이번 리뷰 논문은 VLM과 LLM을 이용하여 파지에 적합한 영역을 zero-shot으로 찾아내는 방법을 제시한 기법입니다. 특이한 점은 vision을 보지 못하는 텍스트 기반의 LLM을 활용합니다. (아마 시기적으로 multi-modal LLM이 등장하기 이전에 개발한 것으로 보입니다.)
이번 논문은 아주 심플합니다. 심플하기 때문에 추후 연구에 있어 적용하거나 개선하기 좋은 기법이라고 보고 있습니다.
Intro
로봇 지능에 있어 익숙하지 않은 객체에 대한 태스크 중점의 파지 능력은 매우 중요한 문제 중 하나 입니다. 해당 기법에서는 보지 못한 객체를 잡기 위해서 사전 지식을 응용하여 객체를 파지하는 사람의 능력에서 영감을 받아, 해당 기법에서는 상식적인 추론이 가능한 LLM을 이용하고자 합니다.
최근 리뷰로 작성된 zero-shot 방식인 LEFT-TOGO도 DINO를 이용하여 후보 파지 지점을 선별하고 태스크에 적절한 작업을 수행하기 위해 LLM을 이용합니다. 해당 기법에서는 더 높은 성능을 위해서는 객체의 명칭, 수행하고자 하는 태스크을 넘어서 각 객체의 파트의 이름을 주어줘야만 합니다. 이러한 점은 기존 zero-shot들의 한계로 지적 할 수 있죠.
해당 기법에서는 타겟 객체에 대한 geometric decomposition과 LLM을 이용한 shape-based semantic part reasoning을 통해 task-oriented reasoning과 novel objects에 대해 강인한 파지 프레임워크 “ShapeGrasp”를 제안합니다. 이때 LLM에게 전달하기 위해서 geometric/semantic information은 graph-based representation으로 변환되어 전달됩니다.
조금 더 정리하면 사람이 새로운 물체를 보면 알고 있는 아주 간단한 구성 요소로 분해할 수 있죠. 그럼 분해된 요소들을 어떠한 용도인지 의미론적인 추론을 진행합니다. 그 다음에 내가 수행하고자 하는 태스크에 맞춰서 어떤 지점을 잡는 것이 유리한지 판단(평가)를 합니다. 가장 합리적인 부위를 파지를 수행하여 작업을 이어나갑니다.
해당 기법에서 새로운 물체를 간단한 요소로 분해하는 부분을 geometric decomposition으로, 분해된 요소(부위)의 의미론적 추론은 shape-based semantic part reasoning으로 이해하시면 됩니다.
자세한 내용은 다음 섹션에서 다루도록 하겠습니다.
Method
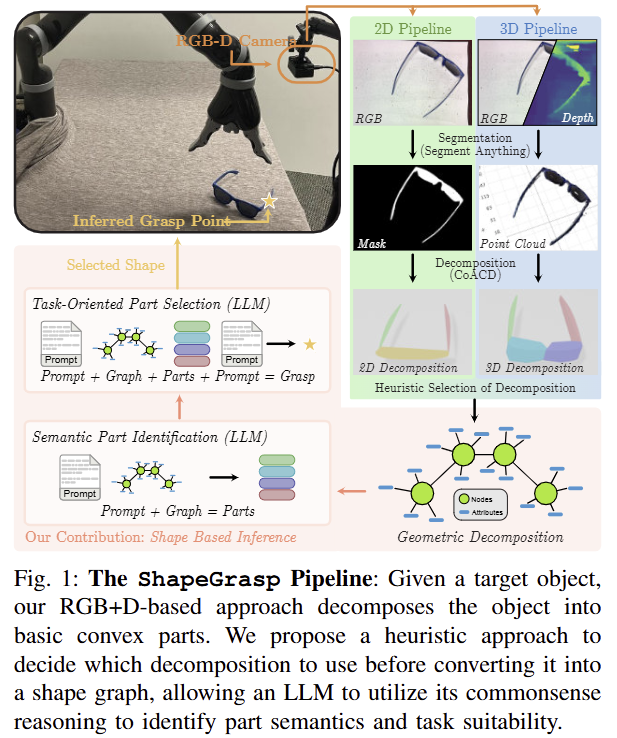
