안녕하세요. 두 번째 X-Review로 소개드릴 논문은 RegionCLIP: Region-based Language-Image Pretraining으로 2022년 CVPR에 게재된 논문입니다.
이 논문은 제가 OVOD(Open-Vocabulary Object Detection) 관련 연구들을 처음 접하고 공부하던 과정에서 가장 먼저 읽은 논문인데요. 이전에 리뷰했던 YOLO-World를 공부하기 이전에 Region CLIP이라는 친구를 먼저 접하게 되었는데, 이 친구는 OVOD의 기본 개념과 배경을 이해하고자 했을 때, 좋은 출발점이 되어주었던 것 같습니다. 기존의 Object Detection과는 다르게 OVOD가 어떻게 제로샷 성능을 낼 수 있었는지, 그 흐름을 이해하는 데 큰 도움이 되었기 때문에 리뷰할 논문으로 가져오게 되었고 읽은 지 얼마 안되었을 때 리뷰로 남겨두고자 합니다.
해당 논문의 메서드 파트를 제대로 이해하기 위해서는 CLIP에 대한 기본적인 이해가 필요하다고 생각을 했습니다. 그래서 자연스럽게 CLIP이라는 논문을 접하게 되었고 또 다른 연구원 분들께서 작성해주신 X-review참고하면서 CLIP에 대한 개념을 먼저 익힐 수 있었습니다. 해당 개념들을 가지고 RegionCLIP이라는 논문을 읽는 과정에서도 자연스럽게 CLIP의 구조와 동작 방식에 대한 이해도를 높일 수 있었던 아주 좋은 밑거름이 되는 논문이기에 굉장히 오랫동안 읽었던 것 같습니다.(물론 첫 논문이기도 했습니다..)
아래는 CLIP을 이해하는데 있어서 굉장히 도움이 되었던 리뷰입니다!
http://server.rcv.sejong.ac.kr:8080/2024/08/04/icml-2021-clip-learning-transferable-visual-models-from-natural-language-supervision/
리뷰 시작해보도록 하겠습니다.
Introduction
이 논문이 나올 당시에 CLIP , ALIGN와 같은 모델들이 등장하면서 vision-language 간 학습에 있어서 엄청난 발전이 있었습니다. 특히 CLIP 이라는 친구들은 수억 개에 달하는 이미지-텍스트 쌍을 활용해가지고 이미지와 해당하는 텍스트 캡션을 같은 임베딩 공간상에 잘 매칭이 되도록 학습이 되게 됩니다.(자세한 내용은 앞서 언급한 CLIP 리뷰를 보시면 많은 도움이 될 것 같습니다!) 이는 결과적으로 별도의 수작업 라벨링 과정 없이도 다양한 이미지들을 인식할 수 있고, 학습된 범주 이외의 클래스에 대해서도 어느정도 제로샷 성능을 보여줄 수 있게 되었습니다.
위와 같은 이미지 분류에서 좋은 성능을 보이는 방법론들이 나오면서 자연스럽게 이어지는 질문은 이미지 분류가 아니라 이미지 영역에 대한 추론 즉, 객체 탐지와 같은 태스크에도 해당 방법론을 사용할 수 있는가 입니다.
따라서 저자는 아주 간단한 실험을 하였는데요.
저자는 사전학습된 CLIP 모델을 사용해서 간단하게 R-CNN 스타일의 객체 탐지기를 구성하였습니다.
간단하게 input으로 이미지가 들어오면 이미지에 대해서 후보 객체 영역을 잘라내고 해당 영역들에 대해서 텍스트 임베딩과 매칭해서 CLIP을 기반으로 탐지를 수행하는 실험으로 이해하면 될 것 같습니다.
실험 결과는 아래와 같습니다.
