제가 이번에 리뷰할 논문은 EVF-SAM이라는 논문으로, 지난번 리뷰와 세미나에서 소개한 affordanceSAM이 베이스라인으로 삼은 방법론 입니다. 해당 논문은 ICLR 2025에 제출되어 open review를 받다 중간에 포기한 것으로 보이는데, 이후에 어디에 제출을 하고 기다리고있는 지 정보는 모르겠습니다. SAM과 text 프롬프트에 대하여 어떻게 접근하였는 지에 대하여 좀 더 자세한 힌트를 얻기 위해 리뷰하게 되었습니다.
Abstract
SAM의 뛰어난 segmentation 성능으로 인해 SAM을 기반으로 하는 다양한 연구가 이루어졌으나, text 프롬프트에 대한 성능은 여전히 개선의 여지가 많이 남아있습니다. 해당 논문은 RES(referring expression segmentation, 입력된 설명에 대응되는 영역을 segmentation하는 작업입니다.)를 위해 SAM에 적절한 text 프롬프트 인코더가 무엇인지에 대해 연구하였으며, multi-modal prmopt와 text-to-image attention에 early-fusion 매커니즘이 중요함을 관찰하였습니다. 이러한 관찰을 기반으로 Early-Fusion 프레임워크를 제안하고, 이를 SAM에 적용하여 EVF-SAM을 제안하였습니다. 또한, 저자들은 다양한 segmentation 데이터를 통합한 하이브리드 데이터셋을 함께 사용하는 방식을 통해 semantic conflict와 모호성을 해결하였습니다. EVF-SAM은 RES 태스크에서 SOTA 방법론인 BEIT-3에 early-fusion을 적용한 것으로, SOTA 성능을 달성하였으며, semantic-level의 RES와 part-level의 RES에도 확장이 가능함을 실험적으로 보였습니다. 마지막으로, 기존 LLM 기반의 방법론들은 7B가 넘는 파라미터로 이루어졌으나 해당 연구에서는 1.32B 크기의 모델로, 파라미터 수가 크게 줄어들었습니다.
Introduction
