
이번 리뷰 논문은 Physical Intelligence의 25.5.28에 새롭게 공개한 VLA 후속 논문입니다. 해당 논문은 최근 박성준 연구원이 세미나에서 발표했던 LLM의 Priming Effect 현상을 Physical Intelligence에서도 인식하고 해결하기 위한 기법이라고 해석하고 있습니다. 제 추후 연구 내용이 해당 방향과 유사한 방향이 되었으면 좋겠네요.
Intro
최근 VLA에 대한 논문들을 많이 다루고 있습니다. 최근 용어 확립이 진행 중이라 혼란이 될 수 있기 때문에 제가 언급하는 혹은 VLA라고 지칭하는 VLA는 GPT4o과 같은 Large VLM을 이용하는 Large VLA에 해당합니다. 해당 논문에서도 다루는 VLA는 제가 정의한 바와 일치합니다.
제가 앞서 언급한 바와 같이 VLA는 Large LLM의 internet-scale datasets을 활용하여 풍부한 지식 추론 능력은 로봇 작업에도 충분한 도움이 되지 않을까?란 가정에서 진행된 기법입니다. 그 가정은 최근 Google Deepmind의 OpenVLA, Physical Intelligence의 pi-zero, Nvidia의 GR00T N1, figure 01의 HELIX 과 같이 굵직한 기업들이 결과물로 들고 나오면서 증빙이 되었습니다.
최근 연구들은 대체로 공통된 구조로 발전되어 가고 있는데요. 이는 discrete tokens을 생성하는 VLM을 확장하여 continuous prediction이 가능한 action expert (e.g. diffusion or flow matching)을 확장한 구조를 취하는 것이 트렌드로 흘러가고 있습니다. 이는 기존 VLM과 다르게 robot과 같은 physical system은 연속적이고 정밀한 정보(e.g. joint angles, target poses)를 실시간으로 요구합니다. 허나, Autoregressive 구조를 가진 기존 VLM들은 연속적인 값을 실시간으로 추론하는데에 적합하지 못합니다. 이는 추론 값인 discrete tokens의 한정적인 resolution이 가장 큰 문제인데 이를 극복하려면 더 많은 계산량을 요구 할 수밖에 없으며, 이러한 문제는 모델이 커질 수록 더 문제가 됩니다. 더 나아가, physical systems은 일반적인 VLM이 학습에 활용된 정보보다 multi-view images나 proprioceptive states (e.g. robot의 dof ~ 기존 상태)와 같이 더 복잡한 관측 정보를 제공합니다. 이러한 차이로 인해서 VLA는 VLM의 구조를 확장하는 방향이 필수적이게 된거죠.
앞서 언급한 바와 같이 최근 연구들은 연속적이고 실시간을 가지며, 보다 복잡한 관측 정보를 이해하기 위해서 VLM에 연속적인 정보를 추론 가능한 action expert를 확장한 구조를 취합니다. 그러나 이러한 확장된 모듈은 사전 학습된 정보 없이 완전 초기화된 상태로 학습을 진행합니다. 또한, 복잡한 정보에 대한 추론을 이해하기 위해서 VLM backbone을 반드시 접목 시켜야 합니다. 이런 구조라면 이런 질문을 던질 수 있습니다. 이렇게 continous state and action adapters로 확장된 VLM~VLA가 인터넷 스케일의 사전 학습 정보로부터 실제로 얼마나 많은 이점을 얻는 걸까? 혹은 제대로 전달 받는 건 맞을까?
저자는 해당 연구를 통해 연속적인 출력으로 VLMs을 미세 조정하기 위해 기존 방식으로 접근 했을 때 예상외로 상당히 좋지 않은 training signal이 전달되는 것을 관찰했다고 합니다. 이는 training signal이 action expert의 기울기에 의존하기 때문이라고 합니다. 이러한 흐름은 language commands를 해석하는 능력이 떨어지게 될 것이며, 이는 VLA 자체의 성능을 저하시킬 수 있습니다.