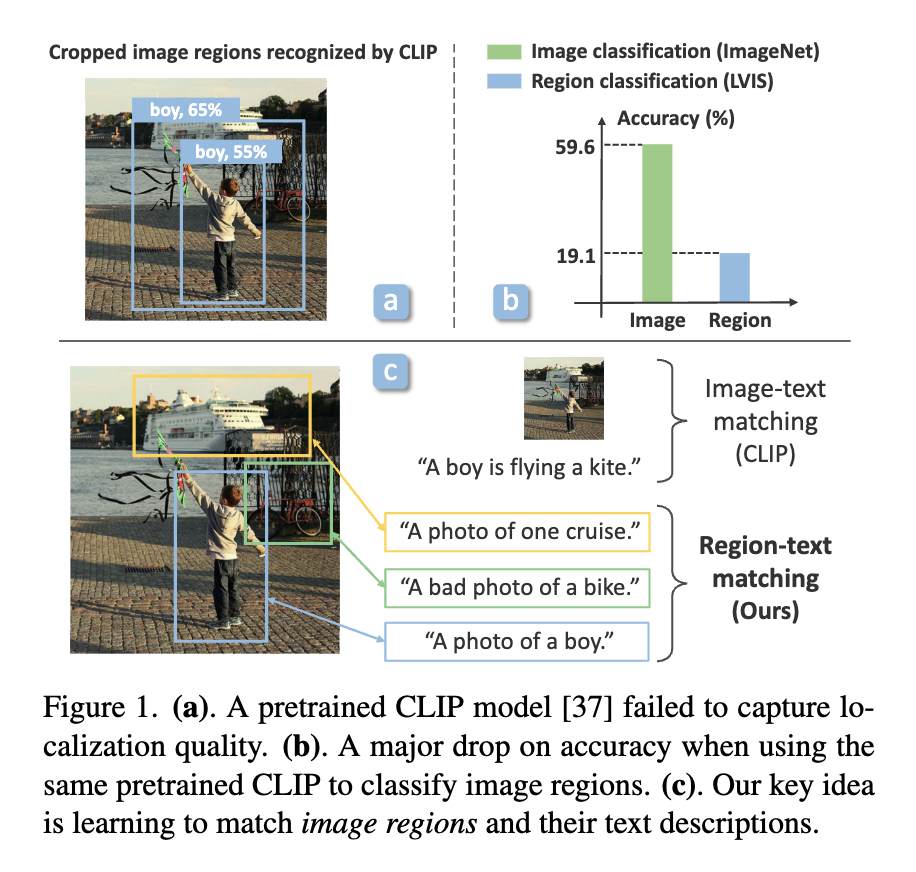
그림 1(a-b)은 LVIS랑 ImageNet 데이터셋 에서의 결과를 보여주는 그림인데요. (a)부분은 CLIP에서 객체 영역을 입력 영역으로 사용할 경우 즉, 사전 학습된 CLIP 모델을 Object Detection 용도로 그대로 적용했을 때 발생하는 문제를 시각적으로 보여줍니다. 좀 더 자세하게 설명을 드리자면 여러개의 객체 영역 후보군들을 특정 이미지 영역(region)으로 잘라내어 그 안에 있는 객체를 인식하도록 그대로 사용하면 (a)그림과 같이 오히려 객체만을 포함한 영역 보다아 주변 context정보까지 포함된 영역이 더 성능이 높기 때문에 localization에 있어서 성능이 좋지 않다는 것을 보여줍니다.
CLIP이 이미지 전체 단위로는 텍스트 매칭이 잘 작동하지만, 이미지 객체 영역에 대해서는 조금 부족하다라는 점을 보여주는 것 같고 (b)에서도 마찬가지로 그에 대한 내용을 표로 설명을 해주고 있습니다. 떠라서 (c)에서는 저자들이 제안하는 핵심 아이디어인 Region-Text Matching 방식을 간략하게 도식화하여, 이미지 전체 수준이 아닌 지역(region) 레벨에서 텍스트alignment를 잘 학습할 수 있도록 하는 방법론을 보여주는 것이라고 생각하면 좋을 것 같습니다.
요약하면 CLIP을 포함한 대부분의 기존 vision-language 모델은 전체 이미지와 이에 대응하는 이미지 수준의 텍스트 설명 간의 매칭을 통해 학습되었는데, 이러한 학습 방식은 지역 이미지 영역과 텍스트 토큰 간의 alignment를 고려하지 않기 때문에 결과적으로 텍스트 개념을 이미지의 특정 영역에 정확히 연결하는 능력이 부족하다 라는 점을 보여준다고 생각하시면 될 것 같습니다.
따라서 image-text쌍에서 나아가 region-text쌍으로 사전학습 시킨 모델을 만들겠다 라는 전략을 이야기 한다고 보시면 될 것 같습니다.
하지만 여기서 저렇게 image-text쌍을 가지고 region-text쌍을 만드는 과정에서 마주하게 될 두 가지 주요 도전 과제(Challenge) 제시합니다.
첫번째는, 이미지 내 개별 객체 영역(region)과 텍스트 단어(token) 사이의 정밀한 정렬 정보가 존재하지 않는다는 점입니다.
기존의 이미지-텍스트 쌍은 보통 전체 이미지와 전체 문장을 쌍으로 갖고 있지만, 이미지 안의 각 영역, 예를 들어 사람, 배, 자전거 같은 객체들이 텍스트의 어떤 단어와 정확히 연결되어야 하는지에 대한 정보는 포함되어 있지 않습니다.
