이번에 리뷰로 작성할 논문은 CVPR2025에 게재된 논문으로 네이버 AI Lab에서 작성한 논문입니다. self-supervised learning에서 자주 소개되었던 Masked Image Modeling을 supervised learning framework에 적용하였을 때의 문제점을 다루고 해결한 것으로 방법론 자체가 복잡하지는 않으니 가볍게 읽기 좋은 듯 합니다.
Intro
지도학습은 당연히 잘 아시다시피 입력 x에 대한 label y가 존재하여 x에 대한 y를 모델이 예측하고 이를 정답 y와 비교하는 방식으로 학습이 진행되는 것입니다. 하지만 수백만, 수천장 데이터에 대하여 x에 대한 label y를 annotation하는 것에서는 너무 많은 cost가 들기 때문에, 10년도 후반부터 20년도 초반까지 pretext task라는 것을 정의하여 입력 x만으로 모델을 학습하는 Self-supervised learning 연구가 꾸준히 등장했습니다. 그리고 이러한 self-sup 연구는 DINOv2와 같이 다양한 vision task의 foundation model 내 backbone 역할을 수행하는 괴물?같은 모델을 만드는데 기여를 하게 됩니다.
이러한 내용들은 DINO, MAE와 같은 self-sup paper 들을 조금 관심있게 보셨다면 쉽게 알고 있는 내용이라고 생각합니다. 이번에 리뷰하는 논문은 이러한 흐름 사이에서 Masked Image Modeling에 조금 더 초점을 맞추어 문제를 정의합니다.
논문에서 이야기하는 문제 정의는 다음과 같습니다. 20년대 초반 ViT라는 백본이 supervised/ self-sup 연구 분야에 등장하기 시작할 무렵, ViT를 지도학습하였을 때 성능은 그리 만족스럽지 않았습니다. CNN과 달리 ViT는 inductive bias가 부족하다고 평가되었기 때문에 CNN과 비슷한 양의 데이터로 학습할 경우 그 성능이 CNN과 유사하거나 오히려 더 떨어지는 결과를 보여주었기 때문이죠. 즉 generalization performance가 부족하다는 평가를 받았고 이를 보완하기 위해서는 ImageNet 수준보다 더 많은 JFT 데이터셋 같은 완전 대용량 데이터로 학습을 해야만 했었습니다.
그러나 22년도쯤?에 ViT에 최적화된 self-supervised learning 기법인 Masked Image Modeling(MIM)을 적용한 self-sup 사례가 등장하면서(Masked AutoEncoder) ViT의 supervised 성능은 물론 SOTA CNN의 성능도 위협할만한 결과물들이 등장하기 시작했습니다.
이러한 MIM 방식은 쉽게 이야기해 입력 영상에 랜덤하게 masking을 하고 모델이 이 마스킹된 영역을 원본과 동일하게 reconsturction하도록 학습하는 것을 의미합니다. 이때 마스킹하는 영역의 수준은 보통 50%에서 많으면 75%정도까지 마스킹을 하는 것이 성능적으로 좋다고 MIM 연구들이 주장합니다. 즉 MIM이 좋은 성능을 보여주려면 높은 수준의 마스크 비율을 채택해야한다는 점이죠.
하지만 이러한 높은 수준의 마스크 비율이 모델 학습에 좋은 영향을 준다는 것은 자기지도학습 framework에서만 통했던 흐름으로, 지도학습 framework에서는 이러한 높은 마스크 비율이 모델 성능에 좋은 영향을 미치지는 못했습니다. 갑자기 자기지도학습 이야기하다가 왜 지도학습으로 넘어왔지?라고 생각을 하실 수 있는데, 위에서 설명드린대로 MIM 방식이 결국 입력 영상에 마스킹을 한다는 것이기 때문에 이 마스킹 자체를 data augmentation이라고 생각하시면 좋을 것 같습니다.
즉, 입력 영상에 높은 비율의 마스킹을 해서 모델이 어떠한 결과물을 추론하도록 학습하는 것이 모델 성능에 좋은 영향을 주었다면 이러한 높은 비율의 masking augmentation이 지도학습 framework에서도 좋은 성능을 보여주지 않을까? 라는 것이죠.
