transformer Decoder 에서는 auxiliary loss 라는 것을 사용하여 Decoder의 최종예측 뿐만 아니라 중간중간 예측의 손실들도 추가하여 loss를 구성합니다.

The DETR model
Object detection set prediction loss
DETR은 N개의 고정된 예측을 하는데, N 은 일반적으로 한 이미지 내에 있는 objects의 숫자보다 크게 설정했다고 합니다. ( 100개)
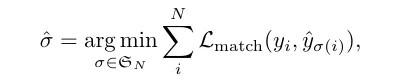
σ̂ 부분은 N개의 예측을 정답에 대응시키는 최적의 permutation 입니다. 즉 어떤 예측이 어떤 GT를 맞출지를 결정한다고 생각하시면 됩니다.
Lmatch 부분은 i번째 GT 객체와 매칭된 예측과의 matching cost이며 각 yi 는 class와 bbox위치로 표현됩니다.
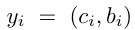
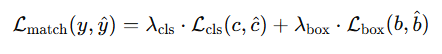
여기서 Lcls 는 class prediction과 GT 간의 Cross-entropy loss이며 Lbox는 bouding box의 L1 loss + GIoU 입니다. ( GIoU 에 대한 개념은 궁금하시면 찾아보면 좋을 것 같습니다.)
정리하면 모든 class와 bbox의 cost를 최소화하는 순열조합을 찾고 해당 시그마햇의 각 예측들로 실제 loss를 업데이트하게 됩니다.
DETR architecture
Backbone
입력 이미지로는 일반적인 RGB 이미지를 사용합니다.
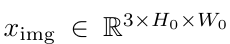
CNN 을 이용하여 feture map f ∈ ℝᶜ×H×W 추출합니다.
C = 2048, H×W = H₀/32 × W₀/32 (ResNet-50/101의 경우)
Transformer encoder-decoder
CNN의 출력채널(C) 가 너무 크기 때문에 1X1 conv 로 차원을 d로 줄여줍니다.
이후 feature map (z₀ ∈ ℝᵈ×H×W)을 1D 시퀀스로 (z₀ ∈ ℝᵈ×(HW))flatten시켜줍니다.
이는 transformer 의 input을 1D로 넣어주기 위함입니다. 여기에 positional encoding을 더한 후 인코더에 넣어주게 됩니다.
트랜스포머의 Decoder에는 Object query라는 객체의 위치를 추측하도록 학습되는 100개의 학습가능한 query가 있습니다. 트랜스포머 encoder 의 출력으로 key value 를 구성하여 이용합니다.
Query = Object Queries ((B, 100, d_model))
Key = Encoder Output ((B, 2048, d_model))
Value = Encoder Output ((B, 2048, d_model))
이 decoder의 output을 가지고 FFN을 이용합니다.
FFN
DETR 의 최종 예측부분으로 ReLU 함수가 들어간 3-layer MLP 와 linear layer로 구성되어 있습니다. MLP 는 bbox의 좌표를 normalized 형태로 예측하고 linear layer로는 softmax로 class 확률을 예측합니다.
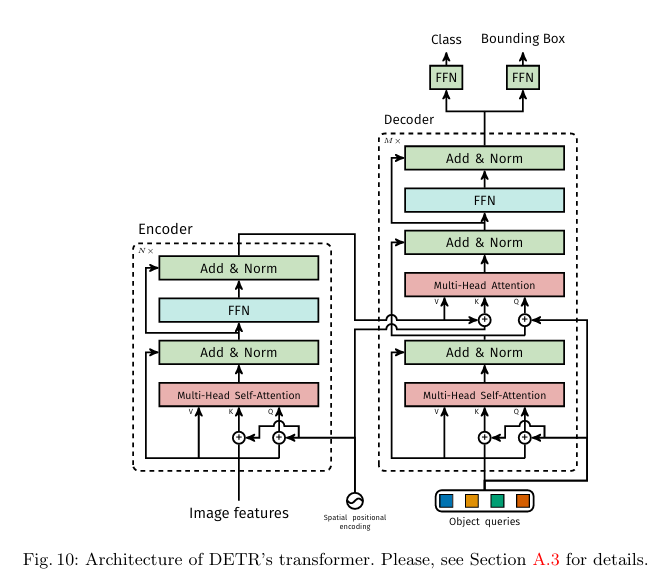
아래 최종 도식도입니다.
Experiments
저자는 COCO dataset으로 평가를 진행하였는데 앞서 말했듯이 Faster R-CNN과 유사한 성능을 보였다고 합니다.
