
1. Introduction
컵퓨터 비전 분야에서는 사전학습 후 파인튜닝하는 방법으로 딥러닝 모델을 학습시키는 게 보편적으로 사용이 되어왔습니다. ImageNet과 같이 대량의 데이터셋으로 사전학습한 가중치를 불러와 실제 수행하고자 하는 작업(downstream task)에서의 학습 파라미터로 초기화하는 방식으로 수행됩니다. 사전학습으로 성능 개선을 이루고 라벨링 부담으로 부터 조금 자유로울 수 있게 주었습니다. 이전 사전학습 방법들은 대부분 image-level에서의 visual representation을 학습하고 이를 transfer합니다. 하지만 image-level representation 학습은 dense prediction을 필요한 downstream task에서는 적합하지 않았습니다. (dense prediction을 요구하는 downstream task의 예로는 object detection과 semantic detection이 있습니다.) 저자는 앞서 연구되어왔던 image-level의 사전학습의 경우 image의 holistic한 features만을 학습하도록 과적합이 되어 이미지 분류외의 다른 태스크를 수행하는 데 필요한 features들은 학습이 되지 않았기 때문에 적합하지 않고 개선에 한계가 있는 것이라고 설명합니다.
이 논문은 object detection에 적합한 self-supervised pretraining 방법인 SoCo (Selective Object COntrastive learning)제안합니다. object detection에서 bounding box가 객체 수준의 representation을 갖게되는데 이때, 기존의 image-level에서의 pretraining과 object level의 detection task간의 gap을 줄인 연구입니다.
사전 학습 과정에서 object-level representation이 학습되도록 객체 수준의 영역을 제안하는 부분을 모델 설계에 추가하였는데 이때 일반적으로 많이 사용되던 selective search 방법을 사용합니다. 이 논문에서 제안하는 self-supervised 방법은 contrasive learning 기반의 방법으로 하나의 object가 contrastive learning의 independent한 instance로 학습에 참여합니다. 그리고 SoCo는 같은 객체에 대한 visual representation이 서로 다른 뷰에서 스케일과 위치 차이를 갖도록 학습을 설계합니다.
또한 이 논문의 또 다른 contribution 하나는 기존 연구가 feature 학습이 되는 백본만이 transfer 되었다면 SoCo에서는 백본 뿐만 아니라 detection에 수행에 사용되는 R-CNN, FPN layer에 대해서도 사전학습이 되고 가중치가 transfer 된다는 점입니다.
2. Methods
이 논문에서 제안하는 self supervised learning 방법은 같은 이미지에 대해서 다르게 증강한 object-level의 feature representation의 유사도를 최대화 합니다. 이후 논문에서는 Mask-RCNN에 transfer 시키고 finetuning합니다.
2.1 overview
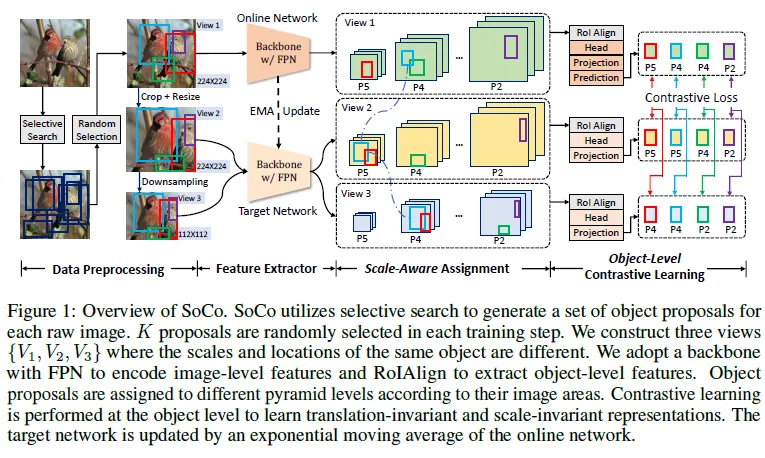
SoCo의 모델 구조는 위와 같습니다. SoCo는 object detector로 사용되는 Mask R-CNN 프레임워크에서의 FPN이나 head가 동일하게 사용됩니다. 그래서 사전학습 후 전이할 때 백본 이외의 여러 모듈의 가중치들도 전이가 되어 detector에서의 가중치 초기화에 사용됩니다. 또한, object-level의 representation을 학습 하면서도 이동과 스케일 변화에도 동일하게 같은 객체에 대해서 동일하게 학습되도록 같은 객체에 대해서 여러 스케일, 위치를 주는 증강을 적용합니다. 다르게 증강이 적용됐지만 같은 객체인 영역에 대해서 이를 가지고 대조학습을 수행합니다.
