Abstract
일반화된 로봇 시스템을 구축하는 것이 중요하며, VLM이 높은 시각적 추론 능력을 갖추고 있으나 세밀한 3D 공간에 대한 이해가 부족하여 로봇 manipulation으로의 직접적인 적용에는 어려움이 있습니다. 로봇 manipulation 데이터를 통해 VLM을 finetuning하여 VLA(Vision-Language-Action model)를 구축하는 연구가 이루어지고 있으나 로봇 조작 데이터를 수집하는데는 많은 비용과 시간이 소요되어 현실적인 어려움이 있습니다. 따라서 저자들은 VLM의 high-level 추론 능력과 low-level의 조작을 위한 세밀한 정보 사이의 간극을 연결하기 위해 새로운 object-centric representation을 제안합니다. 저자들은 객체의 기능적 affordance에 의해 정의되는 정형화된 공간이 상호작용의 primitives인 점이나 방향을 구조적이고 의미 있는 방식으로 설명할 수 있게 해준다고 보았으며, 이를 통해 VLM의 추론 능력과 조작을 위한 정보를 연결하고자 하였습니다. 따라서 저자들은 2개의 closed-loop로 이루어진 open-vocabulary 기반의 로봇 조작 시스템을 제안합니다. 하나의 loop는 high-level planning을 위해 primitive resampling과 interaction rendering, VLM checking을 수행하는 것이며, 또다른 loop는 6D Pose tracking을 통해 low-level execution을 수행하는 것 입니다. 이를 통해 VLM의 finetuning을 수행하지 않고도 강력한 real-time control이 가능하도록 하였으며, 다양한 실험을 통해 로봇 manipulation에서 zero-shot 방식의 일반화 성능을 보였습니다. 이러한 결과를 통해 large-scale의 시뮬레이션 데이터 생성 자동화 방식의 잠재력을 시사하였습니다.
Introduction

복잡하고 다양한 real-world 환경으로 인해 일반화된 로봇 시스템이 필요하지만 이를 구축하는 것에는 어려움이 있습니다. 최근 LLM과 VLM의 발전으로 이를 로봇에 적용하고자 하는 연구가 이루어지고 있으나, 대부분은 이를 high-level planning에 적용하는 것을 목표로 합니다. 또한, VLM은 광범위한 2D visual 데이터를 기반으로 학습되었으나, low-level 조작에 필요한 3D 공간적 이해가 부족하여, 이를 이용한 로봇 시스템이 구조화되지 않은 환경에서의 적용에는 한계가 있었습니다.
이러한 한계를 극복하기 위해 VLM을 finetuning하여 VLA로 확장하고자 하는 연구들이 이루어졌으나, finetuning을 위한 데이터 수집의 어려움과 finetuning시 특정 작업에 특화되어 일반화가 어렵다는 문제가 존재합니다. 이를 해결하고자 로봇 action을 상호작용의 primitives(point와 방향)로 추상화하고 VLM의 추론을 활용해 공간적 제약을 정의하고 기존의 planning 알고리즘을 적용하는 방식이 제안되었습니다. 그러나 이러한 방식은 primitives를 생성하는 과정이 task-agnostic하여 작업별로 달라지는point와 방향을 반영하지 못한다는 문제와, 생성된 primitives에 대해 수동으로 설계된 규칙에 의존하는 후처리 방식에 의해 안정성이 떨어질 수 있다는 문제가 존재합니다.
이러한 이유로 저자들은 VLM의 high-level planning과 low-level의 로봇 조작을 위한 정밀한 정보를 연결하기 위한 효율적이고 범용적인 표현을 개발하고자 하였습니다. 이를 위해, 객체의 정형화된 공간(canonical space, 여기서 canonical space라는 표현은 Omni6DPose의 표현을 따른 것으로 보입니다. Omni6DPose는 범용적인 object pose estimation을 위한 연구로, 동일 카테고리에 해당하는 물체들을 정렬하는 과정을 포함하고 있습니다. 예를 들면 여러 형태의 주전자의 손잡이 방향이 특정 방향을 향하도록 정렬하는 것입니다. 이러한 과정을 canonicalization이라 합니다.)에서 상호작용 지점과 방향을 통합하는 새로운 object-centric한 intermediate representation을 제안합니다. 저자들의 핵심 통찰은 객체의 정형화된 공간이 보통 그 객체가 지닌 기능적 affordance를 기준으로 정의된다는 점이며, 이러한 공간 내에서는 객체의 기능을 보다 구조적이고 의미 있게 표현할 수 있다는 것 입니다. 또한, 최근 범용적인 object pose estimation 기술의 발전으로 다양한 형태의 객체에 대해 이러한 정형화 과정을 적용하는 것이 가능해졌습니다.
