안녕하세요, 허재연입니다. 지난주에 이어서 open-vocabulary scene graph generation(OV-SSG) 논문을 들고 왔습니다. SGG의 long-tailed distribution 문제를 LLM을 활용한 데이터 증강으로 완화한 논문으로, 해당 분야에서 나름 인용 수가 높아서 읽어보게 되었습니다. 논문 리뷰 바로 시작해보겠습니다.
Introduction
Scene Graph Generation은 실세계 영상에서 각 객체들을 탐지하고 이들 간 관계를 예측하는 task입니다. detection, classification과 같은 단순한 task와 비교해 더 높은 수준의 scene understanding을 가능하게 하기에 visual question answering, image captioning, 3D scene understanding과 같은 보다 고차원적인 작업을 하는 데 활용될 수 있습니다. 이 때 visual relationship은 <subject-predicate-object>의 형태로 예측을 수행합니다.
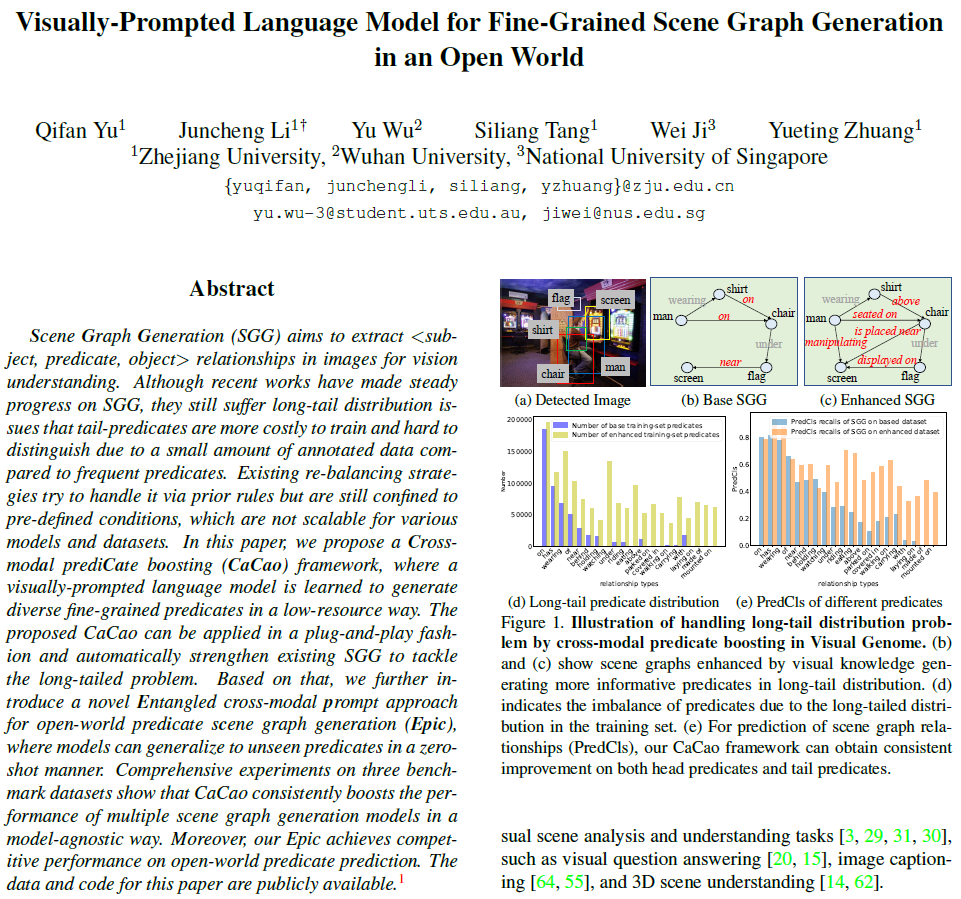
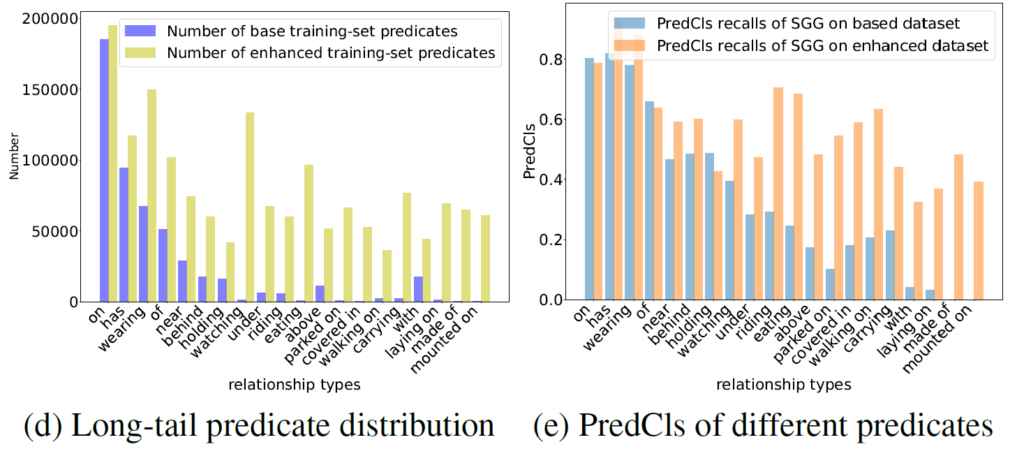
해당 분야는 predicate class의 long-tailed distribution 문제를 겪고 있습니다. 데이터셋의 분포 자체의 문제이기에 이를 고려하지 않는다면 정보가 부족하지만 빈도가 높은 클래스들로 예측이 편향되는 문제가 생길 수 있죠. Visual Genome 데이터셋의 경우아래 (d)와 같이 상위 20%의 predicate class가 전체 샘플의 거의 90%를 차지하며, 나머지 tail부분의 fine-grained한 predicate들은 학습 시 그 데이터 양이 부족합니다. 이 때문에 아래 (e)처럼 tail 부분에 대한 PredCLS recall이 head와 비교해 크게 떨어집니다.