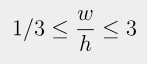
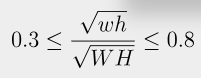
2.2 Data Preprocessing
1. Object Proposal Generation
input 이미지에서 object proposal이 어떻게 수행되는지에 대한 내용입니다. 우선 아무것도 하지 않은 raw한 이미지에 대해서 비슷한 색상, 텍스처 정보를 가지고 한 이미지에 대해서 객체에 대한 여러 proposal을 내게 됩니다. 각 object proposal은 b = \left\{x, y, w, h \right\}형태의 바운딩 박스로 나타나집니다. selective search를 통해서 제안된 영역 중 다음 조건을 만족하는 경우만을 남깁니다.
object proposal은 사전학습하는 것과 별개로 offline 하게 수행됩니다. 그리고 사전학습 시 각 iteration에서 랜덤하게 K개의 proposal을 실제 대조학습에 사용합니다.
2. View Construction
입력된 이미지 하나에 대해서 총 3개의 서로 달리 증강된 view가 생성됩니다. 입력 이미지를 224×224 크기로 변경한 것이 V_1. [0.5, 1.0] 사이의 scale에 대해서 랜덤하게 V1을 크롭한 다음 V1과 동일한 크기로 (224×224)로 resize가 된 V_2. 이때 크롭된 object들은 모두 제거됩니다. V2를 112×112 사이즈로 줄인 V3. 각 객체마다 바운딩 박스 값들도 함께 적용된 증강 그대로 반영됩니다. 이후 각 뷰에 대해서 독립적으로 랜덤한 증강이 추가적으로 적용됩니다. crop 증강을 제외한 채 BYOL에서 사용됐던 증강 그대로 사용되었다고 합니다. 이런 과정을 거치고 나면 같은 객체에 대한 proposal이어도 서로 다른 스케일, 다른 위치에 있게 되고 덕분에 모델은 scale-invariant, translation-invariant한 object-level representation들을 학습할 수 있게 됩니다.
3. Box Jitter
각 proposal 마다 차이를 키우기 위해 propsal의 바운딩 박스에 대해 jitter를 적용하는데 이때 각 뷰마다 0.5의 확률로 jitter이 적용됩니다. 그래서 같은 객체에 대한 proposal이더라도 V_1, V_2, V_3에서 서로 다른 위치의 박스를 갖게 될 수 있습니다.
2.3 Object-Level Contrastive Learning
다음은 실제 대조 학습이 진행되는 방법에 대한 구체적인 내용입니다.
이 논문에서 하고자 하는 것은 객체 검출이란 dense prediction에 적합한 사전학습 방법을 제안하는 것이었습니다. 미세 조정 시 사용되는 검출기는 Mask R-CNN 프레임워크에 FPN을 더한 것을 사용합니다.
1. Aligning Pretraining Architecture to Object Detection.
Mask R-CNN에서 처럼 SoCo도 백본 네트워크에 FPN을 함께 사용해 feature extractor를 구성합니다. f^I 다음 FPN을 통과하고 나온 feature map에 대해 box representation b을 가지고 RoIAlign을 수행하고 R-CNN을 통과시켜 각 proposal 마다 object-level feature represenation h를 얻습니다. 이를 식으로 나타내면 다음과 같습니다.
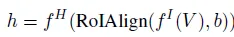
SoCo는 두 개의 신경망을 가지고 학습됩니다. online network, target network 이렇게 두가지로 나뉩니다. 두 네트워크는 동일한 구조를 갖지만 서로 다르게 가중치가 학습됩니다. 타겟 네트워크의 가중치 f_{\xi }^{I}, f_{\xi }^{H}는 online network 가중치인 f_{\theta }^{I}, f_{\theta}^{H} 각각에 대한 EMA(exponential moving average)가 됩니다. (타겟 네트워크 가중치는 online network의 가중치 대로 업데이트 되지만 이전 값을 거의 유지한 채 조금씩 업데이트 합니다.)
