안녕하세요, 예순 세번째 X-Review입니다. 이번 논문은 2024년도 TPAMI에 올라온 Hi-SAM: Marrying Segment Anything Model for Hierarchical Text Segmentation입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
Text는 pixel 단위, word 단위, line 단위, paragraph 단위처럼 계층적으로 구성되어 있습니다. 이 계층 구조를 통해 다양하게 응용해볼 수 있는데, 예를 들어 pixel 단위로 text segmentation을 한다면 글자 폰트 스타일을 바꾼다던가, 혹은 영상 내에 있는 text를 없앤다던가 할 수 있겠으며, visual text understanding을 하기 위해서는 문단 단위의 text를 묶어야 하는 것처럼 text의 공간적 layout 정보가 필요합니다.
하지만, 지금까지의 연구들은 대부분 이 계층 구조들 중 하나 혹은 일부에만 초점을 맞춰 진행되어 왔으며, pixel → word → line → paragraph로 이어지는 이 text 구조 전체를 한번에 통합해 다루는 모델은 꽤 적습니다. 본 논문에서는 이 시점에서 “pixel부터 문단까지 포함하는 다양한 계층 구조를 하나의 프레임워크에서 처리해볼 수 없을까?” 하는 질문을 던집니다.
그런데 이런 네 계층을 다루는 모델을 구성하는게 어려운 이유는 이 모든 계층 구조를 포함한 데이터셋이 부족하다는 점인데요.
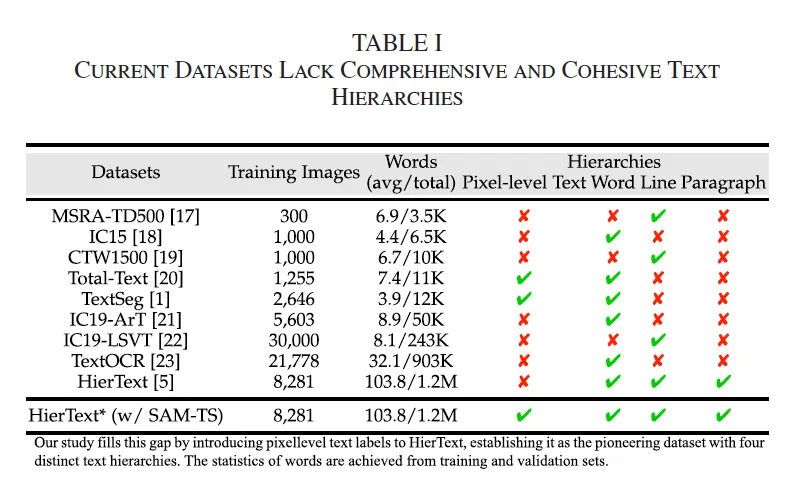
위 Table1에 여러 데이터셋와, 그 데이터셋에 포함된 계층 구조를 보여주고 있습니다. 보시면, 마지막 행에 있는 HierText만을 제외하고는 한 계층만 다루거나, 아니면 두 계층만을 다루고 있습니다. 또, 이 HierText 데이터셋도 pixel level의 mask는 포함이 되어 있지 않고 학습 데이터 수도 많지 않죠. 그렇기에 이 모든 계층을 아우르는 annotation을 확보하는 것이 hierarchical text segmentation을 수행하는데 있어 필수적이라고 볼 수 있겠습니다.
본 논문에서는 제목에서도 알 수 있듯이 다양한 입력 prompt에 따라 object mask를 생성해낼 수 있고, 대규모 데이터의 annotation을 자동화하는데 사용되고 있는 SAM을 기반으로 하고 있는데요. 이 SAM의 특성들을 잘 사용해 hierarchical text segmentation 모델을 설계함으로써, 앞서 던진 질문 “pixel부터 문단까지 포함하는 다양한 계층 구조를 하나의 프레임워크에서 처리해볼 수 없을까?” 에 대한 답을 하고자 합니다.