SAM의 뛰어난 segmentation 성능으로 많은 연구가 이루어지고있으며, 다양한 variation 버전이 등장하였으나, point나 box 프롬프트 방식과는 다르게 text 프롬프트를 이용하는 방식은 여전히 성능 개선의 필요성이 남아있습니다. 저자들은 주어진 텍스트 설명에 대응되는 영역의 segmentation mask를 예측하는 RES를 해결하는 것에 집중하여 SAM의 text 프롬프트에 대한 이해 능력을 개선하고자 하였습니다.
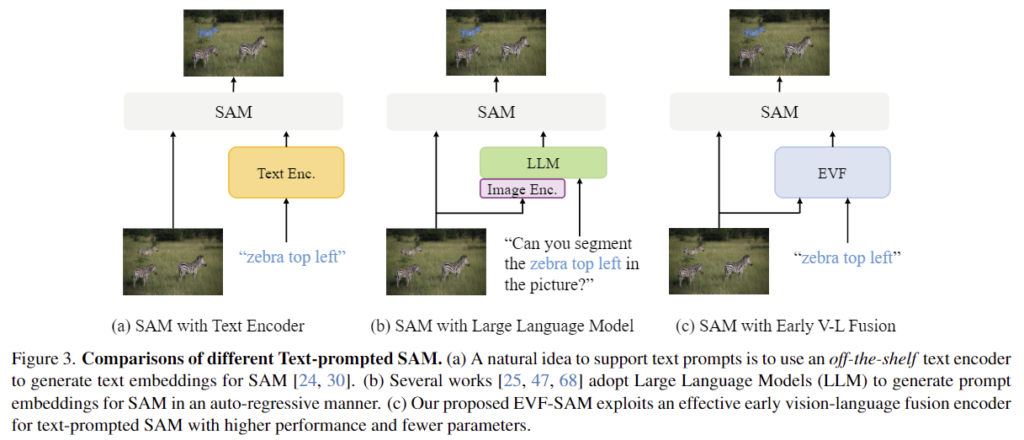
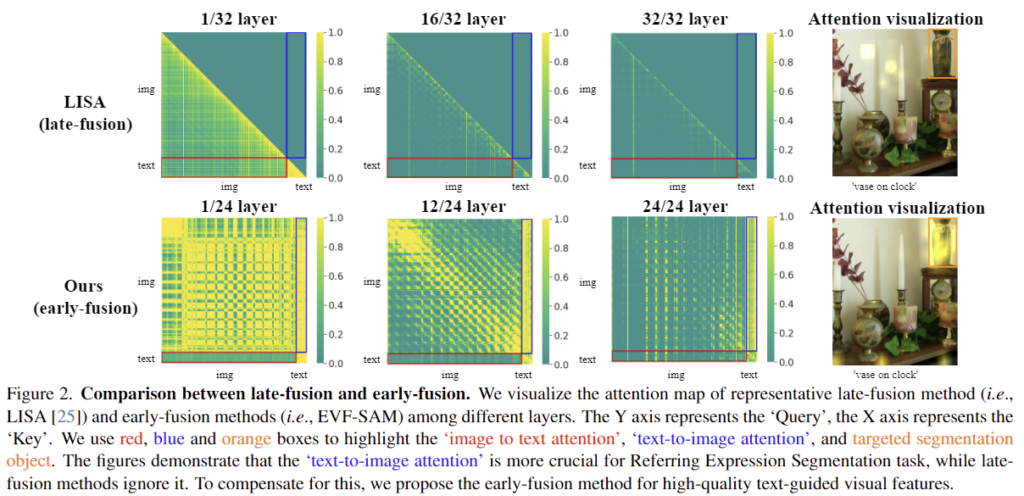
위의 figure 3의 (a), (b)는 기존의 end-to-end 방식의 SAM을 활용한 방법론들의 구조를 나타낸 것으로, (a) CLIP과 같은 text encoder를 SAM과 함께 이용하는 방식은 위치정보를 추출하지 못하므로 성능 저하가 발생합니다. (b) 방식은 LLM을 이용하여 대상 물체에 대한 임베딩을 auto-regressive하게 생성하여 LLM을 fine-tuning하는 방식으로, 이는 visual feature를 추출한 뒤 이를 LLM에 융합하므로 late-fusion 방식으로 볼 수 있습니다. 그러나 이러한 방식은 아래의 Figure 2에서 확인할 수 있듯 text-to-image attention이 잘 반영되지 않으며, LLM을 학습에 너무 많은 연산량이 들어간다는 한계가 있습니다. 아래의 그래프에 대해 조금 더 설명을 해드리자면, 가장 오른쪽에 있는 그림에서 주황색 박스가 대상 물체이고 attention 결과를 그림에 시각화한 거이며, 1~3열의 그래프는 각 레이어의 attention map을 나타낸 것으로 x축은 key, y축은 query입니다. 빨간 박스 영역은 image-to-text이고, 파란 박스 영역은 text-to-image로, RES는 주어진 text에서 대응되는 물체 영역을 찾는 것 이므로, text-to-image가 중요함이 밝혀져 있다고 합니다. 그러나 그래프를 보시면 late-fusion 방식인 LISA에 대해서는 text-to-image 영역에 attention이 잘 이루어지지 않는 것을 확인하실 수 있습니다.
