오늘도 Video-Text Retrieval 논문에 대해 리뷰해보겠습니다. 논문 제목 중 VLA가 있어서 어라 싶으신 분들도 있겠지만, 여기서 A는 Action 이 아닌 Alignment 입니다 ㅎㅎ 리뷰 시작하겠습니다.

- Conference: CVPR 2025
- Authors: Leqi Shen, Guoqiang Gong, Tianxiang Hao, Tao He, Yifeng Zhang, Pengzhang Liu, Sicheng Zhao, Jungong Han, Guiguang Ding
- Affiliation: School of Software, BNRist, Tsinghua University, Hangzhou Zhuoxi Institute of Brain and Intelligence, JD.com, GRG Banking Equipment Co., Ltd., South China University of Technology
- Title: DiscoVLA: Discrepancy Reduction in Vision, Language, and Alignment for Parameter-Efficient Video-Text Retrieval
1. Introduction
기존의 CLIP 모델은 이미지-텍스트 간의 정적인 관계를 학습한 모델입니다. 하지만 비디오-텍스트 검색에서는 시간 흐름과 연속적인 장면을 고려해야 하므로 단순히 CLIP을 그대로 사용하는 것에는 여러 한계가 존재합니다. 예를 들어, 요리 과정을 담은 비디오에서 “우유를 붓는 장면”이나 “칼질하는 장면”은 서로 다른 이미지이지만 하나의 내러티브로 연결되어 있죠. 아래 그림에서 image-level 이 바로 그 예시입니다.
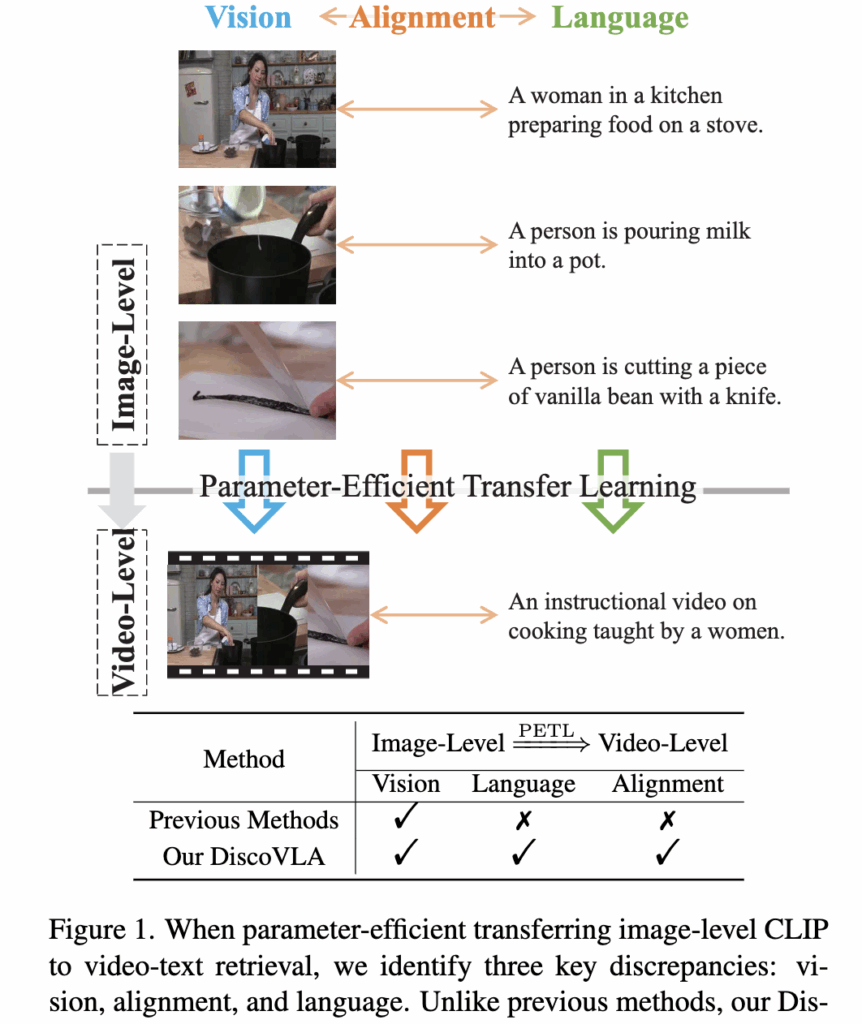
기존 방법들은 주로 영상의 시각적 특성만을 보완하는 데 집중했지만, 언어 표현의 복잡성과 이미지-텍스트 간 정렬 방식의 차이까지 고려하지 못했습니다. 즉, 상단 그림처럼 Video-level 까지 고려하는 것이 어려웠죠. 따라서 해당 논문에서는 시각, 언어, 정렬의 세 가지 차이를 모두 줄이는 DiscoVLA라는 방법을 제안하였습니다.
