안녕하세요, 68번째 x-review 입니다. 이번 논문은 arXiv 2025년도에 올라온 Depth Anything with Any Prior라는 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
monocular depth estimation(MDE)에서 얻는 depth는 dense하고 정확한 정보를 제공하지만, relative한 depth라는 한계가 있습니다. 반면에 SfM이나 depth 센서에서 얻는 depth는 metric하지만 노이즈가 많고 굉장히 coarse한 정보라고 할 수 있습니다. 이 두 depth의 관계를 이용하여 본 논문에서는 prior-based MDE라고 해서, RGB 이미지와 raw한 depth prior를 가지고 정확한 metric depth를 얻을 수 있는 방법을 제안합니다. 여기서 depth prior는 여러 방식으로 얻을 수 있는 depth 값으로 정의하며, 여러 depth를 예측하는 task를 통합할 수 있도록 하였습니다. 이 때 아래 4개와 같이 depth prior의 종류를 명확하게 정의하고 있습니다.
(1) Sparse points (depth completion)
depth completion의 입력으로 쓰이는 sparse depth는 보통 LiDAR 센서로 얻게 되는데, 이는 3D reconstruction이나 자율 주행 scene을 표현하는데 필요합니다.
(2) Low-resolution (depth super-resolution)
저전력 ToF 카메라는 보통 모바일 폰에서 사용되는데, 저해상도의 depth map을 찍을 수가 있다고 합니다. 그래서 depth super-resolution은 휴대용 장치에서의 VR이나 AR 등을 위해 필요한 task 입니다.
(3) Missing areas (depth inpainting)
두 개의 시차가 다른 이미지에서의 스테레오 매칭이 실패하거나 하는 경우, depth map에서 누락되는 영역이 크게 발생할 수 있습니다. 이러한 영역을 채우는 것은(inpainting) 3D scene을 생성하거나 edting하는 경우에 필수적이라고 볼 수 있죠.
(4) Mixed prior
위에서 3개로 prior를 정의했지만, real world에서는 서로 다른 depth prior가 동시에 발생할 수 있습니다. 가령, structured light 카메라는 흔히 저해상도와 누락된 영역이 동시에 발생하는 depth map을 만들게 됩니다. 그래서 여러 케이스의 depth prior가 동시에 발생하는 경우를 다루기 위해 이렇게 Mixed prior라고 추가 정의하였다고 합니다.
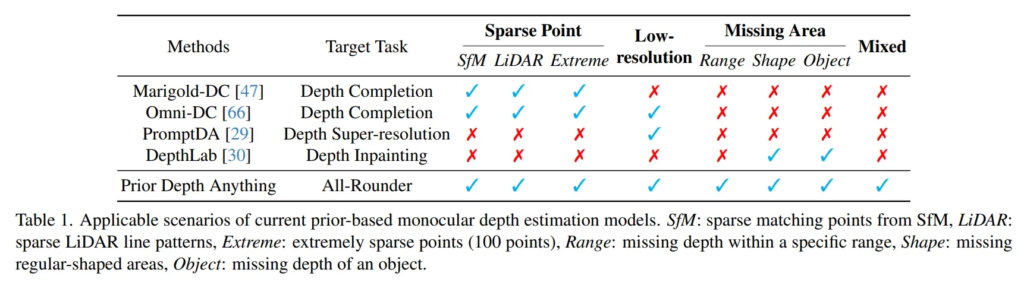
위의 Tab.1을 보면 sparse point에서도 얻는 방식에 따라 추가적으로 분류를 하였고, missing area도 누락된 요소에 따라 세부 정의를 해놓은 것을 알 수 있습니다.
추가적으로 Methods는 depth completion 등, 위에 depth prior 정의에서 언급한 task들을 다루는 연구들을 의미합니다. 이야기 하고자 하는건, 이전에는 각 방법론들마다 굉장히 제한된 prior만을 이용하여 연구를 해왔고, 이는 다양한 real world 시나리오에서의 사용을 어렵게 만든다는 것 입니다. 보면 depth copmpletion을 위한 Marigold-DC는 sparse point만을 이용하고, depth inpainting을 위한 DepthLab은 missing area 종류만을 이용하고 있죠.
그래서 본 논문에서는 Fig.1에서 보여주는 것처럼, MDE를 통해 예측한 depth map과 위의 prior, 즉 측정된 depth 간의 상호 보완적인 점을 이용해서 Prior Depth Anything을 제안합니다. 자세한 방법론은 뒤에서 알아보도록 하며, 어쨌든 이 prior depth anything을 7개의 데이터셋에서 평가했을 때 단일 모달 내에서 zero shot depth completion, super resolution, 그리고 inpainting을 모두 달성할 수 있는 것을 확인하였다고 합니다.