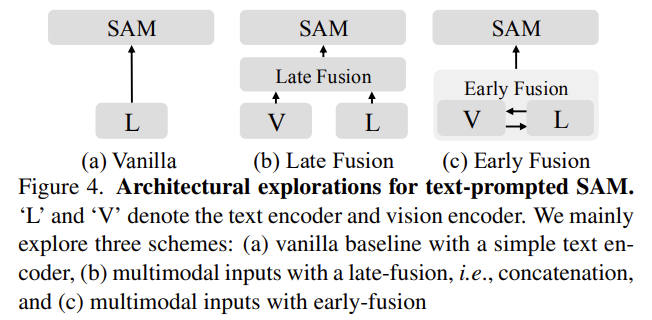
저자들은 이러한 문제를 해결하기 위해 (1) multi-modal 프롬프트가 text만을 이용하는 것 보다 성능이 우수하다는 것과, (2) text-to-image attention을 통합하는 early-fusion 방식이 더 좋은 성능을 보인다는 것을 제안합니다. 이를 기반으로 Early Vision-Language Fusion 인코더를 제안하고 이를 SAM에 적용하여 EVF-SAM을 제안합니다. (위에 있는 figure 3의 (c) 참고)
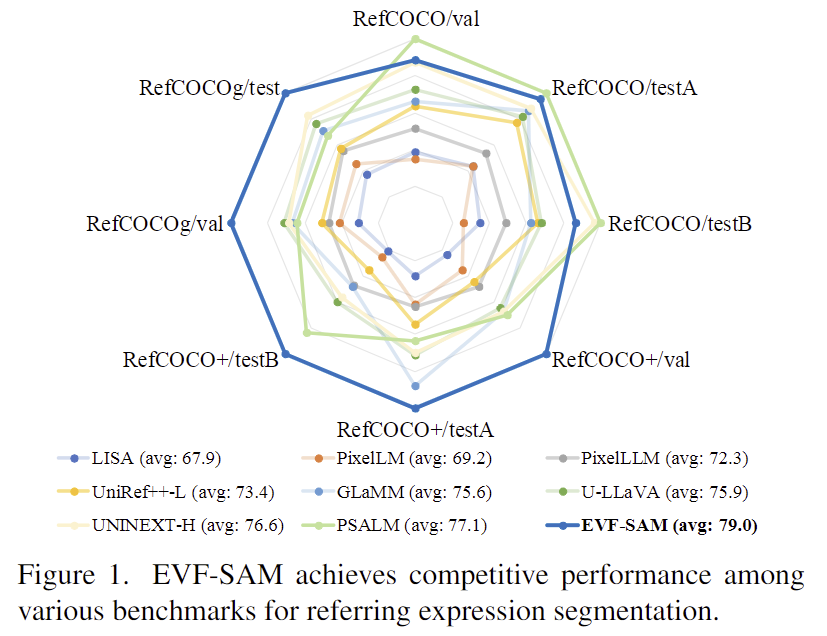
EVF-SAM은 기존의 foundation model을 기반으로 구축된 간단한 프레임워크로, 좋은 성능을 보이는 VLM 모델인 BEIT-3로 구성되어있으며, 간단한 방식을 제안하므로 다른 foundation 모델로의 확장이 용이하다는 장점이 있습니다. 또한, 위의 figure 1과같이, RES 분야에서 대체로 뛰어난 성능을 보이고 있습니다.

또한, 해당 논문은 잘 구성된 학습 데이터 셋의 중요성에 대해서도 이야기합니다. 저자들은 RES 데이터 셋(RefCOCO/+/g: RefCOCO 데이터 셋과 그 확장 버전들)과 semantic-level의 데이터(ADE20K), instance-level의 데이터(Object365), part-level의 데이터(Pascal-Part, HumanParsing, PartImageNe)로 구성된 하이브리드 데이터 셋을 제안하고, 몇 가지 설계를 통해 EVF-SAM을 효과적으로 학습합니다. 구체적으로는 [semantic] 토큰을 도입하였다는 것과, merging/filtering 방식을 제안한 것입니다. 이를 통해 semantic confliction과 모호성 문제를 해결할 뿐만 아니라 성능 개선 뿐만 아니라 다양한 세부성(semantic/part-level)의 능력도 확보하였습니다. 위의 Table 7은 여기서 이야기하는 semantic conflication의 예시로, 첫번째 이미지는 고양이 3마리가 있으므로 “all the cats”가 적절하고, 두번째 이미지는 고양이 한마리가 있으므로 “cat”이나 “the cat”이 적절하지만, 이를 구분하고 있지 않다는 것 입니다. 마지막으로 세번째 이미지도 “all the men”이 적절하지만 “man”이나 “all the mans”로 잘못 라벨링 되어있는 것입니다.