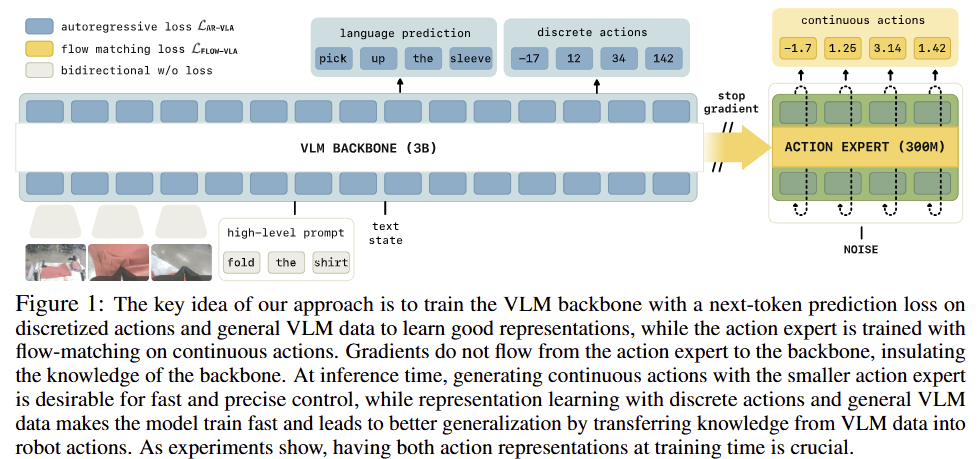
저자는 이를 해결하기 위해서 knowledge instruction이라는 기법을 제안합니다. 해당 기법은 discretized actions에 대한 VLM backbone을 미세 조정하기 위해서 동시 다발적으로 continuous actions을 제공하는 action experts를 VLM backbone에 gradients를 전달하지 않고 학습을 진행합니다. 이는 fig 1에서도 확인 가능합니다. 이는 결과적으로 discrete token은 사전학습되지 않은 action expert의 가중치에 영향을 받지 않고 학습 신호를 제공하며, action expert의 gradient로 인해 발생하는 장애 없이 로봇 제어를 위한 적절한 학습이 가능하도록 합니다.
이를 통해서 얻는 추가적인 이점은 다음과 같습니다. 1. 모델의 학습을 보다 빠르고 안정적이게 만듬. 2. action expert는 여전히 빠른 추론이 가능. 3. 일반적인 vision-language data로 co-training이 가능.
저자는 pi-zero를 확장한 continuous-action VLAs의 다양한 모델링을 통해서 확장된 분석을 제공합니다. 또한 mobile bimanual robots 뿐만이 아니라 open-source benchmarks (DROID, LIBERO)에서 복잡하고 long-horizon robotic manipulation task에 대한 분석 결과를 보입니다.
Standard vision-language-action (VLA) model training recipes
해당 섹션에서는 기본적인 VLA에 대한 training recipes에 대해서 설명합니다. VLM을 적응시킨 VLA \pi 을 학습 시키기 위한 아이디어는 image observations I_{1:V} , robot’s proprioceptive state q \in \mathbb{R}^s , natural language instruction l 를 입력 조건으로 받아 robot actions a \in \mathbb{R}^d 을 출력하는 것을 목적으로 합니다. 즉, VLA은 VLM의 인터넷 스케일의 지식을 상속 받아 robot actions을 미세 조정 하는 것을 목적으로 합니다.
Action representations. 위에서 언급한 robot actions은 robot joint state angles이나 end-effector coordinates로 표현된 real-valued vector를 사용합니다. standard VLA은 공통적인 전략으로 action chunking이라 불리우는 기법을 사용합니다. 현재 robot state에 상대적인 robot action a_{1:H} 의 경로를 예측하기 위한 것이라고 보시면 됩니다. VLM을 VLA을 적응 시키기 위해서는 이 action chunk를 어떻게 표현할지에 대해서 여러 선택지가 존재합니다.
