안녕하세요 제 두번째 X-review로는 Transformer 를 작성하려고 합니다.
이전에 잘 작성해주신 글들이 많지만, 서로 표현하는 방법이나 생각하는 것들이 조금씩 다를 수 있으니 이후 읽을 사람에게 생각의 여러 방향을 보여주는 것도 의의가 있을거라 생각합니다. 리뷰 시작하겠습니다.
Abstract
이전까지는 RNN이나 CNN을 Encoder + Decoder 구조로 사용하는 것이 문장 변환 모델의 방식이었습니다. 저자는 이전 방식의 SOTA 방식에서 주로 사용되던 Recurrent 방식이나 Conv 구조를 사용하지 않고 attention을 사용해서 트랜스포머를 만들게 됐습니다.
- Introduction
이전 연구들은 순환구조를 사용하고 encoder-decoder 방식을 사용했습니다.
순환구조를 사용하는 모델은 값들을 순차적으로 다루기 때문에 병렬적인 처리가 안되고, 엄청 긴 문장이 들어오면 힘들다는 문제가 있었습니다.
문장이 길어지면 힘든 문제는 RNN의 구조상 덧셈이 없고 곱으로만 이루어져 gradient vanishing이 생기기 때문입니다.
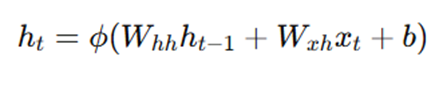
이러한 병렬적 처리를 attention 구조가 가능하게 해줍니다. 트랜스포머 이전에도 attention 기법 자체는 lstm등에 사용되기는 했으나, recurrent 방식을 배제하고 input output의 attention에만 전역적으로 의존하는 방식은 트랜스포머가 최초입니다.
2. Background
이전에도 사용되던 Entended Neural GPU, ByteNet, ConvS2S 같은 방식들은 conv 형태의 연산으로 병렬연산이 가능하게 됐습니다. 그러나 거리가 먼 애들은 거리에 비례하거나 logarithmically하게 연산량이 증가하는 문제가 존재했습니다.
트랜스포머는 정해진 연산량으로 이 문제를 해결하였고, attention 구조로 생기는 정보의 희석문제는 multi-head를 만들어 해결했습니다.
3. Model Architecture
트랜스포머는 이전까지의 SOTA인 encoder-decoder 구조를 차용하며, 이때 인코더와 디코더 모두에 self-attention 레이어와 point-wise fc layer를 쌓아 구성했습니다.
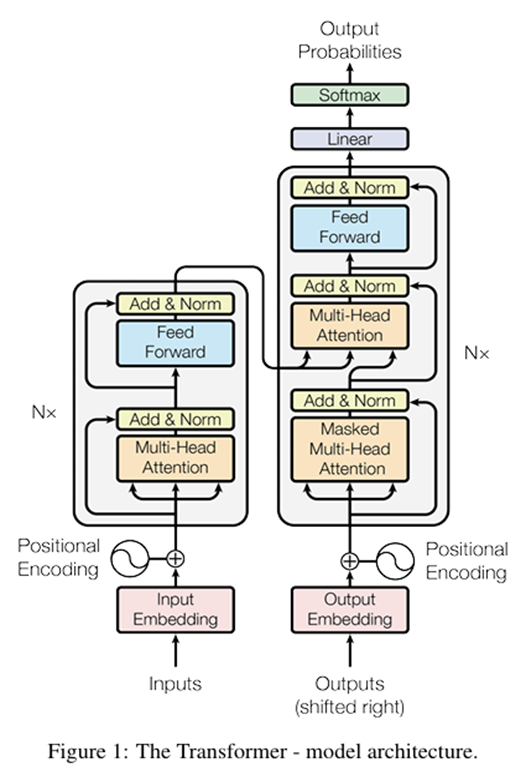
self-attention 레이어를 쌓았다는 것은 N층의 encoder와 decoder를 사용했다는 것이고 논문에서는 N=6으로 설정하였습니다.
point-wise fc layer는 ffn을 각 문장마다 해당 문장의 단어들에 point wise하게 각각 같은 가중치를 사용했다는 것입니다.
(FFN(x) = ReLU(xW1 + b1)W2 + b2)
이는 비선형성을 추가하고, 차원을 확장할 수 있습니다.
