안녕하세요. 이번 리뷰도 Token Pruning에 관한 논문입니다. 아직 어느 학회/저널에 Accept된 것으로 보이진 않지만, 21회의 Citation 수를 보입니다. 논문 제목도 찾아보면 Revised 버전에 따라 다르게 짓는데, 지금의 제목은 논문에 적힌 제목은 아닌 저자 깃의 이름입니다. 그럼 Introduction을 살펴봅시다.
Introduction
늘상 Token Pruning이 하는 이야기처럼, CLIP을 통해 나오는 Visual Token의 수는 576 (336×336)인 반면 Text Token은 100개 미만이니, 이를 줄임이 중요하다는 입장입니다. 이는 저번 세미나에서도 말했듯, Visual Token을 줄이는 방식의 일환입니다. LLaVA-NeXT나 Video-LLaVA의 경우에는 더 큰 해상도, 프레임 수의 증가 등으로 인해 각각 2880, 2560의 Visual Token을 가지게 됩니다. 세미나에서 소개해드린 FastV의 경우는 LLM에서 초기 단계 레이어부터 Less-Attention Token을 줄이기 위한 방식을 소개했습니다. 하지만 저자는 다음과 같이 이야기합니다. “text-visual attention within the language model may not be an ideal indicator for token pruning.” 즉, LLM의 텍스트와 비전 토큰간의 Attention Score를 활용함은 이상적이지 않다는 것입니다. 그 이유로 아래의 Figure를 예시로 드는데, 즉 이전 FastV를 보면 텍스트와 비전 토큰 간의 연산으로 얻은 결과는 여전히 Position Bias로 인해 주로 이미지 하단 부의 토큰이 중요한 토큰처럼 여겨진다는 것입니다. 반면 이미지 중단부, 또는 실제로 객체가 존재하는 위치는 오히려 Attention Score으로 보면 Less-Attention 토큰으로 여겨져 중복되거나 정보량이 적은, 버려지는 토큰으로 처리됩니다.
세미나에서 말했던 바처럼, 요즘의 Token Pruning은 분석이 특히 중요합니다. 저자는 분석을 통해 둘을 찾아내었습니다. (1) Text-visual attention shift: 위에서 언급한 Position Bias의 이유입니다. Transformer의 Rotary Positional Embedding (위치 정보를 기존 Cos-Sin 방식보다 더 정교하게 넣기 위해 설계된 방식)의 Long-term Decay 현상으로 인해 [Image, Text]처럼 이미지와 텍스트가 같이 입력이 되는 경우 텍스트 토큰이 입력 상 뒤에 있을수록, 물리적으로 가까운 Image 토큰 (Image 토큰 – Text 토큰의 순서이니 물리적으로 Image 토큰이 먼저 입력됩니다. 그렇다면 이 때 Text 토큰과 가까운 Image 토큰은 곧즉 Image 토큰의 후반부, 이미지 하단부가 됩니다)에 Text 토큰이 집중합니다.
(2) Text-visual Attention Dispersion: (앞선 (1)의 문제인) 시각 토큰의 위치 임베딩을 조절해서 Position Bias를 없앤다 할지언정, Attention의 고르게 분포하여(Entropy는 높은데, Peak는 낮음) 마치 모든 Visual Token이 중요하거나 또는 중요한 것처럼 보이지 않는, 즉 중요한 정보를 콕 찝어 뽑아내기엔 어렵고 이는 곧 Attention Score를 기준으로 Pruning하면 실제로 중요한 Token이 가지치기될 확률을 높이는 것과 마찬가지이므로, 성능이 크게 줄어든다 (FastV가 Random보다도 성능이 낮은 것도 이와 유사한 결과)

위 두 문제를 극복하고자, 저자는 VisPruner라는 방식을 제안합니다. Visual Cue를 활용하여 Effective Token Pruning을 위하며, 이 모듈을 Plug-and-play (떼어냈다 붙였다하는) 방식으로 쓰일 수 있습니다. 논문 제목에서와 같이 [CLS] 토큰을 적극 활용할 방법이지 않을까 추측됩니다. 방법론에서 조금 더 자세히 살펴봅시다.