이러한 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 모든 depth prior에 대해 완전한 metric depth를 추정할 수 있는 통합 프레임워크인 Prior Depth Anything 제안
- depth prior를 보완하여 채워넣기 위한 coarse metric alignment를 설계하여 다양한 유형의 depth prior 사이의 차이를 좁히고 일반화 강조
- depth 측정에 있어서 내재하는 노이즈를 줄이기 위해 fine structure refinement 설계
2. Prior Depth Anything
인트로에서도 말씀드렸듯이, MDE는 dense한 relative depth를 예측할 수 있고, 반면 depth 센서로 취득하는 depth들은 metric하지만 내재된 노이즈와 누락되는 영역이 발생합니다. 그래서 두 depth의 상호 보완적인 점을 활용할 수 있는 prior depth anything을 제안하고 있습니다.
2.1. Preliminary
RGB 이미지 I \in \mathbb{R}^{3 \times H \times W}와 이에 대응하는 metric depth prior D_{prior} \in \mathbb{R}^{H \times W}가 입력으로 들어가고, 출력으로는 metric depth map D_{output} \in \mathbb{R}^{H \times W}가 나옵니다.
여기서 통합된 프레임워크로 다양한 prior를 처리하기 위해 D_{prior}에서 유효한 값을 가지는 위치 좌표를 P = \{x_i, y_i\}^N_{i=0}으로 동일하게 표현합니다.
2.2. Coarse Metric Alignment
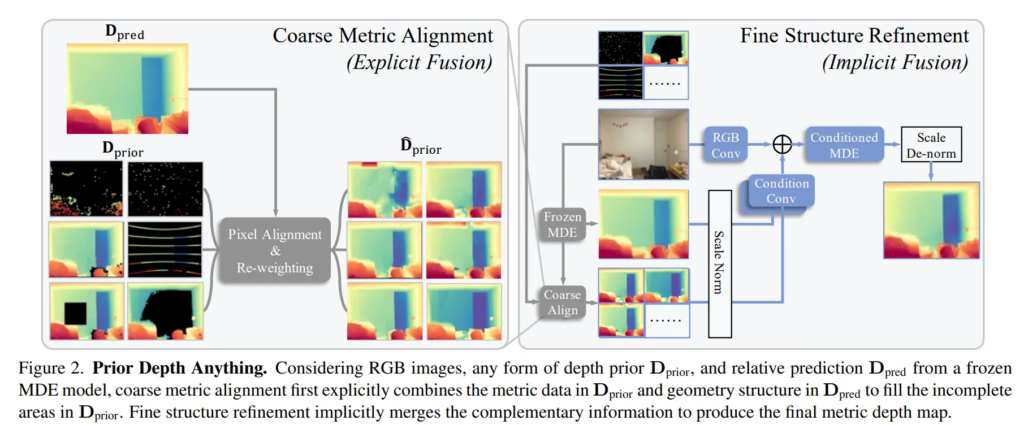
앞선 depth prior 종류를 봐도 알 수 있듯이 형태가 모두 제각각인데, 하나의 모델이 다양한 형태를 공통적으로 잘 처리하기가 어렵고, 이는 일반화 성능의 저하로 이어집니다.
이를 해결하고 싶은데, 기존의 interpolation 방식은 기하학적인 정보가 무시되어 결과적으로 비현실적인 구조를 만들 수가 있습니다. 또 다른 global alignment 방식은 MDE 모델의 예측 결과를 이용해서 prior와 스케일을 맞추게 되는데요, 전체적인 형태를 유지할 순 있지만 왜곡된 거리 정보를 가질 수가 있습니다.
이를 해결하기 위해서 pixel-level metric alignment를 제안하고 있습니다.
픽셀 단위로 relative depth와 prior 사이의 alignment를 하는건데요, 즉 픽셀마다 두 depth를 비교해서 스케일과 shift를 계산하는 것 입니다. 이렇게 되면 metric 정보는 유지하면서 interpolation과 달리 구조적인 정보까지 유지할 수 있다는 장점이 있습니다. 게다가 이렇게 하면 서로 다른 형태의 depth prior가 들어오더라도 일관된 형태로 변환할 수 있기 때문에 하나의 모델이 다양한 상황에 대해 일반화할 수 있게 됩니다.
Pixel-level Metric Alignment
alignment에 대해 좀 더 자세히 얘기해보겠습니다.
먼저 사전학습된 MDE 모델로부터 relative depth map D_{pred}를 얻습니다.