저자들은 범용 6D 객체 자세 추정 모델인 Omni6dpose을 활용해 객체를 정형화하고, 단일 이미지 기반 3D 생성 네트워크로 정밀한 mesh를 생성합니다. 정형화된 공간에서는 객체의 주축을 따라 상호작용 방향을 샘플링하고, VLM이 상호작용 지점을 예측합니다. 이후 VLM은 작업에 필요한 primitives를 추정하고 이 primitives 사이의 공간적 제약을 추론합니다. 여기서 VLM 추론 과정에 발생하는 hallucination 문제를 해결하기 위해 interaction rendering과 primitive resampling을 통한 자체 수정 방식을 제안하여 closed-loop 추론이 가능하도록 합니다. 최종적으로 제약을 최적화하여 동작을 계산하고 pose tracking 기반의 closed-loop execution을 통해 실시간 제어를 수행합니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- 새로운 object-centric한 intermediate representation을 제안하여 VLM의 high-level 추론 능력과 로봇 조작을 위한 low-level 정보를 연결
- 자신들이 아는 한 최초로 VLM을 finetuning하지 않고 planning과 조작에 대한 dual closed-loop의 open-vocabulary 기반의 조작 시스템을 제안
- 다양한 실험을 통해 자신들의 방식이 다양한 작업에서 강력한 zero-shot 일반화 성능을 입증하였으며, 데이터 생성 자동화의 가능성을 제시
Method
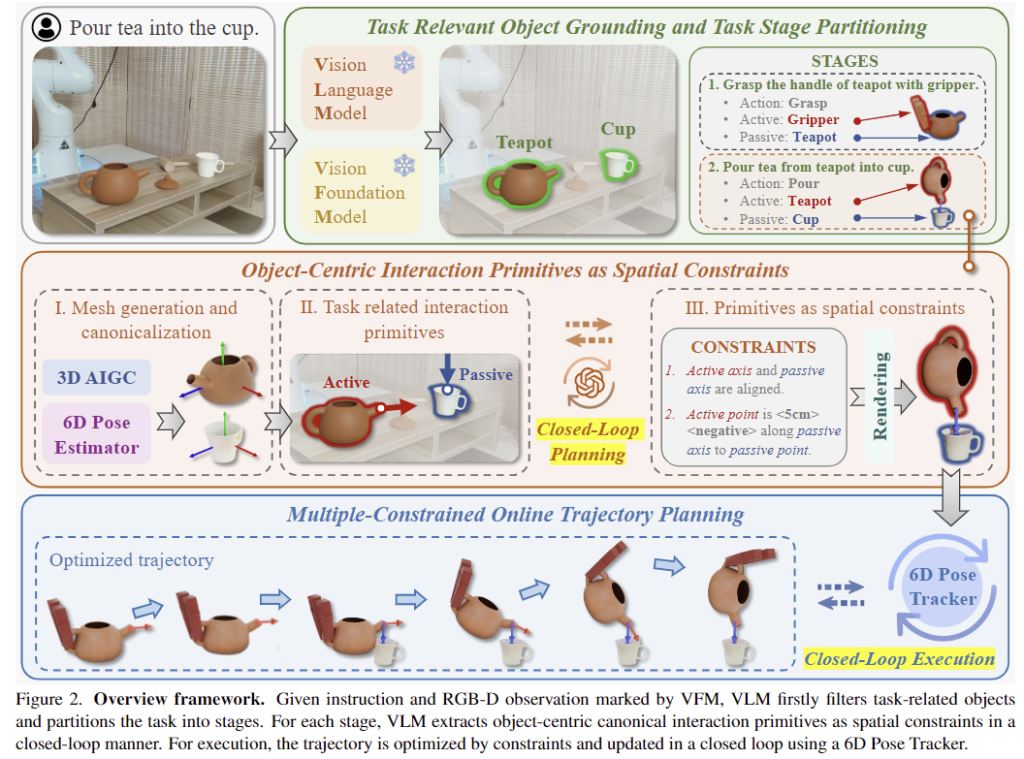
이제 방법론을 살펴보겠습니다. 위의 Figure 2는 전체적인 프레임워크를 나타낸 것으로, 2개의 Closed-Loop가 존재합니다. 작업과 이미지가 주어졌을 때, 작업의 대상 물체를 찾고 대상 물체의 mesh를 생성합니다. 이를 VFM을 이용하여 여러 stage로 분할하고 각 stage마다 interaction primitives를 정의하나 뒤 공간적 제약 조건을 통해 closed-loop방식으로 planning을 수행합니다. 이후 작업을 실행하기 위해 6D Pose Tracker를 이용한 closed-loop 방식을 통해 작업을 수행합니다.
먼저 문제 정의 및 interaction primitive를 통한 공간적 제약 조건 모델링에 대해 살펴본 뒤, 일반화된 open-vocabulary 방식으로 정형화된 interaction primitive를 어떻게 추출할 수 있는지, OminManip는 2개의 closed-loop를 어떻게 구현하였는 지에 대해 설명합니다.
