이번에 소개할 논문은 Video-Text Retrieval 분야에서, 사전학습된 CLIP 모델을 활용한 parameter-efficient adaptation에 초점을 둔 연구입니다. CLIP은 이미지-텍스트 쌍의 alignment에 초점을 맞춰 학습되고, Video-Text Retrieval도 마찬가지로 비디오를 프레임 단위로 나누어 이를 텍스트와 매칭하는 방식으로 학습됩니다. 하지만 비디오의 경우 고려해야할 요소가 더 늘어나는데 저자는 이 요소를 3가지 범주로 나누어서 정의하고 있습니다. 저자에 따르면 vision, language, alignment가 이미지에서 비디오로 넘어갈때 불일치가 생긴다고 합니다. 하지만 지금까지 연구들은 대부분 vision discrepancy를 줄이기 위해 연구가 진행되어온 반면, 저자는 vision, language, alignment의 불일치를 모두 줄인다는 의미로 DiscoVLA (Discrepancy Reduction in Vision, Language, and Alignment)를 제안합니다.
1. Introduction
최근 온라인 비디오가 증가하면서 효율적인 Video-Text Retrieval의 수요가 증가하고 있습니다. 이에 따라 다양한 Video-Text Retrieval(VTR) 벤치마크 데이터셋도 함께 등장하고 있지만, 매 데이터셋마다 모델을 full finetuning하는 것은 높은 저장 비용과 계산 자원을 요구합니다. 이러한 문제점을 해결하고자, 본 논문에서는 parameter-efficient transfer learning에 중점을 적은 수의 학습 가능한 파라미터로도 성능을 달성할 수 있는 방법론을 제안합니다.
VTR은 이미지-텍스트 정렬을 수행하는 CLIP과 같은 사전학습 모델을 비디오 도메인으로 확장하는 task입니다. 하지만, 단순히 CLIP을 그대로 사용하는 것은 한계가 있으며, Image-Text Retrieval과 Video-Text Retrieval 간에는 세 가지 중요한 구조적 차이가 존재합니다. 저자는 이를 Vision, Language, Alignment Discrepancy로 정의합니다.Vision Discrepancy: 비디오는 시간 축(temporal dimension)을 포함하므로, 정적인 이미지 기반 모델만으로는 motion이나 action dynamics를 포착하기 어렵습니다.
Language Discrepancy: 이미지 캡션은 개별 객체나 장면을 간결하게 설명하지만, 비디오 캡션은 시간의 흐름에 따른 사건의 연속성과 narrative를 담고 있어, 훨씬 더 복잡한 구조를 필요로 합니다.
Alignment Discrepancy: 이미지-텍스트 정렬은 일반적으로 정적인 시각 객체와 문장 간의 매칭이지만, 비디오-텍스트 정렬은 시간적 연속성과 공간적 전환을 동시에 고려한 정렬(spatio-temporal matching)이 필요합니다.