구체적으로, pre-trained된 SAM과 계층적으로 완전하지 않던 데이터셋들을 함께 사용해서 text-centric hierarchical segmentation 모델 Hi-SAM을 제안합니다. Hi-SAM은 우선 HierText 데이터셋에서 유일하게 없던 pixel level mask를 생성하는데 SAM을 사용하고자 했는데, 이런 automatic mask generation(이하 AMG) 모드에서는 기존 SAM이 사용하던 object-agnostic grid point 기반의 prompt 방식을 그대로 사용하긴 어렵습니다. 왜냠 그냥 다른 object들과는 달리 text segmentation task에서는 오직 scene 영상 내의 text만 foreground로 보고 mask가 나와야 하고, 동시에 word, text line, paragraph 단위로 병렬적으로 segmentation할 수 있어야 하기 때문인데요.
이런 문제를 해결하기 위해 Hi-SAM은 먼저 pixel level의 mask를 먼저 생성한 후, 그 후에 그 mask 영역 내의 point를 sampling해 prompt로 사용하고, 그 이후에 word, line, paragraph mask를 prediction하는 단계적인 방식을 사용합니다. 또, SAM은 object segmentation을 타깃으로 하기에 mask 해상도가 작아 text의 세밀한 표현이 어려운데, 이점을 해결하기 위해 고해상도 mask feature를 생성하는 모듈을 추가하였습니다. 이렇게 구성된 모델을 SAM-TS라구 합니다.
이 SAM-TS를 기반으로 하여 end-to-end 학습 가능한 hierarchical text segmentation model Hi-SAM을 제안하는데, 여기서는 기존 pixel-level segmentation을 수행하는 S-Decoder에 추가로, hierarchical mask를 생성하기 위한 H-Decoder를 붙여 하나의 모델로 word, text line, paragraph 단위의 segmentation을 동시에 수행할 수 있도록 하였습니다.
이 Hi-SAM은 두 방식으로 동작할 수 있도록 설계되었는데요.

위 Fig1을 보시면 Automatic Mask Generation과 Single Point Prompt라고 나눠져 있는 것을 볼 수 있습니다. AMG(Automatic Mask Generation)모드에서는 전체 영상에서 pixel-level segmentation을 수행하고 이 mask에서 point를 샘플링해 hierarchical mask를 생성하는 과정을 자동으로 수행하게 되구요. PS(Promptable Segmentation) 모드에서는 user가 클릭한 한 point를 기반으로 해당 위치의 word, line, paragraph mask를 생성합니다. 보다 구체적인 내용은 아래 method단에서 살펴보도록 하겠습니다.
2. Method
2.1. Preliminary
그 전에 잠깐 SAM에 대해 간략 설명하고 넘어가도록 하겠습니다. SAM 모델은 크게 ViT 기반 백본, prompt encoder, mask decoder 세 부분으로 구성되어 있습니다. 영상이 입력으로 들어오면 백본에서 64×64 크기의 embedding이 나오게 되구요, 여기에 prompt encoder가 point, box, mask 등의 다양한 입력을 받아 그에 맞는 prompt token을 생성합니다. 이 image embedding과 prompt token이 mask decoder로 들어가게 되면 이 decoder는 DETR처럼 object query 개념의 output token을 사용하게 되고, 각 object token을 기반으로 MLP를 통해 dynamic weight을 만들어 최종 mask를 생성하게 됩니다. 이 mask는 보통 256×256 해상도로 나오게 됩니다.
2.2. Overview of Hi-SAM
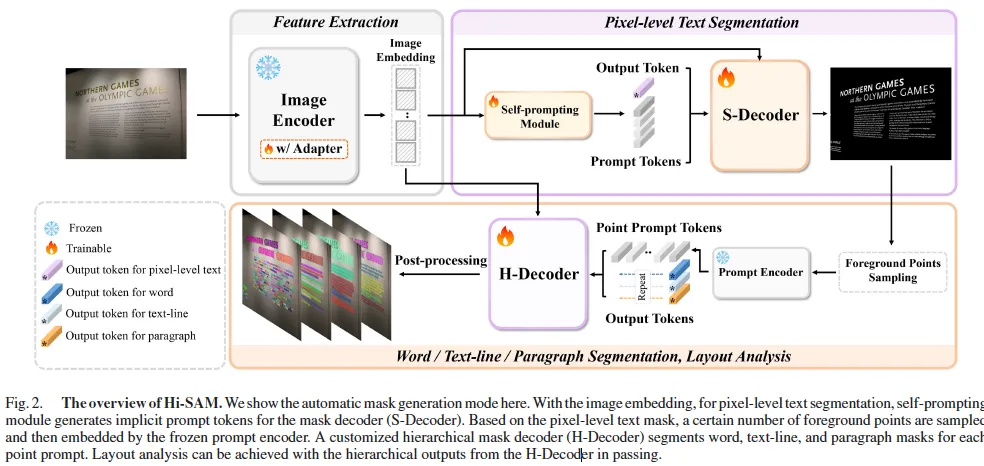
이제 Hi-SAM에 대해 살펴보도록 하겠습니다. 위 Fig2를 통해 전체적인 구조를 살펴볼 수 있는데요. 보시면 먼저 한 이미지에 대해 pixel level로 text segmentation을 수행한 다음 (보라색 박스), 이 결과를 바탕으로 hierarchical segmentation을 수행(주황색 박스)하는 단계적인 segmentation 방식을 사용합니다.
