안녕하세요 류지연입니다.
이번에도 Scene text recognition을 다루는 논문을 리뷰해보겠습니다. 지난주에 DiG를 리뷰했었는데요 사전학습된 인코더에 이 논문의 디코더를 붙여 파인튜닝을 해 recognition을 수행하더군요. TESTR에서의 recognition 방법과 조금 달라 궁금한 마음에 읽고 리뷰까지 하게 되었습니다. 이 논문을 조금 소개드리면 전체적인 구조는 Transformer와 거의 흡사합니다. 그리고 TESTR에서는 non-autoregressive하게 text recognition이 되었지만 이 논문에서는 Transformer의 디코더에 더 가깝습니다. suquential하게 각 character를 예측하는 점에서 다릅니다.
그럼 이제 리뷰하겠습니다.

Introduction & prior studies
본 연구는 STR (Scence text recognition) task를 다룹니다. natural scene 이미지에서 텍스트가 있는 부분만을 크롭한 patch 단위의 이미지에 대해서 character sequence를 예측하는 테스크입니다. 보통 image의 특징을 추출하기 위한 CNN과 RNN의 character sequence generator를 결합한 인코더-디코더 구조로 설계한 모델을 가지고 학습하는 것으로 해당 테스크를 수행했었습니다.
하지만 이런 기존 방법들은 텍스트가 horizontally하게 나열돼 있는 경우에 최적화된 방법으로 arbitrary 텍스트를 recognize하는 데에는 한계가 있었습니다. (기존 연구는 CNN을 타고 나온 2D의 이미지를 height 방향으로 압축 해 1D sequence로 변형한 다음 recognition을 수행하는 식이었습니다) 실제 세계에는 이런 arbitrary shape의 text가 난무하기 때문에 이런 문제는 꼭 해결되어야 했습니다. 실제 해당 분야의 연구자들 사이에서도 해당 문제를 해결하는 것을 중요하게 여겼는데요 이는 irregular shape의 텍스트 모음 벤치마크 데이터셋이 만들어진 데에도 영향이 있지 않았나 싶습니다.

첫번째 방법은 사전에 어떤 transformation을 적용할지에 대한 것을 직접 정의해줘야 한다는 번거로움과 정의된 transformation만으로도 normalized되지 않는 arbitrary한 텍스트가 남아있을 수 있다는 한계가 있습니다.
2D feature maps으로 부터 sequential한 character를 예측하는 두번 째 방법의 경우에도 여러 한계가 있었습니다. 여전히 horizontal한 텍스트에 적합하도록 설계돼 있거나, 과하게 복잡해지거나, 각 character를 아우르는 바운딩 박스를 필요로 한다거나 하는 등의 한계가 있었습니다.
저자는 이 분야에서 STR를 단순한 방법으로 해결하는 것이 필요하다고 생각했답니다. 그리고 본 논문은 2D self-attention 방법론을 채택해 arbitrary text를 포함한 모든 텍스트에 대한 recognition 성능을 높이는 모델인 Self-Attention Text Recognition Network(이하 SATRN)을 제안합니다.
논문에서 제안하는 모델은 NLP와 비전 분야에서 먼저 많은 발전을 일으킨 transformer를 기반으로 둡니다. 앞서 잠깐 언급한 대로 SATRN도 트랜스포머의 인코더-디토더 구조를 따릅니다. 그리고 학습 전과정에서 feature map은 2D 형태를 유지해 보다 구조적인 정보를 잃지 않으면서 잘 학습하도록 했다고 합니다. 아래는 height extraction을 수행하는 기존 모델인 SAR과의 비교입니다.

추가적으로 인코더 부분에 3가지의 변경사항을 추가해 2D feature map에 대한 attention이 효과적으로 수행되도록 했다고 합니다. 해당 내용은 뒷절의 methods 부분에서 다시 설명 드리겠습니다.
Method
다음은 SATRN의 전체 아키텍처입니다.