1. Manipulation with Interaction Primitives
<Problem Definition>
저자들은 복잡한 로봇 작업을 공간적 제약이 있는 interaction primitives로 정의되는 여러 stage로 분해합니다. 작업 \mathcal{T}가 주어졌을 때, 2개의 VFMs인 GroundingDINO와 SAM을 통해 모든 전경 물체를 찾은 뒤, VLM인 GPT-4를 통해 task와 연관된 물체만 남기고 작업을 여러 stage로 분해합니다. stage는 \mathcal{S}_i=\{\mathcal{A}_i, \mathcal{O}^{active}_i, \mathcal{O}^{passive}_i \}로 정의되며, 각각 수행할 action과 상호작용의 주체가 되는 물체, 상호작용의 대상이 되는 물체를 의미합니다. 예를 들면, “컵에 차를 따른다”는 작업이 들어오면, 이를 주전자 잡기{grasp, 그리퍼, 주전자}와, 물 붓기{pour, 주전자, 컵}로 분해하는 것 입니다.(figure 2 참고)
<Object-Centric Canonical Interaction Primitives>
해당 논문에서는 조작 작업에 대한 물체 상호작용 방식을 표현하기 위해 interaction primitives를 포함하는 새로운 object-centric 표현을 제안합니다. 각 primitives는 \mathcal{O}_i=\{\mathbf{p}, \mathbf{v}\}로 정의되며, 각각 상호작용이 이루어지는 point와 방향을 의미합니다. 이러한 primitives는 task를 수행하기 위한 기하학적이고 기능적인 특징을 포함하므로, 다양한 시나리오에서 보다 범용적이고 재사용 가능한 조작 전량을 가능하게합니다.
<Interaction Primitives with Spatial Constraints>
각 stage \mathcal{S}_i에서의 공간적 제약은 \mathcal{C}_i로, \mathcal{C}_i는 상호작용 point 사이의 거리를 의미하는 \mathcal{d}_i와 상호작용의 방향 사이의 alignment를 보장하기 위한 \theta_i로 구성됩니다. 이러한 공간적 제약 조건은 아래의 식으로 정의가 되며, \mathcal{C}_i가 정해지면, 작업 실행은 이에 대한 최적화 문제로 풀 수 있습니다.
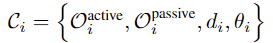
2. Primitives and Constraints Extraction
해당 섹션에서는 각 stage마다 interaction primitves와 공간적 제약 조건을 추출하는 과정을 설명합니다. 위의 Figure 2에서 가운데의 주황색 박스 안의 내용에 해당합니다. 먼저 기존 sigle-view 3D generation과 object pose estimation 연구를 이용하여 대상 물체의 3D object mesh를 구하고, 표준화된 pose를 추정합니다.
<Grounding Interaction Point>
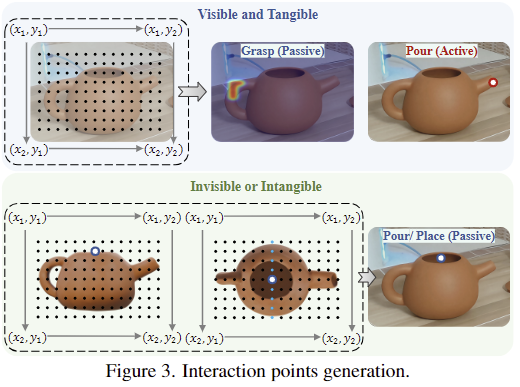
위의 Figure 3과 같이 interaction point는 주전자의 손잡이와 같이 가시적이고 물리적인 지점과 주전자 입구의 중앙과 같은 비가시적이고 비물리적인 지점으로 구분됩니다. interaction point를 찾기 위한 VLM의 grounding 성능을 높이기 위해 이미지에 격자 좌표계를 시각화한 SCAFFOLD라는 시각적 prompt방식을 사용하며, 여기서 가시적인 지점은 이미지에서 직접 찾아내고, 비가시적인 지점은 원본 view의 point와 view에 대해 생성한 multi-view를 통해 추론합니다. 이때 추론한 형태는 heatmap 형태가 되도록 합니다.
<Sampling Interaction Direction>
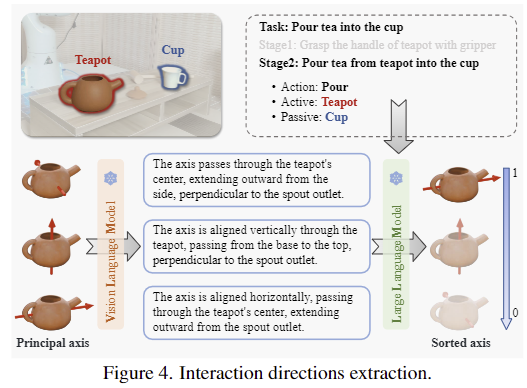
정형화된 공간에서 객체의 principal 축은 상호작용 방향의 후보로 간주됩니다. 그러나 VLM이 공간적 이해 능력이 떨어지므로, 각 방향이 얼마나 적절한 지를 평가하기에는 어려움이 있습니다. 따라서 저자들은 VLM 캡션과 LLM의 scoring 방식을 제안합니다. 이는 VLM을 통해 canonical space에서 축에 대한 설명을 생성한 뒤, LLM을 통해 해당 설명이 task와 얼마나 연관이 있는지를 점수로 나타내는 것으로, 이를 통해 작업을 수행하는데 가장 적합한 후보 방향이 순서대로 정렬된 리스트 \mathcal{K}_i=\{ \mathcal{C}_i^{(1)}, \mathcal{C}_i^{(2)}, ..., \mathcal{C}_i^{N}\}를 구할 수 있게 됩니다. 해당 과정에서 축을 기준으로만 예측 결과를 만드는 것이 너무 한정적이지 않을까 하였는데, 실험(Table 3에 대한 결과입니다)을 통해 저자들이 이후 closed-loop 과정에서도 이를 보완하여 효과적으로 추정이 가능하였음을 보였습니다.
