안녕하세요, 이번주는 Google DeepMind의 end-to-end로 3DGS 기반으로 물리 시뮬레이션이 가능한 3d asset generation pipeline을 소개한 논문입니다. Synthetic data 활용을 한 로봇 학습에서는 asset generation이 필수적이고, 이를 효율적으로, 사실적으로 하는것은 매우 중요하다고 생각해서 계속 보고있습니다. 직접 asset generation을 해보는 과정에서 3DGS 방법을 활용했을 때 geometry를 생성하는 과정이나 전체적인 시간 대비 image to 3d 쪽이 더 효과적이라고 생각하고, 실제로 광범위한, 방대한 데이터를 취득하는 파이프라인에는 image to 3d가 활용되는 것을 보고 해당 방법론을 위주로 보려고 했지만 이번에 리뷰하는 논문 포함 몇몇 리뷰들이 iamge to 3d의 문제점을 언급하고 불가능하다고(?) 여겼던 3DGS의 속도 개선이나 깔끔한 geometry 생성 또한 가능성을 확인할 수 있어서 논문들을 조금 더 보려고 합니다. 해당 논문도 제가 image to 3d를 활용해 asset generation을 진행할 때 사용한 TRELLIS 대비 장점을 어필하는 논문이었어서 리뷰하게 되었습니다.
Introduction
로봇 학습의 안전성, 확장성, 효율성 등을 확보하기 위해서는 실제 로봇 동작 데이터를 기반으로 한 정밀한 시뮬레이션을 구축해야 하지만 이는 각종 occlusion, 카메라 포즈의 노이즈, dynamic한 장면들 때문에 큰 어려움을 겪고 있습니다. 이를 photorealistic rendering (3DGS)와 명시적인 object mesh를 하이브리드로 통합해서 해결한다고 합니다. 이런 표현 구조를 중심으로 differentiable rendering과 physics를 활용해 모든 scene 구성 요소와 물리적인 파라미터까지 최적화를 진행할 수 있다고 합니다. 제안된 방법을 시뮬레이션을 넘어서 실제 환경에서도 검증을 마쳤다고 하는데요, 심지어 이 모든게 별도의 장비 없이 저렴한 로봇과 RGB카메라 만으로도 성공했다고 하네요.
저자들의 contribution은 RGB 시퀀스로부터 scene appearance, object geometry, robot pose, camera parameter를 공동으로 최적화할 수 있는 fully differentiable end-to-end real-to-sim pipeline을 제안한 것, 하나의 RGB 궤적 데이터와 같은 불완전한 입력만으로도 새로운 객체가 포함된 동적 장면의 재구성을 가능하게 한 것, 시각적 일관성을 기반으로 물리 시뮬레이터에 바로 적용 가능한 mesh 자산을 controllable하게 복원할 수 있음을 주장했습니다.
아래 표에서도 알 수 있듯 differentiable physics나 dynamic scene 학습, 그리고 simulation-ready 3D asset 생성 파이프라인을 제공하는 차별점을 지니고있습니다.

Problem setting
현실에서 수집한 관찰 데이터와 어느 정도 신뢰할 수 있지만 부정확한 로봇 시뮬레이션 모델이 주어진 상황에서, 이 논문이 다루고자 하는 문제는 해당 데이터를 바탕으로 새로운 객체의 geometry까지 포함된 정확한 시뮬레이션 장면을 복원하는 것입니다. 이를 위해 저자들은 시뮬레이터가 생성한 관찰값과 실제 세계에서 수집된 관찰값 사이의 불일치, 즉 prediction error를 최소화하는 방향으로 모델을 구성했습니다.
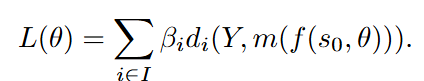
여러 모달리티로 구성된 로봇 관찰값 Y=(y1,…,yI)에 대해, 시뮬레이터 상의 물리상태 s로부터 관찰값을 생성하는 m과 최적화 대상 파라미터 집합들 θ에각 모달리티별로 정의된 divergence 함수 di와 가중치 βi를 적용하여 전체 loss를 다음과 같은 형태로 정의했습니다.

