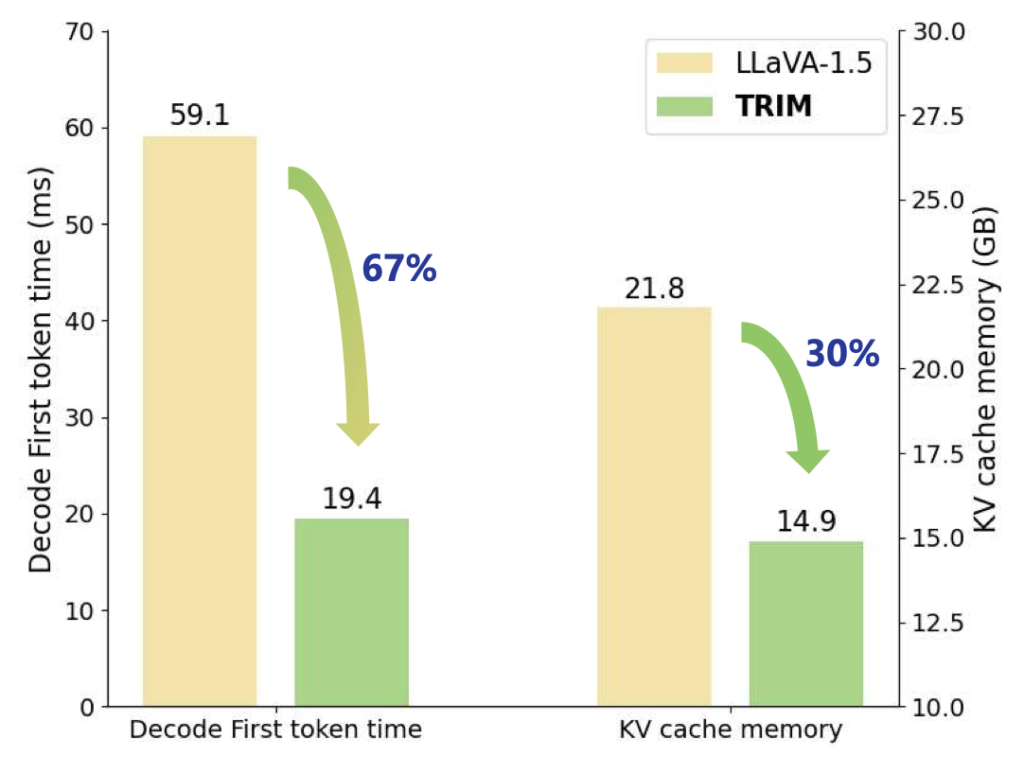
안녕하세요. 이번 리뷰는 최근 연구 및 실험 중인 MLLM (LMM) Token Reduction에 관한 논문입니다. 요즘 “MLLM의 VG/Segmentation에서 Token Reduction 시 성능 및 효율성을 고려하는 방법”에 관해 실험을 하고 있습니다. 본 방법론도 비교군 중 하나로, 우선 원활한 이해를 위해서는 최신 Token Reduction 방법론이 어떠한 측면에서 이루어지고 있는지를 이해해야 합니다. 방법론 측면에서 보면 Token Reduction의 위치가 (LLaVA 기준) CLIP의 ImageEncoder에서 수행되는지 / LLaMa (LLM)에서 수행되는지로 나뉩니다. 효율성 측면에서 전자는 아래 그림의 Decode First token time (LLM이 decoding 시 첫 번째 토큰을 생성할 때까지 걸리는 시간)이 중요 지표이며, 후자는 LLM의 연산 시간/메모리가 중요 지표입니다. 본 방법론은 CLIP의 ImageEncoder에서만 수행되며, LLM에서 수행되진 않습니다. 이 점을 염두에 두면 내용 이해에 훨씬 쉽습니다.
