안녕하세요, 예순 다섯번째 X-Review입니다. 이번 논문은 2024년도 CVPR에 올라온 PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection입니다. 바로 시작하도록 하겠습니다.
1. Introduction
Anomaly Detection은 normal이 아닌 anomalous한 데이터를 탐지하는 task입니다. 본 논문은 one-class classification(OCC) 세팅에서의 unsupervised AD(anomaly detection)에 초점을 맞췄다고 보시면 되는데요. 이 OCC 세팅에서는 모델이 학습할 때 오직 normal 데이터만 보게 되며, 테스트 때는 본 적 없는 anomalous한 데이터를 잘 탐지해야 합니다. 이런 세팅을 사용하는 이유는 단순 생각해보면, 예를 들어 산업 환경에서의 AD인 경우 생산 라인마다 제품도, 결함도 다를 수 있어 모델을 개별적으로 구성해야 하는 경우가 많기 때문에, 몇 개의 normal 샘플만으로 학습하여 anomalous 샘플을 구분하는 것은 실용적인 측면에서 중요하다고 볼 수 있겠죠.
최근에는 이런 few-shot 세팅에서도 좋은 성능을 내기 위해 좋은 zero-shot 성능을 보이는 CLIP과 같은 foundation model을 활용한 AD 연구도 진행이 되고 있습니다. 그 중 대표적으로 WinCLIP이라는 방법론이 있는데, 이 WinCLIP에 대해 간략히 설명하자면 prompt ensemble 방식을 사용해 prompt의 다양성과 표현력을 극대화하고자 한 모델입니다. 예를 들어 “a cropped photo of a []”이나 “a blurry photo of the []”같은 다양한 문장을 만들어 모델이 normal sample을 더 잘 이해하도록 돕는 느낌입니다.
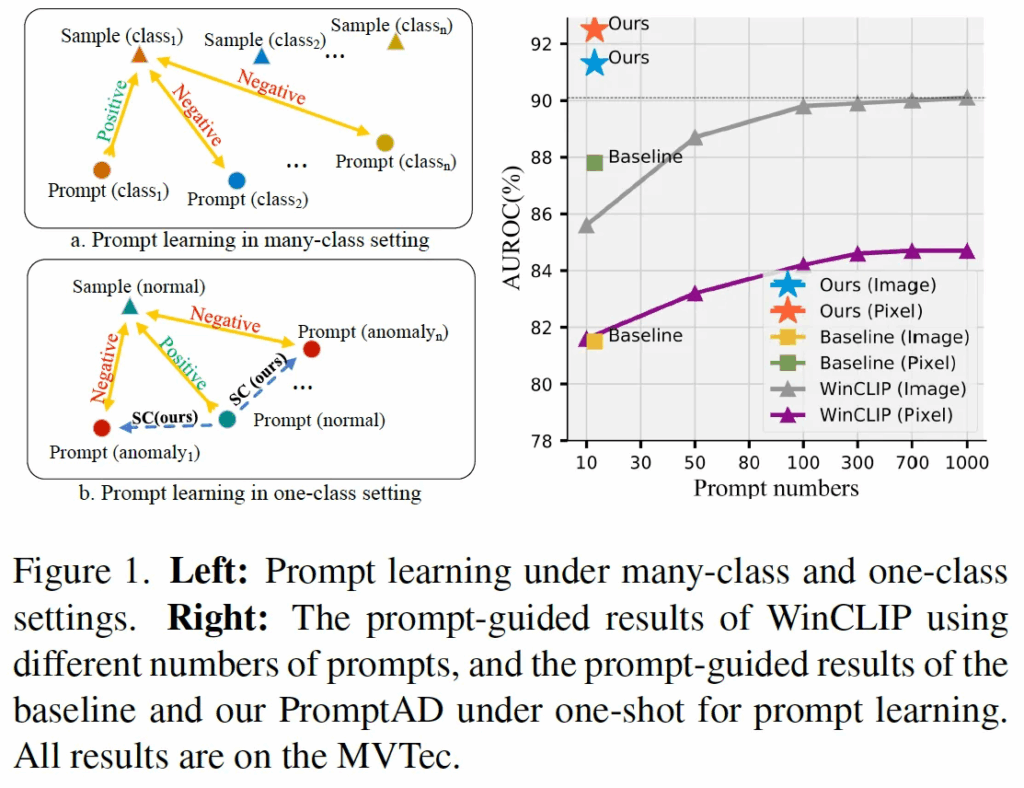
실제로 위 Fig1에 오른쪽에 있는 그래프를 보시면, X축이 prompt 개수이고 y축이 성능을 나타내는 그래프인데, 여기서 prompt 개수를 늘릴수록 성능이 향상되고 있으며, 약 1000개 정도에서 수렴하는 경향을 보입니다. 이렇게 WinCLIP처럼 prompt를 수작업으로 늘려서 사용하는 방법은 prompt 수가 늘어날수록 좋은 성능을 보이기는 하지만, 결국 사람의 개입이 들어가기도 하고 설계하는 과정 자체도 번거로워서 자동화가 중요한 실제 산업 환경에서는 적용하는데 한계가 존재합니다.
