안녕하세요 이번주 x-review는 image to 3D 논문입니다. 기존에 3D reconstruction을 진행하면서 3D-gaussian을 mesh화 한 뒤에 시뮬레이터를 위한 asset으로 활용하려고 했으나 gaussian -> mesh 과정에서 어려움이 있어 TRELLIS라는 image to 3D모델을 활용해보았습니다. 단일, 혹은 두장의 RGB를 통해서 생각보다 깔끔하고 사실적인 asset이 만들어지는 것을 확인해볼 수 있었는데요, rigid object 외에 관절 구조를 가진 서랍이나 전자레인지 같은 articulated object에는 대응할 수 없다는 문제점을 가지고 있었습니다. 관절 구조를 가진 물체는 한 장의 이미지로는 손잡이나 닫혀있는 구조를 통해서 관절이 어떻게 작동하는지, 내부 구조가 어떻게 구성돼있는지를 예측해야하기 때문에 단순한 image to 3D 구조 외에 확장된 파이프라인이 필요하다고 생각하던중 해당 내용을 다룬 논문을 찾게 되어서 읽어봤습니다. 3D mesh 자체를 생성하는 것은 아니지만 articulation 관계를 정립하는 과정에서 VLM의 활용방법을 확인해볼 수 있었습니다.
Introduction
실내 환경에는 사실 articulated object들을 흔하게 발견할 수 있고, 로봇이 이들과 상호작용 하기 위해서는 시뮬레이션에서 활용할 수 있는 고품질의 3D asset이 필수적이라고 생각합니다. 다만 역시 이를 전문가가 일일이 제작하는 것은 비용적으로 매우 비효율적이고, 기존의 모델들은 사용자가 원하는 수준의 형태를 구현하기 어려운 구조이기 때문에 새로운 모델이 필요하다고 주장합니다. 따라서 저자들은 RGB 이미지 한 장으로 articulated object를 생성하는 문제를 설정하고, 닫힌 상태에서 가려진 부분들에 대한 모호성, 같은 카테고리 안에서도 다양하게 움직이는 관절들, 식별하기 힘든 작은 부품들을 구체적인 문제로 삼아 해결 방안을 제시했다고합니다. 기존 generative model들의 이점을 살리기 위해 generative model을 사용하되 VLM을 활용해 part connectivity graph를 추론하고, 이를 이미지와 함께 활용해 디퓨전 모델을 통해 부품의 바운딩 박스·라벨·관절 속성 등을 생성하고, 생성된 속성에 맞춰 파트 라이브러리에서 메시를 검색·조립해 최종 3D 객체를 완성한다고 합니다.
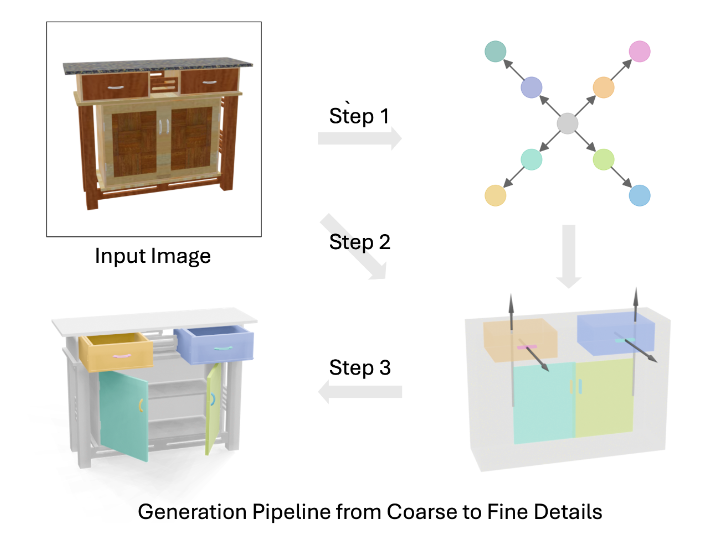
이를 통해 단일 이미지 기반 articulated object 생성을 처음으로 탐구한 점, coarse-to-fine 모듈식 파이프라인을 설계해 해석 가능성과 편집 용이성을 확보한 점, diffusion 모델을 통해 시각적인 요소 뿐 만 아니라 운동학적 일관성을 달성한 점, 여러 데이터셋에서 기존 방법보다 우수한 재구성 정확도와 일반화 성능을 입증했다는 점을 contribution으로 주장했습니다. 아래를 보면 다양한 구조에 대해 articulation이 적용된 결과물을 보여줍니다.