Introduction
MLLM (LLM)의 놀랄만한 성능의 뒷면에는 수 많은 파라미터로부터 오는 많은 양의 메모리 소비와 추론 속도 지연이 따라옵니다. 적어도 이 논문이전까지는, 이를 극복하기 위한 방법 중 하나인 Token Reduction 측면에서 PruMerge라는 논문 (이전 리뷰 글)밖에 소개되지 않았습니다. PruMerge에서는 이미지에 대해 Query/Key 간의 연산으로 이미지 토큰의 중요도를 판단하여, Top-K개 이외의 토큰을 Pruning합니다. 이에 추가로 Pruning된 토큰들을 Merging하여 정보를 보완해줍니다.
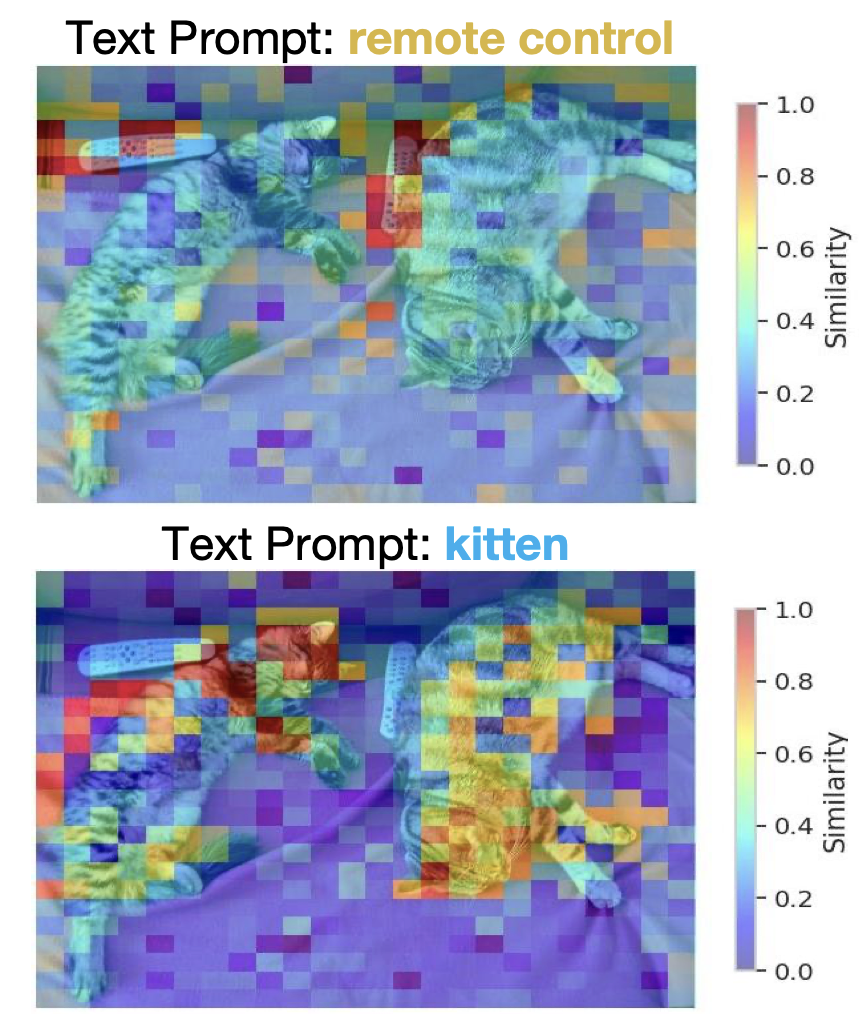
하지만 이는 다음과 같은 문제점이 있음을 지적하며, 저자는 Token Reduction using CLIP Metric (이하 TRIM)을 제안합니다. 문제점은 위 그림으로 설명이 가능합니다. 즉, 이미지에 대해 중요한 토큰을 가름짓는 것은 이미지 자체만이 아닌 텍스트라는 것입니다. 이미지에 대해 유저가 “remote control”을 요구하는지, “kitten”을 요구하는지 다를 수 있는데, 그 점을 고려하지 않고 이미지만 보고 중요 토큰을 판별하는 것에는 문제가 있다는 것이죠. 물론, 실험에서 언급하겠지만 이전 PruMerge의 저자가 이를 고려하지 못했을리는 없을 것이라 생각합니다. 우선 요즘의 방법들은 주로 텍스트를 사용함이 정설처럼 되어가는데, 이 논문은 그 시초입니다. 빠르게 방법론으로 넘어가봅시다.