이 방법은 이미지와 비디오 레벨의 feature를 함께 다루고(IVFusion), 이미지별 pseudo-caption을 생성하여 세밀한 정렬을 학습하며(PImgAlign), 이미지 레벨에서 배운 정렬 정보를 비디오 레벨으로 전이하는(AlignDistill) 방식이라고 합니다. 중요한 점은 이 모든 과정이 소량의 추가 파라미터로만 이루어진다는 점에서 효율적이라는 것입니다.
이러한 방식 덕분에 DiscoVLA는 기존 방법보다 더 적은 파라미터로도 더 뛰어난 비디오-텍스트 검색 성능을 달성하였다고 합니다. 결국 해당 논문은 CLIP을 사용하되, Text-Video Retrieval 을 위해 효율적으로 Fine-tuning 하는 방식을 제안한 논문이라고 정리할 수 있겠네요, 본격적인 리뷰 시작하겠습니다.
2. Method
저자가 제안하는 DiscoVLA는 기존 이미지-텍스트 기반 모델(CLIP)을 비디오-텍스트 검색으로 전이할 때 발생하는 세 가지 차이점 “시각(Vision), 언어(Language), 정렬(Alignment) “을 동시에 해결하고자 제안된 방법입니다.
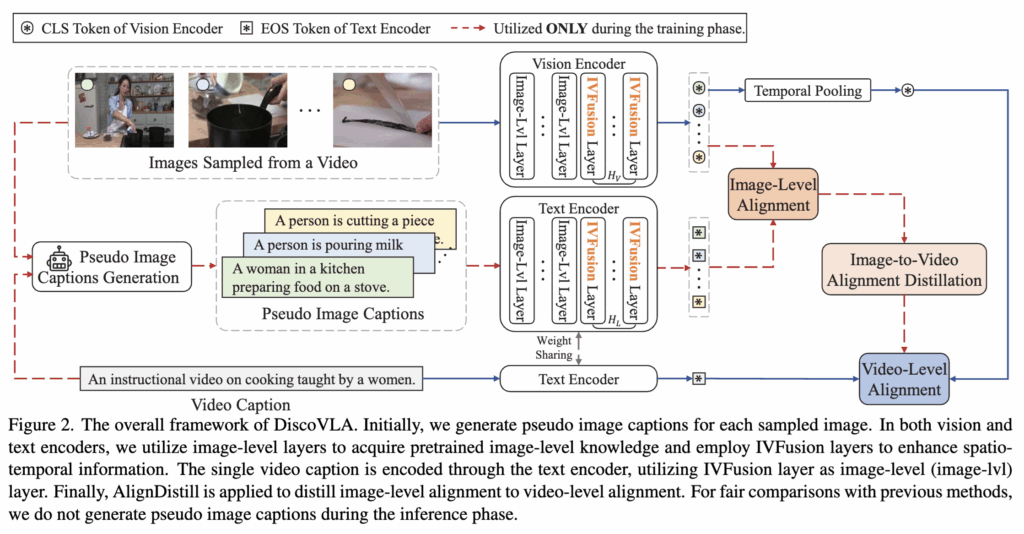
DiscoVLA이 집중한 문제는 “파라미터 효율성”인 만큼, 기존 CLIP 백본은 고정하여 소량의 추가 파라미터만 학습하였습니다. 이러한 효율적인 파라미터 학습 구조는 각 인코더 층의 attention 모듈 안에 경량화된 방식으로 삽입되었다고 합니다.
2.1 Image-Video Features Fusion
비디오-텍스트 검색에서 중요한 문제 중 하나는 이미지와 비디오 단위의 표현 방식이 서로 다르다는 점입니다. CLIP 같은 기존 모델은 이미지 단위의 특징만 잘 처리할 수 있지만, 시간에 따른 변화나 움직임을 포함한 비디오 정보까지 포괄하기에는 한계가 있습니다.
이를 해결하기 위해 저자들은 이미지 단위의 특징을 유지하면서도 시공간 정보를 통합할 수 있도록 IVFusion 모듈을 제안합니다. IVFusion은 세 가지 attention 구조를 결합하여 연산 효율성과 표현력을 동시에 확보하였습니다 (아래 그림 3 참조).