Methods
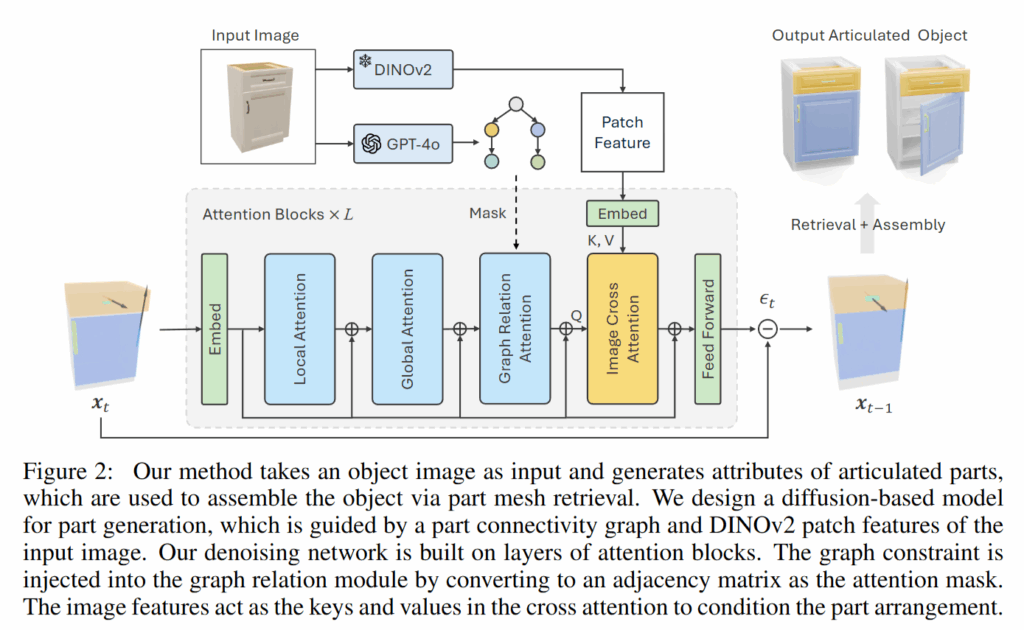
SINGAPO는 크게 그래프 예측, 부품들의 속성 생성, 3D 모델 조립의 순서로 이루어집니다. 하나씩 살펴보도록 하겠습니다.
Step 1: Part Connectivity Graph Generation
먼저 단일 이미지로부터 articulated object의 구조를 생성해야 하기 때문에, 이를 위해 물체의 aprt간의 연결구조와 kinematic hierarchy를 표현하는 Part Connectivity Graph를 생성합니다. Part들을 전부 다 노드로 표현하고, 노드들 간의 운동학적 관계를 나타내는 graph를 생성합니다. 이 때 edge가 운동학적 관계를 의미하는데, 부모 자식 관계를 나타내는 directed edge, undirected edge, articulation 정보를 담고있는 articulation edge로 구성합니다.
Graph 생성을 위해서는 GPT-4o를 사용했다고 합니다. 먼저 하나의 RGB이미지에 Grounding DINO와 SAM을 활용해 객체를 인식하고 객체의 part segmentation을 수행하고, segment에 대해 bbox를 추출해줍니다. 모든 bbox는 결과물 object를 구성하는 part 후보로 취급한다고 합니다.