Method
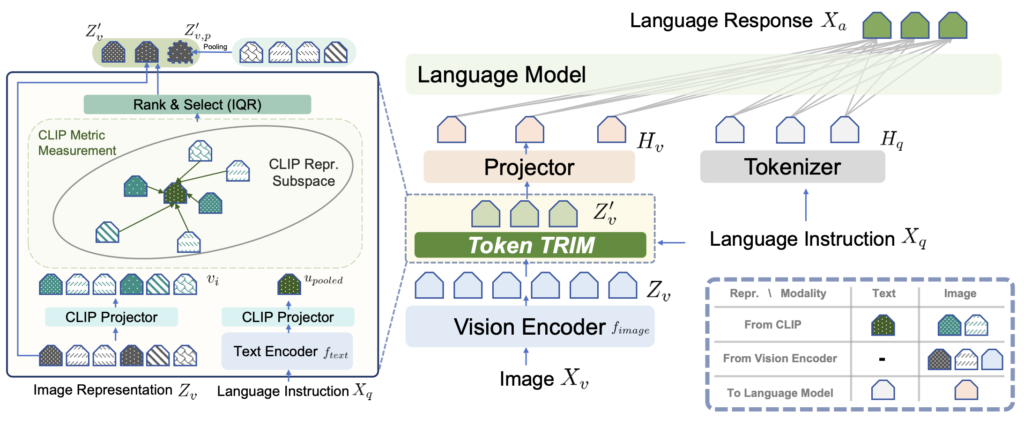
방법론 자체가 한 페이지 분량으로 길지 않습니다. Token Reudction의 핵심은 서로 다른 토큰 (LLaVA 기준 576)에서 어떤 토큰이 중요한지를 판별하는 것입니다. 앞서 말한 바와 같이 저자는 이때 텍스트 프롬프트가 핵심임을 언급하며, LLaVA 기준 CLIP ImageEncoder를 사용하기에 텍스트 프롬프트를 CLIP TextEncoder를 태웁니다 (위 그림의 Language Instruction이 Text Encoder로 통과하는 모습입니다). 텍스트의 [eot] 토큰 (텍스트 전체를 요약하는 정보를 포함)을 활용하여 (그림의 u_{pooled} ) 이미지 토큰과의 유사도 매트릭스를 (similarity matrix)를 활용합니다. 이 유사도는 576개의 이미지 토큰과 [eot] 토큰과의 cosine similarity를 소프트맥스 태워 나온 값입니다. 이 유사도 값을 기반으로 중요 토큰을 선별합니다. 이 때 몇 개의 토큰을 선별할 지는 PruMerge의 IQR 방법을 차용하여, 유사도 점수의 IQR 점수 (outlier를 판별)로 개수를 정합니다. 이는 곧 정해진 수가 아닌 이미지와 텍스트에 따라, 유동적으로 토큰을 제거할 수 있음을 의미합니다. 마지막으로, PruMerge와 마찬가지로 Pruning된 토큰들을 모아 (Merging), 정보를 보완하기 위해 그들을 평균낸 하나의 토큰을 추가하여 활용합니다. 방법론은 이로써 끝입니다. 사실 우리가 CLIP을 이미 잘 알고 있기에, 즉 CLIP의 ImageEncoder와 TextEncoder (CLIP ViT-L/32)와 그 사이의 유사도를 구하는 과정을 잘 알고 있기에 사실은 크게 어렵지 않습니다. 이외 IQR 방법이나 Merging 방식은 이전의 PruMerge에서 영감받았기에 사실 신규성 자체가 크다고 생각되진 않습니다.