이런 이유로, 본 논문에서는 사람이 직접 prompt를 만들지 않고 자동으로 학습하는 방식인 prompt learning이 산업 환경에서는 더 적합하다고 말합니다. 실제로 prompt learning은 Fig1 (a) 그림처럼 원래 contrastive learning 기반으로 image classification을 수행하는 방식인데, 이를 AD에 적용해보면 어떨까 생각을 한거죠. 근데, Fig1 오른쪽에 있는 그래프에 baseline이라고 적힌 부분을 보면 알 수 있듯이, 기존의 prompt learning 방식을 그대로 AD에 적용하게 되면 one-class setting이라는 제약 조건 때문에 오히려 성능이 떨어지는 문제가 생갑니다. 특히 직접 수동으로 만든 prompt를 사용하는 WinCLIP보다도 성능이 낮게 나오는 것을 확인할 수 있죠. 왜 이런 문제가 생기는가를 생각해보면 다음과 같습니다. 먼저, prompt learning은 contrastive learning을 기반으로 하기 때문에 normal과 anomalous를 비교해야 하는데, one-class setting에서는 anomalous 샘플이 학습 때 사용되지 않기 때문입니다. 또, 다음으로 anomalous 샘플이 없기 때문에 normal prompt와 anomalous prompt 사이 거리를 조절할 기준도 마땅히 없는 것도 이유라고 볼 수 있겠습니다.
본 논문에서는 이런 문제를 해결하여 오직 normal 샘플만 가지고 prompt를 학습하는 모델인 PromptAD를 제안합니다. 앞서 말한 one-class setting에서 contrastive learning을 하기 위해서는 normal이 아닌 게 필요하다는 문제를 해결하기 위해서 Semantic Concatenation (이하 SC)라고 하는 방식을 제안하였는데, Fig1(b)를 보시면 SC(ours)라고 써져있으면서 normal과 anomaly prompt사이 거리를 멀게 하고 있는 것을 확인할 수 있습니다.
또, 학습 시에 이상 샘플이 아예 없기 때문에 contrastive learning 만으로는 normal prompt와 anomalous prompt 사이 거리를 명시적으로 조절할 수 없다는 문제를 해결하기 위해서는 Explicit Anomaly Margin(이하 EAM)이라는 방식을 제안합니다. 이 두 SC와 EAM에 대해서는 method단에서 자세히 설명드리도록 하겠습니다.
무튼 이 둘을 제안하게 되면서 이를 적용한 PromptAD는 Fig1의 오른쪽 그래프를 보시면 단 10~20개 정도의 prompt 만으로 기존 대략 1000개의 prompt를 사용한 WinCLIP이나 baseline보다 더 높은 성능을 보입니다.