저자들은 사전학습된 언어 모델의 지식을 활용해 scene graph에서 tail predicate를 보다 풍부하게 활용할 수 있는 Cross-modal prediCate boosting (CaCao) framework를 제안합니다. 사전학습된 언어 모델이 다양한 relation knowledge를 내포하고 있긴 하지만 실제로 이런 장면 그래프를 만드는데 이 지식을 활용하는게 간단하지는 않다고 합니다. 그 이유는 다음과 같습니다.
첫째로, LLM은 시각적 인지 능력이 없기에 언어 지식을 시각적 지식 기반의 predicate prediction으로 적용하는데 모달리티 격차가 크다고 합니다. Vision-Language Pretrained(VLP)모델을 사용할 수도 있지만, 대부분의 VLP 모델들의 경우 image-text pair 간 contrastive learning으로 학습되어 보다 세밀한 predicate category를 생성하는 섬세한 언어적 능력이 부족하다고 합니다.
둘째로, 각 predicate에는 다양한 유의어 / 동의어가 있어서 동일한 의미이지만 다르게 표현할 수 있습니다(ex : he “walks through” / “is passing through” / “passed by” a street는 모두 동일한 의미이죠). 이런 의미적 유의/동의어를 고려하지 않으면 자칫 관계를 예측하는 언어 모델이 monotonic predictions(단조롭게 하나의 표현만을 반복해서 예측하는거라고 하네요)에 빠질 수 있다고 합니다. 이를 semantic co-reference 문제라고 합니다.
이 문제들을 해결하기 위해 저자들은 먼저 새로운 cross-modal prompt tuning법을 제안합니다. 이를 통해 언어 모델이 visual context를 섬세하게 포착하고, masked language modeling기법으로 정보성이 높은 predicate을 예측할 수 있게 합니다. semantic co-reference 문제에 대해서는 prompt tuning을 위해 적응적인 semantic cluster loss를 도입하여 다양한 predicate 표현들의 의미적 구조를 모델링하고, boosting 과정에서 특정 관계가 과도하게 증폭되지 않도록 분포를 조정해서 보다 더 다양하고 균형 잡힌 분포를 만들어내었습니다. 이에 추가적으로 시각 프롬프트 기반 언어 모델이 생성한 정보성 있는 관계들을 사용하여 기존 데이터셋을 확장하는 fine-grained predicate-boosting 전략도 함께 제안합니다. 위의 그림에서 (e)를 보면 제안하는 CaCao기법이 SOTA 모델들의 성능을 plug-and-play 방식으로 개선하고, 이 때 대부분 predicate에 대해 PredCLS(관계 분류)성능이 파란보다 보라색 막대 기준 약 30%이상 일관되게 증가함을 확인할 수 있습니다.
저자들은 CaCao가 SGG에서 long-tail 문제를 완화할 수 있을 뿐만 아니라 open-world로도 잘 일반화 될 수 있다고 어필합니다. 기존의 고정된 predicate classification layer를 category-name embedding으로 교체하고 CaCao가 생성한 다양한 관계 표현을 사용해 보다 일반적이며, 전이가 가능한 predicate embedding을 학습시킵니다. CaCao뿐만 아니라 추가적으로 open-world predicate 기반의SGG를 수행하기 위해 Entangled cross-modal prompt approach for open-world predicate scene graph generation (Epic)을 제안하는데, 이 기법은 cros-modal prompt가 predicate representation을 조정해서 Scene Graph 모델이 추상적인 interactive semantics를 인지하도록 유도합니다. 별도의 GT annotation을 전혀 사용하지 않고 CaCao 프레임워크가 생성한 정보성 높은 관계 표현들만으로 Epic에 open-world predicate learning에서 높은 성능들 달성했다고 합니다.
저자들이 주장하는 contribution을 정리하면 다음과 같습니다 :
- 우리는 Cross-modal prediCate boosting (CaCao) framework를 제안한다. 이는 시각 프롬프트 기반 언어 모델을 학습하여 fine-grained 한 predicate를 기존 데이터셋에 풍부하게 추가할 수 있도록 설계하였다.
- CaCao는 기존 SOTA 방법론들에 plug-and-play 방식으로 쉽게 적용이 가능하며, 3가지 데이터셋 벤치마크에서의 실험 결과 일관적인 성능 향상을 보여주었다. 이는 대규모 사전학습 언어 모델을 통해 데이터를 자동으로 boosting하는 방향성을 제시한다.
