오늘은 Video-Text Retrieval 중에서도, 비디오-텍스트 정렬이 맞지 않은 noisy한 상황에 집중한 논문에 대해 리뷰해보겠습니다.

- Conference: CVPR 2025
- Authors: Huakai Lai, Guoxin Xiong, Huayu Mai, Xiang Liu, Tianzhu Zhang
- Affiliation: University of Science and Technology of China, Deep Space Exploration Laboratory, Dongguan University of Technology
- Title: Rethinking Noisy Video-Text Retrieval via Relation-aware Alignment
1. Introduction
비디오-텍스트 검색(Video-Text Retrieval, VTR)은 비디오에 맞는 설명을 찾거나, 문장에 맞는 비디오를 검색하는 태스크입니다. 대부분의 기존 연구는 학습 데이터의 비디오-텍스트 쌍이 정확히 맞는다는 전제를 바탕으로 정렬 관계를 학습해왔습니다.

하지만 실제 데이터는 그렇지 않습니다. 웹에서 수집한 데이터에는 잘못 연결된 쌍(Noisy Correspondences, NC) 이 흔하게 존재하며, 이는 모델이 잘못된 정렬 관계를 학습하게 만들어 성능을 크게 떨어뜨릴 수 있습니다. 그림 (a) 가 그 예시인데, 비디오-텍스트 매칭 관계가 실제로는 “물고기를 칼로 자르는 장면”인데도 “부엌에서 요리하는 장면”과 유사도가 높아 잘못 연결된 상황이죠. 이러한 잘못된 쌍이 학습에 사용되면 모델은 엉뚱한 관계를 학습하게 됩니다.

기존의 NC 문제 해결법은 “clean pair”와 “noisy pair”을 구분하고, noisy pair는 학습에서 덜 사용하거나 수정하는 방식이었습니다. 하지만 이 역시 모델이 계산한 유사도에 크게 의존하기 때문에, 유사도 예측이 틀리면 오히려 오류가 강화되는 악순환이 발생하죠. 그림 (c)가 바로 그 예시입니다.

저자들은 이러한 한계를 극복하기 위해, 각 비디오나 텍스트가 단일 쌍으로만 비교되는 것이 아니라 여러 개의 대표 기준(agents) 과의 관계 속에서 정렬될 수 있도록 하는 방식을 제안했습니다. 그림 (b)에서처럼, 각 샘플은 α, β, γ와 같은 대표 쌍들과 연결되어 있고, 이들과의 상대적인 유사도 순위(Ranking Distribution) 를 통해 정렬을 학습합니다.
보시면, α와 γ는 모두 ‘a man’, β는 ‘a woman’이라면, α와 γ가 더 유사해야 하는 것이 자연스럽습니다. 이처럼 구조적 관계를 모델이 학습하게 만들면, 단순한 유사도 점수보다 더 안정적인 정렬이 가능하다는 것이 해당 논문의 motivation 이죠.
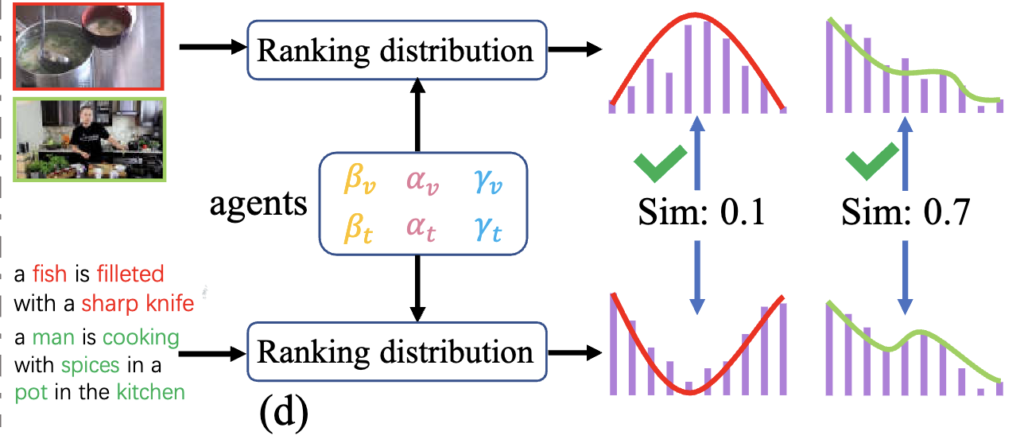
그림 (d)는 이러한 순위(rank) 기반 학습이 어떻게 더 신뢰할 수 있는 지를 보여줍니다. 기존 방식은 하나의 텍스트와 비디오 간의 유사도만 비교했기 때문에, 잘못된 noisy pair가 높은 유사도를 갖는 경우 이를 그대로 학습하게 되는 문제가 있었습니다. 반면, 이 논문은 각 샘플이 여러 agent들과 맺는 관계를 전체적으로 고려하여, 이들과의 상대적인 순위 분포를 생성하죠.
즉, 단일 유사도 점수에 의존하지 않고, “이 비디오가 어떤 agent들과 더 가까운지를 정렬 기준으로 보고, 텍스트도 마찬가지로 순위를 만들고, 이 두 순위가 얼마나 일치하는지를 비교“하는 방식입니다. 만약 잘못된 noisy pair라면, 이런 순위 일관성이 자연스럽게 깨지게 되고, 모델은 이를 잘 맞지 않는 쌍으로 인식하게 됩니다.
결과적으로 이 논문은 단순한 유사도 기반 학습이 아닌, 구조적 관계를 반영한 순위 분포 기반 정렬 학습을 도입하여 NC 문제를 해결하고자 한 것이죠. 특히, 노이즈가 많은 실제 환경에서도 모델 성능을 안정적으로 유지하는 것이 저자들이 초점을 맞춘 부분이 아닐까 합니다. 이제 해당 논문의 컨셉은 충분히 이해하셨을 거라 생각되니, 본격적인 리뷰 시작하겠습니다.
