안녕하세요 이번주에도 Text Spotting 논문을 가져와 리뷰해보겠습니다.
1. Introduction & Related Studies
natural scene에서의 text를 인식하는 text spotting 태스크는 실제 세계에서 다양한 분야에 적용되기 때문에 아주 중요한 기술입니다. 자율 주행, 네비게이션, 이미지에서 시각 정보를 읽어오는 상황에서 사용되는 기술입니다.
전통적인 text spotting은 text detection 과 recognition 이 두 단계로 이루어져 있습니다.
text detection은 natural scene의 이미지에서 텍스트의 location을 찾는 것을 말하고 recognition은 앞선 detection 과정에서 찾은 영역에 대해 crop을 수행한 다음 crop된 영역의 텍스트가 무엇인지 그 내용을 인식하는 것을 말합니다.
이런 two-step text spotting이 갖는 단점이 두가지가 있습니다. sub-optimal performance를 갖는다는 것과 error propagation 문제입니다. error propagation이란 detection에서 부정확하게 detection이 수행된 경우 그 영향을 recognition 단계에서 고스란히 받아 오류가 누적된다는 것을 일컫습니다. 따라서 이런 작은 차이로 인해 그리고 학습 과정에서 서로 보완이 되는 과정이 없다는 점 때문에 최적의 성능을 내는데 한계가 있습니다.
이런 두 단계의 text spotting 과정의 단점을 보완하고자 하나로 통합하는 end-to-end 방식의 시도도 함께 계속 되어왔는데요.
통합 모델은 detection-by-recognition 방식을 따랐었습니다. recognition 모듈과 공유하는 인코더로부터 추출된 특징들을 가지고 detection을 수행하는 방식으로 경험을 토대로(heuristic) ROI Pooling과 같은 작업과 추가적인 후속작업을 해줘야 한다는 단점이 있었습니다. 이후 추가적인 작업이나 human knowledge 없이 수행하기 위해 트랜스포머 구조로 설계하는 연구가 등장했습니다. 그리고 이외에도 detection과 Recognition이 동시에 수행되면서 서로에게 좋은 시너지를 줄 수 있는 연구 또한 있었습니다.
이러한 지속적인 연구가 활발히 이뤄짐에도 불구하고 통합되 방식보단 기존의 two-step 방식을 선호하고 고수되어왔습니다. 이런 이유는 two-step 방식의 text spotter model이 모듈성을 가져 유연하단 점 때문입니다. detector와 recognization module 이 서로에 구속되지 않고 따로 개선발 및 유지보수가 될 수 있으며 개별적으로 학습하는 게 가능해 각 태스크에 적합한 대량의 데이터셋을 가지고 효과적으로 학습이 가능하다는 아주 큰 강점이 있습니다.
그래서 two-step 방식의 모듈성이 갖는 장점은 그대로 가져가며 Two-step 방식이 가지던 두가지 문제점 1) sub-optimal performance 를 내는 문제 2) error propagation 문제를 해결하는 방향으로 논문의 저자는 새로운 방식을 제안합니다. 이를 저자는 Bridging Text Spotting (BTS) 라고 이름을 붙입니다.
그 방식을 설명하자면 대략 이렇습니다. 사전에 따로 잘 학습된 detector와 recognizer를 그대로 가져와 사용합니다. 그리고 각 모델의 가중치를 학습이 되지 않도록 고정시킵니다. 이미 각 모델이 충분히 잘 학습이 됐다고 판단하기 때문입니다. 여기에 저자는 detector와 recognizer를 통합할 Bridge라는 모듈을 추가할 것을 제안합니다. Bridge 모듈에서는 detector에서 학습되는 넓은 수용영역(receptive field)의 feature들을 recognizer 중간 단계에 추가해 함께 학습시키는 방식을 제안합니다. 학습 초기에 recognizer가 detector의 feature를 노이즈로 인식하지 않도록 Bridge 모듈의 입출력 레이어의 가중치를 0으로 초기화합니다. 추가적으로 recognizer와 detecor는 freeze되어 있기 때문에 end-to-end 기능이 학습되도록 각각 학습 가능한 Adapter를 덧붙입니다.