- 추가적으로, 우리는 Entangled cross-modal prompt approach for open-world predicate scene graph generation (Epic) 기법을 도입하여 unseen 관계들에 대한 CaCao의 확장 가능성을 확인하여, 실험을 통해 그 효과를 검증하였다.
Method
아래 Figure 2에서 확인할 수 있듯, Cross-modal prediCate boosting(CaCao) 프레임워크는 다음 3가지 요소로 구성됩니다.
- 먼저, visually-prompted language model은 사전학습된 언어 모델의 언어 지식을 최대한 활용하여, fine-grained predicate 생성하는데 사용합니다.
- 다음으로, 시각 프롬프트 기반 언어 모델(visually-prompted language model)에서 발생할 수 있는 의미적 동의 표현 문제(semantic co-reference)문제를 완화하기 위해 adaptive semantic cluster loss를 도입합니다. 이를 위해 다양한 predicate 표현을 모델링하고, 관계 보강 과정에서 분포를 적응적으로 조정하게 됩니다.
- 마지막으로, fine-grained predicate boosting 단계에서 위에서 생성된 보강된 관계(predicate) 표현들을 활용해 long-tail 분포 문제를 model-agnostic하게 완화하게 됩니다. 이 때, Epic이 open-world SGG가 가능하도록 CaCao가 다양한 predicate을 제공할 수 있습니다(Epic 동작은 뒤에서 살펴보겠습니다.)
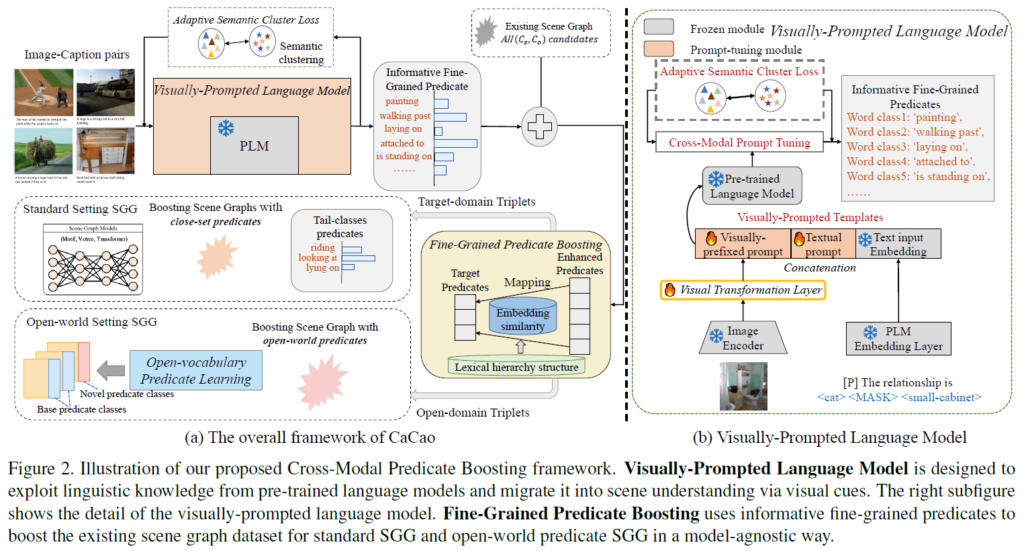
Visually-Prompted Language Model
사전학습된 언어 모델이 보유한 언어 지식을 활용해 fine-grained predicates를 보강하고, 언어 모델이 시각 정보를 인지할 수 있도록 visual prompt를 활용합니다. Figure2(a)에서 visually-prompted language model module에서 확인할 수 있습니다.
Visually-Prompted Templates
언어 지식과 시각 정보 간에는 modality gap이 있어서 언어 모델은 scene graph 내의 시각적 관계를 직접적으로 인식할 수 없습니다. 저자들은 visual semantic 정보를 효과적으로 활용하기 위해, 시각 정보와 텍스트 정보를 모두 포함하는 시각 프롬프트 기반 템플릿(Visually-Prompted Templates)을 활용합니다. 저자들이 고안한 템플릿은 다음 형식으로 구성됩니다.
- X = “[visually-prefixed prompts] [P] [SUB][MASK][OBJ]”
여기서 [visually-prefixed prompts]는 visual feature가 변환 레이어 {h}_{θ}를 거쳐 생성된 이미지 기반 토큰이고, [P]는 text prompt engineering을 위한 learnable text prompt입니다. 학습 과정에서 이 visually-prompted template을 freeze한 언어 모델에 입력해서 MASK 위치에 올바른 predicate를 예측하도록 합니다. 이 때 learnable text prompt [P]와 visual projection layer {h}_{θ}만 학습된다고 합니다.