3.1 Encoder and Decoder Stacks
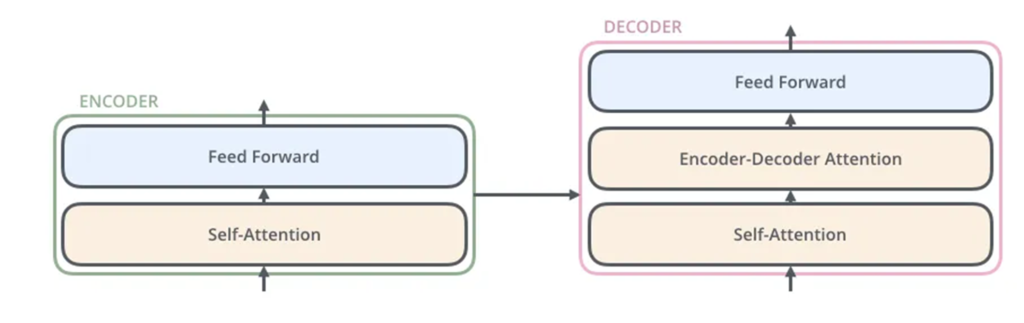
Encoder
총 6개의 동일한 Layer를 보유하며 각 layer는 각 2개의 sub-layer를 보유합니다. 각 sub-layer는 Residual connection과 layer norm을 가지고 있습니다.
1. multi-head self-attention 매커니즘
2. point wise fc layer
Decoder
Masked multi-Head attention이 들어가는데, 이유는 문장을 예측하는데 있어서 미래의 단어를 안보게 하기 위함입니다. 학습에서와 평가에서 auto-regressive가 실제로 적용되는지 여부는 약간 다릅니다. 학습에서는 masking된 attention맵을 생성하여 한 문장을 한번에 학습하며, 실제 문장 번역에서 사용될때는 이전 입력의 결과를 다시 input으로 넣어주면서 auto-regressive가 이루어집니다. 이후 표로 masking 예시를 보여드리겠습니다.
3.2 Attention
Query,key,value 를 이용하여 Query와 key의 유사도를 계산하고 해당 유사도는 학습과정에서 각 단어들의 관계를 의미하게 되며 value에 곱해집니다.
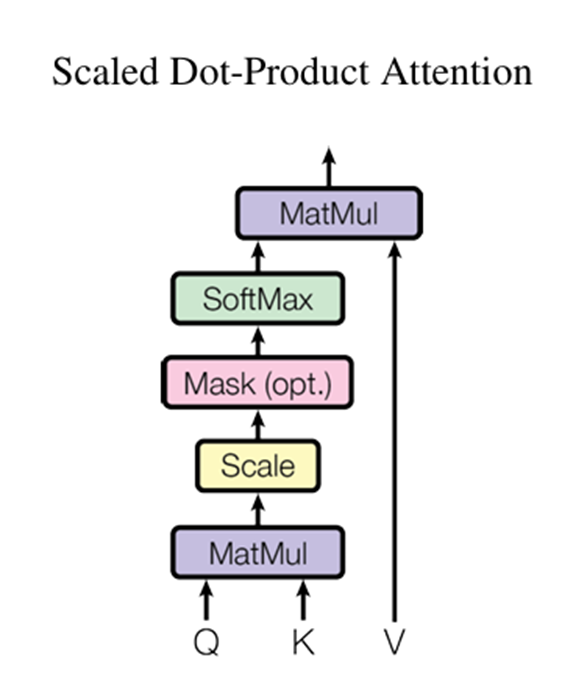
3.2.1 Scaled Dot-Product Attention
Query와 key의 차원은 dk, value의 차원 dv입니다. 아래 순서로 self-attention 연산이 진행됩니다.
- query와 key의 dot product
- 루트dk로 나누기(scale)
- softmax (가중치 벡터 생성)
- Value 에 가중치 벡터 곱해서 가중합 계산
2번에서 루트dk로 나누는 이유는 dot product 연산은 dk 값에 의존적이라 큰 값이 들어오면 softmax연산에서 매우 작은 gradient를 흐르게 하여 scaling해서 조절해준다고 합니다.