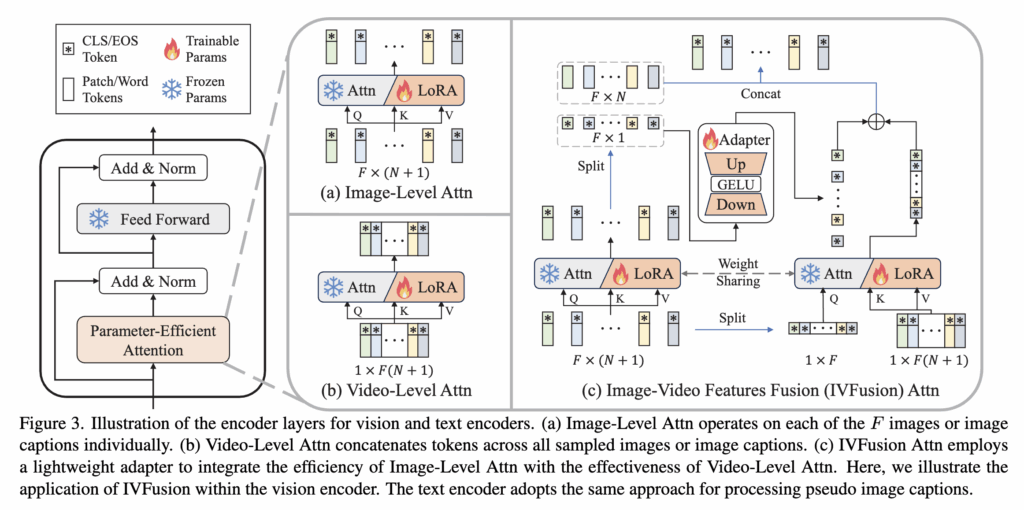
- Figure 3 (a) Image-Level Attention: 각 프레임을 독립적으로 처리하며, 이미지별로 CLS + patch token을 입력받아 attention을 수행합니다. 시간 정보는 반영되지 않지만, 연산량이 작고, LoRA 기반의 경량화 구조로 효율적인 학습이 가능합니다.
- Figure 3 (b) Video-Level Attention: 여러 프레임의 토큰을 모두 결합하여 한 번에 attention을 수행함으로써 시공간 정보를 학습합니다. 하지만 계산 복잡도가 O((FN)^2)로 높아 실용성이 떨어질 수 있습니다.
- Figure 3 (c) IVFusion Attention: 위 두 방식의 장점을 결합한 구조. 각 프레임의 CLS 토큰을 모아 spatio-temporal attention을 수행하고, 이를 다시 개별 이미지 정보와 통합합니다. 이때 사용되는 Adapter는 low-rank 구조와 GELU 활성화를 적용하여 효율적으로 두 정보를 융합합니다. 복잡도는 O(F(N)^2 + F^2N)로 줄어들며, 시공간 정보를 효과적으로 반영할 수 있습니다.
전체 vision encoder는 shallow layer에서 Image-Level Attention을, 상위 H_v개 layer에서는 IVFusion Attention을 적용하여, 점진적으로 시공간 정보를 통합합니다. 이 구조는 CLIP의 사전학습 정보를 유지하면서 비디오 수준의 표현력을 보완하는 데 효과적이라고 정리할 수 있겠네요.
2.2 Pseudo Image-Level Alignment
기존 비디오-텍스트 검색 방식은 대부분 비디오 전체와 텍스트 간의 정렬에 초점을 맞추었기 때문에, 개별 프레임 수준의 세부 정보는 잘 활용하지 못하는 문제가 있었습니다. 이를 해결하기 위해 DiscoVLA는 학습 시에만 사용되는 PImgAlign 모듈을 도입하였습니다.
핵심은 각 프레임에 대해 Pseudo Image Caption을 생성하고, 이미지와 캡션 간의 유사도를 학습함으로써 더 정밀한 alignment를 확보하는 것입니다. 다만 VTR 데이터셋에서는 프레임 단위의 캡션이 존재하지 않기 때문에, 저자들은 멀티모달 LLM인 LLaVA-NeXT를 활용하여 각 프레임에 대해 캡션을 생성하였습니다. 이때 사용되는 프롬프트는 다음과 같습니다:
The provided image is a frame sampled from the video, which describes {video caption}. Based on the video’s content, provide a caption for the provided image.
이렇게 생성된 캡션은 텍스트 인코더에 입력되어 임베딩되며, 시공간 정보 추출을 위해 IVFusion을 통해 처리됩니다. 이후 이미지와 캡션 간 유사도 행렬을 구성하고, 각 행/열에서 최대값을 추출하여 최종 image-level similarity를 계산합니다.