DINO를 통해 semantic한 object proposal들을 얻은 후, GPT-4o가 이러한 box들을 인간과 같은 방식으로 해석하고 semantic category와 관계를 추론하도록 프롬프팅을 한다고 합니다. 예를 들어, 이미지에 문 손잡이, 상단 문, 하단 서랍 등이 존재한다면, GPT-4o는 이들 사이의 계층 구조를 묻는 프롬프트를 통해 “하단 서랍은 상단 문과 형제 관계이다” 또는 “손잡이는 상단 문의 자식이다”와 같은 답변을 생성한다고 합니다.
프롬프트는 in-context learning 방식으로 구성되며, 총 4개의 예시 질문과 그에 대한 정답이 사전 삽입되어 있습니다. 예시들은 다양한 가전 제품에 대해 구성 요소들이 어떻게 연결되어 있는지를 묻는 형식으로 작성되며, object의 카테고리를 명시하고, 그 object를 구성하는 부품들의 이름 목록과 각각의 bounding box 위치 정보를 나열한 후 part 간의 부모-자식 관계, 형제 관계, 그리고 articulation 여부를 세 가지 질문으로 제시한다고 합니다. 출력은 텍스트 형태이고, 후처리를 통해 directed graph로 변환한다고 합니다. 아래와 같이 프롬프트도 공개가 돼있었습니다.
System:
You are an expert in the recognition of articulated parts of an object in an image.
You will be provided with an image of an articulated object. You should follow the following steps to achieve the task:
• 1) Recognize all the articulated parts of the object in the image, in the choice of ['base', 'door', 'knob', 'handle', 'drawer', 'tray']. Note that there
should be always one "base" part, and trays can only exist in microwaves. Each handle or knob should be attached to a door or a drawer. Each
door should only have one handle or knob at most.
• 2) Describe how the parts are connected and then organize them in a part connectivity graph. The "base" part is always the root of the graph.
Here is an example of your response:
I recognize all the articulated parts of a storage furniture, they are:
base, drawer (attach to base), handle (attach to drawer), handle (attach to drawer), door (attach to base), handle (attach to door).
The part connectivity graph for the object is:
```json
{"base": [{"drawer": [{"handle": []}, {"handle": []}]}, {"door": [{"handle": []}]}]}
```또 당연한 말일수도 있지만 (어떻게 생각하니 당연하지 않을 수도 있겠네요,,) 같은 장면을 이미지로 전달하는것보다 “하나의 핸들이 달린 구조를 가진 서랍장이 두 개 있다”와 같이 텍스트로 전달할 때 part connectivity grpah를 더 잘 만들었다고 합니다.
추가적으로 저자들은 VLM 기반 구조 추론 방식이 end-to-end 학습 방식보다 사전 학습 과정에서 구조적 묘사와 object 구성에 대한 방대한 텍스트-이미지 페어를 학습했기 때문에, 일반적인 관계에 대한 추론 능력이 우수하다는 장점을 가진다고 합니다. 또한 프롬프트를 수정하거나 in-context 예시를 교체함으로써, 그래프 예측의 행위를 명시적으로 통제하거나 보완할 수 있는 여지가 크다는 점에서 우수하다고 주장합니다.
Step 2: Abstract Part Attribute Generation
이제 생성된 Part Connectivity Graph와 RGB로부터 각 part들의 속성을 추론합니다. 3D geometry를 최종적으로 만들어내기 전에 각 부품들의 속성을 추상적으로 정의하는 중간 표현을 만들어주는 과정이라고 합니다. Part Attribute는 세가지 요소를 가지고 있습니다.
각 부품의 3D 위치와 크기를 나타내는 6-DOF bounding box 정보, 부품의 semantic label, 해당 부품이 articulation 관계를 갖는 경우 그에 대한 articulation type, axis, 그리고 range를 설정한다고 합니다. 이 모든 정보는 이후 geometry retrieval 및 assembly에 핵심적인 조건 정보로 활용된다.