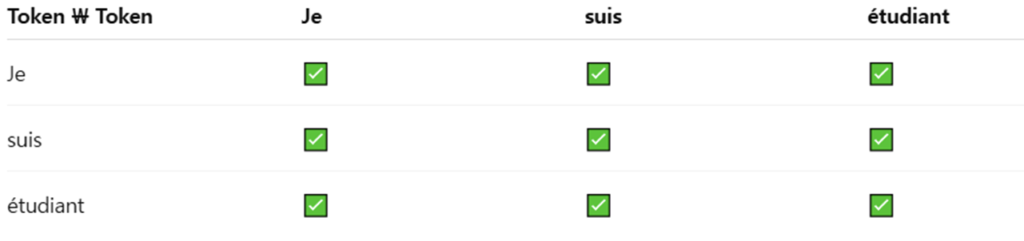
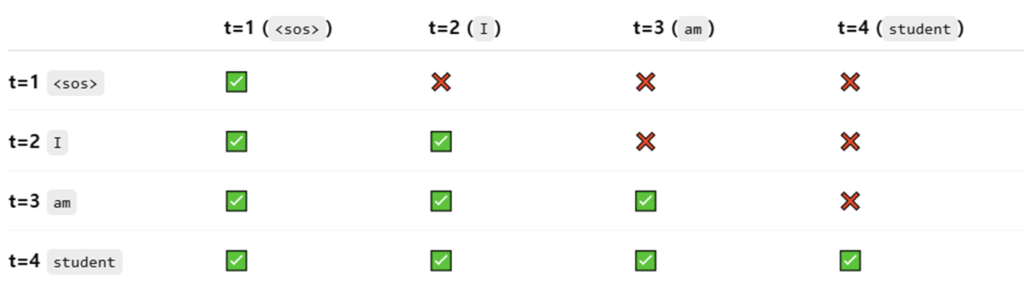
해당 표는 encoder와 decoder에서 각각 문장의 attention map을 만드는 방식입니다. encoder에서는 불어로 나는 학생이다의 attention map을 학습하고 이후 Decoder에 cross attention 형태로 넣어주게되며, decoder에서는 masked를 가중치값에 -inf 값으로 넣어 이후 softmax를 통과하면 0으로 계산되게끔 하여 구현하였습니다. sos는 문장의 시작점을 의미합니다.
위에 사진중 Decoder 부분에 존재하는 Encoder-Decoder Attention 부분은 Encoder의 output을 key, value로 사용하고 디코더의 셀프 어텐션 부분에서의 결과를 쿼리로 사용하여 내가 번역하고싶은 언어와 번역할 나라의 언어의 attention을 학습하게됩니다.
3.2.2 Multi-Head Attention
단일 head만 사용했을때 생기는 문제점은 앞서 말했듯이 정보가 희석된다는 점입니다. 문장에서 각 단어가 다른 단어와 가지는 관계가 하나가 아닐 수 있기 때문에, 여러 head로 나누어 각 head들이 각 단어들이 가지는 여러 문맥적 관계를 포착할 수 있게 합니다. 다만 이후 차원을 맞춰주기 위해 모든 head들을 다시 concat해서 전체 encoder나 decoder에서의 차원을 맞춰줍니다.
3.3 Position-wise Feed-Forward Networks
FFN은 convolution block (kernel size=1) 과 비슷한 효과를 냅니다.
입력 x : (batch_size, sequence_length, d_model)
x-> Linear(d_model -> d_ff) -> ReLU -> Linear(d_ff -> d_model) 순서로 구성됩니다.
즉 d_model (512) 차원으로 표현되던 특정 seq(“나는”) 같은 단어들이 2048차원으로 표현력을 확장시키고 이후 비선형적 특징을 넣어준 후 다시 512차원으로 요약하여 attention이 놓친 복합적인 의미를 해석하게 도와줍니다.
3.4 Embeddings and Softmax
트랜스포머는 입력토큰과 출력토큰을 d_model 차원의 벡터로 바꾸기 위해 learned embedding을 사용합니다. 미리 pretrained 된걸 사용하지 않고, 예를 들어 “나는” 같은 단어를 123번 index로 치환하여 123번 index에 해당하는 d_model 사이즈의 벡터로 초기화하고 그걸 학습하게 됩니다. 그래서 “나를” 같은 단어와 비슷한 방향으로 학습될 수 있습니다.
랜덤시드를 고정해놓지 않는다면 학습마다 해당 언어 임베딩 벡터의 방향은 달라질 수 있지만, 비슷한 단어의 방향은 비슷하게 유지됩니다.
3.5 Positional Encoding
저자는 recurrent 방식이나 convolution 방식을 사용하지 않기 때문에, 순서적인 정보를 따로 넣을 필요가 있었다고 합니다. 이를 위해 positional encodings를 추가하게 됩니다.