해당 유사도는 아래와 같이 정의됩니다:
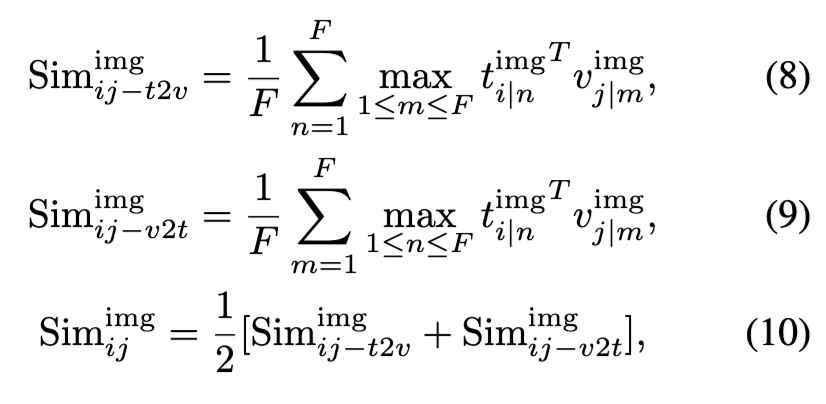
이 구조는 이미지 수준에서 정렬을 정교하게 수행할 수 있도록 하며, 공간적 세부 정보를 강화합니다. 하지만 추론 시에는 프레임 단위 캡션이 존재하지 않기 때문에, 해당 모듈은 inference에서 제외됩니다. (LMM 추론하는 데 시간이 오래걸리는 것도 그 이유 중 하나겠죠?)
2.3 Image-to-Video Alignment Distillation
DiscoVLA는 이미지 수준의 정렬 성능이 우수한 CLIP을 기반으로 하지만, 비디오-텍스트 검색에는 시공간적 정렬 능력이 추가로 요구됩니다. 이를 해결하기 위해 AlignDistill 기법이 제안되었습니다.
AlignDistill은 학습 과정에서 이미지 기반 정렬 분포와 비디오 기반 정렬 분포 간의 Kullback-Leibler (KL) divergence를 최소화하여, 정렬 정보를 효과적으로 전이(distill)합니다.
수식으로 설명드리면 먼저, 텍스트-비디오와 비디오-텍스트 유사도를 각각 다음과 같이 정의합니다:
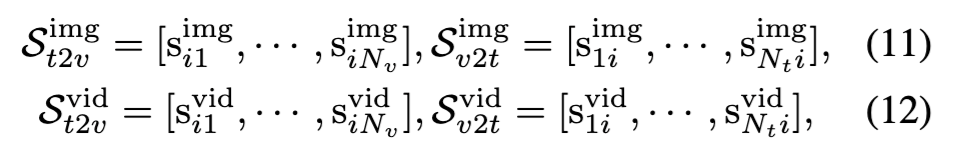
그리고 KL divergence 기반의 distillation 손실은 다음과 같습니다:
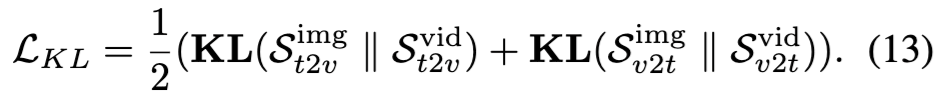
즉, 이 Loss의 목적은 이미지-기반 정렬 분포가 비디오-기반 분포와 유사해지도록 유도함으로써, 모델이 시공간적 정보를 학습하는 것이죠.
이제, 최종 학습 Loss는 다음과 같이 세 가지 손실을 결합하여 구성됩니다:
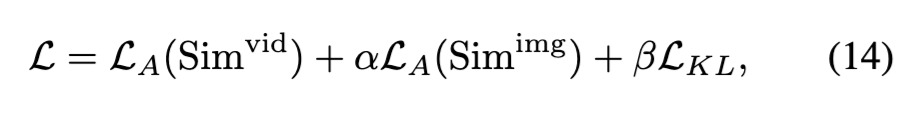
- \mathcal{L}_A(\text{Sim}^{\text{vid}}): 비디오 레벨 alignment loss
- \mathcal{L}_A(\text{Sim}^{\text{img}}): 이미지 레벨 alignment loss
- \mathcal{L}_{KL}: 위에서 설명한 KL 기반의 distillation loss
정리하면 AlignDistill은 이미지 수준에서의 정렬 정보를 비디오 수준으로 효과적으로 전달하여, 시공간 정렬 성능을 향상시키는 데 중요한 역할을 합니다.