Naïve discretization. 가장 단순한 방법으로 각 action을 discrete token으로 출력하는 방법으로 chunk는 H * d tokens으로 맵핑된다고 보시면 됩니다. robot actions prediction은 next-token prediction problem으로 정의된다고 보시면 됩니다. 해당 방법은 non-robot specific VLM에서 사용되는 cross-entropy loss로 학습되어집니다.
Temporal action abstractions. Naïve discretization의 단점은 high-frequency와 high-dim을 가진다는 점입니다. 시간이 지나면서 token 수가 크게 증가 할 수 밖에 없습니다. 이는 높은 계산량과 학습 수렴 속도를 매우 느리게 만든다는 단점이 있습니다. 이를 해결하기 위해서 PRISE나 FAST* 기법은 시간에 따른 information을 압축 시킨 변화 기법을 적용시킵니다. 저자는 FAST를 사용합니다.
* FAST는 저자가 발표한 기법으로 x-review 참조 부탁
Diffusion and flow matching. 최근 제안된 VLA 기법들은 continuous actions을 생성하기 위해서 diffusion이나 flow matching 기법을 사용하며, 해당 논문에서 따르는 pi-zero는 action expert라 불리우는 flow matching으로 설계되어져 있습니다. flow matching time index \tau \in [0, 1] 에 대해 모델에 대한 입력은 노이즈가 추가된 action chunk a_{\tau, \omega_{1:H}} = \tau a_{1:H} + (1 - \tau)\omega, \omega \sim N(0, I) 이며, 모델은 flow \omega - a_{1:H} 를 예측하도록 학습됩니다. 추론 시에는 이 flow field가 통합되어 \omega 에서 최종 action chunk로 디노이즈됩니다. fig 1을 통해 구조에 대한 정보를 얻을 수 있습니다. 혹은 pi-zero 리뷰를 참조하시길 바랍니다.
State representations. 추가로 저자는 robot’s proprioceptive state를 3가지 표현으로 사용하는 것을 고려했다고 합니다. 먼저, 이산화 후 text로 표현하는 “text state”, 이산화 후 special token을 사용하는 “special token state”, 학습된 projection을 사용하여 연속적인 state를 backbone에 직접 매핑하는 “continuous state”이 있다고 합니다.
+ 쉽게 정리하면 text state는 그냥 text token에 concat, special token state은 별도의 token으로 보고 입력, continuous state은 FAST tokenizer를 이용하는 방법으로 보시면 됩니다.
VLA architectures, training, & mixture of experts. 대부분의 VLA는 사전 학습된 VLM 가중치로 초기화된 multi-modal transformer를 기반합니다. 해당 방식에 대한 수식은 아래와 같이 정리 가능합니다.
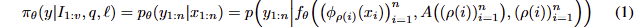
sequence of n multimodal input tokens x_i는 sequence of n multimodal output tokens y로 매핑됩니다. VLA에서는 actions target에 대응되도록 y = y^a 구성됩니다. 또한 modality type \rho : i \rightarrow {image, word, action, state, …} 의 각 토큰은 text token (x_i^l \in N), image patch (x_i^I \in R^{p \times p \times 3}) , 또는 robot state나 action과 같은 continuous inputs (x_i \in R^d) 이 될 수 있습니다. 각 token은 서로 다른 encoder \phi_j : T_j \rightarrow \mathbb{R}^{d_e} 로 임베딩되며, T_j는 type j의 token에 대한 space를 의미하며, d_e는 해당 model의 차원에 해당합니다. 또한, attention mask A(\rho(i))_{i=1}^{n} \in {-\infty, 0}^{n \times n} 에 따라 token들은 서로에게 attention을 수행하게 됩니다.
일반적인 transformer와 actions 생성에 빠른 추론 속도를 위해서 비교적 작은 weight set을 구성한 pi-zero를 이용합니다. VLM backbone과 action token은 자체적인 query, key, value을 가지지만, 동일한 차원을 가져, 각 experts들이 서로 상호 작용 가능하도록 설정 됩니다.
