안녕하세요 이번 X-Review로 ViT를 가져왔습니다.
Transformer 구조를 이미지 쪽으로 가져오기 위한 많은 과정이 있었겠지만 약 4년만에 나온 논문으로 생각보다 오랜시간이 걸렸는데요. 해당 Transformer가 나왔을 당시의 GPU적 한계나 기존의 Image classificatoin 모델들의 성능이 이미 어느정도 높은 상태였기 때문에 트랜스포머 구조를 활용하여 이미지 classification 성능을 SOTA에 근접하게 달성하기 어려운 환경이었을거라 생각합니다.
해당 논문을 들어가기에 앞서 introduction에 나오는 inductive bias라는 개념을 먼저 설명하고 시작하겠습니다.
Inductive Bias(귀납적 편향) 란?
정의는 머신러닝에서 모델이 학습 데이터 외의 새로운 상황에서도 일반화 하기 위해 미리 가정하거나 내포하는 구조적 성향을 말합니다.
즉 학습 데이터가 부족할 때에도 잘 작동하게 해주는 모델 자체의 구조적 성향을 말합니다.
예시로는
1.인간이 “고양이는 대체로 네 다리를 가졌고 얼굴이 앞에 있다” 는 직관을 가지고 새로운 고양이를 본다.
2. CNN은 “이미지는 지역적으로 중요한 정보를 가진다”
와 같은 iductive bias 를 가지고 있습니다. 이는 일반화 성능을 높이기 위한 추가적인 가정이라고 생각하면 됩니다.
CNN이 가진 대표적인 Inductive Bias들
- Locality (국소성)
CNN은 작은 커널로 국소적인 영역을 먼저 학습합니다. 이는 이미지의 의미있는 정보가 주로 이웃한 픽셀간에 존재한다는 가정을 내포합니다. - Translation equivariance
입력이 이동하면 출력도 바뀝니다. 즉 고양이의 위치에 따라 feature의 위치도 이동하게 됩니다.
Transformer 는 왜 이러한 bias 가 없는지 생각해보면 입력을 패치 또는 토큰단위로 나누어 각 요소가 서로 동등한 관계로 처리가 됩니다. self-attention은 전역적인 관계를 중심으로 학습하며 지역정보나 위치정보에 대한 내용을 내포하고 있지는 않습니다. 즉 CNN처럼 미리 가지고 있는 정보가 있는 것이 아니기에 적은 데이터로 일반화하지 않고 많은 데이터가 있어야 패턴을 직접 학습할 수 있습니다.
Abstract.
이미지를 토큰으로 분할 :
이미지를 고정된 크기의 patch( 예: 16*16 )로 나눈 후, 각 패치를 flatten 하여 linear projection을 통해 embedding vector로 변환
클래스 토큰 추가:
NLP에서처럼 전체 이미지를 대표하는 역할을 하는 learnable class token을 추가함
위치 임베딩 사용:
patch 순서에 대한 정보를 보존하기 위해 positional embedding을 덧붙임
Transformer Encoder 사용 :
BERT나 GPT 에서 사용되는 standard Transformer Encoder 블록을 그대로 사용, Attention 구조 덕분에 global context를 잘 파악할 수 있음.
사전학습 및 파인튜닝 전략:
ImageNet같은 작은 데이터셋 ( 해당 논문부터는 이미지넷 데이터셋도 작은 데이터셋이라고 언급합니다..) Transformer가 잘 작동하지 않아서 JFT-300M 처럼 매우 큰 데이터셋에서 사전학습을 수행한 후, Downstream task에 파인튜닝하여 높은 성능을 달성했다고 합니다.
1. Introduction
NLP 에서 Transformer가 대규모 사전학습 + 소규모 파인튜닝 전략으로 큰 성공을 거두었습니다. 비전 분야는 여전히 CNN이 주류였고 self-attention을 도입하거나 대체를 시도했으나 효과적인 하드웨어 적용에는 어려움을 겪고 있었습니다.