2. Method: RPC
2.1 Overview of Framework
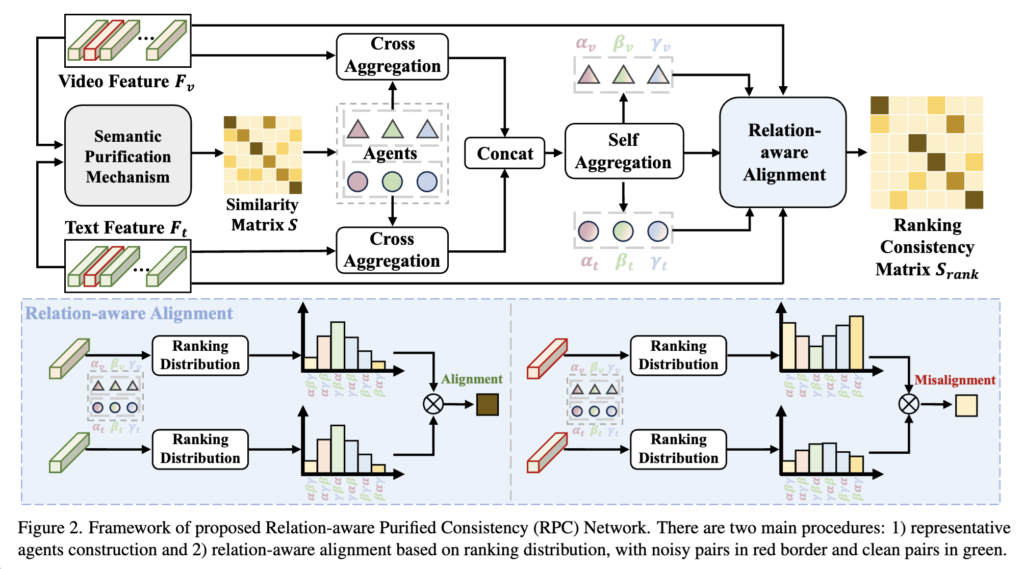
본 논문에서 제안하는 RPC(Relation-aware Pair Consistency) 프레임워크는 크게 두 가지 과정으로 구성됩니다. 첫 번째는 대표 agent를 어떻게 구성할 것인가에 대한 것이고, 두 번째는 각 비디오나 텍스트가 이 agent들과 어떤 관계를 가지는지 학습하는 방법에 대한 것입니다.
Introduction을 통해 이 논문의 컨셉을 이해했다면, agent를 어떻게 구성하느냐가 핵심일 것 같다고 생각하셨을 것 같습니다. 저자 역시 마찬가지였고, 좋은 agent가 되기 위한 세 가지 기준을 다음과 같이 정의했습니다:
1) 신뢰도(Reliability) – 잘못된 쌍이 agent로 선택되지 않을 만큼 신뢰할 수 있는지
2) 표현력(Representativeness) – 다양한 의미를 폭넓게 대표할 수 있는지
3) 회복력(Resilience) – 비디오와 텍스트 간 표현 차이를 잘 견디고 일관성을 유지할 수 있는지.
이 논문의 첫번째 과정인 agent 설계는 바로 이 세 기준을 충족하기 위한 모듈로 구성됩니다.
두 번째 과정에서는 이렇게 구성된 agent들을 기준으로, 각 비디오나 텍스트가 agent들과 맺는 관계를 확률적인 순위 분포(ranking distribution) 로 표현합니다. 즉, 하나의 고정된 유사도 점수가 아니라, 어떤 agent에 더 가깝고 먼지를 상대적인 순위 형태로 모델에 전달하는 것이죠. 이 방식이 relation-aware 정렬의 핵심입니다.
이 RPC 프레임워크는 결국 잘못된 쌍이더라도 agent들과의 관계를 통해 상대적인 일관성을 측정할 수 있고, 이를 바탕으로 더 신뢰할 수 있는 비디오-텍스트 정렬을 수행하는 것이죠. 이제 2가지 과정에 대해 구체적으로 설명하겠습니다.
2.1 Agents Construction
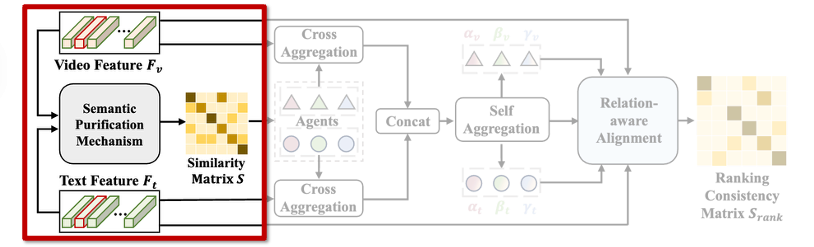
2.1.1 Semantic Purification (for Reliability): 비디오-텍스트 유사도 계산
먼저 신뢰도를 높이기 위해 저자들은 Semantic Purification 모듈을 제안합니다. 이 모듈의 핵심 목적은, 잘못된 쌍이 agent로 선택되지 않도록 유사도 계산 자체를 정제(purify) 하는 데 있습니다.
기존 방식은 프레임과 단어 간 유사도를 단순 내적으로 계산하고, 이를 그대로 평균하거나 가장 높은 값만 사용하는 방식이었습니다. 하지만 noisy 데이터에서는 겉으로 유사해 보이지만 실제로는 의미가 다른 쌍도 많기 때문에, 이런 방식은 오히려 오류를 강화시킬 수 있습니다.
저자들은 이를 피하기 위해, 먼저 비디오와 텍스트 간의 프레임-단어 유사도 행렬을 구한 뒤, 각 프레임마다 가장 잘 맞는 단어, 각 단어마다 가장 잘 맞는 프레임만을 선택하여 유사도를 계산합니다. 그리고 이 유사도들은 단순히 평균되는 것이 아니라, 각 프레임과 단어가 얼마나 중요한지를 나타내는 가중치를 통해 계산하였습니다.
