안녕하세요. 박성준 연구원입니다. 오늘 리뷰는 ICLR 2025 스포트라이트에 선정된 구글 딥마인드 연구입니다. 본 연구는 dense video object captioning이라는 task를 다룬 연구입니다. 익숙한 키워드들이 포함되어 있는데 본 연구에서 처음으로 제안하는 task로 어떤 연구인지 한번 리뷰해보겠습니다.
Introduction
Dense Video Object Captioning (이하 Dense VOC or DVOC)는 비디오 내에서 객체 trajectory(궤적)을 검출하고 추적함으로 각 객체의 움직임마다 자연어로 caption을 생성하는 task로 본 논문에서 새로 제안하는 task입니다. 이 과제는 비디오에 대한 공간 및 시간적 이해를 통합하며 동시에 정확한 시각적 이해를 필요로하는 task입니다. 저자는 end-to-end로 학습 및 수행하는 Dense VOC 모델을 제안하고 단일 객체 검출, tracking(추적), captioning 모델을 통한 단계별 파이프라인보다 정확하고 일관된 결과를 산출합니다. 또한 저자는 서로 다른 모델을 disjoint 데이터로 학습(각각의 모듈을 서로 다른 데이터셋으로 학습하는 방법)을 weakly supervision으로 학습합니다. 이러한 disjoint 학습 기법은 상호보완적으로 작용하여 뛰어난 zero-shot 성능을 보일 수 있습니다. 이후 finetuning을 위해서도 사용될 수 있음을 통해 저자는 본 연구의 강력함을 강조하고 있습니다. 추가로 DVOC task를 평가할 수 있는 평가지표를 제안하고 기존의 video grounding 데이터셋을 평가에 활용합니다. VidSTG와 VLN 데이터셋에서 SOTA까지 달성하며 본 연구의 강력함을 보입니다.
대규모 데이터셋과 대규모 모델의 등장으로 자연어는 현대 인공지능 모델에서 핵심적인 출력(output) 양식으로 떠오르고 있습니다. 언어는 다양한 작업의 출력을 공통적으로 표현할 수 있을뿐만 아니라 고정된 레이블에서 벗어나 더 다양하고 일반화된 형태로 나타낼 수 있어 zero-shot 연구에서 각광받고 있습니다. 이 경향은 vision-language 연구에서도 동일하게 나타나고 있습니다. image captioning, VQA, video captioning등 다양한 vision-language 연구에서 자연어를 활용하고 있습니다. 하지만, 저자는 이러한 연구들은 많았지만, unified vision-language 모델을 통해 모두 아우르는 연구는 거의 진행되지 않았습니다. 본 연구에서 저자가 제안하는 Dense VOC는 vision-language 모델을 어느정도 통합하는 연구로 객체 검출, 다중 객체 추적, 캡셔닝을 모두 수행합니다.
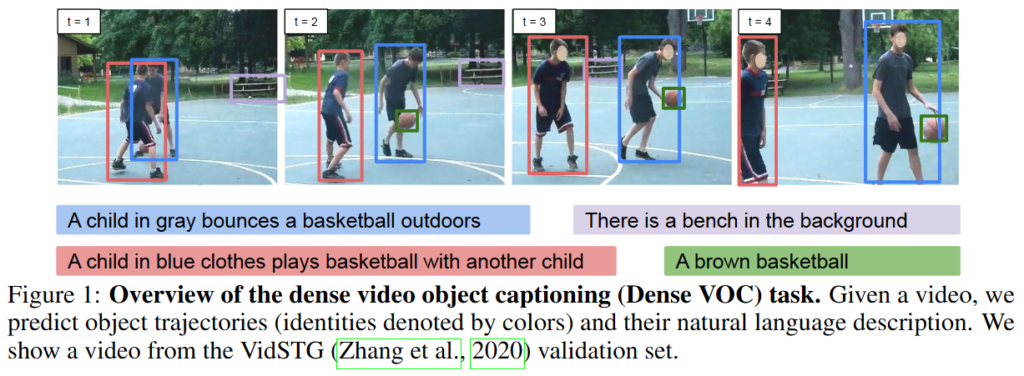
Figure 1.에서 보이는 것과 같이 Dense VOC는 object detection, object captioning, object tracking을 모두 수행하며 더 나아가 video에서도 수행 가능한 연구입니다.