어떤 영상에서의 proposal 집합이 다음과 같을 때 \left\{ b_i\right\} object proposal b_i에 대해서 각각 view V_1, V_2, V_3에서의 object level representation들을 h_i, {h}'_i, {h}'’_i이라고 하겠습니다. V1에 대해서는 online network로 V2, V3은 target network로 각 representation이 추출됩니다.
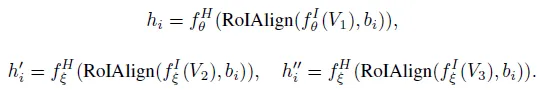
그 다음 online network에서는 projector, predictor head를 통과해 latent embedding으로 변환되고 target network에서는 representation 들이 오직 projector head를 통과해서 latent embedding이 됩니다.
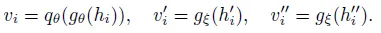
i 번째 객체에 대한 contrastive loss는 다음과 같습니다.
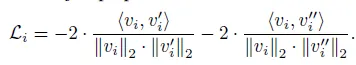
같은 객체 인스턴스에 대해서 V1에서 뽑은 임베딩 벡터를 V_2, V_3에서의 벡터와 positive 쌍으로 구성해 대조 학습이 진행 돼 같은 이미지지만 view가 다른 경우의 positive 쌍은 latent 공간 상 거리가 가까워지도록 합니다.
그리고 영상 내 모든 객체에 대해서 각각 loss를 계산 후 더합니다.
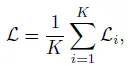
마지막으로 SoCo에서는 손실 대칭화라는 방법이 사용되는데 위의 Loss에 반대로 이번에는 V1을 타겟 네트워크에 V_2, V_3을 online network에 feed하고 얻는 또 다른 loss를 더해 최종 loss를 구합니다. 그래서 V_1 → V_2, V_3 방향으로 한번 V_2, V_3 → V_1 방향으로 또 한 번 contrative learning이 진행되는 것입니다.
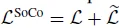
2. Scale-Aware Assignment
box proposal에 대해서 feature representation을 extract 할 때 proposal의 크기에 따라 FPN을 통과하고 나온 feature map에 다르게 extract 되게 합니다. 이렇게 하면 같은 객체임에도 다른 뷰에서는 다른 크기의 앵커박스를 갖게 될 수 있고 그렇기 때문에 서로 다른 scale에서의 representation 학습이 될 수 있습니다.
3. Introducing Properties of Detection to Pretraining
SoCo는 translation, scale invariant 한 특징들을 학습한다고 앞절에서 얘기했었는데 이는 V_1과 V_2간의 contrastive loss를 통해서는 translation invariant한 representation을 학습하게 되고 V_1과 V_3은 resizing으로 scale-invariant 특징들을 학습하게 됩니다.
3. Experiments
3.1 Comparison with State-of-the-Art Methods
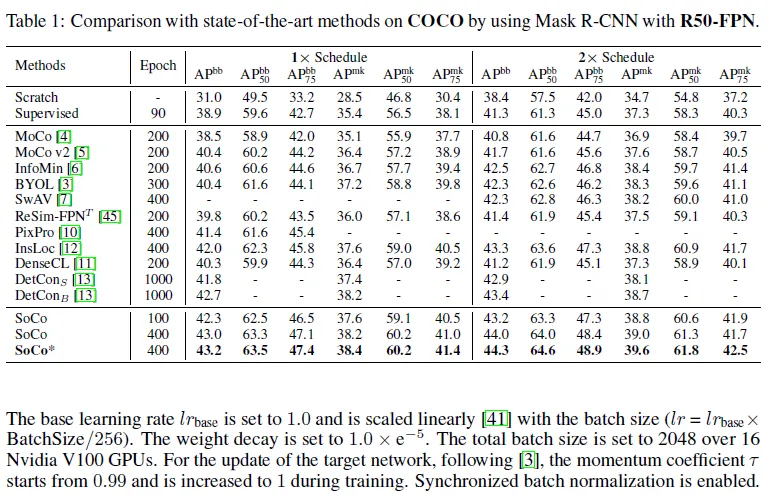
Table1.은 COCO 데이터셋에 대해 Mask R-CNN detector와 R50-FPN(ResNet-50) 백본 조합의 모델에 대해 파인튜닝한 결과입니다. 각각 object detection과 Instance segmentation에 대해서 IoU 값을 달리하며 계산된 AP를 평가지표로 사용합니다. AP^{bb}를 detection의 정확도, AP^{mk}을 Instance Segmentation의 평가 지표라고합니다. 위 테이블의 결과를 보면 SoCo로 400 epoch 만큼 사전학습한 경우 detection, segmentation에서 제일 높은 정확도를 보입니다.
