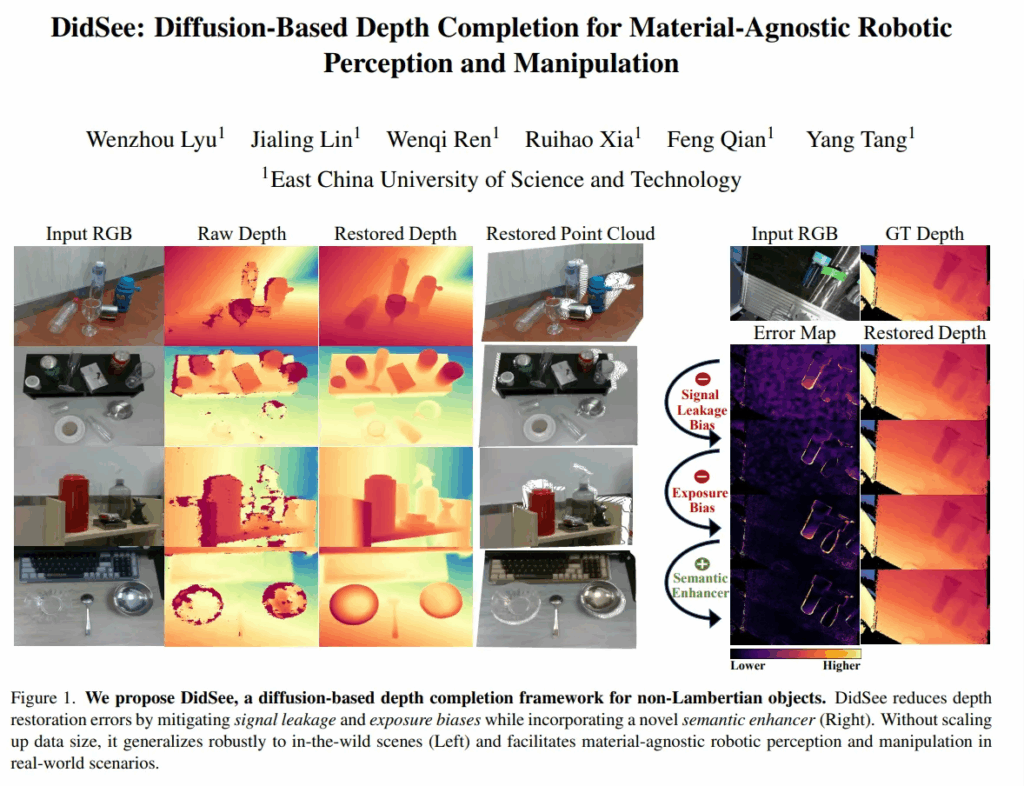
1. Introduction
상용 RGB-D 센서는 Lambertian 표면 아닌 물체(투명하거나 반사되는 재질을 의미)에서 노이즈가 발생하며 성능이 저하되는 한계가 있습니다. 그래서 RGB 이미지를 같이 활용하여 누락되는 depth를 복구하는 방법론들이 많이 제안되고 있습니다. 그러데 이러한 방식은 RGB 이미지에서 나타나는 시각적인 특징이 굉장히 모호하고 Lambertian이 아닌 depth를 예측하는 것은 여전히 어려운 일 입니다. 또한 Lambertian이 아닌 물체는 학습 데이터가 많지 않기 때문에 새로운 물체나 복잡한 scene이 들어오면 real world에서 일반화가 어렵게 됩니다.
데이터를 늘리는 관점 외에도 최근에는 일반화가 가능한 dense prediction이 가능하도록 diffusion 방식을 이용하고 있습니다. dense prediction에 바로 diffusion을 적용하면 generation과 dense prediction 간에 차이가 발생하는데요, 대부분의 방법론들은 이를 무시하고 진행을 한다고 합니다. 가령 이미지 생성에서는 상대적으로 미치는 영향이 적은 signal leakage bias와 exposure bias는 dense prediction에는 성능을 크게 저하시킬 수 있다고 합니다.