이 과정을 수식으로 나타내면 다음과 같습니다:
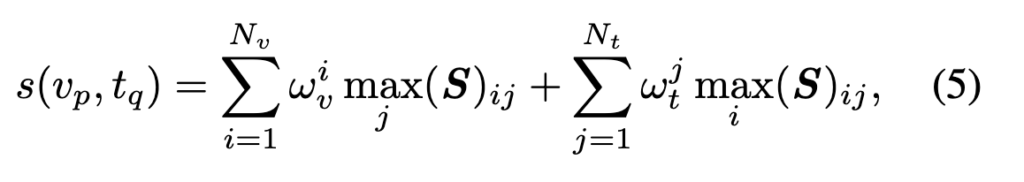
여기서 S_{ij}는 i-번째 프레임과 j-번째 단어 간의 유사도이며, \omega는 해당 프레임 또는 단어의 중요도를 나타냅니다. 이 가중치는 다음과 같이 정의됩니다:
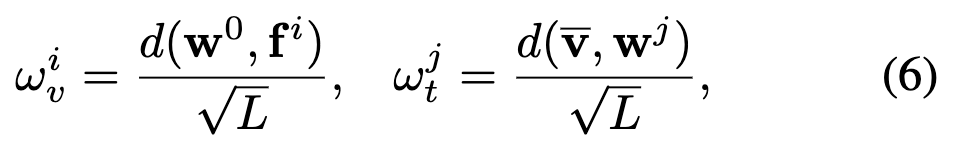
즉, 각 프레임이 텍스트의 전체 의미([CLS], \mathbf{w}^0)와 얼마나 밀접한지, 각 단어가 비디오 전체(\bar{\mathbf{v}})와 얼마나 밀접한지를 계산해 덜 관련된 요소는 자연스럽게 영향력을 줄이는 방식입니다. (여기서 d(⋅,⋅)은 내적 연산을, L 은 feature 차원 수.)
또한, 특정 기준값보다 중요도가 낮은 프레임/단어는 아예 제거하여 더욱 정제된 계산만 남기게 되는데, 이 기준은 다음과 같은 데이터 기반 임계값 \delta을 통해 계산됩니다:
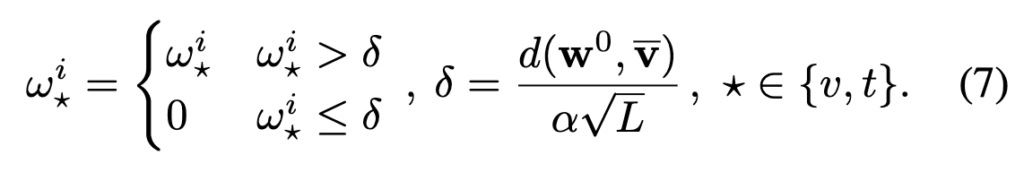
마지막으로, 이렇게 정제된 유사도를 양방향으로 비교해 해당 쌍의 신뢰도를 계산합니다. 두 방향 모두에서 높은 유사도를 보일수록, 이 쌍은 신뢰할 수 있는 agent 후보가 됩니다. 이 점수는 다음 수식으로 표현됩니다:
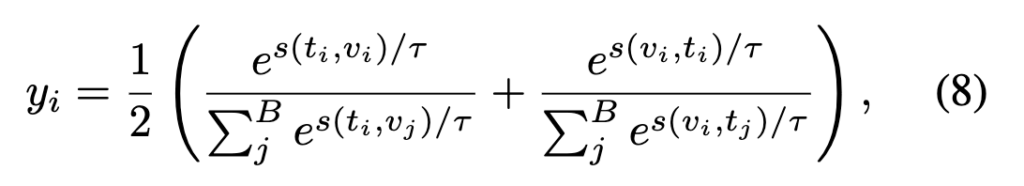
결국 이 y_i 값이 높을수록, 비디오와 텍스트가 서로 일관되게 잘 맞는 쌍이라는 뜻이고, agent로 선택될 가능성이 높아지는 것이죠.
2.1.2 Cross-aggregation Mechanism (for Representativeness)
이처럼 신뢰도를 보장할 수 있는 agent 후보가 구성되었다면, 이제는 각 agent가 얼마나 다양한 의미를 대표할 수 있는지, 즉 표현력(Representativeness) 을 높이는 것이 중요합니다. 이를 위해 저자들은 Cross-aggregation 모듈을 제안합니다.
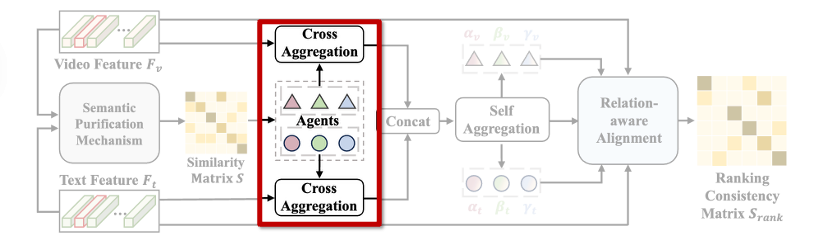
이 모듈의 목표는, 하나의 agent가 다양한 의미적 맥락을 담을 수 있도록 다른 쌍의 의미 정보를 끌어오는 것입니다. 예를 들어 특정 agent가 ‘달리는 사람’이라는 의미를 담고 있다면, 이와 유사한 의미의 다양한 비디오/텍스트와의 관계를 강화해 그 표현력을 더욱 풍부하게 만드는 방식입니다.
이를 구현하기 위해, 저자는 비디오 또는 텍스트의 feature F_\star에서 얻은 정보를 기준으로 agent feature F^A_\star를 정제하죠. 좀 더 구체적으로, agent를 query로 두고 전체 feature를 key/value로 삼아 attention 연산을 수행하는 방식입니다.