2. Methodology
2.1. Overview
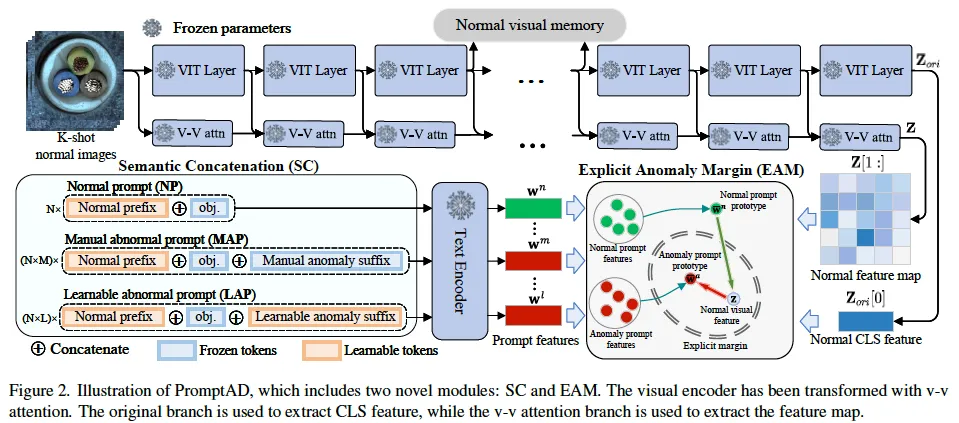
먼저 본 PromptAD의 overview를 설명드리도록 하겠습니다. 위 Fig2가 전체적인 프레임워크 그림인데요, 이 PromptAD는 기존 CLIP 모델을 살짝 변형한 VV-CLIP을 기반으로 설계가 되었습니다. 여기서 VV-CLIP의 vision encoder는 global feature와 local feature를 동시에 추출할 수 있는 구조로, 본래 CLIP이 image classification을 수행하기 위해 설계되었다면 VV-CLIP은 classification 뿐만 아니라 pixel level의 AD까지 수행가능한 형태라고 보심 됩니다.
아래 부분에 그려져 있는 Text Encoder의 입력으로 들어가는 prompt 부분을 보시면 앞서 intro에서 짧게 언급한 Semantic Concatenation(SC) 방식이 적용되고 있습니다. 구체적으로는 모델이 학습하는 N개의 normal prompt [latext]NP_s[/latex]를 만들기 위해 N개의 learnable한 prefix와 object 이름인 obj를 연결하고 있는데요. 그림에서는 Semantic Prompt 박스 안에 맨 윗 행에 해당합니다. 이렇게 만든 normal prompt 각각에 대해서 이전 WinCLIP처럼 수작업으로 만든 M개의 anomalous 관련 suffix(접미어)를 붙이면 NxM개의 anomalous prompt MAP_s가 되고, 마지막 행처럼 learnable한 L개의 anomaly suffix를 붙이면 N x L개의 learnable한 abnormal prompt LAP_s가 됩니다.
그 다음 이 normal prompt와 abnormal prompt들은 image로부터 얻은 visual feature들과 함께 Explicit Anomaly Margin (EAM) loss를 통해 학습됩니다. 여기서 EAM은 normal prompt와 abnormal prompt가느이 거리를 조절해서, 두 representation이 잘 분리되도록 하는 과정이라고 보면 되겠습니다.
이렇게 학습이 끝나게 되면, 만들어진 prompt들을 가지고 Prompt-guided AD(PAD)를 수행할 수 있게 되는데요. PAD란 image feature vector와 prompt vector간의 유사도 기반으로 해당 이미지가 normal prompt에 더 가까운지 아니면 anomaly prompt에 더 가까운지를 계산해 이상 여부를 판단하는 것입니다. 근데, PromptAD는 여기서 추가로 Vision-guided AD(VAD)도 함께 도입을 하는데, 이는 간략히 말하자면 image자체만 보고 anomaly를 탐지하는 방식입니다. 구체적으로는, 학습 과정에서 vision encoder의 특정 layer에서 얻은 local feature들을 저장해두고, 이들을 normal visual memory R로 사용하는 것입니다. Fig2에서 맨 위에 Normal visual memory가 있는 것을 확인할 수 있습니다. 학습 때 이렇게 memory에 feature들을 저장해두고 test단에서 input image에서 같은 layer의 feature map F와 R(normal visual memory)을 비교해 각 pixel level에서 유사도를 계산합니다. 이때 유사도가 낮을수록 해당 위치는 anomaly일 가능성이 높은 것이죠.