이러한 관점에서 depth completion을 위해 diffusion 프레임워크를 직접 사용하는 것에 대한 한계를 우선 분석하였다고 합니다. 분석을 통해 내린 결론은, 먼저 signal leakage bias는 첫번째 inference 단계에서 오류를 발생시켜 depth completion 성능 저하에 영향을 미칩니다. 두번째는 여러 단계의 inference는 exposure bias로 인해 오류가 누적되어 예측을 점차적으로 악화시키게 됩니다. 마지막으로는 Lambertian이 아닌 물체의 표면은 뚜렷한 시각적인 특징이 없기 때문에 모델이 그러한 물체의 depth를 생성하는 것이 어렵습니다.
위의 세 가지 문제를 해결하기 위해 저자는 DidSee라는 depth completion 모델을 제안합니다. DidSee는 먼저 signal leakage를 완화하기 위해 zero terminal SNR을 적용하는 스케줄러를 사용합니다. 원래 diffusion 모델은 마지막 타임 스텝에서 미세하게 원본 신호가 남아있어서 샘플이 완전한 노이즈가 아니라 신호가 섞인 상태가 되어 모델이 학습할 때와 inference할 때 다르게 동작이 됩니다. 이를 signal leakage bias라고 하는데, zero terminal SNR을 적용하면 마지막 타임스텝의 SNR을 정확히 0으로 만들어서 완전히 순수한 가우시안 노이즈만 포함되도록 만들 수 있습니다. 또한 여러 단계의 inference가 아니라 단일 단계의 학습을 통해 exposure bias를 완화하고자 하였습니다. 마지막으로 모델의 depth와 semantic 정보를 공동으로 생성할 수 있도록 하여 non Lambertian 표면을 배경과 구별할 수 있는 능력을 가지도록 설계하였다고 합니다.
이러한 본 논문의 main contribution을 정리하면 다음과 같습니다.
- non Lambertian을 위한 diffusion 기반 depth completion 네트워크 DidSee 제안
- depth completion의 성능을 저하시키는 두 bias에 대해 분석 및 해결
- non Lambertian 물체와 배경의 구분력을 향상시키기 위해 semantic enhancer 제안
- 여러 벤치마크와 물체, 로봇 downstream task에서 SOTA를 달성
2. Methodology

Fig.2는 DidSee의 프레임워크를 나타내는데요, 크게 3가지 요소로 나눠볼 수 있습니다.
(1) signal leakage bias를 완화하기 위해 zero terminal SNR로 조정된 노이즈 스케줄러
(2) exposure bias를 줄이고 task specific loss들을 통합할 수 있는 단일 단계 학습 방식
(3) depth completion과 semantic segmentation을 동시에 수행하여 물체와 배경에 대한 구분력을 높일 수 있는 semantic enhancer
2.1. Zero Terminal-SNR Noise Schedular
diffusion 모델에서는 깨끗한 데이터 z_0에서 점차적으로 노이즈를 추가하여 z_t를 만들고 이를 역으로 복원하는 방식으로 학습합니다. 이 때 중요한건 마지막 타임스텝에서 어떤 수준의 노이즈인가 인데요, 보통은 완전한 노이즈가 이상적이지만 실제로는 식(5)와 같이 원본 정보가 조금은 남아있습니다.
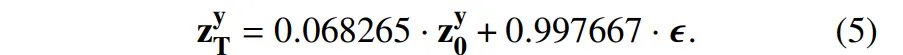
즉, 완전한 노이즈가 아니라 약 6.8%의 원본 정보가 섞여있음을 의미합니다.
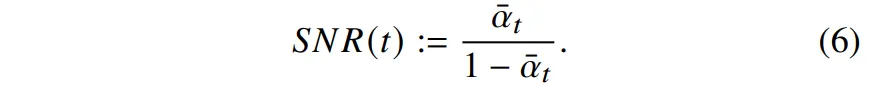
\bar{\alpha_t}가 0.00466이라고 가정했을 때 diffusion의 마지막 스텝에서 SNR은 약 0.0046으로 완전한 노이즈가 아니라 조금의 신호가 남아있는, signal leakage가 발생합니다.
학습할 때는 이렇게 마지막 스텝에 원본 정보가 조금 남아있는데, 실제 inference 할 때는 보통 마지막 스텝의 입력이 완전한 가우시안 노이즈가 주어집니다. 결국 학습과 추론 사이의 입력 분포가 불일치해서 첫 스텝 복원부터 틀어지면 이후 단계에서는 오류가 누적되겠죠.
본 논문에서는 이를 해결하기 위해 노이즈 스케줄러를 다시 설계하고 있습니다.