각 패치를 word token 처럼 활용하여 처리하였고 중간규모 데이터셋 ( ImageNet) 에서는 CNN보다 성능이 낮지만 대규모 데이터로 사전학습하면 Transformer의 성능이 CNN보다 뛰어남을 보였습니다.(ImageNet-21K , JFT-300M)
3. Method
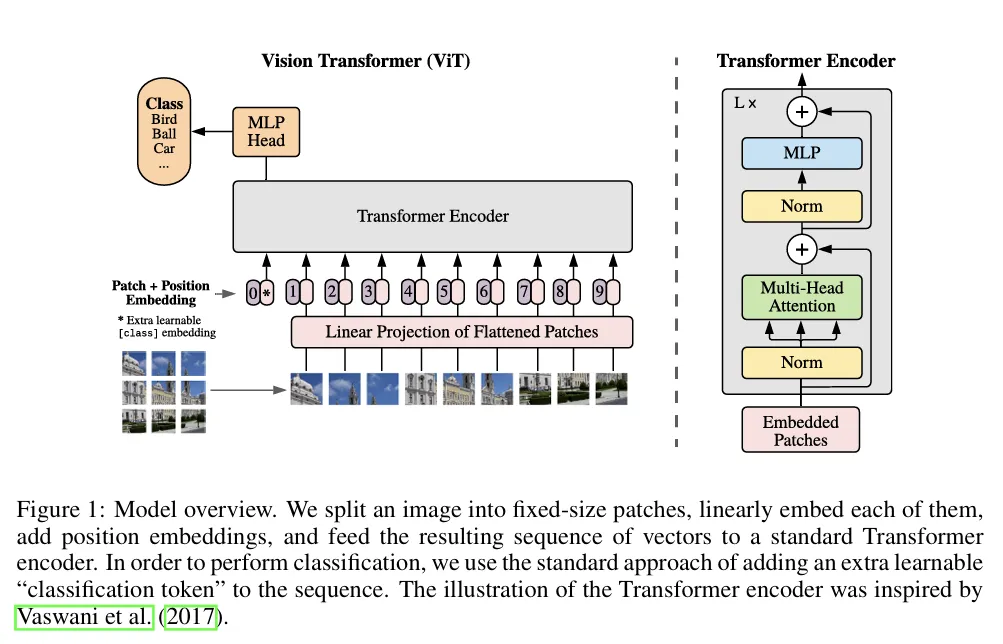
16X16 의 이미지 임베딩 앞에 cls 토큰을 추가해서 전체 이미지가 어떤 정보를 담고 있는지 전체 class 요약정보를 표현했습니다. 이후 classification 등에서 해당 cls 토큰을 softmax하여 클래스를 얻습니다.
3.1 Vision Transformer(ViT)
입력 이미지 분할 : 이미지를 16X16 크기 패치로 나누고 -> 각 패치는 1D로 펼친 뒤 선형 임베딩시킵니다. (이미지 H*W*C 구조면 N*(P*P*C) 형태로 바꿈, 이때 P는 patch)
토큰 입력: [class]토큰 추가, positional embedding 추가
positional embedding은 기존 Transformer의 sinusoidal 방식 대신 학습 가능한 1D positional embedding을 사용합니다. 이는 이미지의 패치 수가 거의 일정하다는 특성상 일반화 가능한 형태가 크게 필요하지 않으며, 실제로 성능 차이도 크지 않기 때문입니다.