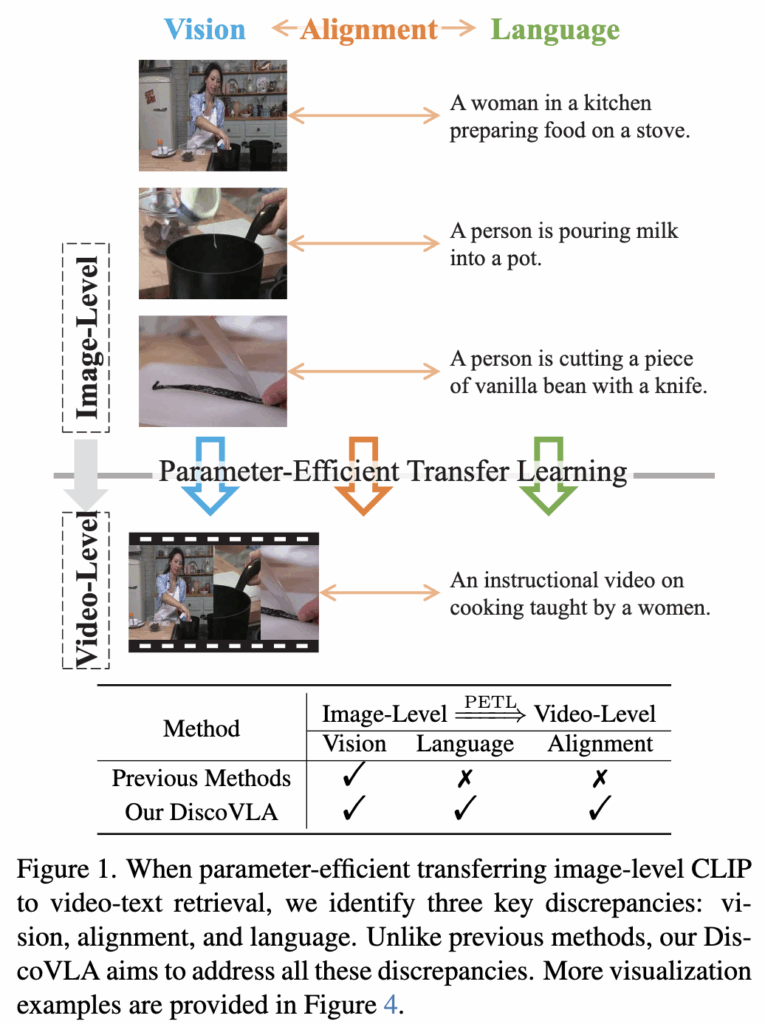
예를 들어, 그림 1에서 “preparing food”, “pouring”, “cutting”와 같은 프레임들은 각각 개별 이미지를 설명할 수 있지만, 전체 영상은 요리 과정을 설명하는 하나의 캡션으로 표현됩니다.
기존의 연구들은 주로 Vision 측면의 불일치를 해결하는 데 초점을 맞추었으며, Temporal Modeling이나 Cross-modal Fusion을 통해 비디오 level의 표현을 추출하려 했습니다. 하지만 이러한 방법들은 Language와 Alignment 측면의 불일치는 고려가 되지 않고 있습니다. 따라서 저자는 Vision, Language, Alignment 세 가지 측면의 불일치를 동시에 줄이기 위한 DiscoVLA(Discrepancy Reduction in Vision, Language, and Alignment),를 제안합니다. DiscoVLA는 다음과 같은 세 가지 핵심 모듈로 구성됩니다:
- IVFusion (Image-Video Features Fusion): 이미지와 비디오에서 추출된 특징을 통합하는 adapter를 통해 Vision과 Language 불일치를 동시에 고려
- PImgAlign (Pseudo Image-level Alignment): pseudo image captions을 생성하여 fine-grained image-level alignment을 수행
- AlignDistill (Image-to-Video Alignment Distillation): 이미지 level에서 학습된 alignment 정보를 비디오 level로 전이하는 Alignment Distillation을 통해, Alignment Discrepancy를 줄임.
따라서 저자의 Contribution은 다음과 같이 정리할 수 있습니다.
- Vision, Language, Alignment라는 세 가지 image-to-video discrepancies(vision, language, Alignment)를 모두 해결하는 것이 parameter-efficient Video-Text Retrieval(VTR)을 달성하는 데 필수적이라는 점을 처음으로 밝힘.
- IVFusion을 도입하여 이미지 level과 비디오 level의 특징을 통합함으로써 Vision과 Language 측면의 불일치를 동시에 해소. 또한, PImgAlign을 통해 fine-grained image level alignment를 학습하며, AlignDistill을 도입하여 Alignment Gap를 최소화.
- 제안한 DiscoVLA는 MSRVTT, LSMDC, ActivityNet, DiDeMo 등 주요 벤치마크에서 SOTA를 달성하였으며, 특히 MSRVTT에서 CLIP(ViT-B/16) 기반으로 R@1 50.5%를 기록하며 기존 방법들보다 1.5%p 높은 성능을 보임.