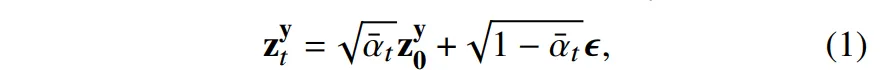
우선 식(1)은 원래 diffusion의 노이즈 스케줄을 의미합니다.
여기서 시작은 그대로 유지하는데, 마지막 스텝에서 \bar{\alpha_T}를 0으로 설정하여 순수 가우시안 노이즈만 남도록 강제로 설정합니다. 중간 구간을 linear하게 스케일링을 다시 하였다고 합니다. 이렇게 노이즈 스케줄 전체를 일관되게 수정함과 동시에 마지막은 완전히 깨끗한 노이즈가 될 수 있도록 유도하는 것 입니다.
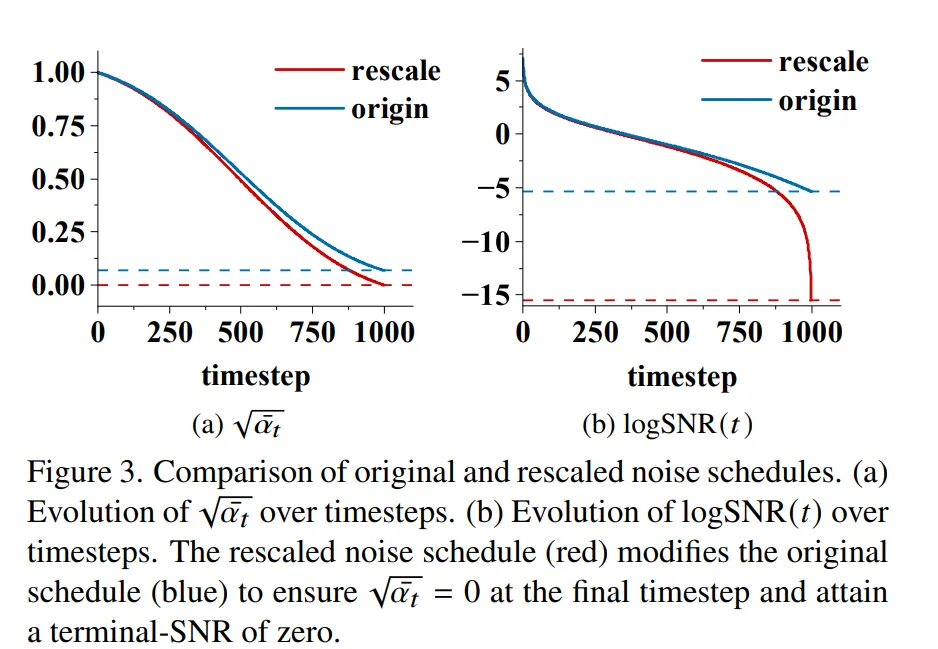
Fig.3은 원래의 스케줄과 변형한 노이즈 스케줄을 시각적으로 비교한 것 입니다. 앞서 말씀드린 것 처럼 \bar{\alpha_t}가 마지막에도 여전히 0이 아닌 값으로 남아서 SNR도 -2 근처인 것을 알 수 있습니다. 반면 변형한 스케줄은 \bar{\alpha}_T = 0이 되도록 하여 마지막 SNR이 정확히 0이 되도록 설정됩니다. 이를 통해 마지막에 조금 남아 있는 신호를 완전히 없앴다는 것을 확인할 수 있죠.
변형한 노이즈를 이용하여 학습 시에도 마지막에 순수 노이즈만 보고 학습을 하며 inference 때도 마찬가지로 동일한 노이즈에서 시작하기 때문에 학습과 inference가 일치하여 signal leakage를 완전히 제거할 수 있었습니다.
2.2. Noise-Agnostic Single-Step Training
앞선 signal leakage가 발생하는 마지막 타임스텝에서의 문제를 해결하였지만, 사실 멀티 스텝으로 추론을 하기 때문에 중간 타임 스텝에서 발생하는 오류가 누적되어 exposure bias가 발생하게 됩니다. 학습에는 GT로부터 생성되어 노이즈가 추가된 z^y_t를 사용하는데, 반면 추론 시에는 raw한 depth부터 시작해서 이전 단계에서 스스로 예측한 결과 \hat{z}^y_t를 사용합니다. 즉, 학습 때는 정확한 데이터를 시작으로 학습을 하지만 실제 inference 때는 모델의 예측 결과를 기반으로 다시 예측을 반복하기 때문에 오류가 점점 누적되는 것이죠.