또 크게 다섯가지 모듈로 구성이 되어 있는데, 각각 image encoder, self prompting module, S-Decoder, Prompt encoder, H-Decoder가 그에 해당합니다. Image encoder는 SAM의 ViT 백본을 그대로 사용하게 되구요. Self prompting module은 이 image 안에 중요한 영역 내에서 자동으로 prompt를 생성하는 역할을 하며, S-Decoder는 SAM의 mask decoder를 기반으로 pixel level의 mask를 생성합니다. 이렇게 image encoder, self prompting module, S-Decoder로 구성된 모델을 SAM-TS라고 하게 되구요. HierText 데이터셋에서 pixel-level mask가 존재하지 않았던 문제를 해결하기 위해 이 SAM-TS를 활용하여 반자동으로 pixel level mask를 생성하게 됩니다.
pixel level의 mask가 생성되면 이 mask 내에서 일정 개수의 foreground point를 sampling하게 되며, 이 point들이 이후 hierarchical segmentation을 위한 prompt로 사용됩니다. 즉, point를 기반으로 다시 word, line, paragraph mask를 prediction하는 구조입니다. 이런식으로 동작하는 모드는 AMG(Automatic Mask Generation) 모드라구 하구요. 또, 기존 SAM이 user가 입력으로 prompt를 줄 수있다는 특징을 살려서 PS(Promptable Segmentation)모드도 지원하는데, 이 모드에서는 user가 클릭한 단 하나의 point를 기반으로 해당 위치의 word, line, paragraph mask를 예측할 수 있게 됩니다.
각 부분에 대해 아래에서 구체적으로 살펴보도록 하겠습니다.
2.3. Feature Extraction
먼저 Feature Extraction 부분인데요, SAM의 Image encoder를 그대로 사용했다고 했었지만, SAM은 원래 일반적인 object segmentation을 위해 학습된 모델이기에 좀 얇은 구조를 가지고 있는 text 구조를 segmentation하기 위해서는 한계가 있었다고 합니다. 따라서 Fig2에서 보이는 것처럼 adapter를 넣어 tuning하는 방식을 사용하였습니다.
2.4. Pixel-Level Text Segmentation
Self-prompting Module
이후 image encoder로부터 feature가 추출된다면 본 논문에서 설계된 self-prompting module로 들어가는 것을 볼 수 있는데요. 기존 SAM은 point나 box처럼 어떤 prompt가 주어져야 동작하도록 되어 있지만, Hi-SAM에서는 이런 입력 없이 image 자체로부터 implicit한 prompt를 생성할 수 있도록 하였습니다. 그 기능을 하는 것이 self-prompting module입니다.
이 self-prompting module의 아이디어는 백본 타고 나온 image embedding에는 이미 text의 visual feature가 충분할테니, 이 embedidng자체로부터 prompt를 뽑아내자는 것입니다.
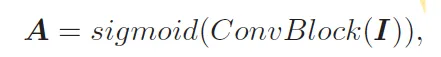
먼저, image embedding을 convblock을 태워 attention map A를 뽑아내게 되구요.
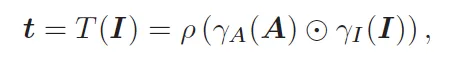
이 attention map A를 기반으로 원래 image embedding(I)과 element-wise 곱한 다음 pooling을 통해 token t를 추출하게 됩니다.
