안녕하세요, 이번주 리뷰는 소수의 human teleloperation 데모를 통해 자동으로 엄청나게 많은 양의 시뮬레이션 데모를 만들어 낼 수 있는 방법을 제안한 논문입니다. NVIDIA에서 수행한 연구인 만큼 최근 NVIDIA에서 공개한 휴머노이드를 위한 대규모 사전학습 모델인 GR00T-N1의 데이터 생성의 핵심으로 활용되었다고 하네요. 11일만에 78만개에 달하는 시뮬레이션 데모를 만들었다고 하니 정말 놀라웠습니다. (직접 teleoperation을 한다고 가정했을 때는 무려 쉬지않고 해도 9개월이 걸린다고 하네요). 결국 범용적인 모델이나 policy를 위해서는 데이터의 양이 중요한 만큼, 특히 제한된 로봇 리소스와 시간을 고려했을 때 굉장히 의미가 있는 논문이라고 생각합니다. 기존의 단일 팔에대한 MimicGen 파이프라인을 양팔로 확장한 프레임워크인데, 더 자세히 알아보도록 하겠습니다. 사실 양팔을 위한 프레임워크이고 프레임워크의 기술적인 부분은 MimicGen을 완전 기반으로 하지만 양팔 데이터 구조가 어떻게 구성되는지 엿볼 수 있었습니다.

Introduction
최근에 imitation learning을 활용한 방법들이 주를 이루고 있지만, 특히 dexterous manipulation(자유도가 굉장히 많은 조작들)은 오래 전부터 imitation learning 기반 방법들이 주가 되었다고 합니다. 따라서 teleoperation 기반의 데이터 수집을 다수의 사람을 투입해 수개월에 거쳐 policy를 학습해왔다고 합니다. 하지만 당연하게도 이러한 방법은 복잡한 제어 방식으로 인한 사람의 극심한 피로도는 물론 시간과 구축비용, 확장성 측면에서 굉장한 비효율을 가지고 있다고 합니다. (직접 해봤을 때는 간단한 구조의 로봇을 활용해 블럭을 컵에 옮기기와 같은 task의 데모를 만드는 것도 상당한 피로도를 느끼게 했습니다.) 특히 휴머노이드 수준으로 많은 자유도의 teleoperation을 할 때는 해당 단점들이 극대화될 뿐 만 아니라 teleoperation의 난이도 자체도 너무 높아져 imitation learning의 한계로 다루어졌다고 하네요. 저자들은 이런 한계를 극복하고자 인간의 teleoperation 데모를 최소한으로 활용하는 방법으로 연구를 진행했다고 합니다. One shot, 단일 데모 등을 강조하는 연구들이 25년에 많이 등장하는 만큼 imitation learning을 위한 데이터 수집의 비효율성은 모두가 느끼고 있는 문제점이라고 생각합니다. 따라서 저자들은 이 논문의 contribution으로 소수의 시연으로부터 데이터를 대규모로 생성할 수 있는 자동화 시스템을 제안한것 외에 세가지 embodiment에 대해 여러 화경을 구성하고 21000개의 trajectory를 생성해낸 점, 더 나아가 디지털 트윈 환경을 구성하고 teleoperation 데이터를 시뮬레이터 상에서 재현해 policy를 학습해 실제 로봇으로 전이하는 real to sim to real을 통해 90퍼센트의 성공률을 달성한 점을 언급했습니다.