3.2 학습
사전학습 : JFT-300M , ImageNet-21k 등 대규모 데이터셋에서 학습
파인튜닝 : ImageNet, CIFAR-100, VTAB 등의 벤치마크에서 수행
전처리 & augmentation : RandAugment, Dropout 등 적용
최적화 : Adam, learning rate warm-up, cosine decay 등 사용
4. Experiments
4.1 실험 세팅
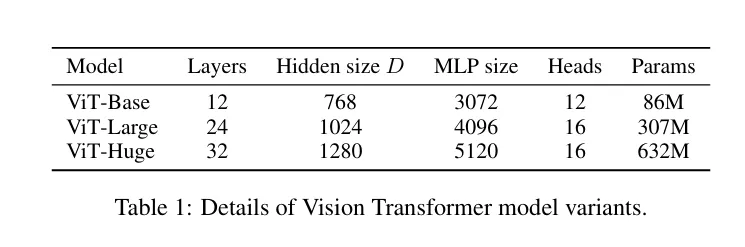
모델 구성 : ViT-B (Base) , ViT-L (Large) , ViT-H (Huge)
예 : ViT-B/16 -> base model & patch size 16을 의미
4.2 주요 결과
대규모 학습의 힘:
JFT-300M 에서 사전학습 후 ImageNet-1k 파인튜닝으로 SOTA를 달성합니다.
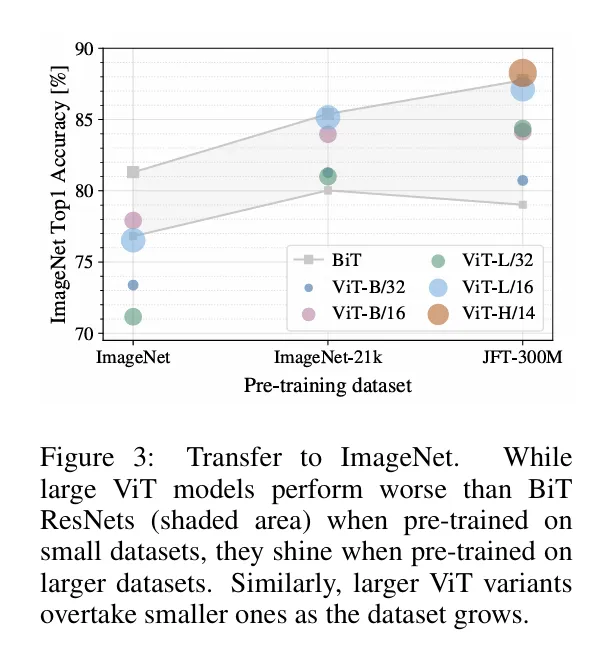
Figure 3 을 보면 대규모 데이터셋으로 갈수록 ViT의 성능이 ResNet을 넘기 시작합니다.
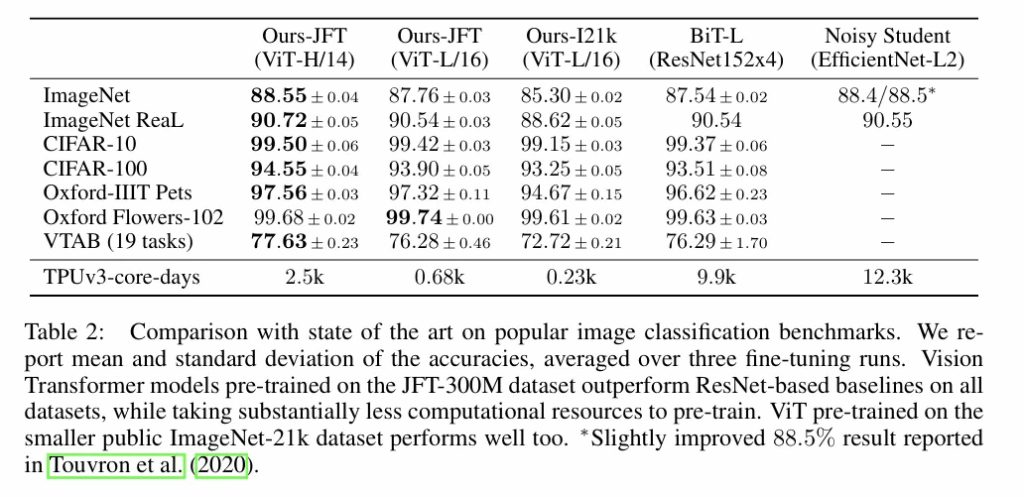
ViT variant 모델들 중 가장 큰 size의 ViT-H/14와 ViT-L/16 을 SOTA인 CNN들과 비교합니다. 하나는 대규모의 ResNET으로 지도방식의 전이학습을 수행시킨 Big Transfer(BiT) 모델, 두번째는 큰 EfficientNet으로 준지도학습을 이용해 학습시킨 Noisy student입니다. 본 연구가 진행되던 시점을 기준으로 imageNet에서 Noisy student가 SOTA이고 다른 데이터셋에 대해서는 BiT-L 이 SOTA였습니다.