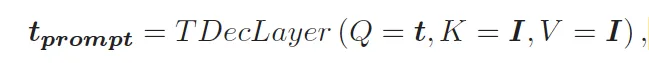
마지막으로 이 prompt token을 query로 image embedding을 key, value로 transformer decoder를 태워 최종 prompt t t_{prompt}를 뽑아내게 됩니다. 이렇게 나온 최종 prompt token들이 S-Decoder로 넘어가 pixel-level의 text mask를 추출하게 되겠죠. 정리하자면, 이 sefl-prompting 모듈은 user의 input prompt 없이도 image내에서 text 관련 정보가 있는 부분을 스스로 찾아내고, 이를 바탕으로 prompt를 생성해내는 모듈이라고 보심 됩니다.
S-Decoder with High-resolution Mask Features
다음은 S-Decoder 부분입니다. Hi-SAM에서는 pixel level text segmentation의 성능을 높이기 위해 기존 SAM 디코더를 사용하지 않고 더 큰 해상도의 mask를 생성하도록 확장한 디코더를 사용하였는데요. 이는 기존 256×256 해상도의 mask feature로는 fine한 text shape을 표현하기에는 부족했기 때문입니다.
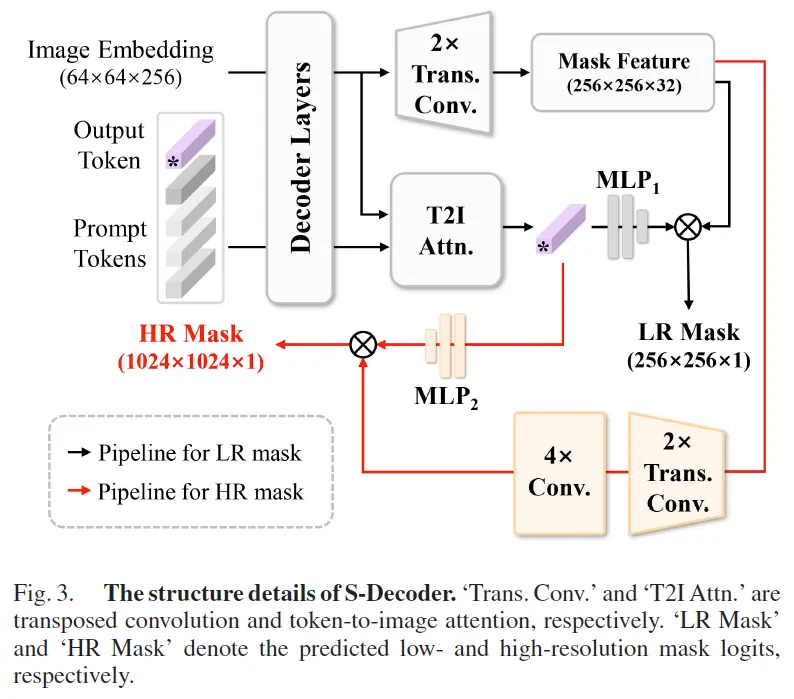
전체적인 S-Decoder 구조는 위 그림3에서 확인할 수 있는데요. 보시면 먼저 이전에 나온 output token 중 첫 번째(보라색 토큰)을 t_s^{\text{out}} \in \mathbb{R}^{1 \times 256}이라고 하고, 여기에 앞서 self-prompting module에서 생성한 prompt tokens t_prompt ∈ ℝ^{N \times 256}를 concat하면 (1+N)x256 크기의 input이 됩니다.
이를 S-Decoder에 입력으로 넣으면 token-to-image attention(T2I Attn)과 transposed convolution(Trans. Conv.)를 각각 태워 update된 output token (보라색 token) \hat{t}_out과 저해상도 mask feature F를 얻게 됩니다.
이 \hat{t}_out은 MLP를 태워 F(저해상도 mask)와 shape을 맞춰주고 이후 point wise 곱을 통해 mask logit M을 뽑게 됩니다. 최종적으로 이 mask를 image 크기에 맞춰 interpolation하게 되구 thresholding을 통해 binary mask로 나오게 됩니다.