MimicGen
DexMimicGen이 MimicGen을 확장시킨만큼 MimicGen에대한 이야기를 하고 넘어가도록 하겠습니다. 결론부터 말하면 소수의 데모를 통해 대규모 데이터셋을 만들어내는 프레임워크입니다. 다만 task를 object centric한 관점에서 subtask로 분해해서 정리하는 아이디어를 활용합니다. MimicGen은 모든 조작 과제가 객체 중심의 subtask 시퀀스로 구성된다고 가정합니다. Task마다 다르지만 예를들어 컵을 쟁반에 옮기는 작업에서는 잡기, 이동 시키기, 놓기 와 같이 미리 정의한다고 합니다. 이렇게 정의된 subtask 기준으로 task를 나눈 뒤 각각의 액션을 EE의 포즈 시퀀스로 annotation 한다고 합니다. 이후에는 임의로 변경한 object pose 기준으로 기존의 annotation된 데이터의 object pose와의 차이를 계산해 trajectory를 예측한다고 합니다. 두 pose간의 상대적인 SE(3) 변환을 계산해 EE와 object와의 상대적인 위치를 유지한다고 합니다. (Subtask의 순서는 무조건 유지한다고 하네요.) 이전에 리뷰한 RoboSplat에서도 비슷한 방식으로 진행했던 것 같습니다. 다만 mimicgen의 파이프라인에는 모든 subtask를 진행한 후 새로운 데이터셋으로 사용할 수 있는지에 대한 성공 여부를 평가한다고 합니다. 이를 통해 데이터의 신뢰도를 향상시킬 수 있다고 하네요. 결과적으로 이렇게 증가한 데이터를 통해 일반화를 이루어낼 수 있다고 합니다. (다만 Augmentation의 경우 object pose 외에도 정말 다양한 augmentation들이 있었는데, 이것들은 안 하는건지 의문이긴 합니다.)
DexMimicGen
DexMimicGen은 MimicGen을 기반으로 하되, 훨씬 더 복잡한 양팔, 다지 환경에서의 조작을 위한 데이터 생성을 목표로 하기 때문에 생긴 세 가지 난관이 있다고 합니다. 우선 두 팔 각각이 서로 다른 목표를 수행할 수 있도록 독립적으로 동작해야 하며, 두 번째로는 양팔이 동시에 협력해 하나의 목표를 이루어야 하는 협응이 필요하다고 합니다. 마지막으로, 특정 작업은 반드시 한 팔의 동작이 완료된 후에야 다른 팔이 그다음 작업을 수행할 수 있도록 순차적인 정책이 요구된다고 합니다. 기존의 MimicGen은 단일 작업을 단순한 subtask들로 분해하여 처리하는 방식이었기 때문에, 그대로 적용할 수 없었다고 합니다.

따라서 DexMimicGen은 이러한 문제를 해결하기 위해 세 가지 subtask 유형(병렬, 협동, 순차적)을 양팔에 맞게 정의했습니다. 먼저 병렬 서브태스크는 양팔이 서로 독립적으로 움직여야 하는 상황을 정의했습니다. 예를 들어, Piece Assembly 작업 (그림의 맨 위 경우)의 시작에서는 각 팔이 서로 다른 물체를 잡아야 하며, 이 과정은 양팔이 동시에 시작하더라도 각각 다른 시점에 완료될 수 있다고 합니다. 기존 MimicGen 방식은 한개의 팔을 위한 파이프라인이기 때문에 병렬성을 처리하는 데에는 한계가 있었다고 합니다. DexMimicGen은 이를 해결하기 위해 각 팔마다 독립된 서브태스크 시퀀스를 정의한다고 합니다. 시연 데이터 역시 각 팔에 대해 분리된 object-centric segment로 나뉘어진다고 합니다. 하지만 두 팔의 작업이 서로 다른 타이밍에 시작되고 끝날 수 있기 때문에, DexMimicGen은 각 팔에 대해 독립적인 액션 큐를 유지하면서 비동기적으로 trajectory를 실행한다고 합니다. 액션은 큐에서 하나씩 추출되어 병렬로 실행되며, 큐가 비면 다음 서브태스크를 변환 후 큐에 삽입하는 구조로 진행된다고 합니다.