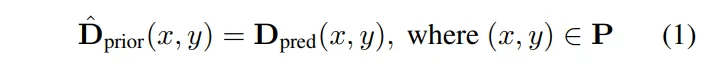
식(1)의 결과인 \hat{D}_{prior}(x,y)은 우선 유효한 픽셀에 대해서 그대로 기존의 D_{prior}를 사용하는 depth 위치를 의미합니다. 이 때 P가 D_{prior}에서 depth 정보가 존재하는, 즉 유요한 픽셀들의 좌표 집합을 의미하죠.
그 다음에 누락된 픽셀에 대해 채워넣어야 하잖아요. 이렇게 누락된 픽셀은 (\hat{x}, \hat{y})로 표현하는데, 이 픽셀들에 대해서 주변의 K개의 유효한 픽셀 \{x_k, y_k\}^K_{k=1}을 k-NN으로 사용하여 찾습니다.
다음 식(2)를 통해 k개의 유효한 픽셀에서 D_{pred}와 metric depth D_{prior} 사이의 차이를 최소화하는 스케일(s)과 shift(t)를 구하는 과정을 진행합니다.
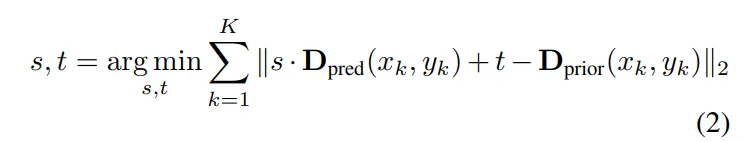
- D_{pred}(x_k, y_k) : k개의 유효한 픽셀들에 대한 relative depth에서의 예측값
- D_{prior}(x_k, y_k) : k개의 유효한 픽셀들에 대한 depth prior의 값
결국 s와 t를 구해서 두 depth 값이 가장 잘 일치되는 조합을 찾는 것 입니다.
가장 잘 맞는 s와 t를 구해서 이제 식(3)과 같이 누락된 픽셀을 채워넣습니다.
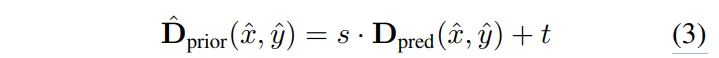
즉, 누락된 픽셀 위치의 relative depth 값을 선형 변환해서 metric depth로 변환하는 것이죠. 이렇게 하면 relative depth 본래의 형태는 유지하면서 주변 metric 정보로부터 실제의 depth 값으로 align 맞출 수 있게 됩니다.
Distance-aware Re-weighting
위의 pixel alignment 과정을 생각해보았을 때 두 가지 한계가 존재합니다.
먼저 인접한 위치에서 누락된 두 픽셀이 서로 다른 k개의 이웃 픽셀을 활용할 수도 있는데, 이렇게 되면 두 픽셀 간의 depth 값이 갑자기 달라질 수가 있어서 depth map이 마치 뚝뚝 끊긴 것 처럼 부자연스러워질 수 있습니다.
두번째는 위의 alignment 과정에서는 모든 이웃에 동일한 가중치를 주고 있습니다. 하지만 실제 depth 관계를 생각해보면 가깝게 있는 픽셀에 더 높은 신뢰도를 주어야 하는 경우가 많습니다. 멀리 있는 픽셀은 가장 가까운 k개를 찾는 것 이기 때문에 자칫하면 노이즈가 많거나 조금은 멀리 떨어져 있는 픽셀이 들어가서 context한 정보가 달라질 수 있습니다.
이 두 개의 한계를 보완하기 위해 제안하는 것이 distance-aware weighting 입니다.
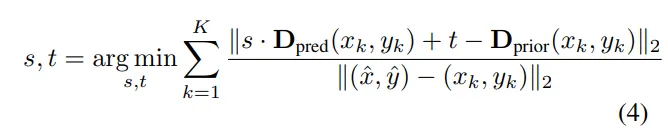
식(2)에서 바뀐 수식이 식(4)인데요, 분모에 픽셀 간의 거리가 들어가게 됩니다. 거리 계산을 해서 가까운 이웃 픽셀일수록 가중치가 커져서 더 많이 반영하고, 반대로 멀리 있는 이웃은 가중치가 작아져서 반영하는 정도가 적어지는 것 입니다.
이렇게 추가적인 처리를 해주어서 depth map 결과가 부드럽고 자연스럽도록 할 수 있도록 하고, 특히 depth prior 정보가 sparse하더라도 가까운 픽셀을 무조건적으로 찾아서 계산하기 때문에 효과적이라고 합니다.