3. Experiments
3.1 Experimental Settings
- <Dataset>
- MSRVTT
- LSMDC
- ActivityNet
- DiDeMo
- <Evaluation Metric>
- Recall at K (K = 1, 5, 10),
- the sum of these recalls (R@sum),
- Mean Rank (MnR)
3.2 Comparison
Table 1 – MSRVTT 성능 비교
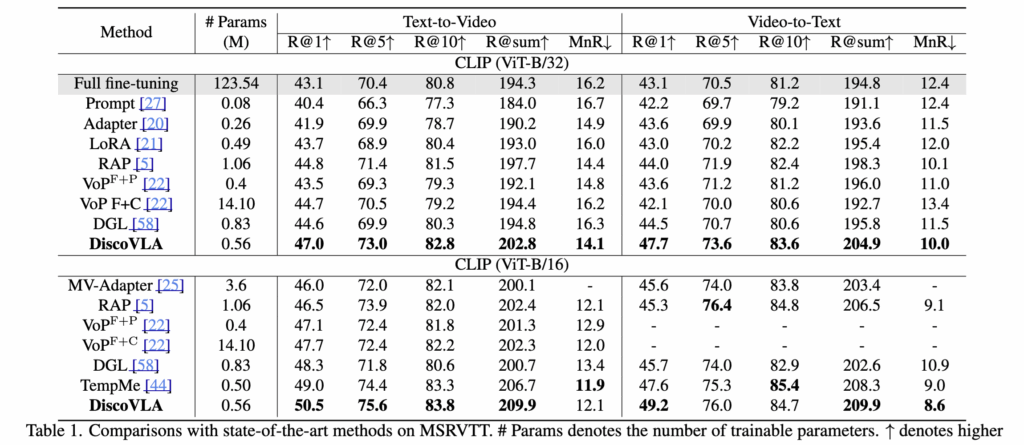
- 기존 PEFT(Prompt, Adapter, LoRA)는 시간 정보 학습이 부족하여 한계가 있음
- RAP, VoP 등은 시간 정보를 반영했지만 모델 크기나 효율성 측면에서 제약이 있음. (예를 들어 full fine-tuning 필요하거나, ViT attention 그대로 쓰다보며 발생하는 연산 과부하 등)
- DiscoVLA는 파라미터 효율성과 시간 정보 모델링을 동시에 고려하여 R@1 기준 최고 성능인 47.0% 달성
Table 2 – LSMDC 성능

- DiscoVLA가 기존 방법들 대비 R@1, R@5 등 모든 지표에서 우수
- 특히 영상과 자막 간 의미적 불일치가 심한 LSMDC에서 더 큰 효과
Table 3 – ActivityNet 성능
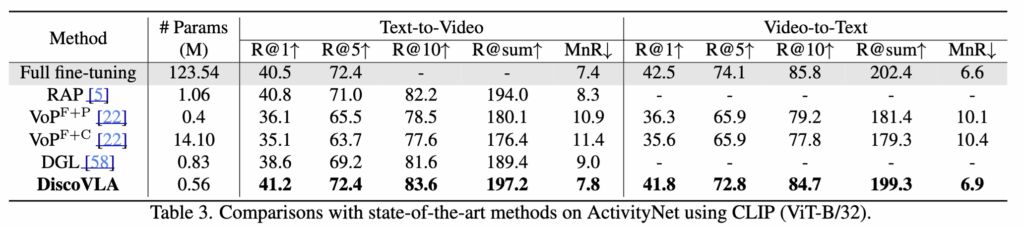
- 비디오 길이가 길고 다양성이 높은 데이터셋에서 비디오 정렬 및 언어 정렬 성능이 모두 향상
Table 4 – DiDeMo 성능
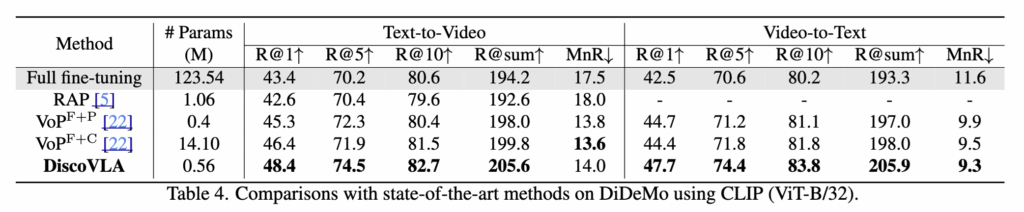
- 시간적 세분화된 문장이 필요한 데이터셋으로, DiscoVLA는 정렬 정확도와 전반적 검색 성능 모두 우수
정리하자면, Prompt / Adapter / LoRA 기반 방법은 파라미터는 적지만 시계열 정보 모델링이 부족하고, RAP, DGL 등은 시계열 처리는 가능하나 파라미터 효율성이 낮다는 기존 방법론의 한계가 있었습니다.