근데 실제로는 그렇지 않았다고 합니다. 50%가 넘는 마스킹을 적용할 경우 지도학습에서는 오히려 모델의 성능이 크게 감소하는 경향성을 보였다고 하며, 이는 다른 말로 해서 지도학습은 강한 수준의 마스킹 증강 기법과 어울리지 않는다고 하죠. 저자들은 이렇게 두 학습 방식이 서로 다른 경향성을 보여주는 것에 대하여 현존하는 지도학습의 학습 과정 자체에 큰 문제가 있다고 주장합니다.
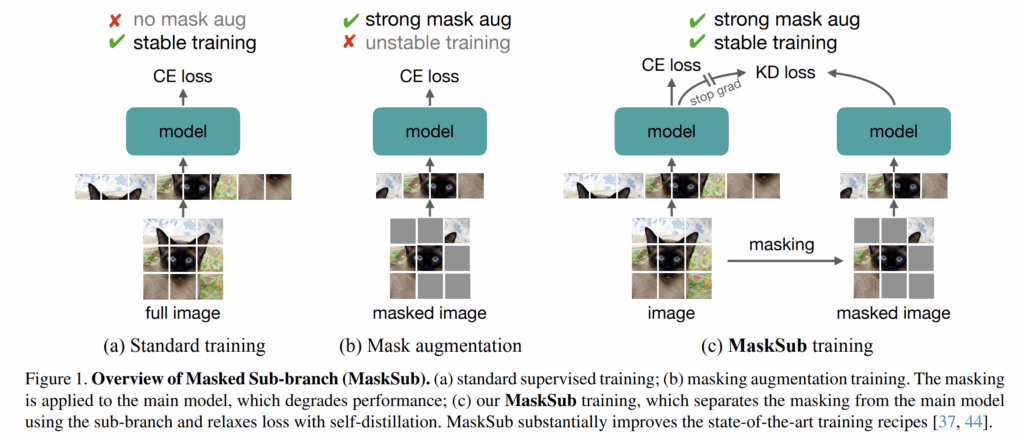
그래서 저자들은 지도학습에서 50%가 넘는 수준의 mask augmentation을 적용하여서 모델의 성능을 높이는 것을 논문의 목적으로 설정합니다. 그 결과 저자들은 main branch와 별개로 sub-branch를 나누어 해당 branch에서 mask augmentation과 관련된 학습 과정을 거치는 새로운 framework을 제안하였다고 하죠 (이를 MaskSub라고 저자들은 명칭합니다.)
근데 사실 여기까지 내용만 보면 좀 의문이 많이 들긴 합니다. Self-supervised learning이 annotation하는 비용도 안들어서 supervised learning보다 더 매력적으로 다가오는 framework인데 굳이 self-sup에서 잘 동작했다는 masking 기법을 supervised learning에 적용하려고 노력하는거지? 라는 생각이 들었습니다.
제가 CVPR에서 직접 저자분과 이야기했을 때 얘기로는 supervised learning과 self-supervised learning이 학습에 사용되는 모델도 같고, 학습 데이터도 같은 경우가 많다보니 실험 세팅이 거의 유사하다고 생각할 수 있는데 실제로는 하이퍼파라미터 종류도 서로 다르고 동일 종류 내에서도 그 값이 서로 상이하기에 결코 같은 framework으로 볼 수 없다? 라는 식으로 이야기하셨던 것 같네요. 쉽게 말해서 self-sup 연구로 작성된 코드에 그냥 dataloader 깔짝 바꾸어서 label y값만 불러오고 목적 함수 바꾸면 바로 supervised learning으로 학습할 수 있다는게 아니라는 것이죠.
그리고 MIM 기반의 self-sup framework 자체에도 사실 문제가 없는 것은 아닙니다. 높은 비율로 영상에 마스킹을 적용하는 것 자체로 인하여 모델이 활용할 수 있는 정보가 많지 않습니다. 이로 인해 모델의 학습 자체가 불안정하는 경우가 흔하게 발생한다고 합니다. 반대로 지도학습 같은 경우에는 output과 곧바로 비교할 수 있는 정답 GT가 존재하기 때문에 명확한 학습 신호를 줄 수 있다는 점에서 학습 안정성만큼은 확실하다고 볼 수 있어요.