2.3. Fine Structure Refinement
앞선 2.2 섹션에서 만든 depth map을 coarse depth map이라고 표현하는데요, 이는 전체적으로 정확한 metric 정보를 잘 반영한다고 볼 수 있습니다. 거리 자체는 신뢰할 수 있지만, 구하는 방식이 모델이 학습한게 아니라 수식적으로 계산된 것이죠. 그래서 depth prior에 노이즈가 섞이게 되면 그대로 alignment 과정에 포함이 됩니다. 특히 엣지가 흐릿하게 취득이 돼버리면 그 노이즈한 픽셀이 주변 누락된 영역의 참고 픽셀로 포함이 되어서, 넓은 범위의 영역에 잘못된 depth 값을 전달할 수도 있습니다.
이를 해결하기 위해 본 논문에서는 MDE를 또 한번 활용하고자 합니다.
대신, 이전과 다르게 수식적으로 보정하는게 아니라 학습을 통해 노이즈를 알아서 refinement 할 수 있도록 유도하려 합니다.
Metric Condition
\hat{D}_{prior}를 기존 MDE 모델의 추가 입력으로 사용하는데, 이를 condition이라고 지칭합니다. 이는 단순히 RGB 이미지만 입력하는게 아니라 여기에 metric 정보가 있는 depth map도 같이 입력으로 넣어서 모델이 더 정확하게 depth를 예측할 수 있도록 하는 것이죠.
RGB 이미지 정보를 바탕으로, \hat{D}_{prior} 안에 있는 노이즈나 오류를 보정하는 법을 학습합니다. 이를 위해, RGB 이미지 입력과는 별개로, \hat{D}_{prior}를 입력으로 넣는 별도의 condition용 컨볼루션 레이어를 추가합니다. 이 레이어는 처음에는 가중치를 모두 0으로 초기화를 합니다. 왜냐하면, 처음 학습을 시작하는 시점에는 사전학습된 MDE 모델이 가진 RGB 기반의 depth 예측 능력을 그대로 유지하기 위함 입니다. 즉, \hat{D}_{prior}가 없는 것처럼 처음에 시작하면서 이후 학습 과정에서 점차적으로 \hat{D}_{prior}의 정보를 학습에 합쳐서 사용할 수 있도록 합니다.
Geometry Condition
이 부분이 특이한데, \hat{D}_{prior}뿐만 아니라, 추가로 D_{pred}도 같이 입력으로 넣어준다는 것 입니다. 이건 처음에 freeze된 MDE 모델로부터 생성한 결과이잖아요. 이걸 또 condition 입력으로 추가해서 coarse하게만 보완된 prior depth가 가진 구조적인 왜곡을 보정하는데 도움을 준다고 합니다. 이 depth에 대해서도 새로운 컨볼루션 레이어를 이용하고, 동일하게 초기값 0으로 설정해서 학습 초기에는 영향을 주지 않습니다. Metric Condition과 Geometry Condition은 공통적으로 기존 RGB 기반 MDE 모델의 능력을 방해하지 않으면서 학습에 점차적으로 두 condition의 정보를 활용하는 것을 목적으로 합니다.
Synthetic Training Data
원래 사용되는 depth 센서로 측정된 데이터셋은 두 가지 문제를 가지고 있습니다
엣지 부분이 분명하지 않은 값을 가지고 있고, 투명하거나 반사되는 물체에 대해 표현되지 못한 픽셀 영역이 존재합니다. 이러한 depth를 학습 데이터로 사용하기 때문에 학습에 노이즈로 적용될 수 있죠.
그래서 본 논문에서는 정확하고 dense한 GT 값이 제공되는 합성 데이터(Hypersim, vKITTI)를 학습에 사용합니다. 이 GT에 인위적으로 여러 형태의 depth prior를 생성합니다. 예를 들어, 랜덤으로 일부 픽셀만 남겨서 sparse depth를 표현하거나, 사각형의 블럭 형태로 누락되는 영역을 생성하여 missing area를 표현하기도 합니다. 추가적으로 현실적인 상황을 또 반영하기 위해서, 만든 합성 prior에 노이즈도 추가한다고 합니다. outlier를 위해 랜덤으로 말도 안되는 depth 값을 넣거나, 엣지 주변에 노이즈를 추가하기도 합니다. 사실 이 부분은 의도는 알겠으나, 원래 노이즈로 적용될 수 있는 학습 데이터를 보완하기 위해 합성 데이터를 사용하는데 다시 노이즈를 추가하는 게 효과가 있을까 생각이 들긴 했습니다. 그치만 전체적인 학습 정확도는 높이면서, 그럼에도 실제 센서에서 자주 발생하는 문제를 학습에 반영하려는 의도였다고 이해하였습니다.