대부분의 VLAs는 large robot behavior cloning datsets으로 학습이 되어집니다. Autoregressive architectures를 가진 경우에서의 standard training은 negative log-likelihood를 최소화하는 방향으로 학습을 진행합니다. 이를 정리하면 아래와 같습니다.
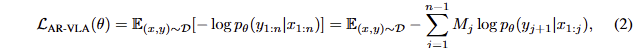
여기서 M은 loss mask로 예측해야 하는 token의 위치를 가르키는 것이며, D는 데이터 셋에 해당합니다. action을 예측하기 위한 flow-matching는 다음과 같은 loss로 구성됩니다.
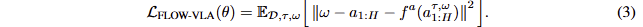
Problems with standard VLA recipes
현재 제시된 VLAs의 training recipes의 시각적인 문제점을 fig 2에서 볼 수 있습니다.

Autoregressive VLAs are slow. Autoregressive VLAs은 action을 예측하는 방법은 discrete next-token prediction problem으로 해소합니다. 해당 방식은 표현 가능한 예측 값의 크기에 대한 한계와 이에 따른 연산량 증가로 인한 늦은 추론 속도에 해당합니다. FAST인 경우에는 1-second action chunk는 750ms에 해당합니다. 해당 방식은 실험적으로 dynamics mismatches와 slow overall trajectories를 야기 할 수 있음을 볼 수 있었다고 합니다.
Robotic specific architectures and modality adapters don’t benefit as much from VLM pre-
training. pi-zero나 GR00T N1과 같은 구조들은 빠른 추론 속도를 갖추기 위해서 robotics specifc modules를 포함합니다. pi-zero를 예를 들면 VLM에서는 1.3HZ를 보이는 반면에 action expert는 10HZ를 보입니다. 하지만 robotics-sepcific modules은 scratch로 초기화 되기 때문에 model의 language command를 따르는 능력에 영향을 미치는 문제가 존재합니다.
VLM pretraining does not have sufficient representations for robotics freezing doesn’t work. 위와 같은 문제를 해결하기 위한 아주 단순한 방법은 사전 학습된 가중치를 freezing하고 추가된 weight만 추가 학습하는 방법이 있습니다. 하지만 현존하는 VLM은 robotic data를 본적이 없기 때문에 고성능 추론에 있어 충분하지 못합니다. 실험적으로 fig 4-a나 fig 8에서 보면 매우 낮은 성능을 보임을 볼 수 있습니다.
Method
Improving VLAs with co-training, joint-training & knowledge insulation
저자는 이를 해결하기 위해서 다음과 같은 방법을 제시합니다.
- Autoregressive와 flow-matching action prediction을 함께, 동시에 학습할 것. Autoregressive에 대한 학습은 학습 단계에서만 활용되기 때문에 빠른 추론 속도를 유지할 수 있음
- 공동 학습 중에 non-action datasets ~ general vision-language data and robot planning data를 같이 학습 할 것. 이를 통해서 VLA에 적응시킬 때, 지식 손실을 줄어들게 만들어 성능 향상을 이끌 수 있음
- action expert와 backbone (VLM) 가중치 간의 gradient flow를 멈출 것. 해당 방식은 사전학습된 VLM을 VLA에 적응 시킬 때, 새로 초기화된 action expert의 가중치가 사전 학습 가중치에 영향을 주지 않도록 함
Co-training & representation learning with joint discrete/continous action prediction
VLM data에 대한 공동 학습을 효율적으로 하기 위해서, 정책에 따른 언어 지시에 대한 지식 전이를 강화하기 위해서 그리고 빠른 학습을 위해서, 저자는 autoregressive language와 discrete action predictions, continuous actions의 flow-matching modeling을 한번에 공동 학습을 합니다. 이를 정리하면 수식 2와 수식 3을 결합한 loss에 해당하며 이는 다음과 같습니다.