두 번째로, 협동 서브태스크는 두 팔이 정확히 동기화되어야 하는 정밀한 협력 상황에서 필요하다고 합니다. Box Cleanup (그림의 두번째 경우) 작업에서는 한쪽 팔이 뚜껑을 들고 다른 쪽 팔이 상자를 고정하는 자세가 필요하기 떄문에 이때는 양쪽 end-effector 사이의 상대적인 자세를 항상 기존 데모와 동일하게 유지해야 한다고 합니다. 이를 위해 DexMimicGen은 두 가지 요소를 도입했습니다. 양팔의 trajectory는 시간적으로 완벽히 동기화되어 실행되고, 동일한 SE(3)을 사용한다고 합니다. (쉽게 말해 두 팔의 실행 데이터를 같은 변환행렬을 통해 trajectory를 변환하고 동시에 실행한다고 이해하면 될 것 같습니다. 이러한 temporal alignment를 위해, 원본 시연 데이터를 분할할 때부터 협동 서브태스크는 반드시 같은 타임스텝에서 끝나도록 설정하며, 실행 중에는 남은 스텝 수를 기준으로 서로를 기다리는 방식의 동기화 전략을 수행한다고 합니다. 이로 인해 협동 구간이 정확히 일치된 상태에서 종료될 수 있다고 합니다. 추가로 협동 서브태스크를 위해 사용되는 변환을 하는 방법도 두 가지가 존재한다고 합니다. 하나는 Transform 방식이며, 이는 기존 MimicGen 방식과 유사하게 객체의 포즈를 기준으로 SE(3) 변환을 적용하는 방식이라고 합니다. 객체의 새로운 포즈와 원본 시연에서의 객체 포즈간의 관계를 통해 변환 행렬을 계산하고, 이를 통해 trajectory를 변환하는 방법을 사용한다고 합니다. 다만 특정 상황에서는 replay 방식을 사용한다고 합니다. 이 방식은 기존 데모 trajectory를 변환을 거치지 않고 그대로 사용하는 (데이터 증강을 하지 않는)경우이고, Can Sorting같은 작업에서 물체를 다른 손으로 넘겨주는 동작은 transform을 할 경우 기구학적인 문제가 발생해 그대로 사용한다고 합니다. 애초에 이런식의 augmentation은 Robosplat을 읽으면서도 문득 들었던 생각인데 주변 환경이 완전히 깔끔하고 방해하는 물건이 없는 경우에만 가능하지 않나,, 하는 생각이 듭니다.
마지막으로, 순차 서브태스크는 특정 동작이 반드시 다른 동작보다 먼저 실행되어야 하는 상황을 다룬다고 합니다. 예를 들어 Pouring 작업(그림의 아래)에서는 한쪽 팔이 공을 그릇에 붓는 동작을 먼저 수행해야 하고, 그 후에 다른 팔이 그릇을 패드로 옮겨야 하기 떄문에 ordering constraint mechanism을 도입했다고 합니다. 작업 정의에 따라 어떤 동작이 선행 되어야 하는지를 pre-subtask로 지정하고, 후속으로 진행되어야 하는 post-subtask를 명시적으로 지정하며, 후속 동작을 담당하는 팔은 선행 동작이 완료될 때까지 기다리도록 구성된다고 합니다. 이를 통해 작업 흐름의 논리적 순서를 보존한 채 데이터 생성이 가능하다고 합니다.