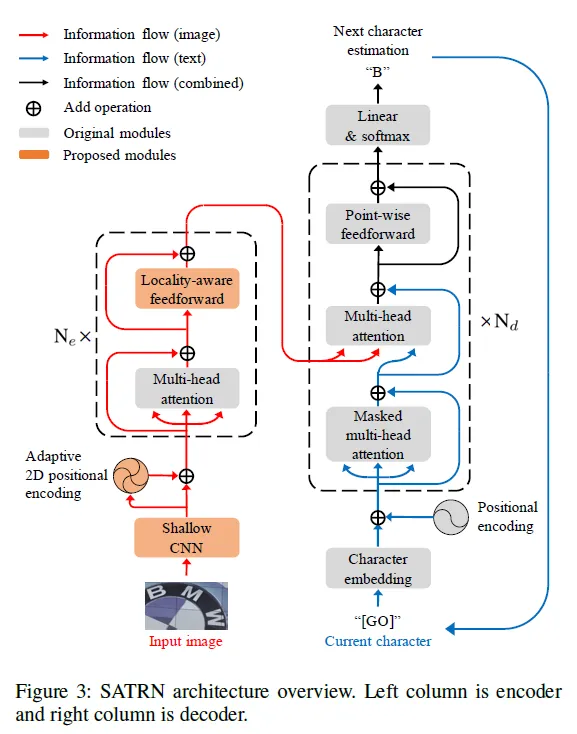
논문의 저자는 기존 트랜스포머 구조를 유지하면서도 추가적으로 novel한 modification을 주었다고 합니다.
우선 전체적인 구조 부터 설명드리겠습니다
크게 보면 입력되 이미지로 부터 2D feature map을 출력하는 인코더와 그 다음에 feature map으로 부터 charcaeter sequence를 예측하는 decoder 부분이 있습니다.
모델에 입력된 이미지는 얕은 CNN(1)을 통과하며 비교적 fine한 패턴과 텍스처 정보를 학습합니다. 이후 self-attention module에서 attention이 수행되는데 이때 adaptive 2D positional encoding(2)이 돼서 들어가게 됩니다. 새롭게 positional encoding 방법을 제안 및 적용한 건 STR 테스크에 보다 적합하게 적용하기 위함입니다. 기존 트랜스포머의 인코더 블록 내부에는 attention 이후에 point-wise한 ffn을 통과하지만 이를 locality-aware한 FFN으로 교체하였다고 합니다.
디코더에서는 순서대로 character를 예측합니다. 이미지와 텍스트 간의 cross modality의 연산은 multi-head cross attention에서 수행됩니다. (제가 text spotting 테스크에 대해 제일 먼저 작성했던 TESTR에서와는 달리 SATRN에서는 text의 character들이 auto-regressive하게 예측됩니다.) 이외의 masked self-attention, FFN은 기본 transform의 구조와 같습니다. 이렇게 보니 트랜스포머를 안다면 구조 자체는 간단하다고 생각될 수 있겠습니다.
그럼 다음으로 논문의 저자들이 새롭게 적용한 부분을 인코더에서 찾아보겠습니다.
Shallow CNN block
self-attention은 연산량이 많이 드는 작업인지라 이미지에서 배경이 되는 부분을 굳이 인코더에서의 연산에 텍스트가 있는 부분과 동일한 중요도를 적용해 연산을 수행할 필요는 없습니다. 그래서 CNN의 pooling 연산을 통해 연산량의 부담을 줄입니다. 2개의 커널 크기가 3인 convolution layer와 각 합성곱 연산 후의 커널크기가 2이고 stride가 2인 max pooling layer를 통과해 거의 원본 이미지로 부터 1/4 정도 축소된 크기를 갖습니다. 이 정도의 reduction이 performance를 해치지 않는 선에서의 최적이라고 합니다.
Adaptive 2D positional encoding
attention 연산은 따로 입력된 값들의 순서를 고려하지 않습니다. 따라서 위치 정보를 보존하기 위해서 기본 트랜스포머도 encoder, decoder에 입력하기 전 positonal encoding을 적용했었습니다. 기존 Transformer는 1D positional encoding vector를 더했다면 SATRN의 2D positional encoding은 2차원의 height, width의 정보를 담습니다. 추가적으로 arbitrary한 텍스트에 대한 형태도 잘 표현하기 위해 텍스트 마다 adaptive하게 positional encoding이 더해집니다. 논문에서는 이를 줄여 A2DPE라고 합니다.