이러한 매칭 정보를 사람이 직접 일일이 만들어주려면 많은 시간과 비용이 소요됩니다.
두 번째는, 이미지에 대한 텍스트 설명이 불완전하다는 점입니다.
하나의 이미지에는 여러 객체와 장면이 존재할 수 있지만, 그에 대한 텍스트 설명은 대부분 일부 장면만 간략하게 언급하는 데 그칩니다.
예를 들어, 앞서 첨부한 표의 사진만 봐도 사진 속에 ‘사람’, ‘배’, ‘자전거’ 등 다양한 객체가 있는데, 텍스트에는 단지 “A boy is flying a kite” 처럼 ‘배’, 나 ‘자전거’가 포함되어있지 않은 문장인 경우가 많습니다. 이처럼 텍스트가 이미지 전체를 충분히 설명하지 못할 경우, 모델은 텍스트에 언급되지 않은 많은 시각 정보들을 학습하지 못하게 되고, 다양한 객체에 대한 표현을 학습하기 어렵게 됩니다.
위와 같은 두개의 문제를 챌린지로 삼으면서 이를 해결하기 위한 RegionCLIP이라는 방법론을 제시하게 됩니다.
해당 방법론을 간단하게 말로 풀어서 설명을 드리자면, 먼저 RegionCLIP에서는 사전학습된 vision-language 모델(CLIP)을 활용하여 이미지와 텍스트 개념 간의 매칭 정보를 활용하는 방식을 사용합니다. 그리고 대규모 텍스트 코퍼스로부터 객체를 나타내는 단어(object concept) 들을 추출한 뒤, 이 object concept들을 “A photo of a {concept}” 와 같은 사전 정의된 문장 템플에 삽입해 영역을 설명하는 텍스트를 생성합니다.
그 다음, 주어진 이미지에 대해 후보 영역들을 생성하고, 각 후보 영역과 앞서 만든 텍스트 설명 사이의 유사도를 CLIP 모델을 통해 계산합니다. 이렇게 하여 가장 잘 매칭되는 텍스트 개념을 해당 이미지 영역에 의사 레이블(pseudo-label)로 할당합니다. 그리고 이렇게 생성된 영역–텍스트 쌍(pseudo region-text pairs)과 기존의 전체 이미지–텍스트 쌍(image-text pairs)을 함께 활용해가지고 대조 학습(contrastive learning)과 지식 증류(knowledge distillation)를 통해 새로운 visual 인코더를 사전학습하게 됩니다.
이제 논문에서 저자가 언급한 3가지 contribution 입니다.
- 수작업 주석 없이 region과 해당 텍스트 설명을 정렬하는 새로운 방법을 제안(앞서 말한 사전학습된 CLIP을 활용해서 수도 라벨 생성)
- 객체 설명과 이미지 영역을 정렬하기 위해 텍스트 프롬프트 기반의 확장 가능한 방법을 제시(앞서 말한 사전 정의된 문장 템플릿)
- 제로샷 객체 탐지 성능
지금까지 introduction을 비교적 자세하게 설명을 드렸는데요. 개인적으로 해당 논문이 초보자인 저에게도 비교적 쉽게 읽혔던 이유 중 하나가introduction에서 말한 것이 region CLIP의 전부라고 봐도 될 만큼 region CLIP의 핵심 아이디어들이 잘 녹아들어있었고, 기존의 문제와 저자들이 제안하는 방법론을 하나하나 풀어서 설명해주기 때문에 전체적인 흐름을 이해하는 데 큰 도움이 된 것 같습니다. 그래서 이 부분에 조금 더 분량을 많이 작성했습니다.
method
이제 실험 부분입니다.