이는 d_model 차원으로 구성되어 있고 기존의 input과 더해질 수 있게 했습니다.
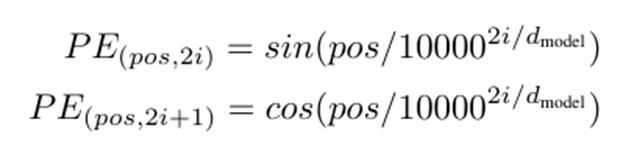
이런 함수 기반 인코딩을 사용한 이유는 서로 다른 파장을 가진 sinusoidal 값들을 사용하면 모델이 상대 위치에 대한 정보를 선형적으로 쉽게 예측할 수 있다고 합니다. (벡터의 내적이나 차로 선형적 위치 추정 가능)
저자는 learned positional embedding도 사용해봤으나 실제 성능은 비슷했으며, sin, cos 을 사용하는 것이 학습시 사용했던 문장보다 더 긴 문장이 들어왔을 때 extrapolation에 유리하여 sinusoidal 방식을 채택했다고 합니다.
Ablation sutdy
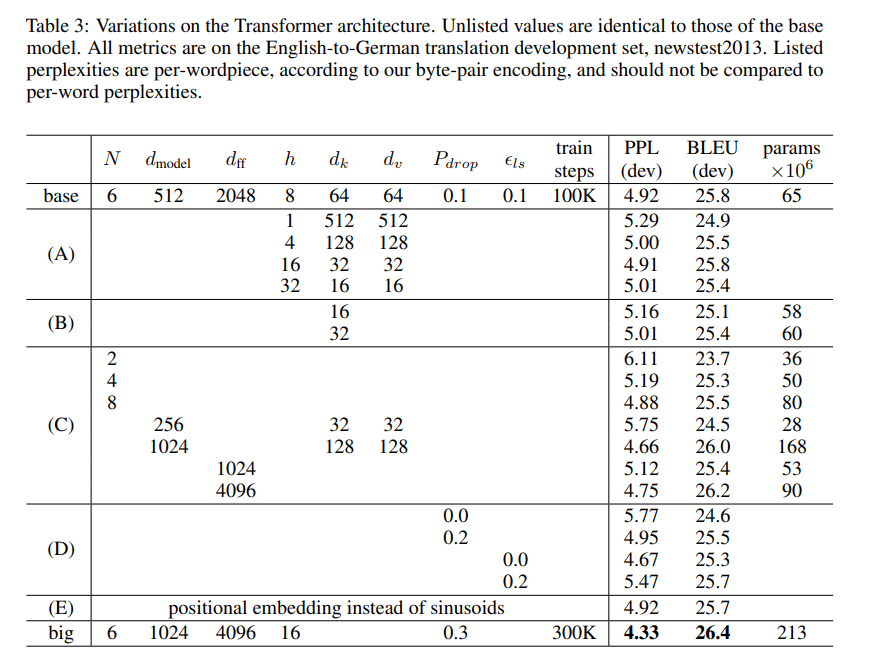
Transformer의 각 요소들로 ablation을 진행하였습니다.
PPL은 얼마나 문장을 혼란스러워하는지에 대한 점수이고
BLUE는 번역의 정확도입니다.
base모델로부터 A , B , C , D , E 의 ablation을 진행하여 N이 커질수록 성능이 좋아지며 head 개수는 16개 이후부터는 성능감소, positional embedding은 성능적으로 base와 거의 유사한 점을 확인할 수 있습니다.
트랜스포머 논문이 실험적 내용보단 이론적으로 이후에 많은 분야에 영향을 미치는 만큼 개념적인 흐름이 머리속에 그려지면 이후 논문들을 이해하는데 도움이 될 것 같습니다.
안녕하세요 인택님 리뷰 잘 읽었습니다!
궁금한점이 하나 생겨 여쭤보고싶습니다.
positional encodig 사용한 이유는 서로 다른 파장을 가진 sinusoidal 값들을 사용하여 모델이 상대 위치에 대한 정보를 선형적으로 쉽게 예측할 수 있다고 하셨는데 이에대해 크게 와닿지않아서 자세한 설명 부탁드립니다.
감사합니다^^
안녕하세요 우진님 좋은답글 감사합니다.