수식과 함께 설명 드리겠습니다.
shallow CNN을 통과하고 나온 feature map E에 대한 attention 과정을 다음과 같이 나타낼 때
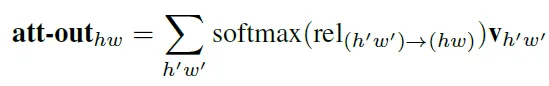
기본적인 트랜스포에서의 attention에서 쿼리와 키 간의 attention map을 구하는 과정은 아래와 같습니다
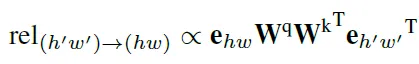
논문의 저자는 여기서 positional encoding인 p_{hw}를 더합니다.
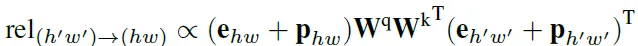
각 위치에서의 positional encoding은 각각 width, height 방향의 위치 인코딩을 더한 값인데 앞에 \alpha와 \beta가 계수가 된 것입다.
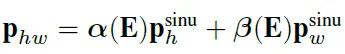
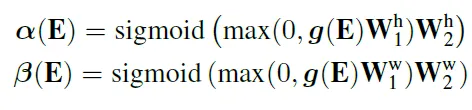
각 \alpha(E)와 \beta(E)의 scale factor은 feature map E에 global max pooling한 g(E)에 두 차례에 perceptron을 통과한 다음 시그모이드를 적용한 값으로 0과 1 사이의 값을 가지며 텍스트의 방향에 대한 정보를 나타내는 값으로 \alpha(E)이 높다면 height 위치 정보가 더 강조가 되고 반대로 \beta(E)이 높다면 width 정보가 더 강조된다고 합니다. 아래 텍스트 이미지에 대응을 시켜보면 \alpha(E)이 높아 height에 대한 정보가 강조되어야 하는 것은 \alpha(E)/\beta(E)가 Hight한 아래 열의 텍스트들에 해당하겠고 반대로 \alpha(E)이 낮은 경우에는 Low에 해당하는 텍스트들이 되겠습니다.

Locality-aware feedforward layer
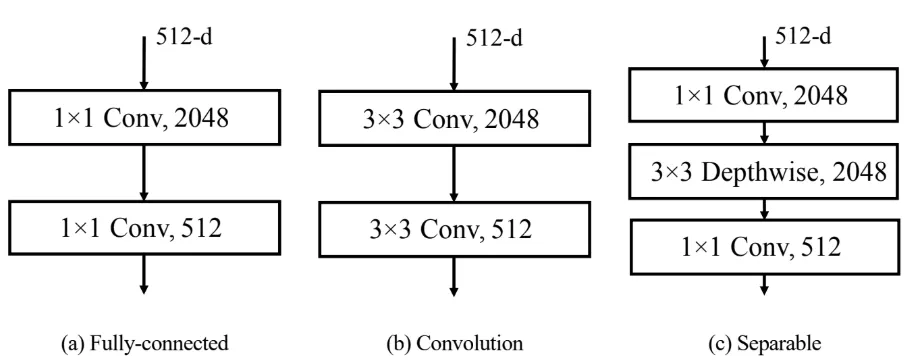
self-attention 은 이미지 내 전체적인 관계를 point-wise하게 잘 학습하지만 local한 구조는 학습되지 않습니다. (예를 들어 하나의 character 주변의 local한 구조 정보들) 기존의 트랜스포머가 attention 후 1×1 convolution 연산을 수행한 것을 3×3 convolution으로 바꿔 보다 지역적인 관계 까지도 학습이 되도록 했습니다.
Experiments
실험 부분입니다.
SoTA와 비교한 실험입니다.
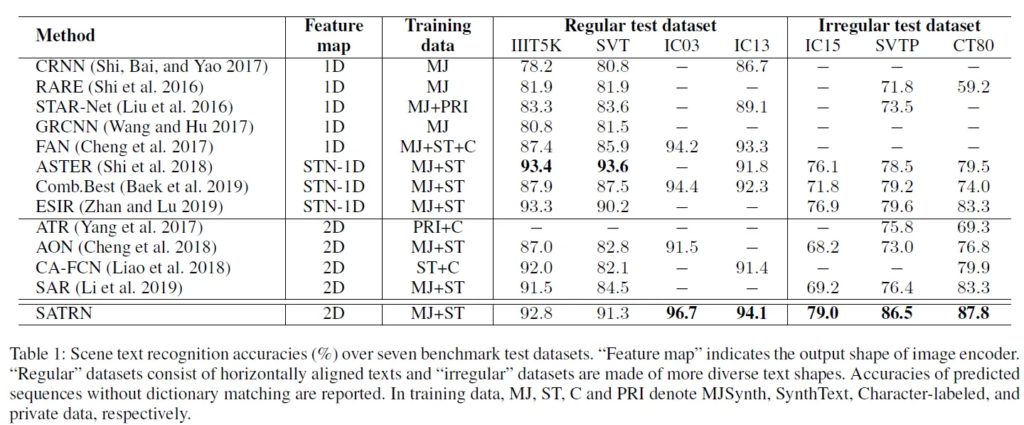
Feature map 항목은 인코더를 타고 나와 디코더로 들어가는 feature map의 차원을 나타내는 것을 실험한 결과, SATRN이 다른 2D 기반의 방법들 보다 성능이 더 좋습니다.