해당 논문의 컨트리뷰션을 정리하면
- EVF 프레임워크를 제안하여 다양한 실험 및 시각화를 통해 early-fusion 방식이 장점을 확인하고, 이를 기반으로 EVF-SAM을 제안
- EVF-SAM 학습에 하이브리드 데이터 셋을 사용하여 다양한 세분성의 RES 작업이 가능하도록 하였으며, 저자들의 데이터 전략을 통해 semantic confliction과 모호성 문제를 해결
- RES 테스크에서 SOTA 달성 및 7B 이상의 모델 파라미터를 약 1.3B까지 크게 줄임
Method
1. Motivation:
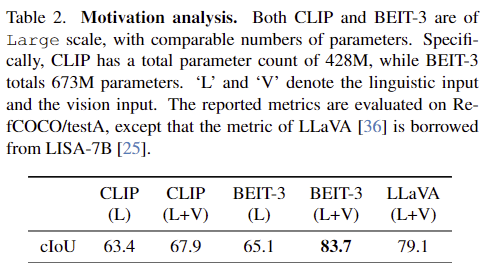
우선 저자들은 multi-modal referring 정보의 중요성을 검토합니다. SAM은 프롬프트에 따라 segmentation 성능이 달라지며, SAM을 기반으로 하는 RES 작업을 수행하기 위해서는 입력 텍스트로부터 대상 영역의 위치 정보를 인식해야 합니다. Table 2는 RefCOCO/testA에 대한 RES 성능 결과를 나타낸 것으로, SAM이 사용한 방식인 CLIP의 text encoder로 text 모달리티만 인코딩한 방식은 위치 정보를 추출할 수 없어 성능이 저조함을 실험적으로 확인하였으며, CLIP과 BEIT-3에서 모두 multi-modal 프롬프트를 사용하는 게 성능이 더 좋다는 것을 확인하였습니다.
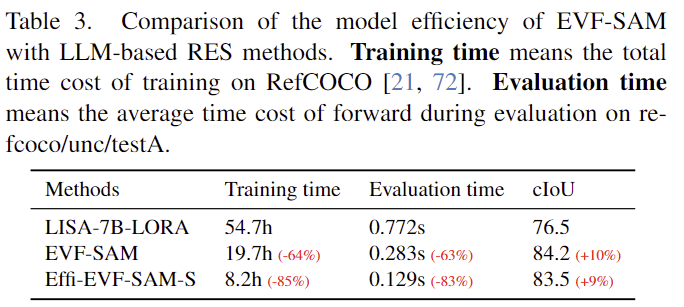
두번째로, 저자들은 late-fusion 방식보다 early-fusion이 더 유리함을 확인합니다. 이는 앞서 introduction에서 설명한 Figure 2에 대한 분석 결과로, text encoder를 이용한 late-fusion 방식은 입력으로 들어온 text 설명을 정확히 이해하는 데 어려움을 겪을 수 있음을 시사합니다. 또한, Table 3을 통해 early-fusion 방식이 효율적이고 효과적임을 보였습니다. (학습 시간 및 평가 시간은 줄고, cIoU는 개선됨)
2. Architecture
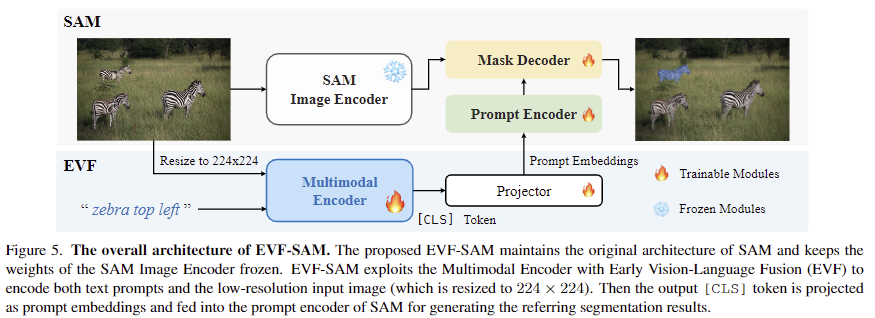
EVF-SAM의 구조는 위의 Figure 5에서 확인할 수 있으며, 간단한 구조입니다. 크게 Multi-modal encoder, Projector, SAM 3가지 구조로 이루어집니다. 먼저 Multi-modal encoder는 입력 이미지와 text를 받으며, BEIT-3의 멀티모달 인코더를 이용하였다고 합니다. 여기서 입력 text는 XLM-Roberta Tokenizer로 토큰화되고, 이미지는 224×224 크기로 resize된 후 1/16을 패치로 사용합니다. 이를 통과하여 얻은 [CLS] 토큰을 이용하여 기존 SAM에 multi-modal 프롬프트의 정보를 전달합니다. SAM의 Image encoder와 Mask Decoder 구조는 그대로 유지하며, projector를 통해 prompt encoder와 차원을 맞춰준 뒤 Mask Decoder에 입력되도록 합니다. 모델 구조는 정말 간단하게 이미지와 text를 입력하여 multi-modal feature를 추출하고, 이를 SAM에 mask 생성에 활용하는 구조입니다.