여기까지가 기존 SAM decoder 동작 과정에 해당하구요. 그림에서는 검정색 화살표가 이에 해당합니다. 이 구조만으로는 작은 글자를 표현하기 어려워 F(저해상도 mask)를 더 고해상도로 확장하고자 하였습니다. 추가된 부분은 빨간색 화살표 부분을 보시면 되는데, 먼저 기존 F를 두 transposed conv를 통해 1024×1024로 upsampling한 다음 이렇게 얻어진 feature를 다시 4개의 conv layer로 refine해서 최종적으로 F_hr ∈ ℝ^{1024\times1024\times16} 크기의 고해상도 feature를 얻어냅니다. 이때도 \hat{t}_out은 3 MLP를 거쳐 차원을 맞추게 되고 F_ht과 point wise 곱을 통해 최종 고해상도 mask logit M_hr을 만들어 사용하게 됩니다.
이렇게 decoder 쪽에서만 고해상도로 해주는 과정은 기존 image super-resolution과는 좀 다른데요. 일반적인 super resolution은 input image자체의 해상도를 키워 encoder에서 연산량이 엄청 들게 되는데, Hi-SAM은 encoder는 그대로 두고, decoder에서만 고해상도 연산을 하도록 설계하여 메모리나 연산량 측면에서 효율적이라고 할 수 있습니다.
Semi-automatic Annotation of Pixel-level Text Masks
Intro에서 HierText 데이터셋은 유일하게 word, line, paragraph에 대해 annotation이 되어 있지만, pixel-level segmentation label은 없다는 언급을 했었습니다. 이를 해결하기 위해 본 논문에서는 SAM 기반의 text segmentation 모델인 SAM-TS를 먼저 학습시켜 mask를 생성하는데 활용하고자 했습니다.
생성 과정은 여러 단계를 거치도록 했는데, 먼저 맨 처음에는 문서나 포스터, 손글씨처럼 text가 조밀하고 세밀한 image를 선정해(418장) Adobe 포토샵을 통해 대비를 조절하거나, 반전, 브러시 등등 다양한 도구를 통해 수작업으로 annotation을 수행하였습니다. 이는 학습용 seed data를 만드는 과정이라고 보심 됩니다.
이렇게 수작업으로 annotation된 418장의 HierText image와 기존 pixel-level label이 있는 Total-Text 데이터셋을 함께 사용해 SAM-TS 모델을 학습시킵니다. 이 모델이 학습되고 나면 나머지 HierText train 이미지에 대해 pixel-level의 mask를 자동으로 생성하도록 합니다. 이때 sliding window 방식을 통해 보다 정밀하게 예측하도록 했는데, 이미지 전체에 대해 한번에 label 뽑는게 아니라 일정 크기의 window를 정해 좀 더 작은 크기에서 여러번 mask를 생성한거라고 보면 됩니다. 이후 사람이 직접 보면서 false positive와 false negative 부분만 수정했다고 합니다.
이 과정을 계속 점진적으로 반복하게 되는데, annotation된 양이 전체 1/8, 1/4, 1/2이 될 때마다 모델을 다시 학습하고 다시 개선했다고 합니다. 점진적으로 사람이 손봐야 할 영역을 줄어들게 되겠고, 결국 전체 HierText train image에 대해 pixel-level label이 생성되게 됩니다. validation 및 test set에 대해서도 같은 방식으로 mask를 생성했다고 합니다.

위 Fig4는 HierText에 대해 SAM-TS를 가지고 자동으로 annotation한 sample 예시입니다.
2.5. Word, Text-Line, and Paragraph Segmentation
다음은 word, text line, paragraph segmentation을 수행하는 과정을 설명드리겠습니다. 앞서 pixel level segmentation을 수행했던 S-Decoder는 image 내에 text 위치를 implicit하게 학습된 token으로 처리했었다면, H-Decoder는 보다 명시적인 point prompt 기반으로 동작하도록 설계하였습니다. 왜냠, 이제 text 전체가 아니라 그 중 특정 지점으로부터 시작해 word, line, paragraph 단위로 영역을 구분해야 하기 때문이죠.
구체적으로 우선 SAM-TS에서 생성한 pixel-level mask에서 K개의 foreground point를 샘플링하게 되는데요, 이 점들은 SAM의 prompt encoder를 통해 처리되어 prompt token t_point로 변환됩니다.