Experiments
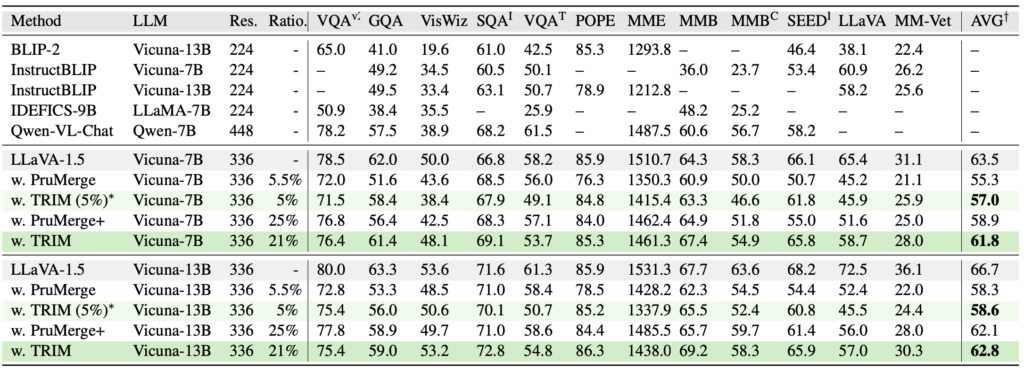
이전 PruMerge도, 본 논문의 TRIM도 모두 LLaVA에서 시작합니다. 실제로 두 방법의 코드를 보면, 2024/25년도 논문임에도 불구하고 100줄 남짓의 코드만 존재합니다. 그만큼 구현면에선 단순합니다. 위 12개의 LLaVA 벤치마크의 결과를보면, PruMerge에 비해 TRIM은 기존 LLaVA 비교 63.5->61.8 (Vicuna-7B 기준), 66.7->62.8 (Vicuna-13B)의 2-4퍼센트 정도의 성능 차이만 납니다. PruMerge와 비교 시에 Ratio (Token Reduction 이후 남은 토큰의 비율)은 약 21%로, 물론 PruMerge+의 25% 대비 4% 대비 더 많이 남긴 합니다만, 이 정도면 그래도 성능면에서 약 1-3%가 좋다보니 이해되는 수준입니다. 그런데 제가 초반부에 언급했듯, 사실 본 논문의 방법론을 보면 PruMerge와 비교해서 CLIP의 TextEncoder를 사용해야 한단 단점이 있습니다. 즉, 텍스트 프롬프트를 활용한다는 점은 다시 말해 원래의 LLaVA에선 수행되지 않았던 CLIP의 TextEncoder를 사용함에 따르는 연산량 증가가 존재합니다. 본 논문에서 이 점은 쏙 뺴놓았지만, 그래도 알아두면 좋을듯합니다.
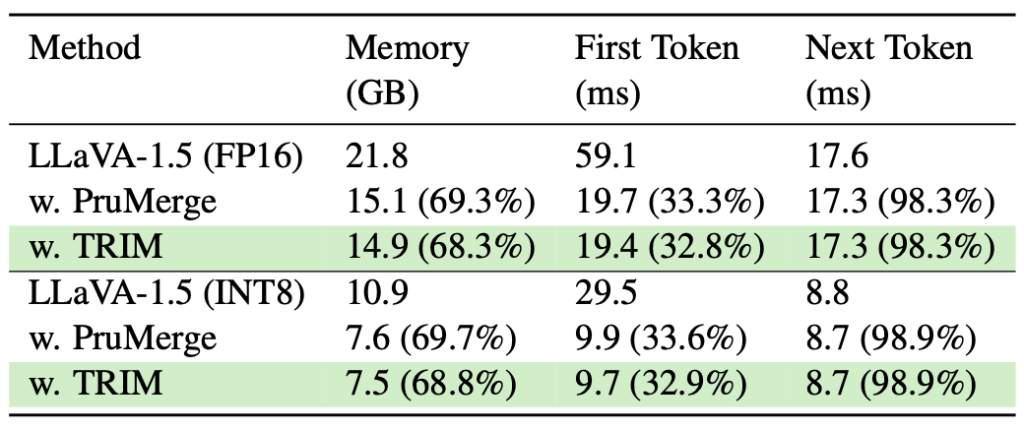
효율성 측면에서는 메모리 소비 (GB), First Token / Next Token의 LLM 디코딩 시 첫 토큰 생성까지, 그리고 다음 토큰 생성까지 걸리는 시간 (ms) 비교입니다. TRIM은 기존 LLaVA 대비와 PruMerge에서 메모리와 First Token에서 우수한 모습을 보입니다. 그런데 과연 앞서 말한 바와 같이, 과연 이 계산에서 TextEncoder를 포함시켰는지는 의문입니다. 자세히는 적혀져 있지는 않지만, LLM 연산에 대해서만 계산한 것 같습니다.