저자들은 part attribute 예측을 위해 Diffusion Transformer 기반의 conditional generative model을 설계했다고 합니다. 이 모델은 image feature와 Part Connectivity Graph를 conditioning으로 받아서, part attribute를 생성합니다. 이때 입력으로는 이미지에서 DINOv2를 사용하여 추출한 high-resolution patch feature와 각 부품의 semantic label, 그래프 adjacency matrix, 그리고 전체 객체의 category 정보가 들어간다고합니다. label로는 앞선 단계에서 GPT-4o가 예측한 결과를 사용하고, category는 PartNet-Mobility나 ACD 데이터셋의 사전 정의된 클래스 중 하나를 사용한다고 합니다. 찾아보니 ACD 데이터셋은 2024년에 공개된interactive articulated 3D object들로 구성된 대규모 데이터셋이라고 하네요. articulated 3D object의 자동화(?) 대한 연구들도 활발히 진행중인거 같습니다.
아래는 transformer 구조에 대한 내용인데 사실 완전히 그 구조가 어떤 의미를 갖는건지는 이해를 못 했습니다.. 트랜스포머와 디퓨전을 좀 공부해야 할 것 같습니다 허허,,
SINGAPO의 Diffusion Transformer는 CAGE (Composable Attention Graph Encoder) 아키텍처를 기반으로 하며, 각 part attribute를 하나의 토큰으로 간주한 후 attention 연산을 수행한다고 합니다. 각 attention block은 총 세 종류의 self-attention으로 구성됩니다. Local attention은 각 부품 내부의 속성 간 조화를 조정하며, global attention은 부품 간 상호작용을 통해 전체 객체가 구조적으로 일관성을 갖도록 돕고, graph relation attention은 앞서 생성된 Part Connectivity Graph의 edge 정보를 attention mask로 반영하여 구조적 제약을 명시적으로 적용한다고 합니다.
Diffusion Transformer는 두 개의 stage로 구성되며, 각각 앞서 등장한 attention 메커니즘을 포함하고 있습니다. 첫 번째 block은 Image Cross-Attention (ICA) 모듈을 포함하고 있어서 이 모듈은 각 part query와 DINOv2 patch feature 간의 cross-attention을 수행함으로써, 각 부품이 이미지의 어떤 위치에 대응하는지를 학습한다고 합니다. 이때 attention score는 부품과 이미지 간의 명시적인 위치 대응 정보를 내포하므로, part의 공간 배치 예측에 매우 중요한 정보를 제공한다고 하네요. Appendix에 포함된 figure 입니다.
두 번째 block은 Graph-Masked Self-Attention을 수행합니다. 여기서는 Part Connectivity Graph의 adjacency 정보(graph가 인접했는지)가 attention mask로 주어져, 연결된 부품들 간에만 attention이 작동하도록 한다고 합니다. 이를 통해 부품 간의 articulation 관계나 위치 정렬 정보를 구조적으로 보존하면서 속성 예측을 수행할 수 있다고 하빈다. Articulation 관계를 명확히 유지하려면 motion parameters 예측 시 이러한 구조 정보가 필수적이므로, Graph-Masked Attention은 학습의 일관성을 유지하는 데 핵심적인 역할을 한다고 하네요.
이 모델은 모든 part에 대해 속성을 나타내는 32-dimensional vector를 생성하며, 여기에는 3D bounding box의 위치와 크기, semantic label, joint type, axis, 그리고 articulation range가 포함된다고 합니다. Diffusion 방식이기 때문에 학습 시에는 ground truth 속성값과의 noise injection 및 denoising 단계를 거치며, 생성 시에는 랜덤 noise에서 출발하여 점차 현실적인 속성값으로 수렴하게 됩니다.