Irregular 데이터셋에 대해서는 그 폭이 더 큽니다.
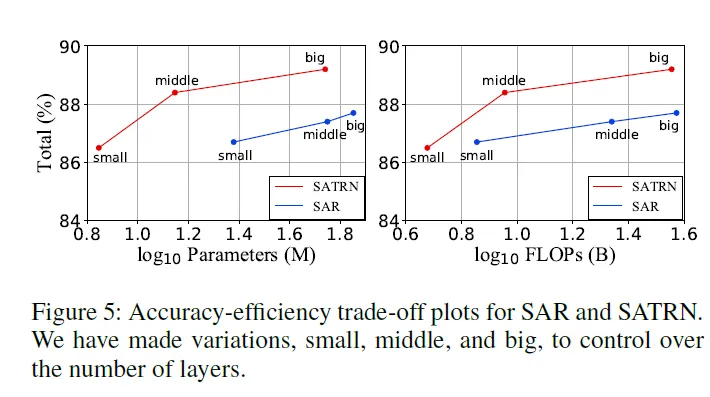
다음은 SAR 모델과 accuracy-efficienty 간의 트레이드 오프 정도를 비교한 실험 결과입니다. SAR과 SATRN은 비슷하지만 인코더에서 attention 대신 ResNet을 사용한다는 점과 디코더에서도 LSTM의 방법이 사용된다는 점이 다릅니다. 아래의 표와 함께 같이 보겠습니다. 맨 위 첫 줄이 SAR 모델을 나타냅니다. 인코더를 SATRN의 것으로 변경하는 것 만으로도 파라미터 수와 FLOPs를 대폭 줄일 수 있었습니다. 정확도는LSTM 디코더를 그대로 썼을 때 1, SATRN의 디코더를 썼을 때 0.9 정도 올라가고요. SATRN의 디코더를 사용하는 경우 정확도의 개선은 있지만 파라미터 수와 연산량의 지표인 FLOPs는 증가하는 것도 확인이 됩니다.
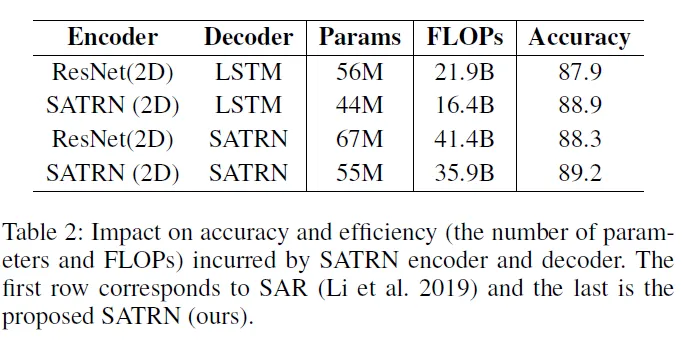
아래의 Figure 5를 보면 같은 메모리 사용량과 연산량에도 SATRN의 방법이 더 정확합니다.
다음은 Ablation study입니다.