보다 구체적인 현실 제약 조건을 반영하기 위해, 저자들은 저비용 양팔형 테이블탑 조작 플랫폼인 ALOHA2와 그에 연동된 오픈소스 MuJoCo 모델을 실험 대상으로 설정했다고 합니다. 이 시스템은 위 사진과 같이 두 개의 고정된 카메라와 각각의 손목에 장착된 두 개의 이동식 카메라를 포함한 총 4개의 RGB 카메라를 사용했다고 합니다. 다만 이런 세팅은 카메라의 개수가 적어 다양한 시점을 확보하기 어렵고, 로봇 팔의 움직임으로 인해 장면이 지속적으로 변화하며, 타이밍 지연이나 기계적 백래시, 엔코더 캘리브레이션 오류 등으로 인해 카메라 포즈 추정이 매우 불안정하다는 문제가 있고, 따라서 표준적인 3DGS 데이터 수집 및 장면 모델링에 여러 문제를 야기한다고 합니다. 또 실제로 COLMAP을 이용해 객체 마스크 기반 이미지나 전체 궤적 이미지에 대해 reconstruction을 시도했으나, 카메라 간 일관된 추정을 얻지 못했다고 합니다.
또한 객체 분할을 위해 사용된 SAM2 같은 segmentation 모델은 로봇 처럼 텍스쳐가 부족하고 배경과 구별이 어려운 요소에 대해서는 부정확한 결과를 보여주기 때문에 저자들은 이러한 조건 하에서도 동작 가능한 프레임워크를 목표로 하며, 복원된 시뮬레이션의 품질을 평가하기 위해 다음 세 가지를 수행했다고 하빈다. 카메라 extrinsics 및 로봇 포즈의 자동 보정, novel view synthesis, novel object geometry reconstruction을 통해 최소한의 세팅에서 진행 가능하도록 했다고 합니다.
Methods
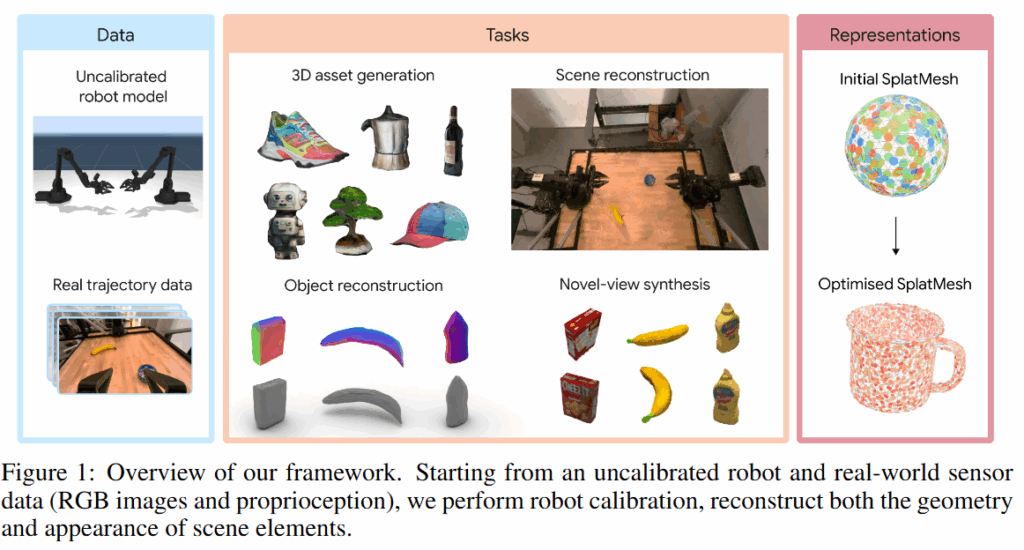
전체적인 과정은 실제 로봇에서 얻은 trajectory에서 RGB 이미지와 로봇 state 정보를 수집하는 단계로 시작됩니다. 이후 이 데이터를 바탕으로 장면 전체를 표현할 수 있는 새로운 scene representation을 구성하고, 이 구조 위에서 로봇 궤적 데이터만을 입력으로 하여 differentiable physics simulation과 differentiable rendering을 통해 최적화를 수행합니다. 이를 통해 geometry, appearance, pose 등의 요소를 분리된 모듈 없이 하나의 통합된 파이프라인에서 학습 가능하게 만들 수 있음을 강조했습니다.
해당 파이프라인의 중요한 요소는 scene representation의 방식입니다. SplatMesh라는 hybrid scene representation의 방식을 도입해 triangle mesh의 표면에 3DGS를 결합해 mesh의 움직임에 따라 3DGS를 같이 움직인다고 합니다. 이렇게 geometry와 appearance를 분리해 표현함으로써, 각 요소에 대해 독립적으로 학습할 수 있는 유연성을 제공하며, 필요에 따라 appearance, pose, shape을 학습 대상으로 삼거나 고정된 상태로 유지할 수도 있다고 합니다. 초기에 모든 객체를 642개의 점과 5cm 반지름을 가진 구의 형태로 초기화 한 뒤 최적화를 진행한다고 합니다.