결과적으로, 저자들은 지도학습의 안정적인 학습 신호를 가져가면서 (stable training) 동시에 mask augmentation을 기존 supervised learning에 성공적으로 이식함으로써 generalization performance까지 함께 향상시키는 연구를 진행하고자 하였다고 하네요.
Method
우선 저자들이 제안하는 Masked Sub-branch 구조에 대해서 알아보겠습니다. 일반적으로 이미지 분류에서 지도학습의 과정은 아래 수식 1처럼 나타낼 수 있어요.
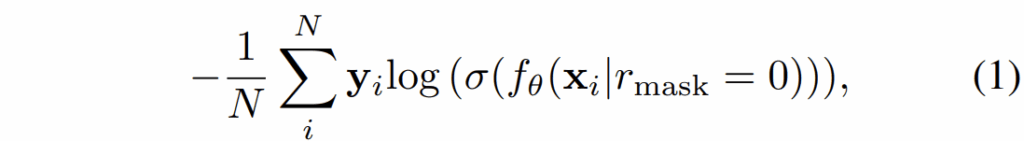
여기서 시그마 함수는 softmax를 의미하고 f_{\theta} 는 백본을 포함한 분류 모델을 의미합니다. 그리고 입력에 마스킹이 되어있다는 것을 함께 표현하고 있는데 r_{mask} 의 값이 0인 경우는 마스크 비율이 0%로 마스킹이 전혀 안된다는 것을 의미한다고 보시면 됩니다.
즉 만약 마스킹 augmentation을 취하게 된다면 아래 수식으로 표현할 수 있는 것이며, 이때의 r 값은 0~1 사이의 범위를 가지게 됩니다. 즉 1이 되면 입력 영상 전체에 대해 100%로 마스킹한다고 이해하시면 됩니다.
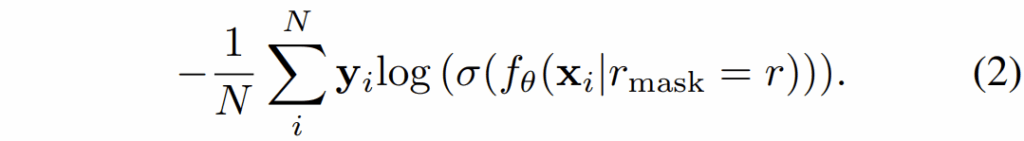
저자들은 실험적으로 수식2를 통해 모델을 (지도)학습시킬 때, 마스크 비율을 0.5 이상으로 하게 될 경우 상당한 학습 불안정성과 낮은 성능을 달성했다고 합니다. 저자들은 마스킹을 통해 학습이 안정적으로 흘러가게 하기 위해 knowledge distillation과 유사한 방식을 채택하여 모델을 학습시키려고 했습니다.
즉 모델의 softmax타고 나온 output 값을 label y와 cross-entropy loss 계산하는 것이 아니라 아래 수식3과 같이 마스킹이 안되었을 때의 soft-label과 마스킹된 입력으로 추출한 soft-label 사이에 cross-entropy loss를 계산하는 것이죠.
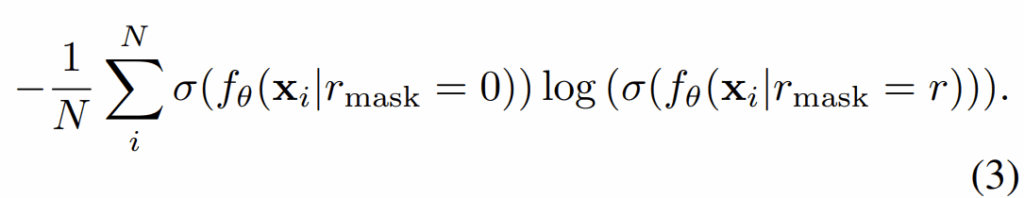
저자들은 기존의 지도학습인 수식1과 soft-label로 계산한 loss 3을 반반씩 평균하여 모델을 학습시켰다고 합니다. 여기서 마스킹 비율이 0인 입력을 처리하는 네트워크 브랜치를 main-branch로 지정하였으며, 마스킹이 r 비율만큼 적용된 영상을 처리하는 네트워크 브랜치를 sub-branch로 지정하였습니다.