우선 positional encoding 을 sin, cos으로 사용하게된다면 0~1을 부드럽게 움직이면서 주파수를 조절해서 주기적인특징을 반영할 수 있다는 장점이 있습니다. 그리고 sin과 cos을 각각 번갈아 사용하는 이유는, sin함수만 이용하게 되면 거리차이를 선형적인 곲셈형태의 translation operator를 찾을 수 없는 반면 cos까지 사용하게되면 서로의 내적의 형태가 가까우면 내적값이 커지고, 멀면 내적값이 작아지는 특징이 생겨 내적을 사용하는 트랜스포머 구조에서는 포지션 간 간격에 대한 패턴을 학습하기 용이합니다.
안녕하세요 신인택 연구원님 리뷰 잘 읽었습니다
질문이 하나 있습니다
attention을 수행할 때 여러 헤드로 나눠서 어텐션을 수행하고 그게 주는 효과가 대단히 신기한데요! 저자는 이런 방법을 어떻게 적용하게 되었는지가 궁금합니다.
이전에도 이런 임베딩 벡터를 같은 크기로 나눠 연산을 하던 방법이 있었던 건 가요? 그냥 저자가 실험을 해보니 조금 더 여러 의미에서 학습이 가능하더라 라고 얻게된 결과인 걸 까요?
감사합니다!
이전에도 attention 자체를 사용하는 방식은 존재했으나 임베딩 벡터를 여러 head로 나눠서 attention을 수행하고 다시 결합하는 구조는 아마 트랜스포머가 최초일 것입니다. (이유는 트랜스포머라는 구조 자체가 처음 제안된만큼 mutl-head라는 개념자체가 없지 않았을까 싶습니다.)
논문에서는 head를 여러개로 나누는 행위가 경험적으로 효과가 있었다고 언급합니다. 즉 문장의 의미론적 관계나 문법적 관계 위치관계등의 역할을 각 head가 병렬적으로 학습하게 되기 때문에 single-head가 아닌 mutl-head구조를 선택하게됩니다.
안녕하세요 신인택 연구원님 좋은 리뷰 감사합니다.
리뷰를 읽으면서 몇가지 궁금한 점이 생겨서 질문합니다.
1. 디코더에는 Figure.1에서 Masked Multi-Head Attention과 Multi-Head Attention 두가지 attention이 존재하는데 두 연산은 masking만 차이가 있는 건가요?
2. 3.4절에서 learned embedding과 pretrained embedding의 차이가 무엇인지 궁금합니다. learned가 사전학습을 통해 학습했다는 것과는 다른 의미인지, 어떻게 비슷한 단어의 방향이 유지되는 건지 궁금합니다.
3. 포지셔널 임베딩에서 긴 문장이 들어왔을 때 extrapolation에 유리하여 sinusoidal 방식을 사용한다고 언급해주셨는데, sinusoidal 방식은 삼각함수가 주기함수이기 때문에 긴 문장이 입력되면 같은 값을 갖는 경우가 생길 수 있을 것 같습니다. 이 중복 가능성 문제에 대한 저자의 분석이 있었나요?
4. Ablation Study을 첨부해주셨는데, 기존 RNN 방법론과 성능이 얼마나 차이나는지 궁금합니다. 그리고 PPL과 BLEU로 성능을 평가하는 것 같은데 어떻게 평가되는 건지도 설명 부탁드립니다. 기존 방법론과의 비교와 평가지표에 대한 설명이 없어서 모델의 성능이 얼마나 향상된건지, 각각의 ablation에서 파라미터에 따른 성능이 얼마나 차이나는 건지가 체감이 안되네요.
5. Ablation Study에서 head의 개수가 늘어남에 따른 성능이 오르락 내리락하는 것 같습니다. 각 단어들이 가지는 여러 문맥적 관계를 포착하기 위하여 여러 head를 사용한다고 하셨는데, head가 32개일때의 성능이 16개일 때의 성능보다 오히려 낮은 이유에 대한 저자의 분석이 있었는지 궁금합니다.
감사합니다.
안녕하세요 성준님 좋은질문 감사합니다. 질문에 대한 답을 하자면
Q1. 디코더에는 Figure.1에서 Masked Multi-Head Attention과 Multi-Head Attention 두가지 attention이 존재하는데 두 연산은 masking만 차이가 있는 건가요?