Gaussian들은 mesh 표면 상에 강제로 배치되며, 초기 위치는 각 face의 barycentric coordinate를 샘플링하여 설정한다고 합니다. 각 face당 6개에서 20개 정도의 Gaussian을 분포시켰고, face의 면적에 비례하여 Gaussian 수를 재분배하기 위해 stochastic rounding을 사용하였다고 합니다. 최적화 과정에서 Gaussian의 최종 위치와 방향은 해당 face의 vertex 위치와 barycentric 좌표에 따라 동적으로 업데이트된다고 합니다.
이러한 mesh의 vertex 위치를 변형시키는 방식의 geometry의 최적화는 vertex 간 연결성은 그대로 유지해 mesh의 topology를 일관되게 유지할 수 있게 하며, vertex와 face의 개수를 제어 가능하게 만들어 시뮬레이션 효율성과 제어력을 확보하는 데 유리하다고 합니다. 또 explicit한 geometry를 최적화하는 접근은 mesh regularization term을 직접 objective에 포함시킬 수 있고 mesh 복잡도를 정확히 제어할 수 있어 계산 비용이 매우 효율적이라고 합니다. NeRF와 3DGS를 비교했을때와 비슷한 이치이지 않을까 생각하고있습니다.
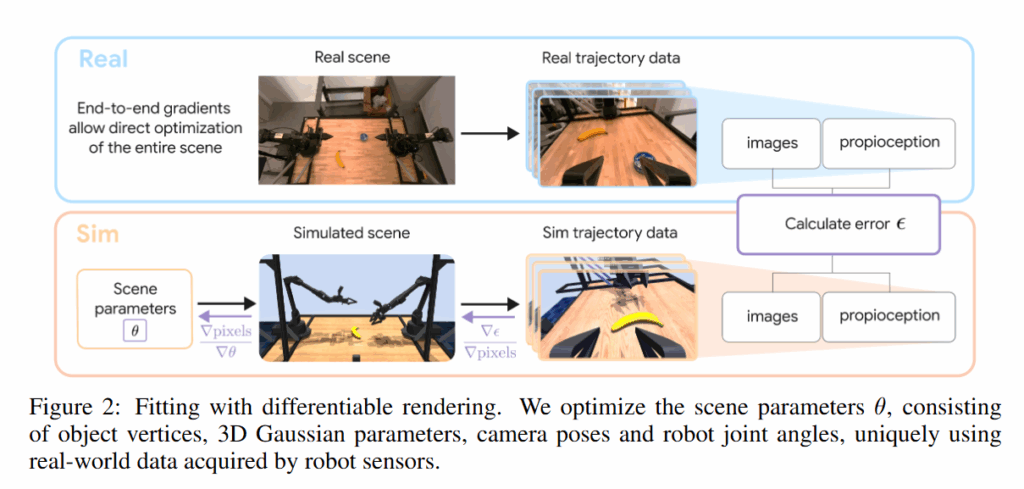
이후 시뮬레이션과 렌더링의 과정을 미분 가능한 형태로 구성한 이점을 살려서 모든 요소들을 통합적으로 학습하는 end-to-end optimization을 구현한다고 합니다. MuJoCo를 시뮬레이터로 사용하는 것으로 알고있는데, 시뮬레이션의 렌더링 자체를 현실적으로 표현한다고 이해했는데, 이걸 3DGS를 활용한다는건지 무조코 상의 시뮬레이션 렌더링을 현실적으로 만드는건지는 좀 더 이해해볼 필요가 있는 것 같습니다,,

RGB 이미지 x_hat(θ), surface normal 이미지 n_hat(θ), 그리고 binary mask 이미지 m_hat(θ)는 대응하는 GT인 x,n,m으로부터 supervision을 받고 위와 같은 Loss들을 Adam optimizer를 사용해서 최적화 해서 파이프라인의 모든 요소들(메쉬의 위치, 가우시안 파라미터, 카메라포즈)을 통합적으로 학습한다고 합니다.