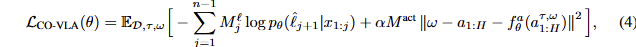
여기서 α는 loss multiplier로 flow-matching와 standart language modeling loss 간의 trade off를 조절하는 인자입니다. M^l은 language loss mask ~ token 중 loss를 적용해야하는 위치에 대한 정보. M^{act}는 action mask indicator로 주어진 예시가 action에 관련된 정보인지에 대한 것입니다. 해당 loss는 유연하게 서로 다른 모달리티 간의 mix-and-match co-trianing을 가능하게 해준다고 합니다.
자세하게, 이는 VLM data (which has only images and text annotations), action-only data (where the task is action prediction conditioned on images and text), conbined language and action prediction tasks (where we take action only data and additionally annotate it with a language description of what the robot should do next)이 결합되어 있습니다. 이렇게 서로 다른 모달리티를 결합한 방식은 지식 전이를 강화사키는 결과로 이끌었다고 합니다. 여기서 \hat{l}은 text (language) tokens과 FAST tokenized action tokens을 포함합니다. 특징적으로 FAST action token은 discrete token과 continuous token에 둘 다 활용 됩니다.
Knowledge insulation & gradient flow
action expert의 gradients는 VLM의 image encoder와 language model backbone에 안 좋은 영향을 줄 수 있습니다. 특히 새롭게, 랜덤 초기화된 action expert와 사전 학습된 backbone인 경우에는 더 안좋습니다. 그러므로 저자는 둘 사이의 gradient flow를 단절 시키는 방법을 제시합니다. 이는 backbone이 language output으로 action을 직접 예측할 수 있을 때에 활용 가능한 방식입니다.
그렇기에 transformer layer에서도 action에 대해 추론하기 위한 충분한 정보를 생성할 수 있으며, VLM과 action expert는 attention layer를 통해서만 상호 작용합니다.
action expert와 backbone에 대한 gradient flow를 막기 위해서는 attention layer를 다음과 같이 수정합니다. single head attention의 경우에는 다음과 같이 구성됩니다.
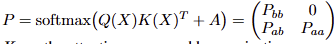
여기서 X는 attention layer에 대한 입력이며, Q, K는 query와 key이며, A는 attention mask에 해당합니다. 여기서 VLM backbone에 특징이 집중할 확률은 P_bb이며, action expert의 특징이 backbone 특징에 집중할 확률은 P_ab이며, action expert과 다른 action expert에 집중할 확률은 P_aa로 분해해 볼 수 있습니다.
이를 기반으로 softmax 연산을 구현하여 정보 흐름을 제한하면 다음과 같이 정리 됩니다.
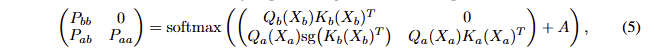
여기서 sg는 stop-gradient operator에 해당합니다. X_b는 x_i에 대한 backbone wieght에 대한 값이며, X_a는 action expert에 대한 값입니다. 이에 대한 값을 계산하면 다음과 같습니다.
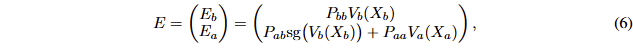
+ 진짜 단순하게… action expert와 VLM backbone 사이의 attention 연산은 수행해서 활용하되, backbone에게 주는 gradient flow는 멈추자…
그런 다음 마지막 attention은 attn(X)=PE에 해당합니다. 해당 구조의 또 다른 장점은 diffusion loss 항에 독립적인 가중치에 적용되기 때문에 α=1로 설정이 가능하다는 점입니다.
+ inference 단계에서는 flow-matching만 이용합니다. 이때 α=1로 두면 loss도 바로 변경이 가능하다는 이야기 입니다. ~action expert만 학습하는 방식을 쉽게 구현 가능하다
Experiment
다양한 로봇 형태(정적/모바일, 단일/양팔 로봇)와 실제 세계 및 시뮬레이션 환경에서 실험이 진행되었습니다. 평가에 사용된 주요 작업들은 다음과 같습니다.
real-world task:
– “items in drawer” (서랍에 물건 넣기).