Cross-Modal Prompt Tuning
Cross-Modal Prompt Tuning은 visually-prompted templates를 최적화해서 X로부터 cross-modal context를 기반으로 마스킹된 위치에 올바른 fine-grained predicate를 예측하는 것을 목표로 합니다. 이를 위해서 웹에서 무작위로 8만개의 image-caption 쌍을 수집합니다(ex : CC3M, COCO caption ..). 이렇게 수집된 데이터에는 약 2,000개 정도의 predicate가 포함되어 있는데, 이 중에서는 on, near과 같이 정보성이 부족하고 단순한 predicate가 많이 포함되어 있습니다. 휴리스틱하게 설정한 필터링을 통해 정보가 적거나(on, near), 너무 빈도가 적은 술어들을 자동으로 걸러내고 결과적으로 실세계의 대부분 상황을 포괄할 수 있는 관계 카테고리 585개를 확보하였다고 합니다. 학습 과정에서는 softmax classifier를 사용해 마스킹된 위치의 predicate token을 예측합니다. 우선 각 predicate 카테고리{Y}_{i}를 나타내는 K-차원 원핫벡터 ϕ({y}_{i})를 정의하고(K는 총 predicate category 수), 입력 {X}_{i}에 대해 마스킹된 위치에서의 확률 분포 ψ와, 이에 해당하는 label ϕ를 기반으로, visually-prompted templates 및 predicate 분류기를 (1)번 수식처럼 Cross-Entropy Loss로 최적화합니다.
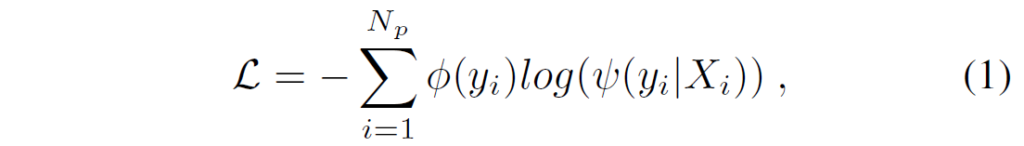
수식에서 {N}_{p}는 prompt tuning에 사용된 predicate 수입니다. 참고로, 이 학습 과정에서는 랴혁ㄷ2(b)에서 확인할 수 있듯 visual-linguistic projection layer의 파라미터만 업데이트됩니다.
Adaptive Semantic Cluster Loss
여전히 co-reference 문제가 남아있기에 이를 고려한 학습 요소를 추가해야 합니다. 이에 저자들은 동의어 기반의 클러스터링 구조와 문맥 인식 레이블(context-aware label)을 활용하는 adaptive semantic clustering loss (ASCL)을 추가로 설계하였습니다. 이 loss는 관계의 분포에 따라 과도하게 boosting되는 특정 관계 카테고리를 억제해서 CaCao 내에 더 다양한 관계 분포가 생성되도록 유도합니다.
복잡한 장면 내에서 <subject-predicate-object> triplet 간 의존성을 고려해서 각 predicate는 해당 triplet의 BERT 임베딩 벡터들의 평균으로 표현합니다. 이후에 K-menas clustering을 적용해 predicate들을 군집화한 뒤 각 관계 간 similarity threshold를 기준으로 초기 중심점 개수를 설정합니다. 학습 과정에서는 같은 클러스터 내에 있는 관계들에 대한 penalty를 줄이기 위해 semantic-synonym label을 적용해 서로 강하게 연관된 predicate들이 과도하게 억제되는 것을 방지합니다. loss는 다음과 같이 context-aware label과 semantic-synonym label로 조정됩니다.
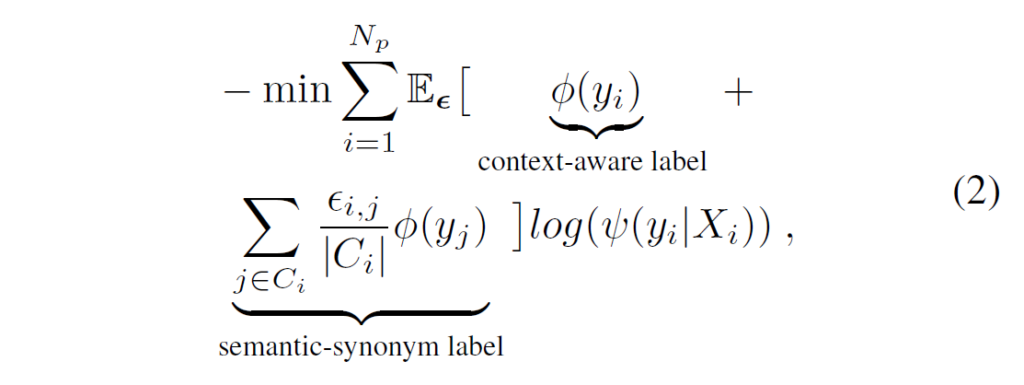
{ϵ}_{i,j}는 동일 클러스터 {C}_{i}에서 predicate {y}_{i}와 다른 related predicates {y}_{j}와의 correlation coefficient입니다.
저자들은 고정된 방식의 predicate 증강 기법이 관계들의 동적인 분포 변화를 충분히 반영하지 못해서 일부 특정 관계(predicate)가 과도하게 증폭되고 결과적으로 전체 다양성이 훼손되는 문제를 관찰하였다고 합니다. 이를 해결하기 위해 학습 과정에서 각 관계의 등장 비율에 따라 boosting 비율을 동적으로 조절할 수 있도록 adaptively re-weighting factor를 설정하였다고 합니다. 이를 통해 ASCL loss 내에서 각 관계 카테고리에 대한 가중치를 수식(3)과 같이 조정하였다고 합니다.