Results
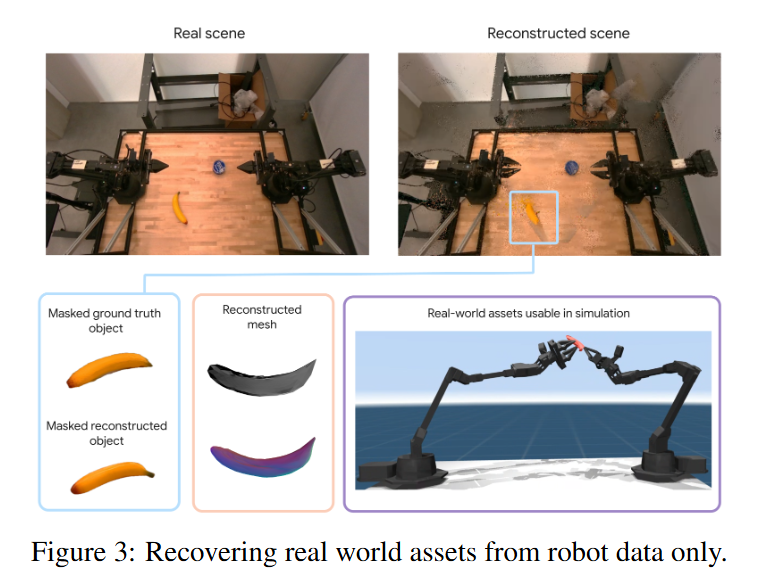
제안한 통합 프레임워크의 주요 기여를 입증하기 위해 저자들은 novel-view synthesis, geometry reconstruction, 3D asset generation의 세 가지 관점에서 실험 결과를 제시했습니다. 이를 위해 시뮬레이터와 real 기반으로 평가를 수행했습니다.
텍스트 프롬프트나 단일 이미지를 입력으로 받으면, CAT3D 모델을 활용해 해당 객체의 여러 시점에서의 이미지를 예측하고 SplatMesh 기반의 novel-view synthesis 및 geometry reconstruction를 진행했다고 합니다.
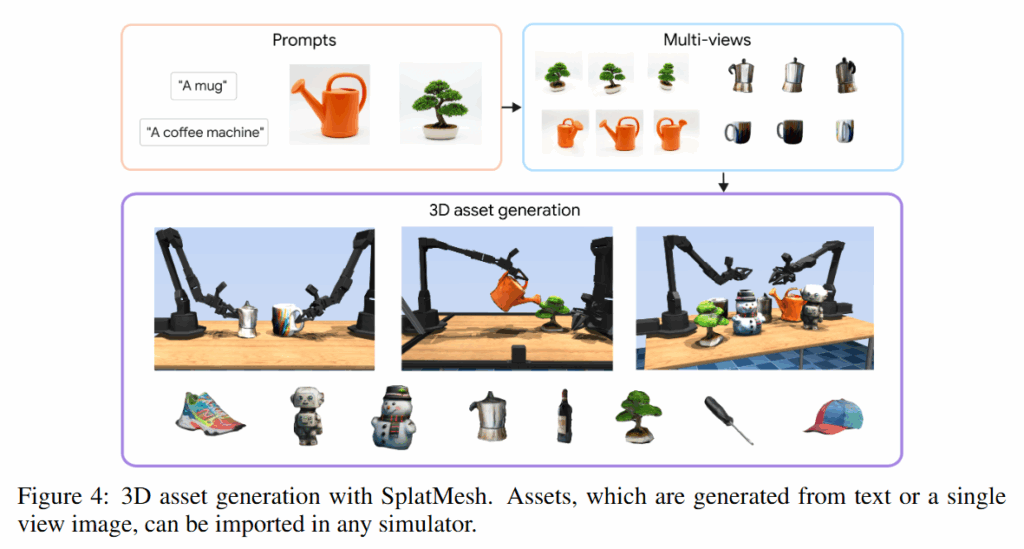
첫 번째는 Simulation 실험으로, YCB object set을 활용해 생성한 합성 데이터셋을 사용했습니다. 이 데이터셋은 총 64개의 객체 각각에 대해 50개의 정해진 포즈 이미지를 포함하며, 전체 데이터를 80%/20% 비율로 학습용과 테스트용으로 분할하여 사용했다고 합니다.