3. Data Strategy
다음은 EVF-SAM을 학습시키기 위해 공개 데이터 셋을 활용하는 방식입니다. RES 데이터 뿐만 아니라 Semantic segmentation 데이터와 Instance segmentation 데이터, part segmentation 데이터를 모두 포함하는 하이브리드 데이터를 구성합니다. 이를 통해 다양한 세부성을 이해할 수 있도록 하고자 하였으나, 세분성에 따라 정답이 조금씩 달라지므로 semantic conflict 문제가 발생할 수 있습니다. 이를 해결하기 위해 저자들은 데이터 필터링 과정을 적용하여 데이터를 선별하고, semantic 토큰을 도입합니다. semantic-level 데이터는 카테고리 이름만 주석으로 제공하고 인스턴스 번호에 관한 정보는 제공하지 않습니다. 그러나 RES 작업에서는 설명이 관련 영역과 명시적으로 일치해야 하므로 “all the {카테고리}”와 같은 정해진 형태의 템플릿이 부적절한 경우가 발생하며, 어휘적으로도 복수형은 변형이 생기므로 semantic 토큰을 도입하였다고 합니다.
먼저 데이터를 선별하는 과정을 조금 자세히 살펴보면 다음과 같이 이루어집니다.
- Instance-level 데이터(Objects365)
- Objects365는 365개의 물체에 대한 detection 데이터로, bounding box 형태의 라벨이 제공됩니다. 저자들은 모호성을 피하기 위해 인스턴스가 1개 이상인 경우는 모두 제거하고, SAM2를 이용하여 GT bounding box에 대해 Segmentation mask를 생성하여 학습에 사용하였다고 합니다. 이를 통해 600K 이미지에 대한 10M의 어노테이션 데이터가 524K 이미지와 1.8M개의 어노테이션 정보로 줄어들었다고 합니다.
- Semantic-level 데이터(ADE20K)
- ADE20K를 RES로 확장하기 위해 저자들은
[semantic]토큰을 도입하여'[semantic]{category}’ 형태로 모델에 입력합니다.
- ADE20K를 RES로 확장하기 위해 저자들은
- Part-level 데이터(PartImageNet, HumanParsing, PASCAL-Part)
- 모델이 객체의 part 정보로 세분화할 수 있도록 하며, PartImageNet 데이터와 PASCAL-Part 데이터는 instance-level의 주석이 다려있으므로 동일한 instance들을 병합하여 semantic-level로 만들고 이후 part-level 데이터들에도 ADE20K와 동일하게
[semantic]토큰을 도입합니다.
- 모델이 객체의 part 정보로 세분화할 수 있도록 하며, PartImageNet 데이터와 PASCAL-Part 데이터는 instance-level의 주석이 다려있으므로 동일한 instance들을 병합하여 semantic-level로 만들고 이후 part-level 데이터들에도 ADE20K와 동일하게
Experiments
평가 데이터는 RefCLEF, RefCOCO, RefCOCO+, RefCOCOg를 사용하였습니다. 평가 지표는 RES에서 사용하는 모든 test 데이터에 대한 평균 IoU를 의미하는 gIoU와, 누적 교집합/누적 합집합으로 구하는 cumulative IoU(cIoU)를 평가지표로 사용합니다.