그럼 더 자세히 알아보겠습니다.
2. Methods
아래는 논문에서 제안하는 Briding text spotting 모델의 아키텍쳐입니다.
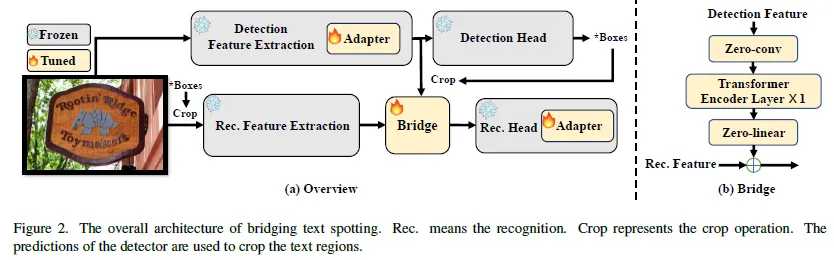
개별적으로 구현되고 학습이 잘 된 detector와 recognizer를 사용합니다. 각 모듈마다 각기 필요한 데이터셋에 맞게 그리고 구조도 각 특성에 맞게 독립적으로 설계 될 수 있다는 유연함을 가지게 됩니다. 개별적인 학습 과정에서 최적화된 두 모듈을 freeze 시킵니다. 모델은 위와 같이 scene text image를 입력 받습니다. 입력된 이미지는 detector에 전달 돼 text instance의 위치를 예측합니다. 예측된 위치 정보를 바탕으로 detection 백본을 타고 나온 features map과 입력되는 raw 이미지를 crop 합니다. Crop된 이 둘을 각각 , C_i라고 하겠습니다.
원본 이미지에서 텍스트 영역 만큼 crop된 부분을(C_i) recognition 백본으로 전달해 특징을 추출합니다. 이는 또한 F_i라고 하겠습니다. 앞서 detection 백본을 타고나온 Feature를 Crop한 C_f와 F_i를 Bridge 모듈에 입력합니다. 그 다음 마지막으로 Bridge의 출력은 recognition head를 타고 나와 최종적인 recogition 예측을 수행합니다. 그리고 여기에 추가적으로 서론에서 얘기했던 Adatpter layer가 detector 와 Recognizer에 추가돼 end-to-end하게 수행되는 과정을 최적화합니다.
다음으로 Bridge모듈과 Adapter모듈을 각각 설명하겠습니다.
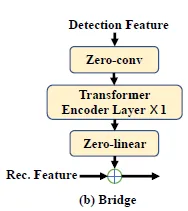
2.1 Bridge
브릿지는 well-trained 디텍터와 인식기를 연결짓는 역할을 담당합니다. two-step text spotting 모델들이 갖던 오류 전파 문제와 sub-optimal performance 이상의 한계를 갖는 문제를 해결해주는 부분입니다.
입력되는 이미지를 I라고 할 때 detection 과정은 다음과 같이 나타나집니다.
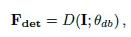
F_det는 detection 백본을 타고 나온 feature map입니다.
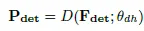
P_det는 F_det에 대해서 백본 헤드를 타고 나온 텍스트 인스턴스 위치에 대한 예측이라고 할 수 있습니다. 그 다음, P_det를 가지고 해당하는 영역에 대해서 F_det과 I(원본 이미지)로 부터 crop합니다. 아래가 그 과정입니다.
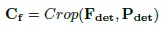
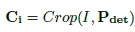
C_i를 recognition 백본에 전달해서 얻는 feature는 F_i입니다.
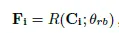
Bridge모듈은 C_f와 F_i를 입력으로 받습니다. Bridge는 0으로 초기화된 합성곱 레이어와 선형 레이러로 구성됩니다. 각각 Z_c, Z_l이라고 하겠습니다.
Bidge에서의 연산을 나타내면 다음과 같습니다.
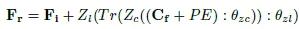
초기 학습 시에는 Z_c, Z_l의 가중치가 0으로 초기화 돼 있어 Bridge의 출력이 곧 Recognizer 백본의 출력 feature F_i와 같습니다.