Data Generation
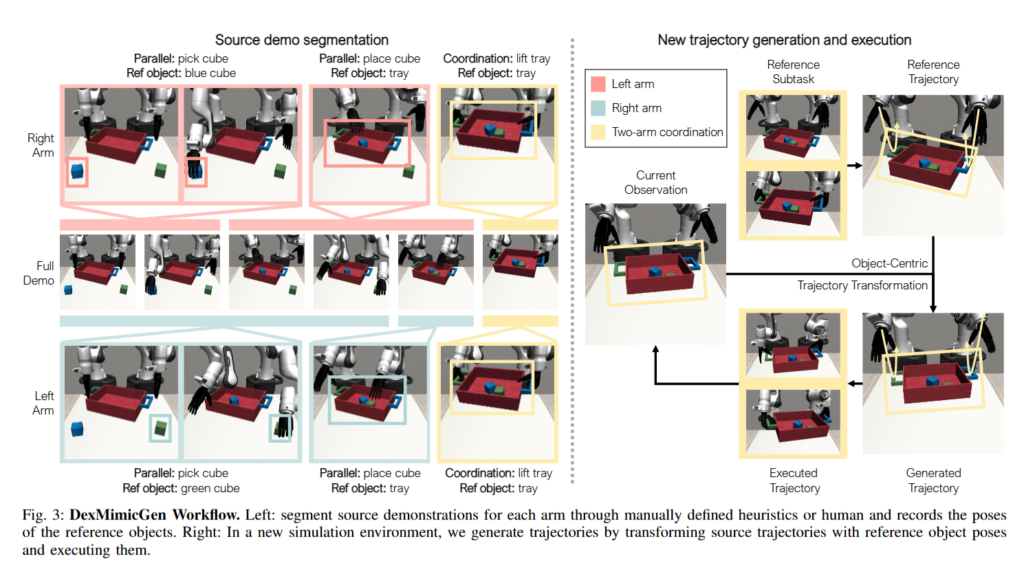
데이터를 만들어내는 workflow를 tray에 큐브를 담아 들어 올리는 task를 예제로 삼아 확인해보도록 하겠습니다. 해당 task는 각각의 팔로 pick and place를 수행한 뒤 마지막에 쟁반을 들어올리는 과정이 협업 task에 해당하고, coordination subtask로 명시해 진행한다고 합니다. 이 과정을 시작하기 위해 먼저 인간 시연 데이터를 수집하고, 이를 팔마다 서브태스크 단위로 나누는 작업을 진행한다고 합니다. 이때 세분화된 서브태스크 구간은 사람이 직접 어노테이션하고, 각 팔이 우선 따로 pick and place를 수행한 뒤 동기적으로 움직여 들어 올리는 subtask들의 시퀀스로 구성합니다.
데이터 생성은 scene을 무작위로 초기화하고, 기존 시연 중 하나를 선택하는 것으로 시작된다고 합니다. 이후 각 팔의 서브태스크에 대해 trajectory를 병렬적으로 생성하고 실행하며, 이 때 주어진 레퍼런스 오브젝트(쟁반)의 현재 pose와 시연 데이터에서의 pose 사이의 상대 SE(3) 변환을 계산한다고 합니다. 이 변환을 두 팔 모두의 source trajectory에 동일하게 적용하여 새로운 장면에 적절한 동작 시퀀스를 생성하며, 특히 coordination 서브태스크인 경우에는 두 팔의 동작을 시간적으로 정렬시키는 동기화 실행 전략을 사용해 trajectory를 실행한다고 합니다.
손가락 움직임의 경우에는 별도로 변환하지 않고, 원본 시연에서 사용된 손가락 관절 제어 명령을 그대로 재생하는 방식을 사용하는데, 이는 손가락의 동작이 end-effector의 움직임에 상대적인 관계이기 때문이라고 합니다. 이러한 과정을 거쳐 생성된 시연 trajectory는 해당 작업이 성공적으로 완료되었을 때에만 데이터셋에 포함되며, 이 과정은 충분한 양의 데이터를 확보할 때까지 반복된다고 합니다.
System Setup
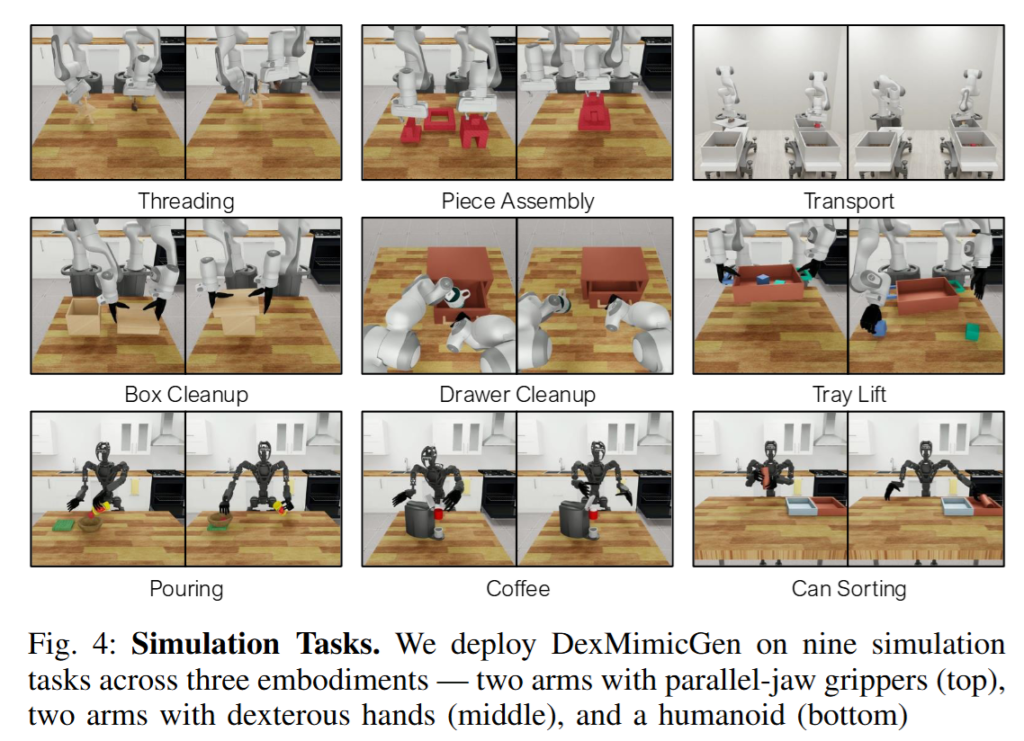