2. DiscoVLA
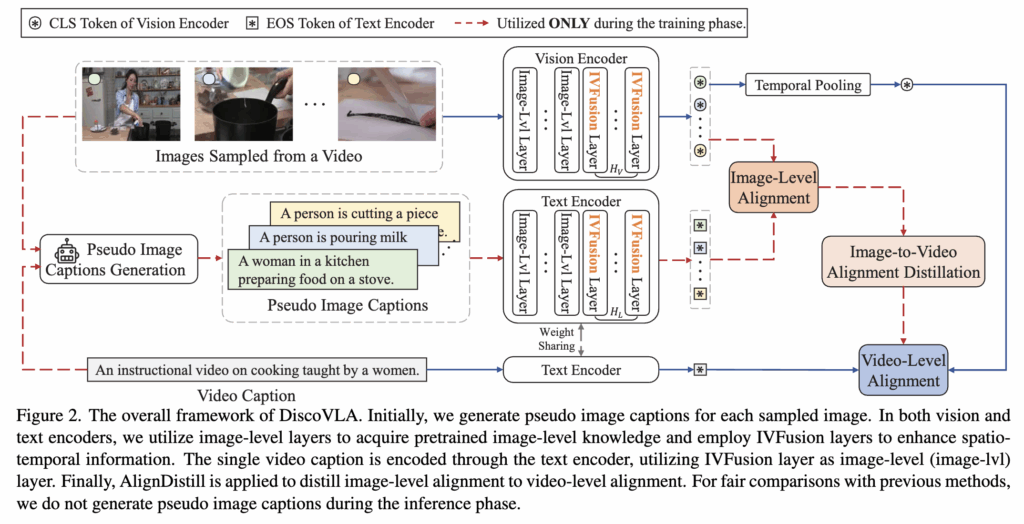
위의 그림 2에서 DiscoVLA의 전체 프레임 워크를 확인할 수 있습니다. 먼저 IVFusion은 Vision,Text Encoder에 포함이 되어 있고, fjne-grained image-level alignment를 위해 Pseudo Image Language Generation 모듈이 추가되었습니다. 마지막으로 video-level alignment를 향상시키기 위해 Alignment Distillation이 추가되어있는 것을 확인할 수 있네요. 그럼 이제 각 구성 요소가 어떻게 구성되는지 살펴보도록 하겠습니다.
Image-Video Features Fusion(IVFusion)
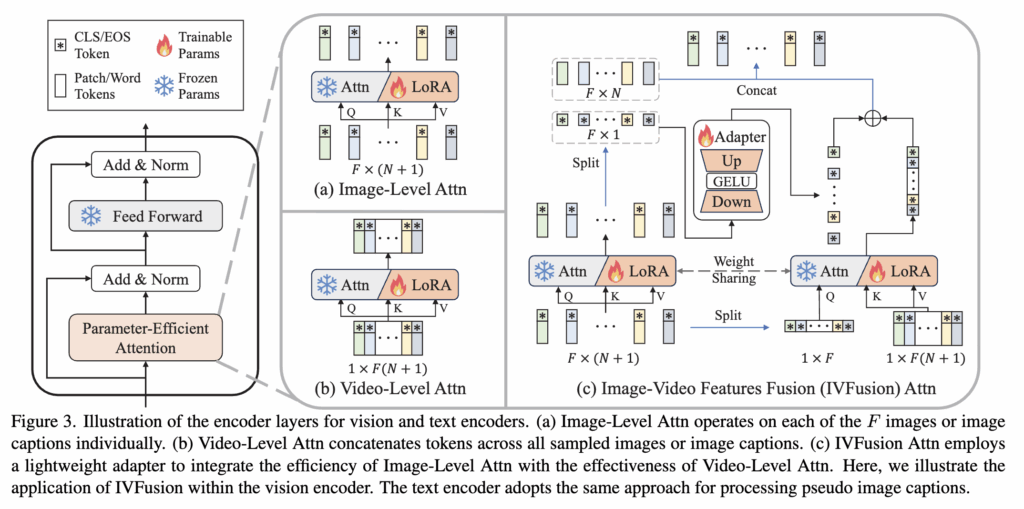
Image-Level Attention
먼저, 각 프레임의 공간 정보를 효율적으로 추출하기 위해 어텐션 모듈에 LoRA를 적용합니다. 그림 3a에 나타난 것처럼, F × (N + 1)개의 토큰이 Image-level Attention을 통해 처리되는데, 여기서 F는 샘플링된 이미지(프레임)의 수를 의미하고, N + 1은 CLS 토큰과 패치 토큰들을 합한 개수를 뜻합니다.