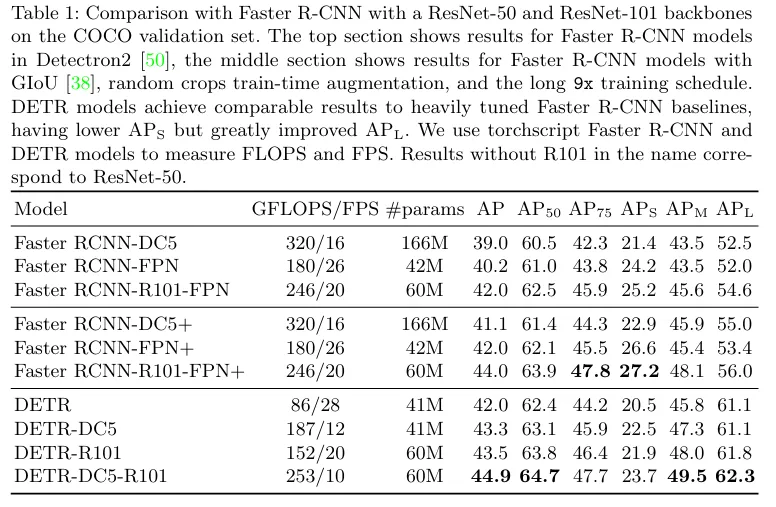
위 3개는 Faster R-CNN 구조를 나타내며
DC5 는 feature map의 해상도를 늘리기 위한 stride효과를 제거한 버전,
FPN을 적용한 버전,
ResNet101 버전이 있으며, 나머지는 ResNet50을 사용했다고 합니다.
중간의 3개는 저자가 설정한 GIoU를 Loss로 설정하였을때 Faster R-CNN 에서 각각 얼마나 성능이 올랐는지를 보여줌으로써 아래의 DETR의 변인통제를 한 모습입니다.
아래 4개는 저자의 DETR이며 베이스라인에서는 인코더와 디코더 모두 6개, attention head는 8개를 사용하였습니다.
저자의 DETr이 APL 즉 큰 객체는 7.8 더 높은 수치이지만 작은 물체인 APs 에서는 -5.5인 수치를 보여줍니다. (논문 상 내용이며 해당 표에는 7.8 더 높은 수치가 존재하지는 않습니다.. 다른 표들에서도 7.8 더 높은 수치는 찾을수 없네요)
Ablation study
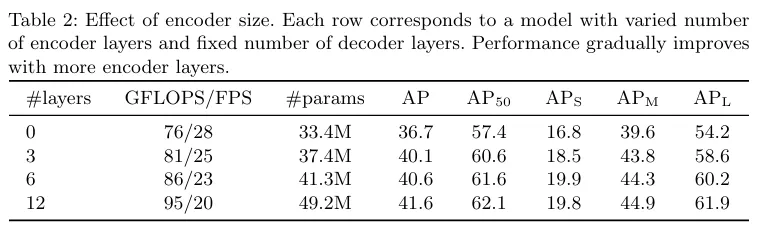
저자는 Decoder 개수는 고정하고 Encoder 개수를 늘려가면 성능이 올라가는 ablation table을 보여줍니다. 저자는 fig3로 encoder가 객체를 분리하는데에 중요한 역할을 하고 있다고 주장하는데 해당 그림은 인코더의 마지막 attention map을 시각화한 것입니다.

인코더는 디코더에 들어가기 이전에 이미 객체들의 위치에 대한 정보를 어느정도 추출하고 있습니다. 특히 APL 성능이 encoder 개수에 크게 영향받는 것을 알 수 있습니다.
(물론 APL 성능이 APm APs 보다 꽤나 높아서 영향받는 폭이 크다고 생각합니다.)
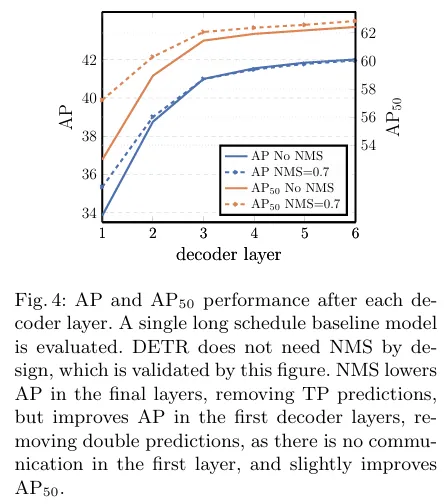
디코더 개수에 따른 AP 예측 성능입니다. 첫번째 layer만 NMS를 적용한 버전이 더 나은 성능이며 나머지는 얼추 비슷한 성능이 나옵니다. 저자가 생각하는 이유는 첫 레이어에서는 아직 객체를 double로 예측하는 경향이 있지만 decoder를 거치면서 자연스레 NMS를 적용한 버전과 갭차이가 줄어든다고 합니다. 6개로 가면 NMS를 적용하면 TP를 제거하는 경향이 생긴다는 것으로 보아, NMS없이 하는 것이 결과적으로 더 좋다고 볼 수 있습니다.