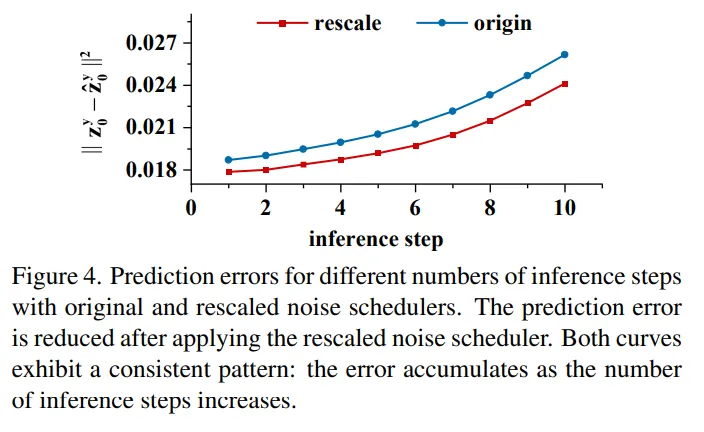
Fig.4를 보면 각 단계마다 예측되는 latent와 GT latent 사이의 RMSE를 확인할 수 있습니다. 결과적으로 보면 inference step이 많아질 수록 오류가 누적된다는 것을 보여주고 있습니다.
이를 해결하기 위해 DidSee는 단일 스텝의 학습 방식을 제안합니다. 하나의 고정된 타임스텝에서만 학습을 수행하고, inference 과정도 동일한 방식으로 단일 단계(t=T)로 진행 합니다. 이렇게 되면 학습과 inference 사이의 입력 불일치가 줄어들고 누적되는 오류를 방지할 수 있게 됩니다.
이러한 단일 스텝 방식을 수식적으로 표현하면 식(7)과 같습니다.
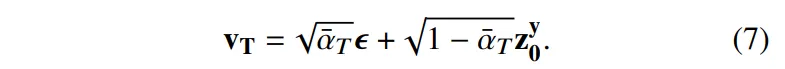
타임스텝이 T일 때 zero terminal SNR을 사용하잖아요. 그렇게 되면 v_T = z^y_0이 되어 노이즈 항이 완전히 사라지고 모델은 z^0_y을 단순하게 예측하는 학습을 하게 됩니다. 그러면 모델이 더 이상 입력 노이즈에 의존하지 않고 디코더를 통해 바로 복원된 depth map을 출력하여 GT depth와 픽셀 공간에서 직접 비교가 가능해집니다. 결국 \hat{y} = D(\hat{v}_T로 바로 복원이 가능하고, 노이즈나 타임스텝에 영향을 받지 않기 때문에 exposure bias가 없어지고 성능이 향상될 수 있습니다.
2.3. Semantic Enhancer
이제는 투명한 물체, non Lambertian 물체에 대한 depth completion을 위해 설계한 semantic enhancer에 대한 부분 입니다. 투명한 물체는 시각적으로 뚜렷한 엣지나 특징이 부족하기 때문에 모델이 이러한 물체와 배경을 명확하게 구분하는 것이 어렵습니다. 그래서 Semantic enhancer는 semantic segmentation을 활용하여 물체와 배경을 구분해서 모델이 더 정확한 depth를 예측하는 것을 도와줍니다.
Color Palette
diffusion의 VAE는 연손적인 RGB 이미지만을 처리할 수 있는데요, semantic segmentation map은 discrete 클래스 라벨로 이루어져 있어서 이를 직접 처리할 수가 없습니다. 그래서 color palette 방식을 사용해서 각 semantic 클래스에 고정된 RGB 색상을 할당합니다. 이 RGB 색상으로 semantic segmentation map을 변환하여 RGB 이미지처럼 보이지만 semantic한 정보를 담을 수 있도록 하는 것이죠. 이렇게 변환된 이미지는 연속적인 표현이기 때문에 VAE로도 인코딩이 가능해집니다.