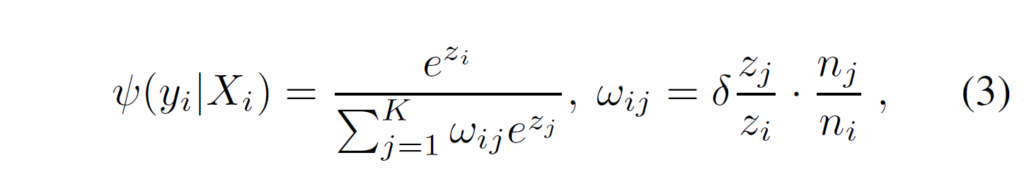
{z}_{i}와 {n}_{i}는 각각 관계 카테고리 {Y}_{i}에 대한 예측 logit과 초기 샘플 수입니다. {w}_{i,j}는 index i, j의 target boosted predicate 사이의 동적 분포에 따른 adaptively re-weighting factor라고 합니다. 특정 predicate가 충분히 boosting되었을 때 {w}_{i,j}를 감소시켜 해당 관계의 추가 증폭을 억제해서 이를 통해 생성된 predicate의 분포의 밸런스를 유지하고 다양성을 유지하게 하기 위함이라고 하네요.
Fine-Grained Predicate Boosting
CaCao를 통해 보다 세분화된 predicate를 얻을 수 있지만, CaCao에서 생성된 관계들과 장면 그래프 내 기존 관계들 간의 카테고리 불일치 때문에 target scene graph에 직접적으로 적용하는게 쉽지 않다고 합니다. 이를 해결하기 위해 저자들은 추가적으로 fine-grained predicate boosing stage를 적용합니다. 이 단계에서는 open-world에서 생성된 관계를 기존 scene graph 카테고리에 매핑해, boosting된 관계들이 기존 scene graph에 원활히 적용 및 정렬되도록 합니다. 어휘적 분석(lexical analysis)을 기반으로 목표 관계 카테고리에 대한 간단한 계층 구조를 구성한 뒤, 각 계층 수준에서 triplet-level embedding의 코사인 유사도를 활용하여 fine-grained predicates를 해당 목표 카테고리에 매핑합니다. 이후 매핑된 후보 관계들 중에서 가장 적게 등장한 카테고리를 최종 predicate로 선택합니다. 이 때 원래 의미를 보존하기 위해 scene graph 내에서 unlabeled 객체 쌍 중에서 겹치는 경우에만 boosting을 적용합니다.
제안하는 CaCao를 기존 SGG에 적용하면 추가적인 학습 데이터를 생성해서 보다 세분화된 predicate boosting을 통해 데이터셋을 확장할 수 있습니다. 저자들은 최종적으로 확장된 데이터셋을 사용해 SGG모델을 재학습하여 더 균형 잡힌 예측을 달성하였다고 합니다. 이 때 learning problem은 다음과 같이 나타낼 수 있습니다.
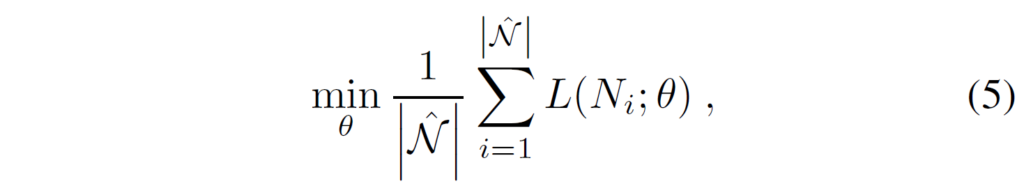
L(Ni; θ) 는 Scene Graph Generation 학습 과정에서의 loss를 의미하고, N hat은 CaCao로 증강한 데이터를 의미합니다.
Open-World Predicate SGG
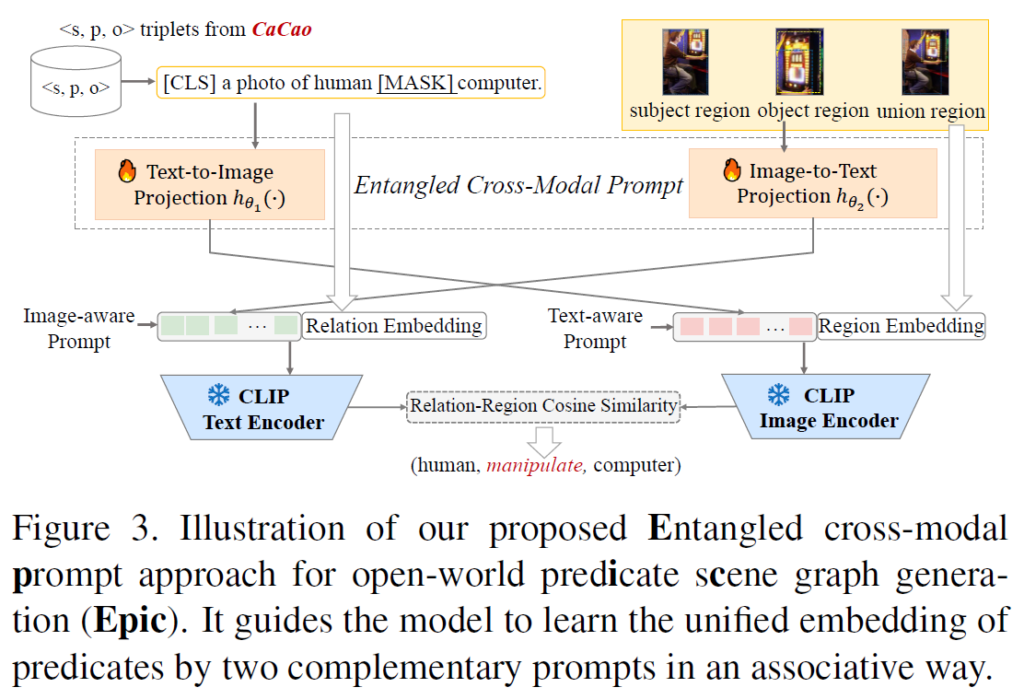
저자들은 open-world predicate SGG를 위해 추가적으로 Entangled Cross-Modal Prompt(Epic) 기법을 제안합니다. 이를 CaCao와 결합하여 문제를 open-world 세팅으로 확장하였습니다. Epic 과정은 아래 Figure 3에 나와있습니다.