Text-Visual Attention Investigation
우선 앞서 말씀드린 내용처럼, 사실 Token Pruning이라는 것을 8장의 논문에서 2-3장 가까이 방법론을 적기엔 쉽지 않습니다. 때로는 방식이 단순해서 일수도, 또는 설계한 방식에 대한 증명이 쉽지 않기 때문일 수도 있습니다. 그렇기에 지금 섹션처럼, 기존 방식의 문제점이나 또는 LLaVA와 같은 MLLM에 대한 통계적인 고찰로부터 시작합니다.
이미 이전 리뷰들에서 LLaVA(MLLM)의 과정 (CLIP 이미지 인코더 – LLM (LLaMA))에 대해서는 자세히 설명하였으니, 이는 넘어가고 하나 모를법한 Relative Rotary Position Embedding (RoPE)에 대해 알아봅시다. 우선 LLM의 입력 시퀀스는 단순히 텍스트가 아닌 [시스템 토큰 – 이미지 토큰 – 텍스트 토큰]으로 구성됩니다. 이 때의 Attention 수식은 우리가 잘 아는 내용과 같이, 아래의 수식으로 계산됩니다. (지금 LaTex가 안되어) R은 Rotary Embedding을 위한 회전 행렬, M은 Casual Mask (하삼각 행렬)에 해당하며, 이 둘은 원래의 Transformer에서 Position Embedding 시 Absoulte 방식으로 토큰의 위치 정보를 더해줬지만 이는 토큰 간의 상대적 거리 정보 인식에 어려움이 있으므로, 회전 행렬을 도입하여 상대적인 위치 정보를 곱하는 방식으로 Position Embedding을 수행하며 이에 대한 더 자세한 내용이 궁금하시다면 다음 링크의 블로그를 참고하면 좋을듯 합니다.
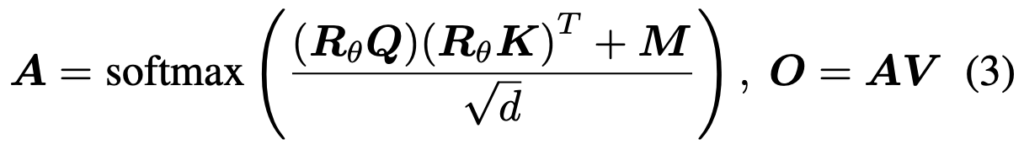
Text-visual attention shift
Introduction에서 언급한 두 문제점 중 첫 번째, FastV와 같이 Attention Score 기준으로 중요한 비전 토큰이 주로 이미지 하단부가 되는 문제에 대한 분석입니다. 이미 앞서 글로 설명을 드렸지만, 자료와 함께 살펴봅시다. 저자는 LLaVA-mix665k 데이터로부터 샘플을 뽑아 FastV를 적용해보았습니다 (Layer 2 이후 75% Pruning).
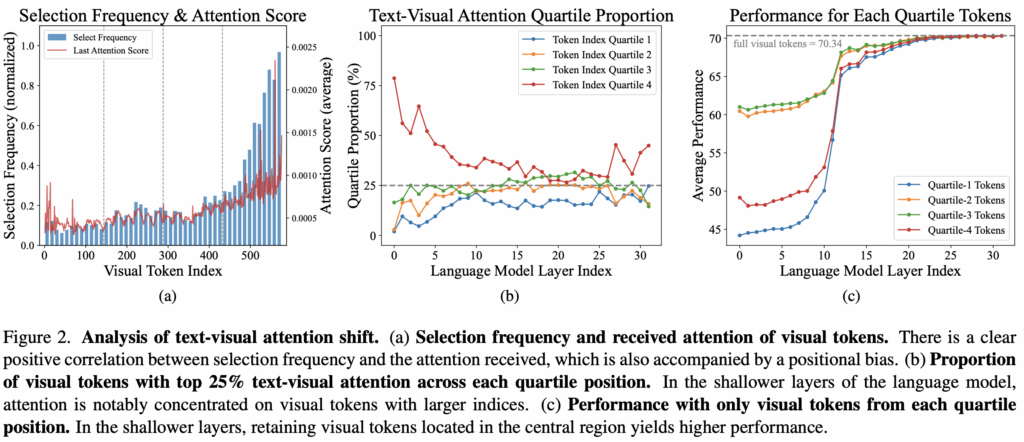
위 Figure 2-(a)는 이를 보여주는 결과로, 파란색 막대는 어떤 Visual Token Index가 자주 선택되었는지, 빨간선은 마지막 텍스트 토큰 ([EoS])이 해당 Index의 Token에 Attention이 어떻게 되고 있는지를 나타냅니다. 결과적으로 Visual Token Index와 Attention Frequency에는 양의 상관관계, 즉 Visual Token Index가 후반부로 갈수록 Attention을 더 많이 받으며, 이는 앞서 저자가 말한 RoPE로 인해 위치적으로 더 가까운 후반부 Visual Token이 영향을 많이 받기 때문입니다 (RoPE 방식의 Long-term Decay).