Figure 2.는 Dense VOC가 수행할 수 있는 여러 능력을 보여주고 있습니다. 주어진 비디오에서 모든 객체의 궤적을 찾고 각각의 적을 captioning을 통해 자연어로 설명합니다. 저자가 제안하는 모델은 end-to-end로 학습하며, 비디오의 매 프레임 객체 영역을 예측하고 후속 tracking 모듈을 통해 객체들을 추적합니다. 마지막으로 autoregressive 디코더를 활용한 trajectory captioning 모듈을 통해 객체 궤적들의 설명을 생성함으로 Dense VOC를 수행합니다.
Dense VOC는 저자가 처음으로 제안하는 task인만큼 평가기준을 새로 정의할 필요가 있었습니다. 저자는 video grounding 데이터셋들을 활용하였으며 기존에는 비디오 내에서 주어진 문장에 해당하는 객체의 tube를 평가하는 데이터셋이지만, 각 객체의 궤적에 문장이 할당되어 있다는 점에서 저자는 Dense VOC로 활용할 수 있다고 합니다. 즉, 주어진 문장을 제공하는 것이 아니라 평가에 활용하는 것으로 Dense VOC를 평가할 수 있다고 합니다. Dense VOC는 일반적인 video grounding보다 훨씬 더 어려운 task로 캡셔닝, 검출, 추적을 모두 반영하는 평가 지표를 통해 평가됩니다. 구체적인 평가지표는 후의 Experiments에서 설명하겠습니다.
이에 따른 저자의 contribution은 다음과 같습니다.
- 저자는 Dense Video Object Captioning이라는 새로운 task를 제안합니다. 평가를 위한 평가지표를 정의하고 기존의 video grounding 데이터셋을 활용하여 평가합니다.
- 저자는 end-to-end 구조를 통해 기존에는 여러 단일 모델의 결합으로 수행해야했던 task를 수행할 수 있습니다.
- 온전한 라벨을 활용하지 않으며 서로 다른 모듈을 서로 다른 데이터셋으로 학습하는 disjoint 방식을 활용합니다.
- video grounding 과제에 대해 별다른 추가 학습 없이도 SOTA를 달성했습니다.
- Semantic Multi-Object Tracking에서도 SOTA를 달성했습니다.
Method
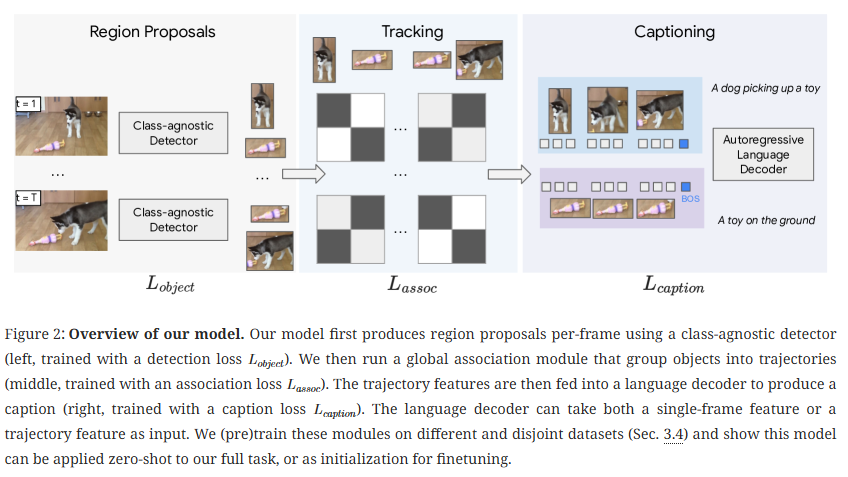
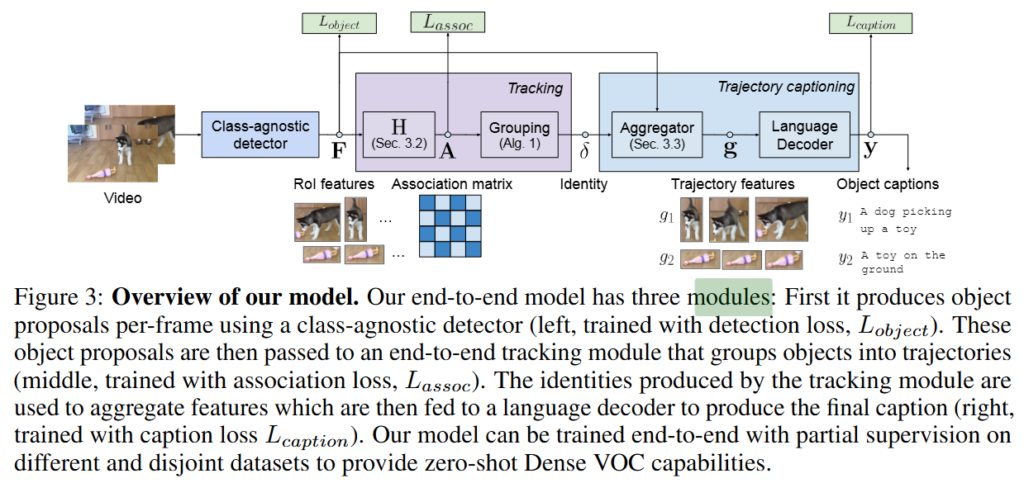