3. Experiments
3.1. Experimental Setting
실험에서 목적은 metric depth map을 zero shot 방식으로 모든 이미지와 모든 형태의 prior에 대해 생성하는 것 입니다. 다양한 환경에 대해 평가하기 위해, 7개의 real world 데이터셋에서 평가를 진행하였습니다.
그리고 비교하는 베이스라인 모델은 두 가지 타입의 방법론들을 사용합니다.
(1) post-aligned MDE
- 해당 모델들은 RGB 이미지만 입력으로 사용해서 relative depth를 예측하고, 그 다음에 별도로 스케일을 맞추는 과정을 통해 metric depth로 보정하는 방식들 입니다.
- Depth Anything v2, Depth Pro
- 학습 중에 depth prior를 사용하지 않고 inference 결과를 후처리를 통해 metric depth로 맞춥니다.
(2) Prior-based MDE
- 해당 모델들은 depth prior를 입력으로 받아서 depth map을 보완하거나 inpainting, 그리고 super-resolution하는 방식 입니다.
- Omni-DC, Marigold-DC, DepthLab, PromptDA
- prior의 정보를 활용해서 metric depth를 예측하지만 보통 특정 task 하나에 최적화 되어 있습니다.
3.2. Comparison on Mixed Depth Prior
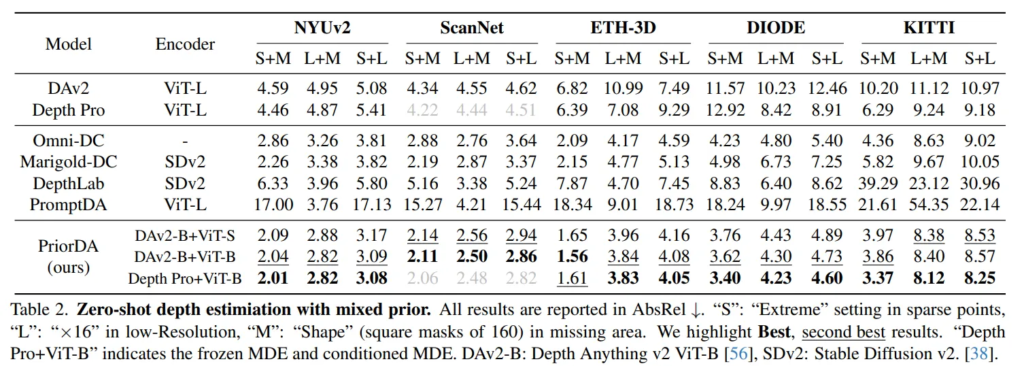
우선 Tab.2는 mixed prior, 여러 depth prior가 섞여 복잡하고 새로운 prior가 주어지는 상황에서도 잘 작동하는 지를 정량적으로 평가한 결과 입니다.
++ mixed prior의 유형(S+M, L+M 등등)은 캡션을 참고해주시면 좋을 것 같습니다.
priorDA의 여러 버전은 다른 베이스라인 모델들과 비교했을 때, 가장 좋은 성능을 보이는 것을 알 수 있습니다. (메트릭은 AbsRel 입니다.)
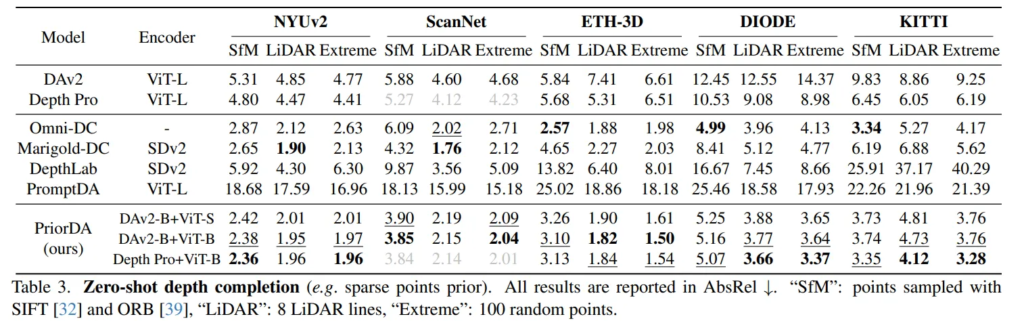
추가로 Tab.3을 봤을 때, 이는 depth completion의 sparse depth의 종류를 세분화하여 평가한 결과 입니다. 이 Tab.3에서의 NYUv2 데이터셋에 대한 PriorDA의 성능과 Tab.2의 S+M, S+L 결과를 비교해보겠습니다. mixed prior가 되었을 때 성능이 저하되긴 하지만 그 정도가 크지 않은 것에 반해, Omni-DC나 Marigold-DC는 성능 저하가 더 크게 나타나면서 복잡한 prior 상황에 취약한 것을 알 수 있습니다.