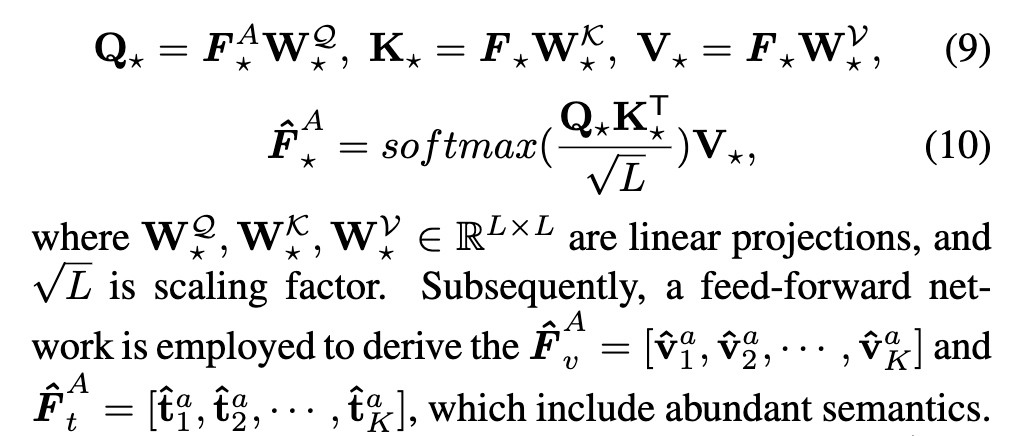
이 attention 연산을 통해 agent는 다양한 쌍의 의미 정보를 요약해 받아들이게 되고, 이를 기반으로 더 풍부한 표현력을 갖추게 됩니다.
2.1.3 Self-aggregation (for Resilience)
하지만 여전히 비디오와 텍스트는 서로 다른 modality이기 때문에, 같은 의미라도 표현 방식이 달라 서로 어긋날 수 있습니다. 이를 극복하고 회복력(Resilience) 을 높이기 위해, 저자들은 Self-aggregation 모듈을 추가로 도입했습니다.
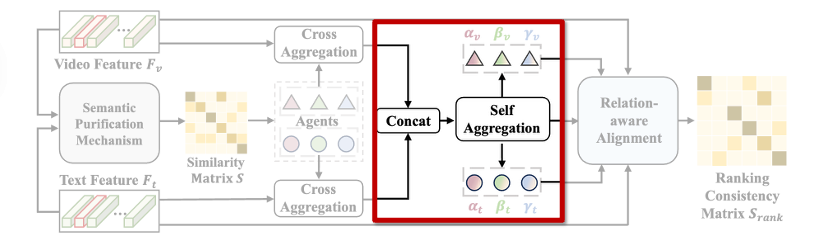
Self-aggregation은 간단히 말해, 앞에서 정제된 비디오/텍스트 agent \hat{\mathbf{F}}^A_v, \hat{\mathbf{F}}^A_t를 하나의 공간으로 통합하여, modality 간 표현 갭을 줄이는 역할을 합니다. 두 modality의 agent를 concat한 후, 이 전체 시퀀스에 self-attention을 적용합니다:
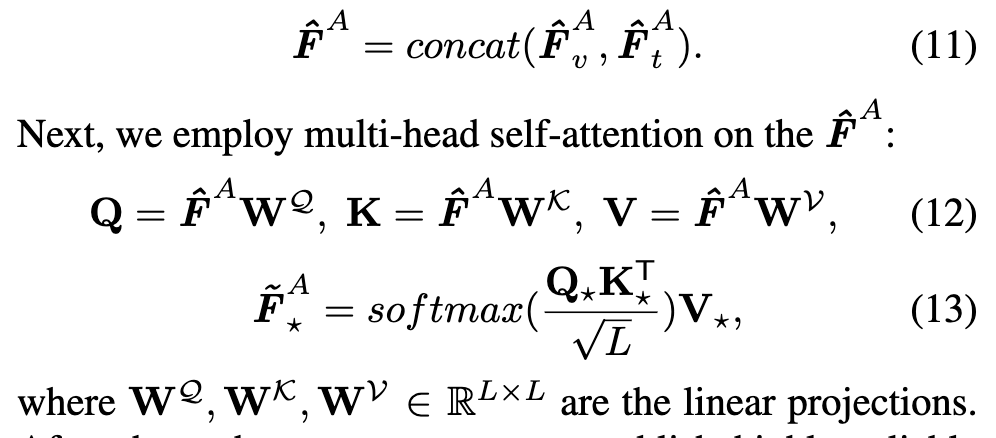
이 과정을 통해 최종적으로 얻어진 \tilde{\mathbf{F}}^A_\star는 modality에 구애받지 않고 다양한 의미를 안정적으로 담을 수 있는 신뢰도·표현력·회복력을 모두 갖춘 agent가 됩니다.
지금까지 설명한 세 가지 모듈(Semantic Purification, Cross-aggregation, Self-aggregation)은 각각 신뢰도, 표현력, 회복력을 위한 요소로, 이 논문의 전체 agent 구축 방식이었습니다. 이를 통해 구성된 agent들은 이후 순위 기반 정렬 학습의 기준으로 활용됩니다.
2.3 Relation-aware Alignment
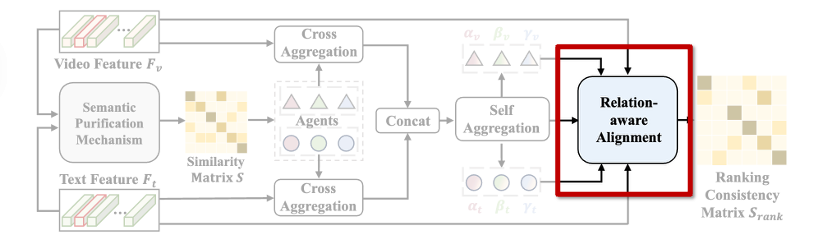
지금까지 구성한 agent들을 바탕으로, 본격적으로 비디오와 텍스트를 정렬하는 과정에 대해 설명드리겠습니다. 저자들은 단순히 각 샘플이 어떤 agent와 유사한지만 보는 것이 아니라, 이들이 가지는 순위의 일관성을 활용하여 더 정밀하고 신뢰할 수 있는 정렬 방식을 제안합니다. 이를 relation-aware alignment라고 부릅니다.