위 Figure 2와 Figure3는 각기 다른 버전?에서 모델의 구조를 설명하고 있습니다. 논문의 이해를 돕기위해 두가지 버전 모두 첨부합니다.
Background
image captioning은 이미지를 입력받아 캡션을 출력하는 task입니다. 기본적으로 인코더와 디코더로 구성됩니다. GIT 모델은 BOS(beginning of sentence)와 EOS(end of sentence) 토큰을 입력하는 autoregressive 디코더의 활용을 통해 image captioning을 수행했습니다. GRiT 모델은 GIT 모델을 다중 객체로 확장한 모델로 region proposal을 통해 특정 지역의 feature 맵을 얻고 이를 텍스트 디코더에 입력하는 것으로 캡션을 생성합니다. 문장 토큰에 대한 크로스 엔트로피 손실인 L_{cap}와 검출 손실 L_{det}을 통해 학습합니다. 검출 손실은 일반적인 box regression과 objectness 손실로 구성됩니다.
End-to-End Tracking
저자가 제안하는 모델은 먼저 매 프레임 객체가 존재할 수 있는 지역을 제안합니다. 그 다음 어느 프레임의 동일 객체에 대항하는 지를 판별하는 추적 모듈을 통해 전에 객체에 ID를 부여합니다. 구체적으로 t번째 프레임의 i번쨰 객체 영역에 대응하는 특징 벡터를 x_{t,i}로 정의하고, 모든 프레임의 모든 객체 특징을 모둔 집합을 X = \{x{t,i}\}로 정의합니다.
이 특징 집합인 X를 입력을 받아 모델은 global association matrix P \in \mathbb{R}^{N \times N}를 예측합니다. 프레임 내 객체 수를 N_t라고 한다면, X의 총 특징 개수 N=\sum_tN_t입니다. 이 특징 집합을 입력 받아 모델이 P를 예측하게 되는데 P의 구성요소인 P_{ij}는 객체 i와 j가 같은 객체의 궤적일 확률을 의미합니다. 위 그림에서 association matrix에서 색이 진한 구간이 i와 j가 같은 궤적임을 의미하는 것입니다. P는 sigmoid 연산을 거친 출력으로 트랜스포머 기반의 예측 모듈입니다. 2개의 self-attention을 통해 구하게 됩니다. 동일 궤적이라면 1, 아니라면 0으로 학습하며 GT 궤적의 일치여부는 IoU가 0.5 이상인 경우를 말합니다. 이후 이진 크로스 엔트로피를 통해 학습되며 손실은 아래와 같습니다.