또한 모델 훈련 시에 Classifier-Free Guidance (CFG)를 활용한다고 합니다. 이는 이미지, 그래프, 카테고리 조건 중 일부를 무작위로 drop하고 모델이 이를 조건 없이도 예측하도록 학습함으로써 오버피팅을 방지하고 일반화 성능을 향상시키는 기법이라고 합니다. 이러한 CFG는 특히 unseen category나 noisy graph 예측 결과가 들어왔을 때도 모델이 안정적으로 속성을 생성하도록 도와준다고 합니다.
Loss는 기본적인 디퓨전 모델에서 사용하는 noise residual loss와 foreground mask와 attention score간의 일치도를 평가하는 loss로cross attention map이 이미지 내 객체의 foreground 영역에 집중하도록 도와줄 수 있는 구조를 가지고 있다고 합니다.

Step 3: Part Geometry Retrieval and Assembly
마지막으로 각 part attribute vector에 대응하는 실제 mesh geometry를 선택하고, 이를 공간적으로 적절히 배치하여 전체 articulated object를 구성해줍니다. 이를 위해 SINGAPO는 PartNet-Mobility 및 ACD 데이터셋에서 미리 수집된 part-level mesh 라이브러리를 활용합니다.
각 part attribute vector는 semantic label, articulation type, joint axis, joint range, 그리고 6D pose 를 포함하기 때문에 geometry retrieval은 attribute vector 정보를 기반으로 part mesh 후보들을 필터링합니다. 이 과정에서 articulation type과 joint axis 정보를 통해 각 candidate mesh의 articulation property와 일치하는지 확인합니다. 예를 들어 ‘revolute joint with horizontal axis’와 같은 조건에 부합하는 메쉬만을 고려할 수 있습니다.
그 다음, 최종 candidate들 중에서 어느 메쉬가 가장 적절한지를 선택하기 위해 SINGAPO는 pre-trained CLIP feature space를 활용한 similarity matching을 수행합니다. 마지막으로 선택된 각 part mesh는 앞서 예측된 6-DOF pose를 기반으로 공간적으로 배치되며, articulation joint의 기준 축과 위치에 따라 부모와 자식 부품 사이에 물리적으로 일관된 연결 관계가 설정됩니다. 이 연결 관계는 articulated USD (Universal Scene Description) 형식으로 저장되며, 물리 시뮬레이터 상에서 joint rotation, translation 등이 실제로 수행될 수 있도록 구성된다고 합니다. 어떤식으로 이루어지는지 코드를 통해 살펴봐야 할 것 같습니다. Articulation consistency를 확보하기 위해 local refinement 단계도 포함됩니다. 예측된 pose나 articulation axis가 실제 메쉬 구조와 충돌하거나 일관성이 없을 경우, 부품 간 joint alignment를 맞추기 위한 미세한 offset 조정이 수행된다고 합니다.
Experiments
평가지표는 생성된 articulated object가 실제 정답 객체와 구조 및 운동학적으로 얼마나 유사한지를 측정하기 위해 설계되었습니다. Bounding box 간의 겹침 정도를 측정하는 generalized IoU 기반의 거리(dgIoU), 각 파트 중심 간 유클리디안 거리(dcDist), 그리고 파트 표면 mesh에 대해 샘플링된 포인트 간 평균 거리인 Chamfer Distance(dCD)가 있으며, 이는 각각 형태 추상 수준, 위치 정밀도, 기하 구조 수준의 유사도를 평가합니다. 이 외에도, 이미지에서 예측된 articulation graph의 정확도를 평가하기 위해 올바른 graph topology 예측 비율(Acc)과 파트 간 물리적 충돌 가능성을 나타내는 평균 중첩 비율(AOR)도 함께 사용됐습니다.