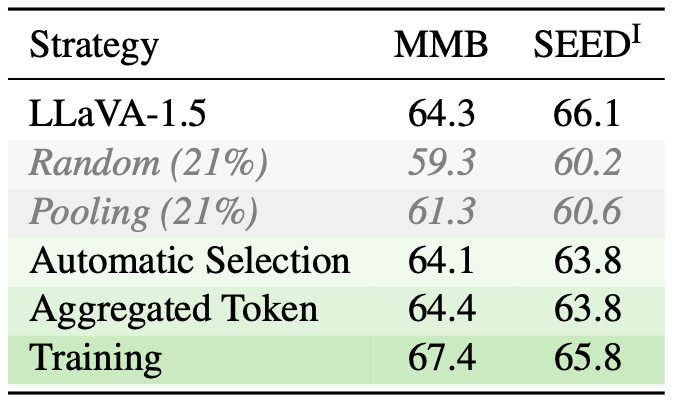
마지막으로 Ablation을 하나 가져왔습니다. 여기서 말하고자 하는 바는 두 가지로, 첫 번째는 지난 리뷰에서 언급한 바와 같이 Random이나 Pooling과 같은 방식으로도 충분히 높은 성능을 보인다는 것에서 놀랍다는 (아마도 제 생각에는, 랜덤으로 제거하더라도 LLM이 그 이름 (Large) 답게 잘 수행해내는 것 같습니다)면이며, 두 번째로는 Training으로 약 2-3%의 성능 향상이 있단 점입니다. 이 점은 요즘 추세와는 벗어납니다. 즉, MLLM을 Training 시켜야한다는 것이 LLaVA 기준 A100 80G 8장이 필요한데, 이것을 학습시키기 위해서는… 어마한 돈이 필요합니다. 그래서인지 요즘에는 Training-free가 대세입니다. 그렇기에 2025, 올해 논문임에도 물구하고 이 이후에도 최근까지 지속적으로 연구되고 있는 추세입니다.
이번 리뷰글은 굉장히 짧았네요. 실제로 논문이 5장짜리여서 방법론 자체가 깊지 않아, 읽기에도 충분했으며 다음 번에는 이를 Segmentation (VG)에 활용한 실험 결과도 한 번 들고와보겠습니다. 감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
한가지 궁금한 점이 있어 질문 남겨두겠습니다.
리뷰해주신 논문에서, 이미지 토큰의 중요도를 판단할 때 텍스트 프롬프트를 CLIP TextEncoder에 태워 [eot] 기준 유사도를 계산한다고 이해했습니다. 다만, 기존 LLaVA에는 TextEncoder가 존재하지 않았던 것으로 아는데, 효율성 측정 시 (특히 First Token Latency 및 Memory 사용량 계산 시) 이 추가 연산을 포함한 결과인지, 혹은 LLM 연산 기준으로만 측정한 것인지 궁금하네요
오호, 재밌는 질문 감사합니다.
정확합니다. LLaVA는 TextEncoder를 포함하지 않습니다.
그래서 Text에 대해 CLIP의 TextEncoder를 로드해야합니다.
음, 제 생각에는 논문에 살짝 돌려 나와 있는데, CLIP의 파이프라인에 대한 시간과 메모리 (First Time Token/Memory Usage)를 포함해서 측정했다고 되어는 있습니다. 그런데, 성능 표를 보면, 제가 LLaVA-PruMerge와 TRIM 두 코드를 모두 보고 실제 실험을 해봤기에 아는 바로는, 연산면에서 절대 TRIM이 더 적을 수는 없습니다. 그래서 뭐 의아하지만 몰래 쏘옥 뺐을 수도 있지 않을까는 싶습니다.