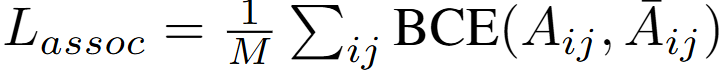
즉, 검출 손실로 학습된 class-agonistic detector를 통해 객체 후보 지역을 예측합니다. 이때 detector는 GRIT의 구조를 따릅니다. 그 후 검출 영역에 대해 같은 객체인지(궤적) 판별하여 ID를 부여합니다. ID를 부여하는 방식은 greedy 알고리즘을 사용하며 아래의 알고리즘입니다. 간단하게 설명드리면, 이진 행렬을 생성하고, 출력 ID를 초기화한 후에 가장 긴 궤적을 식별하고 ID를 부여합니다. 그 후 이미 할당된 객체를 제거 후 남은 객체 중 가장 긴 궤적을 다시 식별하고 ID를 부여합니다. 이진 행렬 내 값이 전부 없어지면 반복문을 종료하는 것으로 모든 궤적에 ID를 부여합니다.

Trajectory Captioning
모든 객체가 ID가 할당되었으므로 같은 ID의 특징들을 모아서 해당 객체 궤적의 캡션을 생성합니다. 모든 프레임을 사용하는 거는 비효율적이기 때문에 일정 간격으로 m개의 프레임을 샘플링하여 구성합니다.
Soft Aggregation: 궤적 특징들을 가중치 합으로 통합합니다. 모델이 예측한 association matrix가 궤적 내 특징들 사이의 가중치 역할을 수행하기 때문에 정규화 후 사용합니다. 정규화한 후 텍스트 디코더에 입력하여 캡션을 생성합니다. 정규화를 하는 과정에서 주변 프레임의 정보가 들어가기 때문에 추가적인 파라미터 없이 프레임별 객체의 특징을 주변 프레임 정보로 보강할 수 있다는 장점이 있습니다. 아래 수식은 정규화 방식입니다. A는 association matrix이고 F는 특징입니다.
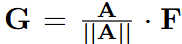
Hard Aggregation: 샘플링된 m개의 특징들을 시계열 순서로 결합하여 텍스트 디코더에 입력됩니다. 디코더는 autoregressive하게 캡션을 생성합니다. 가중치 합이 아닌 나열하여 입력하는 방힉으로 동일한 파라미터를 사용하지만, 입력하는 시각 토큰의 개수가 증가합니다.
Soft와 Hard 모두 크로스 엔트로피 손실로 학습됩니다. 저자는 데이터셋에 따라 적절하게 두가지 방법을 사용했다고하며 VidSTG에서는 soft, VLN에서는 hard를 적용했다고합니다.
Pretraining with Disjoint Subtasks
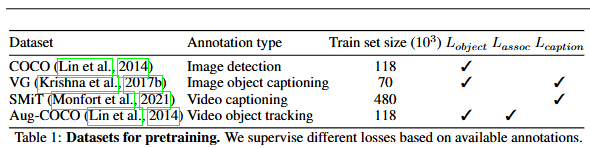
Table 1은 사전학습에 사용된 데이터셋입니다. disjoint방식은 여러 데이터셋을 통해 서로 다른 모듈을 학습하는 것을 의미하며 데이터셋을 사용할때 어떤 loss를 사용하느냐에 따라 특정 모듈을 학습할 수 있습니다. 위 Table1의 설정대로 학습했습니다. 특정 데이터셋에 특정 손실을 사용했다는 점 외에는 특별한 기술이 들어가지는 않았기에 추가적인 설명은 생략하겠습니다. 혹시 이해가 안되는 부분이 있다면 질문 남겨주시면 답변하도록 하겠습니다.
저자가 추가적인 학습 없이 Video Grounding에서도 SOTA를 달성했다고 언급했었는데, 출력 기반의 간접 접근을 통해 예측을 수행합니다. 모델이 예측한 각 객체 궤적에 대해 주어진 문장 Q를 생성할 확률 P(Q|trajectory)를 계산하고, Q의 likelihood를 계산하여 score를 곱하는 것으로 예측을 수행합니다. 수식은 아래와 같습니다.
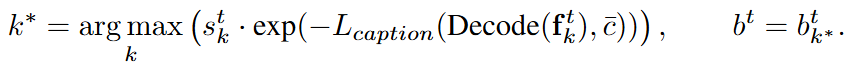
Experiments
평가에 활용한 데이터셋은 VidSTG와 VLN입니다. 두 데이터셋은 원래는 video grounding을 위한 데이터셋으로 비디오마다 객체와 그 객체에 대한 캡션이 존재합니다. 기존에는 둘을 grounding을 위해 사용되었지만, 저자는 이를 Dense VOC를 위해 활용합니다.