DexMimicGen의 전체 파이프라인을 현실에서 구성하기 위해, 저자들은 다양한 시뮬레이션 환경들과 실제 및 가상 환경 모두에서 시연 데이터를 수집할 수 있는 텔레오퍼레이션 시스템을 구축했다고 합니다.시뮬레이션 환경은 다양한 task와 embodiment를 포함하는 RoboSuite 프레임워크 (강화학습 뿐 만 아니라 많은 연구에서 해당 프레임워크를 많이 사용하는 것이 보입니다.) 위에 총 9개의 task를 구성하였다고 합니다. 물리 시뮬레이터는 MuJoCo를 채택했다고 합니다. RoboSuite는 구성된 scene을 MuJoco, Isaac Sim 등 다양한 시뮬레이터로 내보낼 수 있는걸로 알고있는데 왜 NVIDIA에서 MuJoCo를 사용했는지는 조금 더 알아봐야 할 것 같습니다. 로봇은 Panda로봇을 두 개 사용한 양팔의 2Finger 버전, Dextrous Hand버전, GR-1휴머노이드를 사용했다고 합니다. Panda 로봇에는 엔드이펙터의 delta pose를 토크 명령으로 변환하는 방식을 사용하였고, GR-1 휴머노이드는 복잡한 연결구조를 고려해 mink 기반의 Inverse Kinematics 컨트롤러를 구현해 적용했다고 합니다. 손가락의 경우, 직접적인 joint position 제어를 사용해 조작했다고 합니다.
이렇게 설정된 각 embodiment마다 세 개의 태스크를 설계하여 총 아홉 가지 태스크가 선정되었고, Threading, Piece Assembly, Box Packing, Coffee 같은 높은 정밀도가 요구되는 조작들과 Drawer와 같이 articulated object를 다룰 뿐 만 아니라, Transport와 long-horizon task도 포함했다고 합니다. 또한 coordination이 요구되는 태스크들(Box Packing, Can Sorting, Tray Lift 등)과 sequential한 동작 흐름이 필요한 태스크들(Pouring, Drawer Cleanup, Coffee 등)로 나누어져, 다양한 상호작용 양상을 테스트할 수 있도록 설계되었다고 합니다. 이 외에도 MimicGen과 마찬가지로 초기 상태 분포를 확장하는 variant들도 도입했다고 합니다. 더 폭넓은 범위에서 진행할건지, 각각의 물체의 포지션을 바꿀건지 등등이 해당합니다.
텔레오퍼레이션 시스템 또한 DexMimicGen의 핵심 요소라고 합니다. 병렬조형 그리퍼를 장착한 Panda 로봇에 대해서는 기존 RoboTurk에서 소개된 방식과 같이 iPhone 기반의 텔레오퍼레이션 시스템 (아이폰의 IMU 센서를 사용해 움직임을 추적해 EE의 pose에 그대로 반영한다고 합니다)을 사용하여 손목과 그리퍼 움직임을 기록했다고 합니다. 반면, 다지 손을 장착한 로봇들과 휴머노이드(GR-1)에 대해서는 Apple Vision Pro 기반의 새로운 텔레오퍼레이션 시스템을 구축했는데, 여기서는 VisionProTeleop 소프트웨어를 활용하여 사람의 손목과 손가락 움직임을 추적했다고 합니다.