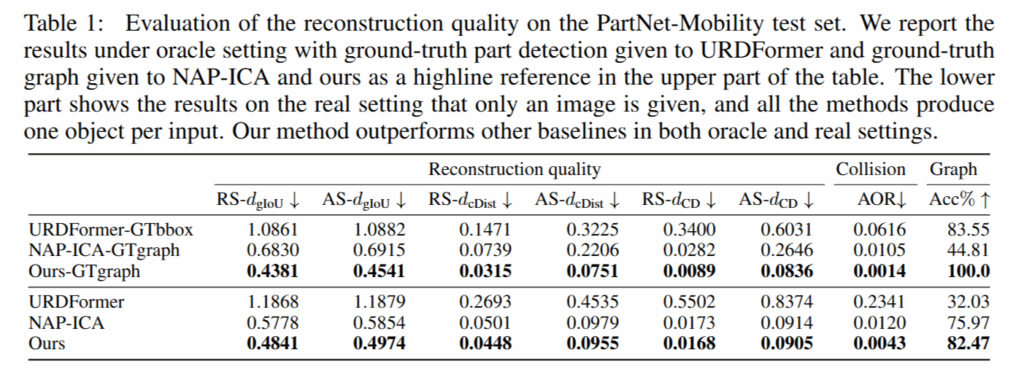
우선 PartNet-Mobility test set으로 URDFormer와 NAP-ICA와 비교했다고 합니다. URDFormer는 SINGAPO의 구조에서 diffusion 과정이 빠진 Transformer 구조만으로 part attributes를 생성하는 모델이고 NAP-ICA는 NAP 프레임워크에 image cross-attention 모듈(ICA)을 붙인 baseline이라고 합니다.
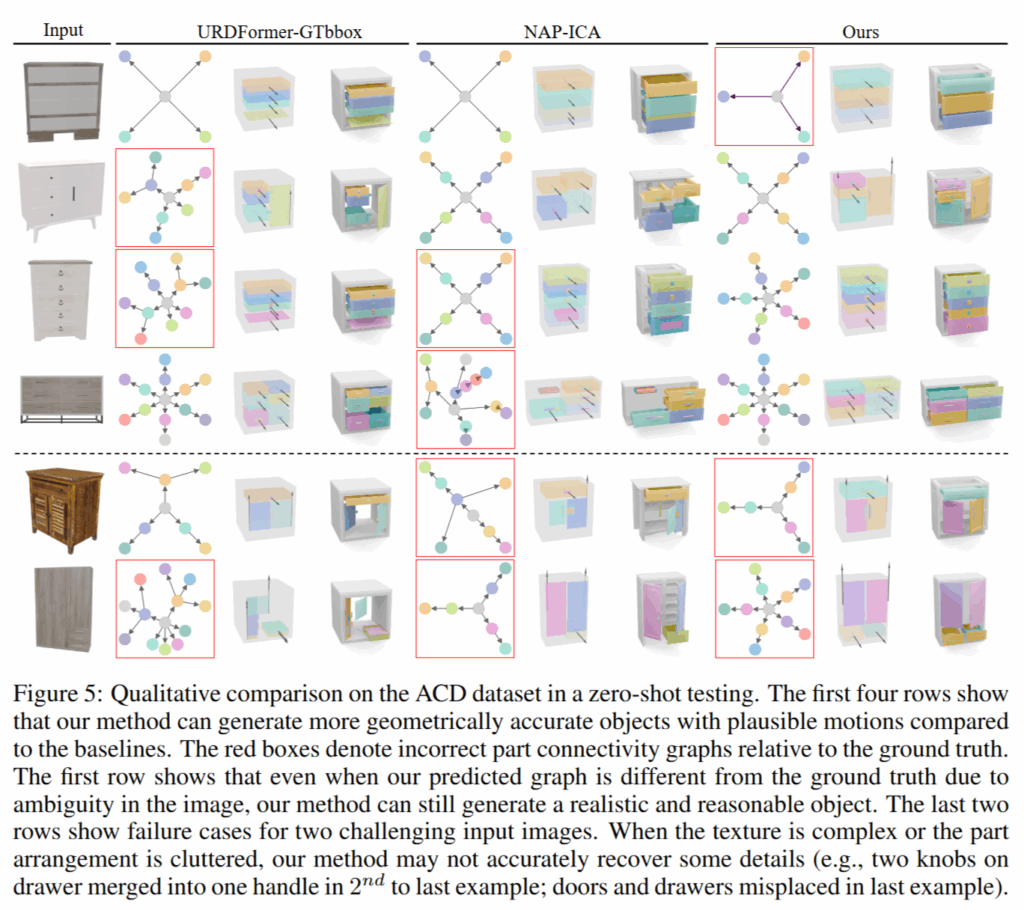
시각적인 결과를 봤을때도 SINGAPO의 결과가 더 뛰어나고, articulation 구조를 예측하는 graph를 보게되면 빨간 박스가 틀린 그래프인데, 더 정확한 구조를 예측하는 것을 볼 수 있습니다. 다만 texture가 많은 이미지거나 clutter된 환경에서는 제대로 작동하지 않는다고 합니다.