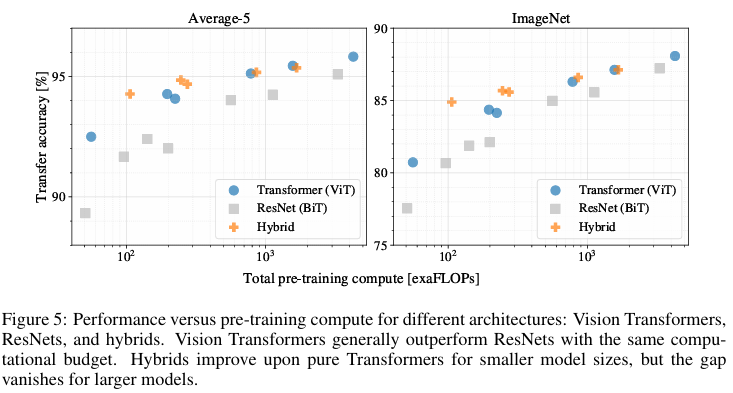
JFT-300M 데이터셋으로부터의 trasfer Learning 성능을 평가하는데, 여기서는 각 모델의 performance와 training에대한 computational budget을 비교합니다.
모든 비전 트랜스포머 모델들은 ResNet모델들을 성능/계산 trade-off에서 압도합니다. 저자는 동일한 성능을 달성하기 위해서는 2~4배정도의 cost가 더 든다고 표현했습니다.
또 알아낼 수 있는점으로는 Hybrid 모델이 비교적 작은 계산 영역에서는 ViT의 성능을 뛰어넘습니다. 이 차이는 모델의 크기가 커짐에 따라 줄어들며 이는 ViT에도 CNN의 local 적 inductive bias를 주입하는 것이 도움을 줄 수 있다고 해석할 수 있습니다.
가장 중요한 점은 ViT는 여러 scale 에서 saturated 되지 않았기 때문에 추후 연구에서 더 큰 모델이 가지는 feature scaling efforts를 기대할 수 있다고 저자는 표현했습니다.
(여기서 나오는 hybrid 모델은 ResNet을 통과한 feature map을 이미지 대신 패치단위로 나누어 인코더에 넣은 모델입니다.)
4.5 Inspecting Vision Transformer
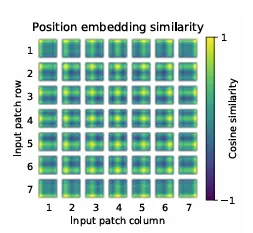
ViT는 이미지 패치를 flatten하여 Linear Projection을 통해 token 임베딩으로 변환합니다. 각 토큰에는 학습 가능한 1D positional embedding이 더해지며, 이 positional embedding은 학습 과정에서 행·열 방향의 위치 관계를 일정 부분 반영하는 구조를 가집니다. 특히 대규모 모델에서 positional embedding을 시각화하면 sinusoidal 형태와 유사한 패턴이 나타나며, 이는 ViT가 명시적인 2D 구조 없이도 공간 정보를 내재적으로 학습할 수 있음을 보여줍니다.
왜 sinusoidal 형태가 2D space를 반영한다고 보는지에 대해서는 기존 Transformer에서의 sinusoidal positional encoding이 서로 다른 위치가 일정한 패턴을 만들게 하여 상대적 위치정보를 만드는 것에서 유추할 수 있는데, 1D positional embedding을 학습시켰는데도 가로축의 미세한 변화와 세로축의 미세한 변화의 주기적 변화가 sin, cos 함수의 형태처럼 보이게 되는 것입니다.