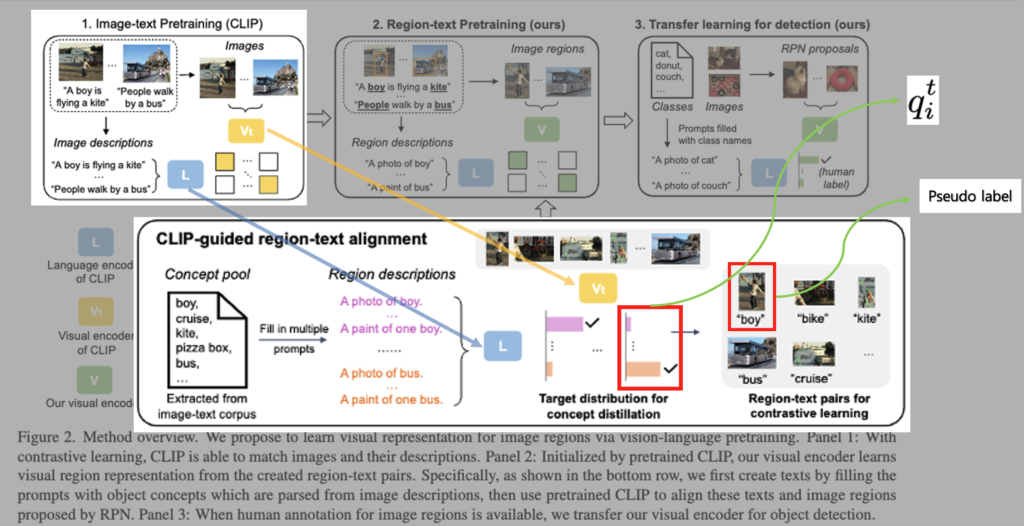
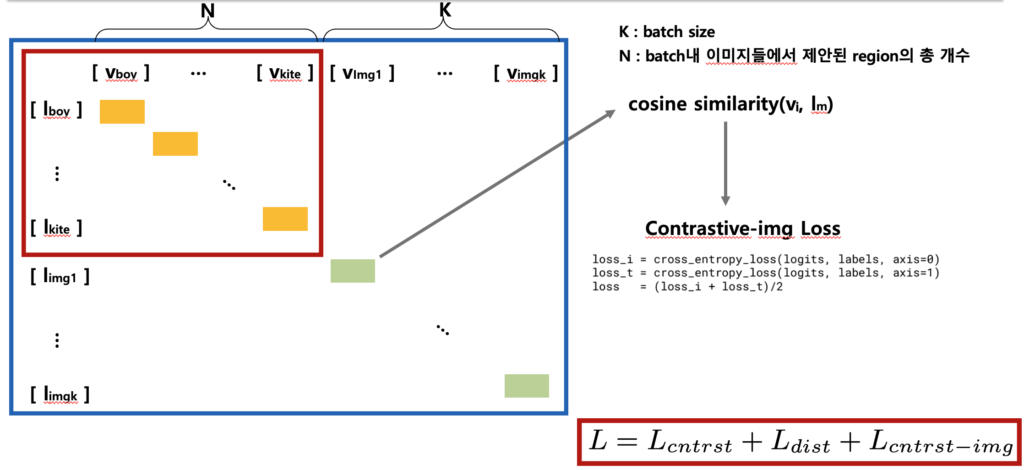
대부분의 이미지-텍스트 쌍에는 region-level에서의 설명이 존재하지 않기 때문에, 먼저 텍스트 코퍼스에서 파싱한 객체 concept(단어) 풀을 구성하고 이를 프롬프트에 삽입하여 region에 대한 설명을 생성해야합니다. 그러고 나서 잘 학습된 CLIP의 visual 인코더 Vt(노랑)를 활용하여 해당 프롬프트와 RPN이 제안한 이미지 영역 간 정렬을 수행하게 됩니다. 이렇게 얻어진 region-text 쌍과 distribution(q_i^t)을 수도 라벨, soft 라벨로 이용해 아래 그림과 같이
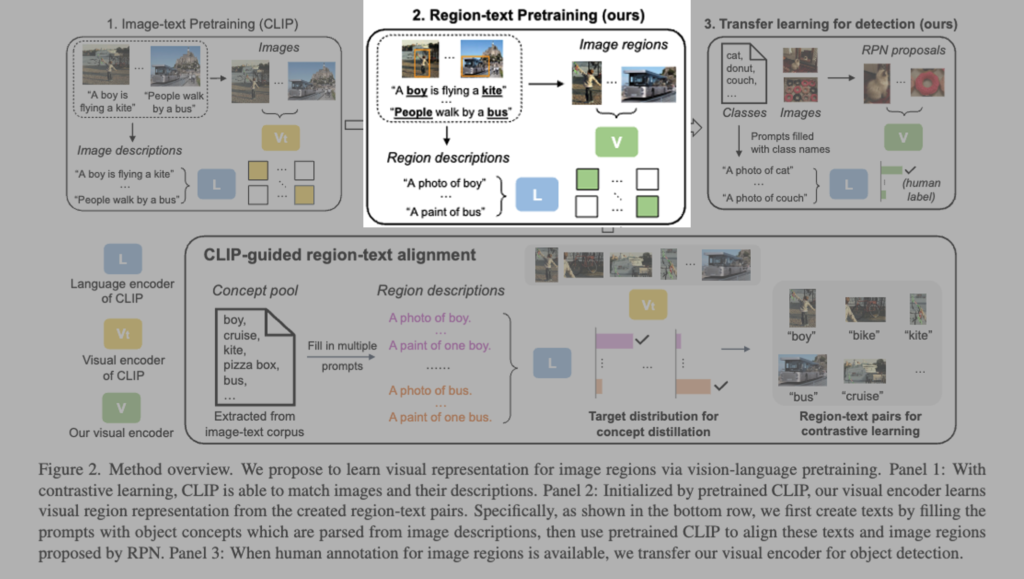
regionCLIP의 visual 인코더 V(연두-ResNet or ViT)를 contrastive learning 과 Knowlegde distillation를 통해 학습하게 됩니다.