Figure2-(b)를 보면 LLM 레이어가 깊어짐(Index)에 따라 Attention 분포의 변화를 보입니다. Quartile은 576개의 토큰을 1/4로 나누어 Quartile1 (초반부, 이미지 상단부) – Quartile4 (후반부, 이미지 하단부)로 표기하였으며 결과적으로 Attention은 Quartile 4, 이미지 하단부가 많이 받으며 이는 특히나 Shallow Layer, 즉 Layer 0-5 사이에서 가장 강하게 나타남이 확인되었습니다. 저자는 이 결과로, 다음의 자연스러운 질문을 던집니다. “In the presence of inherent positional bias, do higher attention scores necessarily represent richer visual information?” Positional bias가 내재되어 있는데, Attention score가 높다고 풍부한 정보가 있다고 볼 수 있냐는 질문입니다. 위의이 Quartile을 활용해 특정 범위의 Quartile만 남겼을 때 (나머지 Quartile을 Pruning했을 시)의 성능을 보면 (Figure2-(c)),평균적으로 성능이 Quartile2-3이 Shallow Layer에서 Pruning을 진행해도 성능이 잘 보존됨을 확인할 수 있습니다. 이는 곧 이미지 중앙부가 대체로 객체가 많이 포진되다 보니, 상단부나 하단부에 비해 훨씬 효과적임이 증명됩니다. 이는 곧 다시 말해, Fig2-(a)/(b)의 경향성 (Quartile 4가 높은 Attention을 보인다)과는 차이를 보입니다.
Text-visual attention dispersion
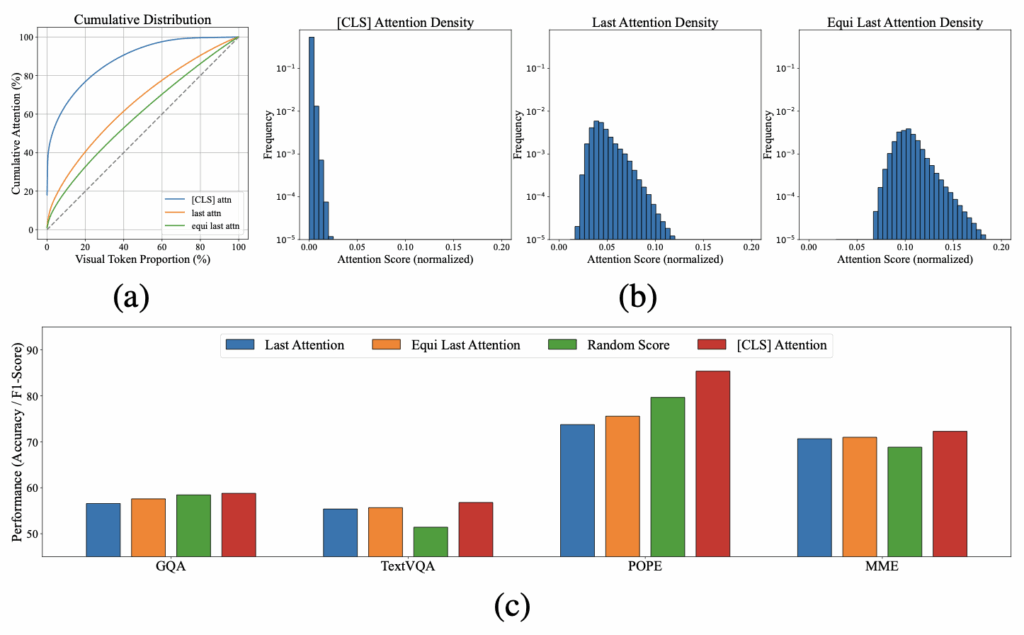
두 번째 분석은 Attention Dispersion(분산)에 관한 내용입니다. 앞서 Positional Bias가 문제임을 알아내었으니, 직관적으로는 위치 임베딩의 감쇠 효과가 없는 Text-visual Attention을 Pruning의 기초로 활용하는 것을 생각할 수 있습니다. 하지만 저자는 그렇게 하더라도, 또 다른 Attention Dispersion 문제가 있음을 밝힙니다. 구체적으로 모든 비전 토큰에 동일한 Position Embedding을 적용한 상태에서 마지막 텍스트 토큰의 Attention을 equi last attention으로 정의하고 시각화 한 위 Figure3-(a)/(b)는 누적 분포 곡선을 살펴봅시다. 