그리고 수식 3에서 마스킹이 0인 입력을 토대로 만들어낸 soft-label에는 stop gradient를 설정하여서 하나의 pseudo label로써의 역할을 수행하도록 하였습니다. 즉 sub-branch는 main-branch를 모방하는 형식으로 모델을 학습하고, 메인 브랜치는 sub-branch의 결과와는 별개로 독립적인 지도학습을 하는 방향으로 진행이 되는 것이죠. 아래는 위에 설명에 대한 수도코드를 나타낸 것으로 매우 직관적이면서 단순하다는 것을 알 수 있습니다.

Analysis
방법론 자체는 사실 위에가 끝입니다. 원래 self-sup 논문들이 method 자체는 그리 복잡하지는 않아서 그런가 해당 논문도 self-sup 논문은 아니지만 MIM을 메인으로 하는 연구다보니 방법론이 매우 단순하게 끝나고 말았네요.
대신에 그만큼 이러한 논문들은 실험 분석을 철저하게 해야한다는 점이 존재합니다. 저자들도 이와 관련해서 다양한 실험들을 진행하는데 우선 실험에 사용되는 세팅부터 간단하게 설명하고 넘어가겠습니다.
모델은 ViT-B를 사용하고 방법론에서 소개한 loss들을 통해 100에포크 정도를 ImageNet-1K 데이터셋에서 학습합니다. 해상도는 224×224를 사용하는 모습이고, 우선 3가지 실험 세팅을 비교한다고 합니다. standard는 수식1만을 사용하는 오리지널 supervised learning을 의미하고, masking은 수식1과 수식2를 합쳐서 학습하는 방식, 마지막으로 mask-sub는 자신들이 제안하는 수식3을 수식1과 합쳐서 학습하는 방식을 의미합니다.
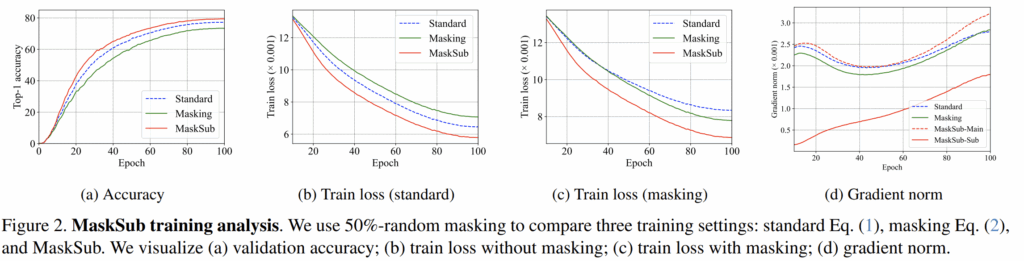
실험 결과는 그림2와 같은데, 우선 정확도 측면에서 자신들이 제안하는 MaskSub가 거의 모든 에포크에서 항상 좋은 모습을 보여주는 모습이고, 학습 초반부터 성능 향상폭이 큰 점을 보아 학습 수렴이 빠르다는 것을 확인하실 수 있습니다.
그리고 단순히 Masking해서 수식2를 통해 학습하는 방식은 기존의 standard보다 더 정확도가 떨어지는 모습을 확인하실 수 있으며, 2번째 그림에 loss 자체도 항상 standard보다 높은 것을 보아 지도 학습 대비 학습 수렴이 잘 안된다는 것을 확인하실 수 있습니다.
그림2의 d 같은 경우는 메인 브랜치와 서브 브랜치 사이에 학습 패턴을 확인하고자 나타낸 그래프라고 합니다. 우선 메인브랜치에 대한 기울기 크기 값(즉 MaskSub-Main)이 다른 학습 기법(Standard, Masking)과 유사한 형태와 크기 값을 가지고 있는 반면에, 서브 브랜치에 대한 기울기는 초기 학습 단계에서 작은 값을 가지고 있는 모습입니다.
이것은 MaskSub가 네트워크를 학습시킬 때 자동적으로 어려움을 통제하기 때문이라고 합니다. 초기 학습 단계 동안에는 메인 브렌치로부터의 기울기값들이 학습을 전반적으로 이끌어나가지만, 점차 학습이 진행되면서 서브 브랜치의 그레디언트 강도가 서서히 증가하면서 학습의 전반적인 흐름을 같이 이끌어나가고 있다고 볼 수 있는 것이죠.