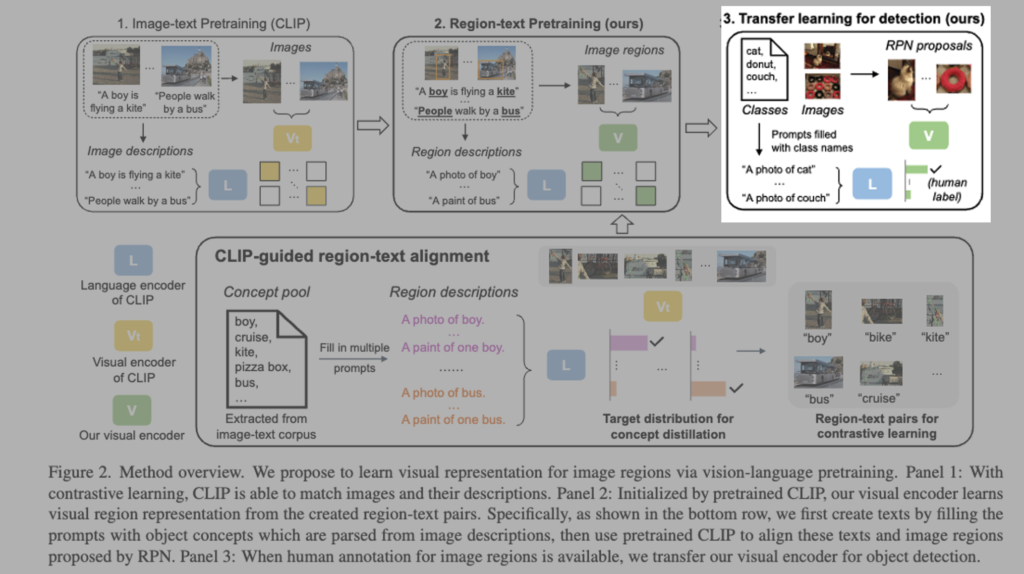
학습이 완료된 후에는, RegionCLIP 의 V(연두)는 사람이 annotation한 label이 있는 경우 객체 탐지기로 transfer learning을할 수 있게 됩니다.
요약하자면 잘 사전학습된 이미지-텍스트 매칭 모델(CLIP)을 기반으로 하는 visual 인코더 Vt(노랑)와 language 인코더 L(파랑)을 가지고, 이미지 영역을 인코딩할 수 있는 새로운 visual 인코더 V(연두)를 사전 학습하여, 해당 영역 표현이 언어 인코더 L(파랑)로 인코딩된 영역 설명과 일치하도록 하는 방식이라고 생각하시면될 것 같습니다.
LOSS
Contrastive Loss : L_{\text{cntrst}}
RegionCLIP의 학습 과정에서는 총 3가지 손실 함수의 합이 최종 Loss로 사용되는데요. 이 중 특히 중요한 두 가지는 Contrastive Loss와 Distillation Loss로 이미지 영역(region)과 텍스트 개념 간 정렬을 학습하는 데 핵심적인 역할을 하게됩니다.