2.2 Adapter
함께 사용되는 detector와 recognizer의 시너지를 늘리기 위해 Adapter가 제안되었습니다.
모델에 Bridge와 두 모듈 각각에 Adapter를 추가해 파인튜닝을 수행합니다.
norm layer를 제외하고 두 모듈을 최적화된 그 파라미터 그대로 freeze 됩니다. norm layer는 freeze 시키지 않아 Adapter의 입력으로 들어가는 feature의 분포를 정규화해 안정적인 학습을 유도합니다.
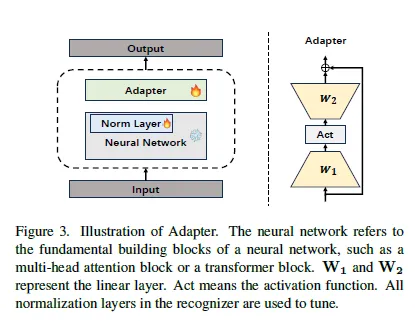
다음은 Adapter의 과정을 수식으로 나타낸 것입니다. Adapter의 구조도와 함께 참고해주세요.
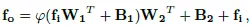
2.3 Optimization
최적화를 위한 목적 함수 설정은 각 detector와 recognizer에서의 loss를 따르고 이 둘의 loss를 더해서 최종 loss가 정의됩니다.
3. Experiments
3.1 mplementation Details
이 논문에서는 detector로는 DPText-DETR를 recognizer로는 DiG를 사용합니다. 이 조합의 제안 모델을 DG-Bridge-Spotter이라고 명명합니다. 파인튜닝 시 사전학스된 체크 포인트 파일로 부터 최적화된 파라마터를 load하고 파인튜닝을 진행합니다. Adapter모듈은 detector의 경우 encoder layer에 recognizer에는 decoder layer에 추가됩니다. 이 말고도 다른 detector, recognizer과의 조합을 가지고 실험을 해 제안하는 방법론에 대한 효과를 검증하였다고 합니다.
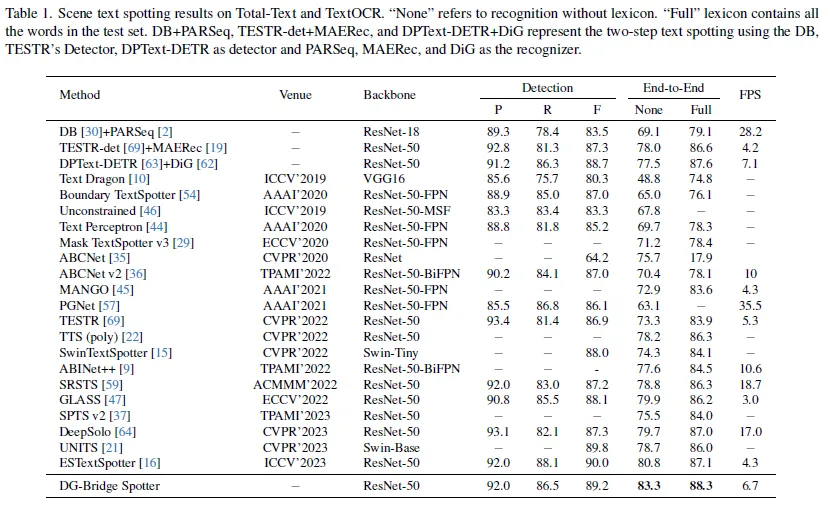
위는 Total-Text라는 벤치마크 데이터셋에 대한 성능 표입니다. Total-Text는 word-level (같은 줄에서도 띄어쓰기를 기준으로 단어를 구분하는 것이 특징.) arbitrarily-shaped text로 구성된 데이터셋입니다. End-to-end 성능은 다른 방법보다 높습니다. Full의 경우의 성능이 None이 더 높지만 None에서의 개선 정도가 더 큽니다. None 과 Full은 lexicon의 유무로 나눠볼 수 있는데 이는 최종 recognition 예측을 수행한 다음 평가를 위해 예측값을 그대로 평가에 반영할지 아니면 lexicon이라는 데이터셋에 대한 모든 텍스트를 담고 있는 하나의 딕셔너리에서 가져와 평가를 할지 차이가 있는 것입니다. None은 모델이 모든 단어의 모든 글자를 정확하게 예측해야 맞았다고 판단되는 반면 Full은 일부 글자가 틀려도 제일 유사한 텍스트가 lexicon으로 부터 선택되기 때문에 맞은 것으로 칩니다. Full보다 None에서의 개선된 정도가 크다는 것으로 미루어 보아 논문에서 제안하는 방법이 효과적으로 작용했음을 알 수 있습니다. 또한, 보통 실생활에 적용해보아도 lexicon을 두고 text spotting을 수행하기를 원하는 것은 아니기 때문에 None에서의 성능 개선을 필수적이라고 생각합니다.