동시에 H-Decoder는 각 point에 대해 N_out개의 output token t_h_out를 받게 되고, 이 output token과 t_point를 concat해 전체 입력으로 사용하게 됩니다. Hi-SAM overview가 나와있는 fig2의 아래 부분에 있는 H-Decoder의 입력 부분을 보시면 이해가 편할 것 같습니다. 이렇게 들어간 입력은 token-to-image attention 과정을 통해 최종적으로 output token 중 마지막 3개 token만 나오게 됩니다. 이 세 토큰은 각각 word, line, paragraph segmentation을 담당하게 됩니다.
원래 SAM에서는 각 token을 어떤 용도로 쓸지 정해두지 않지만, Hi-SAM에서는 이 token들을 명시적으로 hierarchical segmentation에 매핑한 차이점이 있다고 보면 됩니다. 이제 각각 output token은 mask feature와 point wise 곱하게 되어 mask logit을 생성하게 됩니다. mask logit M_{w, l, p} shape은 K x 3 x 256 x 256으로, 즉 K개의 point 각각에 대해 word, lilne, paragraph mask를 하나씩 생성한 구조로 볼 수 있죠. 추가로, S-Decoder에서 했던 것처럼 word segmentation 퀄리티를 높이기 위해 고해상도 mask feature도 사용하였습니다.
3. Experiments
다음은 실험 부분에 대해 살펴보도록 하겠습니다.
3.1. Ablation Studies
Pixel-Level Text Segmentation
Influence on the Adapter and Transformer Decoder Layer in the Self-prompting Module
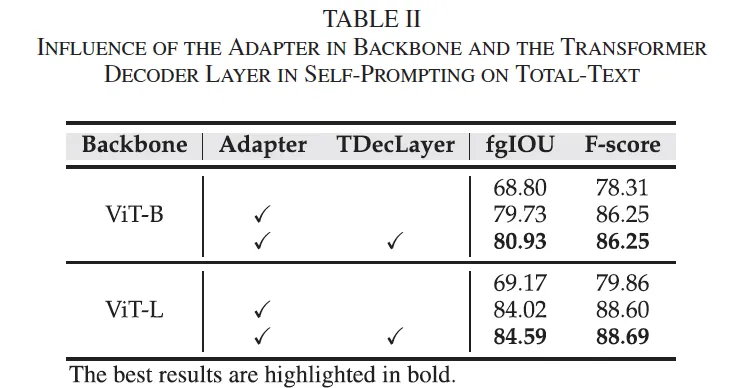
먼저 ablation study 입니다. 그 중 Hi-SAM의 pixel level text segmentation 성능에 있어서 Adapter와 self prompting module 내의 transformer decoder layer의 영향을 살펴보고자 수행한 실험인데요. 보시면 둘 다 사용하지 않은 기존 SAM의 image encoder를 그대로 사용한 경우도 함께 비교하고 있습니다. 결과를 보면 SAM image encoder를 freeze해서 사용한 경우 pixel level의 text를 제대로 구분하지 못해 전반적으로 성능이 좀 낮은 것을 확인할 수 있습니다. 이는 원래 SAM이 text같은 좀 fine-grained한 구조에 약하다는 점을 보여주죠.
이에 대해 lightweight한 adapter만을 추가한 경우 ViT 모델 둘 다에서 확실한 성능 향상을 보입니다. 이를 통해 기존 SAM을 그대로 쓰기보단 text domain에 맞게 부분적으로라도 adaptation하는게 중요하다고 볼 수있죠. 또 여기에 self prompting module에서 생성한 token을 transformer decoder에 한 번 더 refinement하도록 하면 엄청 차이나지는 않지만,, 추가적인 성능 향상을 가져온다는 점도 확인할 수 있습니다.