이러한 결과를 통해 본 논문의 방법론이 다양한 prior가 나타나는 복잡한 상황에서도 안정적으로 동작할 수 있으며, real world에 강인한 모델임을 보여주고 있습니다.
3.3. Comparison on Individual Depth Prior
Zero-shot Depth Completion
이제 각 task에 대해서도 성능을 평가한 결과 입니다.
우선 Tab.3은 depth completion 결과로, depth가 매우 sparse한 상황에서의 성능까지 같이 보여주고 있습니다. (Extreme)
Omni-DC와 Marigold-DC는 depth completion만을 위한 모델인데요, 성능은 좋지만 보통 이러한 모델들은 추론 속도가 느리고 연산량이 많아서 실시간 어플리케이션을 위해서는 비효율적일 수 있습니다. 그에 반해 PriorDA는 간단하게 relative depth와 prior의 align을 맞추고 여러 task로의 확장성을 가지고 있죠.
이 정도의 분석을 하는 이유는 아무래도 성능이 PriorDA가 일관되게 좋은 성능을 보이고 있지 않아서 속도나 효율적인 측면에 대해 어필하고 있는 것 같습니다. 다만 속도와 같은 효율성에 대한 리포팅은 있지 않네요 ..
Zero-shot Depth Super-resolution
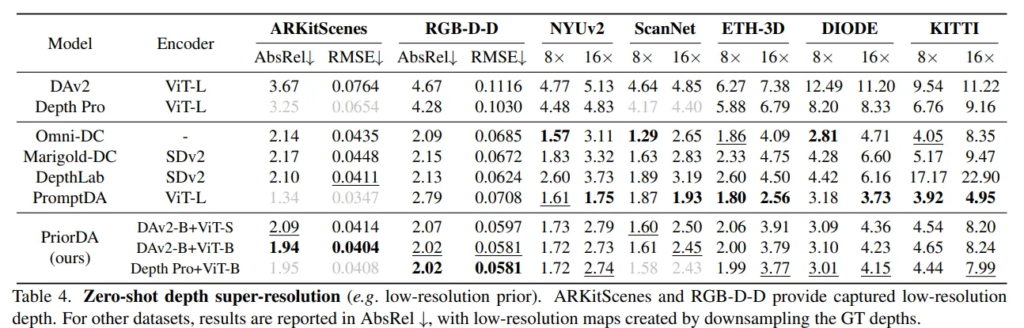
다음 Tab.4는 super-resolution에 대한 결과 입니다.
NYUv2나 ScanNet 등에서는 원래의 GT depth를 인위적으로 다운샘플링하여 저해상도의 데이터를 생성한 다음에 평가하는데, 이러한 방식은 실제 노이즈나 블러링 정도보다 GT의 세부적인 구조를 그대로 보존하여 모델이 복원하기에 더 쉬운 경향성을 보인다고 합니다.
그래서 해당 실험에서는 단순 다운샘플링이 된 데이터보다는 실제 저해상도의 카메라로 촬영된 ARKitScenes와 RGB-D-D로 평가하였다고 합니다.
이런 실제 노이즈나 엣지의 불완전함을 포함하고 있기 때문에 모델의 진짜 복원 능력을 평가할 수 있는데, 이런 데이터에 대해서 기존의 zero-shot 방법론들보다 좋은 성능을 보이고 있습니다. 이를 통해 real world의 저해상도 공간에 대한 super resolution에서도 역시 강인한 모델임을 보여주고 있습니다.
Zero-shot Depth Inpainting
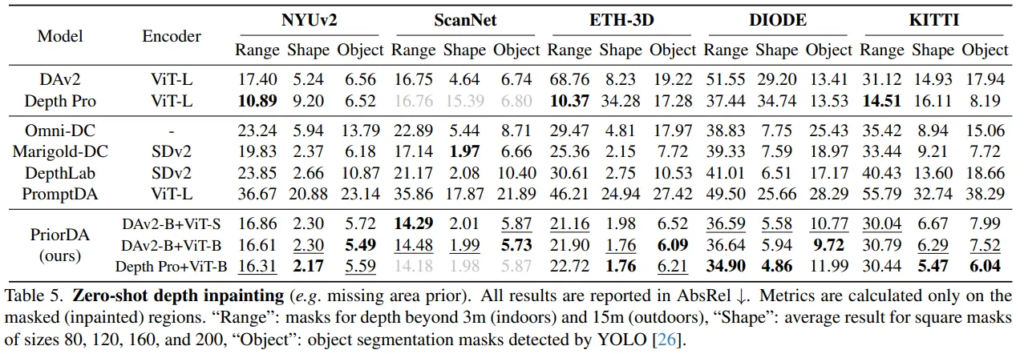
Tab.5는 Depth inpainting에 대한 결과 입니다.