Experiments
DexMimicGen의 성능을 검증하기 위해, 연구진은 2F 그리퍼가 장착된 task에서는 각 태스크마다 10개의 에피소드를 수집했고, 다지 손을 사용하는 태스크에서는 조작의 복잡성과 시연 수집의 시간 비용을 고려해 5개의 시연만을 수집했다고 합니다. 이후 DexMimicGen을 사용하여 각 태스크마다 1000개의 시연 데이터를 자동으로 생성했다고 합니다.
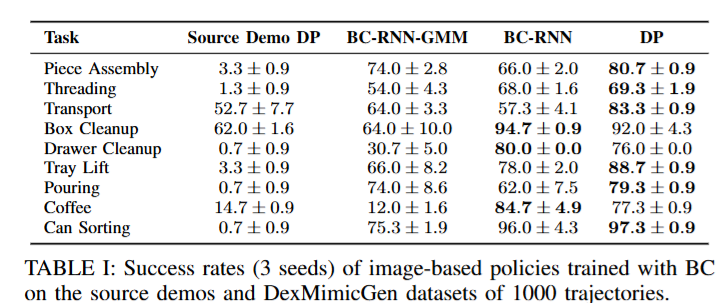
이렇게 생성된 데이터셋은 시각 정보 기반의 조작 정책 학습에 활용되었으며, 학습에는 RNN, RNN-GMM, Diffusion Policy인 세 가지 Behavioral Cloning 기반 모델이 사용되었다고 합니다. Policy의 평가는 기존 연구와 동일한 방식으로 수행되었으며, 각각의 실험은 세 가지 다른 랜덤 시드를 사용해 반복적으로 수행한 뒤, 각 시드에서 달성한 최고 성공률을 기록했다고 합니다. 아래 표를 보면 알 수 있듯 Diffusion Policy를 10개의 데모만으로 학습시켰을때와 비교해 말도 안 되는 성능을 보여준다고 하네요(당연한거 아닌가,,)
이후에는 다른 데이터 증강 기법인 DemoNoise와 비교를 진행했다고 합니다.
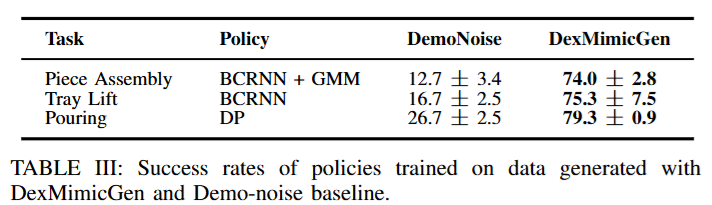
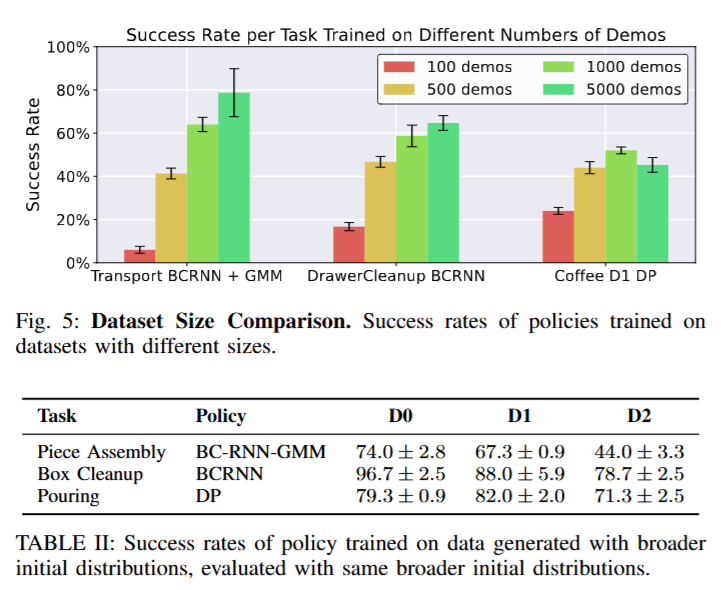
DemoNoise와 비교를 했을 때도 많은 성능 향상이 이루어 진 것을 볼 수 있습니다. 저자는 가장 두드러지게 크게 차이가 나는 요소가 Reset Distribution에 있다고 하네요. 위에서 말하는걸 빼먹은 것 같은데, 정도에 따라 D0, D1, D2로 task 초기화의 다양성의 분포를 점점 더 심화시킨다고 합니다. D0는 기본 (데모 데이터들의 분포), D1은 로봇이나 물체들의 위치 변화, D2같은 경우는 물체의 위치를 랜덤화 하는것을 넘어서 물체의 역할이 달라질 정도로 바꾼다고 합니다. 예를들어 연구실에서 진행했던 pick place cube 데이터 같은 경우 왼쪽에 큐브를 두고 오른쪽에 통을 두되 위치를 랜덤화하는것이 D1이라면 통을 왼쪽에 두고 큐브를 오른쪽에 두는 분포를 D2로 표현했습니다. 또 이렇게 만들어진 데이터의 수와 여러 Distribution이 policy에 미치는 영향을 알아보기 위해 아래와 같은 실험도 진행했다고 하네요.
Real World Experiment