기존의 closed-vocabulary/world 세팅을 open-world, open-vocabulary 세팅으로 변환하는 가장 쉬운 방법은 기존의 fixed classifier를 CLIP등을 활용한 unified embedding으로 교체하는 것이죠. visual encoder로부터 생성된 region embedding x와, text encoder로 생성한 predicate embedding 집합 {p}_{i}, 그리고 정답 관계 임베딩 {p}_{*} 에 대해 open-world predicate 기반 SGG loss를 다음과 같이 정의합니다.
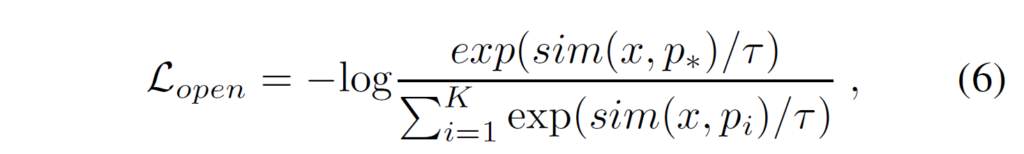
Entangled Cross-Modal Prompt
predicate semantics와 image region은 시각적, 텍스트 context와 연관되어 있습니다. 예를 들어 Figure 1(a)에서 “man on chair”와 “shirt on chair” 은 동일한 영역에 해당하더라도 서로 다른 의미를 갖습니다. 또, “man”과 “horse”는 시각적 문맥에 따라 “riding” 또는 “holding”이라는 전혀 다른 관계로 연결될 수 있습니다. 저자들은 이 부분에 집중하여 text encoder와 image encoder 각각에 entangled cross-modal prompt를 도입하였습니다. 그림 3에서 확인할 수 있듯 {h}_{θ1}와 {h}_{θ2}는 각각 text-to-image, image-to-text projection을 나타냅니다. 이때 predicate probability는 다음과 같이 계산됩니다.
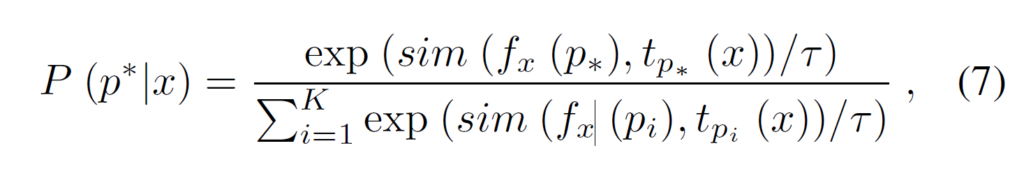
수식(7)에서 {f}_{x}({p}_{i})는 text-aware prompt {h}_{θ1}({p}_{i}) 기반의 conditional region embedding이고 {t}_{pi}(x)는 image-aware prompts {h}_{θ2}(x) 기반의 conditional relation embedding입니다.
Experiment
실험에서는 기본적으로 기존 연구들의 세팅을 참고하여 VG-50 벤치마크를 사용하여 Scene Graph Generation(SGG) 성능을 평가하엿습니다. VG-50은 50개의 관계 클래스(predicate classes)와 150개의 객체 클래스(object classes)로 구성된 데이터셋입니다. 이미지 인코더로 ViT로 사용했고, 임베딩 size 768의 transformer layer를 설정해서 visually-prefixed prompt를 생성해 사용하였습니다. 타겟 관계를 예측하는 언어 모델로는 BERT를 사용했다고 합니다. detector로는 사전학습된 Faster RCNN을 사용하였고, 이때 백본은 FPN ResNet101을 썼다고 하네요. open-world setting에서 CLIP을 백본으로 사용해서 region embedding과 predicate embedding을 추출해 사용했다고 합니다.