Evaluation Metrics
저자는 Captioned-HOTA (CHOTA)를 사용합니다. HOTA는 Higher Order Tracking Accuracy로 최근 다중 객체 추적 분야에서 널리 사용되는 지표로, 검출 정확도(DetA)와 Association 정확도(AssA) 두 요소를 기하평균하여 활용하는 방법입니다. DetA는 IoU 매칭을 기반으로 한 정확도를 의미하고, AssA는 올바르게 검출된 객체들의 ID alignment를 평가한 값입니다. Dense VOC는 여기에 caption이 추가됩니다. CapA(Caption Accuracy)는 올바르게 검출+추적된 객체에 대해 캡션이 얼마나 일치하는 지를 평가하는 지표로 METEAOR, CIDEr, SPICE라는 기존 캡션 평가에서 활용하는 3가지 평가 점수를 0~1로 정규화한 후에 평균한 값입니다. 최종적으로 CHOTA는 DetA, AssA, CapA를 기하평균한 값입니다. 즉, CHOTA=(DetA \times AssA \times CapA)^{1/3}입니다.
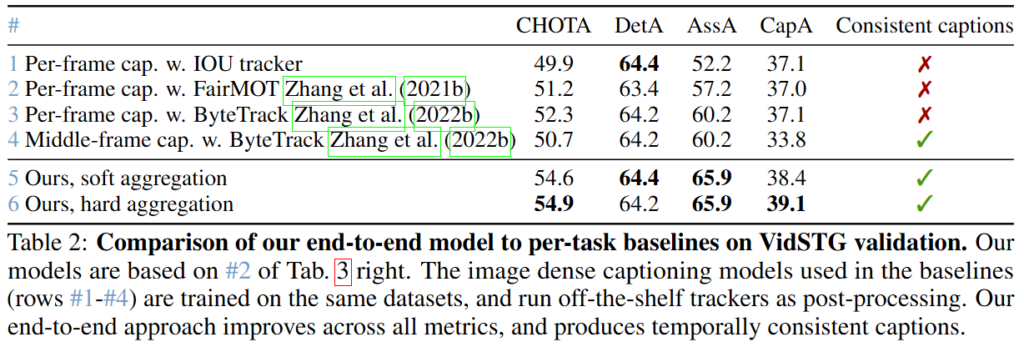
VidSTG 검증셋에서의 저자가 제안하는 모델의 성능으로 end-to-end 모델이 아닌 각 단계를 기존 모델로 수행한 성능과의 비교입니다. end-to-end로 학습하여 수행하는 저자의 모델이 각각의 단계를 단일 모델로 수행하는 것보다 더 좋은 성능을 보이는 것을 확인할 수 있습니다.
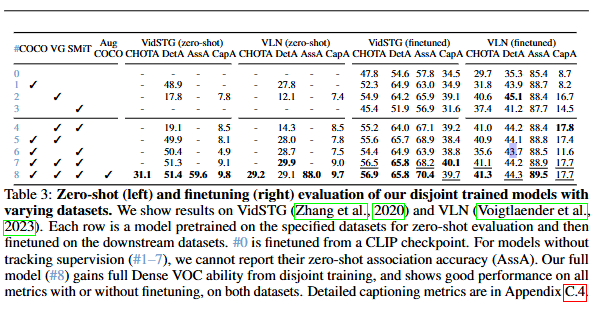
표3는 저자가 제안하는 모델을 VidSTG와 VLN 검증셋에서 평가한 성능입니다. #8이 저자가 제안하는 최종모델의 성능입니다. 먼저, zeroshot에서 COCO로 학습하면 검출 성능이 높지만, Caption 성능이 없고, VG로 학습하면 캡션 능력은 생기지만, 도메인 차이로 인해 검출 성능이 떨어지게됩니다. 하지만, SMiT를 추가로 결합하면 비디오 문장 생성 능력을 추가하기 때문에 성능이 많이 개선되고 마지막으로 Aug-COCO을 추가하는 것으로 성능이 한단계 더 상승되어 최종 모델의 성능을 얻을 수 있습니다. Finetuning을 하면 당연하지만 성능이 개선됩니다. #0 CLIP에서 finetuning을 한 것보다는 약 10퍼센트 가량의 성능 개선을 보이며 저자의 방법이 효과적임을 보이고 있습니다. 다양한 데이터셋으로 disjoint 학습을 하는 것이 효율적임을 보여주는 실험결과입니다.