3. Dual Closed-Loop System
large 모델의 hallucination 문제와 작업에 따른 환경의 동적 변화를 반영하기 위해, 저자들은 작업에 대한 planning과 실행 과정에 대하여 dual closed-loop 시스템을 제안합니다.
<Closed-loop Planning>

interaction primitve의 정확도를 높이고 hallucination 문제를 완화하기 위해 저자들은 Resampling과 Rendering, Checking 과정으로 이루어진 self-correction 방식 RRC를 제안합니다. 위의 pseudo code는 해당 과정을 나타낸 것으로, initial 단계와 refinement 단계로 이루어집니다. initial 단계는 앞서 정의된 제약 조건들 \mathcal{K}_i를 평가합니다. 각 제약 조건 \mathcal{C}_i^{(k)}에 대하여 상호작용 이미지 \mathbf{I}_i를 rendering한 후, 이에 대하여 VLM을 적용하여 유효성을 검사합니다. VLM은 다음의 3가지 결과를 반환할 수 있습니다. success를 반환할 경우 다음 task로 넘어가고 failure를 반환할 경우 다음 제약조건으로 넘어갑니다. refinement를 반환하면 refinement 단계로 넘어갑니다. refinement 단계에서는 더 정밀한 상호작용 방향에 대한 resampling을 수행합니다. 균일하게 6 방향으로 refinement를 수행한 뒤, 이에 대하여 다시 평가를 수행하는 방식입니다.
<Closed-loop Execution>
interaction primitives와 이에 대응되는 공간 제약 조건이 각 단계마다 정의된 후, 작업을 실행하는 과정은 최적화 문제로 해결합니다. end-efffector의 target pose \mathbf{P}^{ee*}를 결정하기 위해 아래의 식을 최적화합니다.
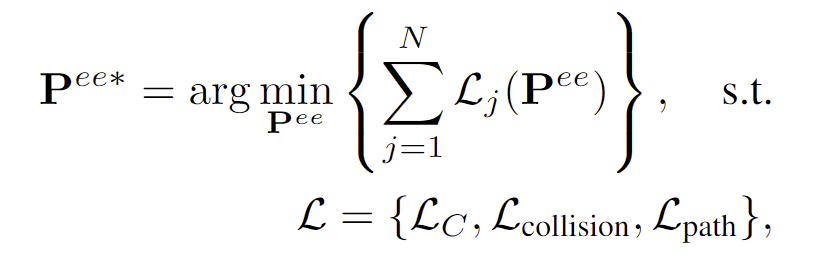
- \mathcal{L}_C는 제약조건에 대한 loss로 동작이 작업에 대한 제약을 충족하도록 하며, 아래의 식으로 정의됩니다.
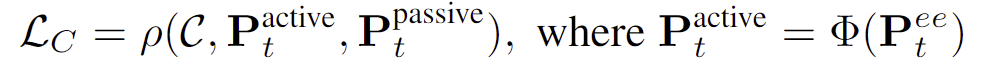
- \rho( ): active 물체와 passive 물체에 대한 공간적 제약의 차이
- Φ( ): end-effector를 pose를 active물체에 대한 pose로 변환하는 것을 의미
2. \mathcal{L}_{collision}은 end-effector가 장애물과 충돌하지 않도록 하며, 아래의 식으로 정의됩니다.
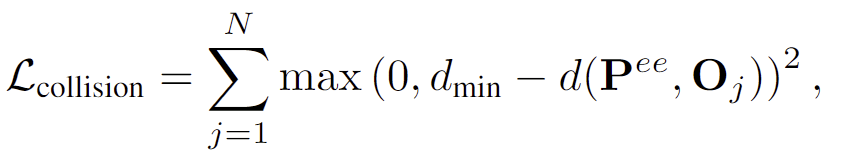
- d(\mathbf{P}^{ee}, \mathbf{O}_j): end-effector와 장애물 \mathbf{O}_j사이의 거리
- d_{min}: 사전에 정의된 최소한의 안전거리
3. \mathcal{L}_{path}는 행동을 부드럽게 수행하기 위한 것으로 아래의 식으로 정의됩니다.
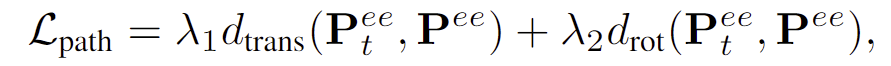
- d_{trans}( )와 d_{rot}: translation과 rotation에 대한 end-effector의 변화량
- \lambda_1, \lambda_2: rkwndcl
또한, 실제 환경에서 다양한 동적 요소로 인한 변화를 반영하기 위해 저자들은, 제안한 object-centric interaction primitives와 함께 omni6DPose 알고리즘을 적용하여 active 물체와 passive 물체의 자세를 실시간으로 갱신합니다. 이러한 피드백 과정을 통해 end-effector를 동적으로 움직이는 closed-loop execution을 수행합니다.