먼저, RGBD input I가 주어졌을 때, 저자가 제안하는 ShapeGrasp g, \theta = f_{SG}(I) 는 로봇이 객체를 들어 올리기(pick up) 위한 파지 위치 g와 방향 \theta 를 추정하는 것이 목적입니다. 해당 기법은 3 단계로 구성됩니다. 1) 타겟 객체를 분할하고 convex decomposition에 대한 검색(~간단한 도형으로 표현)을 수행합니다. 2) 그런 다음, automatic heuristic을 통해서 활용 가능한 분해요소를 선정하고, 3) 타겟 객체의 geometric composition을 추론하기 위해서 그래프 기반으로 표현하고, multi-stage reasoning을 위해 LLM을 적용합니다. 전반적인 흐름은 fig 1에서 확인 가능합니다.\

Segmenting the Object. 영상 분할을 위해 SAM을 활용하고 convex decomposition을 위해 CoACD를 이용합니다.
1) Retrieving the Object Mask and Point Cloud:
SAM으로 input image I를 입력으로 2D segmentation mask M*을 얻습니다. 그 다음, RGBD에 mask를 이용하여 point cloud p를 획득합니다.
*이때, 직접 지정한 point prompt로 얻는 것 같습니다… IROS는 로봇 학회이니 CV 문제를 뒤로 미뤄도 허용하는 것 같습니다.
2) Convex Decomposition with CoACD:
mask M과 이에 따른 point cloud p가 주어지면, 두 입력에 독립적으로 convex decomposition을 수행합니다. 이를 위해, 저자는 CoACD를 이용합니다. (해당 기법은 mesho를 convex hull로 분행하는데 특화된 기법이라고 보시면 됩니다.) 이때, mask는 평면에 사영된 mesh라고 가정하고 분해를 수행합니다. 각각의 convex decomposition은 C_2d, C_3d라고 지칭합니다.
2D와 3D를 별개로 수행하고 이를 다 사용하는 이유에 있어서 저자는 다음과 같이 밝힙니다. 우선 2d는 depth가 부정확한 상황에 있어서도 강인한 정보와 빠른 추론이 가능하다는 장점이 있습니다. 특히, 굴절이 있거나 투명하거나 반사되는 물체이 있어서는 더 강인하죠. 반면에 2D는 깊이 정보가 부재하기 때문에 3D는 3차원 정보에 있어 매우 강력합니다. 저자는 이러한 상호보완적인 장단점을 고려하여 같이 사용하는 전략을 선택합니다. 다음 섹션에서는 두 정보 중 더 적절한 정보를 선택하는 전략을 소개합니다.
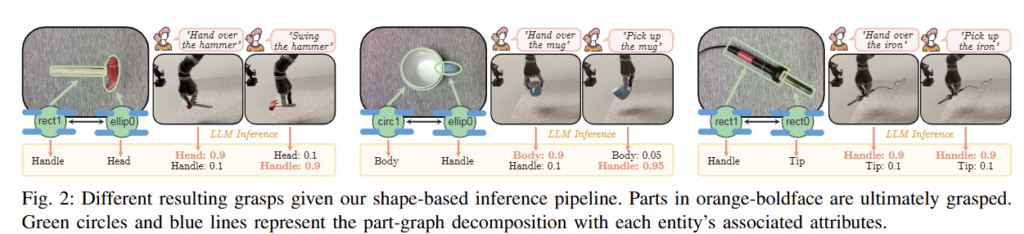
Geometric Decomposition. 해당 섹션에서는 앞서 선별된 convex decomposition을 선택하기 위한 휴리스틱한 방법을 제시합니다. 그 다음, 각 부위의 관계와 각 특성에 대한 object-graph G를 생성하는 방법을 제시합니다. 이에 대한 대략적인 도식화는 fig 2를 참고하시면 됩니다.