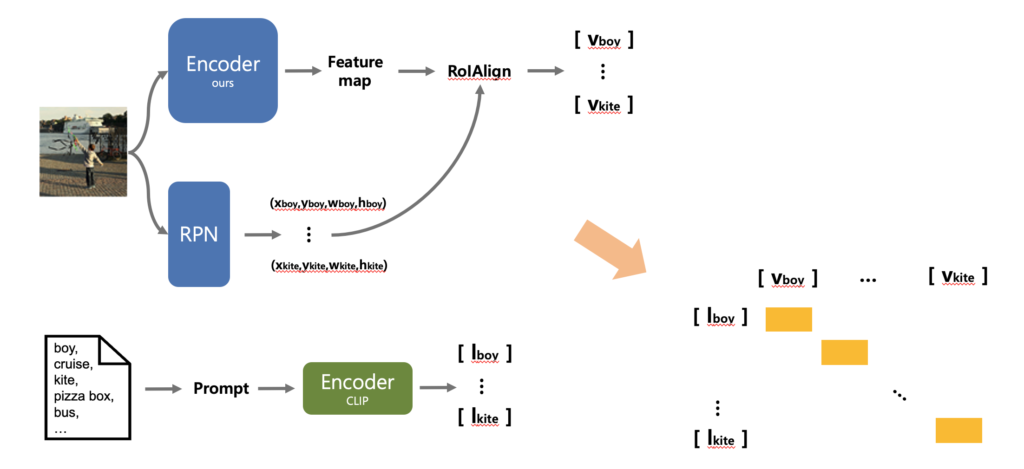
먼저, Method의 두 번째 단계 RegionCLIP의 visual 인코더(연두)를 사전학습시키는 과정에서 Loss가 계산이 되는데요. 이때 visual 인코더를 타고나온 region 임베딩 벡터 v와 CLIP의 language 인코더를 타고 나온 텍스트 임베딩 벡터 l 사이의 코사인 유사도 점수 S(v,l)를 아래 수식처럼 벡터 내적 연산으로 구해집니다.
S(v, l) = \frac{v^\top \cdot l}{|v| \cdot |l|}
계산된 유사도 S(v_i, l_m)는 softmax를 통해 확률 p(v_i, l_m)로 변환됩니다.
p(v_i, l_m) = \frac{\exp(S(v_i, l_m)/\tau)}{\exp(S(v_i, l_m)/\tau) + \sum_{k \in N_{r_i}} \exp(S(v_i, l_k)/\tau)}이 확률을 바탕으로 cross-entropy 기반의 Contrastive Loss가 계산됩니다L_{\text{cntrst}} = \frac{1}{N} \sum_i -\log(p(v_i, l_m))
임베딩 공간상에서 정답인 region–text 쌍이 가까워지도록, 나머지 쌍들과는 멀어지도되도록 학습하게 됩니다.
Distillation Loss : L_{\text{dist}}
앞선 Loss와 함께, CLIP teacher 모델(V_t)(노랑)이 만들어낸 distribution q_i^t을 학생 모델인 RegionCLIP 인코더 V(연두)가 선생과 비슷한 distribution을 output으로 내뱉도록 하는 Distillation Loss도 사용됩니다:
L_{\text{dist}} = \frac{1}{N} \sum_i L_{KL}(q_i^t, q_i)q_i^t: CLIP teacher 모델이 예측한 region–text 분포
q_i: 학생 모델인 RegionCLIP이 예측한 분포
이 손실을 통해 학생 모델은 teacher의 출력 분포를 KL divergence 기반으로 따라가도록 학습됩니다.
Contrastive Loss : L_{cntrst-img}
나머지 한가지는 앞서 바로 넘어간 부분이 있는데,
RegionCLIP의 visual encoder V를 사전학습할 때 region–text 쌍뿐만 아니라, 원본 이미지와 해당 이미지에 대한 text 쌍도 함께 학습에 활용된다는 점입니다.
즉, 모델은 단순히 잘라낸 영역(region)과 텍스트(concept)만을 정렬하는 것이 아니라, 기존 CLIP 방식처럼 전체 이미지와 텍스트 간의 정렬도 병행하게 됩니다. 이때 원본 이미지 – 문장 쌍에 적용되는 손실 함수가 바로 L_{\text{cntrst-img}} 즉, 원본 이미지–텍스트 단위의 contrastive loss입니다.
결과적으로 RegionCLIP에서는 아래의 세 가지 손실 항목을 모두 합쳐 최종 학습하게 됩니다.
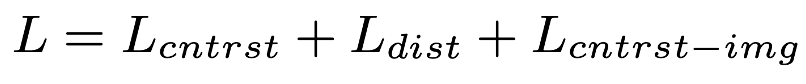
지금까지 글로 설명을 드리긴했는데, 다른 분들이 조금 더 직관적으로 이해할 수 있도록 하고자 ppt로 해당 내용을 플로우형태로 도식화한 그림을 첨부하였습니다.
Experiments
이제 실험 부분입니다.