Network Modification
그러면 이제 semantic enhancer를 네트워크 안에 어떻게 넣어줄 지에 대해 살펴보겠습니다.
본 논문의 DidSee는 한 개의 네트워크에서 depth completion과 semantic segmentation을 동시에 수행하고, 이를 위해 task switcher와 멀티 task attention을 사용한다고 합니다.
task switcher는 depth와 semantic segmentation이라는 task를 구분할 수 있는 역할을 합니다. 이는 1차원 벡터로 이루어져 U-Net 구조의 타임 임베딩에 더해집니다. 그러면 모델이 현재 어떤 task를 하고 있는지를 인식할 수 있도록 하여 지금은 “depth 예측 중”, 혹은 “지금은 semantic segmentation 중”이라는 작업 태그를 네트워크에 신호로 전달할 수 있는 것이죠.
그 다음 cross task attention은 depth와 semantic feature를 서로 참고해서 attention을 계산합니다. cross task attention을 통해 두 task 사이에 정보의 연결이 생기고, 이는 특히나 투명한 물체와 같이 시각적인 정보가 부족한 경우에 semantic 정보가 depth 예측을 보완하는 역할을 할 수 있습니다.
2.4. Loss Functions
지금 DidSee는 depth completion과 semantic segmentation을 같이 진행하기 때문에 식(8)과 같이 loss 함수를 설계하였습니다.
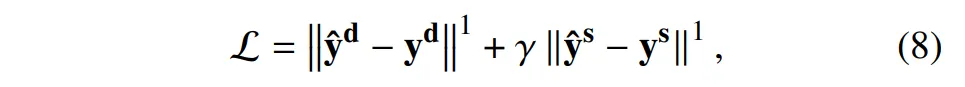
먼저 첫번째 항은 depth loss로, 예측된 depth \hat{y}_d와 GT depth y_d의 차이를 최소화 합니다. 두번째 항은 semantic loss로, 예측 semantic segmentation 이미지 \hat{y}_s와 실제 semancit segmentation 이미지 y_s 사이의 차이를 최소화하여 semantic map의 예측 오류를 줄이는 역할을 합니다. 여기서 semantic loss의 가중치는 모든 데이터셋에 대해 0.1로 고정하였는데요, 그 이유는 depth 예측이 메인 목표이기 때문에 semantic segmentation의 비중이 크지 않으면서 보조적인 역할을 하게 하기 위함이라고 합니다.
3. Experiments
실험은 TransCG, ClearPose, 그리고 DREDS & STD 데이터셋으로 평가하였다고 합니다.
3.1. Quantitative Results
우선 간단하게 각 데이터셋들에 대해 정량적인 평가를 하였습니다.
TransCG / Clear Pose
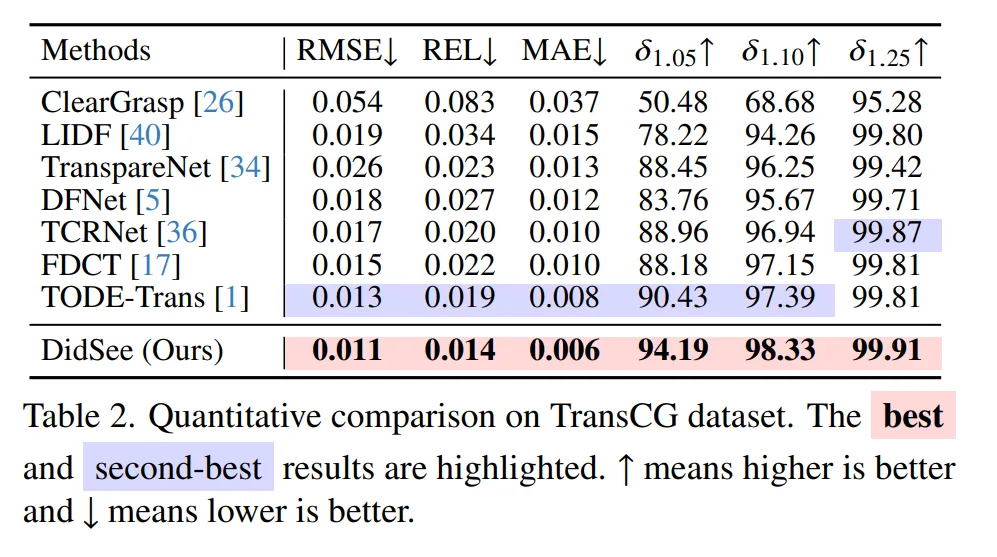
먼저 Tab.2는 TransCG 데이터셋에 대한 평가 입니다. 우선 모든 메트릭에서 DidSee가 SOTA를 달성하였습니다. 특히 이전 SOTA 모델인 TODE-Trans와 비교했을 때 RMSE, REL, MAE에서 각각 15.4%, 26.3%, 25.0%의 성능 향상을 이루었습니다.