A1. 디코더에서의 두 어텐션은 각각 참조하는 정보가 다르다고 생각할 수 있습니다. 디코더 앞단의 masked된 부분은 문장에서의 이전 단어들만 참조해서 미래정보를 보지 못하게 하는 것도 있으며 번역하고자 하는 나라의 언어의 값들을 보고, 중간의 Cross attention인 Multi-Head Attention 부분은 Encoder의 output을 참조하여 두 언어간의 관계도 정보로 들어가게됩니다.
Q2. 3.4절에서 learned embedding과 pretrained embedding의 차이가 무엇인지 궁금합니다. learned가 사전학습을 통해 학습했다는 것과는 다른 의미인지, 어떻게 비슷한 단어의 방향이 유지되는 건지 궁금합니다.
A2. learned Embedding이 Learned라는 표현때문에 사전학습된 것이라고 생각할 수 있지만 학습과정에서 학습되는 learnable한 embedding이라고 생각하시면 됩니다. pretrained embedding과는 다른 의미입니다.
Q3. 포지셔널 임베딩에서 긴 문장이 들어왔을 때 extrapolation에 유리하여 sinusoidal 방식을 사용한다고 언급해주셨는데, sinusoidal 방식은 삼각함수가 주기함수이기 때문에 긴 문장이 입력되면 같은 값을 갖는 경우가 생길 수 있을 것 같습니다. 이 중복 가능성 문제에 대한 저자의 분석이 있었나요?
A3. 논문에서는 extrapolation 즉 긴 시퀀스의 문장 일반화에 유리하다고는 언그밯지만 주기성으로 인한 중복 가능성에 대한 직접적인 언급은 없습니다.
물론 토큰수가 엄청 많아지면 중복될 가능성이 존재하기는 하지만 학습가능한 부분을 반영하거나, 벡터에 회전값까지 넣어 각도차이를 반영하면 중복문제가 해소가 될거라 생각합니다.
Q4. Ablation Study을 첨부해주셨는데, 기존 RNN 방법론과 성능이 얼마나 차이나는지 궁금합니다. 그리고 PPL과 BLEU로 성능을 평가하는 것 같은데 어떻게 평가되는 건지도 설명 부탁드립니다. 기존 방법론과의 비교와 평가지표에 대한 설명이 없어서 모델의 성능이 얼마나 향상된건지, 각각의 ablation에서 파라미터에 따른 성능이 얼마나 차이나는 건지가 체감이 안되네요.
A4.
Transformer(base) 기준으로 이전 SOTA인 LSTM기반보다 BLEU 점수는 2~3점정도 더 높습니다.
BLUE점수는 생성문장과 GT문장과의 일치율로 평가를 하는데, 문장의 길이가 짧으면 점수에 페널티를 부여하는 방식입니다. BLUE 40을 넘으면 전문적인 번역이 어느정도 가능하다고 합니다.
BLEU점수는 문법적인 오류나 패러프레이즈같은 것은 점수에 잘 반영이 되지 않는 문제가 존재하기는 합니다. ( 동일 뜻이지만 다른 문장이면 틀렸다고 판단)
PPL은 앞의 단어들을 보고 이후 단어가 나올 확률로 얼마나 확신을 가지고 다음 단어를 예측하는지로 생각하면 됩니다. 즉 낮을수록 좋은 점수입니다.
Q5. Ablation Study에서 head의 개수가 늘어남에 따른 성능이 오르락 내리락하는 것 같습니다. 각 단어들이 가지는 여러 문맥적 관계를 포착하기 위하여 여러 head를 사용한다고 하셨는데, head가 32개일때의 성능이 16개일 때의 성능보다 오히려 낮은 이유에 대한 저자의 분석이 있었는지 궁금합니다.
A5. 논문에 명시적으로 분석이 있지는 않았습니다. 다만 표로 Head수가 8개가 최적임을 보여주고 16개로가면 늘어나기는 하지만 차원수가 감소하여 생기는 과적합이나 불안정성 때문에 8개로 선택했다고 생각합니다. 같은이유로 32개로 가면 오히려 성능이 낮아짐을 확인할 수 있습니다.
안녕하세요 인택님 리뷰 감사합니다.
attention 구조로 생기는 정보의 희석문제는 multi-head를 만들어 해결했다고 하셨는데, 정보의 희석 문제가 정확히 어떤 문제이고, multi head가 어떻게 해결했는지가 궁금합니다!!
또 ablation을 진행했을때 N은 커질수록 성능이 좋아지지만 head 개수는 16개 이후부터는 성능이 감소 하는데, 연산량 적인 측면에서 문제가 발생하는것은 그럴 수 있을것 같지만 성능이 낮아지는 이유는 무엇인지 궁금합니다!!