– “shirt-folding” (셔츠 접기) <- unseen
– “table bussing” (테이블 치우기) <- unseen
– Mobile manipulation task:
– “make bed” (침대 정리),
– “dish in sink” (싱크대에 접시 넣기),
– “mobile items in drawer” (서랍에 물건 넣기),
– “laundry in basket” (세탁물 바구니에 넣기)
시뮬레이션/벤치마크: LIBERO (LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, LIBERO-100), DROI
저자는 baselines과 ablation을 고려하여 다음과 같은 data mixture로 재학습합니다.
- π0: action expert~continuous actions, robot data로만 학습
- π0-FAST: token compression이 이뤄진 autoregressive VLA, robot data로만 학습
- OpenVLA-OFT: bidirectional attention을사용하여 parallel decoding을 수행하는 standard autoregressive VLA, text state ?? robot data로만 학습??
- Transfusion: π0와 동일한 VLM backbone을 가진 transformer이지만 기존 방식은 image generation 모델, 이를 robot action을 수행 가능하도록 변형하여 학습을 진행
- HybridVLA: transfusion과 naïve autoregressive tokenization을 동시에 학습한 VLA로 서로 attention을 수행함. 이를 continuous action을 예측하도록 재학습
- joint-training: stop-gradient 없이 제시한 데이터로 recipes로 학 진행함
- joint-training w/o VLM data: stop-gradient이 없으며, VLM에 대한 학습 없이 action data로 학습한 모델. HybridVLA와 차이는 action expert가 flow-matching이라는 점
- Naive tokenization as representation learning objective compared to FAST
Task performance & comparison to baselines.
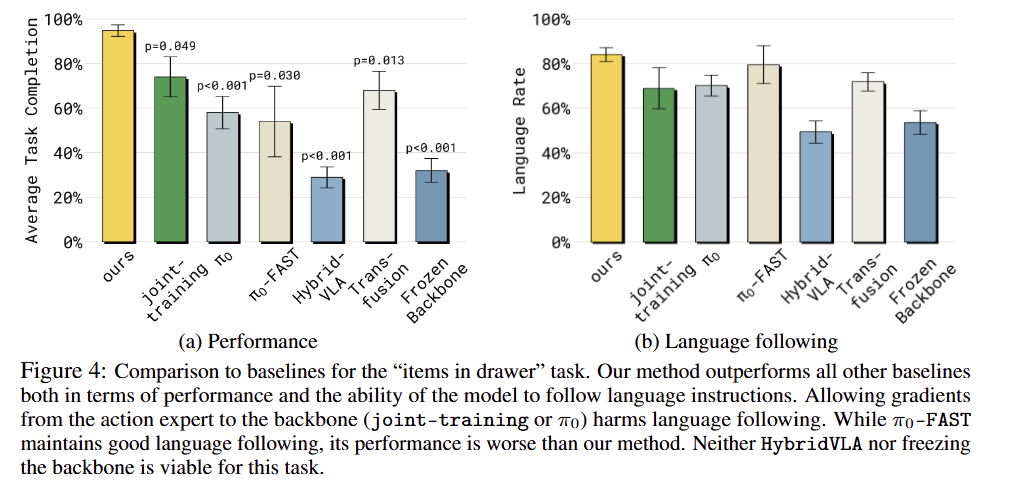
Fig 4-a를 보면 모든 기법들이 저자가 제안한 방법 대비 성능이 매우 떨어지는 결과를 보여주고 있습니다. fig 4-b에 따르면 stop gradient가 없는 pi-zero와 joint-training 같은 경우에는 거의 유사한 구조를 가지고 있지만 언어 지시를 따르는 데에 있어 저조한 결과를 보여주고 있습니다.