Image-Level Attention은 각 이미지(F개)를 개별적으로 처리하며, 이미지마다 N + 1개의 토큰을 사용합니다. 하지만 이 방식은 시간 정보를 고려하지 않기 때문에 순수하게 공간적 특성만을 추출합니다
Video-Level Attn
그래서 프레임의 시간 정보를 고려하기 위해 Video-Level Attention을 적용하는데, 이 방법은 샘플링된 이미지들에서 나온 토큰들을 concate하여 attention 모듈에 입력함으로써, 시공간(spatio-temporal) 정보를 학습할 수 있게 해줍니다.(그림 3b)
IVFusion Attn
이 두 접근법의 장단점을 절충한 방식이 바로 IVFusion Attention입니다. 기본적으로는 Image-Level Attention 구조를 따르되, 각 이미지의 [CLS] 토큰들만 따로 모아서 spatio-temporal attention을 한 번 더 수행합니다. 이렇게 하면 이미지의 공간적 세부정보는 유지하면서도, [CLS]를 통해 시간 정보를 효율적으로 통합할 수 있습니다.
여기서 핵심은 아래 수식처럼 두 attention 결과를 Adapter 구조로 융합한다는 점입니다:
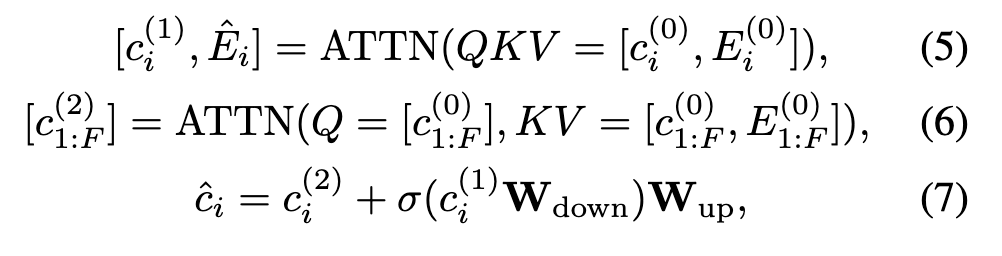
하위 레이어에서는 Image-Level Attention만 적용해 pretrained spatial 정보를 보존하고, 상위 Hv 개의 레이어에서는 IVFusion Attention을 적용해 spatio-temporal 정보를 강화합니다. 결과적으로 파라미터 효율을 유지하면서도 비디오-텍스트 정렬에 필요한 시간 정보까지 고려할 수 있게 모델을 설계했습니다.
Pseudo Image-Level Alignment(PImgAlign)
PImgAlign은 비디오 내용을 image-level로 분해하여 fine-grained image-level 로 학습하기 위한 기법입니다. 이를 위해 pseudo image captions을 활용하는데, 저자는 MLLM LLaVA-NeXT를 활용해 이미지에 대한 pseudo image caption을 생성합니다. 하지만 이 이미지 캡션은 해당 이미지를 간결하게 요약하기 때문에 하나의 캡션이 여러 이미지에 대응될 수 있습니다. 그래서 각 이미지에 대해 모든 캡션과 비교해서 최대 유사도를 계산하는 방식으로 image-level similarity를 계산합니다. 구체적으로는 다음과 같은 수식으로 유사도를 계산합니다
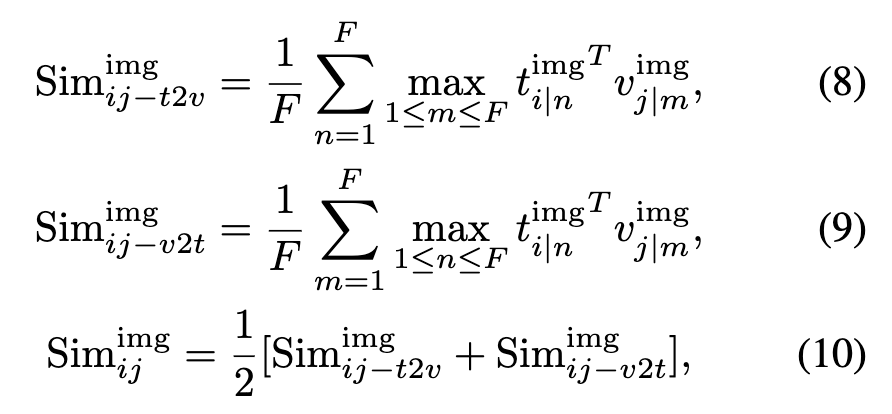
Image-to-Video Alignment Distillation
기존의 CLIP 모델은 이미지와 텍스트 간의 정렬에는 굉장히 뛰어나지만, 비디오-텍스트 검색에서는 단순한 이미지 정렬을 넘어 spatio-temporal 정보까지 함께 고려해야 하므로 더 복잡한 정렬이 필요합니다. 그래서 논문에서는 AlignDistill이라는 방식을 제안합니다.