안녕하세요 영규님, 좋은질문 감사합니다.
우선 논문에 나온 표현을 하자면
“Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.”
mutl head attentoin은 서로 다른 subspace들의 정보를 각각 attention하여 병렬적으로 정볼르 얻고 이후 concat하여 차원수를 맞춰줍니다. 만약 단일 헤드를 사용한다면 하나의 공간에서의 정보를 사용하여 다양한 시각에서의 attention을 얻을 수 없어 정보가 희석된다고 표현했습니다. 그리고 head가 16개이후부터 성능이 낮아지는 이유는 head의 차원은 (512/head) 인데 16이면 32차원 32면 16차원밖에 안되므로 head의 표현력이 매우 낮아지게 됩니다. 이런 이유로 성능이 낮아진다고 생각합니다.
리뷰 잘 읽었습니다. 기존에 잘 정리된 tranasformer 리뷰들이 많은데, 그것들과 비교하면 정리가 덜 된 느낌이네요. 질문 몇 개 드립니다. transformer의 기본적인 개념들이니, 상세한 답변 기대하겠습니다.
1. “문장이 길어지면 힘든 문제는 RNN의 구조상 덧셈이 없고 곱으로만 이루어져 gradient vanishing이 생기기 때문입니다.” 부분이 꽤나 추상적으로 작성되어 있네요. 이 부분을 더 자세히, 문장이 길어지면 왜 문제인지, 덧셈이 없고 곱으로만 이루어져서 gradient vanishing이 왜 일어나는지에 대해 더 자세한 설명 부탁드립니다. 그리고 길이가 긴 sequence가 입력으로 들어왔을 때의 문제가 gradient vanishing 이외에 무엇이 있는지 고민해서 답변 주시기 바랍니다(gradient vanishing이 구체적으로 어떤 문제인지부터 고민을 시작하면 도움이 될 것 같네요). 기존 seq2seq 구조의 어떤 문제점들을 transformer가 어떻게 해결했는지 함께 고민해보면 transformer의 강점을 더 명확히 알 수 있을 것입니다.
2. attention 연산은 내적으로 수행됩니다. 학습되지 않죠(내적은 파라미터가 필요한 연산이 아니므로). transformer 모델에서 학습을 통해 변화되는 부분은 어디인가요? 그리고 학습으로 업데이트 되는 부분들의 역할은 무엇일까요?
3. inference 과정에서 decoder의 cross-attention이 어떻게 수행되는지, 이 때 key, query, value는 어떻게 얻은 값인지 설명해주시기 바랍니다.
4. layer normalization는 무엇이고, 어떤 목적으로 사용되며, 구체적으로 어떻게 연산되나요?
5. 학습할 때 디코더에 정답 sentence를 같이 넣어주면 next token prediction 과정에서 그냥 다음 정답 값 토큰을 보고 현재 출력을 예측하는 방향으로 학습이 shorcut에 빠지게 될 수 있는데, 이를 어떻게 방지하는지 설명해주시기 바랍니다.
안녕하세요 재연님 좋은 질문 감사합니다. 질문에 대해서 답변드리자면
1.
RNN은 구조상 hidden state에서 이전값이 반복적으로 곱해지는 구조입니다. 긴 sequence 가 들어오면 이러한 곱셈연산이 반복되므로 역전파 과정에서 gradient vanishing이 일어나기 쉬워집니다. Skip connection은 곱셈연산 사이사이 덧셈연산이 더해져 gradient가 누적되기 전에 역전파가 앞단에 도착하게 해줍니다. 그리고 RNN기반의 seq2seq같은 경우에는 긴 문장이 들어오게 되면 순차적으로 처리를 해야하므로 병렬화가 불가능하다는 문제점도 존재하였습니다. transformer는 각 단어(토큰)과의 관계를 attention map 형태로 표현하여 병렬화를 가능하게 하여 이러한 문제점을 해결할 수 있었습니다.
2.
attention이 단순 값들의 내적이므로 학습되지 않는게 맞다고 생각합니다. 트랜스포머에서 학습되는 부분은 입력에 곱해지는 가중치행렬들이며 입력에 가중치 행렬들이 곱해져 Query,key,value 벡터가 생성됩니다. 그리고 모델 구조에 존재하는 Feed-Forward Network도 학습가능한 파라미터가 존재합니다.