+Language following에 대한 평가 방식에 대해서 명시되어 있지 않아서 어떻게 구한 건지 잘 모르겠네요… high-level planner를 따르는 방식으로 한건가?… 흠…
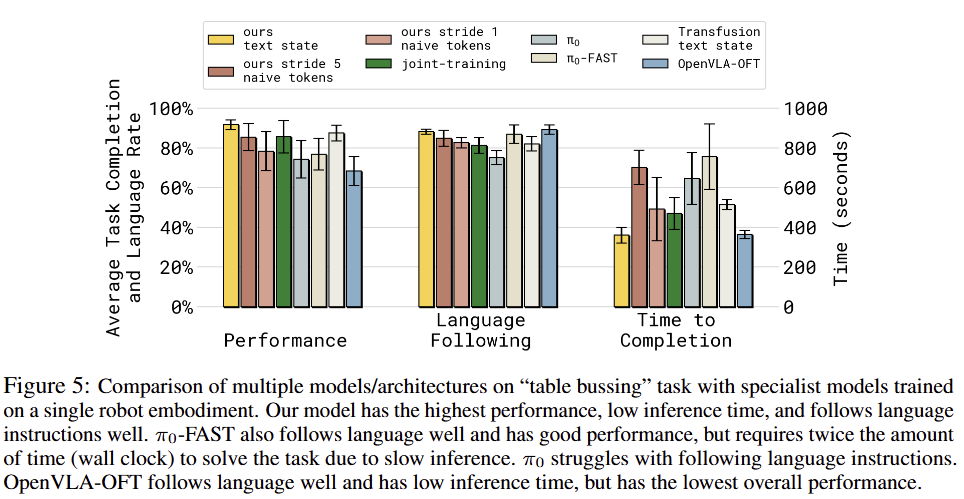
fig 5에서도 제시한 방법이 가장 좋은 결과를 보여주며, discrete token을 이용하는 FAST이 language following 성능이 비교적 높은 결과를 보여주지만, fig 5 오른쪽처럼 낮은 속도를 보여줍니다. OpenVLA-OFT 또한 language following에 대해서 좋은 결과를 보여주지만 performance가 가장 낮은 결과를 보여주고 있습니다.
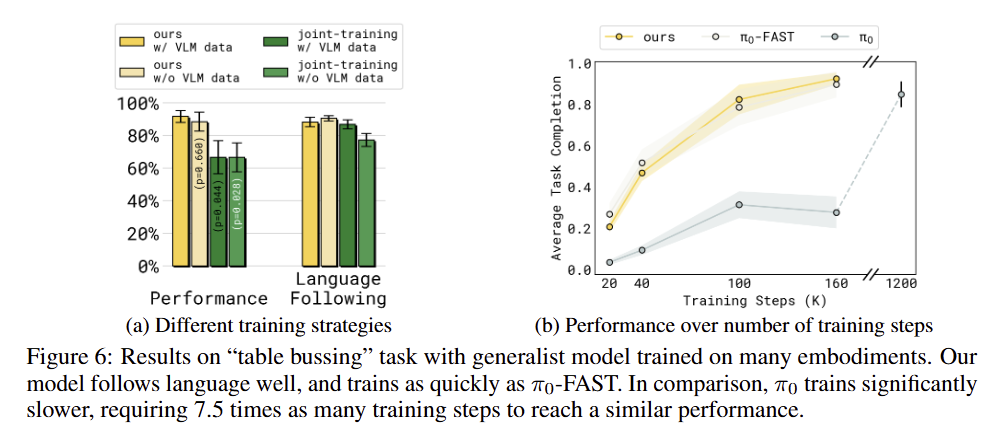
Language following. 해당 평가 방법은 long-horizon task에서 중요한 요소로 언어 지시에 맞춰 모델이 행동하는 가를 보는 평가이며, VLM의 사전 지식을 더 많이 유지 할수록 실제 언어 지시에 더 많은 집중을 한다고 볼 수 있습니다. fig 4-b에서도 action expert로부터의 gradient flow를 중단하고 VLM data로 co-triaing을 수행하는 것이 가장 좋은 효과를 보임 볼 수 있습니다. fig 6-a, fig 5, fig 7에서 VLM data 없이 공동 학습한 joint training도 좋은 결과를 달성했습니다. fig 5의 transfusion은 action expert가 있는 pi-zero보다 언어 지시를 잘 따르는 결과를 볼 수 있습니다. 이를 통해서 새로운 값으로 초기화된 action expert가 안좋은 영향을 줌을 볼 수 있으며, gradient flow를 중단하거나, VLM 데이터와 공동 학습을 하는 방식이 언어 지시를 따르는 성능을 향상시킬 수 있음을 보입니다.