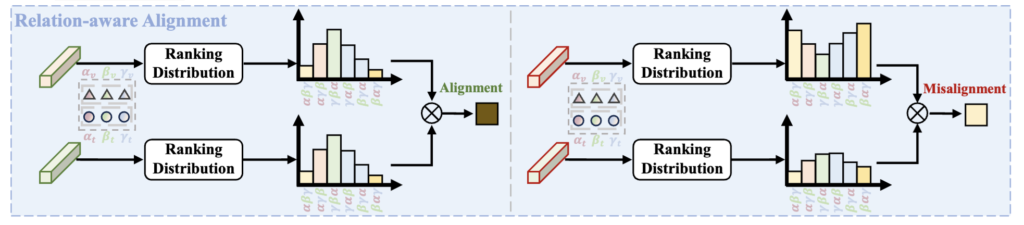
상단 그림을 통해 순위(Ranking)를 기반으로 정렬을 수행한다는 개념을 이해해봅시다. 먼저, 각 비디오와 텍스트는 agent들과의 관계를 바탕으로 하나의 분포(ranking distribution)를 만듭니다. 왼쪽 그림처럼 비디오와 텍스트가 유사한 분포를 가진다면, 두 샘플은 같은 의미를 공유한다고 볼 수 있어 정렬이 잘 된 경우입니다. 반면 오른쪽처럼 두 분포가 크게 다르다면, 이 비디오와 텍스트는 서로 맞지 않는 noisy pair일 가능성이 높습니다. 즉, 이 논문은 단순한 유사도 점수보다, agent와의 순위 구조가 얼마나 비슷한지를 기준으로 정렬을 판단하는 방식입니다.
이제 이 과정을 어떻게 수행하였는지 구체적으로 설명하겠스빈다. 우선 각 비디오 또는 텍스트가 agent들과 얼마나 유사한지를 softmax 기반으로 계산합니다. 이 과정에서 얻는 \mathbf{r}_\star^i \in \mathbb{R}^{1 \times K}는 해당 샘플이 각 agent와 얼마나 가까운지를 나타내는 확률적 유사도 벡터입니다:
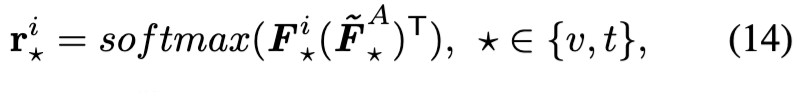
그런데 이 벡터 자체만 비교하면, noisy한 상황에서는 여전히 잘못 정렬될 수 있습니다. 예를 들어 agent α, β, γ에 대해 텍스트는 (0.8, 0.1, 0.1), 비디오는 (0.7, 0.2, 0.1)이라 해도 절대값은 비슷하지만 순위 일관성에 대한 정보는 부족하죠
그래서 저자들은 이 유사도 벡터를 바탕으로 각 샘플이 agent들을 어떤 순서로 “정렬할 것인지”에 대한 확률 분포, 즉 ranking distribution을 계산하였습니다. 이는 단일 순위가 아니라, 여러 개의 가능한 순열(π)에 대해 확률을 부여하는 방식으로, 식 (15)와 같이 정의됩니다:
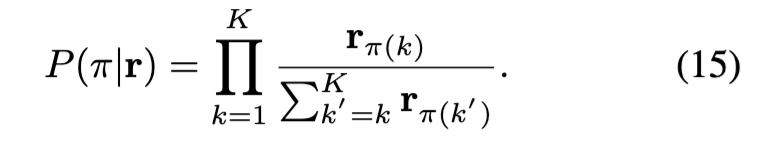
예를 들어 agent α, β, γ에 대해 π = (α, β, γ) 순서를 따를 확률은 아래처럼 계산됩니다:
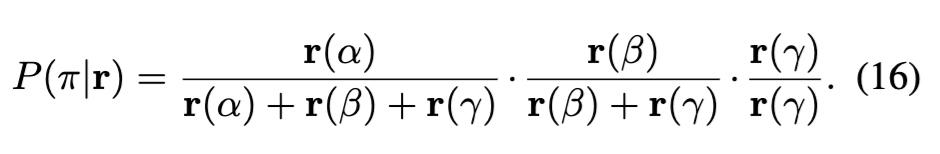
이렇게 구한 ranking 분포는 단순한 유사도보다 훨씬 더 구조적인 관계를 반영합니다. 하지만 K개의 agent에 대해 가능한 순열의 수는 K!개이기 때문에, 실제로는 상위 4개 agent만 고려하여 연산량을 줄였다고 합니다.
이제 비디오와 텍스트 각각의 ranking distribution이 계산되었으니, 이 둘이 얼마나 일관된 순위를 가지고 있는지를 코사인 유사도로 측정합니다:
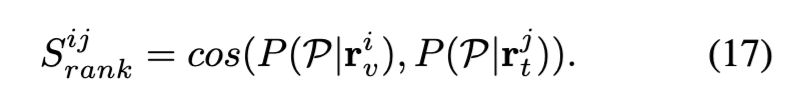
이 값이 클수록 비디오와 텍스트가 agent들과 맺는 관계가 유사하다는 의미이고, 곧 두 샘플이 잘 매칭된다는 신호가 됩니다. 이 정렬 결과는 학습에 바로 사용되고, 기존 유사도 기반 점수 s^{ij} = s(v_i, t_j)와 비교하여 KL divergence를 최소화하도록 학습됩니다:
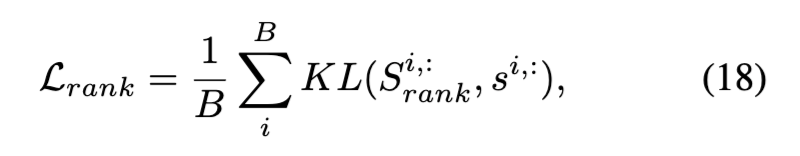
최종적인 Loss는 기본적인 위 KL 기반 정렬 loss를 함께 사용하는 형태로 구성됩니다:
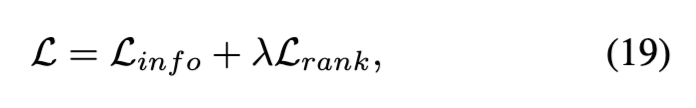
여기서 \mathcal{L}_{\text{info}}는 기존 VTR에서 널리 사용되는 contrastive loss로, 비디오-텍스트 간 유사도를 높이고, 일치하지 않는 쌍과는 멀어지게 학습하는 역할을 합니다. CLIP 생각하면 이해가 쉽겠네요. 결국 이 논문은 여기에 추가로 순위 기반 Loss \mathcal{L}_{\text{rank}}을 더해, Noisy한 상황을 대응하고자 한 것이죠!