즉, 저자들은 그림2의 d 경향성이 학습 초기에 서브 브랜치에서의 학습 과정이 매우 어려워 모델이 이 부분에 대한 집중을 하지 않지만, 원본 영상으로부터의 학습이 충분히 진행되고 난 일정 시점 이후부터는 서브 브랜치를 통해서 학습에 도움이 되는 부분들을 취하는 과정이라고 주장합니다.
Expand to drop regularization
여기까지만 하고 넘어가면 논문이 다루는 내용이 너무 단순해서인지 저자들은 MaskSub와 유사하게 DropSub와 PathSub라는 framework도 함께 만들어서 실험을 진행합니다. 쉽게 말해서 마스킹이라는 과정이 입력 데이터에 정보를 모델이 못보도록 하는 것이고, dropout과 droppath는 모델의 일부분을 forward 과정에서 사용하지 않는 것이니 마치 입력을 가릴래 모델을 가릴래?와 같은 느낌으로 볼 수 있는 것이죠.
그래서 이러한 dropout과 drop path가 적용되는 branch를 sub-branch로, 적용하지 않는 branch를 main branch로 나누어서 동일하게 실험을 진행하는 것으로 보여집니다. 물론 정확히는 main branch에서 drop path가 사용되기는 합니다만 메인브랜치는 서브 브랜치와 달리 높은 확률 값으로 drop path가 적용되는 것이 아니라는 점을 말씀드립니다.
Experiments
바로 위에서 drop regularization에 대해서 이야기를 했으니 해당 실험부터 먼저 말씀드리겠습니다.

저자들은 Deit3를 400에포크로 학습시켰으며, masking의 경우 비율이 50%, dropout은 0.2, drop-path는 baseline이 사용한 기본 값에 +0.1 추가하여 학습시켰다고 합니다. 결과적으로 모든 Sub 방법론들이 베이스라인보다 더 좋은 성능을 보여준 것은 맞다고 합니다. 그치만 그 중에서도 저자들이 메인으로 끌고 나가는 MaskSub가 가장 좋은 성능을 보여주었다는 점이며, 또한 MAE에서 제안하는 연산 과정을 채택했기 때문에 학습에 사용하는 코스트 역시 다른 Sub들보다 더 효율적이라고 하네요.

다음은 scratch 레벨에서부터 학습하였을 때의 성능을 나타낸 것으로, DeiT-3 방식으로 학습한 receipe에 자신들의 masksub framework을 적용하였을 떄의 성능 향상을 보여줍니다.
재밌는 점은 ViT-B, L, H에서 모두 MaskSub를 붙였을 때의 400 에포크 기준 성능이 기존 DeiT-3의 800 에포크 기준 성능보다 더 높다는 점입니다. 즉 MaskSub를 통해서 학습시켰을 때 더 빠르게 모델이 수렴해서 높은 성능에 달성할 수 있다는 점이죠. 반대로 아쉬운 점은 수렴이 빨라서인지 학습을 많이 시켰다고 해서 성능 기대치가 더 높아지고 그러지는 않는 듯 합니다.
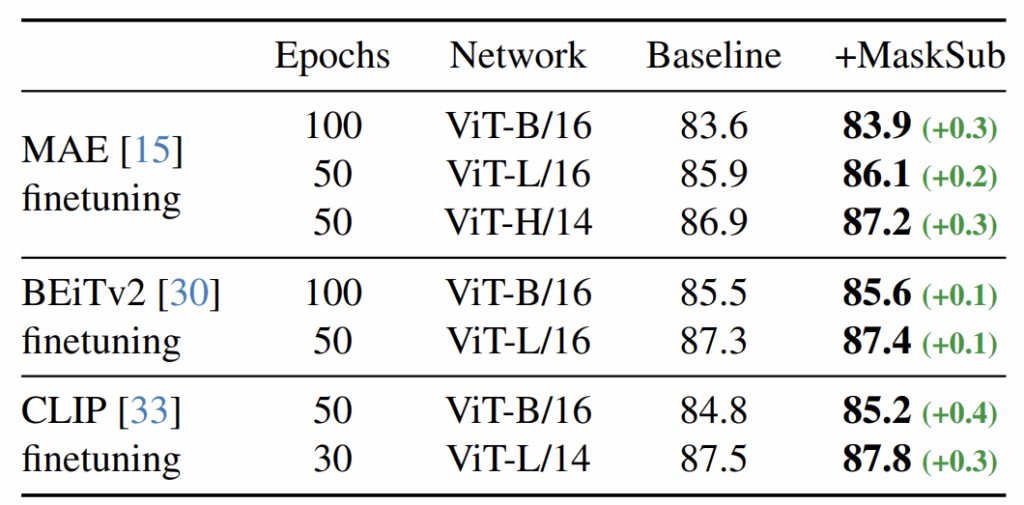
다음은 이미지넷 1K 데이터셋에 대하여 fine-tuning하였을 떄 MaskSub 적용 여부에 대한 성능을 나타낸 것입니다. 사실 MaskSub의 근본적인 아쉬움은 결국 학습에 Label이 필요하다는 것이거든요? 즉 지도학습 세팅에 대해서만 사용할 수 있다는 점입니다.