이 방법은 이미지 수준에서 잘 학습된 정렬 능력을 비디오 수준의 정렬 학습에 전이시키는 distillation 기법입니다. 이를 위해 논문에서는 이미지 정렬 결과와 비디오 정렬 결과 간의 확률 분포 차이를 줄이도록 학습합니다. 구체적으로는, 텍스트에서 비디오로 정렬되는 분포와 비디오에서 텍스트로 정렬되는 분포 각각에 대해 이미지 기반 정렬 결과 분포와 비디오 기반 정렬 결과 분포가 비슷해지도록 KL Divergence(확률 분포 간 거리)를 최소화합니다.
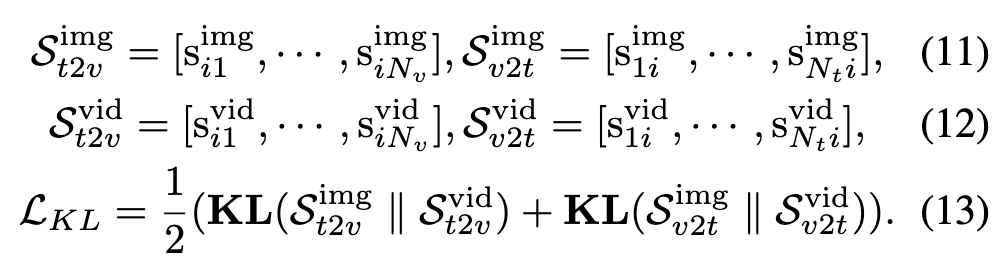
최종적으로 최종 손실 함수는 다음 세 가지 항으로 구성됩니다
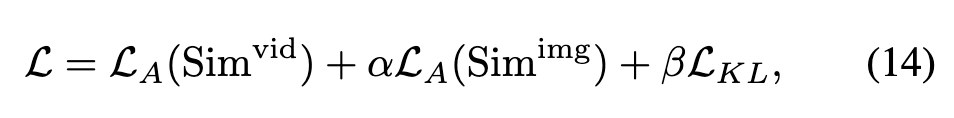
3. Experiments
DiscoVLA는 기존의 video-text retrieval 방법들과 비교했을 때 네 가지 주요 데이터셋(MSR-VTT, LSMDC, ActivityNet, DiDeMo)에서 모두 SOTA를 달성했습니다.
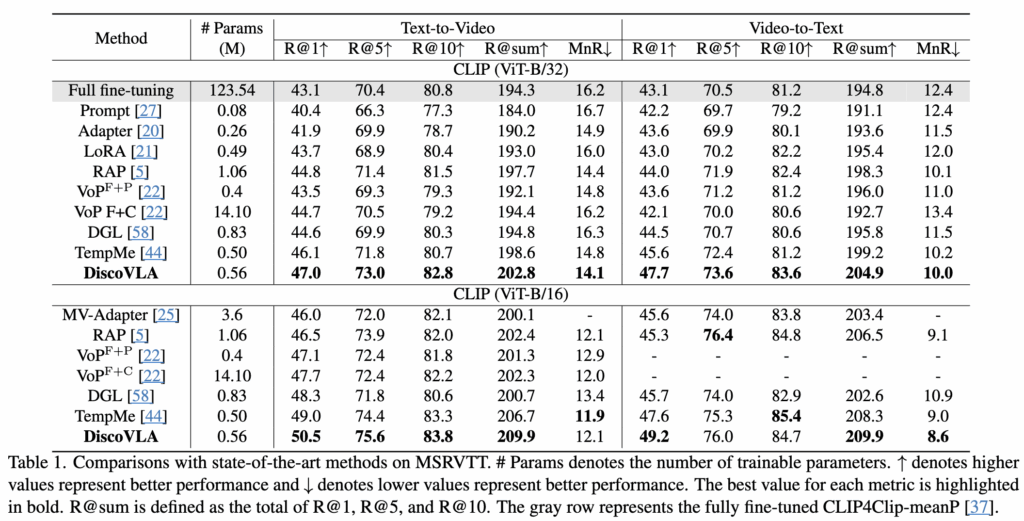
표 1에 따르면, MSRVTT 데이터셋에서 CLIP (ViT-B/32)를 백본으로 사용한 DiscoVLA는 text-to-video retrieval (t2v)에서 R@1 47.0%, video-to-text retrieval (v2t)에서 R@1 47.7%를 달성하며, 기존 방법들보다 앞선 성능을 보였습니다. 또한 CLIP (ViT-B/16)을 사용할 경우, R@1 기준 1.5% 추가 향상되어 최종 50.5% R@1 성능을 기록하였습니다.