안녕하세요. 좋은 리뷰 감사합니다.
table에 있는 ratio가 의미하는게 기존 베이스 모델 LLaVA의 576개 image token 대비 남은 토큰 비율이라고 이해했습니다. 이 비율이 약간씩 차이나서 아주 fair한 비교는 어려워 보이는데, 방법론 특성상 이 비율을 다른 PruMerge와 아주 동일하게 맞추기는 어려운 건가요 ? 또 이 text encoder로 들어가는 instruction이 데이터셋마다 다 통일된 형식으로 들어가는지 궁금합니다.
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
아 그렇습니다. 물론 정확히 몇 프로라는 것을 맞출 수도 있습니다. 표를 보면 TRIM (5%) 같은 것은 정확히 맞춘 예시입니다. 그런데, 이 Pruning이라는 것이 잘 생각해보면 이미지의 복잡도? 또는 텍스트의 복잡도?에 따라 지워도 괜찮은 토큰이 적을 수도/많을 수도 있습니다. 그렇기에 엄밀한 비교는 “엄밀히 말하면 할 수 있습니다, 하지만” 쉬울수도/어려울 수도 있습니다 (저자의 의도에 따라 달라지기 때문입니다).
Instruction은 이미 데이터셋내에 내재되어 있습니다. 통일된 형식이란 없습니다.
재밌는 논문 리뷰 감사합니다.
질문 남기고 가겠습니다.
Q1. VQA과 같이 language instruction의 길이가 길어지는 경우, CLIP text encoder에 어떻게 처리를 하는지 궁금합니다. 영상과 텍스트 clip feature 간의 similarity matrix를 만드는 경우, 객체에 해당하는 text로 만드는 걸로 아는데.. 해당 기법에서는 뭘 기준으로 유사성을 검사하는지 궁금합니다.
Q2. 해당 기법과는 별개의 질문인데요. 최근 token을 특정 정보에 강화하는 방법으로 pruning을 사용하는 것도 고민하고 있긴 합니다. 혹시 이와 유사한 방법론에 대해서 아시는지 궁금합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
A1. 오호, 실제 본 논문의 Git에도 있는 질문과 유사합니다. 물론 지금과는 의도가 다르지만
“https://github.com/FreedomIntelligence/TRIM/issues/2” 위 링크를 보면 LLaVA-7B 기준으로는 최대 토큰을 77개까지만 받을 수 있는데, 어떻게 처리했을까에 관한 질문입니다 (실제로 벤치마크 모든 것을 뜯어보진 않았지만 일반적으로 질문 길이가 길지 않아 문제는 없었으리라 생각합니다).
그래서 질문에 대해서는 우선, 제가 직접 이 코드를 실험했기에 코드적으로 봤을 때는 그냥 입력 문장을 CLIP에 태워버립니다. 우리가 흔히 아는 “A photo of a [CLS]”의 템플릿이 아닌, 문장을 그대로 토크나이징하여 CLIP TextEncoder에 태웁니다. 그리고선 Text Feature는 마지막 레이어의 [EoS] 위치의 임베딩을 사용합니다. 그러니 즉, 객체에 해당하는 Text로 만드는 것은 아닙니다. (참고로 전 객체에 해당하는 Text로 만들어 유사도를 검사하는 실험을 진행 중에 있습니다)
2. Token을 특정 정보에 강화하는 방법에 Pruning을 사용한다는 것이 정확히 와닿지는 않습니다. 제가 이해한 바로는 Pruning을 통해 각 이미지 토큰들에 어떤 정보를 더 주고자(강화) 한다는 의미일까요?
만약 이렇다면, Pruning보다는 Merging을 변형해서 활용함은 어떨까 합니다. 근처 유사한 토큰들과 정보를 Merging하면 정보가 강화될 수 있습니다.
Pruning도 그런 목적으로 활용될 수는 있습니다. 예를 들어 실험 결과 Pruning을 했는데, 원래 성능보다 더 높을 때도 있습니다. 그런데 이것은 이제 오히려 방해가 될 수 있는 토큰을 지웠을 때 성능이 높아지는 것으로 분석됩니다 (그렇다고 해서 이것이 흔한 케이스는 아닙니다. 보통은 Pruning을 꽤나 큰 비율 (75% 수준)으로 하기에, 성능이 낮아집니다).