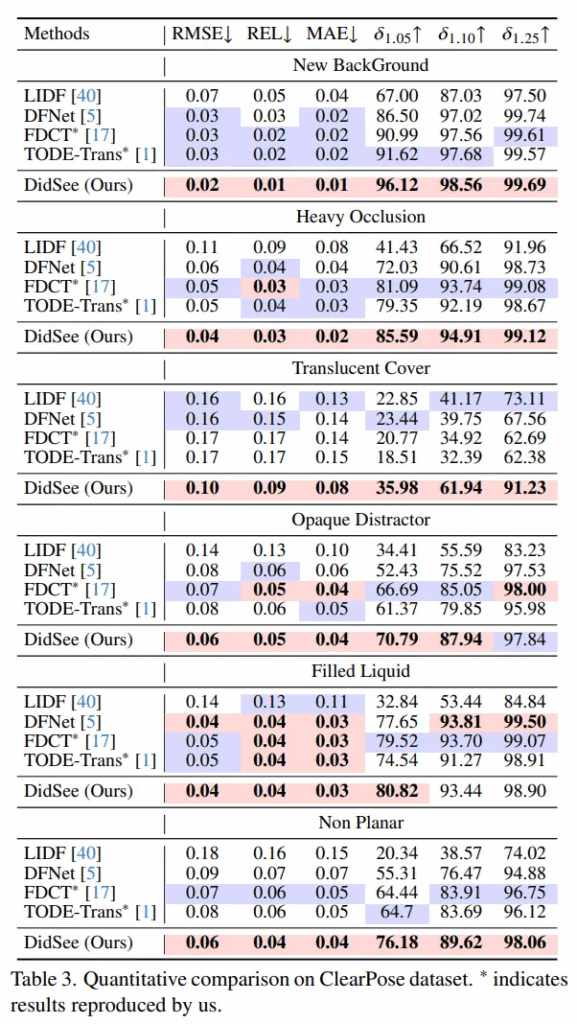
다음 Tab.3의 ClearPose는 여러 시나리오의 데이터가 포함되어 있기 때문에 더 challenge한 데이터로 다루어집니다. Tab.3을 보면 여러 테스트 scene이 있는데요, DidSee는 그 모든 scene에서 기존 방법론들보다 거의 다 좋은 성능을 보이고 있습니다. 특히 다른 모든 모델들이 전반적으로 성능이 떨어지는 Tasnlucent Cover는 반투명 덮개로 덮고 있는 장면인데, DidSee는 여기서도 확실히 좋은 성능을 보입니다. 이를 통해 반투명, 투명, 혹은 다른 식별이 어려운 물체들에 대해서 본 논문의 방법론이 효과가 있다는 것을 입증하고 있습니다.
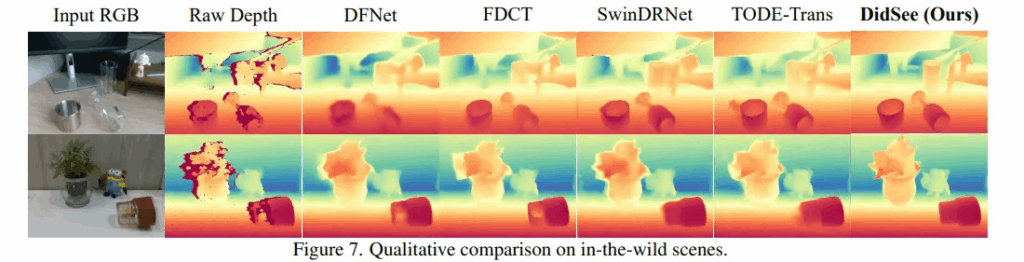
정성적 결과로 봐도, raw depth 센서에서 노이즈가 많이 발생하는 투명한 컵이나 와인잔에 대해서 정확하게 형태를 표현하고 있는 것을 알 수 있습니다. 이 외에도 내재하는 노이즈가 발생하는 부분들에 대해서 타 방법론들 대비 정확한 depth 표현을 하고 있습니다. 이는 대규모 RGB로 사전학습된 diffusion 모델이 가지고 있는 시각적인 prior의 영향으로, real 상황에서의 다양한 조건에서 효과적으로 일반화할 수 있다는 것을 보여줍니다.