SoCo*은 SoCo에 view V_4를 추가해 사전학습 한 경우로 V_2와 비슷하게 V_1를 랜덤하게 crop한 다음 192×192 크기로 resize 시킵니다. 기존 view 3개를 가지고 사전학습하는 SoCo와 비교했을 때 전체적으로 성능 개선이 있습니다.
다음은 SoCo에 확장성을 검증하기 위한 실험으로 Mask R-CNN with R50-C4 백본 모델에 파인튜닝한 것으로 기존 방법론들 보다 높은 성능을 냅니다.
3.2 Ablation Study
ablation study는 Mask R-CNN with R50-FPN에 대해서 transfer learning이 진행되고 100 에포크 만큼 사전학습됩니다. 그리고 COCO 1x Schedule을 따릅니다.

Table 4 : SoCo의 모든 구성 요소에 대한 ablation study로 각 요소가 pretraining에 얼마나 효과를 주는지를 확인할 수 있는 실험
여기서 확인할 것은 image를 하나의 instance로 contrastive learning하는 baseline과 비교했을 때 selective search를 도입해 object-level의 representation을 학습하는 게 꽤 큰 폭으로 성능 개선을 한다는 것입니다.
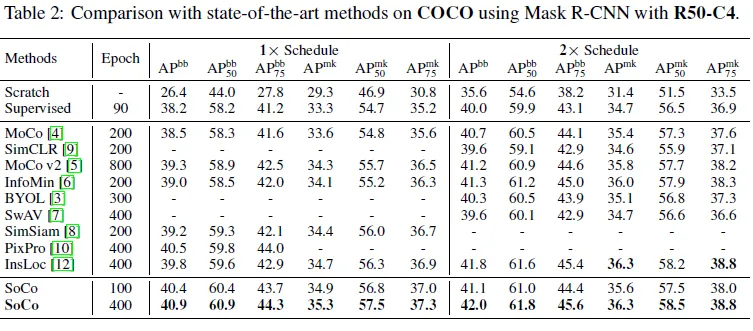
Table 5. 사전학습에서의 각 파라미터를 찾기 위한 실험
(a) V_2을 얼마나 resize해서 V_3을 만들지
(b) 사전학습 시 배치 크기
(c) 제안 영역 방법 비교하고 proposal 개수 비교
selective searc의 방법 대신 랜덤하게 이미지 하나에 대해 하나만의 object proposal을 냈을 때도 selective search를 했을때와 조금 낮지만 비슷한 결과가 나옵니다. 이를 통해 object detection 같은 dense한 task에 대해 transfer 할 때 사전학습에서 object-level을 고려해주는 게 필요함을 확인할 수 있습니다. 랜덤한 proposal을 4, 8개 제안하는 경우에는 무의미한 곳에 제안해 점차 노이즈가 늘어나 모델이 학습 중에 발산하게 되는 결과가 나왔습니다. 또한 Selective search에서 proposal의 개수를 늘리는 게 성능이 하락했는데 이는 ImageNet 데이터셋은 한 이미지의 적은 양의 객체가 포함된 경우가 대부분이라 오히려 중복된 제안을 하게 돼 성능이 하락된 것이라고 설명합니다.
(d) target network의 momentum 계수 비교
4. Conclusion
기존의 image-level의 representation을 학습해 transfer했던 self-supervised learning 방식이 object detection, instance segmentation같은 dense한 task에 적용되는데 한계가 있다는 지적에 저자는 object detection에 align하는 pretraining 방법인 SoCo를(Selectice Object COntrastive learning) 제안했습니다. selective search라는 object proposal 방법을 추가해 object level의 representation을 학습하게 하고 Mask R-CNN의 FPN, R-CNN 헤드에 대해서도 사전학습된 가중치로 초기화를 할 수 있었습니다. 사전학습 후 COCO와 여러 벤치마크 데이터셋에 대해 SoTA와 detection과 segmentation에 대해 성능을 비교한 결과 제일 높은 결과를 보였습니다.