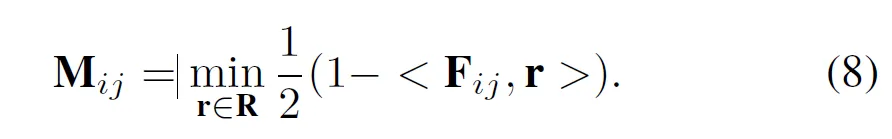
방금 한 말이 위 수식으로 적혀 있는데 저렇게 뽑은 score map M을 anomaly score map으로 사용합니다.
2.2. Semantic Concatenation
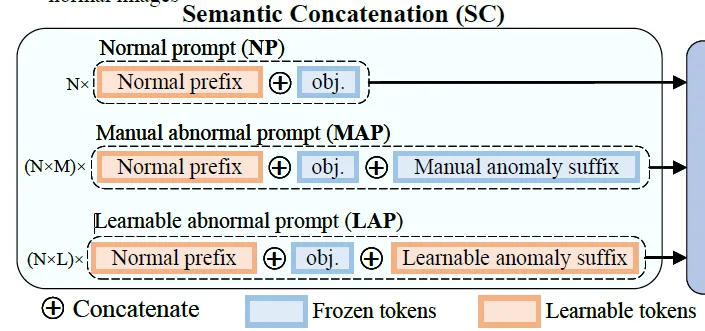
다음으로는 이 Semantic Concatenation부분에 대해 자세히 설명드리도록 하겠습니다. 본 논문 세팅에서는 AD 학습할 때 오직 normal sample만 사용가능했기 때문에 prompt learning에 필요한 negative sample이 존재하지 않는다는 문제가 있었습니다. 이를 위해 제안한 부분이 SC인데요. 앞서 overview에서 간략 언급했지만, 간단히 말해 normal prompt에 anomaly suffix를 붙여 의미만 abnormal한 prompt로 만드는 방식입니다.
예를 들어 “a photo of cable”이라는 문장이 있다고 할 때 이 문장은 normal 문장인데, 여기에 “with flaw”를 붙이면 “a photo of cable with flaw”가 되겠고 이는 abnormal한 의미로 바뀌게 되겠죠. 이처럼 normal prompt이 anomaly 관련 접미어를 덧붙이는 방식으로 가까 anomaly prompt를 만들어 내는 것입니다.
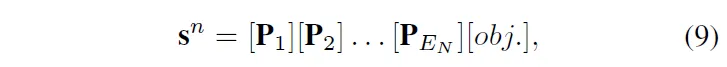
normal prompt를 식으로 표현하면 위 식9처럼 표현해볼 수 있겠는데, 여기서 P_1부터 P_{E_N}는 learnable한 prompt token이고 obj는 실제 object 이름입니다.
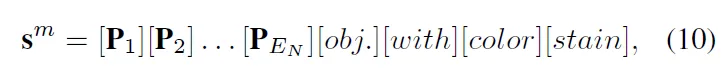
이 normal prompt s^n뒤에 manually하게 만든 anomaly suffix을 붙인 MAP는 위 식10처럼 표현해볼 수 있겠죠. 하지만, 이제 수작업으로 만든 문장은 다양성이 부족할 수 있으니까 추가적으로 learnable한 token을 사용해 abnormal representation자체를 학습시키고자 설계한 LAP도 같이 학습합니다.
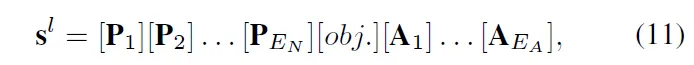
위 식11과 같은데 보시면 normal prompt에 끝에다가 learnable한 token A를 붙인 것이죠.
이렇게 prompt들을 설계한 다음 학습 중에는 아래 식12의 clip training loss를 사용해서 Normal Prompt는 normal image에 가까워지도록 abnormal prompt(MAP와 LAP)는 이로부터 멀어지도록 학습합니다.
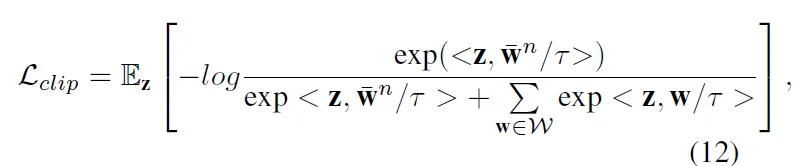
식에서 z는 normal image의 feature vector, \bar{W}^n는 모든 normal prompt의 평균 vector, W는 MAP와 LAP에서 얻은 abnormal prompt vector들의 집합입니다.