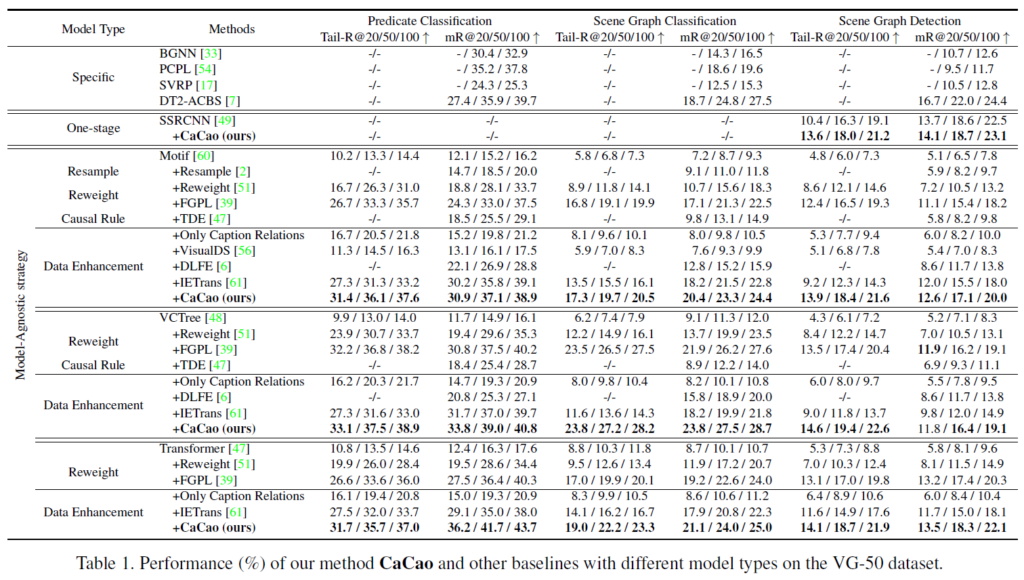
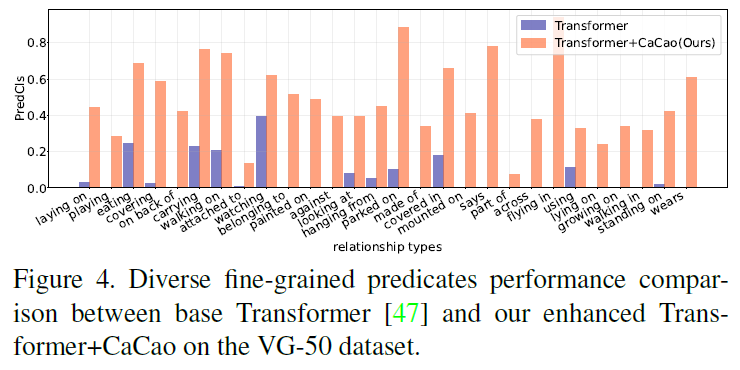
제안하는 CaCao framework는 다양한 베이스라인 모델에 적용이 가능합니다. 평가를 위해 Motif, VCTree, Transformer 백본의 기존 모델들에 적용해봤다고 하네요. 모델 구조가 서로 다름에도 CaCao는 모든 baseline 모델의 mR@K 성능을 일관적으로 향상시켰다고 합니다. 이에 대해 저자들은 CaCao가 관계 표현의 편향 문제를 효과적으로 완화하면서도, 다양한 SGG 모델과의 호환성이 뛰어나다고 어필합니다. predicates 분포에 대한 성능 이점은 Figure 4,5에서도 확인할 수 있습니다.
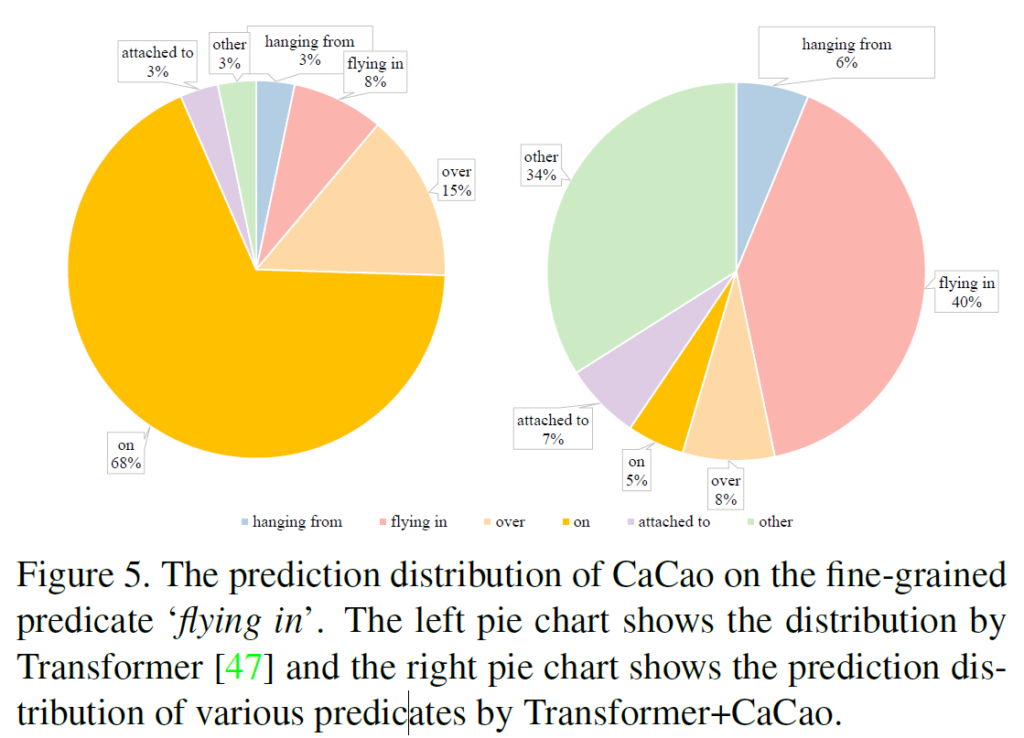
아래 Table 2는 CaCao와 다른 베이스라인 기법들의 대규모 데이터셋 실험 결과를 요약한 것인데, 제안하는 기법이 전반적으로 좋은 결과를 내는 것을 확인할 수 있습니다.