Main Results
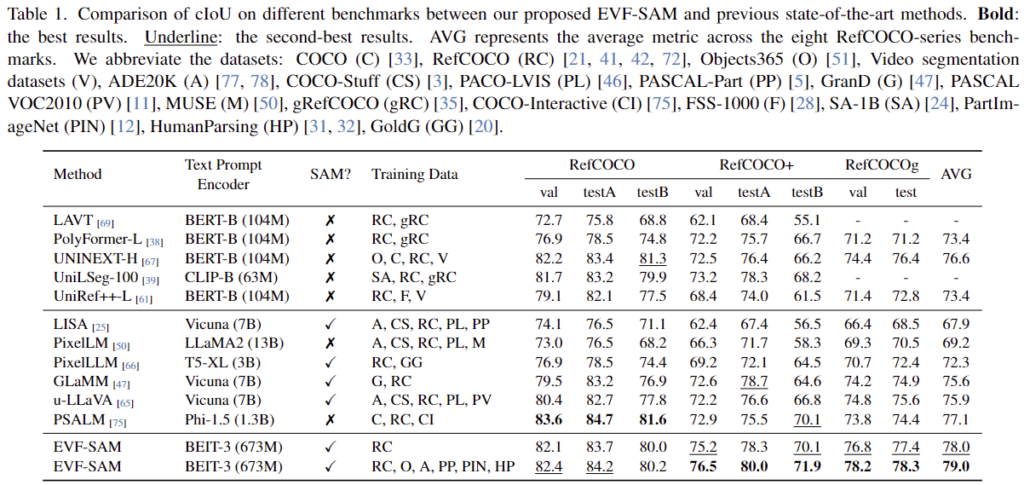
Table 1은 RefCOCO/+/g 데이터에 대한 cIoU 성능으로 크게 전통적인 RES 방식과 foundatio 모델을 사용하는 방식, 저자들이 제안한 EVF-SAM에 대한 결과를 나타냅니다. 정량적으로 EVF-SAM을 통해 성능이 대체로 개선되는 결과를 보인다는 것을 확인할 수 있습니다. 또한, 학습 데이터에 다양한 세분성의 데이터를 포함한 결과(마지막행) RefCOCO 데이터만을 이용하는 케이스보다 성능이 개선되는 결과를 통해 저자들이 제안한 데이터 전략의 효과도 보이고 있습니다.
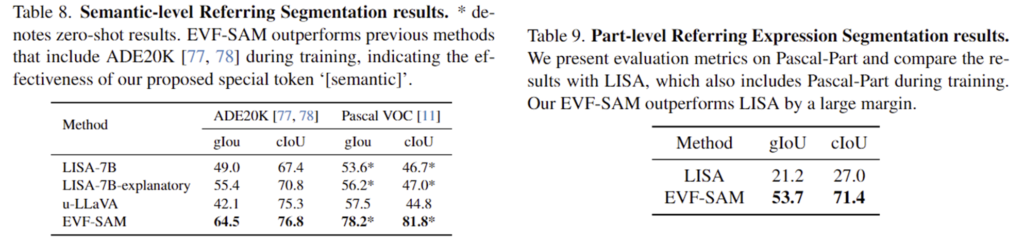
또한 Table 8과 Table 9는 다양한 세분성에 따른 정량적 결과를 리포팅한 것으로, 기존 방법론과 비교했을 때 성능 개선이 크게 이루어진 것을 확인할 수 있습니다. 또한, 아래의 figure6과 7은 이에 대한 정성적 결과입니다. 정서적 결과에는 기존 방법론을 함께 리포팅하지는 않아서 비교는 불가능합니다..

Ablation Study
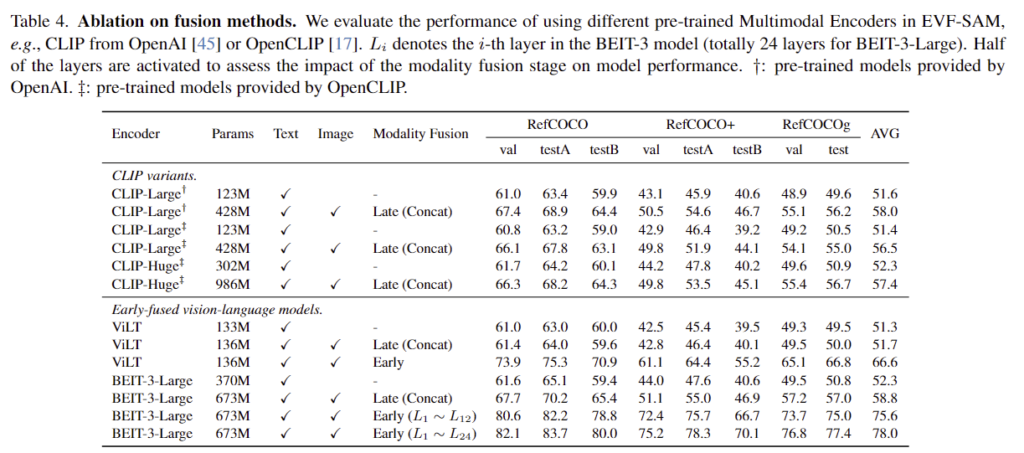
Table 4는 multimodal encoder(CLIP/ViLT/BEIT-3)와 fusion 방식(late-fusion/early-fusion)에 따른 성능을 리포팅한 것입니다. 성능을 보면 Text만 이용할 때 보다 이미지도 함께 이용하는 multi-modal 방식에서 성능이 개선되는 경향을 확인할 수 있으며, early-fusion 방식이 효과적임도 실험적으로 보였습니다. 이를 통해 저자들이 제안하는 EVF 방식에 대해 다시 어필합니다.