3. Experiments
3.1 Experiment Setup
Dataset
- MSR-VTT
- LSMDC
- MSVD
- ActivityNet
- DiDeMo
Evaluation Metrics
- Recall@K (K=1, 5, 50)
<< 왜 10은 안썼지?..?
3.2. Comparison with State-of-the-arts
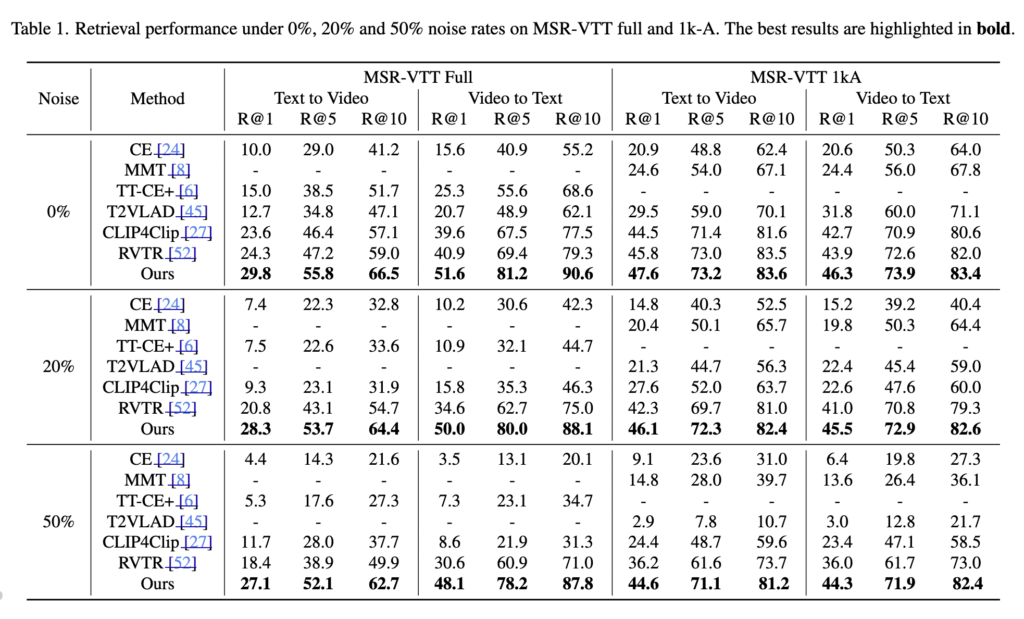
MSR-VTT에서는 noise-free부터 50%-noise까지 모든 설정에서 기존 방법보다 우수한 성능을 보였습니다. 특히 50% noise 환경에서는 기존 SOTA(RVTR) 대비 R@1 기준 최대 8.7포인트 향상되었고, noise 증가에 따른 성능 감소도 훨씬 적었습니다. 이는 제안한 방법이 noise에 강건하다는 점을 보여준다고 하빈다.
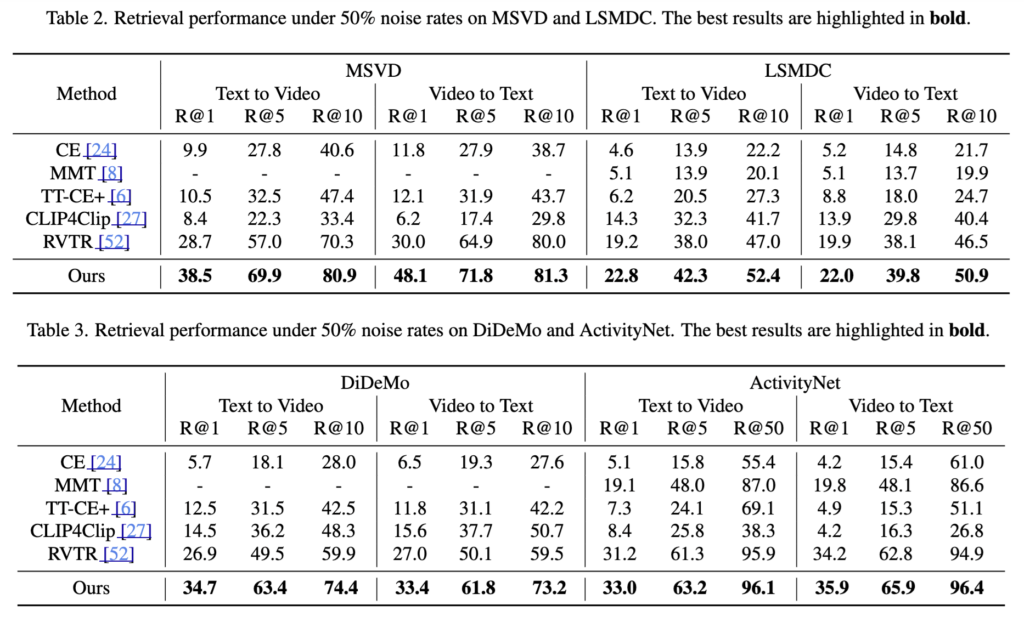
다른 데이터셋인 MSVD, LSMDC, ActivityNet, Didemo 실험에서도 모든 지표에서 기존 방법들을 안정적으로 뛰어넘었습니다. 이는 제안한 방법이 다양한 데이터셋에서도 일관되게 강건하다는 것을 의미합니다.