1) Heuristic Selection of Decomposition:
concave mugs처럼 시각적 특징이 적거나, 반사되는 표면을 가진 경우에는 low-confidence depth map이 나오기 때문에 (3D만 이용하는) convex decomposition으로 표현이 어려운 요소들을 해결하기 위해서 저자는 3D 뿐만이 아니라 2D를 고려하여 최적의 decomposition을 선택하기 위한 heuristic C^* = h(C_{2D}, C_{3D}) 을 제시합니다.
먼저, 낮은 decomposition threshold 초기 값 γ을 배치하고, 2D와 3D에서 하나의 부위가 나오도록 합니다. 그 다음에 만약에 3D decomposition C_3d의 수가 ω보다 많거나 depth의 high confidence가 α보다 낮으면 2D decomposition를 사용합니다. 이는 아래와 같이 정의 됩니다.
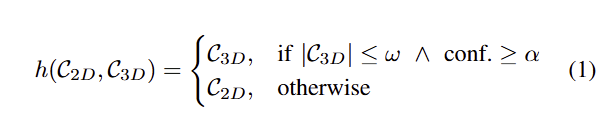
여기서 |C|는 파트 수 입니다. 저자가 제시하는 하이퍼 파라미터는 경험적으로 결정됩니다(ω=10, α=85%). 이렇게 결정된 decomposition C*으로 object graph G를 생성합니다.
2) Structured Object-Graph Creation:
decomposition C*을 원본 영상 I에 투영하고, 이를 기반으로 ojbect-graph G를 생성합니다. 해당 그래프는 개별 분해된 부분을 노드로 나타내고, 해당 노드에는 segment image에서 추출한 다양한 attribute들이 함께 포함됩니다. 각 요소들은 다음과 같이 정리됩니다.
- shape primitive: 각각의 convex hull을 간단한 다각형으로 근사(Polygon Approximation)하며, 이땐 사전 정의된 근사 임계값 ε를 이용합니다. 정의된 다각형은 이등변삼각형, 사각형, 원, 타원을 구성됩니다. 구체적인 전략은 다음고 같습니다.

- Geometric Attributes: 단순화된 convex hull로부터 기하 속성을 추출합니다. 추출하는 정보는 다음과 같습니다. Aspect ratio, Orientation angle (긴 변의 각도), Centroid, Area
- Color Attribute: RGB 스텍트럼을 16개의 web standard color space에서 추출. 각 노드에서 가장 많이 나타나는 색상을 대표 색으로 이용
위 같이 각 분해 요소는 shape primitive, Geometric, Color Attribute로 구성되며, 이를 연결하는 edge는 속성 정보로 두 사이의 연결 길이*를 사용합니다.