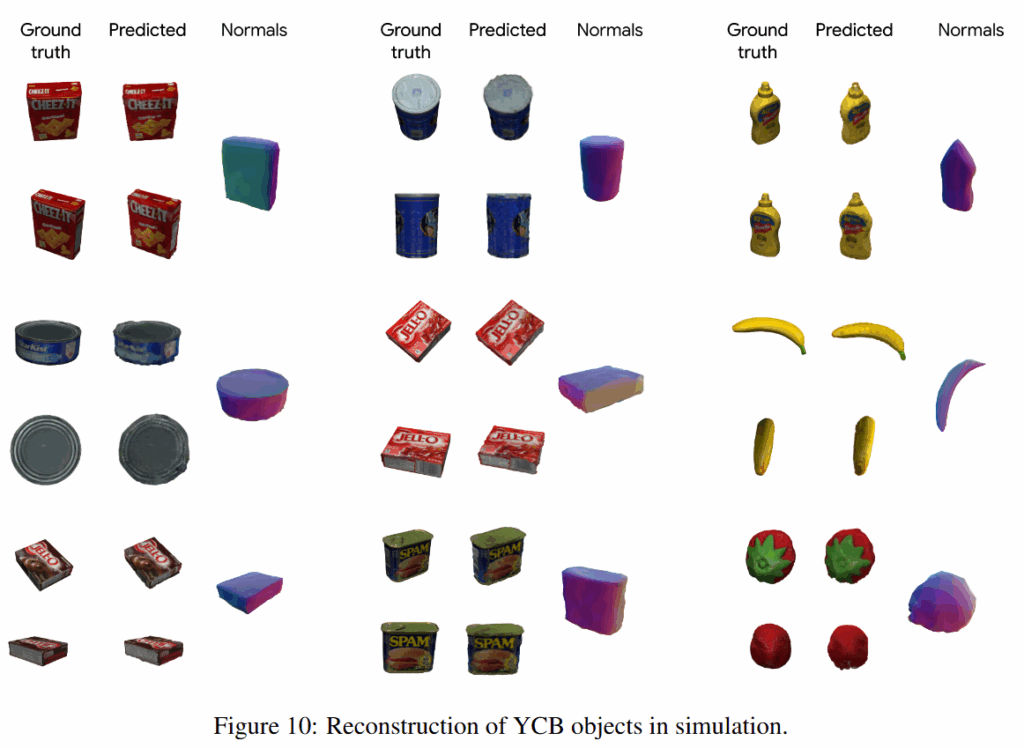
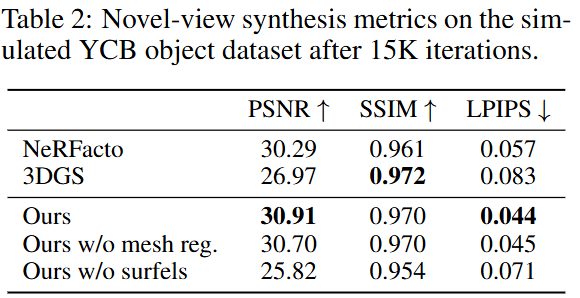
Novel-view synthesis 실험에서는 NeRFacto와 3DGS보다 높은 PSNR, SSIM , LPIPS를 달성했습니다. 다른 기법들이 복잡한 처리나 artifacts 문제를 겪는 반면, 단일 최적화 과정만으로 빠르게 고품질 뷰 생성이 가능하다는 이점 또한 존재한다고 합니다. 이를 통해 mesh regularization과 surfel 제약은 일반화 성능과 시각 품질 향상에 중요한 역할을 한다는 점도 확인할 수 있었다고 합니다.
두 번째는 Real-to-Sim 실험으로, ALOHA2 플랫폼에서 직접 수집한 Real World 데이터셋을 사용했다고 합니다. 이 데이터셋은 총 6개의 observation trajectory로 구성되어 있으며, 약 800 프레임의 RGB 이미지와 각 프레임에 대한 로봇 관절 상태가 포함되어 있다고 합니다. 성능 평가를 위해 획득한 이미지 중 16 프레임을 별도로 보존하여 test set으로 활용하였다고 합니다.
YCB object에 대한 마스크를 얻기 위해 텍스트 프롬프트를 지정해 OWL-ViT로 Bbox를 생성 후 segmentation mask를 구해 사용했다고 합니다.