물론 자신들이 지도학습 프레임워크에서 왜 고수준의 마스킹이 적용될 경우 성능이 오히려 감소하는가에 대한 문제를 풀고 싶어서이기 때문이라지만, 그럼에도 지도학습에서만 적용 가능한 framework이라는 것은 아쉬울 따름이죠. 하지만 결국 self-sup 연구들도 pretraining을 잘 마치고 나서 이 모델의 feature representation이 얼만큼 좋은지를 보기 위해 classification, detection, segmentation과 같은 task에서 fine-tuning한 성능을 보여주긴 합니다.
이 단계에서 저자들이 제안하는 framework를 적용하여 성능을 높일 수 있다고 저자들이 어필하고자 위에 실험들을 준비한 것으로 파악됩니다. MAE와 BEiTv2, CLIP 각각이 각자 사전학습을 마친 후에 ImageNet 1K에 대해서 fine-tuning할 때 자신들의 기법을 적용하면 성능이 미약하게나마 오른다는 것이죠.
근데 솔직히 매력적인 결과인지는 잘 모르겠어요. 특히 BEiTv2의 경우에는 MaskSub 적용 여부에 따라서 0.1밖에 성능 차이가 나지를 않는데 솔직히 저정도면 그냥 랜덤성 차이가 아닌가 싶기도 하네요.
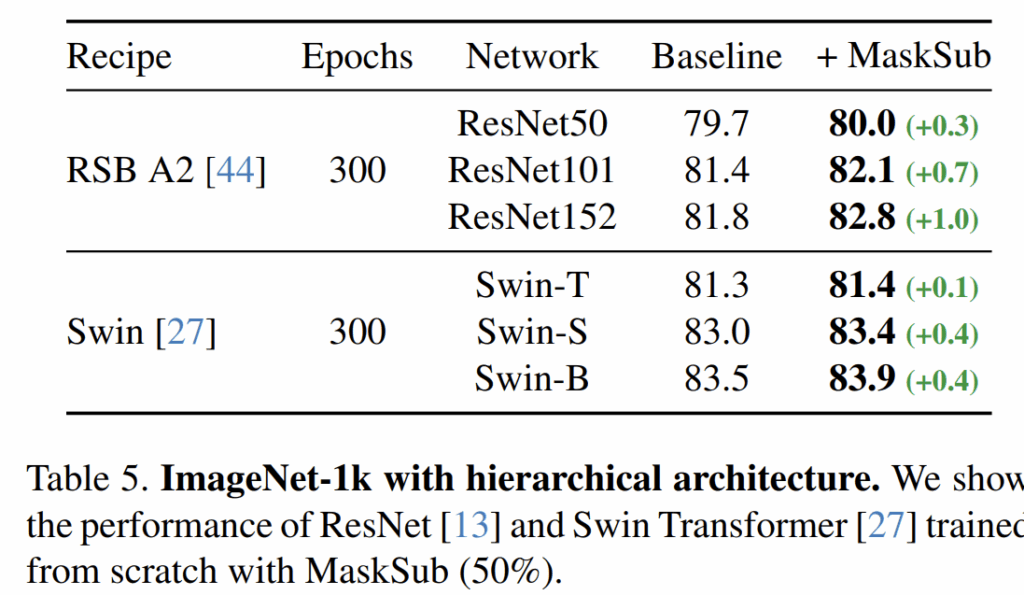
그 외에도 저자들은 Swin Transformer와 같이 계층적 구조의 ViT 또는 ResNet 기반의 구조들에서도 자신들이 제안하는 방법론이 얼만큼의 효과가 있는지를 평가합니다.