위의 Table 6은 3가지 모듈의 finetuning 여부에 대한 실험 결과입니다. 체크는 학습을 의미하는 것으로, SAM의 이미지 인코더는 freeze 되어있는 것이 가장 좋고, Multi-modal encoder를 fine-tuning할 경우 성능이 크게 개선됨을 통해 해당 모듈의 학습의 중요성을 확인하였습니다.
해당 논문에서 text-to-image attention map을 분석한 결과를 통해 기존의 late-fusion 방식의 필요성을 보인 것과 다양한 실험을 수행한 것은 인상적입니다.
안녕하세요 승현님 리뷰 감사합니다.
몇가지 질문이 있는데요, late-fusion 방식인 LISA에 대해서는 text-to-image 영역에 attention이 잘 이루어지지 않았는데 혹시 그 이유가 late fusion 방식의 특성 때문에 그런건가요? Early Fusion과 Late Fusion 둘 다 이미지와 텍스트를 섞는(?) 느낌으로 이해했는데 왜 early fusion을 해야하는건지 이해가 잘 되지 않습니다,,
또 All the {카테고리} 템플릿은 어떤 템플릿인가요?
리뷰 읽어주셔서 감사합니다.
text-to-image에 대한 attention이 잘 이루어지지 않은 이유는 이해하신 것 처럼 late-fusion 방식의 특성으로 보입니다. late-fusion 방식은 이미지의 feature를 추출한 뒤, 이를 LLM에 융합하여 LLM을 fine-tuning하는 방식으로 text feature에 visual feature의 정보를 추가된 것으로 이해하시면 될 것 같습니다.
“All the {카테고리}” 형태의 text 프롬프트를 이용하여 segmentation 결과를 추정하는 것을 의미합니다.
재밌는 논문 리뷰 감사합니다.
간단한 질문 남기고 가도록 하겠습니다.
text에 대한 XLM-Roberta Tokenizer에 대해서 간단하게 설명 부탁드려도 될까요? 처음 들어보는 tokenizer라서 어떠한 이점이 있어 사용했는지 궁금하네요.
[semantic]이라는 스페셜 토큰으로 표현에 대한 모호함을 단수로 해결할 수 있다는 점에서 재미있었는데요. fig 1 예시인 “zebra top left”처럼 해당 위치에 있는 얼룩말 하나만 분할하는 경우에는 스페셜 토큰으로 해결하는 방식이 오히려 독이 될 것 같습니다. 저자는 어떻게 해결하고자 했나요?
해당 tokenizer는 XLM-RoBERTa 모델에 사용되는 tokenizer로, XLM-RoBERTa는 다국어(multi-lingual) BERT 계열 모델에 대한 tokenizer로 한 언어에 대한 데이터가 적어도, 다른 언어의 subword 표현과 공유되는 특성 덕분에 low-resource 언어에서도 성능 유지할 수 있다는 장점이 있으며, subword 수준으로 분해하여 처리하여 새로운 단어에도 강인하다고 합니다. 논문에서 어떠한 이점이 있다는 것을 명시하지 않았으며, 다국어에 대한 실험을 진행하지 않아서 의문이긴 합니다. 잘 되는 tokenizer를 이용하지 않았을까요?