그에 반해 DiscoVLA는 양쪽인 파라미터 효율성과 정렬 능력을 동시에 달성하면서, 다양한 데이터셋에서 일관되게 SOTA 성능을 기록한 방법임을 실험적으로 확인할 수 있었습니다.
3.3 Ablation Study
Table 5 – DiscoVLA Ablation Study
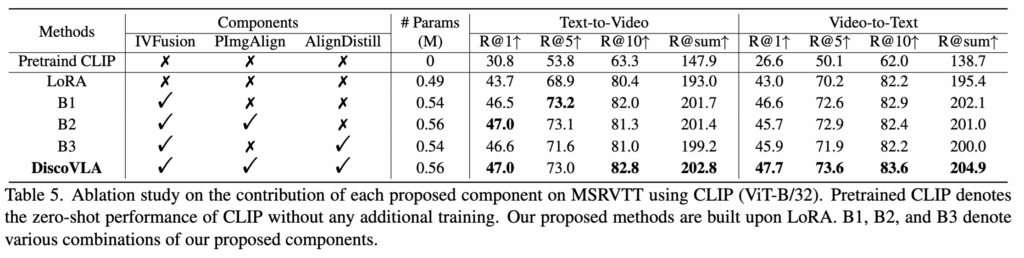
- IVFusion 단독: 시공간 정보를 효율적으로 통합하여 성능 대폭 향상
- PImgAlign: 이미지 수준 학습이 비디오 정렬까지 전달기 어려움
- AlignDistill: 정밀한 이미지 정렬 정보 부족으로 효과 미미
- DiscoVAL (최종): LoRA 대비 t2v: +9.8%, v2t: +9.5% (R@sum 기준)
이 때, 학습 가능한 파라미터는 LoRA 약 0.49M에서 저자가 제안하는 모듈을 추가했을 때, CLIP으로부터 최종 0.56M 만 추가한 것 만으로도 성능 향상을 달성하였습니다.
Table 6 – IVFusion Ablation study
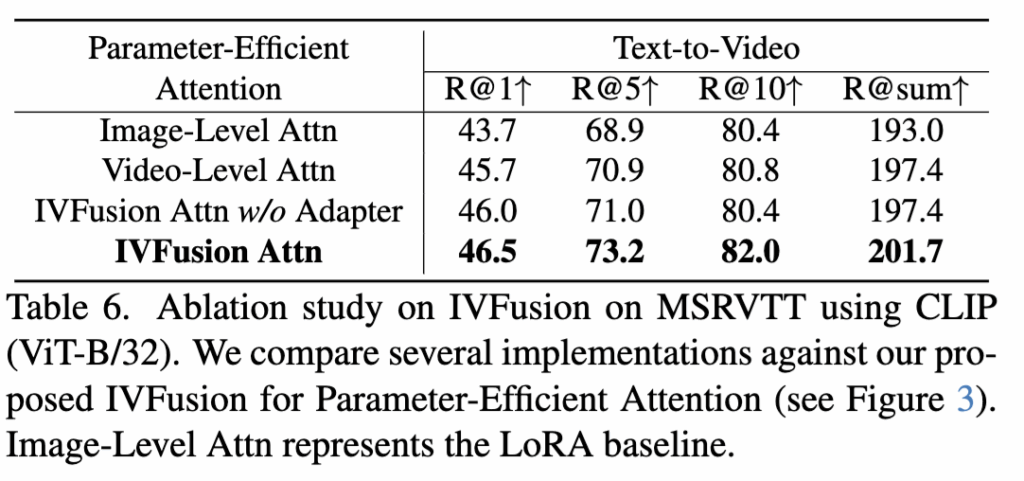
Video-Level Attention
- 모든 토큰을 시간축으로 연결하여 시공간 정보를 학습
- 4.4% R@sum 향상, 그러나 계산량 증가
IVFusion Attention
- CLS 토큰에만 시공간 Attention 적용 → 계산량 감소
- 이미지와 비디오 특징을 Adapter를 통해 효과적으로 결합
- Adapter 없이 평균 결합 시 성능 증가가 크지 않음. (Adapter 사용 시 201.7% R@sum 달성)
즉, 제안한 IVFusion 구조는 효율성과 성능을 모두 확보한 것으로, Adapter의 존재가 성능 향상에 핵심이라고 할 수 있는 결과네요.