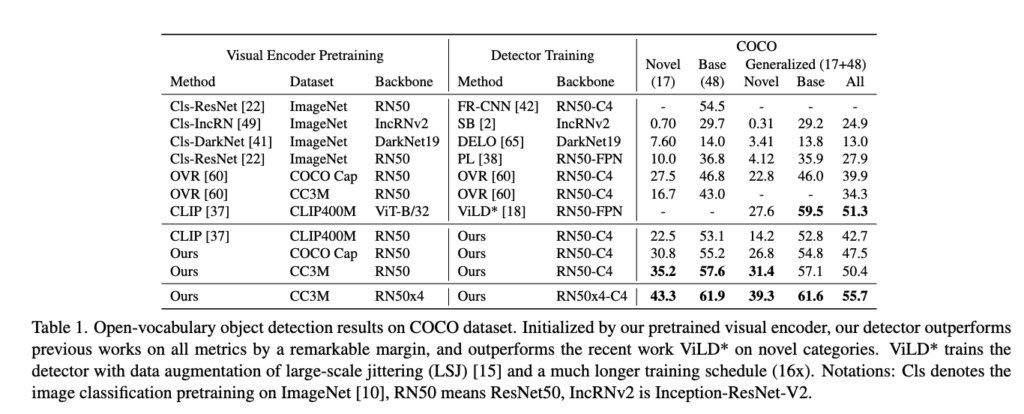
위 Table 1을 처음 접했을 때 정말 이해하기 어려웠던 것 같습니다. 논문에서는 탐지기의 구조나 학습 방식(Detector Training)에 대해 상세히 설명하지 않고, 대신 Visual Encoder를어떻게 사전학습하는지에만 초점을 맞추고 있었기 때문에, detector Training에서의 Method와 Backbone이 어떤 역할을 하는지 직관적으로 이해하기 어려웠습니다.
논문에서는 detector로 Faster R-CNN (C4 혹은 FPN 구조)를 사용한다고만 짧게 언급하고 있지만, 정작 표에서는 ours 라고 표기되어 있어, 단순한 Faster R-CNN이 아니라 RegionCLIP 방식으로 사전학습된 visual encoder를 이 detector에 얹은 구성을 의미하는 것으로 이해하고 넘어갔습니다. 논문 초반intro에서 언급된 바와 같이 기존 CLIP 기반의 객체 탐지기가 이미지 전체 수준의 표현만 학습되어 있어 localization(정확한 위치 인식)에 약하다는 점이 문제였는데, 이 Table 1의 정량 실험을 통해 RegionCLIP이 해당 문제를 효과적으로 개선했음을 확인할 수 있었습니다.
예를 들어, CLIP 기반 ViLD의 zero-shot 성능(Novel)이 27.6인 반면, RegionCLIP은 동일 조건에서 최대 43.3 mAP까지 향상되었고 Generalized mAP(All)도 가장 높은 55.7을 기록한 부분에서 이를 확인해 볼수 있습니다.
결과적으로 이 테이블 표는 다양한 사전학습 기반의 vision 인코더와 detector를 조합하여 COCO 데이터셋에서의 Open-Vocabulary 성능을 비교한 결과를 보여주고 특히 RegionCLIP이 기존 방법들과 비교해 얼마나 성능을 향상시킬 수 있었는지를 정량적으로 보여주는 테이블이라고 보시면 될 것 같습니다.
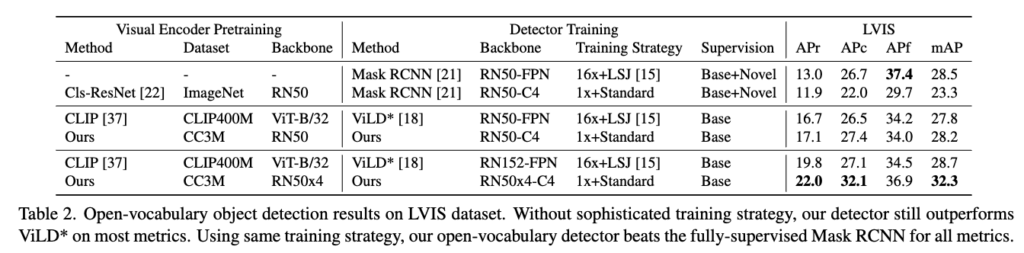
Table 2는 RegionCLIP이 단순히 좋은 성능을 내는 것에 그치지 않고 복잡한 학습 없이도 강력하다 라는 것과 특히 long-tail 분포와, 제로샷 환경에 강한 open-vocabulary detection 모델이다 라는 것을 정량적으로 보여주는 표라고 보시면 될 것 같습니다.
학습 데이터에 base와 novel 클래스 모두가 포함된 fully-supervised 학습한 모델에서 학습 전략이 1x + standard를 Baseline으로 보았을 때, RegionCLIP은 Base만 사용해서 학습한 open-vocabulary 모델임에도 불구하고, 전체 클래스를 모두 사용해 학습한 fully-supervised Mask R-CNN보다도 모든 metric에서 더 좋은 성능을 내는 것을 확인 할 수 있습니다.