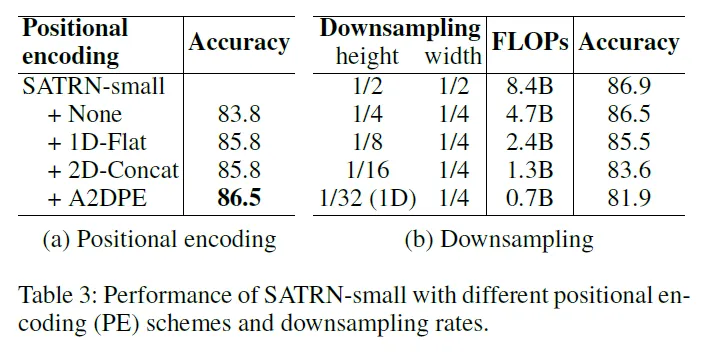
Table 3 (a)는 positional encoding의 방법을 달리하며 정확도를 본 실험으로 이 논문에서 제안하는 A2DPE의 방법으로 scale factor을 적용한 positional encoding을 사용한 경우가 86.5로 제일 정확했습니다. 우측의 (b)는 shallow CNN을 통과해 reduction된 결과입니다. 논문에서는 height, width를 모두 1/4 축소시킨 게 속도와 정확도간의 트레이드 오프를 제일 잘 만족한다고 설명합니다.
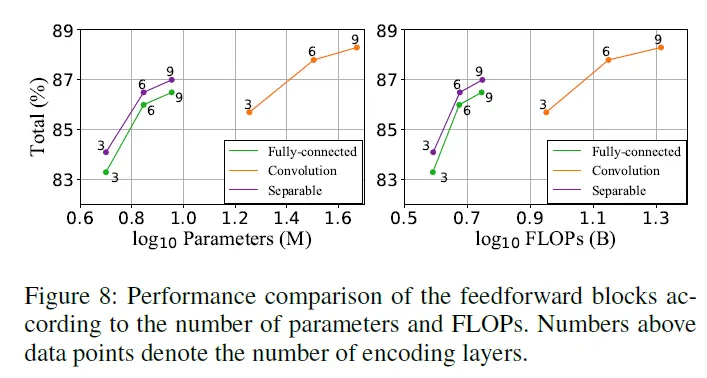
다음은 기존 FFN은 locality aware FFN으로 교체한 것에 대한 ablation study입니다. 아래는 accuracy와 performance간의 트레이드 오프를 시각화한 것입니다. convolution을 적용한 locality-aware FFN으로 교체한 것이 높은 정확도를 보입니다. 하지만 파라미터 수나 FLOPs도 함께 증가함을 확인할 수 있습니다. 더 나아가 depth-wise하게 합성곱 연산을 수행하는 경우 파라미터 수나 FLOPs의 변화 없이도 정확도 개선을 일으킬 수 있었습니다.
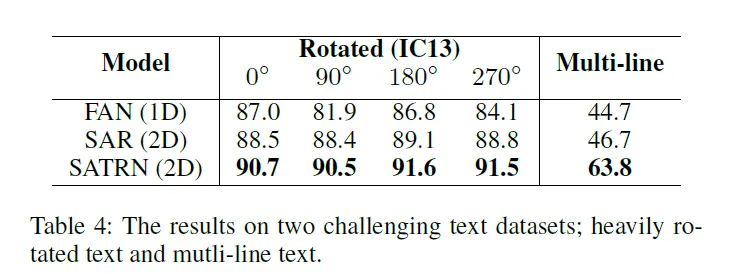
마지막으로 다음은 challenging 한 데이터셋에 대한 실험으로 이러한 shape의 복잡성에도 강인함을 확인한 실험입니다.
Conclusion
이 논문은 arbitrary한 텍스트의 recognition 정확도를 올리는 방법을 제안한 연구로 트랜스포머 기반의 모델을 text recognition에 맞게 설계하였습니다. 이미지 특성 상 그리고 다양한 shape으로 나타날 수 있는 텍스트 특성을 고려해 2D feature map에 대한 attention 연산을 하도록 설계가 되었습니다. 추가적으로 논문의 저자는 인코더 입력 전에 shallow network를 통과해 local한 pattern정볼ㄹ 학습하면서도 연산량의 부담을 줄였습니다. 또한, adaptive한 positional encoding을 더하고 encoder의 point-wise FFN을 locality aware FFN으로 교체해 지역적 구조 정보를 학습하며 정확도를 개선하였습니다. SATRN의 성능은 이전 SoTA와의 비교로 기존의 연구들 보다 높은 정확도를 가짐을 확인할 수 있었고 저자가 제안한 방법들에 대한 ablation study를 통해서 각 제안의 효과를 보였습니다.