또한, 저자들은 학습에 사용될 데이터에 대하여 [semantic] 토큰을 도입하여 동일 물체가 하나일 경우와 여러개 존재할 경우를 모두 처리하고자 한 것으로, 해당 케이스의 겨우 단일 object로 처리하는 데 문제가 없을 것 같습니다.
하이요. 리뷰 읽다가 궁금증이 생겨서 질문 남깁니다.
해당 논문의 핵심은 결국 early fusion이 late fusion보다 좋다. 라고 보여지는데 여기서 왜 저자들이 제안한 방식이 early fusion이고 기존의 LLM 적용 방식은 late fusion인지 잘 모르겠어서요.
리뷰 내용에서는 “(a) CLIP과 같은 text encoder를 SAM과 함께 이용하는 방식은 위치정보를 추출하지 못하므로 성능 저하가 발생합니다. (b) 방식은 LLM을 이용하여 대상 물체에 대한 임베딩을 auto-regressive하게 생성하여 LLM을 fine-tuning하는 방식으로, 이는 visual feature를 추출한 뒤 이를 LLM에 융합하므로 late-fusion 방식으로 볼 수 있습니다.” 라고 적혀있었는데, 일단 (a) 경우에는 SAM에서 text과 image 정보가 합쳐지기 때문에 fusion이라고 볼 수 없는건가요? 그리고 (b)의 경우에는 auto-regressive하게 생성하여 fine-tuning한다는게 사실 감이 잘 안잡혀서 이게 왜 late fusion이라고 칭할 수 있는지 잘 모르겠어요.
그림만 놓고 봤을 때는 image encoder에서 추출된 visual feature가 LLM의 입력 토큰으로 함께 사용되는 것처럼만 보여서요 만약 그러한 방식이라면 (c) 방식도 결국 multi-modal encoder(BEiT)에 text token과 vision token을 함께 입력으로 넣어서 multi-modal token으로 만들어 사용하는거라 둘이 유사하다고 봐야하는거 아닌가요? b방식에 대해서 조금 더 부연설명해주시면 감사하겠슴다
리뷰 읽어주셔서 감사합니다.
일단 (a)를 fusion이라고 볼 수 없다기보다는, 이미지와 text에 대한 feature를 별도로 추출한 뒤 mask decoder를 통해 text에 대응되는 영역을 찾는 방식으로 두 정보에 대한 feature 추출 과정에 서로 영향을 주지 않는다는 점에서 (b)와 구분한 것으로 보입니다. 최종 goal 관점에서는 fusion으로 볼 수 있지만, 저자들은 feature를 추출하는 과정에 서로 영향 주는 것을 어필하고자 구분한 것으로 보입니다.
(b)에 대한 설명은 제가 잘못 정리한 것 같습니다. 각 feature 추출해서 최종 단에서 concate등의 방식으로 융합된 feature를 추출하면 late-fusion (b), multi-modal 데이터를 하나의 모델이 넣어 출력하면 earl-fusion(a)이라고 이해하시면 좋을 것 같습니다. 추가로 제가 (b)와 (c)의 차이를 저자들이 설명한 figure를 누락하여 추가해두었습니다..
추가로 이야기하신 것 처럼 visual feature가 LLm의 토큰에 함께 사용되는 방식도 이 과정에 visual feature 생성 과정에는 text feature가 영향을 주지 않는다고 보아 이 둘을 구분한 것으로 보입니다.
저자들이 late-fusion 방식으로 이야기하는 LISA방법론에 대해 확인해보니, 토큰을 추가하여 LLM에 다시 입력하여 text response를 만들고, 토큰에 MLP를 적용한 결과와 visual feature를 이용하여 segmentation map 생성하는 방식이라고 합니다. 이때, 학습 과정에 visual encoder는 freeze 하였다고 합니다. 해당 논문은 multi-modal encoder를 finetuning하므로써 visual feature에도 text가 영향을 줄 수 있도록 하였다는 점에서 early-fusion이라 표현합니다.
multi-modal LLM에서 segmentation을 위한
생성된 text에서
정리하면,
(a) feature 생성 과정에 fusion X
(b) text feature 생성 과정에 visusal feature 영향 줌
(c) visual & text feature 생성 과정에 서로 영향을 주도록 학습함
이 3가지를 구분하였습니다.