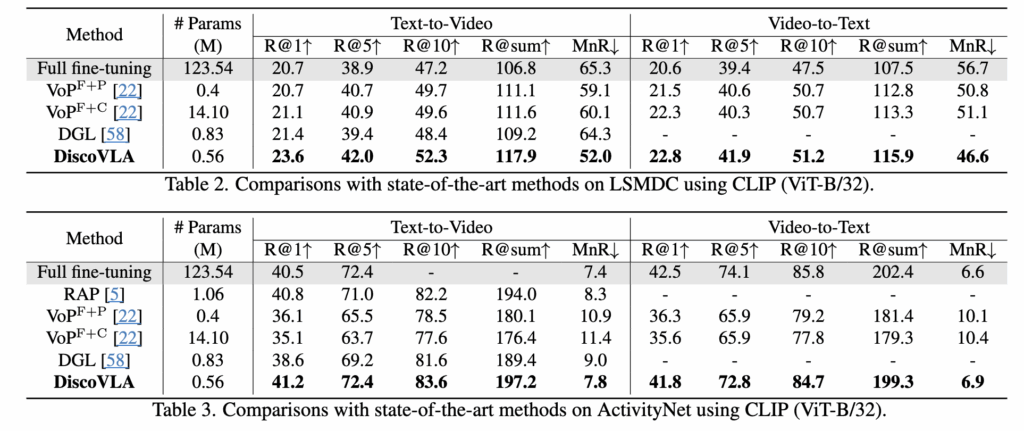
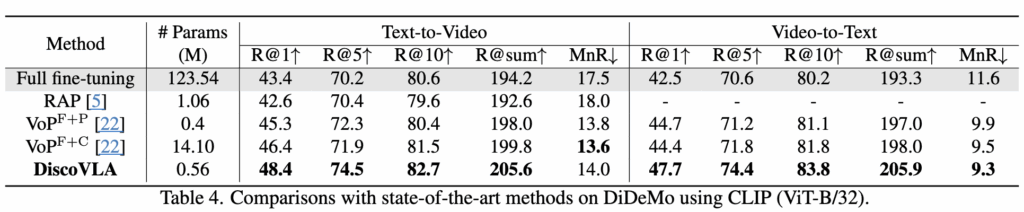
LSMDC, ActivityNet, DiDeMo 데이터셋에 대한 비교 결과는 표 2~4에 정리되어 있으며, 이들 데이터셋에서도 기존 방법들보다 뛰어난 성능을 보여주었습니다.
Ablation study on IVFusion.