Experiment
저자들은 voxposer와 CoPa, Rekep을 베이스라인 방법론으로 설정하고 실험 결과를 리포팅하였습니다. (세가지 방법론 모두 다른 연구원님들의 X-review에서 확인하실 수 있습니다.) 실험은 12개의 조작 task를 설계하였으며, 이중 6개는 rigid object조작, 6개는 articulated object 조작으로 설정하였다고 합니다. 또한, 10번의 시도에 따른 성공률을 평가하였으며, 실험에 사용한 로봇팔은 2지 그리퍼가 장착된 Franka Emika Panda이고, 2개의 RealSense D415로 로봇 관점과 맞은편 두 곳에 설치하여 환경을 촬영하였다고 합니다.
Main Results
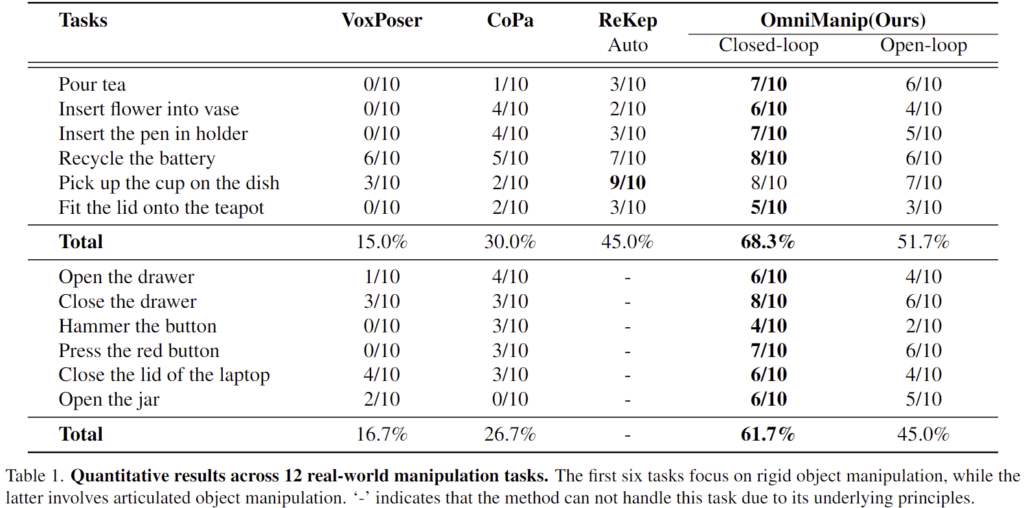
Table 1은 정량적 결과로, 다양한 작업들에 대한 성공률을 리포팅한 결과입니다. 해당 방법론은 finetuning을 수행하지 않았으며, 실험 결과를 통해 zero-shot 일반화 성능이 우수함을 보였습니다. 정성적 결과는 프로젝트 페이지에서 확인하시면 좋을 것 같습니다. 또한, 실험 결과 Closed-Loop 방식을 통해 성능이 확연히 개선되었음을 확인할 수 있습니다.
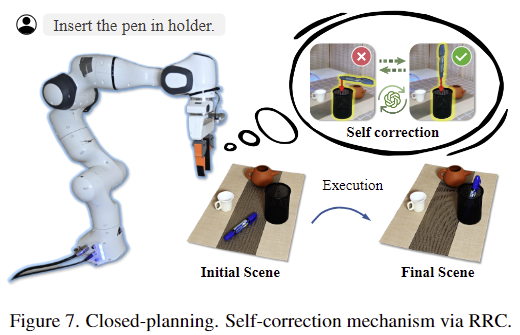
위의 Figure 7은 closed-loop를 통해 self-correction을 거쳐 펜을 홀더에 넣는 작업을 성공할 수 있었다는 것에 대한 정성적 결과입니다.

위의 Figure 8은 대상물체들의 변화가 일어나는 동적인 시나리오를 나타낸 것으로, closed loop execution을 통해 이러한 경우에도 작업을 수행하였으며, 이에 대한 결과는 데모 영상을 통해 확인하실 수 있습니다.
Reliability of OmniManip
저자들은 OmniManip의 신뢰성을 판단하기 위해 안정성과 viewpoint의 일관성에 대해 평가합니다.

먼저 안정성은 task에 대하여 interaction primitives를 신뢰할 수 있는 지를 평가하고자 한 것으로, 위의 Figure 5는 “Pour tea”에 대한 ReKep과 CoPa 방식을 비교한 결과입니다. 다른 두 방식은 작업이 실패한 결과이며, 저자들이 제안한 방식은 물체를 의미론적 기능적으로 정렬하는 정형화된 공간에서 primitives를 생성하므로 안정적이고 작업에 적합한 추론이 가능하였다고 어필합니다.