3.2. Ablation Studies
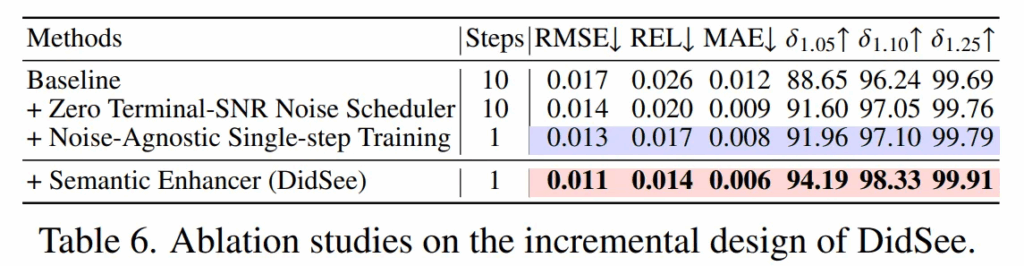
이제 ablation study로, Tab.6의 Baseline은 기본 diffusion 프레임워크를 의미합니다.
그 다음엔 zero terminal SNR만 적용하여 single leakge bias의 효과를 확인하였습니다. 성능이 REL에서 20% 이상 감소하면서 마지막 타임스텝에서의 signal leakage bias가 depth completion에 영향을 미치고 있었다는 것을 알 수 있습니다.
다음 멀티 스텝을 단일 스텝으로 변경했을 때를 보면 멀티 스텝에서 발생하는 exposure bias가 실제로 성능 저하에 영향을 준다는 것을 실험적으로 확인하였습니다.
마지막으로 semantic enhance까지 추가한 최종 모델은 가장 좋은 성능을 보이며 물체와 배경을 더 잘 구분할 수 있도록 도와주면서 depth 예측의 정확도를 높이고 있습니다.
이를 통해 논문에서 제안하는 모든 모듈들이 투명하거나 시각적으로 구분이 어려운 물체에 대한 정확도를 높이고, depth completion에서 발생하는 diffusion 모델의 문제점을 해결하였다는 것을 알 수 있습니다.
3.3. Downstream Robotic Task Evaluation
마지막으로 복원한 depth map을 두 가지 로봇 task에 적용하여 평가한 결과 입니다.
Category-level Pose Estimation
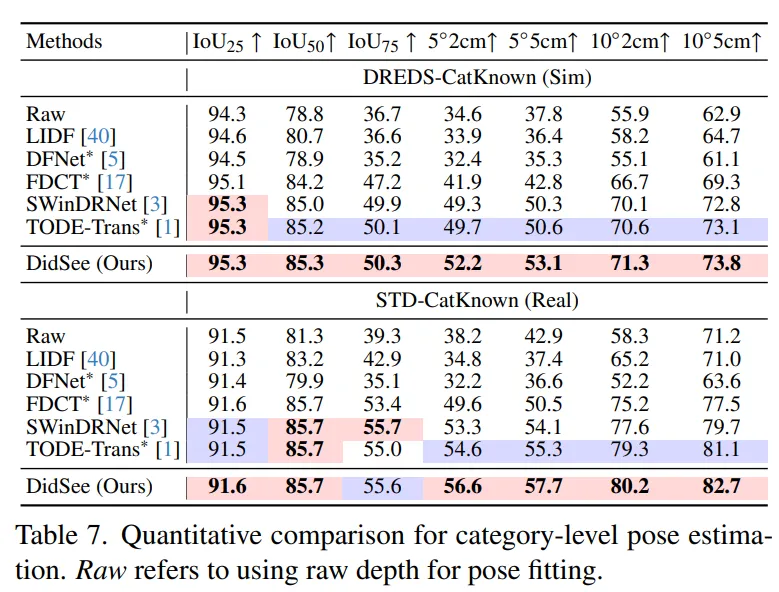
먼저 Tab.7은 카테고리 레벨의 pose estimation task 입니다.