해당 사진은 Decoder attention이 집중하는 부분으로, 객체들의 말단부위인 것을 알 수 있습니다. 이미 인코더에서 각 객체의 분리를 어느정도 마쳤고, decoder 단에서는 더 세부적인 특징들을 파악하는 것으로 저자는 해석했습니다.
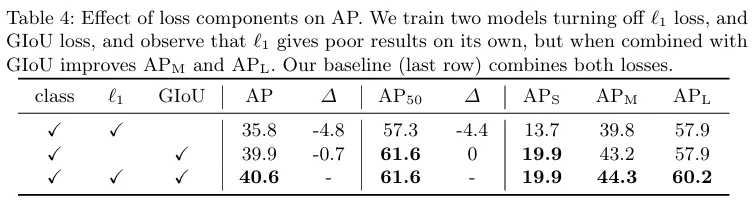
저자는 L1 Loss, GIoU Loss 에 대한 ablation도 진행하였습니다.
해당 표를 보면 L1 Loss 는 GIoU가 적용된 상태에서 적용되어야 올바르게 거리에 대한 손실을 반영해주는 것을 알 수 있습니다. 스케일적인 문제를 GIoU가 해결해줘야 L1 Loss도 올바르게 작동한다고 볼 수 있습니다.

Decoder output slot analysis
저자는 Decoder의 각 slot이 서로 다른 객체사이즈를 집중적으로 학습한다고 주장합니다. 그리고 COCO dataset의 특성을 반영하여 모든 slot이 공통적으로 large image-wide boxes를 예측하고 있다고 분석합니다. 즉 데이터셋의 분포에 따라 각 object query 들이 올바르게 여러 객체를 탐지하고 있다고 볼 수 있습니다.
DETR for panoptic segmentation
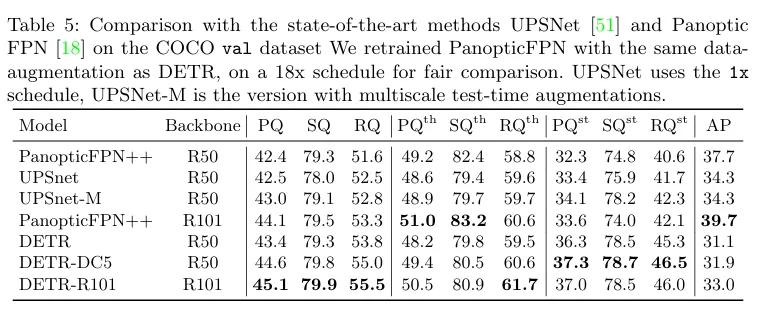
단순히 Decoder outputs에 mask head를 더함으로써 DETR이 panoptic segmentation이 가능하다고 합니다. DETR을 먼저 OD task로 사전학습 시킨 후 mask head를 더해 mask head부분만 학습시키는 것으로 해당 분야의 SOTA 버전과 성능비교를 했습니다.
Decoder 의 output이 객체의 정보를 담고 있으므로, mask prediction head에 넣고, CNN의 feature와 결합하여 pixel 단위의 attention map을 만듭니다.
OD task만 수행할땐 FPN이 필수적이지는 않았으나, 이런 세부 task로 넘어갈때는 pixel 단위로 예측해야 하므로 FPN 을 적용한 버전이 spatial resolution이 좋아 성능이 더 좋았습니다.
PQ는 SQ와 RQ를 모두 고려한 panoptic segmentation에서의 기본적인 평가지표입니다. 해당 지표들을 th, st로 나누는데, 명확한 객체들을 things , 하늘이나 도로처럼 배경은 stuff 로 표현되어 있습니다.
SQ는 TP에 대한 IoU 를 평균낸 값으로 얼마나 정확하게 객체를 맞추었는지 이며,
RQ는 단순히 얼마나 객체를 잘 찾았는지에 대한 score 입니다.
Conclusion
DETR은 transformer와 bipartite matching을 이용한 최초의 Object detection 모델입니다.
hand-craft된 NMS 같은 것들을 사용하지는 않았으나, 결국 Object query라는 지정된 개수의 예측을 해야하는 것이 기존의 NMS와 아다르고 어다른.. 그런게 아닌가 싶기도 하지만, 해당 논문에서 NMS 를 적용한 버전과의 ablation도 존재함으로 더 나은 방법을 제시한 것도 없지않아 있는 것 같습니다. 무엇보다 간단한 구조로 구현이 간단하고 다른 task 로의 확장성이 뛰어나 이후 후속 연구가 되게 많은 것으로 알고 있습니다.