* 명시적이지 않음. 추론으로는 노드 간의 Centroid의 길이로 추측
Grasp Inference through Shape Reasoning. 각 노드로부터 적절한 파지 지점을 선정하기 위해서 저자는 상식적인 추론이 가능한 LLM을 이용한 방법을 제시합니다. 이는 CoT에서 영감을 얻었으며, 보다 reasoning 능력을 향상 시키기 위해서 두 가지 상호 작용 단계로 구성됩니다. 각 단계는 1) graph g에 설명된 각 모양을 기반으로 의미론적 추론, 2) task-oriented grasp에 적절한 부위를 선택하는 방식으로 구성됩니다. 이를 위해서 저자는 fig 3과 같은 prompt template를 이용합니다. (TypeChat를 이용해서 prompt를 작성했다고 합니다. ~ openai api가 잘되어 있어서 딱히 필요 없음)
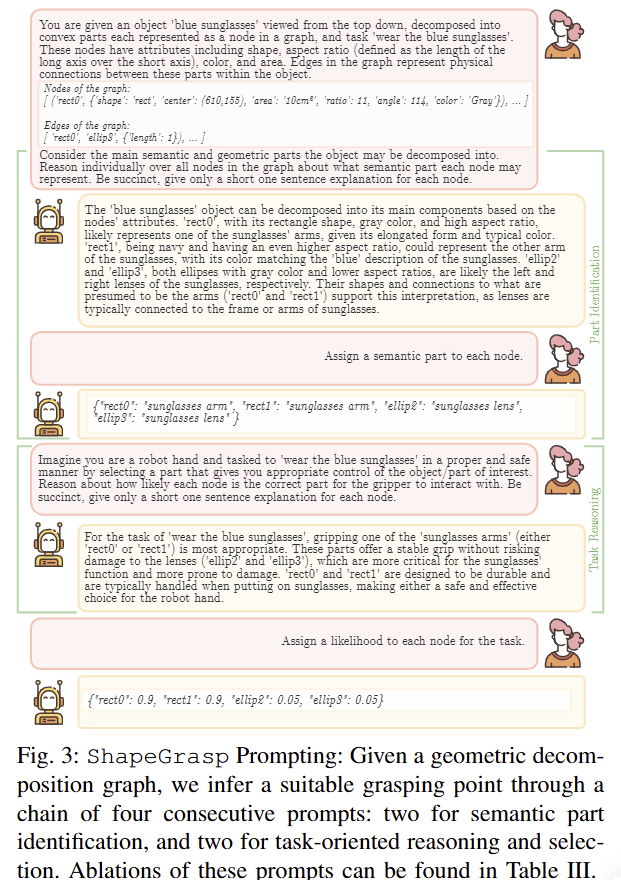
1) Semantic Part Identification:
해당 단계에서는 object와 task에 대한 지칭과 구축한 graph g를 프롬프트에 따라 LLM에 지시하고, 각 노드에 대한 semantic part이 뭔지 표현하길 지시합니다. 예를 들어 “knife”의 “handle” and “blae”로 말이죠. 처음에는 자유롭게 답변하도록 하고, 답변을 기반으로 구조화된 답변을 제시 받습니다(~CoT->fig 3의 1-4 질의에 해당)
2) Task-Oriented Part Selection:
1)을 통해서 각 파트에 대한 명칭을 확보한 정보를 다시 LLM에 지시합니다. 이 때는 각 파트에 대한 task utility를 수치화~각 노드에 대한 task-oriented suitability score~하여 표시하도록 지시합니다. 이때도 CoT를 사용합니다.
Selecting a Grasp Pose. 마지막 단계로, 가장 높은 점수를 가진 graph node을 선택합니다. 파지에 활용하기 위해서 선택된 부위의 centroid를 계산합니다. 이에 대한 depth의 위치로부터 x, y, z를 얻습니다. 파지를 위한 회전을 고려하기 위해서, 해당 부위의 point coloud의 PCA를 통해 가장 큰 주성분 벡터를 계산하여 해당 성분 방향을 방향 정보로 사용합니다.
+ 예를 들어 적절한 부위가 손잡이로 선정된 경우에 파지 지점은 손잡이의 가운데가 무게 중심일 가능성이 높음. PCD의 주성분이 가장 큰 ~ 긴 면이 안정적인 파지를 할 방향이 될 가능이 높음
EXPERIMENTS

해당 실험에서는 fig 4와 같이 12가지 카테고리에서의 38개의 객체와 49 tasks에서 실험을 진행합니다. (LEFT-TOGO의 객체를 재사용했다고 합니다.) 각 실험에서는 3지 그리퍼를 가진 Kinova Jaco robotic arm을 이용하며, Oak-D SR passive stereo-depth camera를 이용하여 실험을 진행한다고 합니다.
평가 방법: 다음 3가지 평가 방법을 사용 합니다. “Part Identification” (GT의 파트 부위 명칭을 잘 맞추는지) , “Part Selection” (태스크 측면에서 적절한 파트 부위를 잘 선별하는지), “Lift Success” (선정된 파트를 파지해서 잘 들어올리는가).
Automatic Geometric Decomposition.