여기서 특히나 실제 상황에서 자주 발생하는 “Range” 세팅에서 PriorDA가 전체적으로 좋은 성능을 보이고 있는데요, DepthPro와 유독 성능 차이가 크게 발생하는 부분에 대해서 별다른 분석이 없어서 조금 아쉬운 것 같습니다.
이 부분 외에는 사각형 형태나 물체에 대해 누락된 케이스에 대해서까지 모두 포함해서 전반적으로 이전 방법론들 대비 개선된 성능을 보이고 있습니다. 이를 통해 본 논문의 방법론이 단순하게 빈 부분을 채워넣는 것을 넘어서 더 확장된 task에 적용할 수 있는 성능을 가지고 있다고 이야기합니다.
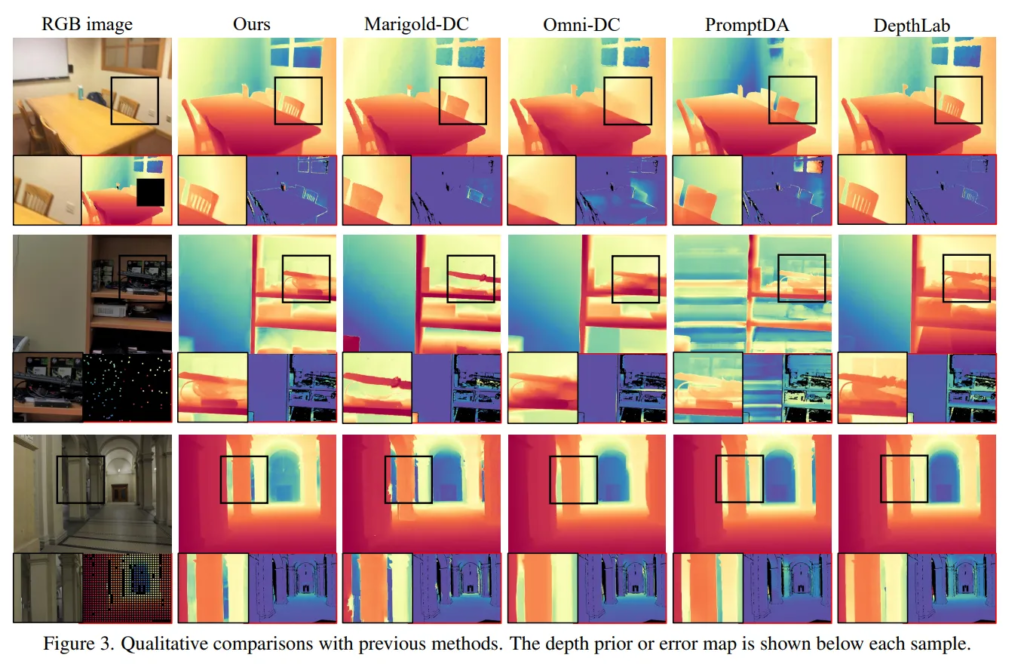
Fig.3은 정성적 결과인데, 간단하게 본 논문의 모델이 이전 방법론들에 비해 일관되게 정확한 depth를 표현하고 있네요. 검정색 사각형으로 강조한 부분을 보면, 엣지는 더 명확하게 표현하고 디테일한 부분을 잘 예측하고 있는 것을 알 수 있습니다.
3.4. Ablation Study
Accuracy of difference pre-fill strategy
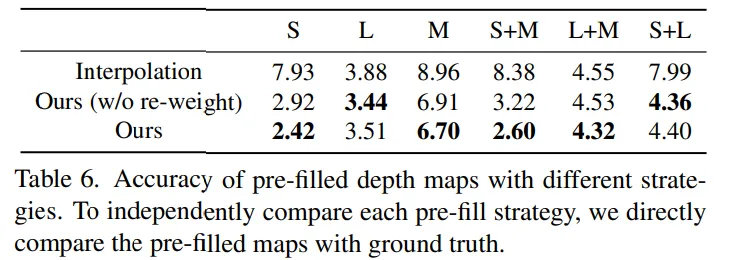
Tab.6은 ablation study에서 depth를 pre-fill하는 방식의 효과를 보여줍니다.
pixel level의 metric alignment를 사용한 방식은 기존의 단순한 interpolation 방식보다 모든 실험 세팅에서 더 높은 정확도를 보여주고 있습니다.