Digital Twin환경을 이용해 만들어진 데이터를 시뮬레이션에서 학습해 현실로 적용해보는 실험까지도 진행했다고 합니다. 실험에 사용된 하드웨어는 GR1 휴머노이드 로봇이며, 이 로봇에는 두 개의 6자유도 dexterous hand가 장착되어 있다고 합니다. 시각 인지에는 두 대의 RealSense D435i 카메라가 사용되었으며, 하나는 로봇 머리에 부착된 1인칭 시점 카메라이고, 다른 하나는 정면에서 전체 장면을 캡처하는 3인칭 카메라로 구성되었다고 합니다.

디지털 트윈 환경은 Can Sorting 태스크를 기반으로 구성되었으며, 시뮬레이션 환경이 실제 로봇 환경과 정밀하게 일치하도록 정렬 작업이 선행되었다고 합니다. 이를 위해 RGB-D 프레임을 캡처한 뒤, Grounding DINO를 사용해 객체의 RGB 마스크를 추출하고, 마스크 내부의 깊이 값을 평균 내어 객체 중심의 (x, y) 좌표를 시뮬레이션 환경에 정확히 반영했다고 합니다. Digital Cousin이 Depth Anything을 활용한것만 다르고 객체를 찾은 뒤에 배치하는 과정과 같은 방법입니다. 총 40개의 generated data통해 Diffusion Policy를 학습시킨 뒤, 기존 소스 demonstration 4개만으로 학습된 모델과 성능을 비교했다고 합니다. 실험은 빨간 컵과 파란 컵 각각에 대해 10회의 테스트를 진행했고, 그 결과 DexMimicGen으로 학습된 정책은 90%의 성공률을 달성한 반면, 기존 모델은 0%의 성공률에 그쳤다고 합니다.
영규님 좋은 리뷰 감사합니다.
MimicGen 방식은 어떤한 작업에 대한 subtask가 있을 때, object pose를 임의로 변형한 뒤, 이에 대한 동일한 순서의 subtask를 통해 일련의 작업을 위한 시퀀스를 만들고, 이 데이터가 새로운 데이터 셋에 포함될 수 있는지를 평가해 데이터를 증강하는 방식이라 이해하였습니다. 이러한 데이터 생성 파이프라인은 MimicGen이 최초로 제안한 것인지 궁금합니다.
양팔의 경우 한팔 작업보다 더 고려해야 할 사항이 많아 subtask의 유형을 정의하고 각 task를 구분한 것이라 이해하였습니다. 그렇다면, 평가 시 특정 작업을 수행할 때, 그 안의 subtask들이 어떤 유형의 작업에 해당하는 지 판단하는 과정이 따로 있는지, 있다면 어떻게 이루어지는 지 궁금합니다.
안녕하세요 승현님, 댓글 감사합니다.