그 결과, [CLS] 토큰은 훨씬 Attention이 높아 상위 20%의 토큰이 전체의 80%를 차지하고 있습니다. 반면, Text-Visual Token은 위치 임베딩을 제거하든(equi last attn) 아니든 (last attn), 거의 y=x꼴의 누적 분포를 보입니다. 누적 분포임을 잊지 않고 해당 그래프를 잘 해석해봅시다. 그럼 우리는 다음과 같이 알 수 있습니다. [CLS] 토큰과 비교 시, Text-Visual Token은 대체로 Entropy가 높고 Peak가 낮습니다. 고르게 퍼져있다는 말이죠. 이를 다르게 말하면 실제로 이 Text-Visual Token은 실제로 중요한 토큰이 무엇인지 잘 알지 못한다는 것과 같습니다. Figure3-(c)의 다양한 LLaVA-Benchmark (GQA, TextVQA, POPE, MME)에서 Random을 포함한 것들과 비교해볼 때, Random에 비교할 때도 [CLS] Attention은 높은 성능을 보이는 반면, 다른 방식으로 Pruning 진행 시에는 대체로 낮은 또는 비슷한 성능을 보임을 확인할 수 있습니다. 이 분석을 통해 저자가 하고자 하는 말은 [CLS] 토큰이 핵심이라는 점입니다. 이것이 논문의 제목이 왜 [CLS]로 시작하는지를 알 수 있습니다.
Exploiting Visual Cues for Token Pruning
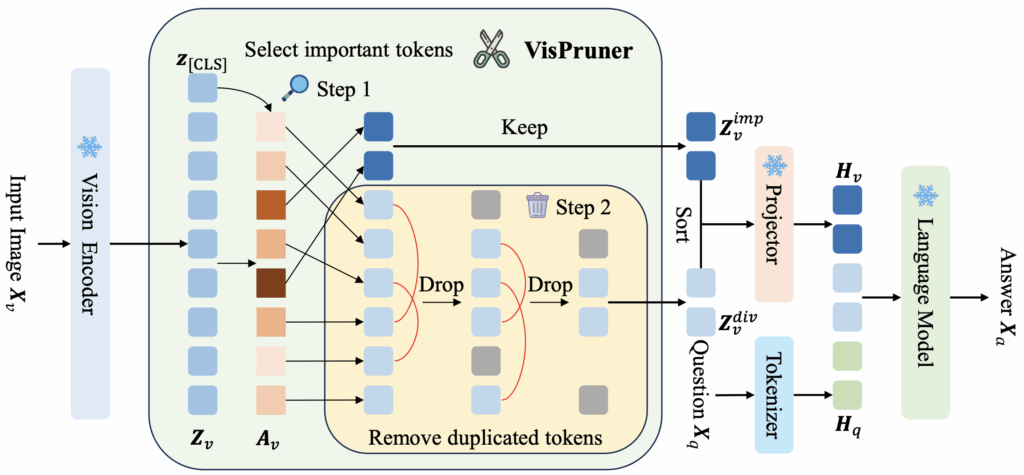
저자가 제안하는 VisPruner에 대해 살펴보겠습니다. 핵심은 Text-visual의 Attention Score는 앞서 언급한 문제로 부정확한 지표이다 보니, Vision Encoder의 Attention Score를 활용하려 합니다. 이 때 전체 정보를 요약하는 [CLS] 토큰을 활용합니다. [CLS] 토큰이 존재하지 않는 SigLIP과 같은 모델은 Attention 행렬의 모든 행을 평균 내어 각 토큰이 다른 모든 토큰으로부터 받은 평균 Attention을 계산합니다. 이후에는 간단히 기존의 방식과 같이 하이퍼파라미터인 Pruning 퍼센티지(%)를 기준으로 토큰을 Pruning합니다. 결국 저자는 CLIP의 [CLS] 토큰을 활용한다, 논문 제목에 충실하긴 하지만 사실 개념 상으로는 Fancy하다고 보기는 어려운데, 앞서 1.5-2장 분량으로 “왜 Text-visual Attention”을 활용하면 안되는지에 대해 자세한 분석을 하였다 보니 그것을 인정받지 않았을까 싶습니다.