RegionCLIP이 ViLD의 iter도 16배 적고 데이터 agumentation도 적은데에 반해서 전반적으로 높은성능을 보이는 것을 확인할 수 있습니다.
안녕하세요 안우현 연구원님 리뷰 잘 읽었습니다.
너무 잘 풀어써주셔서 이해가 잘됩니다.
특히 Introduction 부분에서의 자세한 설명 덕분에 RegionCLIP 논문의 전체적인 흐름을 잘 잡고 이후 글을 읽을 수 있었습니다. 감사합니다.
객체 영역과의 텍스트 매칭에 포커스를 두어 영역 level의 localization 성능을 개선한 연구라고 이해했습니다.
질문이 있습니다. 수도 라벨과 제안된 영역간의 aligning 과정에서 얻어지는 distribution값은 어떻게 나오게 되는 값인지가 궁금합니다.
안녕하세요 지연님 댓글 감사합니다.
질문의 의도가 regionCLIP의 visual encoder를 사전학습시키는 과정에서 텍스트와 제안된 영역간의 aligning 과정에서 얻어지는 distribution값이 어떻게 구해지는지를 묻는 것이라면,
각 region–text 쌍에 대해 코사인 유사도를 계산한 후,
이 유사도 점수들을 softmax를 통해 확률 분포로 정규화 값들이 distribution이라고 보시면 될 것 같습니다!
감사합니다.
안녕하세요 안우현 연구원님 좋은 리뷰 감사합니다.
Distillation Loss에서 KL divergence로 학습한다고 하셨는데, region-level 정보를 teacher로부터 student가 학습하는 것으로 이해했습니다. 학습을 할 때는 crop된 이미지를 학습하는 건가요? teacher는 image regions으로 추출한 feature라고 생각이 되는데, student의 입력이 일반적인 이미지인지, crop된 이미지인지가 궁금합니다. 만약에 crop된 이미지로 학습한다면, 그냥 학습 데이터의 양이 늘어나는 것과 무엇이 다른건지도 궁금합니다.
감사합니다.
안녕하세요 성준님, 댓글 감사합니다.
RegionCLIP에서는 말씀하신 것처럼 teacher의 region-level feature를 기반으로 student가 학습하도록 distillation loss를 설계하고 있습니다. 여기서 중요한 포인트는 student가 입력으로 받는 것이 crop된 이미지가 아니라, RoIAlign을 통해 RPN이 제안한 영역과 인코더를 타고 나온 feature 맵간 RoIAlign을 통해 전체 이미지에서 해당 region에 대응되는 feature를 가지고 학습한다고 보시면 될 것 같습니다!
다시 정리하자면 이미지는 RPN과 encoder에 동시에 들어가게 되며 둘의 output간의 RoIAlign을 통해 제안된 영역에 대한 feature를 생성한다고 보시면 될 것 같습니다.
따라서 teacher, student 두 친구들 모두 이미지 전체를 입력을 받고 그리고 전체 이미지에 대한 피쳐맵을 생성하게 되고 RPN을 통해 제안된 영역에 대해서만 feature를 잘라내는 그러한 작업을 거친다고 생각하시면 될 것 같습니다!
감사합니다.
안녕하십니까 안우현 연구원님 리뷰 잘 읽고 도움을 많이 얻어갑니다!
한가지 여쭙고싶습니다.
RegionCLIP에서 vision encoder를 학습하는 과정에서, CLIP의 텍스트 인코더는 고정된 상태로 사용되는 것이 맞나요?
혹은 함께 fine-tuning 되나요? 궁금합니다.
감사합니다.
안녕하세요 손우진님, 좋은 댓글 감사합니다.
제가 리뷰에 RegionCLIP의 Visual 인코더를 pretrain하는 과정에서 사용되는 텍스트 인코더에 대한 내용을 뺴먹었습니다.
질문 주신 부분에 대해 말씀드리면, RegionCLIP에서는 CLIP의 텍스트 인코더는 학습 과정에서 고정된 상태(frozen)로 사용됩니다. 다시 말해, vision encoder는 새롭게 학습되고 업데이트되지만, 텍스트 인코더는 사전학습된 CLIP의 상태를 그대로 유지한 채 사용됩니다.
또한 저자도 언급하길 기존에 잘 사전학습된 대규모 언어 표현 공간을 유지하면서 region-level feature을 정렬하는 데에 집중하기 위한 설계를 하였다고 합니다.
감사합니다.