2.3. Explicit Anomaly Margin
학습 시에 normal image들만 사용하기 때문에 manually하게 만든 MAP나 learnable하게 학습한 LAP prompt가 있다고 해도 이 normal prompt의 visual feature 기준으로만 contrastive learning을 수행할 수 있고, normal prompt와 abnormal prompt간의 명시적인 차이를 학습하기에는 한계가 있습니다.
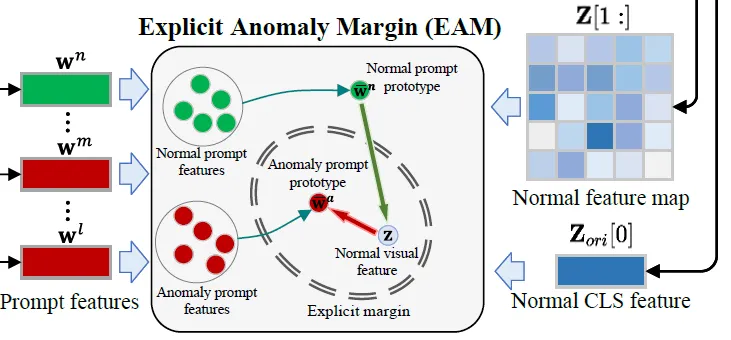
이런 문제를 해결하기 위해 제안된게 Explicit Anomaly Margin(EAM)이라고 말 그대로 명시적으로 normal prompt와 abnormal간의 거리를 조절하는 부분입니다.
구체적으로, EAM은 normal image의 feature와 normal prompt vector간의 거리보다, normal image와 abnormal prompt vector간의 거리가 더 멀어지도록 학습하는데요. 그림을 보면 각각의 prompt feature를 다 멀게 하는것이 아닌 이 normal prompt vector를 평균 낸 normal promtp prototype와는 가까워지도록 abnormal prompt를 평균 낸 abnormal prompt ptorotype와는 멀어지도록 설계되어 있습니다.
수식으로 표현하면 다음과 같은데, 수식 그대로 normal image와 normal prompt간의 거리가 abnormal prompt 거리보다 작아지도록 학습하는 방식입니다. 여기서 z는 normal image의 feature w_n는 normal prompt의 prototype, w_a는 abnormal prompt의 prototype입니다.
추가적으로 learnable한 abnormal prompt인 LAP은 완전 random으로 초기화돼서 학습이 되기 때문에 manually하게 만든 MAP에 비해서 semantic한 가이드가 부족할 수 있다고 합니다. 그래서 본 논문에서는 두 prompt set의 분포를 맞춰주는 추가적인 loss도 사용하였습니다.
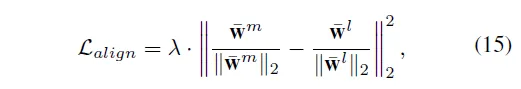
2.4. Anomaly Detection
실제 test 단에서는 학습한 normal prototype \bat{w}^n와 anomaly prototype \bat{w}^a를 사용해 prompt-guided anomaly detection을 수행합니다.
구체적으로 이미지 한 장이 입력으로 들어오면 CLIP 기반 vision encoder를 통해 visual feature를 뽑아내고, 이 vector가 normal prototype과 anomaly prototype 중 어디에 더 가까운지를 계산하게 됩니다.
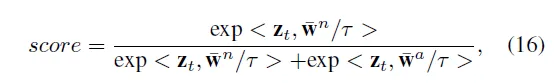
수식 16처럼 softmax 기반으로 계산이 되고 결과적으로 나온 score는 입력으로 들어온 이미지가 normal일 확률을 나타내는 것이죠.
최종적으로는 아래 수식 17, 18처럼 vision guided score M_v와 prompt guided score M_t를 합쳐 pixel level의 score map을 계산하게 되고, M_v 최댓값과 S_t를 가지고 image level의 score를 얻게 됩니다.