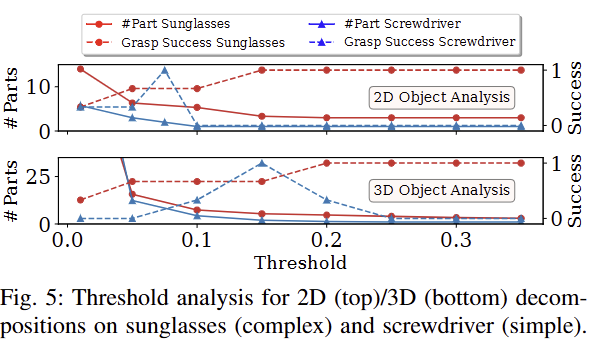
Dynamic Threshold Selection: 2D와 3D에 대한 분해에 있어 convex decomposition threshold γ는 굉장한 중요한 파라미터입니다. 해당 임계값이 높다면 (>0.2) 단순하게 분해가 되기 때문에 단순한 객체들은 실패할 확률이 올라갑니다. 반면에 낮다면 (< 0.1) 복잡한 객체들의 구성 요소들이 너무 많아져서 LLM이 reasoning을 수행하기 위해서 굉장히 복잡해지고, hallucination이 발생한 가능성이 높아집니다. fig 5는 sunglasses와 screwdriver에 대한 γ (0.01~0.35) 변화에 따른 Lifting success rate로 두 객체는 각각 복잡함과 단순한 객체로 보시면 됩니다. fig 5에서 보이는 바와 같이 객체의 복잡도에 따른 영향력이 다르기 때문에 2D는 γ=0.15, 3D는 γ=0.2로 설정하고 유효한 부위가 2개 이상 검출되지 않는 경우에는 0.025씩 낮추면서 반복적인 탐색을 수행하는 것을 제시합니다.
+ 3D가 더 높은 이유는 depth의 불확실성으로 인해서 더 낮은 값을 설정한다고 합니다.

2D vs 3D Decompositions: Tab 1에 보이는 바와 같이 2D만 사용한 경우와 3D만 사용한 경우, object name을 제거하고 기하적인 정보만 넣은 경우, 저자가 제안함 방법에 대한 Part Selection에 대한 결과입니다. 실험적인 결과, 저자가 제안한 방법이 가장 성능이 좋은 결과를 보여주면서 2D와 3D의 정보를 상호보완적으로 적용했을 때 더 좋다는 결과를 보입니다.
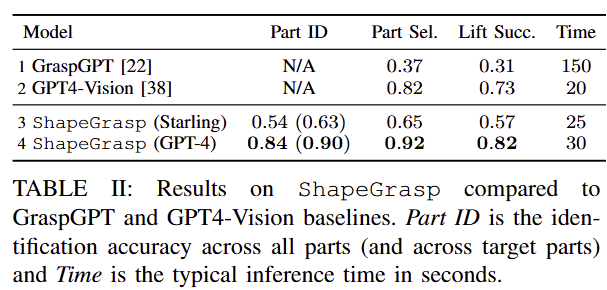
Zero-Shot Task-Oriented Grasping: Tab 2에서는 SOTA인 GraspGPT와 multi-modal GPT인 GPT4-v에 graph-based reasoning stages만 제외한 prompt를 넣은 결과입니다. 실험적인 결과 저자가 제안한 방법이 hallucinations을 줄이고 안정적인 결과를 보여줍니다. (Starling은 open-source LLM 입니다.)
+ 의외로 GPT4v가 높은 성능을 보여주고 있습니다. segment만 수행해서 제공하는 구조인데도 불구하고 index를 부여하고 part selection까지 했다는 건, grounding 능력이 생각보다 좋다는 것을 의미하는 것 같네요. 실패한 경우에 대해서 분석이 더 있었다면 좋았을 텐데 없어서 아쉽습니다.