그런데, Visual Attention은 주로 Foreground에 집중됩니다. 때로는 Background를 담은 이미지 전반적인 내용도 필요합니다. 이를 위해 우선 다양한 위치의 토큰들을 바로 Pruning하지 않고 남겨둡니다. 이후, 예를 들어 전체 100개의 토큰에서 50%의 토큰을 줄여야한다고 하면 50개가 남아야합니다. 그럼 우선 100개 중 3-40개 정도의 토큰을 [CLS] Attention Score로 선택한 이후, 임의 위치의 토큰을 몇 십개 정도 더 추가합니다. 예를 들어 추가한 이후 70개 정도의 토큰이 되었다고 하죠. 그럼 이것을 50개로 맞추기 위해 20개의 토큰을 다시 Pruning해야 하는데, 이전 위 과정에서는 “중요한 정보를 추출해내는” Pruning이였다면, 이번에는 전체 토큰 간의 유사성을 계산하여 “중복되는 정보를 제거해나가는” Pruning을 진행합니다. 막상 방법론 자체는 기존의 방법론들에서 새로운 인사이트를 찾기는 어려웠습니다.
Experiments
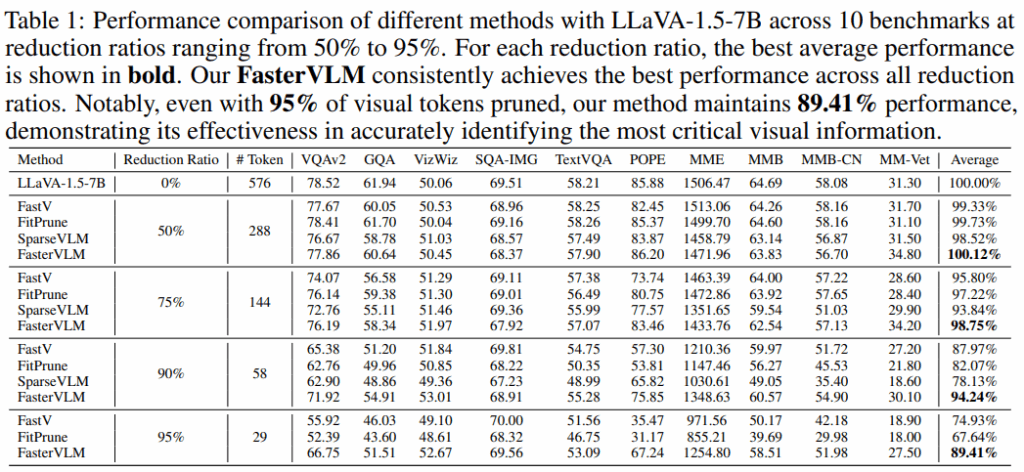
main result를 보면, reduction ratio를 0/50/75/90/95% reduction 시의 성능을 보입니다. LLaVA-Bench에서 수행되었을 때, 이전의 FastV/FitPrune에 비해 월등히 뛰어난 성능을 보입니다. 심지어 50% Reduction 시에는 Token Pruning을 진행하지 않은 LLaVA-1.5-7B에 비해 오히려 성능이 높은 모습을 보입니다.