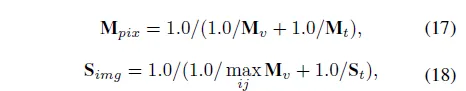
3. Experiments
이제 실험 부분입니다. 본 논문에서는 1-shot, 2-shot, 4-shot 세팅에서 실험을 수행하였고, image level과 pixel level 둘 다 실험을 수행하였습니다. image level이란 입력 이미지 전체에 대해서 normal/abnormal을 예측하는 classification이라고 보면 되겠고, pixel-level이란 그 image 안에서 어느 pixel이 abnormal한 부분인지 예측하는 segmentation이라고 보면 되겠습니다.
본 논문은 Industrial 환경에서의 AD를 focus한 논문으로 관련 데이터셋인 MVTec과 VisA 벤치마크를 사용하였으며, 평가지표로는 AUROC를 사용하였습니다.
3.1. Image-level Comparison Results
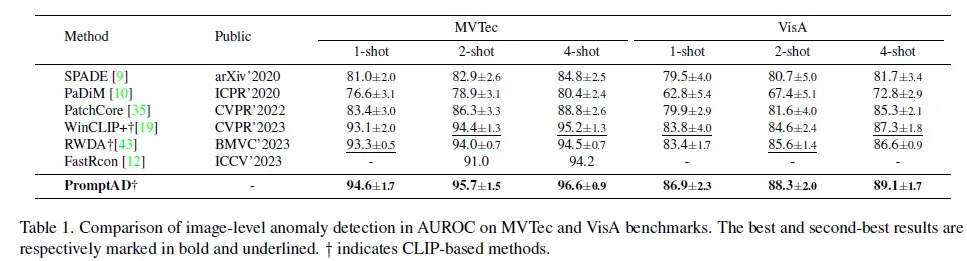
먼저 Image level 결과인데요. 위 표1을 보시면 기존 SPADE, PaDiM, PatchCore 방법론은 기존 full-shot 방식은 few-shot에 맞게 재구성한 것들입니다. 보시면 PromptAD는 두 벤치마크 MVTec, VisA에서 1-shot, 2-shot, 4-shot 모두 기존 sota에 비해 성능 향상을 보이고 있습니다. 특히 기존 유사 방식인 WinCLIP과 RWDA 비교해서는 훨씬 더 적은 수의 prompt만으로 더 좋은 성능을 보였다고 합니다.
3.2. Pixel-level Comparison Results
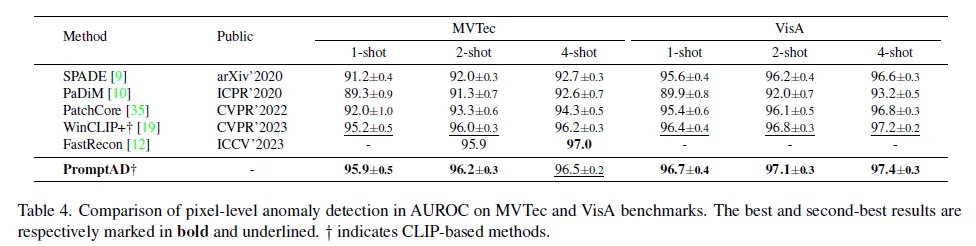
다음은 pixel level의 실험 부분입니다. 표 4를 보시면 CLIP 기반 방식인 WinCLIP+의 성능이 위에 image level에서는 CLIP을 도입함으로써 보이는 성능 향상폭이 컸었는데, pixel level에서는 이전 방법론들과 유사한 성능을 보입니다. 그렇지만 PromtpAD는 여기에 추가로 약간의 성능 향상을 보이면서 SOTA를 달성하고 있습니다. MVTec 벤치마크에서 4-shot 성능이 좀 떨어지기는 합니다.

위 Fig3은 anomaly 영역을 모델이 찾은 정성적 결과입니다. 보시면, PromptAD는 1-shot 세팅에서 PatchCore나 WinCLIP+보다 object와 texture 모두에서 더 정확하게 anomaly 위치를 파악하고있음을 확인할 수 있습니다. 특히 왼쪽 Grid나 오른쪽에 Chewing Cum처럼 엄청 anomaly 영역이 작은 경우에도 정밀하게 탐지하고 있습니다.