Attention Distance
이는 저자가 도입한 receptive field 같은 개념인데 하나의 토큰이 attention을 분배한 다른 토큰들과의 평균 거리입니다. 즉 낮은층에서는 좁고 깊은 층에서는 넓어지는 특징을 가지고 있습니다.
ViT의 관찰 결과:
일부 attention head 는 초기 layer에서도 전체 이미지에 골고루 attention 을 분포시켰고 다른 head들은 주로 가까운 거리의 토큰에 attention을 집중하는 경향을 보였습니다.
hybrid 모델과의 차이점:
Hybrid 구조는 이미 ResNet이 local 적 정보를 많이 인코딩 했다고 주장하는데, 이 이유로 Transformer의 attention head들이 굳이 local 적 정보를 다시 강조하지 않았다고 합니다. 따라서 작은 데이터셋에서는 hybrid 구조가 ViT보다 더 좋은 성능을 낼 수 있었다고 저자는 추측합니다.
5. Conclusion
이 논문은 이미지 분류에 순수 Transformer 구조를 적용한 Vision Transformer를 제안하며, CNN의 강한 inductive bias 없이도 대규모 데이터와 학습규모가 뒷받침된다면 높은 일반화 성능을 낼 수 있음을 입증했습니다.
ViT는 단순한 구조에도 불구하고 기존의 복잡한 CNN 기반 모델보다 우수한 성능을 보여주었고, 이후 많은 연구에서 기본 구조로 채택되는 계기가 되었습니다.
안녕하세요! 리뷰 잘 읽었습니다.
ViT를 여러 번 접했다고 생각했지만 인택님 리뷰를 읽으며 새롭게 알아간 게 여럿 있어 흥미롭게 읽었네요! (1D position embedding이 더해진다는 것, inductive bias가 더해지는 경우 성능이 개선된다는 점 기타 등등)
inductive bias 개념도 이번에 확실히 이해하게 되었습니다!
질문이 하나 있는데요 실험 부분에서 제시됐던 하이브리드와 ViT의 차이점은 트랜스포머에 입력하기 전 ResNet을 통과하거나 하지않는 차이라고 보면 될까요?
감사합니다!
안녕하세요 지연님 새롭게 알게된게 있다니 다행이네요.
질문해주신 hybrid 방식과 ViT의 차이점은 이해하신대로 트랜스포머의 encoder에 입력되기 전 ResNet backbone을 통과하는지 여부라고 생각하시면 됩니다.
hybird모델은 백본을 통과하고 난 후 feature map을 3*3 으로 패치를 얻거나, 그냥 flatten 시켜서 트랜스포머 인코더에 인풋으로 넣게됩니다. ( flatten 시킨 것은 픽셀의 각 위치를 토큰으로 사용하는 것입니다.)
이러한 차이를 실험한 이유는 저자가 완벽하게 conv block을 배제한 버전(ViT)도 학습성능이 뛰어남을 보여줌과 동시에 conv block을 통과시켜 local 특징을 미리 내포한 feature map을 input으로 넣었을때의 성능과 두 버전의 학습데이터량에 따른 성능을 분석하기 위함이었습니다. 감사합니다.
안녕하세요 인택님 리뷰 감사합니다
사실 저도 ViT나 트랜스포머를 깊게 공부해보진 못 한 상황인데, “positional embedding을 시각화하면 sinusoidal 형태와 유사한 패턴이 나타나며, 이는 ViT가 명시적인 2D 구조 없이도 공간 정보를 내재적으로 학습할 수 있음을 보여줍니다” 라는 표현이 어떤 의미인지 조금만 자세히 설명해주실 수 있으실까요??
안녕하세요 영규님 좋은질문 감사합니다.
우선 후속 연구들에서는 2D구조로 positional embedding을 사용하기는 합니다. 다만 ViT가 초기 연구였기 때문에 기존 Transformer의 구조를 최대한 유지하고자 했을 것 같습니다. Transformer의 입력이 1D이기 때문에 1D learnable positional embedding을 사용했습니다.