Effectiveness of High-resolution Mask Features in S-Decoder
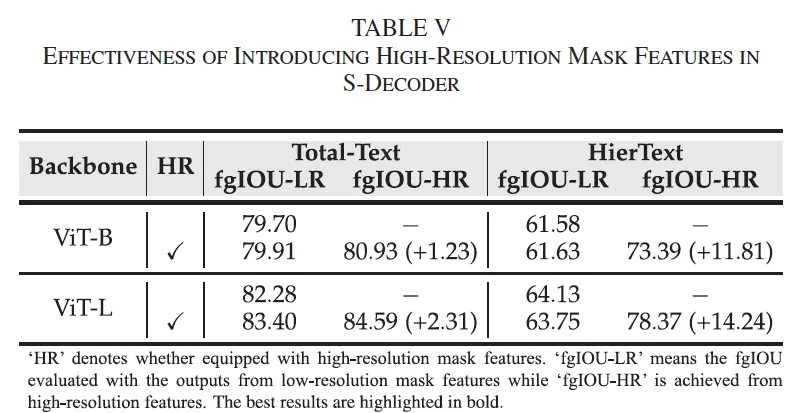
다음은 Hi-SAM에서 제안한 고해상도 mask feature 생성 모듈이 pixel level text segmentation 성능에 미치는 영향을 확인한 실험입니다. 실험은 TotalText와 HierText 데이터셋에 대해 수행이 되었으며, 특히 둘 중에 text 밀도가 좀 더 높고 구조가 복잡한 HierText에서 중점적으로 확인하고자 하였습니다.
위 table5를 보시면 기존 SAM처럼 저해상도 mask feature만 사용한 경우 text의 stroke(획)이나 얇은 부분이 다 손실되어 segmentation 품질이 떨어지지만, HR을 도입하면 좀 더 fine-grained한 구조가 보존되어 전반적으로 성능이 아주 약간 상ㅅㅇ하는 것을 확인할 수 있습니다. 특히 HierText에서 LR에 비해 HR인 경우 14.24% fgIoU 지표가 향상한 것을 확인할 수 있습니다. 이로써 text가 빽빽한 문서 영상이나 손글씨 이미지처럼 좀 더 복잡할수록 HR mask feature의 이점이 더 크다는 걸 보여주죠.

또, Fig6 정성적 결과를 보면 LR mask feature를 쓴 결과는 글자가 윤곽이 다 흐려져 사라져 있는 반면에 HR feature를 쓴 오른쪽 결과는 좀 더 섬세한 디테일까지 보존된 것을 확인할 수 있습니다.
3.2. Comparison With State-of-the-Art Methods
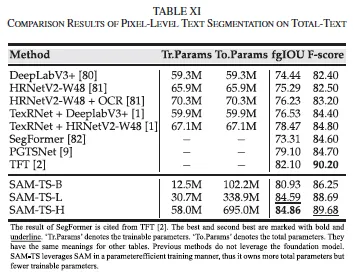
다음은 벤치마크 실험으로 먼저 totaltext 데이터셋에 대한 실험 결과를 살펴보도록 하겠습니다. Total Text는 curved text가 포함된 scene image를 주로 포함하고 있는 데이터셋으로, 기존 방법들은 성능 향상을 위해 text recognizer를 결합하거나 추가적인 text detector나 annotation을 활용하고는 했습니다. 반면 Hi-SAM은 이런 추가적인 요소 없이 기존 방법론들의 성능을 능가하는 것을 확인할 수 있습니다. F-score기준으로는 추가적인 요소를 사용한 TFT가 좀 더 높기는 합니다. 아래 TextSeg 실험에서도 유사한 양상을 보입니다.
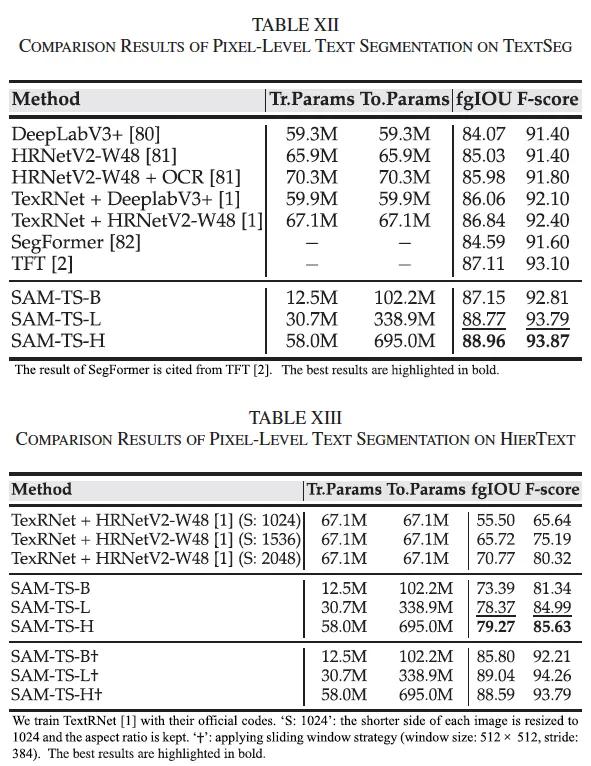
또, HierText 데이터셋에 대한 벤치마크 결과를 살펴보도록 하겠습니다. 이 HierText 데이터셋은 scene, 문서, 손글씨 등등 text 밀도나 다양성이 엄청 높아 좀 까다로운 데이터셋이라고 보면 되는데요. 기존 방법론 중 하나인 TexTNet + HRNetV2-W48을 사용할 때 기존 해상도에서 55% 성능을 보이고 좀 더 해상도를 늘릴 때도 71% 정도로 좀 제한적인 성능을 보입니다. 반면에 SAM-TS는 그보다 높은 성능을 보이고 있죠. 추가로 + 표시가 붙은 마지막 행들은 sliding window 방식을 사용해 성능을 더 높여본건데, 이 단순한 방식으로 10%가 넘는 추가 향상을 보이며 최종적으로 TexRNet 대비 18% 이상의 차이를 보입니다.