평가에 사용한 데이터셋은 투명하고 반사되는 표면을 가진 물체들이 포함되어 있습니다.
여러 방식으로 복원된 depth map을 입력으로 사용한 pose estimation 결과들과 비교하고 있는데, 여기서도 마찬가지로 가장 좋은 성능을 보이고 있습니다.
이를 통해 복원된 depth가 실제 로봇 어플리케이션에 적용했을 때 도움이 되는 정보들을 제공할 수 있을 정도의 퀄리티를 가졌다는 것을 알 수 있습니다.
++ n°m cm는 물체의 변환 오차가 몇 cm 이하이며 회전 오차가 n도 이하일 때의 평균 정확도를 의미합니다.
Robotic Grasping
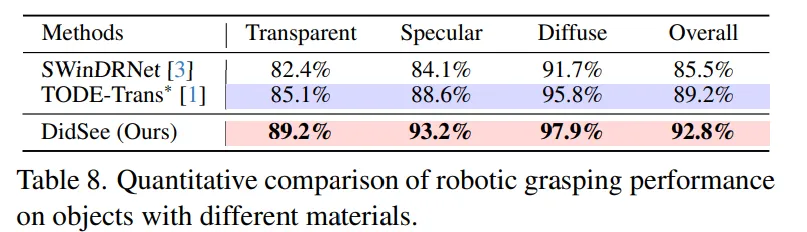
마지막은 로봇 grasping에서의 성능 평가 입니다.
성능 평가는 각 물체를 얼마나 성공적으로 잡았는지에 대한 평균 성공률 입니다.
Tab.8을 보면 타 방법론들의 depth map 대비 가장 높은 성공률을 달성하였으며, 특히나 반사되거나 투명한 물체에 대해 가장 안정적으로 grasping에 성공한 것을 확인할 수 있습니다. 이러한 결과는 다른 방법론에서 복원된 depth map을 사용하였을 때 투명/반사 표면의 물체에서 눈에 띄게 성능이 저하되는 것과 비교했을 때 물체의 특성에 상관없이 일반화를 이루고 있다는 것을 보여주고 있습니다.
안녕하세요 연구원님✌️
최근 diffusion 관련 내용을 공부하면서 time step마다 가우시안 노이즈를 준다는 구조를 당연하게 생각하고 있었는데 이번 논문을 통해 terminal snr을 0으로 두는 접근방식이 신박하게 느꼈습니다. 또한 diffusion의 기본 틀을 깨고 single-step 구조로 depth latent를 직접 예측하는 방식이 신선한 접근이라고 느꼈습니다. 하지만 이런 구조가 특정 학습 도메인이나 scene에 특화되어 일반화 측면에서 제약이 생기진 않을까 하는 부분인데요 혹시 다양한 scene이나 unseen domain에 대해 저자의 언급이나 분석이있나요? 궁금합니다
손건화 연구원님 리뷰 잘 읽었습니다
한 가지 궁금한 점이 있어 질문 남겨두겠습니다
일단 해당 논문은 Zero terminal SNR을 통해 signal leakage를 해소한 것으로 이해하였습니다. 하지만 완전한 노이즈로 학습하는 것이 오히려 학습 안정성에 악영향을 주거나 convergence가 느려질 가능성은 없었는지 궁금합니다. 또한, 이 방식이 depth completion 외의 다른 dense prediction task에서도 동일하게 효과를 낼 수 있을지, 혹은 task별로 sensitivity가 다를 가능성은 없는지도 궁금하네요!
안녕하세요. 좋은 리뷰 감사합니다.
signal leakage bias라는건 마지막 타임 스텝에서 완전한 노이즈가 아니라 조금의 원본 신호가 남아있는 현상을 의미한다고 설명주셨는데요, 어떻게 학습과 추론 사이에서 불일치가 발생하는지 이해가 잘 되지 않습니다. inference 시에는 동일 모델에서 특정 처리 없이 어떻게 마지막 스텝의 입력이 완전한 가우시안 노이즈가 될 수 있나요 ..! ? 그리고 수식 (6)에서부터 a_t에 대해 여러번 언급이 되는데 이게 정확히 무엇을 의미하는지도 궁금합니다.
감사합니다.