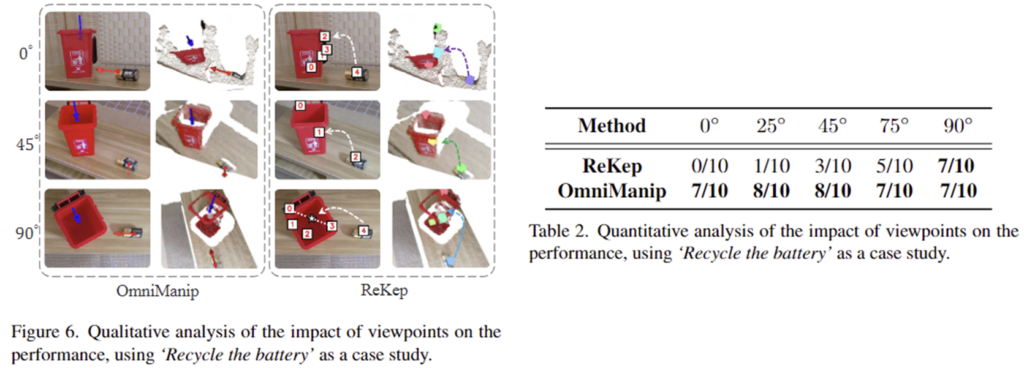
그 다음은 위의 Figure 6과 Table 2는 viewpoint에 따라 interaction primitives를 일관적으로 추출하는 지 평가한 결과를 정성적 정량적으로 나타낸 결과입니다. “Recycle the battery”에 대하여 ReKep은 90°에서만 작업에 성공할 수 있으나, OmniManip는 모든 시점에서 작업을 수행할 수 있었다고 합니다. (45°에서 배터리에서 빨간 축 방향이 다르지만, 빨간 축 방향이 파란 축 방향으로 이동하는 것으로 작업은 성공한 것으로 보입니다.)
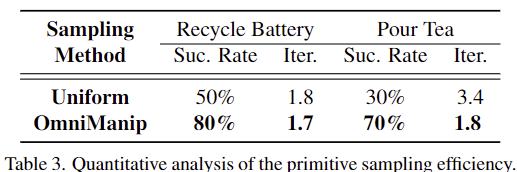
위의 Table 3은 상호작용 방향에 대하여 균일하게 샘플링한 방식과 저자들이 제안한 canonical sapce에 대한 축을 기준으로 샘플링한 결과를 비교한 것 입니다. 반복 횟수가 줄어 효율적일 뿐만 아니라 성능도 개선되는 결과를 확인할 수 있습니다.
OmniManip for Demonstration Generation
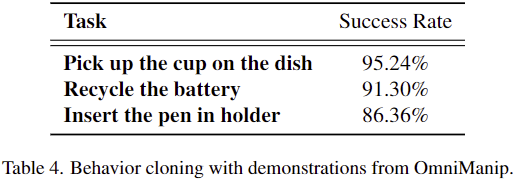
마지막으로, abstract와 contribution에서 데이터 생성 자동화에 대한 가능성을 확인하였다고 하였는데, 이에 대한 실험결과입니다. 사전지식 없이 zero-shot 방식으로 새로운 작업에 대한 데모 150개 수집한 뒤, behavior cloning policies를 학습한 결과를 나타낸것올 굉장히 높은 성공률을 달성하였습니다.
안녕하세요, 좋은 리뷰 감사합니다.
self-correction 루프에서 VLM이 interaction rendering 결과에 대해 success/failure/refinement 중 하나를 반환한다고 말씀해주셨는데, 여기서 refinement는 VLM의 어떤 기준을 기반으로 내뱉게 되는건지 궁금합니다. 또한 실험적으로 봤을 때 얼마나 refinement가 빈번하게 나타나는지, 그 정도가 성능에 미치는 영향이 달라지는 지도 궁금합니다.
감사합니다.
리뷰 읽어주셔서 감사합니다.
해당 과정은 VLM의 추론 결과로, 우선 제약 조건에는 active 물체와 passive 물체에 대한 interaction primitives(상호작용 지점과 방향정보)와 두 지점 사이의 거리, 이동 축 사이의 alignment가 포함되어있습니다. 이 정보와 렌더링으로 생성한 영상을 보고 해당 제약 조건이 적절한가에 대하여 VLM이 추정한 결과입니다.
안녕하세요 좋은 리뷰 감사합니다.
질문이 몇가지 있어 댓글 남깁니다
먼저, 해당 연구에서 Primitive Interactions의 의미를 어떻게 받아들이면 될까요? 해당 블로그의 설명을 참고하면 되는지요? https://eltaonx.tistory.com/entry/Primitive-Interactions (essential interactions)
Primitives and Constraints Extraction 단계가 공간적 제약 조건을 추출하는 과정이라고 말씀해주셨는데 비가시적이고 비물리적인 지점의 역할이 무엇인지 궁금하며,는 포인트 클라우드 형식으로(격자 좌표 형식) 상호작용할 위치를 모델링 하는것으로 이해했는데, 은 어떠한 의미를 갖는지 이해를 못했습니다. 도움을 요청합니다.
3번의에서 VLM을 적용하여 유효성을 검사한다고 하셨는데, 유효성의 의미가 무엇인가요? 요청받은 행위의 수행 여부로 이해하면 되나요?
해당 연구가 zero-shot 방식의 일반화 성능이 우수하다고 하셨는데, 해당 방식의 경우의 최적화는 수행하지 않는것인가요? 일반적인 지도학습의 목적함수와 해당 방법론의 최적화 수식이 동일한 의미를 갖는지 궁금합니다.