우선 첫번째 질문에 대한 답을 하자면 맞습니다. 다만 MimicGen이 object pose의 SE(3) 변환을 이용한 시연 데이터 증강 기법을 제안한 첫 연구는 아닙니다. SE(3)-equivariant하다는 점을 이용해 변환을 시키는 컨셉은 이전에도 존재했다고 합니다. 다만 여기에 subtask라는 개념을 도입하고 이를 정의한 것이 contribution입니다.
두번째 질문에 답을 하자면 현재는 사람이 직접 annotation 합니다. 작업 설계자가 task에 따라 수동으로 설정하고, 추후에 자동화를 위한 연구 포인트라고 합니다.
재밌는 리뷰 감사합니다.
저도 승현님이랑 유사한 질문을 남기고 가고자 합니다.
Q1. teleop data에서 subtask로 분행하는데에 있어 스스로 파악하는지가 궁금한건데요. 이때, 어떤 subtask인지 어느 시점까지 인지를 알아야 한다고 판단됩니다. 해당 기법에서는 어떻게 수행했는지에 대한 설명이 따로 있을까요?
Q2. 물체 중심으로 변경한다면… 제 생각엔 행동도 크게 변경되는 경우가 있을 것 같단 생각이 들어요. 이런 변화에 맞는 데이터 생성에 대한 제약은 없었는지 궁금합니다.
Q3. 객체 중심으로 생성한다고 하지만 시뮬레이터의 한계로 실제 세계의 객체와 외관적 차이가 크잖아요? 저자는 해당 이슈에 대해서는 어떻게 집고 갔는지 궁금합니다… GR00T N1의 일반화에 해당 데이터가 도움이 되었을까란 의문이 들긴 합니다.
안녕하세요 태주님 댓글 감사합니다.
A1. Teleop data에서 subtask는 모델이 스스로 파악하지 않고 human annotation으로 진행합니다. 이를 자동화 하는것이 추후 연구 포인트라고 합니다.
A2. 저자들도 물체 중심으로 변경할 때 환경에 따라, 아니면 각종 기구학적인 이슈로 언제나 의미있는 데이터가 생성되지는 않는다고 합니다. 따라서 변형된 trajectory가 실행 불가능한 경우이거나 변형된 trajectory를 따라서 작업을 마친 후 성공여부를 판단해 실패한 경우는 폐기한다고 합니다.
A3. 저도 깊은 이해를 하지는 못 했지만 GR00T-N1은 데이터 피라미드라는 컨셉을 사용해 정책 학습시 여러 구성의 데이터를 통해 다양한 유형의 특징에 의존하고 이를 전부 혼합해서 학습하기 때문에 visual적인 요소만 사용하는것이 아니라 영상에서 객체별 위치·크기·관계를 추출해 토큰화한 뒤, 이를 기반으로 행동 계획을 세운다고 이해했습니다. 따라서 trajectory가 중요한 파이프라인이기 때문에 DexMimicGen이 제공하는 수많은 trajectory가 기여를 하는게 아닌가,, 싶습니다. 추가로 GR00T-N1 학습 파이프라인에는 조명·색상·배경 augmentation과 depth 채널 보강 등이 포함돼 있어 visual gap을 추가로 줄여준다고 합니다.
안녕하세요, 영규님. 좋은 논문 리뷰 감사합니다.
소수의 데모를 활용해 대규모 imitation 학습 데이터를 자동으로 생성하는 방식이 인상적이었습니다.
이번 주차에 imitation learning 기초 강의를 들으면서, 로봇 학습에서는 Reinforcement Learning이 탐색 비용이나 보상 함수(reward function) 설계의 어려움 때문에 제약이 많아 IL이 주로 활용된다는 점을 배웠습니다. 그런데 DexMimicGen처럼 대규모 데이터를 자동 생성할 수 있다면 RL 학습에도 활용할 수 있을 것 같아 보이는데, 저자들이 IL을 대상으로 한 데이터 생성에 집중한 이유가 궁금합니다. 혹시 보상 함수 설계의 난해함 외에도 RL을 적용하지 않은 다른 이유가 있을까요?
다시 한번 좋은 논문 리뷰 감사드립니다. 🤖