Table 7 – PImgAlign Ablation study
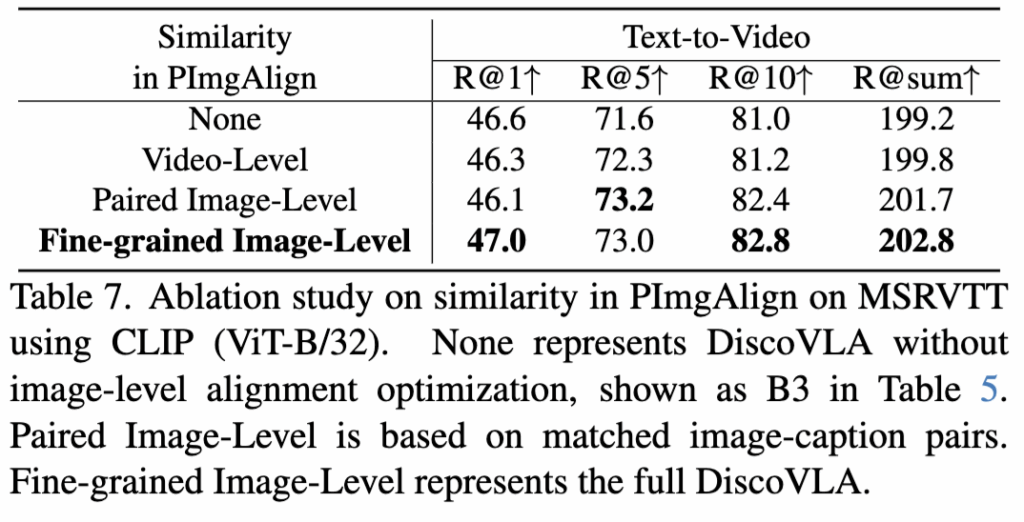
해당 실험은 PImgAlign에서의 유사도 계산 방식 단위에 따른 효과를 비교한 것입니다. 비디오 단위로 할 지, 이미지 쌍 단위로 할지, 저자가 제안한 세분화된 이미지 – 캡션 단위로 할 지에 대한 비교 실험이죠
- Video-Level baseline은 단순 평균 기반 유사도 계산으로 성능 저하 발생
- Paired Image-Level baseline은 1.9% R@sum 향상
- 최종 방식은 하나의 이미지에 대해 모든 caption과의 유사도 중 최댓값을 선택해 정렬 성능을 더욱 향상시킴
3.4 Qualitative Analysis

마지막으로 정성적 결과 보이고 마무리하겠습니다. 상단 그림 4는 이미지-레벨과 비디오-레벨 간의 차이를 보여주는 것인데요. 그림 4a, 4b에서는 이미지 정보만으로는 영상의 전체 의미를 포착하기 어렵고, 4c, 4d에서는 두 수준 간 유사성은 높지만 이미지 간 차이로 인해 캡션이 달라질 수 있음을 보여줍니다.
결과적으로, 시간 정보를 고려하지 않은 이미지 정렬만으로는 한계가 있고, DiscoVLA는 이를 보완하기 위해 이미지-레벨 정렬 정보를 비디오-레벨로 효과적으로 전이할 수 있다는 것을 보여주며 리뷰 마무리 하겠습니다.
4. Summary
지금까지 이미지-비디오 정렬의 불일치를 해결하기 위해, CLIP 기반 모델의 이미지 정렬 능력을 비디오 정렬로 전이(distill)하는 DiscoVLA에 대해 알아보았습니다. DiscoVLA는 정교한 이미지-레벨 정렬 학습을 위한 PImgAlign, 그리고 이를 비디오-레벨로 효과적으로 이전하는 AlignDistill, 마지막으로 이미지와 비디오 간 정보를 통합하는 IVFusion 모듈을 구성하여 전체 정렬 성능을 끌어올렸습니다.
DiscoVLA는 학습 시 이미지 정렬 손실과 비디오 정렬 손실 외에, 이미지 기반 유사도 분포와 비디오 기반 유사도 분포 간의 Kullback-Leibler divergence를 최소화하는 distillation loss를 도입하여, 이미지 정렬 정보를 비디오 정렬에 자연스럽게 반영합니다. 이렇게 설계된 구조는 전체 학습 파라미터가 약 0.56M에 불과함에도 불구하고, MSRVTT 기준 2.2% R@1 향상, 7.5% R@sum 향상을 달성하며 기존 기법들을 뛰어넘는 성능을 보였습니다.