최적화 수식 관련하여도 몇가지 질문이 있습니다.
먼저 L_C의 경우 active 물체와 passive 물체에 대한 공간적 제약의 차이의 의미가 이해가 여럽습니다. 또한 end-effector를 pose를 active물체에 대한 pose로 변환하는 것은 end-effector의 센터의 위치를 포인트로 하여 미리 지정한 위치로 이동하도록 최적화함을 의미하는 것으로 이해하면 될까요?
다음으로 L_collision의 경우 은 end-effector가 장애물과 충돌을 줄이기 위한 식으로 이해했는데, 로봇의 모든 움직임 과정에서 장애물과 d_min 이상의 거리를 유지하도록 하는 최적화 식으로 이해했습니다. 학습에 사용되는 움직임의 경우 데이터셋으로 주어지는지, 시물레이션 데이터인지 궁금합니다. 직접 구축한 데이터셋의 경우 장애물과의 거리가 유지되지 않는 상황이 발생할 것 같은데, 이러한 경우 어떻게 학습하는지 궁금해서 여쭤봅니다.
감사합니다
질문 감사합니다.
1. 먼저 해당 연구는 interaction primitives를 상호작용이 일어나는 지점과 그 방향으로 설정합니다. 이에 대한 질문이 맞으실까요?
2. 상호작용이 일어나는 지점이 어떨 경우에는 물체의 표면일수도 있고, 어떨 경우에는 물체의 표면이 아닐 수 있습니다. 해당 figure의 예시를 이용하자면, pour tea일 경우 물이 부어지는 주전자 주둥이는 표면에 나타낼 수 있으나, 물이 부워지는 위치는 컵의 입구 부분으로 그 표면이 아니라 중간의 허공을 의미하는 게 적절합니다. 이러한 이유로 2가지 타입으로 구분한 것 입니다.
3. 유효성은 해당 제약조건이 각 stage에 적절한 제약조건인지를 VLM을 이용하여 판단하는 과정 입니다.
4. 해당 방식은 네트워크를 학습하지 않고, L_C와 L_collision, L_path를 이용하여 최소의 loss를 가지도록 하여 로봇 작업을 수행하는 방식이므로 zero-shot 방식이라 볼 수 있습니다. 네트워크 학습이 아니라 total loss 최소가 되도록 하는 end-effector의 pose를 계산하는 것으로 이해하시면 될 것 같습니다.
5. active 물체와 passive 물체에 대한 primitives는 상호작용이 이루어지는 지점과 방향입니다. 두 지점과 방향 사이의 상호작용이 이루어져야 하므로, 두 지점 사이의 거리가 줄어들고 방향의 align이 맞도록 점차 업데이트가 되도록 하는 것으로 이해하시면 될 것 같습니다.
6. 학습은 아니고 작업을 수행함에 있어 충돌을 방지하기 위한 term입니다. end-effector와 장애물 사이의 거리가 멀어지면 loss가 0이 되도록 하므로 충돌을 방지할 수 있는 것입니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
저는 사실 저자들이 “Pour tea” 에서 성공했다고 하지만, teapod과 cup 간의 상호작용 축이 일직선이 되는 것이 사실 좋은 액션은 아니라고 생각이 듭니다. 사람은 tea를 부을 때 완전히 컵의 바로 수직 위에서 90도까지 기울여서 붓진 않고, 물의 포물선을 유추하며 조금 떨어진 각도로 부으니까요. 그 외의 태스크들도 뭔가 active 객체와 passive 객체 간의 축을 거의 수직으로 align 맞추는 경향이 있을 것 같습니다. 이런 부분에서 저자들의 limitation언급이나, failure case에 대한 고찰이 있었나요?
질문 감사합니다.
우선 closed-loop execution은 계속해서 loss가 최소가 되도록 업데이트 하여 작업을 수행하는 과정으로 이해하였습니다. 따라서 처음부터 위에서 수직으로 붓지는 않고 점차, 수직 방향이 되도록 기울이게 되는 것으로 이해하였습니다.
안녕하세요 승현님 리뷰 감사합니다.
기존 VLM들은 affordance를 정밀하게 인식하지 못하는 한계가 있다고 생각했는데 OmniManip에서는 zero-shot을 강화하기 위한 목적으로 VLM을 활용한 걸까요? pixel 단위의 affordance 모델들과 비교했을때는 어떨지 궁금합니다
질문 감사합니다.
이야기하신대로, VLM을 이용하여 zero-shot 일반화가 가능하도록 접근한 방법으로 이해하였습니다. pixel 단위로 affordance를 예측하도록 학습된 모델과 차이를 의미하시는걸까요? 픽셀 단위의 affordance 예측 모델은 CLIP과 같은 vision-language의 feature 사이의 align을 맞춘 정보를 기반으로 affordance 영역에 대한 mask를 학습하는 연구들이 이루어지고 있으며, 해당 논문은 VLM을 이용하여 직접 영상 내의 관련 영역을 찾으려는 방식입니다.
재밌는 논문 리뷰 잘 읽었습니다.