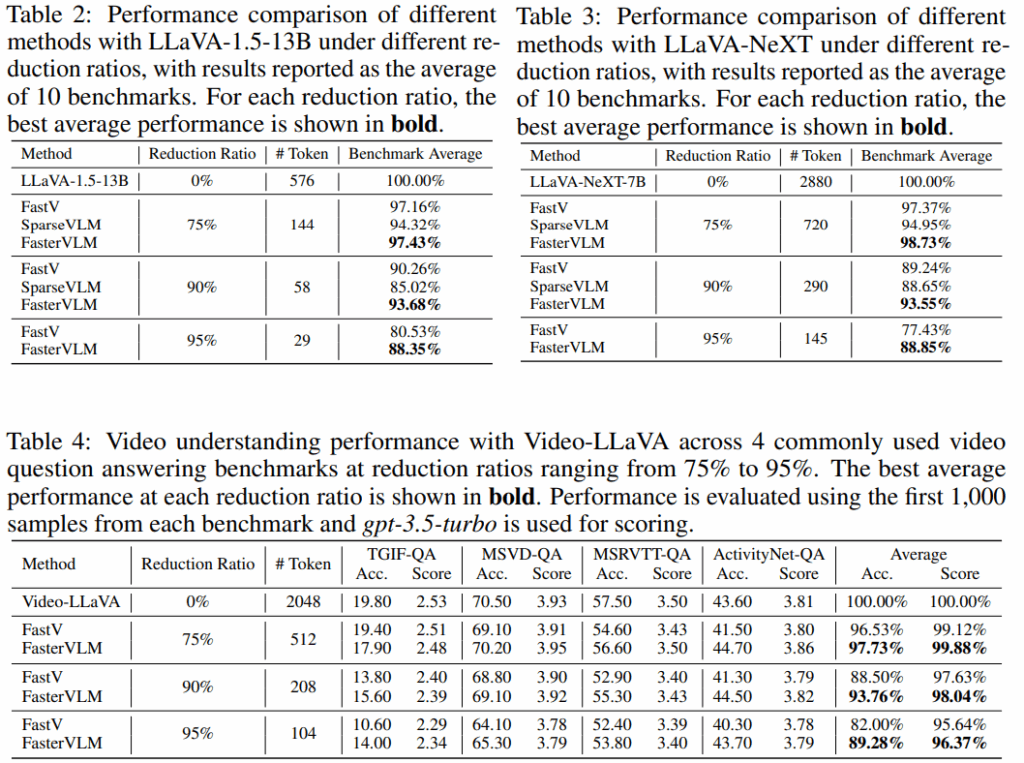
그 외 LLaVA-1.5-13B/LLaVA-NeXT/Video-LLaVA에서도 FastV/SparseVLM 대비 높은 성능을 나타냅니다. 이는 다시, 높은 성능이 고해상도 이미지에 대해서도 효율성을 증명함을 나타냅니다.
상인님 리뷰는 항상 잘 읽고있습니다.
한가지 궁금한 점이 있어 댓글 남겨두겠습니다.
일단 Text-Visual Attention의 positional bias와 dispersion 문제를 분석한 것 같습니다. 그런데 궁금한 점은, CLIP의 Visual Attention만으로 중요한 정보를 판단하는 것도 결국 Text-free한 방식이기 때문에 task-specific relevance 판단이 어려울 수 있지 않을까 라는 생각이 들었습니다? 예를 들어 동일한 이미지에서도 질문(prompt)에 따라 중요한 객체가 달라질 수 있는데, 이때 Visual Attention만으로 판단하는 것이 항상 적절할지에 대한 저자의 생각이 있는지, 없다면 상인님의 생각이 궁금해지네요
안녕하세요. 리뷰 읽어주셔서 감사합니다.
우선, 질문에 대해 전적으로 동의합니다. 저도 Task-specific relevance라는 점을 대응하기 위해서는 Text-relevance해야한다고 생각합니다.
우선 현재의 벤치마킹은 LLaVA-Benchmark로, QnA가 주됩니다. 그렇기에 아마 우려하는 Prompt에 따라 중요한 객체가 달라질 수 있는 점이 많이 나오지 않았으리라 생각합니다.