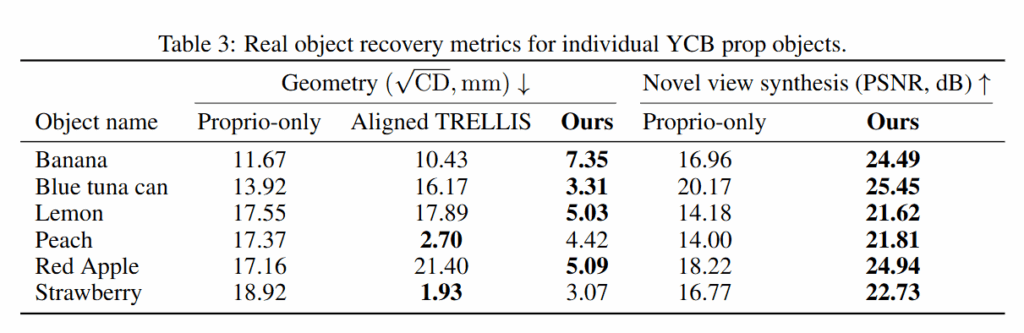
TRELLIS와 비교를 진행했는데, TRELLIS는 단일 또는 소수의 이미지로부터 appearance와 geometry를 생성하는 pre-trained 3D foundation model입니다. Metric scale이나 절대 pose를 예측하지 않기 때문에 Chamfer Distance 기반으로 alignment 후 평가되었다고 합니다(Aligned TRELLIS). 일부 객체에 대해서는 품질 높은 복원을 수행했으나, 스케일 왜곡, 잘못된 geometry , 심지어 특정 경우 단순한 형태조차 정확히 포착하지 못하는 등의 한계를 보였다고 합니다.

Conclusion
적고나니 Asset generation은 Real image에서 텍스트 프롬프트를 통한 OWL-ViT, SAM2, CAT3D (시점 다각화) 이후 SplatMesh 과정을 거치는게 전부인 것 같습니다. 다만 논문에서는 이를 시각적 RGB에서 출발해 물리 시뮬레이션이 가능한 3D Asset을 만드는 과정에서 모든 요소를 하나의 파이프라인을 통해 최적화 했다고 주장합니다. Method 부분의 End-to-End Optimization이 그것인것 같은데, 결국 이 파이프라인에 활용되는 파라미터들을 RGB이미지와 ALOHA 세팅에서 한 번에 역전파해서 진행했다고 이해하는게 맞는것 같습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
COLMAP 기반 reconstruction 이 일관된 추정을 얻지 못한다는 건 이제 거의 기정사실화가 된 것 같고, 컴퓨터 그래픽스와 로봇비전 간의 결합이 제 생각보다 더 빠르게 발전되고, 섬세하게 개선되고 활용되고 있는 것 같아 놀랍네요.
1. 어쨌든 전반적으로 미분가능한 어떤 end-to-end 파이프라인으로 3d asset을 generation하는 과정으로 이해했는데, 어떻게 해서 미분가능한 physics simulation을 만들고, 미분가능한 렌더링을 가능케 하는 지 잘 이해가 안됐습니다. 이 모든게 3DGS라서 가능한 건가요? 어떻게 미분가능하게 만들었는지를 제가 놓친 것 같습니다.
2. barycentric coordinate 이 찾아보니 질량중심좌표계로 나오는데, gaussian 들의 초기위치를 설정하기 위해 이것을 샘플링한다는 것이 무슨 의미인가요?
감사합니다.
안녕하세요 재찬님 댓글 감사합니다.
1. 저도 이해가 잘 안 된 부분인데 렌더링과 물리를 모두 JAX 연산 그래프 안에 넣어 한꺼번에 미분하도록 설계된 구조 때문에 미분 가능하다는 표현을 한 것 이라고 합니다. 3DGS또한 가능하게 한 요소중에 하나입니다. 미분 가능하다는게 역전파가 가능하다는 말을 한건데 3D Gaussian Splatting(3DGS) 렌더러에서 가우시안의 위치·크기·색으로 기울기가 전해지고, MuJoCo를 JAX로 포팅한 MJX 시뮬레이터에서 같은 그래프 안에서 “픽셀 손실 → 가우시안 → 메시 기하 → 로봇·카메라 파라미터”를 한 체인으로 연결돼 한 번에 최적화를 한다고 합니다.
2. barycentric 좌표를 쓰는 이유는 SplatMesh라는 방법론에 대한 설명이 부족했던 것 같은데, 메시를 기준으로 가우시안을 덕지덕지 붙이는 개념을 사용하기 때문에 초기 가우시안 중심의 좌표를 정할 때 메시 삼각형들의 질량중심 좌표를 사용하면 더 매끄러운 점을 활용하기 위해 샘플링 해서 사용한다고 합니다.