질문 남기고 가겠습니다.
Q1. 방법론이 생각보다 어려워서 이해하기 위한 질문을 해야 할 것 같아요. 해당 기법에서 6D도 추론하는 것으로 파악됩니다. 이는 어떻게 구하는 걸까요?
Q2.에 Loss에 대한 내용이 어려워서 이해를 구하기 위한 질문 남깁니다. 최적화된 ee를 구하는 것이 목적이라하는데… 최종 골을 찾는 것일까요? 그럼 모션을 만드기가 어려울 것 같은데… 경로에 대한 최적화까지 고려하는 걸까요?
질문 감사합니다.
A1. 우선 해당 연구의 6D Pose Estimation 방식은 기존 연구인 Omni6DPose에서 제안된 GenPose++입니다. 단일 view 이미지로 생성한 3D mesh를 canonical space로 정렬한 뒤, 이에 대한 pose를 구하는 방식입니다.
A2. 제가 이해하기로는 loss를 한번에 구한다기보다 점차 업데이트를 진행하여 최종적으로 작업을 수행하는 방식으로 이해하였습니다. 따라서 저자들이 closed-loop라는 표현을 쓰고, 3개의 loss를 합친 통합 loss의 최적화 문제로 접근한다고 표현한 것으로 보입니다.
하이요. 여기가 맛집이라는 소문 듣고 질문 남기러 왔습니다.
우선
객체를 정형화한다는게 무슨 말일까요? canonical space라는 곳으로 변환시키는 것을 정형화한다고 하는 것 같은데, 여기 예시에서는 외형이 달라도 주전자에 속하면 다 동일한 위치로 정형화한다..? 라는 식으로 이해했는데, 이게 그럼 각 클래스 별로 정형화를 시키는 기준?같은 것을 이전 연구에서 정의했다고 보면 되는건가요?
두번째로 closed-loop과 open-loop에 대해서 설명해주실 수 있나요? 로보틱스쪽 페이퍼에서 종종 등장하는걸 봤는데 정의가 와닿지 않아서요.
마지막으로 active 물체와 passive 물체에 대한 공간적 제약의 차이가 무슨 말인가요? 리뷰 내용 중 최적화 term 설명에서 L_C 관련된 내용에서 나온 것이긴한데, 제가 리뷰를 읽으면서 이 공간적 제약이라는 워딩 자체를 완벽히 이해하지 못한 것 같아요. 이 공간적 제약의 정의와 예시를 간단하게 설명해주실 수 있나요?
감사함다.
질문 감사합니다.
먼저, 객체를 정형화 한다는 것은 특정 카테고리의 물체에 대하여 대표적인 형태로 표현한다고 이해하시면 좋을 것 같습니다. 예를들어 주전자다 하면, 손잡이가 있고 그 맞은편에 주전자 주둥이가 있고, 가운데 둥근 통 형태를 생각할 수 있는데, 이처럼 동일 카테고리의 다양한 인스턴스들의 평균 형태를 나타낸 것입니다. 그리고, 이해하신 것처럼 이전 연구에서 정의된 형태를 이용한 것 입니다.
closed-loop 방식은 로봇이 센서 데이터를 실시간으로 받아들여, 그에 따라 행동을 조정하는 방식입니다. 즉 해당 논문의 2가지 closed loop는 planning 과정과 6D Pose tracking 과정으로, 이러한 반복적인 업데이트를 통해 다양한 물체나 조작 조건에서도 작업 성공률을 높일 수 있었던 것이라 이해하시면 될 것 같습니다. 반대로 open-loop라고하면, 처음 입력 과를 통해 planning과 6D Pose 추정을 한번 수행하는 것 입니다.
마지막으로, 해당 논문에서 공간적 제약은 active 물체와 passive 물체의 상호작용이 이루어지는 두 지점 사이의 거리와 그 둘의 방향 사이의 방향의 오차라고 생각하시면 됩니다.
우선 해당 논무에서는 active 물체와 passive 물체에 대하여 상호작용이 이루어지는 지점과, 상호작용이 일어나는 방향을 예측하게 됩니다. 이후 두 물체 사이의 상호작용이 이루어지도록 두 지점 사이의 거리가 줄어들고 방향의 align이 맞도록 작업이 이루어져야 합니다.
예를 들자면, 주전자와 컵이 있고 물을 따르려 할 때(주전자는 잡고있고 컵의 위까지 이동해온 상태), active 물체는 주전자가 되며 상호작용이 이루어지는 지점은 주전자 주둥이 끝부분이 됩니다. 반대로 passive 물체는 컵이 되고, 상호작용이 이루어지는 지점은 컵의 입구 부분이 됩니다. 이 경우 물을 따르는 행동을 수행하기 위해 주전자 주둥이와 컵의 입구 부분이 가까워지고, 두 방향의 align이 맞도록 하는 것 입니다. 즉, Figure 2의 파란색 박스 안의 optimized trajectory를 보시면 주전자의 주둥이와 컵 입구가 가깝게 위치하고, 주전자 주둥이의 주황색 화살표와 컵의 파란색 화살표가 align이 맞도록 하는 것이 공간적 제약을 준다는 것 입니다.