3.4. Ablation Study
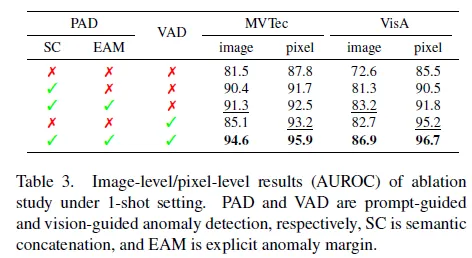
다음으로 ablation study로, 본 논문에서 제안한 여러 요소, SC(Semantic Concatenation), EAM(Explicit Anomaly Margin), VAD가 어떤 영향을 주는지 확인한 실험입니다. 위 표 3을 보시면, 먼저 SC를 적용한 경우에 성능이 image level에서는 거의 10%정도로 성능이 크게 향상된 것을 확인할 수 있는데, 이는 contrastive learning에서 negative sample의 수가 중요한 역할임을 입증합니다. 즉, 기존의 prompt 학습 방식에서는 negative prompt가 부족해서 성능이 크게 떨어지게 되는 것이죠.
다음으로 EAM의 경우에는, 학습 중에 실제 anomaly sample이 존재하지 않기 때문에 normal prompt와 anomaly prompt간의 명확한 margin을 정해주기 위해 제안한 모듈이었는데, 성능을 보시면 0.7~2 내외의 성능 향상을 보이고 있습니다.
마지막으로 VAD는 normal sample에서 얻은 feature를 memoty에 저장해두고 사용함으로써 prompt 기반 방식인 PAD에 비해서 좀 더 local한 세부적인 정보를 반영할 수 있었는데, 이 역시 마찬가지로 3~5 정도의 성능향상을 보이면서, 특히 세부적인 정보를 요하는 pixel-level에서 좀 더 좋은 영향을 미치는 것을 확인할 수 있습니다.
3.5. Visualization Results
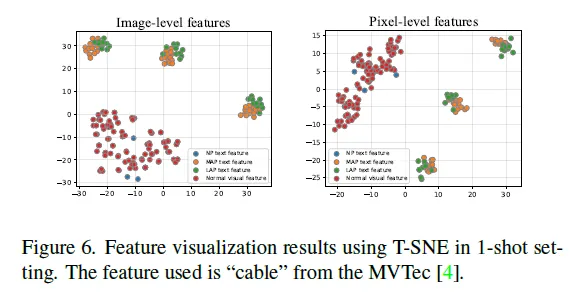
마지막으로 promptAD의 효과를 정성적으로 확인하기 위해 visual feature와 prompt feature를 시각화한 것인데요. 위 Fig6은 3개의 normal prompt NP와 manually하게 구성하는 anomaly prompt MAP 3×13개, 그리고 learnable하게 학습하는 anomaly prompt LAP 3×10개를 T-SNE로 시각화한것입니다. 그림에서 빨간색 점이 normal visual feature구요, 파란색 점이 normal prompt feature, 노랑 초록이 각각 MAP, LAP입니다. 보시면, 정상 prompt feature와 이상 prompt feature 사이 구분이 잘 되고 있으며, 정상 prompt feature와 정상 image feature가 overlap되고 있음을 확인할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
전체 프레임워크 설명해주시는 부분을 보니 그냥 기존 CLIP을 사용한게 아니라 VV-CLIP을 사용했다고 말씀해주셨는데, 이게 그림에서 보면 V-V attn이라고 되어 있는 부분이 그냥 추가된 버전이라고 생각하면 될까요? 또 본문에 관련 말이 없는 것 같은데 이 V-V 어텐션이 어떻게 동작하고 어떤 구조인건지 설명해주실 수 있나요?
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
V-V attn은 value 간의 attention만 수행하는 것입니다. 기존 CLIP attention 방식이 보통 CLS 토큰이 모든 patch에 대해 attention해서 global한 embedding을 뽑아내는 것이라면, V-V attn은 input feature끼리 서로 attention해서 local한 정보만 주고받고 CLS token은 무시하는 방식이라고 보면 됩니다. 즉,,, – 즉, attention(Q, K, V)를 → attention(V, V, V)로 하는 것입니다.