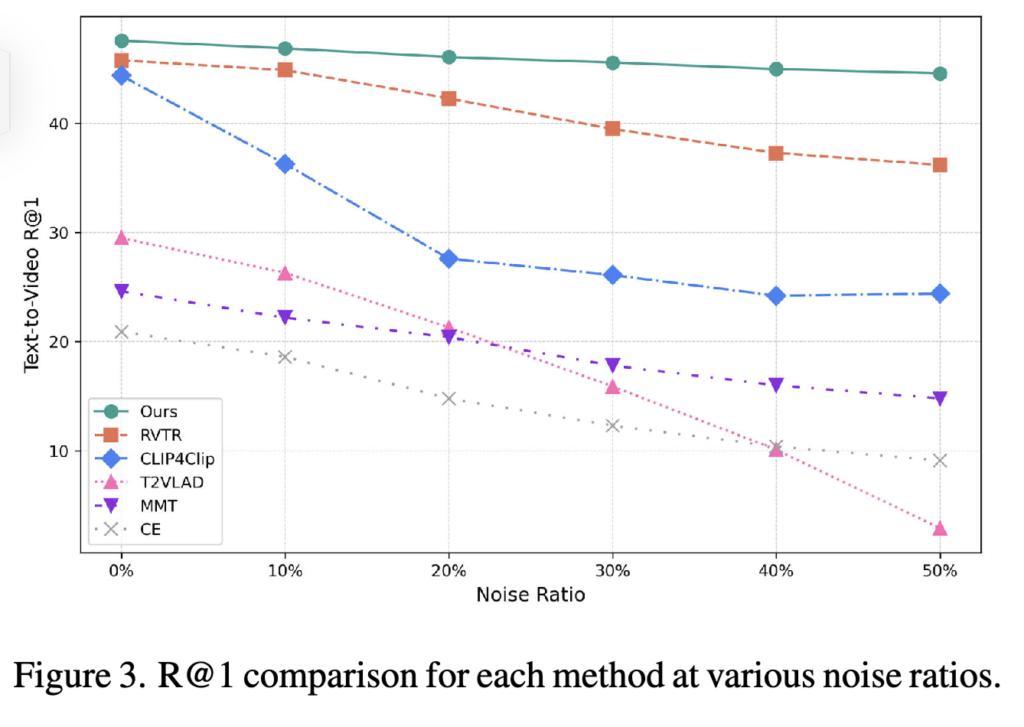
Fig. 3에서 확인할 수 있듯이, noise 비율이 증가해도 제안한 방법은 다른 모든 기법보다 높은 R@1 성능을 유지하였습니다. 성능 감소폭 가장 작아, 제안한 방법이 높은 안정성과 noise 저항성을 가지는 것을 확인하였습니다.
3.3. Ablation Study
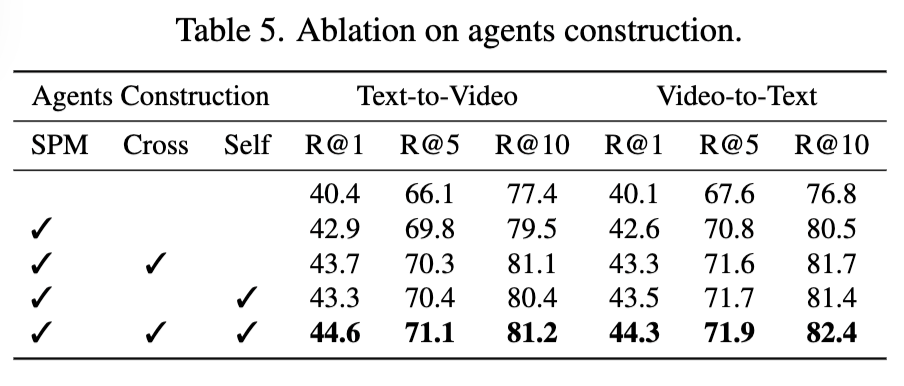
Table 5는 1번째 과정인 agnet 설계에 대한 ablation study 입니다. 저자가 제안하는 2번째 과정인 relation-aware alignment만 적용해도 기존 SOTA를 능가했고, 이후 semantic purification 도입 시 R@1이 2.5 증가, cross-aggregation 도입 시 0.8 증가, self-aggregation 도입 시 추가로 0.9 향상되었습니다. 각 모듈이 정확한 유사도 계산, 다양한 의미 흡수, 모달리티 간 간극 해소에 기여했기 때문이라고 합니다.
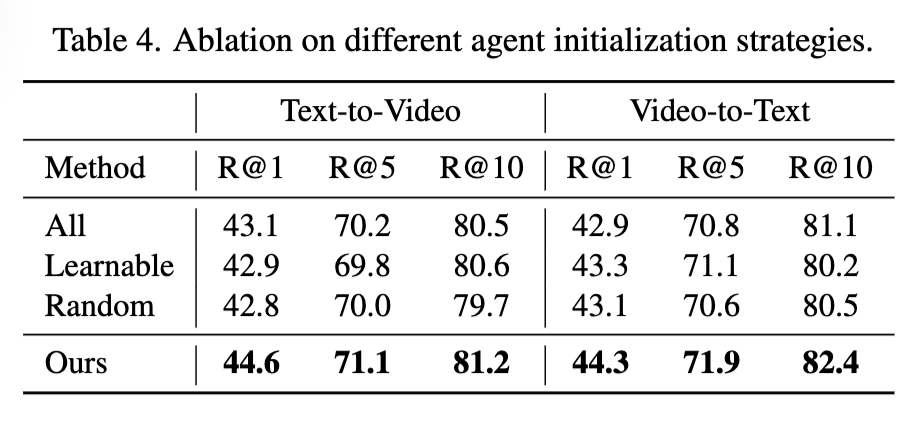
Table 4에서는 다양한 agent 초기화 방식을 비교하였습니다. agent를 잘 설계하였는지를 확인할 수 있는 부분인데요. 모든 쌍을 사용하는 방식(All), 무작위 선택(Random), 학습 가능한 임베딩(Learnable)과 비교했을 때, 제안한 양방향 선택 방식이 가장 높은 성능을 보였습니다. 이는 더 신뢰할 수 있는 agent를 선택하고, noisy 쌍의 영향을 효과적으로 줄였기 때문이라고 합니다.