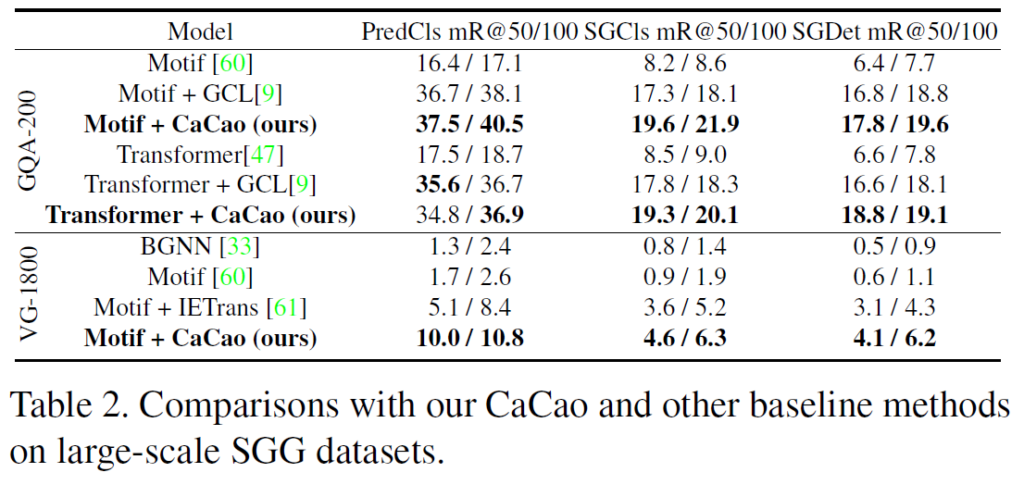
Table 3에서는 open-world predicate의 확장을 고려해 CaCao+ Epic 조합의 오픈 월드 세팅에서의 성능을 평가하였습니다. base, novel, total class에 대해 predicate 을 예측하는(PredCLS) 세팅에서, 실험적으로 Cacao+Epic이 굉장히 좋은 결과를 보였습니다.
언어 모델로 데이터를 증강해서 long-tail 문제를 완화하고 각 모달리티 특정을 정렬하는 모듈을 통해 open-world로 확장하는 방법론을 살펴보았습니다. SGG에서 각 object나 predicate을 계층적으로 어떻게 모델링할지 고민하고 있는데, 이 논문의 연구 흐름을 참고하면 좋을 것 같네요.
안녕하세요 재연님 좋은 리뷰 감사합니다.
Cross-Modal Prompt Tuning으로 585개의 predicate을 넓게 학습했을 때,평가 단계에서 vg50처럼 평가 기준이 되는 제한된 관계 목록만을 사용해야 할 경우, 모델은 어떤 방식으로 예측 결과를 해당 목록 안에서만 선택하도록 동작하나요?
감사합니다.
CaCao로 얻은 fine-grained predicate들은 말씀처럼 카테고리 불일치 때문에 target scene graph에 직접적으로 적용하기 어렵습니다. 이를 위해 fine-grained predicate boosting 단계에서 open-world로 생성된 관계를 기존 scene graph 카테고리에 매핑합니다.
이 때 어휘적 분석(lexical analysis)을 기반으로 목표 관계 카테고리에 대한 간단한 계층 구조를 구성한 뒤, 각 계층 수준에서 triplet-level embedding의 코사인 유사도를 활용하여 fine-grained predicates를 해당 목표 카테고리에 매핑합니다. 이후 매핑된 후보 관계들 중에서 가장 적게 등장한 카테고리를 최종 predicate로 선택합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
Fine-grained predicate-boosting 전략에서 질문이 있습니다. 해당 방법에서 매핑된 후보 관계들 중에서 가장 적게 등장한 카테고리를 최종 predicate로 선택한다고 하셨는데, 자주 등장하는 단어는 텍스트 도메인 관점에서 다양한 상황을 커버할 수 있는 단어로, 학습에서 가중치를 무조건 줄이는것이 좋지 않을수도 있다고 생각했습니다.
그럼에도 해당 방법이 잘 동작하는것은 자주 등장하지 않는 단어를 우선으로 학습하더라도 on과 같은 포괄적 단어(=long-tailed의 상위 분포에 해당하는 단어)가 많아 충분히 학습할 수 있기 때문으로 이해하면 될까 궁금합니다.
감사합니다.
제 의견으로는, 일단 해당 부분이 너무 자주 등장하고 간단한 predicate보다 fine-grained한 다양한 predicate를 boosting하는것이 목적이기 때문이지 않나 싶습니다. 또한 빈도가 적은 술어들을 이미 앞에서 한번 걸러주었기 때문에, 적은 후보를 선택해도 학습과 추론에 부정적인 영향을 덜 줄 수 있을 것 같습니다(후보를 선택하는 방법은 뭔가 실험적으로 성능이 좋은 전략을 선택하지 않았을까 추측되긴 하는데 관련 언급은 없네요)