Qualitative Results: fig 2에서 지칭한 task에 맞게 객체를 처리하는 결과를 보여주며, 더 나아가 fig 6에서 그리퍼의 너비에 맞춰 파지를 수행하는 결과를 보여줍니다.
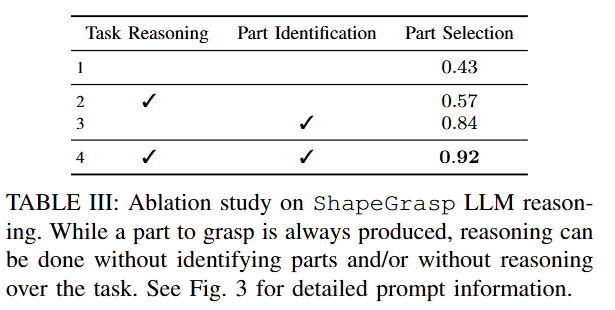
LLM Ablations: Tab 3에서 보이는 바와 같이 semantic part reasoning과 task reasoning이 미치는 영향을 분석을 진행하였습니다. 실험적인 결과, semantic part reasonin이 없는 경우에는 성능이 급감하는 결과를 보여줍니다. 이는 semantic label 없이 기하 정보만 이용하면 task와 관련된 부위를 얻기 힘들기 때문입니다. 또 다른 이유는 예를 들어 파란 선글라스에서 arm을 frame으로 오인했지만 lens는 정확하게 인식하여 피해야 할 부품을 잘 인식해 올바른 task를 수행했다고 합니다. 이와 같이 모든 파트를 정확하게 인식하지 않아도 태스크 수행에 있어 핵심 파트만 잘 인식해도 수행에 성공한다는 점입니다.
task reasoning는 fig 2와 같이 task의 측면에서 한 객체에서 파지 부위가 달라질 수 있어 굉장히 중요한 요소로 작용합니다. 이러한 점이 성능 향상에 영향을 끼친 결과를 보여줍니다.
방법이 생각보다 굉장히 심플하고 multi-modal LLM이 등장하면서 더 좋은 방법이 있을 것 같긴 합니다. 현재 zero-shot affordance prediction에 관심이 많았는데 해당 기법을 기반으로 multi-modal LLM을 이용하는 방법 혹은 lightweight로 적용하는 방법을 제시할 수 있다면 좋을 것 같네요.
태주님 좋은 리뷰 감사합니다.
해당 방법론은 물체에 대하여 단순화된 형태들로 재구성한 뒤, 물체의 속성을 추출하여 object-graph를 만들고, 여기에 LLM을 적용하여 물체의 파지점을 찾는 방법론으로 이해하였습니다.
해당 방법론에서 2D와 3D에 대한 convex decomposition 결과를 융합할 때 사용하는 confidence는 어떻게 얻을 수 있는 지 궁금합니다.
또한 실험파트에서 Part Identification에 대한 평가는 어떻게 이루어졌는 지 궁금합니다. part-segmentation과같이 이를 평가하기 위한 별도의 데이터 셋이 있나요?
Q1. 해당 방법론에서 2D와 3D에 대한 convex decomposition 결과를 융합할 때 사용하는 confidence는 어떻게 얻을 수 있는 지 궁금합니다.
A1. 2D와 3D를 선택하는데에 사용되는 값은 3D convex decomposition의 파트 수와 3D의 depth confidence에 해당합니다. 여기서 depth confidence는 stereo camera인 Oak-D에서 나오는 confidence를 이용하는 것으로 보입니다.
Q2. 실험파트에서 Part Identification에 대한 평가는 어떻게 이루어졌는 지 궁금합니다.
A2. Part Identification는 타겟 객체의 part 명칭에 대한 classification에 대한 정확도로 이뤄지는 것으로 보입니다.
Q3. part-segmentation과같이 이를 평가하기 위한 별도의 데이터 셋이 있나요?
A3. 넵… fig 4에서 보이는 12가지 카테고리에서의 38개의 객체이로 구성된 49 tasks에서 실험을 진행합니다. 이에 따라 annotation도 진행했겠죠?