왜냐하면 주로 전체적인 이미지를 모사하거나, 아니면 그다지 복잡하지 않은 장면에 대한 질의-응답 수준이기 떄문입니다. 저도 역시 그렇기에 특히 VG와 같은 태스크에서는 Text가 연관되어야 한다는 입장입니다 (제가 직접 실험하는 지점도 이 주장이 포함되어 있습니다)
안녕하세요 이상인 연구원님 좋은 리뷰 감사합니다.
리뷰의 실험중에서 이미지 중간 부분에 객체 정보가 주로 포진되어있기에 해당 영역을 보존하는게 효과적이였다는 설명을 본 것 같습니다. 존재하는 공개 데이터의 대부분이 이러한 특징을 갖고있는 것으로 알고있는데요, 그렇다면 이러한 데이터셋 기반의 분석에 편향등의 오류가 포함될 수 있을까 우려됩니다. 이에 대한 해당 분야의 관점, 대응법이 있을까요?
또한 비교적으로 다양한 영역을 다루는 VQA 테스크의 경우 이러한 편향 문제가 덜할것 같은데, 해당 테스크를 중점으로 분석하면 이러한 문제가 해결될까요? 이에 대한 상인님의 의견이 궁금합니다
안녕하세요. 리뷰 읽어주셔서 감사합니다.
제 생각컨데, 데이터셋 기반의 분석에 편향등의 오류가 분명 있을 수 있습니다. 또, 아래 주영님의 질문처럼 특정 태스크에 대한 편향도 존재할 수 있습니다. VQA와 관련된 태스크는 해당 편향 문제가 덜할 것임도 맞지만, 막상 VQA도 역시 Question이 장면에 대한 Coner-case까지 묻는 경우가 잘 없으므로 편향이 존재할 수도 있다는 생각은 합니다.
아마 이런 편향으로 인한 오류라고 정의해야할까요, 그 문제를 가장 잘 보여주는 것은 역시 Perception/Grounding과 같은 태스크라고 생각이 됩니다. 그런 점에서 VQA보다도 제 생각에는 인지와 관련된 태스크를 중점으로 분석함은 어떨까싶습니다.
하이요. 제가 이전에 pruning 리뷰들을 챙겨보지 못해서 그런지 리뷰 내용 중 이해를 못한 부분이 있어서요.
결국 pruning에서 중요한 것은 어떤 토큰들이 중요한 토큰들인가?를 잘 정의해서 찾아내는 것이 목표이고 저자들은 여러 분석 끝에 CLS token이 중요 토큰을 찾는 중요한 역할을 한다고 이해를 했습니다. 근데 정작 CLS token으로 중요한 token들을 살리고 불필요한 토큰들을 지우는지에 대한 과정이 이 리뷰에는 나와있지 않는 것 같은데 어떻게 동작한다는 건가요? CLS token과 그 외에 토큰들 사이에 코사인 유사도를 계산하는건가요? 아니면 QK attention 스코어를 계산해서 연관성이 없는 아이들을 제거하는건가요?
그리고 모델을 어떻게 학습시켰느냐에 따라서 경향성이 달라질 것 같은데 저자들이 집중한 모델들은 CLIP과 같은 방식으로 학습한 모델들이라고 이해하면 될까요?
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
아, 네 제가 여태 몇 번 리뷰와 세미나를 이 주제로 하며 새로운 Pruning 전략이 아니면 짚고 넘어가진 않았습니다.
지금 논문도 마찬가지, 새로운 Pruning 기준을 제시하지 않은 논문도 마찬가지로 (즉, 일반적인 경우) [CLS]토큰은 Query로 두고, 다른 Vision Token을 K,V로 두어 Attention Score를 뽑아내어 Top-K개를 살리는/나머지를 죽이는 방식입니다. 보통 이러한 방식은 LLaVA에서 수행되는데 (LLaVA라 해도 결국 Vision Encoder만으로 크게 보면 CLIP), 물론 모델 자체(LLaVA)의 학습 방식에 따라 그 경향성이 달라질 수는 있지만 지금은 그렇게 학습시킨 이후, inference시에 training-free로 적용하는 방법이기에 경향성이 다를 수 있어도 그것부터 시작한다고 생각하면 좋을 것 같습니다.