기존에 읽었던 text recognition을 수행하는 방법을 제안했던 TESTR의 경우에는 non auto-regressive한 방법으로 text의 character sequence를 예측하였는데요 이 논문을 통해 auto-regressive하게 예측되는 방법또한 가능하다는 것과 그 방법을 알 수 있었습니다. 다만 DiG 논문에서 파인튜닝 시 SATRN이 제안한 모델의 디코더만을 사전학습된 인코더에 붙여서 파인튜닝을 진행하는데요 원래 이 논문을 읽은 목적은 해당 디코더가 궁금해서 이에 대해 더 자세히 알기 위함이었는데 이 논문에서는 디코더보단 인코더에 조금 더 힘을 준 연구라는 생각이 들어 제 생각과는 달라 조금 아쉬웠습니다. (절대 논문의 내용이 아쉽다는 내용은 아닙니다!)
읽어주셔서 감사합니다!
안녕하세요. 좋은 리뷰 감사합니다.
table1에서 제안하고 있는 SATRN이 기존 1D 기반 방법론보다는 성능이 좀 떨어지는 부분도 있는거같은데, 이에 대해서는 어떻게 해석하면 되는지 궁금합니다.
또, 평가지표가 accuracy로 보이는데, 한 이미지 내에 있는 단어를 예측했을 때 한 character라도 틀리면 반영이 안되는건가요? 혹은 이에 대한 고려가 있을까요?
감사합니다.
안녕하세요 질문 감사합니다!!
1. regular text 데이터셋 일부에 대해서 1D + STN(Spatial Transformer Network)를 사용하는 모델의 성능보다 결과가 낮은 경우가 보이는데 이 부분은 논문에 나와있지 않아 정확한 이유를 설명을 드리지는 못하겠고 또 아는 선에서 이유를 내보려 했지만 뾰족한 결론을 내리지는 못했습니다..
2. 공개된 코드를 확인하니 대소문자 구분 없이 예측과 실제 정답간의 텍스트가 와전히 일치해야 맞다고 합니다.
감사합니다!
안녕하세요 지연님 리뷰 감사합니다.
찾아보다 보니 데이터셋에 대한 궁금증들이 생겼습니다. synthetic data와 real world 데이터셋이 있는걸로 알고있는데 혹시 둘의 차이가 있을까요? synthetic 데이터로 학습하고나서 real world의 데이터로 평가했을 때 성능 변화가 있나요?
synthetic data는 raw한 이미지 곳곳에 텍스트를 붙여넣어 구성한 데이터입니다. 대표적인 데이터셋으로는 SynthText가 있습니다. 이 논문에서도 합성 데이터셋 두가지를 모두 사용하였습니다. 여기서는 합성 데이터를 사용했을 때의 성능 개선이나 하락 여부를 확인하는 실험을 진행되지는 않았습니다만 text data는 라벨링의 부담이 있다 보니 사전학습 때 이런 합성 데이터를 가지고 학습하는 경우가 많았는데 사실 이 둘간의 domain gap이 있어 성능이 더 개선되는데에는 한계가 있다고 합니다.
안녕하세요 지연님, 좋은 리뷰 감사합니다.
다만 궁금한점은 모델의 구조상 transformer의 encoder decoder를 그대로 사용한 것 같지는 않습니다.
제가 알기로는 ViT나 DETR같은 경우도 1D flatten 시킨 벡터에 1D positional encoding을 더해서 트랜스포머의 input으로 집어넣는 것으로 알고있습니다. 꽤나 이전 논문이라 아직 2D attention 구조를 생각하지 않고 기존의 트랜스포머 구조를 최대한 이용한 것일수도 있으나 지금 지연님이 리뷰해주신 SATRN 에서는 2D 구조로 attention을 진행하는 것 같아서, 기존의 1D와의 차이점이나 계산방법의 차이가 있을지, 연산량이 달라지거나 하는건 없는지에 대한 궁금증이 생깁니다. 감사합니다.
기존 attention 방법들은 높이에 해당하는 차원을 축소해 인택님이 얘기해주신 대로 1D 임베딩 상태에서 임베딩됩니다. 하지만 이 연구에서는 차원 축소 없이 attetion이 수행되기 때문에 연산량이 많아질 수 밖에 없는데 논문에서는 인코더에 입력으로 feature map을 전달해주기 전에 shallow cnn을 통과시켜 두 차례의 max pooling을 통해 (텍스트에 비해 중요하지 않은) background feature를 suprress하며 연산량 부담을 해소한다고 설명합니다.