효율성과 성능을 둘 다 잡았다는 측면에서 높은 평가를 받는 모델이라 CVPR 에 붙은 것은 아닐지 생각이 드는 논문입니다. 제안하는 모듈들이 굉장히 혁신적이고 새로운 방법은 아니지만.. 기존 지식을 해당 태스크에 잘 풀어낸 정석적인 논문이 아닐까 싶네
홍주영 연구원님 좋은 리뷰 감사합니다
LLM을 사용하여 pseudo 캡션을 만든다는 것이 제법 인상적이네요. 다만 당연하게 드는 생각이 어떤 모델을 썼는지 그리고 LLM의 퀄리티에 따라 성능이 달라질 거라 생각이 듭니다. 이런 편차를 다룬 실험 결과는 없나요? 그리고 그 pseudo 캡션 데이터를 저자들이 공개하는지도 궁금합니다
좋은 질문 감사합니다.
말씀해주신 대로, DiscoVLA는 멀티모달 LLM인 LLaVA-NeXT를 활용해 프레임별 pseudo-caption을 생성하고 이를 정렬 학습에 활용하였습니다.
다만, 이 pseudo-caption의 품질이 정렬 성능에 영향을 줄 수 있는건 저도 동감하는 바입니다. 그러나 아쉽게도 본 논문에서는 이러한 LLM 종류 간 비교 실험이나, caption 품질 변화에 따른 정렬 성능 민감도 분석은 따로 다루지 않았습니다.
제가 리뷰에는 작성하지 않았는데, Table 7의 ablation에서는 “프롬프트 유무에 따른 caption 품질 차이”를 보이긴 하였습니다만, 이게 다양한 LMM을 비교하거나 caption 오류에 대한 robust analysis는 포함되어 있지 않았습니다.
그리고, 생성된 pseudo-caption 데이터셋의 공개 여부에 대해서도 본문에서는 별도로 언급이 없습니다. GitHub에도 데이터셋이 보이지는 않아 저도 굉장히 아쉽게 생각하는 부분입니다
안녕하세요 주영님, 좋은 리뷰 감사합니다.
주영님이 말미에 말씀해주신대로 문제정의부터 해결을 위한 접근법까지 막힘없이 레고처럼 딱딱 맞아떨어지는 논문이라고 느껴졌습니다.
궁금한 점이 하나있는데요.
MLLM인 LLaVA-NeXT를 활용하여 PImaAlign 모듈에서의 pseudo image caption 생성으로 이미지와 캡션 간 유사도를 학습하고, 이를 inference 때는 무거워서 제외하는 것으로 이해했는데요. prompt를 보면 describes {video caption}이라고 했으나, 이 caption의 context길이가 어느정도로 제약이 있느냐에 따라 pseudo caption이 noisy해지거나, 혹은 hallucination으로 인해 잘못된 caption을 생성할 수도 있을 거라고 생각합니다. 혹시 이 부분에서 추가적인 prompt engineering 방법이나, 저자들의 설명이 있었을까요?? reasoning 근거를 더 잘 설명해주는 CoT 방식을 붙인다던지.. 감사합니다.
좋은 포인트를 지적해주신 것 같네요.
말씀하신 내용처럼, DiscoVLA는 PImgAlign 모듈에서 멀티모달 LLM인 LLaVA-NeXT를 활용해 프레임 단위의 pseudo-caption을 생성하고, 이를 통해 이미지-레벨 정렬을 학습합니다.
이때 지적하신 것처럼, {video caption}의 길이나 품질, 그리고 LLM의 응답 방식에 따라 pseudo-caption이 부정확하거나 hallucination을 포함할 가능성은 당연히 존재합니다. 특히 긴 비디오 캡션의 경우, LLaVA가 어떤 부분을 강조하여 프레임을 설명할지 예측하기 어렵기 때문에 더 그렇죠.
그렇지만 본 논문에서는 이러한 위험 요소를 다루기 위한 prompt engineering 기법이나 CoT (Chain-of-Thought) reasoning 추가 등은 따로 도입하진 않았습니다. 제가 저자는 아니지만 디펜스를 하자면, 그런 디테일한 요소는 저자가 다룰 영역 밖이기 때문이지 않나 싶습니다. 그렇기 때문에 MLLM에 단일 문장의 프롬프트를 사용하는 것이지 않나 싶습니다.
추가로, caption이 noisy해질 수 있다는 점은 Table 7의 실험을 통해 확인할 수 있긴 합니다. 제가 해당 테이블을 실험에서 다루진 않았지만, 해당 테이블엔 영상 캡션을 프롬프트로 제공하지 않은 경우에는, saliency 위주로만 설명이 생성되며, 이는 정렬 성능 저하로 이어졌다는 결과를 보여주었습니다. 하지만 hallucination 자체를 찾거나 제거하는 방법은 없지만요.