이는 단순하게 빈 공간을 채우는게 아니라 relative depth에서 나온 구조적인 정보를 이용해서 빈 공간을 더 정확하게 보완할 수 있기 때문이라고 분석합니다.
또한 추가로 가중치를 가까운 픽셀에 대해 더 부여하는 최종 방식은 성능이 조금 더 향상되는 것을 확인함으로써 alignment 방법이 전체 모델 성능에 긍정적인 영향을 준다는 것을 알 수 있습니다.
Effectiveness of fine structure refinement
그 다음은 fine structure refinement 단계의 효과를 보여주는 ablation study 입니다.
Tab.6의 coarse한 depth map의 성능과 Tab.2,3,4,5의 최정 성능을 비교해보겠습니다.
refinement를 거친 최종 성능이 크게 향상되는 것을 알 수 있는데, 가령 sparse point에서는 2.42 → 2.01로 향상, low-resolution에서는 3.51 → 2.79로 개선됩니다.
특히나 missing areas는 6.70 → 2.48로 매우 큰 향상이 있엇는데요, 이러한 결과는 refinement는 단순하게 거리적인 보완이 아니라서 구조적인 왜곡을 정확하게 보정하면서 기존의 metric 정보를 유지할 수 있음을 입증합니다.
Effectiveness of metric and geometry condition
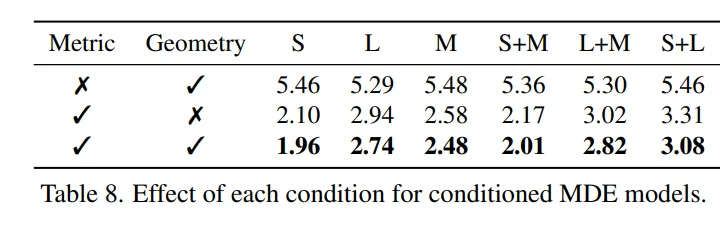
마지막으로 metric, geometric 조건을 활용하는 것에 대한 효과를 보여주는 결과 입니다.
개별적으로 이 depth들을 추가 입력으로 사용했을 때 보다 같이 사용할 때 가장 좋은 성능을 보입니다. 이는 refinement 단계를 단순하게 진행하는게 아니라, metric과 형태적인 정보를 동시에 보완하는 것이 중요하다는 점을 강조하고 있습니다.
즉 하나의 조건만을 사용하는 건 조금 부족하고, 두 조건을 모두 잘 활용해야 모델이 더 정확하고 자연스럽게 depth map을 생성할 수 있다는 것을 실험저으로 보여줍니다.
안녕하세요. 좋은 리뷰 감사합니다.
MDE 모델이 inference 할 때는 RGB 이미지 하나만을 사용하지만, 학습을 할 때는 depth sensor로 취득한 depth map이 입력으로 같이 들어간다고 봤습니다. 근데 지금 추가 학습을 위해서 metric condition과 geometry condition으로 두 depth map이 들어간다고 말씀해주셨는데 원래의 입력 depth map은 사용하지 않는 것인가요 ?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
논문에서 말하는 두 condition은 학습 초반부터 사용하는게 아닌 중간부터 사용되는 형태 입니다. 말씀하신 raw한 depth map은 학습에 사용하지 않으며, 학습 초반에는 rgb only로 학습되다가 중간부터 metric, geometry condition이 입력으로 사용된다고 이해해주시면 좋을 것 같습니다.
감사합니다.
안녕하세요. 리뷰 잘 읽었습니다.
Distance-aware Re-weighting은 가까운 픽셀에 더 가중치를 두어 sparse할 때에도 대응 가능하도록 한다고 이해하였습니다. 그런데 이 이웃이라는 것이 sparse의 수준에 따라 몇 개를 찾아야 좋은지 불명확할 수 있는데요, 예를 들면 sparse하더라도 근처에 이웃픽셀들이 많은 경우와 그렇지 않은 경우가 존재할 것입니다. 그런데 지금처럼 re-weighting을 해주더라도 k라는 고정된 수로만 꼭 해야하나요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀해주신 것처럼 sparse 수준에 따라 사용할 수 있는 최적의 k 수가 달라질 수 있는 건 맞습니다. 이걸 고정된 수로 한 것에 대해 논문에서 따로 얘기한건 없지만, 제 생각에는 고정된 수 만큼의 이웃을 계속 사용하더라도 그 중에서도 가까운 이웃 픽셀에게 더 큰 가중치를 주고 멀리 있으면 적은 가중치를 주도록 설계되어 있기 때문에 모델이 집중하는 정보 자체는 adaptive하게 작동할 수 있게 되어 고정된 수를 사용하는데 크게 무리가 없을 것 같습니다.
감사합니다.