아래는 정성적인 결과입니다 왼쪽이 CTW 1500이라는 또 다른 벤치마크 데이터셋에 대한 결과이고 오른 쪽 열의 사진이 Total-Text에 대한 정성적 결과입니다.

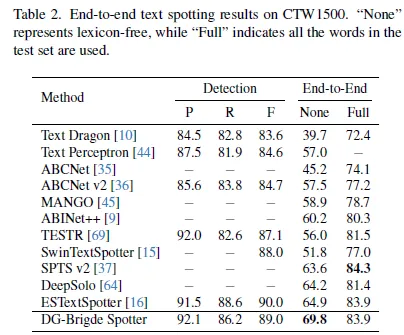
CTW1500 데이터셋에 대한 정략적 결과. End-to-end None의 결과를 보면 되겠습니다. 69.8로 제일 높습니다.
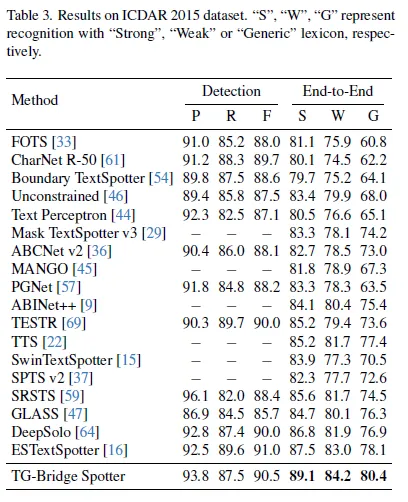
ICDAR 2015에 대한 결과. DPText-DETR 대신 TESTR의 detector를 사용합니다. TESTR(의 detector 부분만) + DiG는 TG-Bridge Spotter로 표기돼있습니다.
S, W, G가 있는데 이 또한 lexicon종류에 대한 분류로 Strong은 텍스트가 있는 이미지 내의 모든 텍스트가 있는 lexicon에서 제일 유사한 단어를 선택하는 것이고 Weak은 앞서 봤던 Full로 데이터셋 내에 이씨는 모든 단어로 구성되고 마지막으로 G는 generic으로 데이터셋에 포함돼 있지 않은 단어도 포함해 제일 난도가 높습니다. 그래서 결과 또한 제일 낮습니다.
3.2 Ablation study
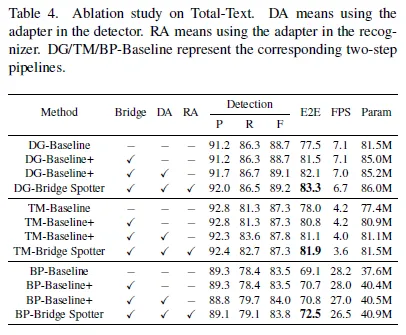
서로 다른 detector, recognizer의 조합 3가지에 대한 ablation study입니다. 세 조합에서 모두 Bridge 모듈을 추가했을 때 E2E (End to End)성능이 개선됨을 확인할 수 있습니다. 순서대로 (+4.0, +2.8, +1.6) 의 개선이 있었습니다.
아래는 정성적인 결과 또한 Bridge를 추가하고 안하고 간의 차이를 봅니다. without Bridge에서의 결과는 two-step method의 문제점 중 하나였던 error-accumulation 을 잘 보여주는 예입니다. detection 결과가 부정확했을 때 recognition 결과도 함께 부정확한 것을 가리켜 error accumulation error라고 합니다. 하지만 Ours의 경우 Bridge 모듈이 추가되고 Detector 백본의 출력 feature에 대해 crop 한 영역에 대해서 학습이 추가적으로 이뤄지기 때문에 원본 이미지에서의 Crop 영여보다 더 넓은 수용 영역을 가져 detection 이 부정확했어도 recogniiton 결과는 정확할 수 있습니다.