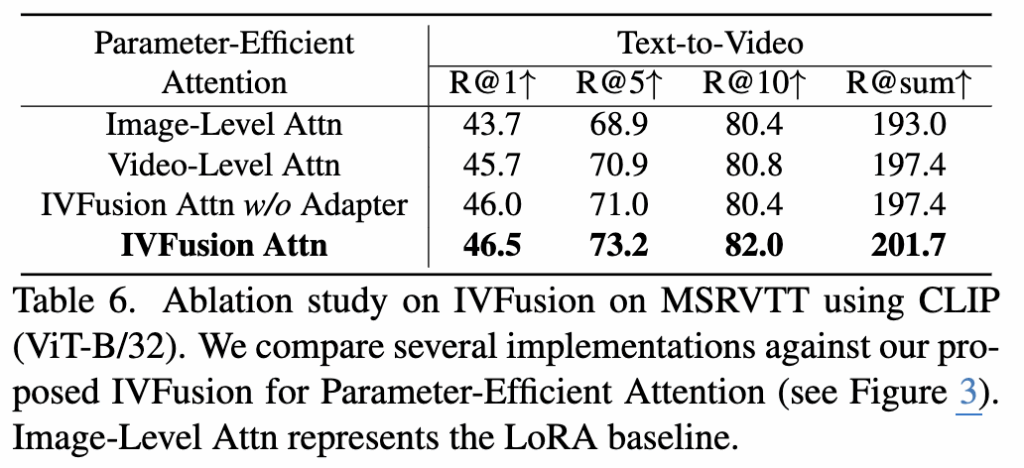
표 6에서는 IVFusion에 대한 Ablation 실험 결과를 보여줍니다. 그림 3에 나오는 parameter-efficient attention 전략들을 비교했는데, Video-Level Attn은 샘플링된 모든 이미지의 토큰을 연결하여 spatio-temporal 정보를 학습하며, 4.4%의 R@sum 성능 향상을 달성했습니다. 계산 복잡도를 줄이기 위해 IVFusion은 global CLS 토큰에만 spatio-temporal attention을 적용하고, 이미지 레벨 특징과 비디오 레벨 특징을 결합합니다. Adapter 없이 이미지와 비디오 레벨 특징을 단순히 평균할 경우 성능이 다소 향상되지만, 학습 가능한 Adapter를 사용하면 IVFusion이 특징들을 더욱 효과적으로 결합하여 201.7%의 R@sum 성능을 달성했습니다.
Qualitative Analysis

그림 4에서 이미지와 비디오 데이터를 비교하는 시각화 실험을 진행했습니다. 그림 4a와 4b에서는 이미지 데이터만으로는 비디오의 전체 내용을 완벽히 포착하지 못하는 모습을 볼 수 있습니다. 반면 그림 4c와 4d는 비디오와 이미지 내용 간에 강한 상관관계가 있음을 보여주지만, 각각의 이미지마다 차이가 있어 이미지 캡션이 다르게 생성되는 점도 확인할 수 있습니다. 시각적으로 비디오는 시간적인 정보를 포함하는 연속된 이미지들의 집합이며, 텍스트로는 이미지 캡션은 개별 이미지에 국한되고 비디오 캡션은 전체 비디오 내용을 설명합니다. 이러한 차이점으로 인해 CLIP을 효과적으로 비디오에 적용하는 데 어려움이 생깁니다.
결론적으로 DiscoVLA는 이 문제를 해결하기 위해, 이미지에서의 정렬 학습을 먼저 수행한 후 이를 비디오 정렬로 확장하는 방식(alignment distillation)을 사용했습니다. 이로써 이미지의 시각 정보와 비디오의 시간적 흐름을 모두 반영한 정밀한 정렬 결과를 얻을 수 있었습니다.
안녕하세요. 리뷰 잘 읽었습니다.
PImgAlign, Pseudo Image-Level Alignment라는 것이 LLaVA를 통해 이미지에 대한 Pseudo Caption을 생성한다고 하는데, 이것에 대해 조금 더 자세히 설명해주셨으면 합니다. 예를 들어 LLAVA와 같은 MLLM은 보통 사용자의 질문에 대응해서 응답을 내는 모델이기에, 유저가 어떤 질문을 던졌는지가 중요한데, 어떤 목적을 가지고 어떤 질문을 던졌는지에 대해 풀어 설명해주시면 감사합니다.
안녕하세요 상인님 좋은 질문 감사합니다.
LLAVA 모델에게 주어지는 프롬프트는 다음과 같습니다. “The provided image is a frame sampled from the video, which describes “{video caption}”. Based on the video’s content, provide a caption for the provided image.” 모델에게 주어지는 프롬프트는 비디오 전체 설명과 함께 프레임에 대한 장면을 설명하도록 요구하기 때문에 프레임마다 비디오의 맥락을 반영해서 이미지 캡션을 생성할 수 있고, 이를 활용하여 이미지-텍스트 간 fine-grained alignment를 학습할 수 있습니다.
감사합니다.