마지막으로 정성적 결과입니다. 비디오 내에 존재하는 객체를 검출하고 객체의 궤적을 추적할 수 있으며 동시에 객체의 행동에 대한 캡션을 생성합니다. 정성적 결과에서 확인할 수 있듯이 하나의 객체 궤적에 대해 하나의 캡션을 생성하기에 동일한 객체가 여러 행동을 하더라도 따로 묘사할 수는 없다는 단점이 존재합니다. 또한, 저자는 200프레임이 넘어가는 긴 영상에 대해서는 대응이 어렵다고 한계점을 말하고 있습니다. 이는 추후에 시간축을 늘리거나 메모리 효율적 구조를 도입함으로 개선할 예정이라고합니다.
구글의 연구라서 JAX로 코드가 공개되어있고, 가중치 체크포인트는 추후 공개예정이라고하네요. 나중에 공개되면 한번 성능이 얼마나 좋은지 확인해보고 싶네요.
감사합니다.
좋은 리뷰 감사합니다. 이제 간단한 task가 어느정도 정복되다 보니 이를 기반으로 점점 복잡한 scene / video understanding task를 수행하려는 흐름이 보이네요. 해당 task도 해당 맥락에서 제안된 것 같습니다.
질문이 잇는데, trajectory를 예측하는 부분에 대해서 잘 이해가 가지 않습니다. tragectory를 모델링하는 tracking / association module 부분에서 association matrix가 모든 region proposal에 대해 어떤 물체인지 예측을 하고 동일한 클래스(ID)면 tracking된다고 보는 것인가요? 이렇게 되면 모든 frame에 segmentation mask를 만들어야 하니 연산 측면에서 비용이 높이져 이렇게 수행되는것 같지는 않은데, 설명해주시면 감사하겠습니다.
안녕하세요 허재연 연구원님 좋은 댓글 감사합니다.
비디오의 매 프레임 객체를 검출하고 각 프레임에 있는 객체들 중 같은 객체가 어떤 객체인지 알 수 있으면, 비디오에서 객체가 어떻게 이동하는지 알 수 있습니다. 이렇게 객체의 움직임을 파악하는 것을 tracking이라고 합니다. 따라서 tracking에서 중요한 점은 같은 객체를 동일한 ID로 매핑하는 과정이고, 그 과정이라고 이해해주시면 될 것 같습니다. 즉, trajectory를 예측하는 과정에서 segmentation mask는 필요하지 않습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰감사합니다.
Trajectory Captioning의 Soft Aggregation 부분에 대해 질문이 있습니다. 객체의 궤적 특징을 추출하고, 이를 단순히 합하는 것이 아니라 association matrix를 통해 가중합을 수행한다고 하셨는데요. 이때 association matrix를 활용하면 효율성 외에도 어떤 추가적인 장점이 있을지 궁금합니다
안녕하세요 성준님 좋은 리뷰 감사합니다.
예전에는 Image classification과 retrieval 테스크의 동시 학습도 어려웠던것 같은데, Table2를 보니 region proposals, traking, captioning과 같은 다양한 테스크가 동시에 학습되며 서로 긍정적으로 영향을 미치는것 같아 신기합니다.
joint 학습이 이렇게 잘 되는 이유가, 네트워크의 순차적 구조 region proposals, traking, captioning 덕분이 아닐까도 생각하는데요, 그렇다면 영상 내 움직임 정보가 비교적 중요하지 않은 데이터 도메인에서는 해당 방법론이 잘 동작하지 않을 것 같습니다. (ex 줄넘기, 제자리 뛰기 같은 움직임이 많은 경우)
위에 대해 혹시 어떻게 생각하시는지, 그리고 테스크 간 순차적으로 수행하는 프레임워크에 대한 논문의 설계의도가 추가적으로 기술되어있는지 궁금합니다.
감사합니다.