Convergence speed. fig 6-b에서 보이는 바와 같이 SG와 VLM data로 co-training을 활용한 경우에 pi-zero보다 훨씬 빠르게 수렴하는 결과를 보여주며, autoregressive model인 FAST보다 같은 step에서도 더 좋은 성능을 보여줌으로써, convergence에 긍정적인 효과를 줌을 증빙합니다.
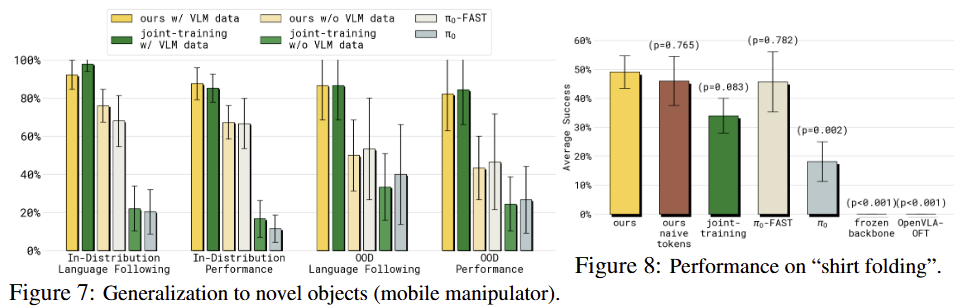
Transfer from VLM data into robotics. VLA의 숙원 중 non-robota data로부터 지식을 얻는 것이죠. fig 7은 서랍을 열어 물체를 옮기는 작업을 진행하는 task에 대한 평가로 여기서 옮기는 물체는 학습 중에 본적 없는 객체로 구성되어 있습니다. fig 7의 OOD Follow Rate에서 보이는 바와 같이 VLM data와 같이 학습한 joint-training w/ VLM data와 ours w/ VLM data가 가장 좋은 결과를 보여주는 것에 반해 다른 기법들은 저자한 결과를 보여줍니다.
Frozen backbone. fig 8에서 보이는 바와 같이 VLM backbone을 frozen 한 상태에서 학습을 진행하는 경우에 보지 못한 robot data에 대한 지식이 전달되지 못하여 action expert에 유의미한 정보를 전달하지 못해 0에 가까운 성능을 보여주고 있음. 이는 fig 4에서도 비슷한 양상을 보여줌

Fig 9에서 보이는 바와 같이 unseen 환경에서의 mobile manipulation task에서도 joint training을 사용한 경우에 좋은 성능을 보여주며, VLM data를 함께 사용한 경우에 더 좋은 결과를 보여주고 있습니다.
Tab 1에서는 open-source benchmark인 LIBERO에서의 평가 결과로 spatial과 90에서 새로운 SOTA를 달성했습니다.
+ 분석 내용을 따로 작성되지 않았습니다.
의외인 점은 시뮬레이터인 Tab 1의 결과와 real-world의 결과의 경향이 일치하지 않는다는 점인데요… 아마 점점 형평성에 대해 문제를 제시하는 방향으로 나아가지 않을까 싶습니다….
그리고 action에 대한 학습 신호가 사전 학습된 VLM에 안좋은 영향을 줄 것이라고 생각했지만, 생각보다 나이브한 해결 방법이 좋은 결과를 내보여서 좀 더 깊게 파도 좋은 결과를 보여줄 것 같습니다.