Query 벡터와 key 벡터의 내적을 통해 어떤 토큰이 다른 토큰에 얼마나 주목할지 계산하고,이 attention score로 value 벡터들을 가중합하여 최종 표현을 만듭니다.
3.
inference시에 decoder의 cross-attention의 Q,K,V는 각각 인코더의 output과 디코더의 이전 self-attention의 결과를 이용합니다. 인코더의 입력 시퀀스를 받아 그 출력으로 key, value 벡터를 만들고 Decoder에서는 auto-regressive하게 이전 정보만을 참조하여 생성한 출력 query를 만들고 이 Query,Key,Value를 이용하여 cross-attention을 수행합니다.
4.
Layer norm은 한 샘플의 feature를 정규화하는 것입니다. 목적 자체는 gradient의 흐름을 유지하여 학습을 안정화하는 것인데, 입력 벡터의 평균과 분산으로 정규화해주고 학습가능한 scale shift를 적용하여 연산됩니다.
5.
학습할때에는 디코더의 self-attention 구조에 masking을 추가하여 이후 토큰을 참조하지 못하게 합니다. 추론할때는 auto-regressive구조이지만 학습할때에는 masking 기법으로 이후 토큰을 참조하지 못하면서 병렬적으로 연산될 수 있도록 구현하였습니다.
틀리거나 부족한점이 있으면 알려주시면 감사하겠습니다.
안녕하세요 인택님 ! 궁금했던 논문인데 덕분에 잘 보았습니다. 리뷰 읽다가 궁금한 부분이 생겼는데
1. 어텐션 구조로 생기는 정보희석 문제를 멀티헤드로 해결했다고 하셨는데 구체적으로 어떤 메커니즘 때문에 정보의 희석이 생기는 건가요?
2. 멀티헤드의 역할을 그럼 단순히 표현력을 늘리는것 이상으로 실제로 다른 의미적인 관계를 학습하는 역할로 이해하면 될까요?
안녕하세요 찬미님 답글 감사합니다.
순차적으로 답변 해드리자면
1. 어텐션 구조로 인한 정보희석이라는 표현은 단일헤드로 만들었을 때와 멀티헤드로 만들었을때의 차이점이라고 생각하면 될 것 같습니다. 어떠한 긴 문장을 단 한가지의 attention score로 표현하는 것보다 여러가지 score들로 그 관계를 학습시키면 여러가지 이해관계들을 표현할 수 있습니다.
2. 넵 맞습니다. 문장에서 여러가지의 이해관계를 학습하게되어 표현력이 늘어난다고 생각하면 되겠네요 잘 이해하신것 같습니다.
안녕하세요 인택님! 항상 attention 연산을 겉핥기로 알고 있는거 같아
이 기회에 제대로 공부해볼겸 찾아 읽었습니다
먼저 좋은 리뷰 감사합니다.
읽고 나서 든 궁금증이 몇개 있습니다.
1. point(position)-wise feed forward network에서는 마치 NiN(1×1 conv)와 유사하게 비선형성을 추가해준다고 이해했습니다.
그렇다면, NiN에는 비선형성뿐만 아니라 연산적 측면에서도 이점을 가지는데 point-wise ffn 역시 다른 장점도 있는지 궁금합니다.
2. input, output token을 d_model 차원으로 바꿀 때 왜 pretrained를 사용하지 않는지 궁금합니다.
이미 잘 구축된 vector embedding이 있다면, 새로운 token을 그 embedding에 추가하는 방향으로 가면, token간의 유사도를 더 잘 구할 수 있지 않을까라는 의문을 가졌습니다.
안녕하세요 정우님 답글 감사합니다.
궁금증에 대한 답변을 해드리자면
1. FFN 구조에 관련되어서는 연산량적인 측면 이외에도 attention으로 배운 관계들에 대한 토큰 내부 표현을 강화하는 효과를 가지고 있습니다.
2. 입출력 토큰을 d_model 로 맞출때 굳이 pretrained embedding을 사용하지 않는 것은 Transformer가 학습 과정에서 embedding 공간을 최적화하는 성질을 가지고 있기 때문입니다. 미리 학습한 word2vec 같은 임베딩을 가져오면 학습 초기 안정성에는 좋을 수 있으나 학습 중 embedding layer 들도 업데이트 되므로 같이 학습시킨다고 합니다.
감사합니다.