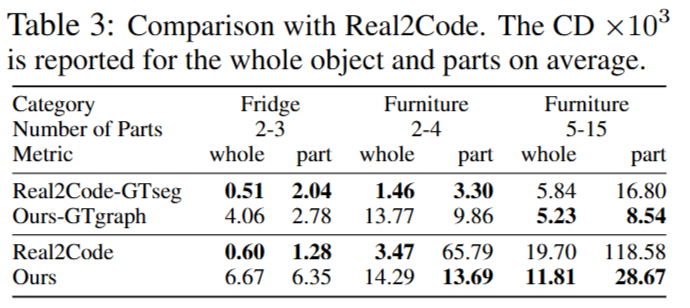
Real2Code 와 같은 지표를 통한 비교도 진행했는데요, Real2Code는12개의 multi-view RGB 이미지를 입력으로 사용하여 object의 형상과 관절 구조를 복원하는 기법입니다. 여기서 저자는 Real2Code는 관절이 작동하는 과정의 영상을 12개나 담아야하는 Real2Code에 비해 SINGAPO는 단 한 장의 닫혀있는 RGB 이미지만을 사용하여 비슷한 수준의 articulation을 예측했다는 점을 강조합니다.
또한 공정한 비교를 위해 Real2Code 논문에서 제시한 evaluation protocol을 그대로 따랐다고 합니다. Table 3에서 확인할 수 있듯이, SINGAPO는 부품 수가 많고 구조가 복잡한 객체에 대해서 더 뛰어난 reconstruction 성능을 기록했다고 합니다.
안녕하세요, 좋은 리뷰 감사합니다.
Input을 기준으로 Grounding DINO와 SAM을 활용해서 segment를 하게 되면 물체 전체에 대해서 자세하게 part를 나누어서 output으로 뱉을 것 같은데요, 그 중에서 예시들과 같이 책장의 문이나 손잡이 등만 part라고 정의하는 부분은 어디일까요 ?? 프롬프트에서 사전에 부품들의 이름 목록을 통해 필터링 되는 것일까요 ?
해당 task에서 전체 물체 중에 다루는 부분에 대한 정의를 명확히 잘 모르겠어서 질문 드립니다. 로봇을 가지고 동적인 작업이 가능한 부분들을 의미하는 것인지 궁금합니다 . .
감사합니다.
안녕하세요 건화님 댓글 감사합니다.
Part는 시스템 프롬프트에 서랍을 찾을때 handle, door, base, knob 등등 사전정의를 해두고 그 안에서 찾으라고 지시합니다.
해당 task에서 다루는 부분에 대한 정의는 말씀주신 것처럼 로봇이 task를 진행함에 있어서 조작 대상이 관절구조를 가지고 움직이는 물체인 경우에 서랍, 문, 손잡이 등등 움직이는 파츠들과 손잡이들을 부분으로 합니다.