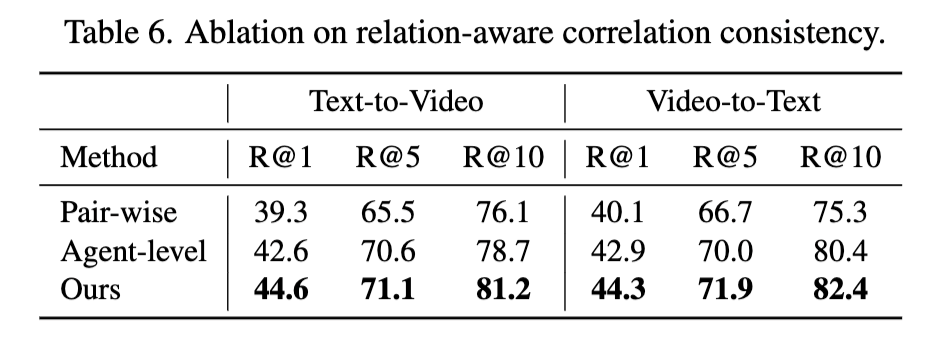
마지막으로 Table 6에서 다양한 정렬 방식의 성능을 비교하였습니다. 기존 pair-wise 방식은 잘못된 매칭을 유발하기 쉽고, agent-level 유사도만 비교하는 방식은 agent 간 구조를 반영하지 못했습니다. 반면 제안한 relation-aware alignment는 agent 간 관계를 모델링하여 가장 안정적인 정렬 성능을 보였습니다.
4. Summary
본 논무네서는 비디오-텍스트 검색에서 발생하는 잘못된 쌍(Noisy Correspondence) 문제를 해결하기 위해, 단순한 유사도 계산이 아닌 구조적인 순위 정보를 활용하는 새로운 정렬 방법을 제안했습니다. 핵심은 각 비디오·텍스트가 여러 기준(agent)과 맺는 관계의 순위를 통해 정렬 여부를 판단한다는 점입니다. 실험을 통해 제안한 방법은 다양한 데이터셋과 노이즈 환경에서 기존 방법보다 더 높은 정확도와 안정성을 확인하였습니다. 실제 학습 데이터에서의 오류를 고려하여, 구조적으로 노이즈를 걸러내서 학습하는 방식을 찾아낸 것이라고 정리할 수 있겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
질문이 몇가지 있어 댓글 남깁니다
여러 개의 대표 기준이 agents라고 정의된 것 같은데, 해당 단어가 익숙하지 않아서 *concept과 같은 개념으로 이해하면 될까요?
*concept: 이미지 분류 문제에서 카테고리가 아닌, 카테고리에 속한 작은 개념 (ex “새” 클래스의 “날개”)
또한 agents의 경우 사람이 직접적으로 이해할 수 있는 개념이 아니고 자동적으로 생성되는 feature 공간상의 하나의 중심으로 이해하면 되는지 궁금합니다.
Semantic Purification 단계에서 프레임, 텍스트 시퀀스 별로 임베딩된 특징량의 유사도 계산을 통해, 유사도가 낮은 특징량은 제거하는 방법으로 이해했는데요, 해당 방법은 유사성이 떨어지는 시간의 정보를 제거할 수 는 있지만, 아예 aligne이 되지 않는 경우 특정 모달리티 전체가 누락되게 되는 방식으로 동작하게 되는지 궁금합니다.
감사합니다
안녕하세요, 댓글 감사합니다.
Q1. Agent가 익숙하지 않은 개념인데, concept과 비슷하게 이해해도 될지? 사람이 해석 가능한 단위인지, 아니면 feature 공간상의 중심점 정도인지?
-> Agent는 concept과 비슷하다고 할 수 있습니다. 정확히 말하면, 사람이 해석 가능한 단어/개념(ex: ‘날개’) 수준은 아니고, 학습된 feature space 내의 대표적인 anchor 혹은 기준점에 가깝습니다. 본 논문에서는 agent를 직접 사람이 지정하지 않고, 학습 데이터 내에서 신뢰도가 높은 비디오-텍스트 쌍을 골라 자동으로 구성하는 것이죠
Q2. Semantic Purification은 유사도가 낮은 특징량을 제거하는 방식인가? 만약 프레임과 문장이 전혀 align되지 않으면 한쪽 modality 전체가 제거되진 않는지?
-> 네 맞습니다. Semantic Purification은 각 프레임-단어 간의 유사도를 계산한 뒤, 의미적으로 맞지 않는 쌍을 가중치를 줄입니다. “특정 모달리티 전체가 누락”되는 일은 이 weight 값이 엄청나게 작아지면 가능할 수 있겠으나, 이게 완전히 0이 되어버리진 않기 때문에 완전히 제거라기보단 학습에 영향이 덜 가도록 완화하는 정도까지 가지 않을까 싶네요
안녕하세요 주영님 좋은 리뷰 감사합니다.
Agent는 특정 데이터셋에서 구성되는 것 같은데, 만약 다른 새로운 데이터셋에 적용할 경우, 기존 agent를 그대로 사용할 수 있을까요? 아니면 매번 데이터셋에 맞춰 새롭게 학습해야 하나요? 또한, 이러한 agent가 다양한 데이터셋에 일반화될 수 있는 가능성이 있을지 궁금합니다.
댓글 감사합니다.
Q1. Agent는 다른 데이터셋에 그대로 사용할 수 있을까?
-> 일반적으로는 어려울 것 같습니다. Agent는 특정 데이터셋(예: MSR-VTT)에서 해당 도메인과 정렬 관계에 최적인 anchor 역할을 합니다. 따라서 다른 데이터셋(예: LSMDC, ActivityNet 등)은 도메인, 문장, 영상이 모두 다르기 때문에 기존 Agent를 그대로 사용하면 정렬 기준으로 적절하지 않을 것 같습니다
Q2. 매번 데이터셋마다 agent를 다시 학습해야 하나요?
-> 제 생각에는 그럴 것 같습니다. 논문에서도 dataset별 실험을 진행할 때 각각의 데이터셋에서 Agent를 다시 선정하기 때문이죠. 실제로 논문에서 언급한 실험 순서는 (1) 전체 샘플 중 신뢰도 높은 상위 k개의 비디오-텍스트 쌍을 agent로 선택 (2) 또는 학습을 통해 cross-modal 정렬이 좋은 샘플을 중심으로 agent feature 구축
어찌보면 Agent는 ‘한 번 학습해서 저장해두는 고정된 개념’이 아니라, ‘각 데이터셋마다 구성되는 기준점’에 가깝다고나 할까요. 해당 논문의 한계라고 할 수 있을 것 같습니다. 그렇기 때문에 아직 이 방법론 만으로는 일반화 까지는 어려울 것 같습니다