결론
CVPR 포스터 섹션을 훑다가 요즘도 Self-sup 연구를 하는구나 싶기도하고 네이버에서 한 연구길래 한번 찾아가서 본 것인데 방법론도 심플하니 첫 인상이 나쁘지 않았던 논문이었습니다. 다만 실제 논문을 읽고 해보니 아쉬운 부분들도 몇몇 존재했던 것 같아요. motivation이 인트로에서 명확히 담겨있어보이지 않고, 본 페이퍼만 보았을 때는 결국 Image Classification만을 다룬다는 점에서 요즘 같이 빠르게 발전하면서 복잡하고 풀기 어려운 task들을 다루는 흐름에 맞지 않는다는 느낌이 들었네요. 아카이브에는 23년 6월쯤에 공개된 것을 보아하니 돌고 돌고 돌다가 마침내 25년 CVPR에 게재된 것 같아 보이는데 논문을 쓰려고 했던 그 시기 기준으로는 논문의 모티브가 좋아보였을지도 모르겠네요.
안녕하세요 정민님 깔끔한 리뷰 감사합니다.
말씀하신 것처럼 약간 지도학습기반으로 다시 회귀하는 점이 장점이자 단점이라고 생각할 수 있을 것 같습니다.
제가 과정중에 든 생각이 맞는지 여쭤보고싶은데, 결국 방법론이 실제정답을 바로 masking 기법을 통해 예측하라고 하면 어려우니 domain gap을 없애기 위해 모델을 통과한 값과 masking 값을 비교해서 해결한거라고 이해해도 될까요?
그리고 지도학습 기반으로 하기 위한 라벨링 코스트를 넘어설만큼의 성능향상이라고 생각할 수 있을까요? 생각이 궁금하여 질문드립니다.
하이요. 우선 질문 중에 하신 “도메인 갭을 없앤다”라는 표현은 조금 모호한 것이 도메인이라고 하는 것의 정의는 다양하겠지만 보통 비전 분야에서 도메인 갭은 학습 때 본 데이터 분포와 평가 때 본 데이터 분포의 차이 같이 어떠한 데이터의 분포를 의미하는 편인데, 해당 논문에서는 똑같은 입력 영상에 마스킹을 했냐 안했냐 여부 차이만 존재하므로, 이 마스킹 기법 적용 여부로 인하여 도메인 갭이 나타난다고 표현하기에는 무리가 있어 보여요.
다시 질문으로 돌아가면, 결국 저자들이 하고자 하는 것은 일반화 성능에 좋다는 마스킹 증강 기법을 학습에 적용해서 주어진 task(classification)와 관련된 목적함수를 줄이는 방향으로 학습해보고자 했는데, 이 학습 방식은 학습 불안정성이 매우 컸다는 것이 문제였고, 이를 해결하고자 “마스킹이 적용 안된 입력의 특징을 pseudo label삼아 KD해주자.” 라고 이해하시면 될 것 같습니다.
그리고 2번째 질문으로 넘어가면, 성능 향상 측면에서는 아쉬움이 많이 남지만 결국 이 방법론은 “지도학습 framework을 사용해야만 한다면 일반화 성능까지 고려해서 성능 개선을 잘 시켜보자”가 주요 관심사이기 때문에 라벨링 비용과 관련해서는 사실 크게 고려할만한 대상은 아니라고 생각합니다. 결국 자기지도학습쪽 논문들과는 풀고자 하는 관심사 자체가 다른 것이기 때문이죠.
그리고 자기지도학습으로 잘 학습된 백본 모델들도 결국 target task에 맞게 fine-tuning 과정을 진행해주어야만 하는데, 이 과정에서 해당 논문의 아이디어를 잘 활용해볼 수도 있기에 관점에 따라서는 타 연구자들에게 많은 도움이 되는 논문이라고 생각합니다.