Table 4에서 이어서 Adapter에 대한 ablation study 결과를 설명하게습니다. Detector와 reconnizer에 모두 Adapter layer를 추가했을 때의 end-to-end 결과가 좋습니다. Bridge, Adapter 모듈을 추가하는 것이 파라미터의 개수를 늘리고 추론속도를 늦추지만 치명적인 정도는 아니라고 합니다.
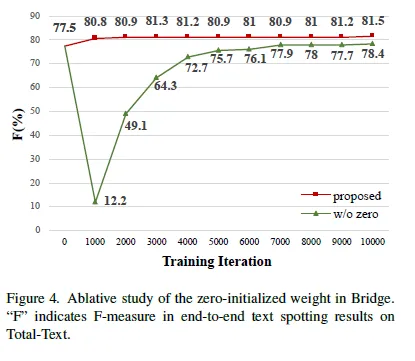
Bridge 모듈의 가중치를 초기에 0으로 초기화하는 것과 가우시안 분포를 따르도록 랜덤하게 초기화 하는 방법을 비교한 실험 결과입니다. 0으로 초기화 한 것이 일정 margin의 차이를 두고 좋은 결과를 보입니다.
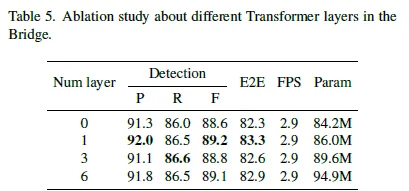
다음은 트랜스포머 layer의 개수 차이에 따른 결과입니다. Bridge 모듈이 Transformer layer를 하나로 두는 것이 제일 성능이 좋았습니다. 계층을 추가하는 것이 성능을 개선시키지도 않았습니다.
마지막 실험 결과입니다.
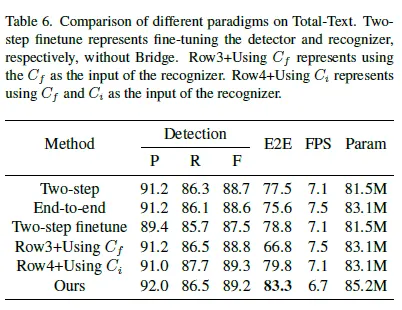
모델이 제안하는 방법에 대해 검증하고자하는 실험입니다. 기존의 two-step 방법과 end-to-end 방법과 비교합니다. detector는 DPText-DETR을 사용하고 recognizer로는 DiG를 사용합니다. Two-Step의 end-to-end 결과가 End-to-end 하게 구현된 방법보다 성능이 좋았습니다. 저자는 Recognizer를 따로 학습시킬 수 있는 모듈성 덕분에 large dataset으로 학습한 덕분에 error-accumulation, sub-optimal 문제가 있음에도 이를 극복하고 end-to-end 모델 보다 나은 성능을 보인 것이라고 분석합니다.
표에서 다른 메소드에 대해서도 설명드리겠습니다.
Two-step finetune은 detector와 recognizer를 더한 것으로 Total-Text 데이터셋에 대해서 파인튜닝을 거친 것이 특징입니다.
Row3_Using C_f는 recognizer 입력으로 C_f(detector의 백본 출력을 detectio 결과로 crop한 feature)를 준 것입니다. 오히려 성능이 하락하는 결과를 냈습니다.
Row4_Using C_i는 Recognizzer의 입력으로 C_f와 C_i의 합을 입력한 것입니다. ours를 제외하고서 제일 높은 정확도를 보였습니다.
하지만 이 모든 방법론을 모두 outperform하는 것은 저자가 제안하는 Bridging Text Spotting 방법론입니다.
그럼 이만 마치겠습니다. 읽어주셔서 감사합니다!!
안녕하세요. 좋은 리뷰 감사합니다.