Visualizations

마지막으로 정성적 결과입니다. 위 그림은 pixel level, word, line, paragraph layout 단위로의 segmentation 결과를 보이고 있습니다.

위 시각화가 Automatic mask generation 모드 결과였다면 위 Fig10은 promptable segmentation(ps) 모드에서의 시각화 결과인데요. 잘 안보이겠지만 초록색 영역 내에 찍혀있는 점이 user 가 입력으로 한 point이며 이를 기반으로 segmentation한 word(초록)와 line(파랑), 문단(주황) 단위로 구분이 된 것을 확인할 수 있습니다. 아랫 행은 실패 케이스들인데 주로 곡선이거나 긴 단어들인 경우 mask가 중간에 끊기는 문제가 발생했다고 합니다.
안녕하세요. 좋은 리뷰 감사합니다.
word, line, paragraph segmentation을 수행하는 디코더는 H-Decoder이고 여기에 입력으로 각각을 담당하는 3개의 output token과 prompt encoder로부터 나온 prompt token이 함께 들어가는걸로 이해했습니다. 그런데 여기서 output token은 token-to-image attention 과정을 통해 나온다고 했는데 이 과정은 원래 SAM에 포함된 부분인건가요? 이렇게 나온 output token 들 중에 3개만을 어떻게 정하는지 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
1. 넵 맞습니다. token-to-image attention은 원래 SAM에 포함된 과정입니다. output token과 image embedding 사이 attention이라고 보면 됩니다.
2. H-Decoder output으로 나온 여러 output token 들 중에서 맨 뒤 3개의 token을 순서대로 word segmentation, text line segmentation, paragraph segmentation하는 용도로 사용합니다.
안녕하세요 리뷰 잘 읽었습니다.
H-Decoder에서 output token을 명시적으로 word, line, paragraph로 mapping하는 구조를 학습 안정성 때문이라고 이해하였습니다. 하지만 기존 SAM은 object token이 flexible하게 여러 instance에 대응될 수 있었는데, Hi-SAM은 각 token 역할이 고정되어 있어 표현력 측면에서 trade-off가 있을 수도 있을 것 같습니다. 혹시 instance별 word-level 분할까지 대응하는 구조로의 확장 가능성도 고려하였는지 궁금합니다
안녕하세요. 댓글 감사합니다.
H-Decoder에서는 하나의 point prompt가 들어가면 그에 대해 마지막 output token 3개가 word, line, paragraph mask를 만드는데 사용됩니다. 즉, 1개의 point prompt가 들어가면 그에 대한 1개의 word mask가 생성된다고 보면 되는데 이때 이 word mask는 질문 주신 instance level word mask에 해당합니다.
그렇기에 여기서는 1500개의 foreground point를 sampling한 다음 이 point 각각이 prompt로 들어가게 되는데요, 그럼 이 각각의 point 마다 H-Decoder가 3개의 output token 뱉게 되겠고 이 중 첫번째가 해당 point의 word-level mask이니 1500개의 word mask가 나오게 됩니다. 최종적으로 이 겹치는 mask들은 NMS로 제거하고 남은 게 최종 결과가 됩니다.