사용방식을 설명드리자면 패치를 왼 -> 오, 위 -> 아래 방향으로 나열한 후 positional embedding을 더해주고 학습시킵니다.
결과적으로 인접한 패치가 비슷한 위치벡터를 가지는 것이 유리한 것임을 학습하게 되며, 이것이 왼->오 방향의 주기적인 형태와 위->아래 방향의 주기적인 형태로 나타나게 되는데, 이 것을 넓은 그리드로 시각화 하였을때 sinusoidal 형태로 보이게 됩니다. 즉 제가 리뷰에 적었던 표현인 명시적인 2D 구조 없이도 는 실제 ViT에서는 1D learnable positional embedding을 사용했기 떄문이고 ( 이미지임에도 불구하고) 후속연구에서는 2D 방식도 많이 고려가 되었습니다.
좋은 리뷰감사합니다 인택님!
간단한 질문이 생겨 남깁니다
16*16 패치로 나눠서 conv1d로 learnable 한 파라미터를 사용해서 위치정보를 학습하는데 이때 로컬 구조적인 면을 보완하는 방법은 추가되지는 않나요?? 또한 hybrid 모델은 평가용으로만 사용한게 맞나요?
안녕하세요 우진님, 질문에 대한 답변을 해드리자면
위치정보 학습시 로컬 구조적인 면을 보완하는 방법은 따로 추가되지 않습니다. 대규모 데이터로 학습하면 그런 내부구조 없이도 충분히 local 특징을 잡아내기 때문인데 다르게 말하면 데이터량이 적으면 성능이 그다지 좋지 못하다는 말이기도 합니다. 그래서 hybrid 구조를 통해 cnn의 local적 특징을 가지는 feature map을 트랜스포머 encoder로 넘겨 데이터가 적을땐 hybrid 모델의 성능이 더 좋다는 걸 보여준 것입니다.
안녕하세요 인택님 !
제가 궁금했던 논문들을 검색해보면 대부분 인택님의 리뷰가 있더라구요…ㅎ 덕분에 리뷰 감사히 잘 읽고 갑니다 !
이미지넷 데이터셋도 작은 데이터셋이라 말하는게 흥미롭네요.. 데이터의 세계란..
읽다가 궁금한점은 포지서널인코딩 관련 질문입니다
지식의 한계로 제가 잘못 이해하고 있을수도 있습니닷…!
글 초반부의 포지셔널 임배딩에서 sinusodial방식이 아닌 학습가능한 1D 포지셔널 임베딩을 사용한다고 하셨는데, 아래쪽 4.5부분에서 positional embedding을 시각화하면 sinusodial형태와 유사한 패턴이 보이고 이거는 명시적인 2d구조 없이도 공간 정보를 내재적으로 학습할수 있음을 보여준다고 하신 부분이 약간 이해가 잘 안됩니다!
sinusodial을 사용한 포지셔널 임베딩이 아닌데도 학습을 통해 sinusodial과 유사한 성질을 갖게 된다인가요?
그럼 처음부터 sinusodial을 사용하지 않고 학습가능한 포지셔널임베딩을 사용한 이유가 무엇인가요?
혹시 지식의 한계로 잘못이해하고 질문을 드린것이라면 바로잡아주십셔..ㅎㅎ!!
안녕하세요 찬미님 답글 감사합니다.
뭐 저런 positional encoding 을 넣은 초기연구이기도 해서 ViT의 구조에 맞게 1D 로 안전하게 넣어준 이유 도 있을거고 떠올리기 가장 편했을거라 먼저 그렇게 실험을 한 것이라고 생각합니다. 결론적으로 2D sinusoidal 형태의 그리드 형태가 나오는 것으로 1D positional encoding 만으로도 충분히 spaital 한 정보를 표현할 수 있어서 굳이 2D sinusoidal 형태로 하지 않은 것이라고 이해하면 될 것 같습니다.