사전에 학습한 detector와 recognizer 각각을 가져와서 e2e 수행가능하게 하는 프레임워크를 제안하는 논문이라고 이해했습니다. adapter module이 pre-trained된 대규모 모델을 효율적으로 fine-tunign하기 위해 사용하는 기법으로 알고 있는데요 여기서는 그게 아니라 detector와 recognizer의 시너지를 늘리기 위해 제안되었다고 언급되어 있어서 이에 대해 좀 더 설명 부탁드립니다.
또, table6에서 two-step과 two-step finetune이 구분되어 있던데, 그냥 two-step은 그럼 제로샷 성능인가요 ? 마지막으로 row3 + using cf인 경우에는 성능이 10 이상이 훅 떨어지는 이유가 궁금합니다.
감사합니다.
안녕하세요 질문 주셔서 감사합니다.
잘 이해하신 것 같습니다.
질문에 답변을 하나씩 드리겠습니다.
1. 본 방법은 사전에 잘 학습된 detector와 recognizer를 가져와 이를 freeze 시킨 채 파인튜닝을 수행합니다. detection feature가 중간에 recognization 단계에 더해지는데 각각 하나의 태스크에 대해 수행되던 두 모듈이 결합됐을 때 end-to-end하게 수행하는 능력을 개선시키고자 detection은 encoder 뒷단에, recognizer는 디코더에 학습이 가능한 어댑터를 붙인 것으로 설명됩니다.
2. 네 two-step은 detection model과 recognization model을 단순히 결합해 결과를 보인 것으로 제로샷 성능이라고 할 수 있습니다.
3. row3 + cf는 recognizer의 입력으로 크롭된 detection feature를 전달하는 것으로 이미지가 가지던 정보 자체가 손실되기 때문에 성능히 상당히 하락폭을 보인것으로 확인됩니다.
좋은 리뷰 감사합니다. E2E 방식에 대해 잘 이해 가지 않는 부분이 있는데요, recognizer의 encoder에서 이미지의 feature를 뽑은 후, 이를 바탕으로 detection, recognition을 모두 수행한다고 이해했습니다. 이 때, 결국 텍스트를 인식하기 위해서는 recognition 단계 이전에 위치를 특정하는 detection이 수행될 것으로 생각되는데 그렇지 않은건가요? e2e방법에서 text spotting이 구체적으로 어떻게 수행되는지 알려주시면 감사하겠습니다. (만일 detection 이후 recognition이 수행된다면 동일하게 error propagation이 일어날 것 같아서요)
안녕하세요 질문 감사합니다.
애기해주신대로 recognition은 detect된 것을 바탕으로 이미지가 크롭되고 크롭된 이미지 위에서 진행되기 때문에 아예 detect되지 않거나 GT와의 차이가 큰 경우에는 기존의 two-step method가 갖던 error accumulation 문제로부터는 자유롭지 못한 게 맞습니다.
다만, 이 논문에서 제안한 모델은 recognizer 헤드로 detection 결과를 가지고 crop된 detection feature를 함께 전달하는데요 feature map은 raw한 원본 이미지에서의 픽셀과 feature map에서의 픽셀이 완전히 매칭되지 않는다는 점에서 같은 영역에 대해서 크롭이 되더라도 이미지에서와는 다르게 그 영역 넘어서의 정보를 일부 갖게 됩니다. 그렇기 때문에 GT와의 조금의 차이가 나더라도 일부 바운더리가 쳐지지 않은 부분에서도 인식이 되었다고 합니다.
안녕하세요 지연님 좋은 리뷰 감사합니다.
궁금한점이 하나 있는데 bridge 부분에서 초기 0 가중치로 학습하는 부분이 다른 분포를 가지는 detection feature와 recognition feature를 초기에 잘 섞이지 않게하고 천천히 학습하는 것 같은데, 이때 0을 유지하는 기간같은것이 데이터 분포에 많은 영향을 받을 것 같은데, 파인튜닝의 난이도가 어떨지 궁금합니다.
질문 감사합니다!
흥미로운 질문인 것 같습니다만 논문에서는 초기값을 0으로 설정한 다음 이를 일정 기간 동안 유지하지는 않는 것으로 보입니다. 이를 비교한 실험도 있다면 좋았을텐데 아쉽습니다.