리뷰 읽어주셔서 감사합니다.
좋은 리뷰 감사합니다. 논문에서 다루는 내용을 모두 잘 짚어주신 것 같습니다. 질문이 있는데요 100개의 Object query는 초기에 어떤 값을 갖는지 궁금합니다.
감사합니다!
안녕하세요 지연님, 질문에 답해드리자면
100개의 object query는 무작위 초기화 됩니다. 무작위로 초기화된 값들이 이미지들과 cross attention 을 거쳐 잠재적으로 객체가 존재할 곳과 하나로 매핑하려고 학습합니다.
안녕하세요 연구원님.
간단한 질문 하나남깁니다.
CNN output vector를 transformer encoder-decoder에 거치게 하는데
디코더에서 N개의 예측은 구체적으로 어떻게 수행되나요?
안녕하세요 우진님 질문에 대해 답변을 드리자면
우선 encoder 부분은 transformer 의 인코더와 거의 똑같다고 보면 됩니다. 단지 이미지를 flatten 시켜서 각 self attention 을 구한 것이고, 여기에 positional encoding이 추가되어있습니다. 이후 decoder 부분에서는 이미지의 어떤위치에 객체가 존재하는지 예측할 Object query 가 N개 존재하고 이를 query로 서 사용하며 encoder의 output을 key,vlaue 로서 서로 cross attention을 적용하게 됩니다. 이때 각 Object query 들은 이미지 내의 어디를 집중적으로 봐야할지를 각각 학습하게 되며 이후 FFN head를 통해 bounding box의 직접적인 위치를 학습한다고 생각하시면 됩니다.
안녕하세요 인택님!
이번에도 제가 궁금했던 논문을 감사하게도 이미 리뷰해주셔서 읽어보게 되었습니다!
읽다가 간단한 질문이 생겼는데 혹시 트랜스포머의 특징이 병렬연산이 OD task에서는 어떻게 사용이 되나요? LM에서는 주로 언어토큰의 임베딩 벡터가 병렬로 transformer에 들어가게 된다면 , CNN을 통과한 이미지 피처는 채널을 1D로 만들어서 채널 상으로 flatten된 HxW의 픽셀(벡터)들이 transformer로 들어가게 된다고 이해하면 될까요?
안녕하세요 찬미님 답글 감사합니다.
질문하신게 CNN 을 통과하고 나온 image features 가 transformer에 어떤 방식으로 입력되는지라면 DETR에서는 해당 feature 를 패치단위로 나눈 후 해당 패치를 flatten 시켜서 입력으로 들어가게됩니다.
즉 [batch, patch(H X W), d_model] 형태의 입력으로 들어간다고 생각하면 되겠습니다.
감사합니다.
안녕하세요 인택님 좋은 논문 리뷰 감사합니다.
저번주에 maskformer에 대해 찾아볼 일이 있었는데, 자주 DETR이 자주 언급되어 찾아보게 되었습니다.
patch 단위로 분할하여 attention 연산을 진행하는 transformer 방식만 알고 있었는데
CNN의 feature map을 이용하는 transformer을 이용하는 아이디어가 신기해 재밌게 읽었습니다.
읽고 든 의문점은 attention 연산을 줄이기위해 1/32 크기의 feature map을 사용하는 것으로 이해했습니다.
그런데 SSD 같은 detector가 여러가지 feature map을 전부 이용해서, 다양한 크기의 객체를 잘 잡는 것에 반해
고정된 하나의 크기의 feature map만 사용하면, 다양한 크기의 객체를 탐지하기도 힘들고
유용한 feature map을 날리는게 아닌가 하는 생각이 들었습니다.
혹시 논문에서 해당 부분에 대해 언급하거나, 해결한 방법이 있나요?
안녕하세요 정우님 답글 감사합니다.
말씀하신대로 DETR 은 backbone의 최종 feature map 만 transformer에 넣기 때문에 다양한 스케일의 feature들을 활용하지 못한다는 한계점이 있습니다. 이를 작은 객체에 대한 탐지 성능이 떨어진다고 논문에 언급하고 있는 것입니다. 해당 논문에서는 단지 한계점이라고만 언급하며,
후속연구인 deformable DETR 같은 경우 FPN 등을 이용하여 여러 해상도의 feature map 을 사용하는 등 작은 객체에 대한 성능 개선이 이루어지긴 했습니다.
감사합니다.